Data Leakage, Lost Information, and the Technical Limits of Preprocessing Pipelines

ELI5
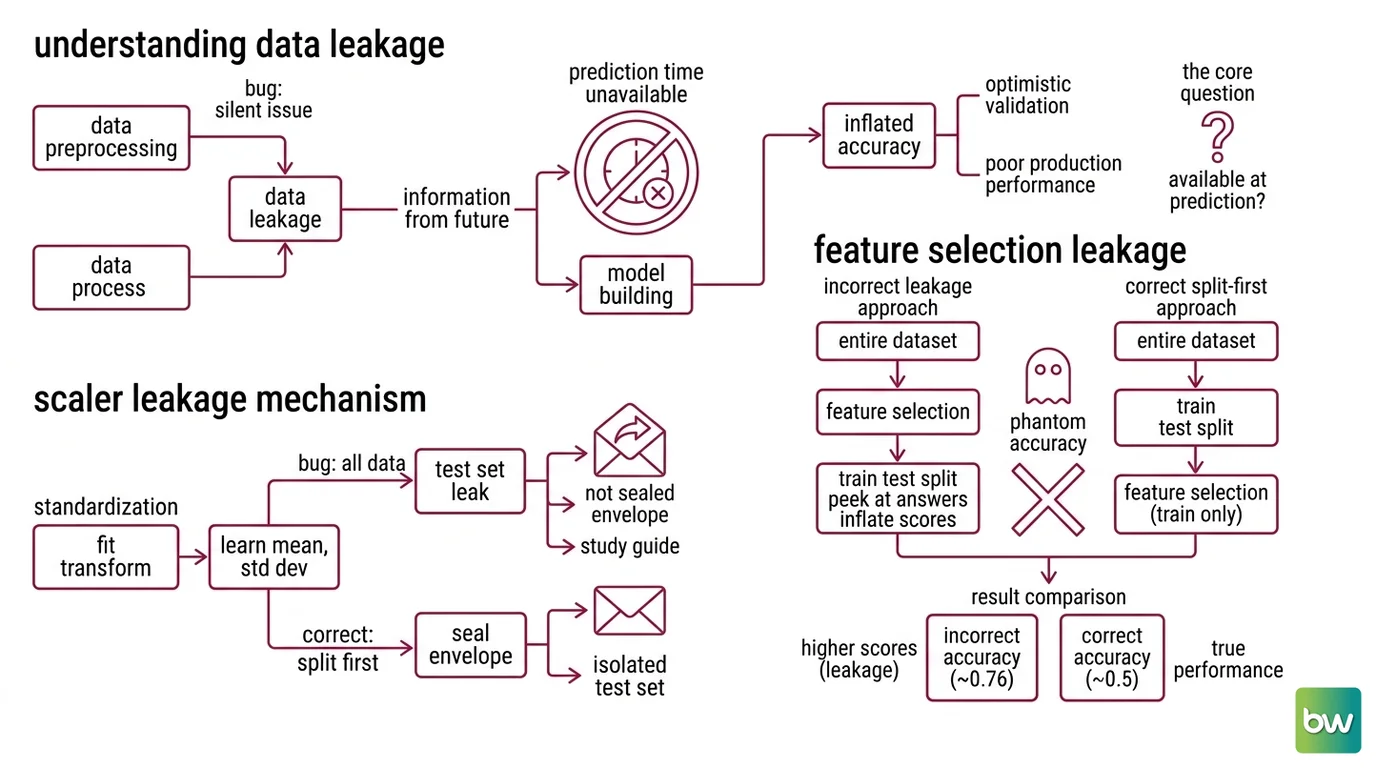
Data leakage is when information your model won’t have at prediction time sneaks into training. The score looks great in testing, then collapses in production — because the model was quietly graded on answers it already saw.
A classifier sails through every validation check with an accuracy near 0.76. It looks ready. Then it goes live, and on real data it drifts toward a coin flip. Nobody touched the model. The architecture is sound, the hyperparameters are reasonable, the loss curve is clean. The failure was baked in earlier — not by the estimator, but by the order in which the data was touched before the estimator ever saw it.
The instinct is to blame the model: wrong algorithm, weak regularization, too few epochs. That instinct is almost always wrong here. The accuracy was never earned. It was borrowed from rows the model was never supposed to see, and production is simply the moment the loan gets called in.
The Accuracy That Came From the Future
Most Data Preprocessing bugs are not exceptions or crashes. They are silent — the code runs, the numbers look good, and the damage shows up only when reality stops cooperating. To see why, follow a single piece of information as it moves through the pipeline and ask one question at every step: would this information actually be available at the moment of prediction?
What is data leakage in preprocessing and how does it inflate model accuracy?
Data Leakage occurs when information that would not be available at prediction time is used while building the model, producing overly optimistic validation scores and worse performance in production (scikit-learn Docs). The mechanism is subtle because it hides inside a step everyone treats as harmless: preprocessing.
Consider a scaler. Standardizing a feature means subtracting its mean and dividing by its standard deviation. To do that, the transform has to learn two numbers — the mean and the standard deviation — from some set of rows. The bug appears when those numbers are learned from the entire dataset before the Train Test Split. Now the mean encodes a little bit of every test row. When you later evaluate on the test set, the model is scored on data whose summary statistics already shaped the features it trained on. The test set stopped being a sealed envelope; it became a study guide.
Feature selection leaks the same way, only worse. In scikit-learn’s documented example, running SelectKBest().fit_transform(X, y) across the full dataset before splitting inflates accuracy to roughly 0.76, while the correct split-first approach lands near 0.5 — chance, for that dataset (scikit-learn Docs). The selector peeked at the relationship between features and the target across all rows, including the ones it would later be tested on, and quietly picked the features that happened to work on the answers.
The phantom accuracy is not a measurement of skill; it is a measurement of how much the test set leaked. That is why it evaporates in production: live data has no answers to leak.
The fit/transform asymmetry that keeps the test set sealed
The fix is an asymmetry, and it is mechanical rather than clever. A preprocessing step has two operations. fit learns parameters from data — the mean, the standard deviation, the category vocabulary, the top-k features. transform applies those learned parameters. Leakage is what happens when fit ever touches the test set.
The rule scikit-learn states plainly: never call fit on the test data; split first, then learn every transformation from the training subset alone (scikit-learn Docs). In practice that means fit_transform on the training data and transform — never fit — on everything that follows. The test set gets standardized using the training mean, encoded using the training vocabulary, projected using the training features. It is treated exactly the way live production data will be treated: as something the model has never seen and cannot learn from.
This is also why a scikit-learn Pipeline is more than a tidiness habit. It binds preprocessing and estimator into a single object so that, during cross-validation and hyper-parameter tuning, the right method runs on the right subset automatically — fit stays inside each training fold, transform handles the held-out fold (scikit-learn Docs). The pipeline does not make leakage impossible. It makes the correct order the path of least resistance, which for a class of bugs this invisible is most of the battle.
Not a modeling error. An accounting error — about which rows are allowed to inform which numbers.
Every Transform Throws Something Away
Leakage is the failure of using too much information. The quieter limitation runs the other direction: every preprocessing transform you apply correctly still destroys information on purpose. Scaling and encoding are not neutral format changes. They are lossy compressions, and the loss has consequences you can predict.
What are the technical limitations of feature scaling and categorical encoding?
Feature Scaling reshapes the distribution of a feature so that algorithms sensitive to magnitude — gradient descent, distance-based methods, regularized models — behave well. But the reshaping is not free.
Standardization (subtract the mean, divide by the standard deviation) assumes the spread of your data is meaningfully summarized by a single standard deviation. When a feature has heavy tails or genuine extreme values, those values get compressed toward the bulk of the distribution. The model still sees them, but their relative distinctiveness — the very thing that might make them informative — is flattened. Normalization to a fixed range like [0, 1] has the mirror problem: it is acutely sensitive to Outlier Detection failures. A single extreme value sets the maximum, and every other point gets squeezed into a narrow band near zero. One unhandled outlier can quietly erase the resolution of an entire column.
Categorical Encoding carries a different cost. One Hot Encoding turns a categorical column with k distinct values into k binary columns. With a handful of categories this is fine. With a high-cardinality column — postal codes, product IDs, user agents — it triggers a dimensionality explosion: thousands of new columns, almost all of them zero for any given row. That sparsity dilutes distance metrics, inflates memory, and gives many models a wider surface to overfit on. The encoding preserved every category faithfully, and in doing so it changed the geometry of the space the model has to learn in.
There is no transform that adds information; there is only transform that trades one kind of loss for another. The skill is choosing which loss your model can afford — and that choice depends on the algorithm downstream, not on the data alone.
What the Pipeline Order Predicts
Once you see preprocessing as an information-flow problem, several failure modes become predictable rather than mysterious. This is the difference between knowing the rules and understanding why they hold.
- If your validation accuracy is far above what the problem plausibly allows, suspect leakage before you suspect genius — check whether any
fitran before the split. - If your model performs well in cross-validation but degrades in production, look for transforms learned outside the training fold, especially feature selection, target-based encodings, and Missing Data Imputation computed on the full dataset.
- If a single numeric feature seems to carry no signal after scaling, check whether one outlier collapsed its range during normalization.
- If a tree-based model suddenly slows down and overfits after you add a categorical feature, suspect a one-hot explosion from a high-cardinality column.
These predictions hold because they all trace back to one invariant: the model may only learn from information that will exist at prediction time. Feature Engineering that respects that boundary generalizes; feature engineering that crosses it produces scores that are, quite literally, too good to be true.
Rule of thumb: Split first, then fit every transform on the training subset only — and wrap the whole sequence in a pipeline so the order cannot drift.
When it breaks: The hardest leakage to catch is temporal. When rows are correlated across time — the same user, the same sensor, the same account appearing in both train and test — a random split scatters tomorrow’s information into yesterday’s training set, and even a correctly ordered pipeline will report an accuracy that production cannot reproduce.
A note on the tooling that enforces all of this, since both libraries shifted under teams’ feet recently:
Compatibility notes (as of mid-2026):
- Pandas 3.0: Copy-on-Write is now the default and only mode. Chained assignment no longer works and
SettingWithCopyWarningis gone, so defensive.copy()calls in older preprocessing scripts are unnecessary — but scripts that relied on in-place chained mutation will silently behave differently. Current stable is 3.0.3 (pandas Release Notes).- scikit-learn 1.9.0: No preprocessing-API breakage; the
fit/transformandPipelinecontracts described above are unchanged (scikit-learn PyPI).
The Data Says
Leakage and lossy transforms are two sides of the same accounting problem: a model is only as honest as the information boundary it respects. A validation score is not a property of the model — it is a property of how carefully the test set was kept sealed. Split before you preprocess, fit only on training data, and treat every scaling or encoding choice as a deliberate trade of one kind of information loss for another.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors