Context Window Collapse, Tool-Call Loops, and the Hard Technical Limits of Coding Agents in 2026
Table of Contents
ELI5
Coding agents fail not because the models got dumber, but because long prompts dilute attention, tool-call retries pile up garbage tokens, and benchmarks reward task patterns that production code rarely matches.
The demo shows a Claude agent finishing a feature end-to-end in a single sitting. The same agent, given your actual repository, churns through file reads, retries the same failing test, and confidently submits a patch that does the wrong thing. Both behaviors come from the same machine. The gap between them is the topic of this article.
The Long-Context Illusion
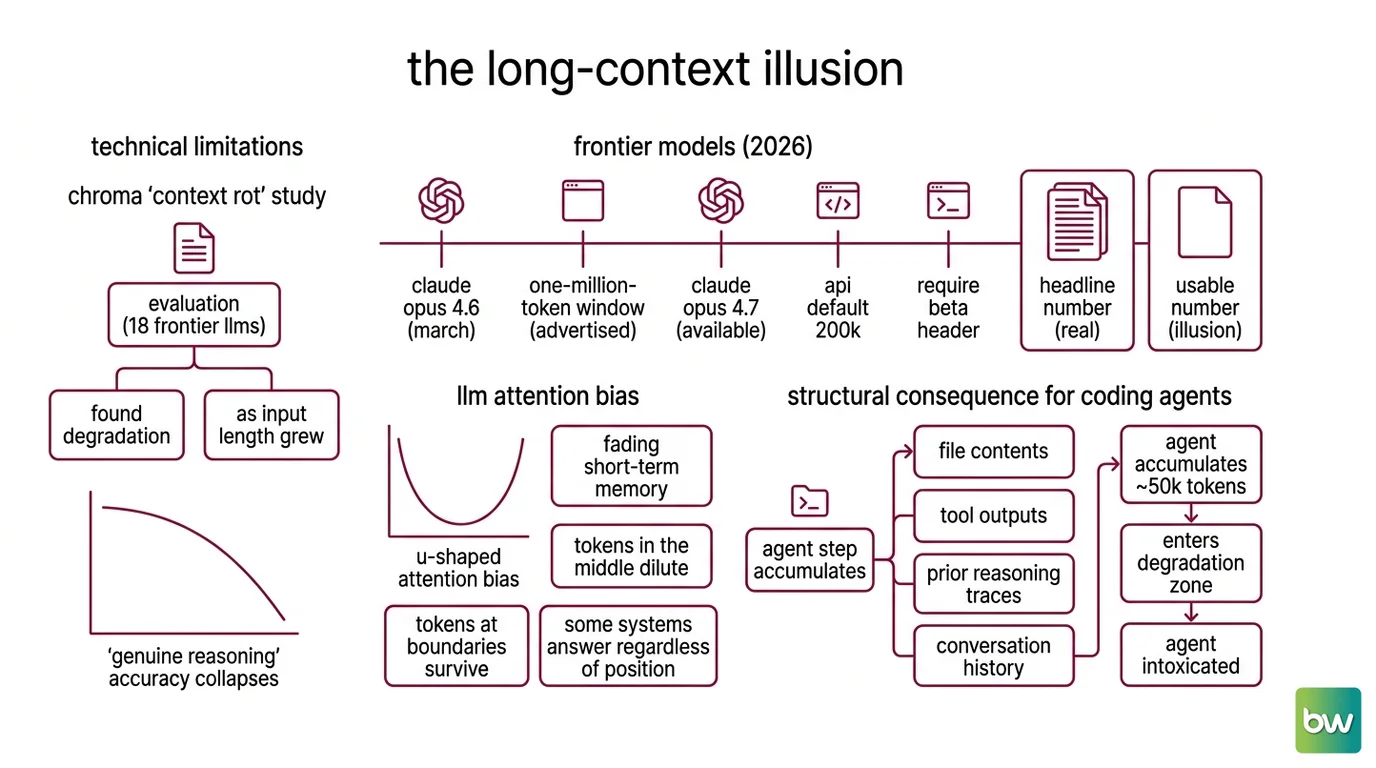
Frontier models in 2026 advertise context windows that would have sounded impossible two years ago. Claude Opus 4.7 comes with a one-million-token window (Claude API Docs). Claude Opus 4.6 reached the same milestone in March, though the API still defaults to 200K tokens unless you pass the anthropic-beta: context-1m-2025-08-07 header (Claude API Docs). The headline number is real. The usable number is not.
What are the technical limitations of agentic coding tools in 2026?
The Chroma “Context Rot” study evaluated 18 frontier LLMs — including GPT-4.1, Claude 4, Gemini 2.5, and Qwen3 — and found that every single one degraded as input length grew (Chroma Research). The drop is not gentle. On tasks that require genuine reasoning rather than keyword lookup, accuracy collapses well below baseline somewhere in the tens of thousands of tokens. LLMs do not process context uniformly.
The Context Window is better understood as a fading short-term memory than as a flat memory buffer. Tokens near the boundaries — beginning and end — survive. Tokens in the middle dilute. Liu et al. described this U-shaped attention bias in their 2023 “Lost in the Middle” paper (arXiv), and although newer architectures handle the middle region better, the effect remains model-dependent rather than solved. Some 2026 systems answer needle-in-a-haystack questions regardless of position. Others still fail predictably.
For a coding agent, the consequence is structural. A single agent step may swallow file contents, tool outputs, prior reasoning traces, and conversation history before it ever reaches a decision. Factory.ai’s engineering team has reported that an agent can accumulate roughly fifty thousand tokens before the first real action — already inside the degradation zone for many frontier models (Factory.ai). The agent isn’t slow. It’s intoxicated.
When the Agent Talks to Itself
Behavioral failures in coding agents do not look like syntax errors. They look like patience.
The “Stuck in Loop” pattern — formally documented in the “Beyond Resolution Rates” study (arXiv) — describes an agent that repeatedly reads the same files, reruns the same tests, and reissues the same Model Context Protocol calls without making progress. It is distinct from execution errors, where a tool call is malformed, and from semantic errors, where the logic is simply wrong. It is the machine convincing itself that one more lookup will reveal the answer that was never there.
Tool-call loops are not accidental. They are baked into how SWE-bench scaffolds work. Standard scaffolds retry after every failed test, and the retry count and prompt structure measurably affect final scores. The implicit assumption is that retrying with more context produces a better answer. The actual outcome, when context is already saturated, is that each retry adds more noise to a prompt the model can no longer parse cleanly.
Compression looks like the obvious fix. It is also the trap. An ICLR 2026 paper on context compression found that monolithic LLM-driven rewriting degrades across iterations — summaries get shorter and less informative, task-specific detail evaporates, and the agent’s later steps lose the structure it needed (ICLR 2026 paper). Strong agentic performance depends on retaining detail, not laundering it through paraphrase.
The pattern is geometric, not psychological. Each iteration moves the prompt away from the manifold of well-formed inputs the model was trained on. Eventually it crosses a boundary, and the next sampled token starts to drift.
Not consciousness. Statistics.
The Benchmark Doesn’t Save You
SWE-bench Verified is the public scoreboard for coding agents. The May 2026 leaderboard puts Claude Mythos Preview at the top with 93.9%, followed by Claude Opus 4.7 (Adaptive) at 87.6% and GPT-5.3 Codex at 85.0% (SWE-Bench leaderboard). Those numbers describe what is solvable on a curated, well-scoped benchmark. They do not describe what is solvable in your repository.
Two caveats need to land at the same time. First, even the top scorer fails on more than one in five tasks — the failure floor for SWE-bench Verified has held above 20% across submissions as of early 2026 (arXiv). Second, OpenAI stopped reporting SWE-bench Verified scores in early 2026, citing contamination concerns, and now recommends SWE-bench Pro as the cleaner comparison (Morph LLM). The benchmark is under audit, not retired, and headline scores should be read with that asterisk.
Long-horizon evaluation is where 2026’s quiet shift is happening. SWE-EVO, released in December 2026, targets multi-step software-evolution scenarios that explicitly stress-test what happens when an agent must hold a moving target across many steps. The metric matters because the failure modes covered in this article — context rot, loop collapse, compression decay — only show up when the task is long enough to expose them. A four-step bug fix on a clean repo does not.
What the Mechanism Predicts
The shape of the failure modes lets you predict where production agents will break before you watch them do it.
- If the agent’s prompt regularly crosses the fifty-thousand-token mark before its first decision, expect quality to degrade on tasks that require synthesis of mid-context information — even on a model with a 1M-token window.
- If your scaffold retries on test failure without changing the prompt’s structural shape, expect tool-call loops on any task the model cannot solve in two attempts.
- If you summarize previous steps with another LLM call, expect detail loss to compound across iterations. The third compression often discards the constraint the agent needed to satisfy.
- If you migrate model IDs mid-project — for example, code still referencing the Claude Sonnet 4.0 or Opus 4.0 identifiers — expect behavioral regressions that are unrelated to capability. They are the new model interpreting your old prompt’s edge cases differently.
Rule of thumb: the advertised context window is your hard ceiling; the usable context window is whatever length your specific task and model preserve attention quality across — and you have to measure it.
When it breaks: Agentic coding fails when accumulated context, retry depth, or compression iterations push the prompt outside the distribution the model was trained to handle confidently. At that point, the next token is no longer a reasoning step; it is just a plausible-sounding sample.
Compatibility notes:
- Claude Sonnet 4.0 / Opus 4.0 model IDs: Hard cut-off 2026-06-15. Migrate references to current model IDs before that date or the request will fail.
- Gemini CLI: Stops serving Pro, Ultra, and free Code Assist on 2026-06-18; replaced by Antigravity CLI. Update agent scaffolds that target Gemini CLI endpoints.
- SWE-bench Verified: Scores remain published, but treat them as contested — OpenAI cites contamination concerns and recommends SWE-bench Pro for new comparisons.
The Failure Modes Are Stackable
The most uncomfortable property of these limits is that they compound.
A long context dilutes attention. A diluted attention layer produces a marginal decision. A marginal decision triggers a tool-call retry. The retry appends more tokens. Compression intervenes to shrink the prompt — and discards a constraint. The next decision is now worse than the first one. Each subsystem behaves correctly in isolation. The composition is what breaks.
This is the reason AI Code Migration from human-written legacy code to agent-maintained code is harder than Vibe Coding a greenfield prototype. Greenfield work fits inside the early-context window where attention is strong. Migration forces the agent to hold a moving model of a system it did not write — exactly the scenario where the failure modes stack.
The Data Says
The 2026 frontier model gives you a million-token context, a top-of-leaderboard benchmark score, and a confident demo. None of those numbers describe what the agent will do on your codebase after the prompt crosses the rot zone, the scaffold retries three times, and the compression step strips out the constraint that mattered. The limits are not in the marketing material because they are emergent — they show up when the failure modes stack, and they show up faster than the benchmark suggests.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors