ColPali, MUVERA, and PyLate: How Multi-Vector Retrieval Went Multimodal in 2026
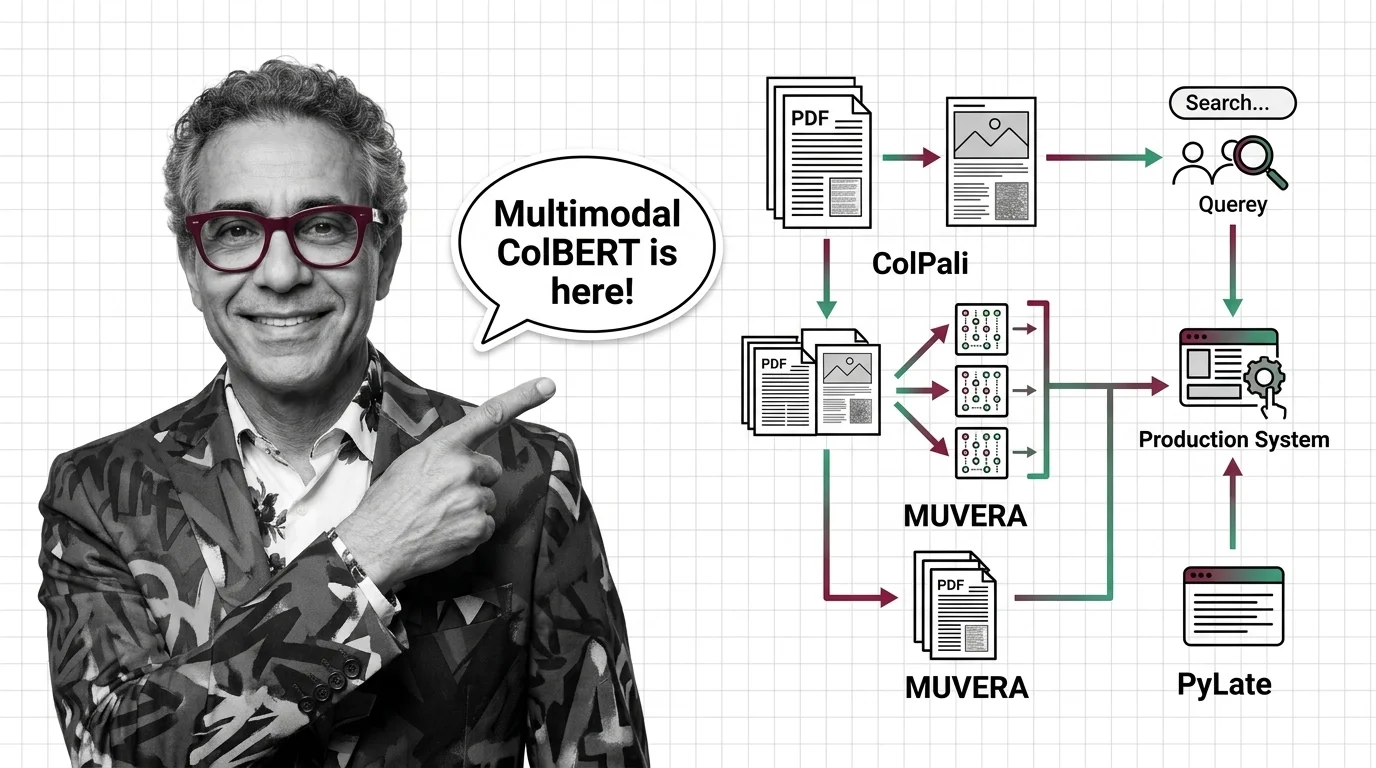
Table of Contents
TL;DR
- The shift: Multi-vector retrieval absorbed vision models and gained compression, turning document search into a visual-first, hardware-efficient problem.
- Why it matters: Teams still running OCR pipelines for document retrieval are building on a layer that just became optional.
- What’s next: The first dedicated academic workshop at ECIR 2026 signals consensus — production tooling will follow fast.
For years, the retrieval stack had a clean division. Text went through text models. Images went through image models. Documents got OCR’d before anything useful could happen. That division just collapsed. Three independent research efforts — ColPali, MUVERA, and PyLate — converged on the same conclusion: Multi Vector Retrieval is the architecture that absorbs multimodal search, and the tooling is ready.
The Retrieval Stack Just Split — Again
Thesis: Multi-vector retrieval is no longer a niche research technique — it is the default architecture for teams that need to search documents, not just text.
For most of 2024, the Embedding conversation was dominated by single-vector models. Faster. Cheaper. Good enough.
The ColBERT family of late-interaction models stayed in the research lane — promising but impractical for production deployments that cared about memory and latency.
Then three things happened at once.
Colpali showed that document pages could be embedded directly as images, bypassing OCR entirely. Google’s MUVERA solved the cost problem by compressing multi-vector representations into single-vector-compatible indexes. And PyLate gave the open-source community a training framework that made ColBERT variants accessible to anyone with a GPU.
Each development was interesting alone. Together, they rewrote the economics.
Three Papers, One Direction
ColPali landed at ICLR 2025 with a simple premise: stop extracting text from documents. Treat every page as an image and let a vision-language model generate the embeddings (ColPali Paper). The benchmark it introduced — ViDoRe — became the standard for visual document retrieval. The latest official variant, ColQwen2.5-v0.2, scores 89.4 on ViDoRe, with community forks from independent contributors pushing past 90.9 (ColPali GitHub).
Two lightweight variants — ColSmol at 256M and 500M parameters — proved the approach works at the edge. The colpali-engine repository has roughly 2,600 GitHub stars and ships integrations with Qdrant, Weaviate, Elasticsearch, and Vespa.
That’s adoption velocity, not academic curiosity.
MUVERA, presented at NeurIPS 2024 by Google Research, attacked the infrastructure bottleneck. Multi-vector retrieval is expressive but expensive — storing per-token embeddings burns memory and slows Similarity Search Algorithms. MUVERA compresses multi-vector representations into fixed-dimensional encodings compatible with standard single-vector indexes. The result: 10% higher recall than PLAID with 90% latency reduction on BEIR benchmarks, and 32x memory reduction via product quantization (Google Research Blog).
Weaviate shipped MUVERA support in v1.31. On the LoTTE-lifestyle dataset, memory dropped from 12 GB to under 1 GB (Weaviate Blog).
That’s the gap between interesting research and deployable infrastructure.
PyLate, accepted at CIKM 2025, completed the triangle. Built by LightOn on top of Sentence Transformers, it gave the community a training and retrieval framework for late-interaction models — including FastPLAID Vector Indexing for production speed (PyLate Paper). Models like GTE-ModernColBERT and Reason-ModernColBERT came out of this ecosystem.
The clearest institutional signal: the first Workshop on Late Interaction and Multi-Vector Retrieval at ECIR 2026, keynoted by Omar Khattab — the creator of ColBERT (LIR Paper).
When the field creates its own workshop, the research phase is over.
Compatibility note:
- colpali-engine + PyTorch 2.6.0: MPS compatibility issue with ColQwen models on Apple Silicon. Downgrade to PyTorch 2.5.1 recommended.
Who Owns the New Stack
Vector databases that moved early. Qdrant added native multivector support in v1.10+ with ColBERT via FastEmbed. Vespa shipped a long-context ColBERT embedder with compression. Weaviate integrated MUVERA. These three built the infrastructure layer before demand arrived — and now they’re the default options for teams adopting multi-vector search.
Open-source framework builders. Ragatouille by Answer.AI made ColBERT accessible inside RAG pipelines and sits at v0.0.9. PyLate took the training side. Between them, the barrier to entry dropped from “publish a paper” to “pip install.”
Jina AI locked the multilingual lane with Jina-ColBERT-v2, covering 89 languages.
Teams with document-heavy workflows — legal, medical, financial — anyone whose retrieval problem starts with PDFs and scanned images. ColPali removes the OCR preprocessing step. That’s an entire pipeline stage deleted.
Who Gets Left Behind
Single-vector-only infrastructure. If your vector indexing stack can’t handle multi-vector representations, you’re locked out of the highest-performing retrieval architectures. Migrating later costs more than adopting now.
OCR-dependent pipelines. ColPali’s vision-first approach doesn’t augment OCR. It replaces it. Teams that invested heavily in text extraction infrastructure for document search are sitting on a depreciating asset.
Closed retrieval stacks without late-interaction support. Proprietary search platforms that haven’t added ColBERT-style scoring will lose deals to the open-source alternatives that already did.
What Happens Next
Base case (most likely): Multi-vector retrieval becomes the default for document-heavy search within a year. ColPali variants handle visual documents, MUVERA handles compression, PyLate handles training. The stack consolidates around these three. Signal to watch: A major cloud provider ships managed ColBERT-as-a-service. Timeline: Within 12 months.
Bull case: Vision-first retrieval extends beyond documents to video frames and UI screenshots. The ViDoRe benchmark expands. Multi-vector becomes the universal retrieval primitive. Signal: ColPali-style models appear in general web search pipelines. Timeline: 18-24 months.
Bear case: Memory and latency overhead stalls adoption despite MUVERA. Single-vector models close the quality gap with larger context windows and better training data. Signal: ViDoRe scores plateau while single-vector models improve on document retrieval tasks. Timeline: 6-12 months.
Frequently Asked Questions
Q: How is ColPali changing document retrieval by treating PDF pages as images instead of extracted text? A: ColPali embeds each document page as an image using a vision-language model, generating multi-vector representations without OCR. This eliminates an entire preprocessing stage and captures visual layout information that text-only pipelines miss.
Q: Which companies are using ColBERT-based multi-vector retrieval in production search systems in 2026? A: Qdrant, Weaviate, Vespa, and Jina AI ship production-grade ColBERT support. DataStax has demonstrated ColBERT Live! as a production feature. End-user company deployments remain largely undisclosed.
Q: How are MUVERA compression and multimodal ColBERT variants reshaping retrieval architecture in 2026? A: MUVERA compresses multi-vector embeddings into fixed-dimensional encodings compatible with standard single-vector indexes, cutting memory by up to 32x. Combined with ColPali’s vision-first approach, this makes multi-vector retrieval viable at production scale.
The Bottom Line
Multi-vector retrieval crossed from research curiosity to production architecture in eighteen months. ColPali removed OCR. MUVERA removed the memory penalty. PyLate removed the training barrier. The teams adopting this stack now will own the document retrieval layer for the next cycle.
Disclaimer
This article discusses financial topics for educational purposes only. It does not constitute financial advice. Consult a qualified financial advisor before making investment decisions.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors