Cross-Encoders, Bi-Encoders, and Listwise Scoring in Reranking
ELI5
A Reranking model is a second, more expensive scorer that reads the top candidates from a first retriever and reorders them — sometimes one document at a time, sometimes the whole shortlist at once. The architecture and the loss function decide which.
The temptation is to treat reranking as a single black box: a knob you turn after vector search to make the top results “better.” Then engineers wire one in, watch query latency jump by an order of magnitude, and start asking why. The honest answer is that there isn’t one reranker. There is a small family of architectures, each making a different trade between cost and how much of the candidate list it gets to see at once.
What you need to understand before reranking makes sense
Reranking does not exist in isolation. It is the second stage of a pipeline that begins with retrieval — and the failure modes of the first stage define what the reranker is even allowed to fix. Most of the confusion about reranking comes from skipping the layer underneath it.
What do you need to understand before learning how reranking works?
Three pieces of context, in order.
First, the surrounding system. Reranking sits inside a Retrieval Augmented Generation pipeline, where a language model answers from external evidence retrieved at query time. The pipeline does not let the model search the whole corpus; instead, a fast retriever shortlists candidates and only those candidates ever reach the model. Whatever the reranker can do, it can only do to that shortlist.
Second, the difference between bi-encoders and cross-encoders, because that single choice separates retrieval from reranking. A bi-encoder embeds the query and each document independently — two separate forward passes through the model — and then compares them by cosine similarity in a shared vector space. The encoding of every document can be precomputed once and stored in an index.
That is what makes vector search fast.
A Cross-Encoder concatenates the query and a single document into one input, runs a full transformer over the joined sequence, and emits a relevance score from the joint attention. Nothing can be precomputed; you have to run the model fresh for every (query, document) pair.
That is what makes cross-encoders accurate, and slow.
Third, the metric. Whatever a reranker does, it is judged on how well its top-K results match a labeled gold list. The standard is nDCG at cutoff 10 — Normalized Discounted Cumulative Gain. nDCG sums per-position relevance gains, discounts each by log₂(rank+1) so deeper positions count less, and normalizes by the ideal achievable score so the result lives in [0, 1] (Evidently AI). On BEIR — the standard heterogeneous IR benchmark from NeurIPS 2021 — every reranker number you read is averaged nDCG@10 across 18 zero-shot tasks (BEIR (NeurIPS 2021)). When a vendor says their reranker is “stronger,” this is almost always the number they are quoting.
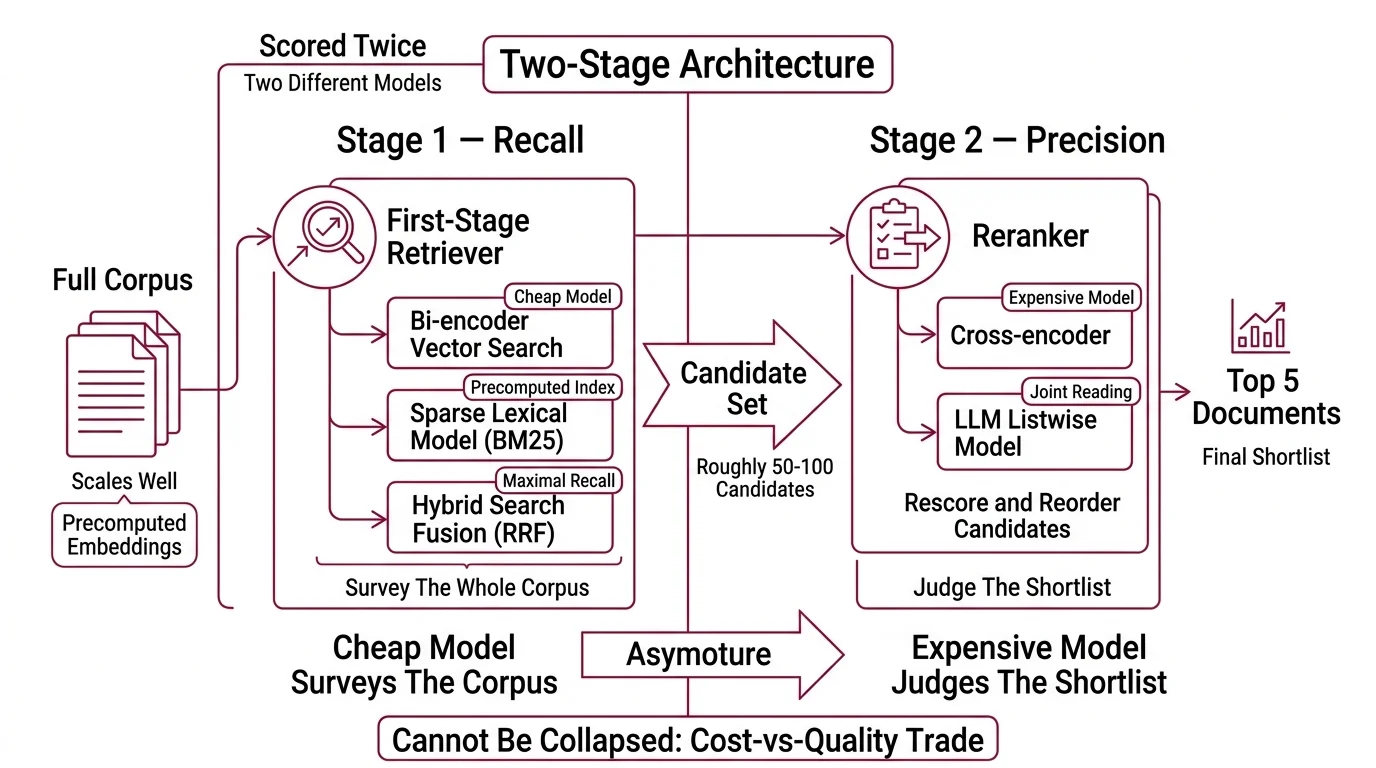
The two-stage architecture and why it cannot be collapsed
Modern retrieval is a two-stage problem because the operations that scale are not the operations that rank well. Vector search scales because every document embedding can be precomputed and nearest-neighbor structures find the closest k vectors in sublinear time. The cost of that speed is that the score is a coarse geometric distance — it says “these documents are about something similar,” not “this document answers this query.” A cross-encoder produces the second signal, but its cost grows with the size of the candidate set. So the system splits the work: the cheap model surveys the whole corpus, the expensive model judges the shortlist.
What are the main components of a two-stage retrieve-and-rerank pipeline?
Two stages, with sharply different cost profiles.
Stage 1 — Recall. A first-stage retriever pulls roughly 50–100 candidate documents from the full corpus (Pinecone Docs). The retriever is usually a bi-encoder running dense vector search, a sparse lexical model like BM25, or a Hybrid Search setup that fuses both with Reciprocal Rank Fusion. It runs against an index that was built once, ahead of time. The job of this stage is to maximize the chance that at least one good answer is somewhere in the shortlist; precision of the ordering does not matter yet.
Stage 2 — Precision. A reranker — typically a cross-encoder, increasingly an LLM-based listwise model — re-scores those candidates by reading each (query, document) pair jointly and reorders the list. Production setups commonly narrow N=50 candidates down to K=5 (Pinecone Docs). The reranker never sees the documents the retriever missed; it can only re-sort what the first stage handed it. That asymmetry is the single most important architectural fact in this pipeline.
The mechanical reason both stages exist is that the same query is scored twice, by two different models, and the cost-vs-quality trade is split between them. Running a cross-encoder over the entire corpus would buy higher precision at a latency cost no production system absorbs. Skipping the cross-encoder and ranking by vector distance alone would publish whatever the embedding geometry happened to favor that day.
The two-stage idea has lived in classical IR for decades, but the concrete shape used in modern RAG was popularized by monoBERT — the original BERT-based passage reranker, which encoded query and document jointly through [CLS] q [SEP] d and trained a relevance classifier on top (Nogueira & Cho (2019)). Almost every cross-encoder reranker shipped since is an architectural descendant of that 2019 design.
Three shapes of relevance scoring
Cross-encoder vs bi-encoder describes how the model encodes a (query, document) pair. It says nothing about how many candidates the model considers when it makes a decision. That second axis — the size of the comparison window in the loss function and in decoding — is where the pointwise / pairwise / listwise distinction lives. It is also what changes when teams move from a classical cross-encoder to an LLM-based reranker.
Pointwise vs pairwise vs listwise reranking: what are the differences?
Three regimes, distinguished by how much of the candidate list the model sees at once when it makes a scoring decision.
Pointwise. The model looks at one (query, document) pair at a time and predicts a relevance score in isolation. Training is a regression or classification problem: given the pair, output a score. Candidates are then sorted by score independently. This is what almost every production cross-encoder does —
BGE Reranker, Cohere’s rerank-v4.0-pro and rerank-v4.0-fast (Cohere Docs),
Mixedbread Rerank (mxbai-rerank-large-v2), and ZeroEntropy’s
Zerank (zerank-2). Pointwise dominates production. It is fast, easy to batch, and good enough for most workloads. The blind spot is that the score for document A does not know anything about document B; the model has no way to express “A is better than B but worse than C” except as three separate forward passes.
Not noise in the score. A boundary in the model’s view.
Pairwise. The model looks at two documents at a time and predicts which one is more relevant. The training objective is a preference, not an absolute score, which captures the structure of relevance more faithfully — but the cost of scoring all pairs is O(N²). The historical reference is duoBERT (Nogueira et al., 2019), which slotted in after monoBERT to refine the top of the list. In modern leaderboards, pure-pairwise rerankers have largely disappeared from production; the regime survives mostly as a training signal for stronger pointwise and listwise models (Nikhil Dandekar, Medium / TDS).
Listwise. The model looks at the whole shortlist at once and produces a permutation. The classical formulation backs ListNet and LambdaMART (Nikhil Dandekar, Medium / TDS); the modern formulation runs on an LLM that reads many candidates inside one prompt and emits a reordered list of identifiers. RankGPT (Sun et al., 2023) is the canonical example — it prompts an LLM to permute candidates with a sliding window over a top-100 list (RankLLM / Castorini). Production listwise rerankers exist: jina-reranker-v3 is a 0.6B-parameter
Listwise Reranking model that uses causal self-attention across a query plus up to 64 documents in a 131K context window, and reports an averaged BEIR nDCG@10 of 61.94 (Jina AI News).
The mechanical difference matters because inter-document dependencies are invisible to pointwise models. If two candidates are near-duplicates, a pointwise reranker scores them both highly and ranks them adjacently, even though only one of them adds information to the answer. A listwise model can see both at once and demote the redundant one.
The cost order is what you would expect: pointwise < pairwise < listwise. The accuracy order is roughly the inverse — but only on tasks where inter-document dependencies actually exist.
What this predicts about your evaluation and your costs
Once you can name the three axes — bi-encoder vs cross-encoder, two-stage architecture, pointwise/pairwise/listwise — most other reranking decisions become a function of those axes.
A few predictions follow directly:
- If you grow the shortlist from N=50 to N=100, the upper bound on reranker recall rises but inference cost grows roughly linearly. Pointwise rerankers absorb this gracefully; listwise rerankers do not, because their context window has to hold every candidate at once.
- If your queries return many near-duplicate candidates — long policy documents, technical docs with repeated boilerplate — a pointwise reranker will rank duplicates adjacently; a listwise reranker is more likely to deduplicate the top of the list.
- If nDCG improves but downstream answer quality does not, the bottleneck is upstream. A reranker only sorts what the retriever returned, and missing documents do not show up in the metric.
- If your pipeline relies on exact-identifier matches — error codes, drug names, version strings — a dense-only first stage will silently miss them no matter how strong the reranker is. The fix lives in retrieval (lexical or hybrid), not reranking.
The same axes predict where the architecture is heading. Agentic RAG pipelines, where an LLM decides what to retrieve next based on what it has already read, push the reranker into a tighter loop with the generator. The reranker stops being a one-shot reorder and becomes a per-step relevance check. The cost calculus changes: many small reranks instead of one big one.
Rule of thumb: start pointwise, measure on a labeled set, and only escalate to listwise once you have evidence of inter-document dependencies — duplicate detection, multi-document synthesis, queries with multiple correct answers.
When it breaks: rerankers have no training signal for queries unlike anything in their training distribution. On highly domain-specific corpora — internal jargon, regulatory text, code — a generic reranker can score worse than the bi-encoder underneath it, because the pre-training distribution does not cover what “relevant” means in that context.
Compatibility & licensing notes:
- Cohere Rerank
rerank-v3.5: Superseded byrerank-v4.0-proandrerank-v4.0-fast. Older code samples and 2025 documentation still cite v3.5 — update references to v4.- Voyage
rerank-2/rerank-2-lite: Superseded byrerank-2.5/rerank-2.5-litein August 2025. Same price, longer context, instruction-following added.zerank-2license: Released under CC-BY-NC-4.0 — non-commercial only. Commercial use requires a separate license from ZeroEntropy. Calling zerank-2 “open” without that caveat is misleading.- BGE Reranker v2-m3 max length: Technically 8192 but BAAI recommends 1024, the fine-tuning length (Hugging Face — BAAI). Quoting 8192 as the practical limit overstates real-world quality.
The Data Says
Reranking is a recall-to-precision conversion: the first stage chooses what enters the room, the second chooses who speaks first. Cross-encoders dominate the second stage because joint attention beats geometric distance, and most production rerankers stay pointwise because the cost of seeing more of the list at once climbs faster than the quality gain. Listwise wins in the narrow regime where candidates depend on each other.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors