Claude Mythos, GPT-5.5, and Gemini 3.1 on SWE-bench: The 2026 AI Debugging Leaderboard
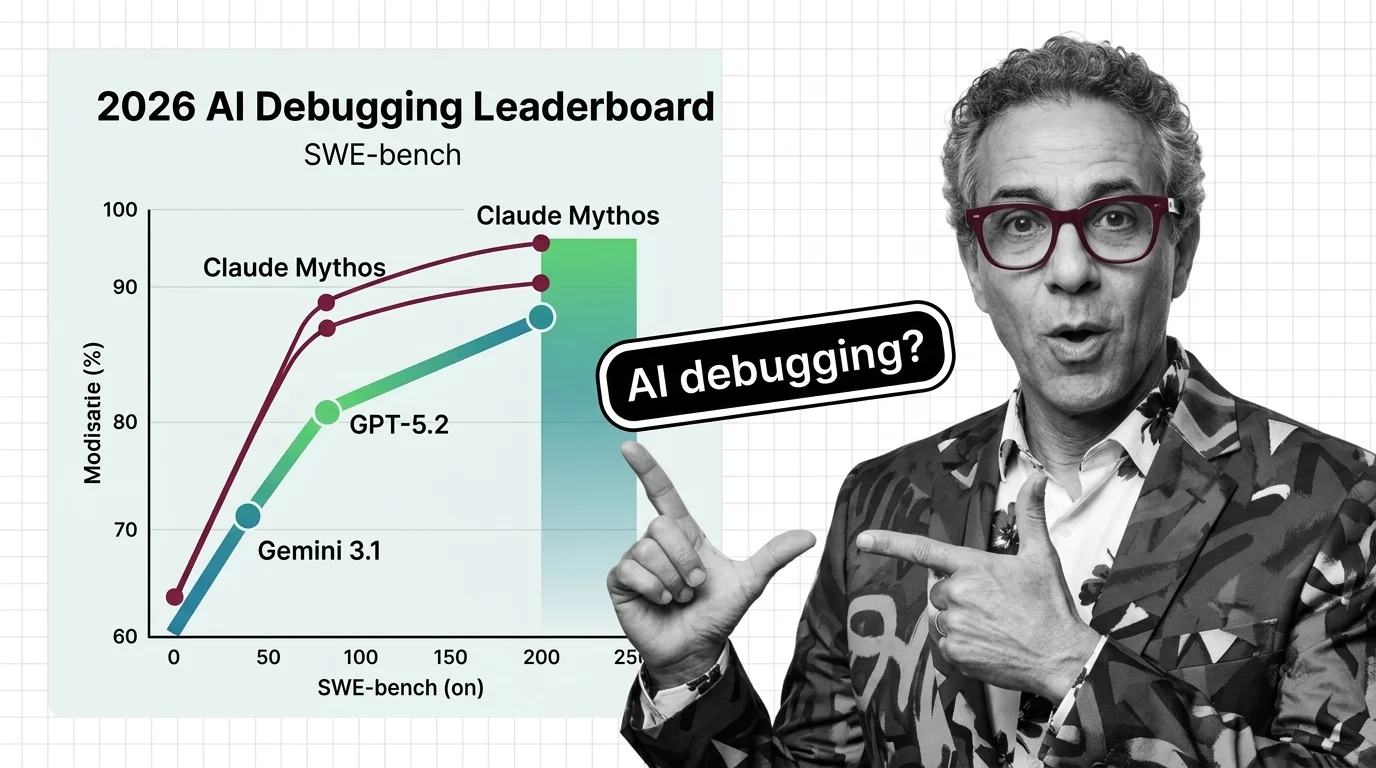
Table of Contents
TL;DR
- The shift: SWE-bench Verified is saturating and frontier labs are walking away from it. The real race moved to agentic debugging loops.
- Why it matters: The model at the top of the leaderboard is not the model you can buy — and the benchmark behind the leaderboard is no longer trusted.
- What’s next: AI-Assisted Debugging stops being a code-completion game and becomes a runtime-instrumented agent loop.
The number one model on SWE-bench Verified is not for sale. The benchmark behind the number is being abandoned by the lab that helped create the discipline around it. And the second-place model — public, available, paid for — is already operating in a different category than the leader.
That is the 2026 AI debugging leaderboard in three sentences. Everything else is interpretation.
The Leaderboard Just Stopped Telling You What You Think It Tells You
Thesis: The SWE-bench Verified ranking has become a marketing artifact, not a capability map — and the frontier labs know it.
Look at the BenchLM snapshot from May 20, 2026 (BenchLM). Claude Mythos Preview sits at 93.9% on SWE-bench Verified. Claude Opus 4.7 Adaptive holds second at 87.6%. GPT-5.3-Codex is third at 85%. Gemini 3.1 Pro became the first model to cross the 80% line back in February (ALM Corp).
Read that ranking like a buyer and you reach for Mythos. Read it like an analyst and you notice something else: Claude Mythos Preview is not generally available. Anthropic has placed it inside Project Glasswing, a gated research program with roughly fifty vetted organizations and a hundred-million-dollar credit pool for defensive cybersecurity work (Anthropic Red). The leaderboard champion is a research preview the public cannot buy.
That is not a footnote. That is the entire signal.
Three Releases, One Direction
The evidence does not arrive as a single product story. It arrives as a pattern across three labs in roughly six months.
Anthropic shipped Claude Opus 4.7 Adaptive into general availability and reserved Mythos for vetted partners (Anthropic Red). OpenAI moved from GPT-5.2 in December 2025 — a model strong on reasoning but lagging on coding (OpenAI) — to GPT-5.4 in early March 2026 with the GPT-5.3-Codex coding stack integrated, then to GPT-5.5 (codename Spud) in late April 2026 (OpenAI). Google’s Gemini 3.1 Pro broke the eighty-percent ceiling in February.
Three labs, three architectures, one shape: every shipping flagship now ships with an agentic coding stack — a AI Code Review loop with planning, tool use, runtime feedback, and iterative repair. Pure one-shot patch generation is a deprecated category.
OpenAI made the deprecation explicit. The lab publicly stopped evaluating on SWE-bench Verified, citing contamination and saturation (OpenAI). When the model maker that helped popularize a benchmark walks away from it, the benchmark is the story.
The divergence between Verified and the harder SWE-bench Pro confirms the same point. Claude Opus 4.5 scores 80.9% on Verified and 45.9% on Pro — same model, same week, roughly half the score on the harder evaluation (Morph LLM). The Verified leaderboard makes models look closer to human engineers than they are.
The Winners
The winners are the labs that built the loop, not the patch.
Anthropic is positioning Claude Code as an agentic CLI that reads the codebase, plans, executes, runs tests, and iterates on failures with explicit user permission gates (Anthropic). That is a workflow shape, not a feature. It is also the shape every serious lab is now copying.
Cursor moved the same idea into the editor. Cursor 2.2 introduced Debug Mode — runtime log instrumentation, multi-hypothesis generation, human verification callbacks — and pushed parallel agents to eight concurrent workers with roughly sixty-percent latency reduction over the prior generation (Cursor Changelog). The Anthropic 2026 Agentic Coding Trends Report shows engineers using these loops record a net decrease in time per task and a much larger net increase in output volume (Anthropic Report).
The labs winning right now are the ones that stopped optimizing for AI Code Completion accuracy and started optimizing for what happens after the first patch fails.
The Losers
The losing position is straightforward: any product whose value proposition was “we generate the patch.”
Single-shot completion vendors are competing against a free feature inside every flagship IDE. Vendors who built their entire pitch on Verified leaderboard screenshots now stand on a benchmark the model makers themselves are walking away from. And any team still treating debugging as a static autocomplete problem — generate suggestion, accept or reject — is competing with teams running parallel agents that hypothesize, instrument, and run AI Test Generation loops against the failing case.
The roadmap that said “ship better single-turn completion in Q3” is the roadmap that ages worst this year.
What Happens Next
Base case (most likely): Frontier labs continue to release public flagship models that close ninety to ninety-five percent of the gap to gated research previews. SWE-bench Pro replaces Verified as the headline number by year-end. Signal to watch: A second major lab publicly de-emphasizing SWE-bench Verified. Timeline: Within six months.
Bull case: Agentic debugging loops become a default IDE feature across all major editors, and the cost of a single debugging session drops fast enough to make the loop economical for solo developers. Signal: A mainstream IDE shipping parallel-agent debugging as a stock feature, not a premium add-on. Timeline: Twelve to eighteen months.
Bear case: The same contamination problem that killed Verified spreads to Pro. The industry loses a shared benchmark and falls into vendor-reported scores that cannot be compared. Signal: Three labs reporting incompatible methodologies on the same Pro task set. Timeline: Twelve months.
Frequently Asked Questions
Q: Which AI model is best at debugging code in 2026? A: Claude Mythos Preview leads SWE-bench Verified at 93.9%, but it is gated to roughly fifty organizations. Of publicly available models, Claude Opus 4.7 Adaptive, GPT-5.5 with the Codex stack, and Gemini 3.1 Pro are the realistic top tier, with rankings shifting by benchmark methodology.
Q: How are agentic debugging tools like Claude Code and Cursor changing developer workflows? A: They are replacing the one-shot suggest-and-accept loop with a plan-execute-instrument-iterate loop. The model reads the codebase, hypothesizes a fix, runs tests, reads runtime logs, and revises. Engineers approve permissions and verify, instead of writing every line.
Q: What is the future of AI-assisted debugging in 2026 and beyond? A: The shape is clear: parallel agents, runtime instrumentation, and continuous verification against tests, replacing static code suggestions. The open questions are benchmark trust, cost per debugging session, and whether smaller labs can match the loop quality of frontier providers.
The Bottom Line
The leaderboard you can read in a press release is no longer the leaderboard that matches the product you can buy. Treat SWE-bench Verified as a historical artifact, treat SWE-bench Pro as the current ceiling, and treat the model’s agentic loop — not its raw patch score — as the only buying signal that survives the next two quarters.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors