Does Deduplication Fix Memorization and Copyright Regurgitation, or Just Hide It?
The Hard Truth
If a model no longer recites a copyrighted passage word-for-word, but will hand you the same passage the moment you ask it to paraphrase — has the harm been removed, or merely made harder to see? And if the difference between those two states is a filtering step, who decided that invisibility counts as a fix?
There is a quiet confidence in the way the industry talks about training data now. Clean the corpus, remove the duplicates, and the most embarrassing failures of large language models — verbatim regurgitation, leaked private records — are supposed to fade. The engineering is real. What troubles me is the word we keep reaching for: solved. A reduction in what a system reveals is not the same as a reduction in what it knows.
The Comfort of a Number That Drops
We like problems that respond to interventions we can count, and deduplication is exactly that kind of problem. The harm appears to shrink on a dashboard, and a shrinking number feels like progress.
But the question underneath the dashboard is harder than the metric admits. Does removing duplicate text actually reduce the risk that a model reproduces someone’s copyrighted work or exposes someone’s personal data — or only the rate at which we catch it doing so? Those are not the same claim: one is about the model’s behaviour, the other about our visibility into it. We keep treating them as interchangeable, and that is where the trouble begins.
What the Evidence Genuinely Supports
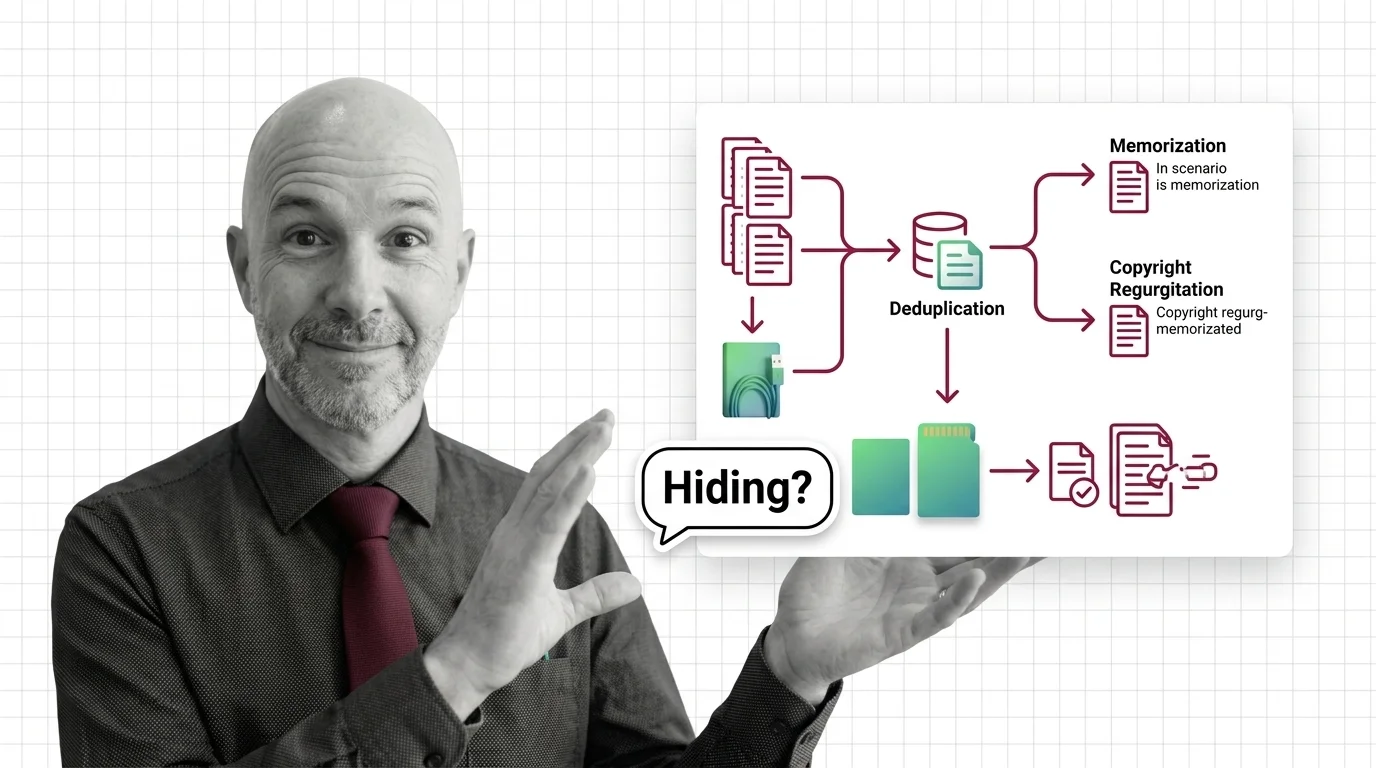
It would be dishonest to wave this away as mere optics, because the case for Data Deduplication is strong and well-earned. The foundational work is careful measurement, not marketing. Removing duplicated sequences makes models emit memorized text roughly ten times less frequently, a result established by Lee et al. 2022. The redundancy they found was extreme — a single sixty-one-word passage repeated more than sixty thousand times in the C4 corpus — and before cleaning, more than one percent of a model’s unprompted output was copied verbatim from its training set.
The privacy findings point the same way. Models trained on deduplicated data regenerate their training examples around twenty times less often, according to Kandpal et al. 2022, who also surfaced the mathematics beneath it: the link between duplication and Memorization is superlinear, so duplication does not merely add risk, it multiplies it. Dedup removes that amplifier — a genuine gain for Training Data Quality, not a cosmetic one.
So the steelman is sturdy, and the tools are mature — MinHash with locality-sensitive hashing for fuzzy matches, Suffix Array removal for exact overlaps, and curated pipelines like NVIDIA’s NeMo Curator that cut a dataset by twenty to fifty percent while holding or improving model quality, per the NeMo Curator documentation. Less data, less leakage, no loss of capability. If that were the whole story, there would be nothing more to say.
The Assumption Hiding Inside the Win
Here is the assumption almost nobody states aloud: that what a model memorizes is the text we can see it repeating. Strip the detectable duplicates, and detectable memorization falls — but memorization was never confined to the strings we know how to search for.
The cracks are already documented. Fuzzy, near-duplicate passages — reworded but substantively the same — contribute up to roughly eighty percent of the memorization an exact duplicate would, yet sit almost entirely outside the reach of standard dedup, as Mosaic Memory 2024 demonstrates. Worse, blocking verbatim output can manufacture a false sense of privacy, a phrase Ippolito et al. 2022 chose deliberately: a system that refuses to recite a passage word-for-word will often surrender the same content the instant you ask for a paraphrase. And memorization does not require heavy duplication: Carlini et al. 2023 found it grows steadily with model size, with duplication, and with prompt length, occurring even for sequences seen only a handful of times. Dedup pushes against one of those three levers and leaves the other two untouched.
And the demonstration that should have ended the “solved” framing entirely: a simple divergence attack drove a production, aligned model to emit training data about a hundred and fifty times more often than normal, with content extractable in gigabytes — the Nasr et al. 2023 result. The data was still in there, waiting behind a behaviour we mistook for absence.
Pruning a Garden Is Not the Same as Changing the Soil
The mental model I keep returning to is not technical at all. Picture a garden where weeds keep returning: deduplication is aggressive weeding that clears what shows above the surface, while the seeds remain in the soil, ready for a differently worded request to bring them back. We change what is showing, not what the ground contains.
This matters because three distinct concerns have been folded into one. Copyright regurgitation, privacy leakage, and raw memorization are not the same harm, and a 2026 position paper argues they deserve to be treated separately. Memorization is largely syntactic — it lives in surface form — so Semantic Deduplication, for all its value in trimming redundant meaning, targets a different axis than verbatim copying. A copyright passage and a leaked medical record are not interchangeable risks, and one technique cannot discharge both. When we report a single number and imply all three are handled, we are not informing the public. We are reassuring it.
The Honest Verdict
Thesis: Deduplication is a real and valuable mitigation, but framing it as a fix for copyright regurgitation and privacy memorization mistakes a reduction in visible symptoms for a reduction in underlying risk.
The discomfort is the point. Mitigation is not a lesser word — where elimination may be impossible, it is the responsible goal. What is irresponsible is the slide from “we reduced the rate” to “we resolved the issue,” because that slide changes who carries the remaining risk. A person whose data still lives, latent, inside a model has been told, on their behalf, that good enough is good enough — without ever getting a vote.
The Questions We Owe the People in the Data
So what do we owe here? Not a checklist, but a few questions that refuse to settle. If a harm is reduced but not removed, who is accountable for the residue — the lab that trained the model, the team that curated the corpus, or no one, because the metric looked acceptable? And if the most effective defenses make leakage harder to demonstrate rather than impossible to occur, have we built safety or deniability?
None of this is a reason to abandon deduplication. It is a reason to stop letting it stand in for the harder commitments — consent, provenance, and the willingness to say plainly what a technique does not do.
Where This Argument Is Weakest
I should name the conditions under which I would soften this. If future work showed that the residual memorization left after aggressive dedup is so hard to surface that it poses no realistic risk — that the latent seeds never germinate under any practical prompting — then “mitigation” would shade close to “fix,” and my insistence on the distinction would look like alarmism. The published extraction attacks suggest we are not there yet. This argument rests on that empirical question, not on moral intuition alone.
The Question That Remains
Deduplication makes models forget how to recite. It does not make them forget what they were shown. The open question is not whether the technique works — it plainly does something worth doing — but whether we have the discipline to keep calling it what it is, when the more comfortable word is sitting right there.
Ethically, Alan.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors