Exact, Fuzzy, and Semantic Deduplication: The Components and Prerequisites of a Dedup Pipeline
ELI5
Data deduplication strips repeated text out of a training set in three escalating passes: exact copies caught by hashing, near-copies caught by fingerprint similarity, and meaning-level copies caught by comparing embeddings. Each pass finds what the previous one cannot see.
A language model trained on web-scale text will, under the right prompt, recite passages it was never meant to reproduce — phone numbers, license keys, paragraphs of someone’s blog, verbatim. The instinct is to call this a privacy bug. It is closer to an accounting error. The model saw those passages dozens or hundreds of times, and repetition is the most reliable teacher a neural network has. Deduplicate the training data, and that recitation drops sharply — language models emit memorized text roughly ten times less often after duplicates are removed, according to Lee et al. 2021.
So the first thing to correct: deduplication is not file cleanup. Deleting byte-identical files is the easy quarter of the problem. The hard three-quarters is finding the documents that are almost the same, and the ones that say the same thing in different words. Those are invisible to the tool most people reach for first.
The Three Passes That Clean a Dataset
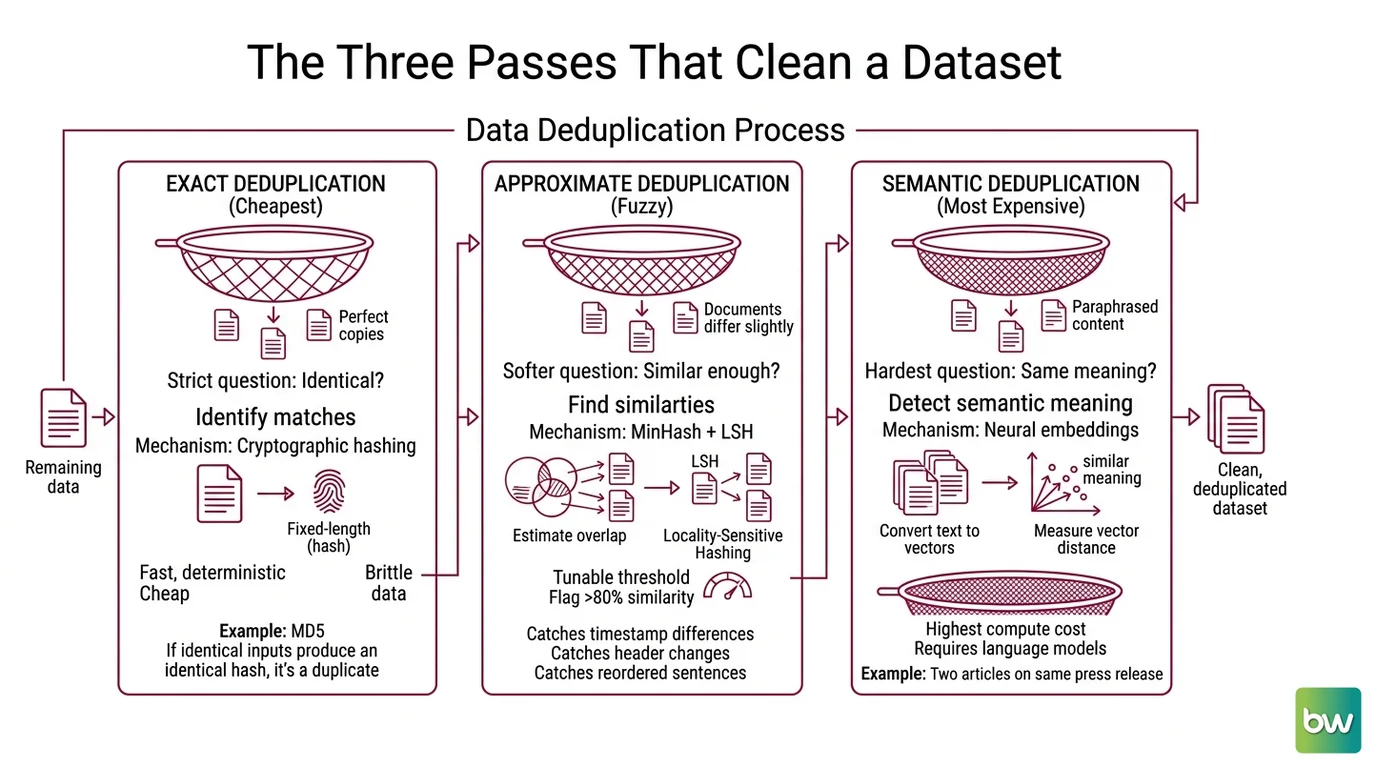
Think of Data Deduplication as three sieves stacked with progressively finer mesh. The top sieve catches boulders — perfect copies. The middle one catches gravel — documents that differ by a timestamp, a header, a reordered sentence. The bottom one catches sand — two articles that paraphrase the same press release. You need all three because each operates on a different notion of “same,” and a duplicate that slips through one mesh is caught by the next.
What are the three tiers of data deduplication: exact, approximate, and semantic?
The industry-standard taxonomy, as described in the NeMo Curator Docs, splits the work into three tiers, and the order matters because each is more expensive than the last.
Exact deduplication asks the strictest possible question: are these two documents character-for-character identical? The mechanism is cryptographic hashing — typically MD5. You run every document through the hash function, which collapses it into a short fixed-length fingerprint, then group documents whose fingerprints collide. Identical input always produces an identical hash, so this is fast, deterministic, and cheap. It is also brittle. Change one whitespace character and the fingerprints diverge completely, and the duplicate escapes.
That brittleness is the whole reason the second tier exists.
Fuzzy (approximate) deduplication asks a softer question: are these two documents similar enough? The canonical mechanism is MinHash combined with Locality Sensitive Hashing. MinHash produces a compact signature that estimates how much two documents overlap; LSH then buckets documents with similar signatures together so you never have to compare every document against every other. NeMo Curator’s default illustration flags pairs above roughly 80% similarity — but treat that number as a dial, not a law. The threshold is tunable through the number of hash functions, the number of LSH bands, and the Jaccard cutoff you choose.
Semantic deduplication asks the deepest question: do these two documents mean the same thing, even with no words in common? Here exact and fuzzy methods are both blind — “The cat sat on the mat” and “A feline rested upon the rug” share almost no tokens. Semantic Deduplication solves this by converting each document into an Embedding, a vector that encodes meaning, then clustering those vectors and comparing pairs within a cluster by Cosine Similarity. The reference method is SemDeDup, introduced by Meta AI (FAIR) and Stanford in March 2023. On a web-scale image-text corpus, SemDeDup removed about half the data with minimal performance loss and roughly halved training time, according to the SemDeDup paper — a striking result that says most of a raw web crawl is semantically redundant.
One caution on the framing itself: “three tiers” is the dominant way to describe this, not a formal standard. Some sources fold substring-level suffix-array dedup in as a fourth category. The boundaries are conventions, not physics.
What are the parts of a data deduplication pipeline?
A working pipeline is not a single algorithm; it is an assembly line, and each stage feeds the next.
The first stage is normalization — lowercasing, stripping boilerplate, Unicode cleanup. This is quiet but consequential, because every downstream comparison inherits whatever inconsistencies you leave in. The second stage is shingling and signature generation: documents are broken into overlapping token sequences (shingles), and from those shingles the system builds the fingerprints — a hash for exact matching, a MinHash signature for fuzzy, or an embedding vector for semantic.
The third stage is candidate generation, the step that makes the whole thing tractable. Comparing every document to every other is quadratic and impossible at scale, so LSH (for fuzzy) and clustering (for semantic) act as a coarse filter that proposes only plausible pairs. The fourth stage is verification and removal: candidate pairs are scored against the chosen threshold, and one member of each duplicate group is kept while the rest are dropped — or down-weighted, if you prefer to keep the signal without the multiplicity.
Production frameworks wire these stages together. NeMo Curator implements all three tiers with GPU acceleration; the open-source Text Dedup library offers MinHash+LSH, SimHash, suffix-array substring matching, and Bloom-filter methods in one place. If you follow an older NeMo Curator tutorial, verify the module paths against current docs — the API has been restructured into a stage/workflow model across recent releases, and deprecated paths surface in pre-existing guides.
What You Need Before You Can Dedup
Deduplication sits on top of a small stack of ideas that are individually simple and collectively the source of most confusion. You do not need all of mathematics; you need a precise grip on four or five concepts. Build those first, and every dedup tool stops looking like magic and starts looking like bookkeeping.
What do you need to understand before learning data deduplication?
Start with why duplicates harm a model at all, because the motivation shapes everything downstream. Duplicated training examples inflate the effective weight of whatever they contain, which drives Memorization — and that memorization scales log-linearly with model size, with how many times a sequence is duplicated, and with prompt length, according to Carlini et al. 2023. Removing duplicates is therefore not housekeeping; it is a direct lever on what the model will and will not parrot back. This is one corner of the broader discipline of Training Data Quality.
Next, understand Tokenization and shingling, because “document similarity” is always measured over sets of pieces, never over raw strings. A document becomes a set of tokens or token n-grams, and the choice of piece size silently determines how sensitive your comparison is. Then understand hashing as a concept — that a function can map arbitrary input to a fixed-length fingerprint where identical inputs collide by design. Exact dedup is nothing more than hashing plus grouping.
Finally, situate dedup among its neighbors. It is one technique in Data-Centric AI, sitting alongside Data Labeling And Annotation, Active Learning, and Data Augmentation. Note the directional tension: augmentation deliberately manufactures controlled variation, while dedup deliberately removes uncontrolled repetition. Confuse the two and you will fight your own pipeline.
What concepts like Jaccard similarity and hashing are required to understand MinHash dedup?
MinHash rests on one elegant idea, and once you see it the rest follows. The idea is Jaccard Similarity: for two sets A and B, their similarity is the size of their intersection divided by the size of their union — the fraction of distinct pieces the two documents share. Treat each document as a set of shingles, and Jaccard gives you a clean number between 0 (nothing in common) and 1 (identical sets).
The problem is that computing exact Jaccard over millions of documents means comparing enormous sets pairwise, which is too slow. This is the gap MinHash fills. MinHash applies many independent hash functions to a document’s shingle set and keeps only the minimum hash value from each. The mathematical payoff is precise: the probability that two documents produce the same minimum under a random hash function equals their Jaccard similarity. So a short MinHash signature — say a few hundred numbers — becomes an unbiased estimator of a quantity that would otherwise be expensive to compute.
LSH then exploits that estimate. It chops each signature into bands and hashes the bands into buckets, arranging things so that documents sharing high Jaccard similarity are very likely to land in the same bucket while dissimilar documents almost never do. You only compare documents that share a bucket. The chain of dependencies is therefore: shingling defines the sets, Jaccard defines similarity over sets, MinHash estimates Jaccard cheaply, and LSH turns that estimate into a sub-quadratic search. Miss any link and the next one has nothing to stand on. Substring-level methods take a different route entirely — the Suffix Array approach indexes all suffixes of the corpus to find long repeated spans rather than whole-document overlap.
What the Three Tiers Predict About Your Data
Once you treat the tiers as three different definitions of “same,” the behavior of a dedup pipeline becomes predictable rather than mysterious.
- If you run only exact dedup and still see memorized output, the duplicates surviving are near-copies — boilerplate headers, mirrored pages, reformatted reposts. Escalate to fuzzy.
- If fuzzy dedup removes a far larger fraction than you expected, your corpus likely contains heavy templating or scraped mirrors; that is a signal about your source mix, not a bug in the tool.
- If semantic dedup removes a large slice on top of fuzzy, you are looking at paraphrase-level redundancy — multiple outlets covering one event — which exact and fuzzy methods are structurally unable to detect.
The practical consequence is that the tiers are cumulative, not alternative. Each one earns its compute cost only after the cheaper one upstream has already done its work, because running embeddings over a corpus you haven’t first cheaply pruned wastes the most expensive stage on documents a hash would have caught for free.
Rule of thumb: Run the tiers in cost order — exact, then fuzzy, then semantic — and tune the fuzzy threshold to your corpus rather than trusting any default.
When it breaks: Aggressive thresholds destroy legitimate diversity. Push the fuzzy similarity cutoff too low or the semantic cluster radius too wide, and you delete genuinely distinct documents that merely share structure or topic — collapsing the variety a model needs to generalize, in the name of removing duplicates that were never there.
The Data Says
Deduplication is three answers to one deceptively simple question — “are these the same?” — applied at the level of characters, fingerprints, and meaning. The payoff is measurable: less memorized output, smaller datasets, and in the semantic case, roughly half the data and half the training time gone with minimal loss. The cost of getting it wrong is just as real, because a threshold tuned by reflex rather than by your corpus erases the diversity it was meant to protect.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors