Citation, Confidence, and Abstention: The 3 Layers of RAG Faithfulness
Table of Contents
ELI5
RAG faithfulness is not one check. It is three separable systems: one that attaches citations to claims, one that scores how grounded the answer is, and one that decides whether to answer at all. Each fails for a different reason.
A RAG system retrieves five plausible passages, generates a fluent answer with three crisp inline citations, and confidently states something the source documents never said. The citations are real. The references resolve. The answer is wrong. This is the failure mode that broke the simple intuition that “ground the model in documents and hallucination goes away” — and the response from research and production has been to stop treating Grounding as a single knob and start treating it as a layered pipeline with three distinct components.
The Anomaly That Forced the Split
The cleanest evidence that grounding is not monolithic comes from a result that should not be possible if it were. In one experimental setup from a 2025 ICLR paper, a model’s incorrect-answer rate jumped from 10.2% with no retrieved context to 66.1% when the retrieved context was insufficient — adding documents made the model more wrong, not less, per the Google Research blog. The model did not abstain. It did not flag low confidence. It used the noisy context as scaffolding for confident fabrication.
That observation tells you something structural about RAG Guardrails And Grounding. The component that retrieves documents, the component that produces citations, and the component that decides whether the evidence is good enough to answer at all are not the same machinery. They can succeed and fail independently. A system that conflates them inherits the worst failure mode of each.
The Three Layers Doing Different Jobs
Survey work on evidence-based text generation now treats citation generation, confidence and grounding scoring, and abstention as separable layers of a faithfulness pipeline rather than aspects of a single property. The split matters because each layer answers a different question, uses different machinery, and breaks under different conditions. Reading the stack as one box hides the place where the failure actually lives.
What are the core components of a RAG grounding system?
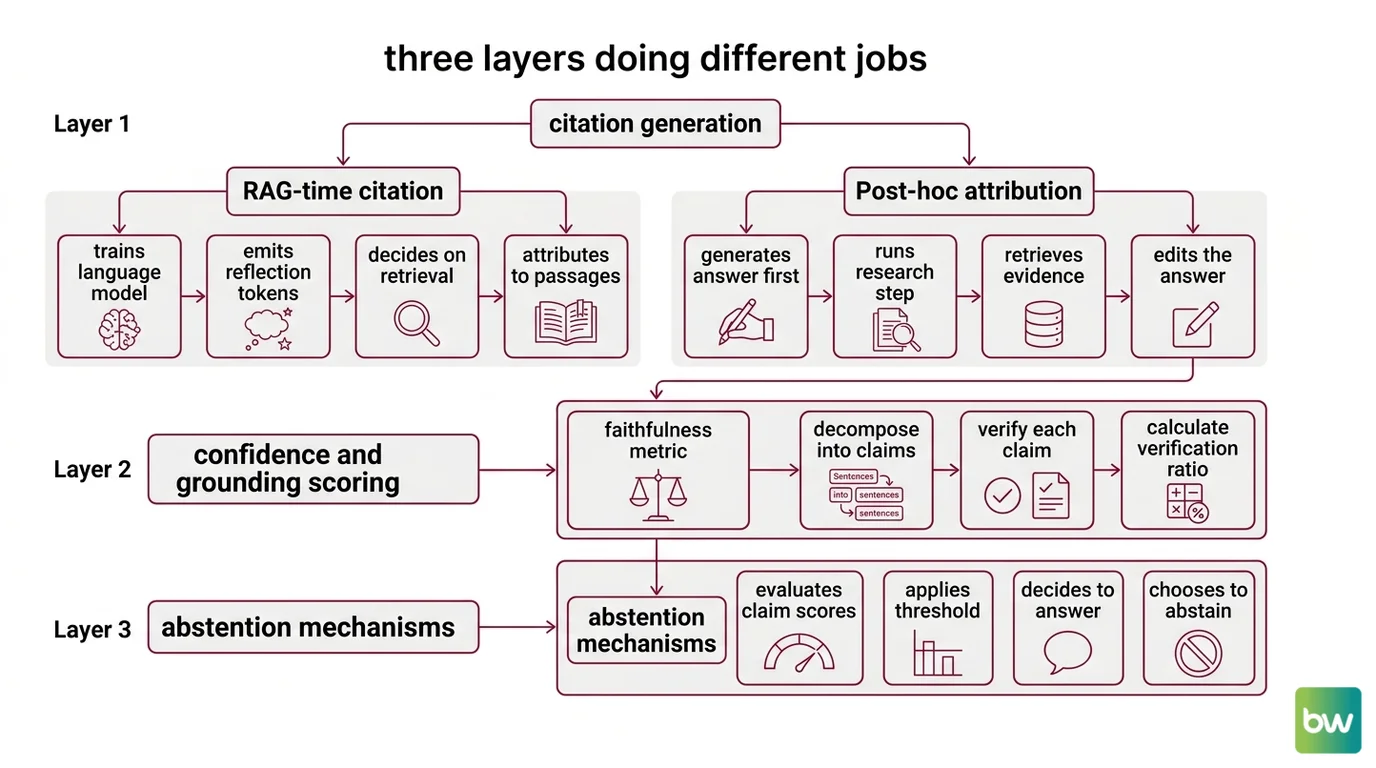
A modern RAG grounding system has three components, and they execute in a specific order.
The first is citation generation — the layer that produces inline references mapping each generated claim back to specific retrieved spans. There are two paradigms for how it does that. RAG-time citation, exemplified by Self-RAG, trains the language model itself to emit reflection tokens that decide when to retrieve, what to retrieve, and which retrieved passage supports each generated claim, per the Self-RAG paper (Asai et al., ICLR 2024). Post-hoc attribution takes the opposite approach: generate first, then go find evidence. RARR — Retrofit Attribution using Research and Revision — pipelines an unattributed answer through a research step that retrieves evidence and a revision step that edits the answer to match what the evidence actually says, per the RARR GitHub. Both paradigms produce citations. They produce them at different points in the pipeline, with different latency profiles, and with different failure modes.
The second is confidence and grounding scoring — the layer that asks how much of the generated answer is actually supported by the retrieved context. This is where Faithfulness — the central primitive of modern RAG Evaluation — lives. Frameworks like TruLens and Ragas operationalize it as a claim-verification ratio: decompose the answer into atomic claims, verify each claim against the retrieved context with an LLM judge, and report the fraction supported. Tools such as Patronus Lynx and Vectara HHEM extend this into a dedicated hallucination-detection model — a separate classifier whose entire job is reading the answer alongside the chunks and flagging unsupported content.
The third is abstention — the generation-time decision to not answer. This is the layer that turns a confidence signal into behavior. A high faithfulness score does nothing if the system always tries to produce an answer; abstention is the policy that converts “the evidence is insufficient” into “I don’t know” or a request for clarification.
These three layers are sequential in the pipeline but orthogonal in what they measure. Citation generation answers where did this come from. Confidence scoring answers how much of this is supported. Abstention answers should we be saying anything at all.
How Citations and Confidence Pass Information Down the Pipeline
Once the layers are separated, the question becomes how a signal from one layer reaches the next. Citation generation produces a span-level mapping. Confidence scoring produces a numeric or categorical grade. Abstention consumes both. The plumbing between them is where most production failures hide.
How do citation generation and confidence scoring fit into a RAG faithfulness pipeline?
A faithfulness pipeline turns retrieved documents into a graded, attributed answer through a sequence of conditioning and verification steps. The citation layer runs first, either inline during generation or as a post-hoc revision pass. Its output is a structured object: text spans tied to source passages.
Recent work on concise and sufficient sub-sentence citations is pushing this granularity finer than sentence-level — the goal is to attribute the smallest text span that a piece of evidence actually supports, which reduces over-citation and exposes weak attribution links that paragraph-level citations would hide. VeriCite, presented at SIGIR-AP 2025, takes the structural approach further with a three-stage process: generate an initial answer with claim verification, select supporting evidence for each claim, then refine the final answer using only verified evidence, per VeriCite (SIGIR-AP 2025).
Confidence scoring then reads the citation map and asks whether each cited span actually supports the claim attached to it. This is the layer where the central distinction in modern grounding research lives — citation correctness is not citation faithfulness. A citation can be correct in the bibliographic sense (the cited document does in fact say something related to the claim) and still unfaithful in the generative sense, because the model produced the answer from its own internal knowledge first and only afterwards searched for a matching document. The “Correctness is not Faithfulness in RAG Attributions” paper at ICTIR 2025 documents this post-rationalization failure mode and argues that grounding evaluation must distinguish the two. A faithfulness-aware pipeline cannot just check that citations resolve; it has to check that the answer was actually produced from those citations.
This is also where dedicated grounding judges enter. Patronus Lynx — released in 8B and 70B variants on Llama-3 — runs three structured checks on every generation: that the answer is contained in the relevant chunks, that no information beyond the chunks appears, and that nothing in the answer contradicts the chunks, per the Patronus AI blog. The 70B model’s benchmark numbers against GPT-4o on PubMedQA come from the team’s own HaluBench evaluation and should be read as vendor-reported rather than independent. The mechanism is what matters: a separate model whose entire pretraining and fine-tuning objective is reading an answer-context pair and emitting a faithfulness verdict.
The output of the confidence layer is a graded signal — per-claim or whole-answer — that flows downstream into the abstention policy. Faithfulness without abstention is a thermometer that nothing reads.
The Decision to Refuse
The third layer is where the system stops measuring and starts choosing. It is also the layer most production stacks underbuild. The intuition that “the model will know when it doesn’t know” turns out to be wrong in a specific way that the data exposed.
What is abstention in RAG and how does it differ from hallucination detection?
Abstention is a generation-time decision: before producing the answer, the system commits to either generating or declining. Hallucination detection is a post-generation classification: an answer already exists, and a separate process labels it as faithful or not. The distinction looks small. It is not.
Hallucination detection is what tools like Lynx and Vectara HHEM do. They sit downstream of generation, read the answer alongside its retrieved context, and emit a judgment. That judgment can be used in many ways — to filter outputs before showing them to a user, to trigger a regeneration with stricter constraints, to log a failure for later analysis. But the answer has already been produced. The compute has already been spent. The user-facing decision still has to be made by something else.
Abstention is the something else. The Google Research selective-generation framework combines two signals — the model’s own confidence score and a separate “sufficient context” classifier that judges whether the retrieved evidence is enough for any model to answer correctly — and uses the combination to decide whether to generate at all. The framework reports up to a 10% accuracy improvement over confidence alone in their experiments, per the Google Research blog. The mechanism is what makes that gain possible. Self-confidence alone tells you how sure the model feels; a sufficient-context classifier tells you whether the evidence justifies any feeling at all. Combining them catches the dangerous case where the model is confident because the noisy context gave it patterns to confabulate from.
The two layers also fail in different directions. Hallucination detection has false negatives — answers it judges faithful but that contain subtle fabrications, often the post-rationalized citations described above. Abstention has a different failure mode: over-refusal. RAG models sometimes refuse to answer questions whose answers they actually know, because the retrieved context was noisy or off-topic and the abstention policy treated noisy retrieval as evidence of insufficient knowledge, per a 2026 AAAI research note. The abstention threshold is not a free parameter. It is a calibration knob with cost on both sides.
This is why production grounding stacks layer the two. Hallucination detection runs after generation as a safety net. Abstention runs before or during generation as a policy. NVIDIA’s NeMo Guardrails toolkit organizes both as distinct rail categories — input rails, output rails, dialog rails, retrieval rails, fact-checking and grounding rails — each running at the appropriate point in the request lifecycle, per the NVIDIA NeMo Guardrails docs. The architectural commitment is the same as the survey literature: faithfulness is not a single check, it is a sequence of checks, and the rails are where the sequence is enforced.
Security & compatibility notes:
- NeMo Guardrails v0.20.0 (January 2026): Introduces the IORails parallel input/output engine and an OpenAI-compatible REST API. Configurations from earlier versions may need migration. Repository was also relocated from
NVIDIA/NeMo-GuardrailstoNVIDIA-NeMo/Guardrails; old links may redirect.- RARR (research repository): The original
anthonywchen/RARRrepo is research-grade and not actively maintained as a production library. Treat the method as a reference design, not a drop-in dependency.
What the Three Layers Predict
Once the layers are separated, the failure modes stop being one fog and become legible from the score sheet. The pipeline tells you where the wound is.
- If citation accuracy is high but faithfulness is low, the model is post-rationalizing — generating from internal knowledge and finding citations to match. Tighten the citation generator (RAG-time over post-hoc) or run a faithfulness judge that checks support direction, not just citation existence.
- If faithfulness scores are high but downstream Hallucination reports keep coming in, the judge model is being fooled — usually by claims that paraphrase the source closely enough to pass surface checks but invert a quantity, a date, or a polarity. Move to a stronger judge or to sub-sentence citation granularity.
- If abstention rates are near zero on questions outside the corpus, the abstention policy is consuming only model-confidence signal and ignoring context-sufficiency. Add a sufficient-context classifier in the style of Google’s selective generation framework.
- If abstention rates are high on questions the model should know, the policy is treating noisy retrieval as a proxy for insufficient knowledge. Recalibrate the threshold or fall back to closed-book generation when retrieval confidence is low.
Rule of thumb: if you cannot point at which of the three layers produced a given failure, you do not have a faithfulness pipeline — you have a single black box wearing the word “grounding” on its label.
When it breaks: the dominant trade-off is latency versus rigor. RAG-time citation, sub-sentence granularity, dedicated judge models, and sufficient-context classifiers each add inference passes; a fully layered pipeline can multiply the effective generation cost several-fold, and end-to-end production reliability data — false-positive rates in real workloads — is not publicly published for any of the major stacks. The architecture is sound. The operating-cost numbers are still being learned.
The Data Says
Treating RAG guardrails and grounding as three layers — citation, confidence, abstention — is what makes failure diagnosable. The Google Research result that adding insufficient context can quintuple the wrong-answer rate is the cleanest evidence that grounding is not monotonic. The ICTIR 2025 finding that correct citations can still be unfaithful is the cleanest evidence that the layers must be measured separately. The architecture follows from the math.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors