Combinatorial Explosion, Interaction Effects, and the Hard Limits of Ablation Studies at Scale
Table of Contents
ELI5
Ablation studies test a model by removing parts one at a time. But at billion-parameter scale, the number of possible combinations explodes exponentially, and parts interact in ways that single removals never reveal.
Here is a paradox worth sitting with: the most rigorous method for understanding what a neural network component does — remove it, measure the damage — becomes the least rigorous method precisely when the network matters most. The systems we most need to understand are the ones where the technique designed to understand them quietly stops working.
The Exponential Hiding Inside a Simple Subtraction
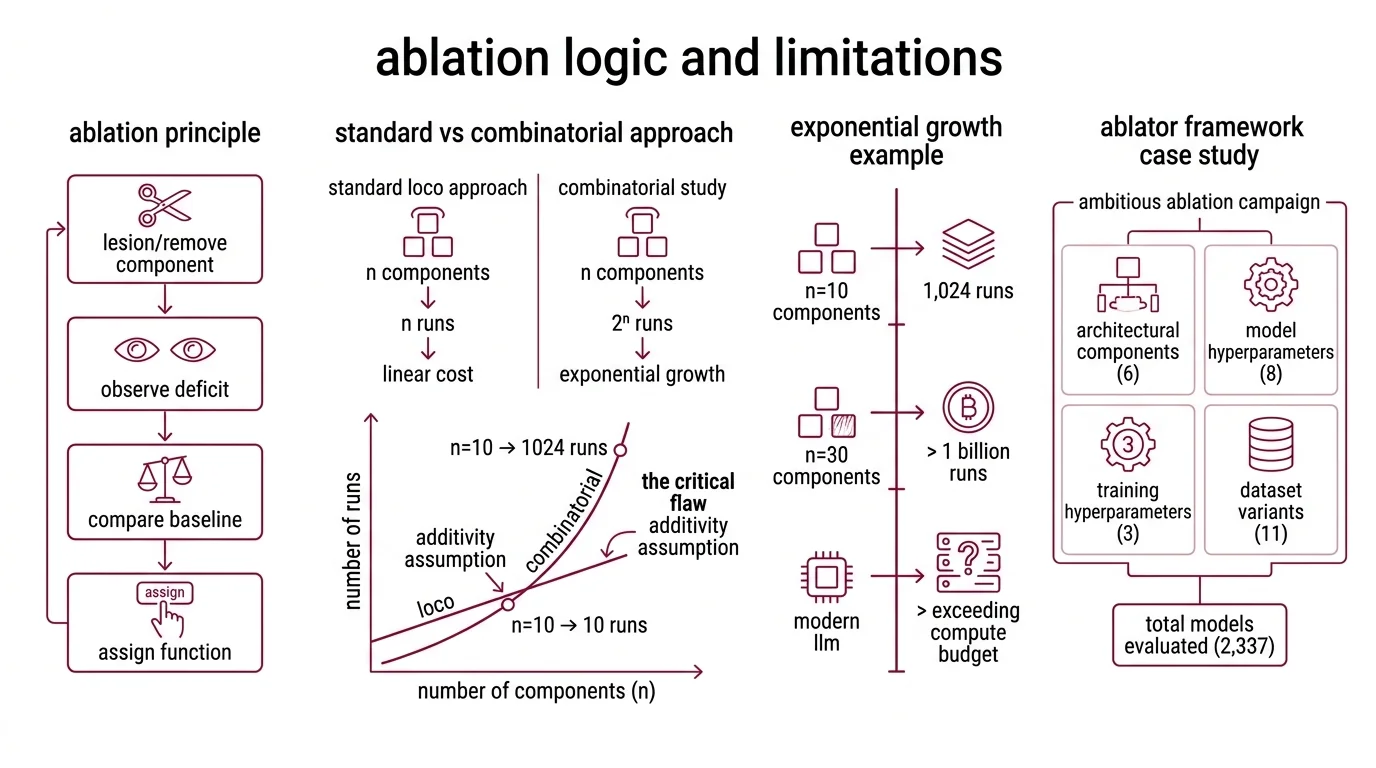
An Ablation Study borrows its logic from neuroscience. Lesion a brain region, observe the deficit, assign function. Allen Newell adapted this principle for speech recognition in 1974 (Wikipedia), and the reasoning has barely changed: remove a component, compare against a Baseline Model, measure what degrades.
The standard approach — Leave-One-Component-Out, or LOCO — tests n components in n runs. Linear cost. Clean attribution. For a system with ten modules, ten experiments; manageable with any reasonable compute budget.
The problem arrives when you notice what LOCO quietly assumes.
What are the limitations of ablation studies for large language models?
LOCO assumes each component contributes independently to the final output. Remove attention head #7, the model loses exactly what head #7 provided — nothing more, nothing less. This is the additivity assumption, and it is the critical flaw hiding inside every single-component ablation.
For a full combinatorial study — testing every possible subset of n components — the required experiments grow as O(2^n). That figure assumes binary include/exclude per component; real ablation designs sometimes use graduated removal rates, which reshapes the combinatorial profile without resolving the exponential growth (Na et al.). A model with 30 ablatable components demands over one billion subset evaluations. A modern large language model with hundreds of identifiable architectural decisions — attention heads, layer normalization positions, activation functions, residual connection patterns, Hyperparameter Tuning choices — sits in a search space that exceeds any physical compute budget available.
The ABLATOR framework, one of the more ambitious ablation campaigns in the literature, evaluated 2,337 models across six architectural components, eight model hyperparameters, three training hyperparameters, and eleven datasets (Fostiropoulos & Itti). That enormous effort barely scratches the surface of the full combinatorial space for a single architecture family.
LOCO gives you a map of n individual removal effects. What it misses is every interaction between them — and that, as it turns out, is where most of the interesting behavior lives.
When Removing Two Parts Breaks More Than Removing Each Alone
Think of a neural network not as a stack of independent filters but as a chemical solution. Each layer, each attention head, each normalization step is a dissolved solute. The behavior of the solution depends on concentrations and reactions between them — not on the properties of each solute measured in a separate beaker.
Why do ablation studies fail to capture component interactions in deep networks?
Meyes et al. demonstrated that combined ablations produce effects stronger than the sum of individual ablations — a clear marker of non-additive component interactions. Remove attention head A, measure the drop. Remove normalization layer B, measure that drop. Remove both, and the performance collapse exceeds the two individual drops summed together. The system is not modular in the way the ablation protocol assumes.
An important caveat: these interaction effect measurements were performed on computer vision benchmarks, not on billion-parameter language models. Whether the same non-additive dynamics hold in transformer-based LLMs at scale is assumed by structural analogy — deep networks with residual connections and multi-head attention create the coupled dynamics where non-additivity would be expected — but the direct empirical confirmation for language models remains a gap in the literature.
The implication for Model Evaluation is immediate. If head A’s contribution depends on the presence of head B, then removing A while B remains tells you what A does in the context of B — not what A does in general. The ablation measures a conditional contribution; the difference between that conditional contribution and the true contribution is the interaction term that LOCO structurally cannot observe.
A component that appears dispensable in single-removal testing may be carrying information that becomes critical only when a partner is also absent.
Not redundancy. Codependence.
The consequence is that LOCO systematically underestimates functional importance. Ablation-based attribution in deep networks is, at best, a lower bound on the true contribution. At worst, it misleads — guiding architectural decisions on the basis of conditional measurements presented as absolute ones.
Meyes et al. also showed that networks can recover from ablation damage via continued training after component removal. This recovery suggests ablation measures a network’s immediate fragility, not the long-term importance of the missing part. The distinction matters to anyone using ablation results to justify removing a module from an architecture.
The GPU-Hours Nobody Has
Even accepting the theoretical limitations and designing a more thorough protocol — testing pairwise or higher-order interactions — you immediately collide with a wall made of money.
How does computational cost limit ablation studies for billion-parameter models in 2026?
The estimated training cost for GPT-4 was approximately $78 million in compute; Gemini Ultra, roughly $191 million; Llama 3.1 405B, around $170 million (Stanford AI Index). These figures are estimates from the Stanford AI Index 2025 and Epoch AI — actual costs, including failed runs, R&D staff, and infrastructure overhead, are proprietary and almost certainly higher. Training costs have grown at roughly two to three times per year over the past eight years, with compute requirements doubling approximately every five months (Epoch AI). Dario Amodei has publicly projected that frontier models could eventually exceed $1 billion to train — a statement, not a peer-reviewed estimate, but one consistent with the observed growth curve.
A single LOCO ablation of a GPT-4-class model — removing one component and retraining to convergence — would cost tens of millions of dollars. For n components, the bill multiplies linearly. For the O(2^n) full study, the number stops having practical meaning.
Na et al. proposed a creative workaround: modular training, where component models are trained independently and merged via parameter averaging. This reduces O(2^n) data-mixture ablation to O(n) by approximating each data source’s contribution without retraining the full model for every combination. In their experiments, 231 data-mixture pairs were evaluable in 640 GPU-hours versus 2,688 naively — a 76% reduction (Na et al.). The trade-off is fidelity: parameter averaging introduces approximation error, and the approach applies to data-mixture ablation specifically, not to architectural component ablation.
The field sits between two constraints. Full ablation is too expensive. Partial ablation is affordable but misleading. The cost of a single training run sets the floor of ablation, not the ceiling — and that floor rises with every generation of frontier model.
What the Arithmetic Predicts
If you are designing an ablation experiment for a model with more than roughly twenty components, full combinatorial analysis is computationally out of reach — plan for targeted interaction tests instead. If removing a single attention head has negligible effect on downstream Precision, Recall, and F1 Score, do not conclude the head is unimportant; it may carry redundant information that becomes critical only when a second component is also removed.
The Reproducibility implications cut deep. Two research groups ablating the same architecture but testing different component subsets can reach contradictory conclusions about the same component — and both can be technically correct, because they measured different conditional contributions. The results will not fail a Statistical Significance test. They will pass one, for a question narrower than what the researchers intended to ask.
For evaluation pipelines that rely on ablation to attribute credit to architectural innovations — common in papers reporting gains on the MMLU Benchmark and similar leaderboards — the interaction problem means reported attribution may overstate isolated contributions and understate interactive ones. In a field already contending with Benchmark Contamination, adding uncertain ablation attribution compounds the difficulty of knowing what actually drives performance on any given Confusion Matrix-derived metric.
Rule of thumb: If your ablation target has more than fifteen components and your evaluation metric is aggregate — accuracy, perplexity, or a single score — assume your results are informative about first-order effects only. For interaction effects, design targeted pairwise experiments and state the conditional scope of your findings explicitly.
When it breaks: Ablation results become actively misleading when used to justify removing a component from a production architecture. A module that appears redundant under LOCO may prove critical under a different removal combination. The Na et al. modular training approximation lowers cost but introduces its own fidelity gap. No current method provides both exhaustive interaction coverage and feasible compute for billion-parameter models.
The Data Says
The fundamental tension of ablation at scale is mathematical, not technical. The method was built for systems where components are roughly independent. Modern neural networks are not those systems. Until a technique emerges that can probe high-order interactions without full retraining, ablation remains a useful first-order diagnostic — and a misleading second-order one. The gap between those two orders is where most of the architecture’s actual behavior hides.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors