RAG & Semantic Search
Connecting AI to real-world knowledge — retrieval-augmented generation, vector databases, embeddings, and semantic search patterns.
- Home /
- AI Principles /
- RAG & Semantic Search
Cross-Encoder Reranker Limits: Latency Walls and Domain Drift
Cross-encoder rerankers hit two architectural walls: latency scales linearly with candidates and quadratically with …
What Is Hybrid Search and How BM25 Plus Dense Vectors Beat Either Alone in RAG
Hybrid search fuses BM25 keyword retrieval with dense vector search using reciprocal rank fusion. Why two ranked lists …
BM25, SPLADE, and Reciprocal Rank Fusion: The Building Blocks of Production Hybrid Search
BM25, SPLADE, and reciprocal rank fusion each solve a different retrieval problem. Here's how the three combine into a …

Why RAG Still Fails in Production: Retrieval, Chunking, Grounding
RAG fails in production because retrieval, chunking, and grounding hit structural limits — not because of bugs. Why …
What Is RAG and How LLMs Use Vector Search to Ground Their Answers
Retrieval-augmented generation pairs an LLM with a vector index so answers are grounded in real documents — not just …

Score Mismatch, Tuning Hell: The Hard Limits of Hybrid Search Fusion
Hybrid search merges BM25 and vector results, but the fusion step has hard limits. Score mismatch, RRF blindness, and …
From Chunking to Reranking: RAG Pipeline Components and Prerequisites
Every RAG pipeline runs five components — chunker, embedder, vector store, retriever, reranker. Here is what each one …
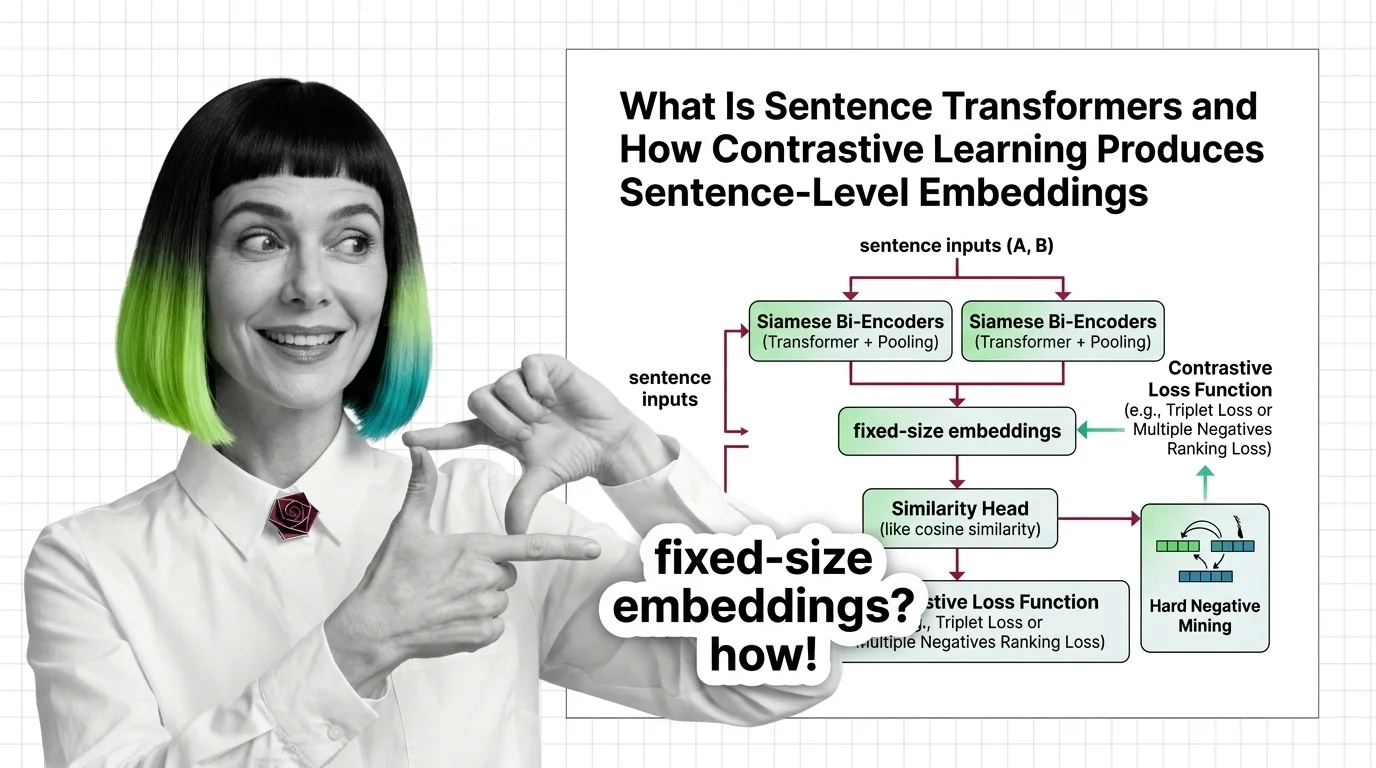
What Is Sentence Transformers and How Contrastive Learning Produces Sentence-Level Embeddings
Sentence Transformers turns transformers into sentence encoders via contrastive learning. Covers bi-encoders, loss …
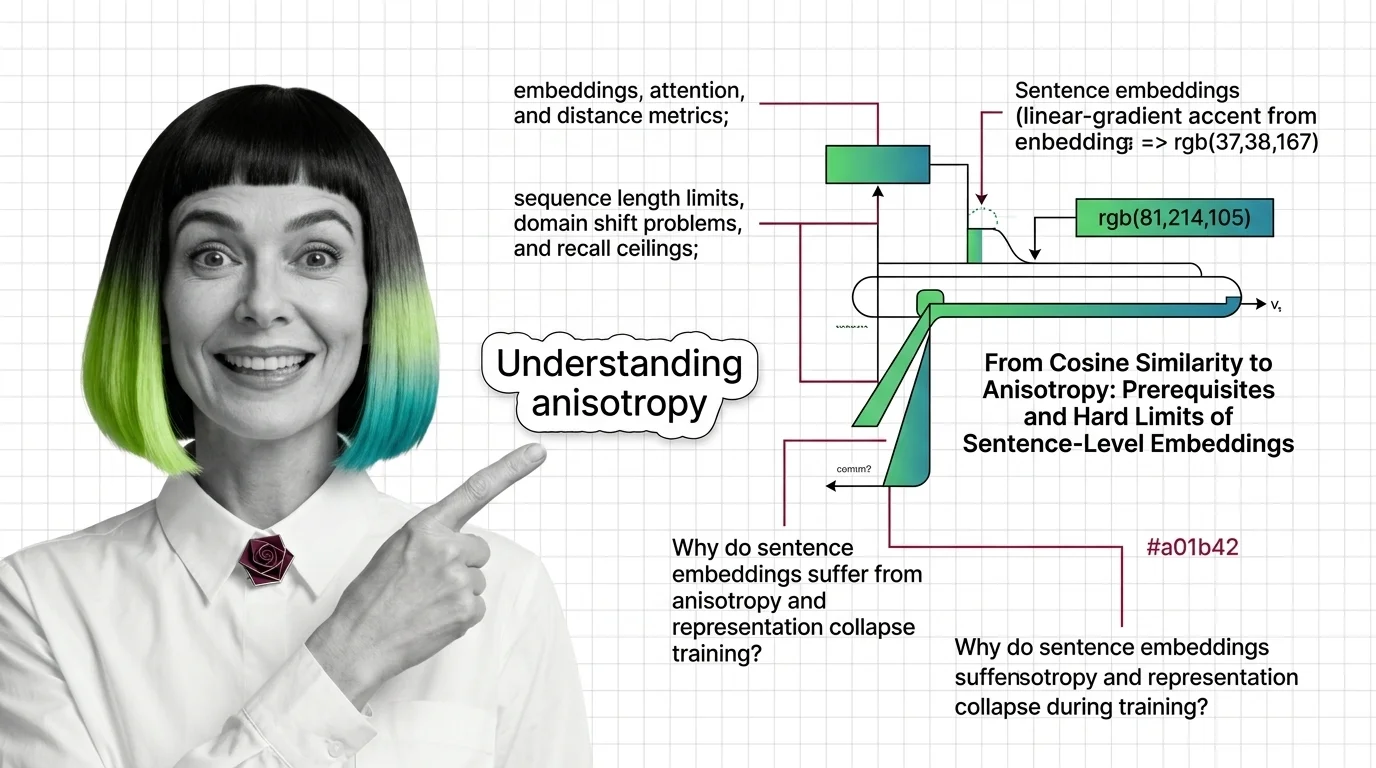
From Cosine Similarity to Anisotropy: Prerequisites and Hard Limits of Sentence-Level Embeddings
Sentence Transformers encode meaning as geometry. Learn the prerequisites, token limits, and anisotropy traps that …
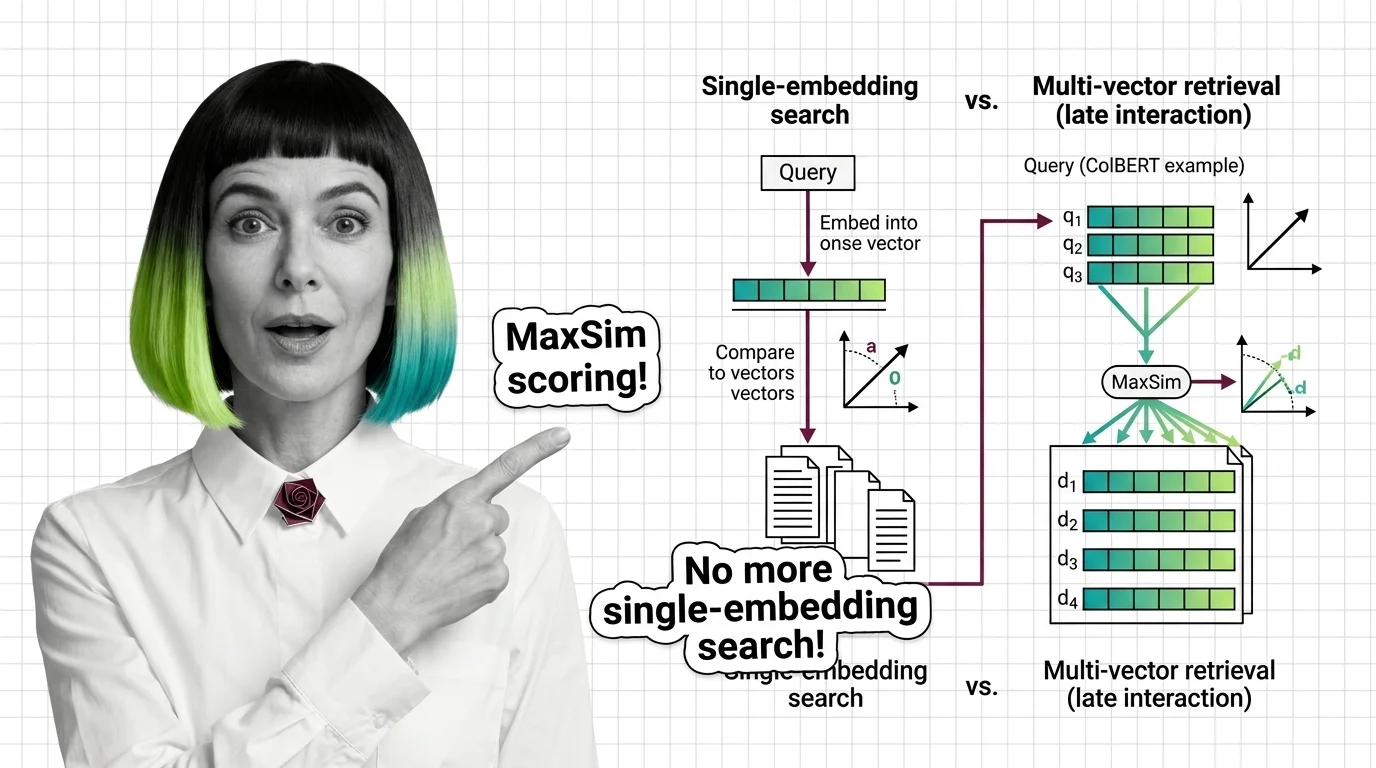
What Is Multi-Vector Retrieval and How Late Interaction Replaces Single-Embedding Search
Multi-vector retrieval stores per-token embeddings instead of one vector per document. Learn how ColBERT MaxSim scoring …

From Embeddings to Token-Level Matching: Prerequisites and Hard Limits of Multi-Vector Search
Multi-vector retrieval trades storage and latency for token-level precision. Learn the prerequisites, storage math, and …
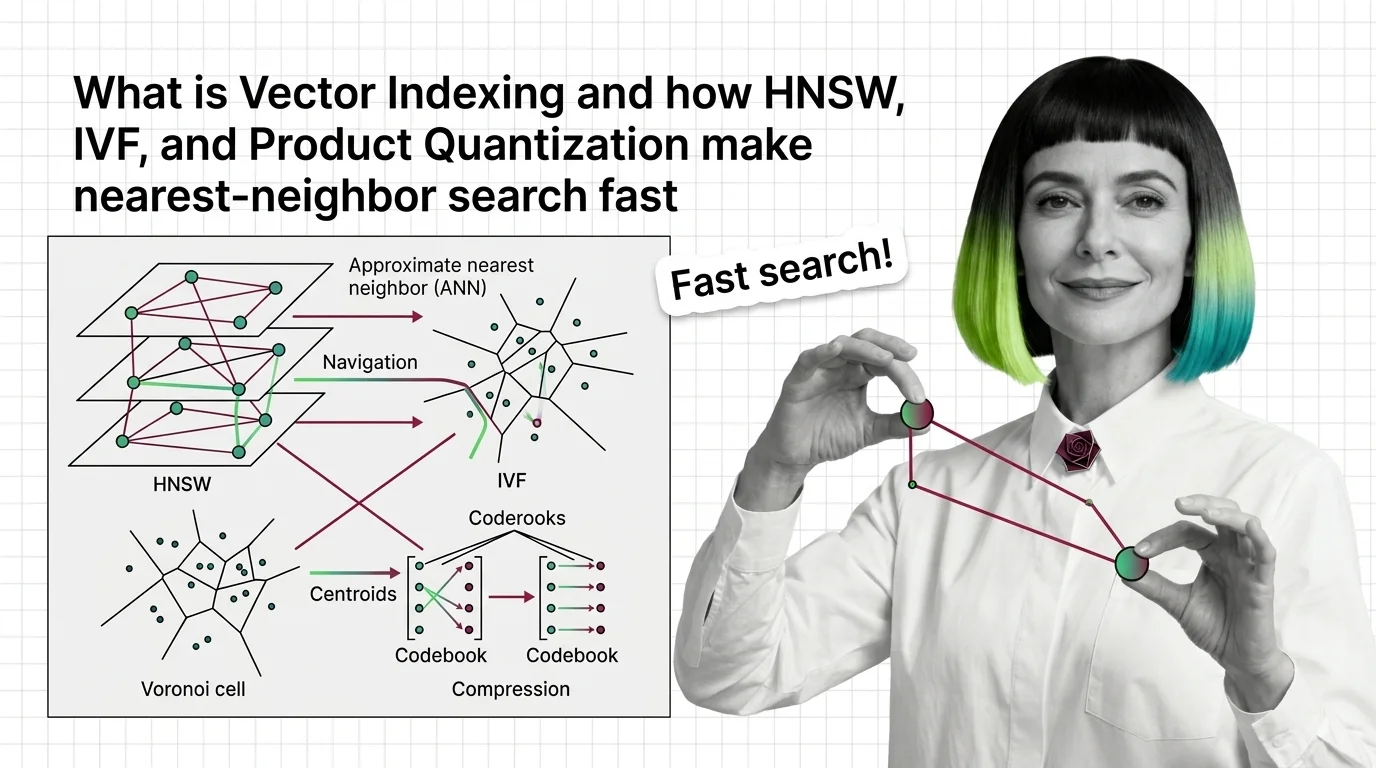
What Is Vector Indexing and How HNSW, IVF, and Product Quantization Make Nearest-Neighbor Search Fast
Vector indexing replaces brute-force search with graph, partition, and compression strategies. Learn how HNSW, IVF, and …
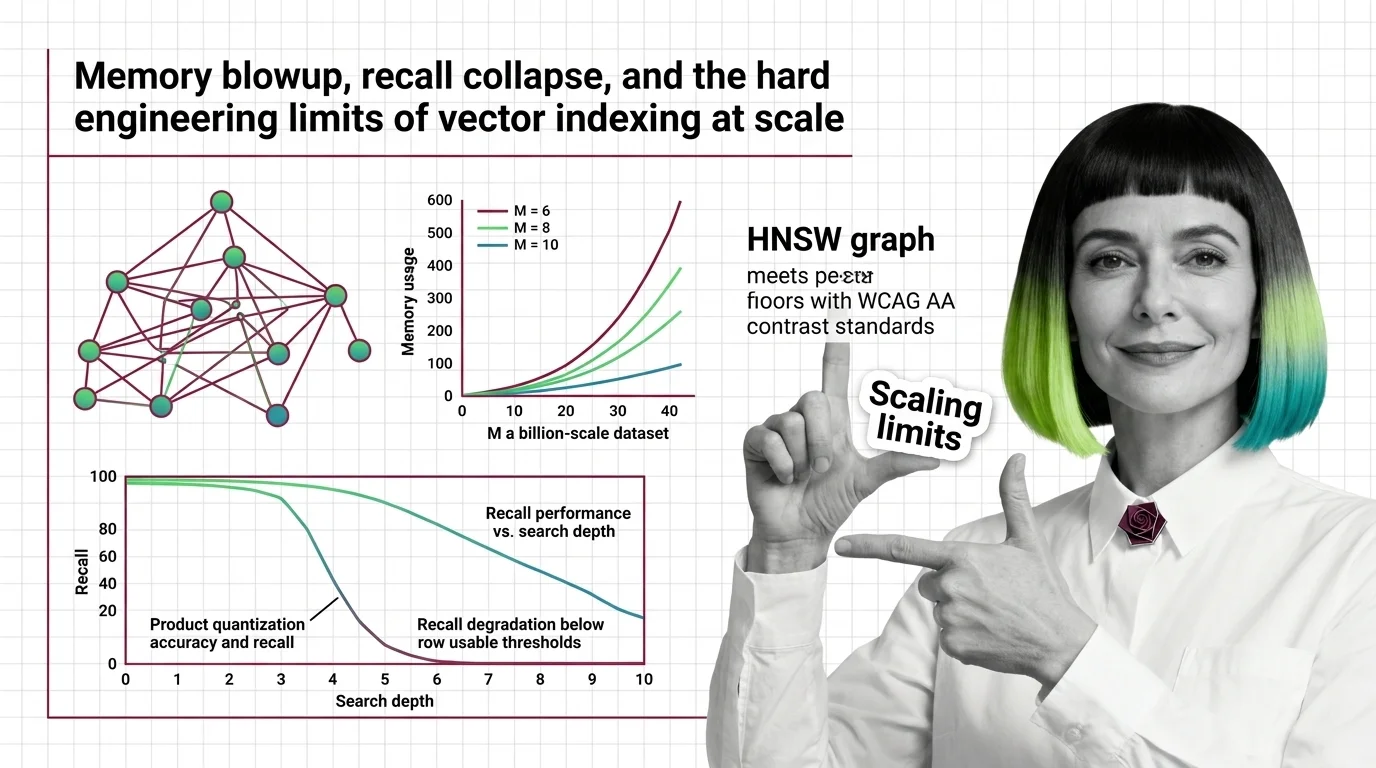
Memory Blowup, Recall Collapse, and the Hard Engineering Limits of Vector Indexing at Scale
HNSW memory grows linearly with connectivity while PQ recall collapses on high-dimensional embeddings. Learn where …

From Distance Metrics to Graph Traversal: Prerequisites for Understanding Vector Index Internals
Distance metrics, high-dimensional geometry, exact vs approximate search — the prerequisites you need before HNSW and …
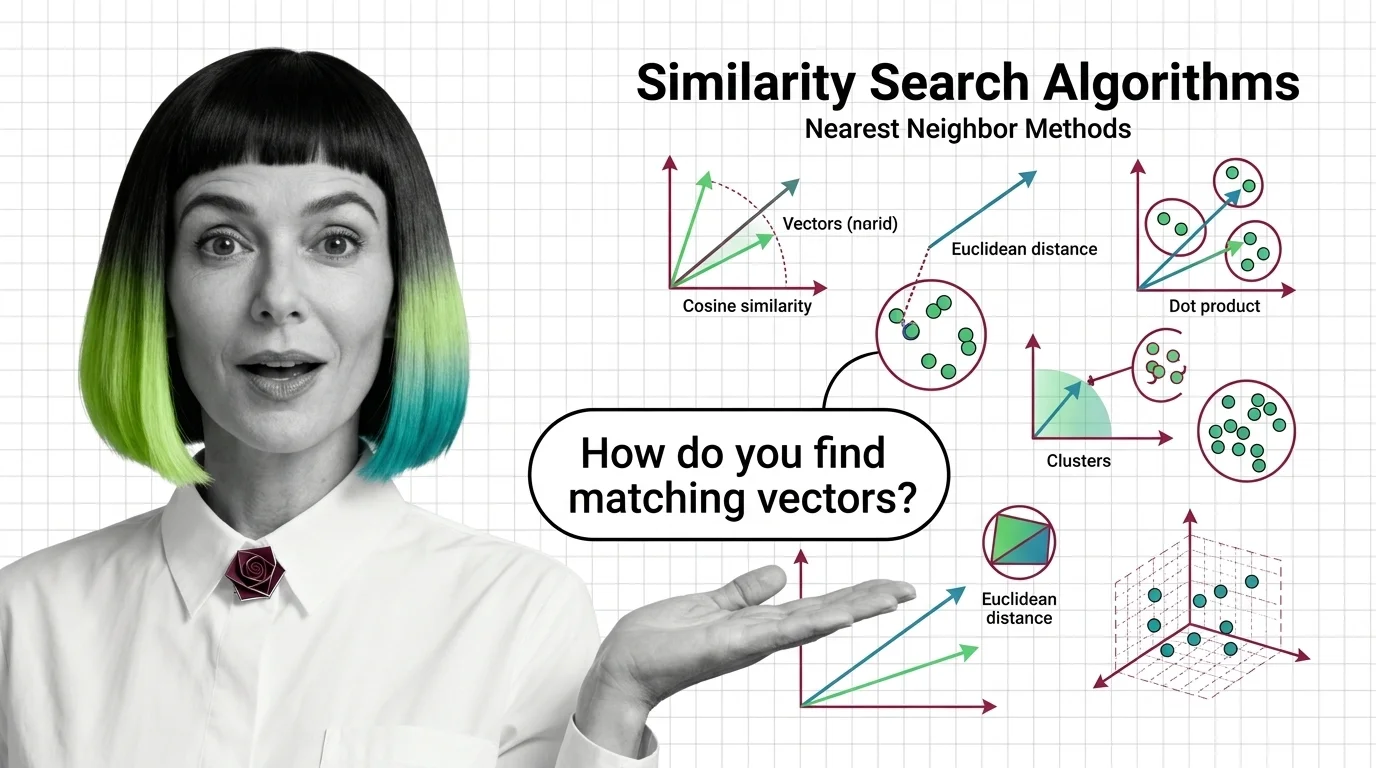
What Are Similarity Search Algorithms and How Nearest Neighbor Methods Find Matching Vectors
Similarity search algorithms find matching vectors by measuring geometric distance, not keywords. Learn how HNSW, PQ, …
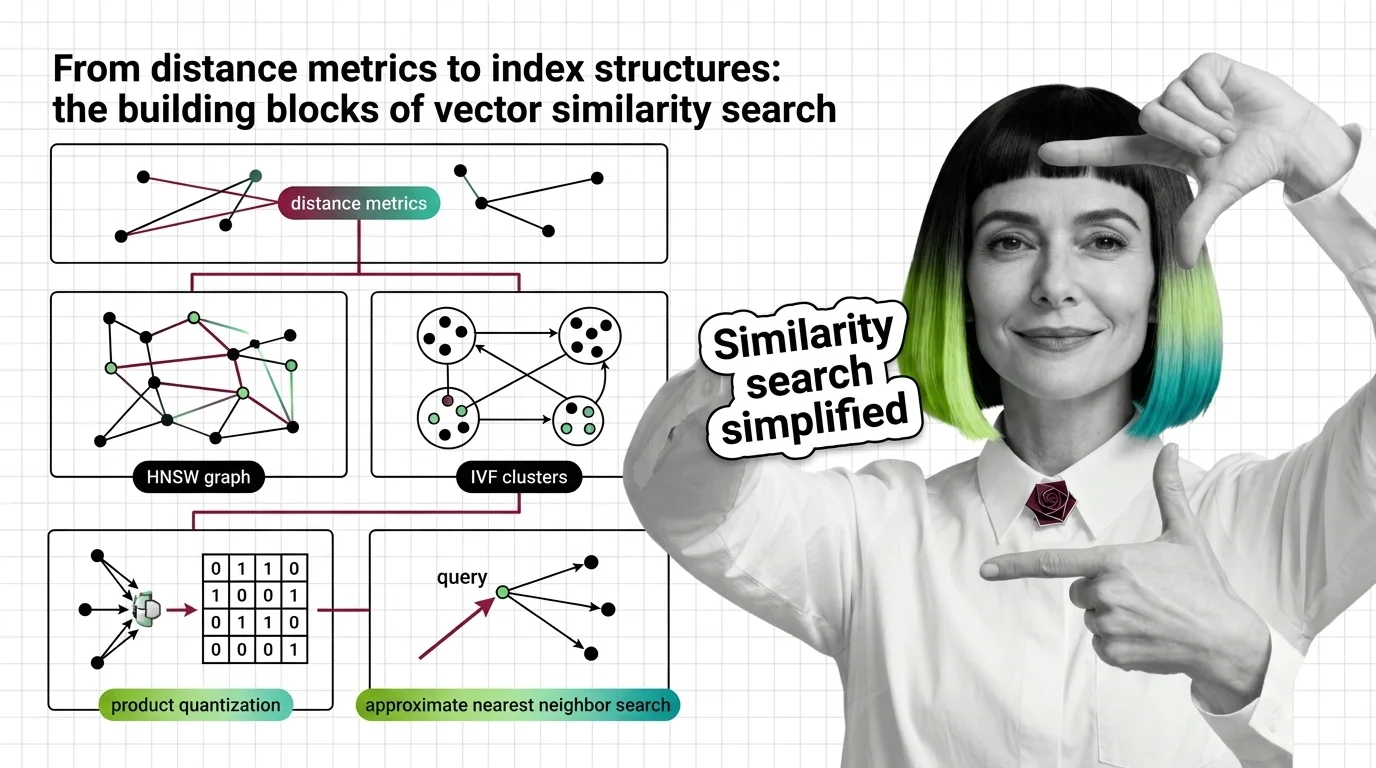
From Distance Metrics to Index Structures: The Building Blocks of Vector Similarity Search
Similarity search combines distance metrics, index structures, and quantization. Learn how HNSW, IVF, LSH, and product …

Curse of Dimensionality, Recall vs. Speed, and the Hard Limits of Approximate Nearest Neighbor Search
High-dimensional similarity search faces hard mathematical limits. Explore the curse of dimensionality, recall-speed …