F1 Score in Production: How Medical AI, Content Moderation, and Fraud Detection Choose Their Metrics in 2026
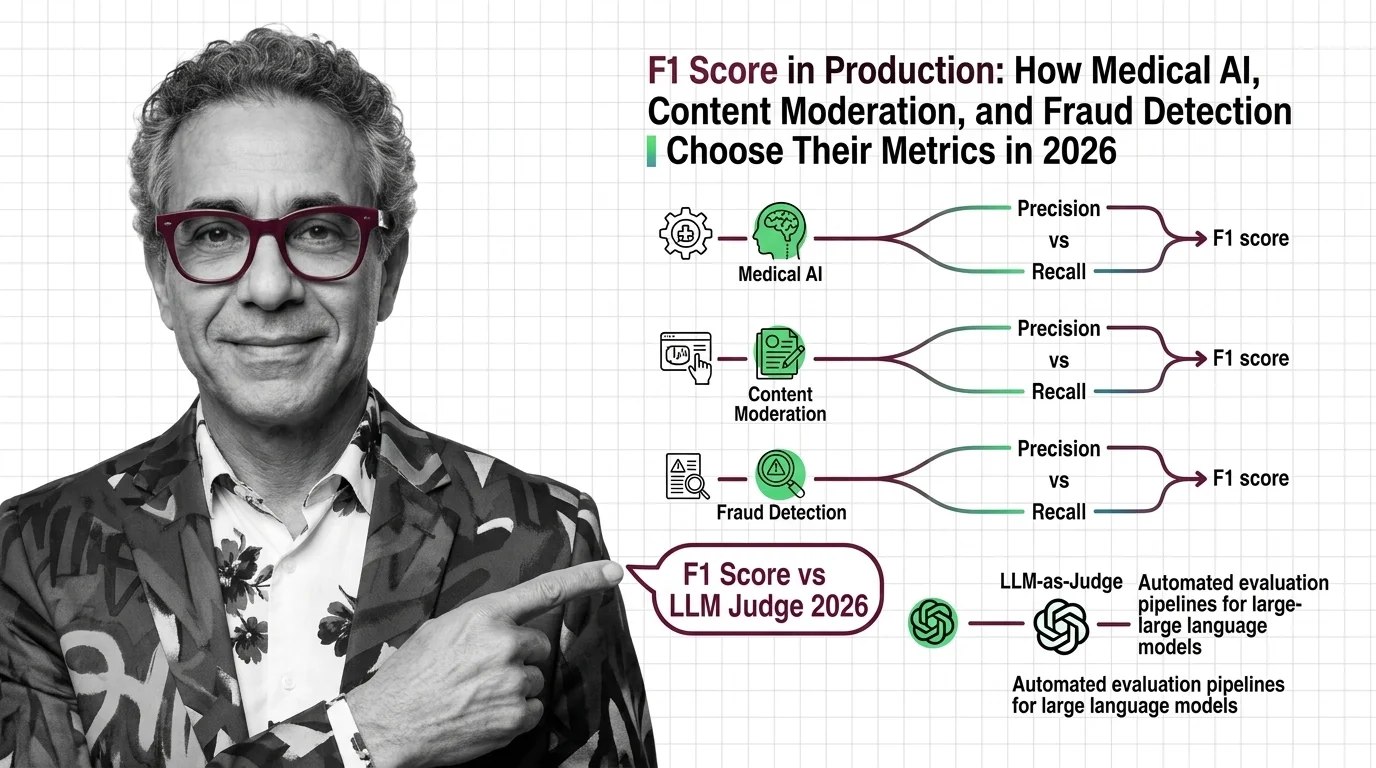
Table of Contents
TL;DR
- The shift: Production AI teams are abandoning F1 as a universal metric — medical, moderation, and fraud systems each optimize for different cost functions.
- Why it matters: Defaulting to F1 hides the failure mode your domain can least afford.
- What’s next: LLM-as-judge pipelines are making classification metrics optional for generative tasks.
The metric everyone learned first is no longer the metric serious teams default to. Precision, Recall, and F1 Score held the consensus for a decade of classification work. In 2026, production teams in three of the highest-stakes AI domains have each moved on — in three different directions.
That divergence is the signal worth reading.
The Default Metric Hit Its Ceiling
Thesis: F1 score’s reign as the universal evaluation standard is ending — not because it failed, but because production stakes exposed its blind spot.
F1 computes the Harmonic Mean of precision and recall. Equal weight to both. Clean, balanced, symmetrical.
Production AI is none of those things.
Medical AI teams screen for cancer. A missed tumor kills. A false alarm means one extra scan. Those costs are not symmetrical — and a metric that treats them equally hides the real risk. Research on medical AI evaluation found that F2 score, which weights True Positive Rate double, is preferred for screening tasks where missing a positive case carries the higher cost (Hicks et al., Scientific Reports).
Fraud detection exposed a different crack. F1’s default Classification Threshold caused 4-6% revenue loss in one documented case by blocking legitimate transactions (Kount). The fix wasn’t a better model. It was a threshold tuned to business impact, not statistical balance.
Content Moderation teams face pressure from both sides at once. Over-flag, and you trigger regulatory backlash and user revolt. Under-flag, and harmful content stays visible. Expanding recall aggressively collapses precision — every gain on one axis extracts a price on the other.
Three domains. Three cost structures. One metric that can’t serve all of them.
What the Numbers Actually Show
The structural weakness was always there. F1 ignores true negatives — the correct rejections that matter most when Class Imbalance defines the dataset. Matthews Correlation Coefficient uses all cells of the Confusion Matrix, and a peer-reviewed comparison found it more reliable on imbalanced data than F1 (Chicco & Jurman, BMC Genomics).
The FDA’s data makes the gap concrete. By end of 2025, 1,451 AI/ML medical devices had received authorization — 295 in 2025 alone, a record (IntuitionLabs). Yet only 1.6% cited randomized clinical trials. Less than 1% reported patient outcomes.
The FDA does not mandate specific F1 or precision thresholds. Acceptable values depend on clinical context and hospital requirements. Sensitivity — not F1 — is what regulators actually care about.
For generative AI, the evaluation question shifted entirely. Roc Auc and F1 measure the wrong thing when the output is text, not a label. LLM-as-judge pipelines now achieve over 80% agreement with human evaluators in specific pairwise comparison setups, comparable to inter-human consistency (Evidently AI). Known failure modes — position bias, verbosity bias, self-enhancement bias — remain active risks.
AI code review benchmarks still rank tools by F1. That makes sense — code review is a classification problem with relatively balanced error costs. F1 earns its keep when the cost asymmetry is small. Everywhere else, it’s a comfort metric.
Who Moved First
Teams that matched their metric to their domain’s cost function.
Medical AI companies running F-beta variants with beta tuned to clinical risk tolerance. Meta’s AI now catches roughly 5,000 daily password scams that human teams missed, with fake celebrity profiles down 80% (The Register). Meta did not disclose the specific precision or recall figures behind these results.
Fraud teams that moved past F1’s default threshold to optimize for revenue impact. LLM evaluation teams building automated judge pipelines instead of forcing classification metrics onto generative outputs.
The pattern: every winner stopped asking “what’s our F1?” and started asking “what does a wrong answer cost us?”
Who’s Still Running the Wrong Scoreboard
Anyone using
Scikit Learn’s classification_report() as the final answer without questioning whether F1 fits the domain.
Compatibility note:
- scikit-learn v1.8.0 (December 2025, Python 3.11-3.14):
y_predparameter inPrecisionRecallDisplay.from_predictionsdeprecated and renamed toy_score. Removal expected in v1.10.
Teams reporting accuracy on datasets that are 99% negative. Teams showing F1 to stakeholders who need to know the dollar cost per false positive.
You’re either choosing your metric deliberately or your metric is choosing your failure mode for you.
What Happens Next
Base case (most likely): F1 persists in academic benchmarks and leaderboards but loses its position as the default production metric. Domain-specific evaluation frameworks become standard in regulated industries. Signal to watch: Major cloud ML platforms adding domain-specific metric dashboards. Timeline: Mid-2026 to early 2027.
Bull case: Automated judge pipelines — LLM-as-judge combined with human-in-the-loop — replace manual metric selection for generative and hybrid systems. Signal: A top-three cloud provider ships evaluation-as-a-service that abstracts metric choice. Timeline: Late 2026.
Bear case: Regulatory fragmentation. Different jurisdictions mandate different evaluation standards for medical AI, content moderation, and financial AI, creating compliance overhead that slows deployment. Signal: EU AI Act enforcement actions citing inadequate evaluation methodology. Timeline: 2027.
Frequently Asked Questions
Q: Real world examples of precision vs recall tradeoff in medical AI and fraud detection? A: Medical screening uses F2 score to weight recall double — missing a tumor is costlier than an extra scan. Fraud detection tunes classification thresholds by transaction value because blocking legitimate purchases costs revenue that F1’s default threshold ignores.
Q: Is F1 score still relevant for evaluating large language models in 2026? A: For classification subtasks like entity extraction and code review, yes. For generative quality — summarization, reasoning, dialogue — LLM-as-judge pipelines and task-specific benchmarks have largely replaced it. F1 measures the wrong dimension when the output is text.
Q: How are LLM-as-judge and automated evaluation pipelines replacing traditional classification metrics in 2026? A: LLM judges score outputs on fluency, coherence, and factual grounding — qualities precision and recall cannot capture. In specific comparison setups, they match human evaluator agreement rates. Adoption is fastest where outputs are open-ended and classification labels do not apply.
The Bottom Line
F1 was the right default when classification was the only game. Production AI in 2026 runs on cost functions shaped by domain stakes, not statistical symmetry. The teams that matched their metric to their risk profile are already pulling ahead. Everyone else is measuring comfort, not performance.
Disclaimer
This article discusses financial topics for educational purposes only. It does not constitute financial advice. Consult a qualified financial advisor before making investment decisions.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors