Model Architectures
How AI models are built — transformers, attention mechanisms, mixture-of-experts, and the design decisions that shape capability.
- Home /
- AI Principles /
- Model Architectures

What Is a Diffusion Model? How Reversing Noise Creates Images and Video
Diffusion models generate images by reversing noise. Learn how forward and reverse processes differ, and why predicting …
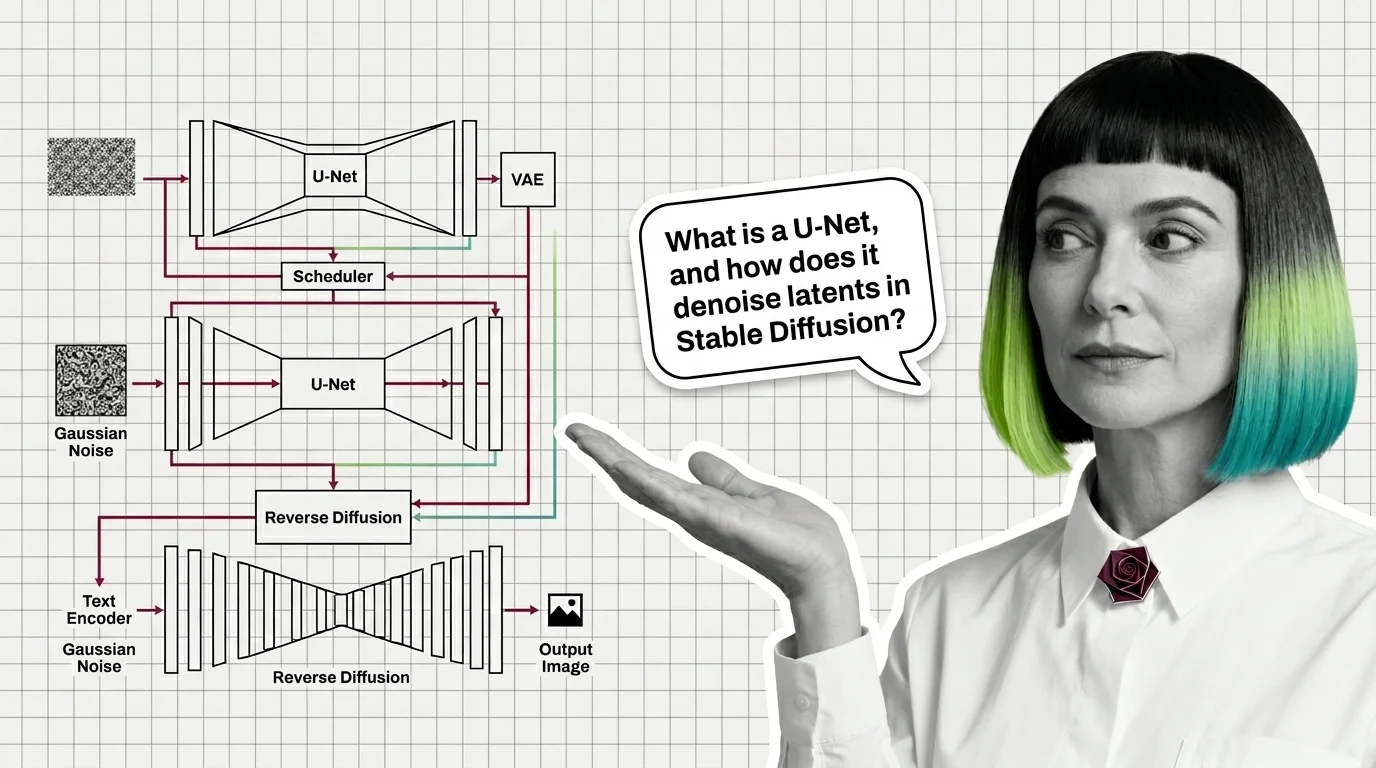
U-Net, VAE, Schedulers, and Text Encoders: The Anatomy of a Modern Diffusion Model
A modern diffusion model is not one network but four: a VAE for compression, a U-Net or DiT denoiser, a text encoder, …
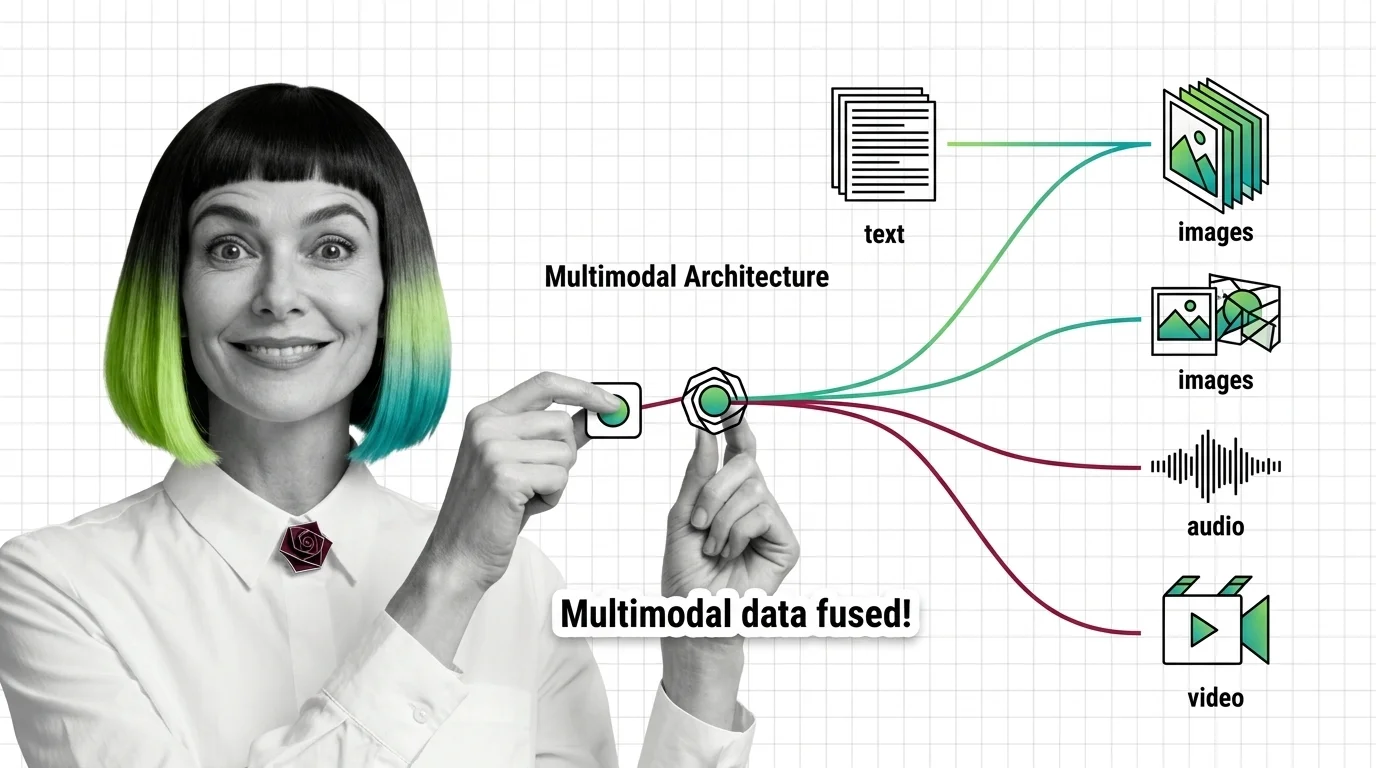
Multimodal Architecture: How Models Fuse Text, Images, Audio & Video
Multimodal models like GPT-5 and Gemini 3.1 Pro don't see images — they translate them into token space. Here's the …
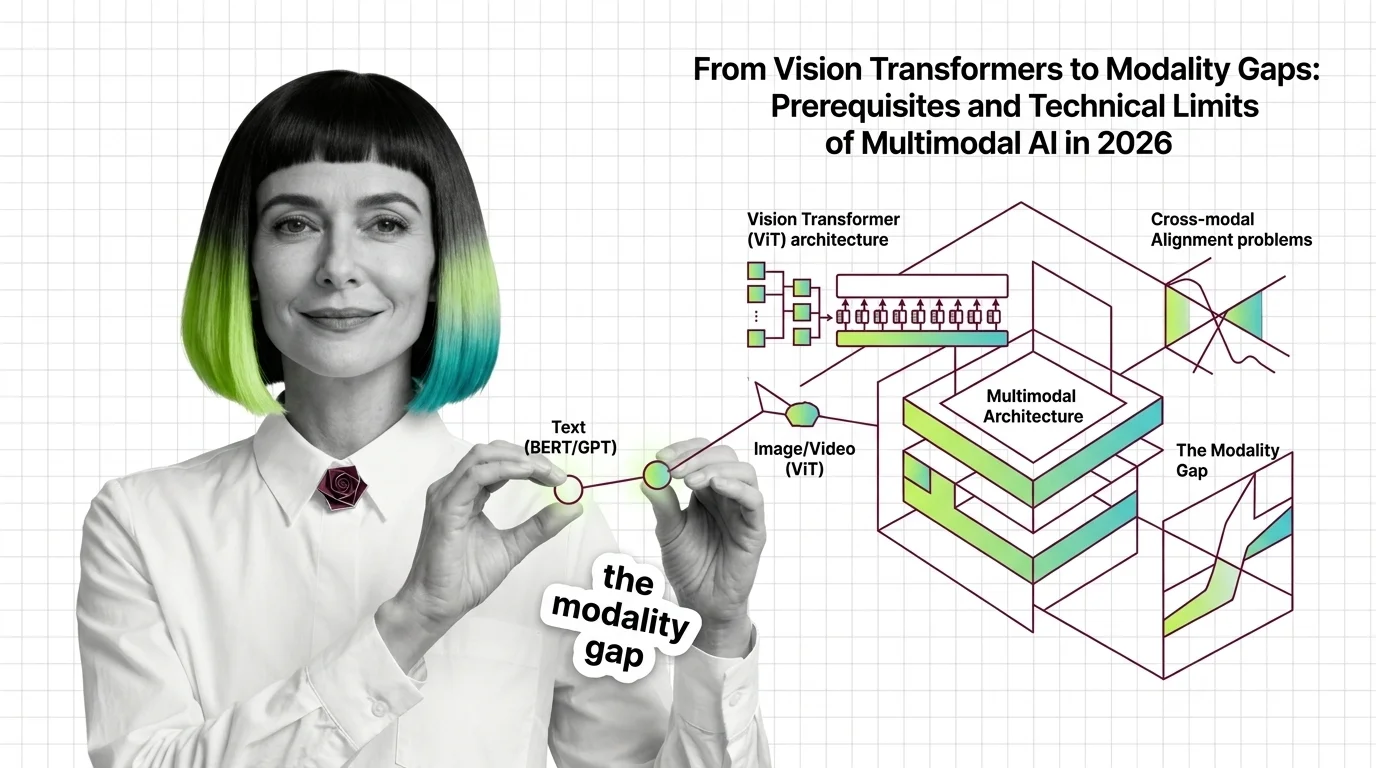
From Vision Transformers to Modality Gaps: Prerequisites and Technical Limits of Multimodal AI in 2026
Before multimodal AI works, vision transformers, modality gaps, and grounding decay define its limits. The mechanics of …

Diffusion Models in 2026: Slow Sampling and Hard Engineering Limits
Why diffusion models still need many sampling steps, why FLUX and SD 3.5 stumble on text and hands, and where the 2026 …
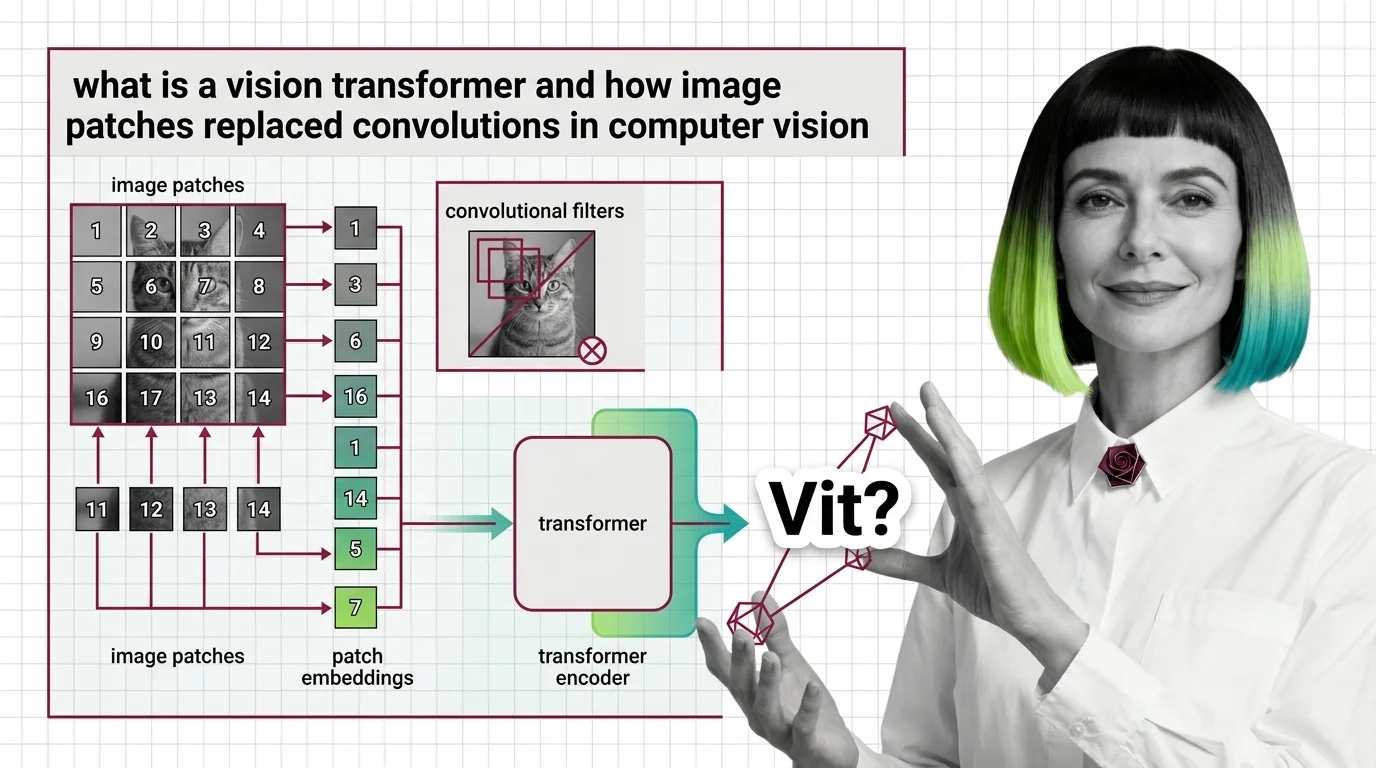
What Is a Vision Transformer and How Image Patches Replaced Convolutions in Computer Vision
Vision Transformers treat images as token sequences, not pixel grids. Learn how 16x16 patches, self-attention, and …
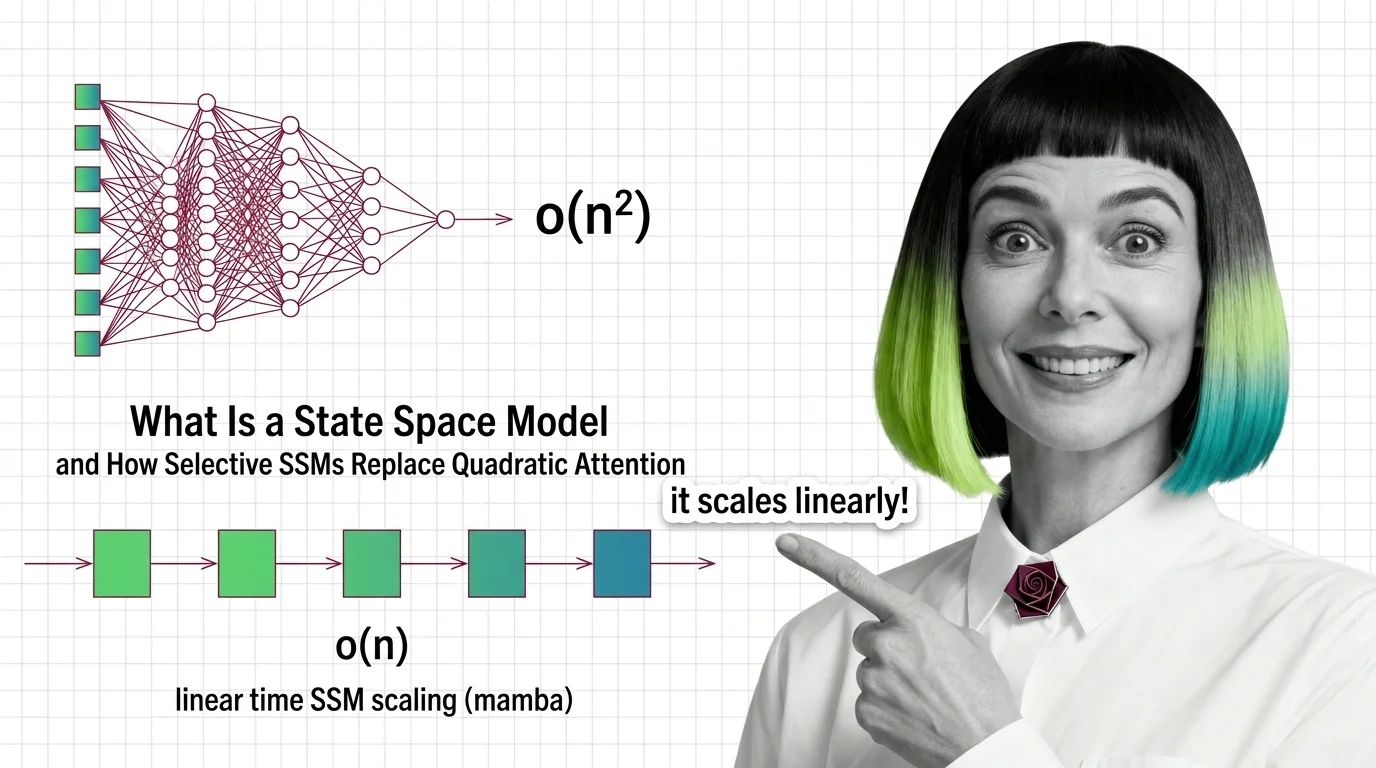
What Is a State Space Model and How Selective SSMs Replace Quadratic Attention
State space models trade quadratic attention for linear recurrence. See how Mamba's selection works and why long-context …
In-Context Learning Gaps, Hybrid Complexity, and the Hard Technical Limits of State Space Models
State space models trade recall for speed. Learn why pure Mamba breaks on in-context tasks and how hybrid SSM-attention …
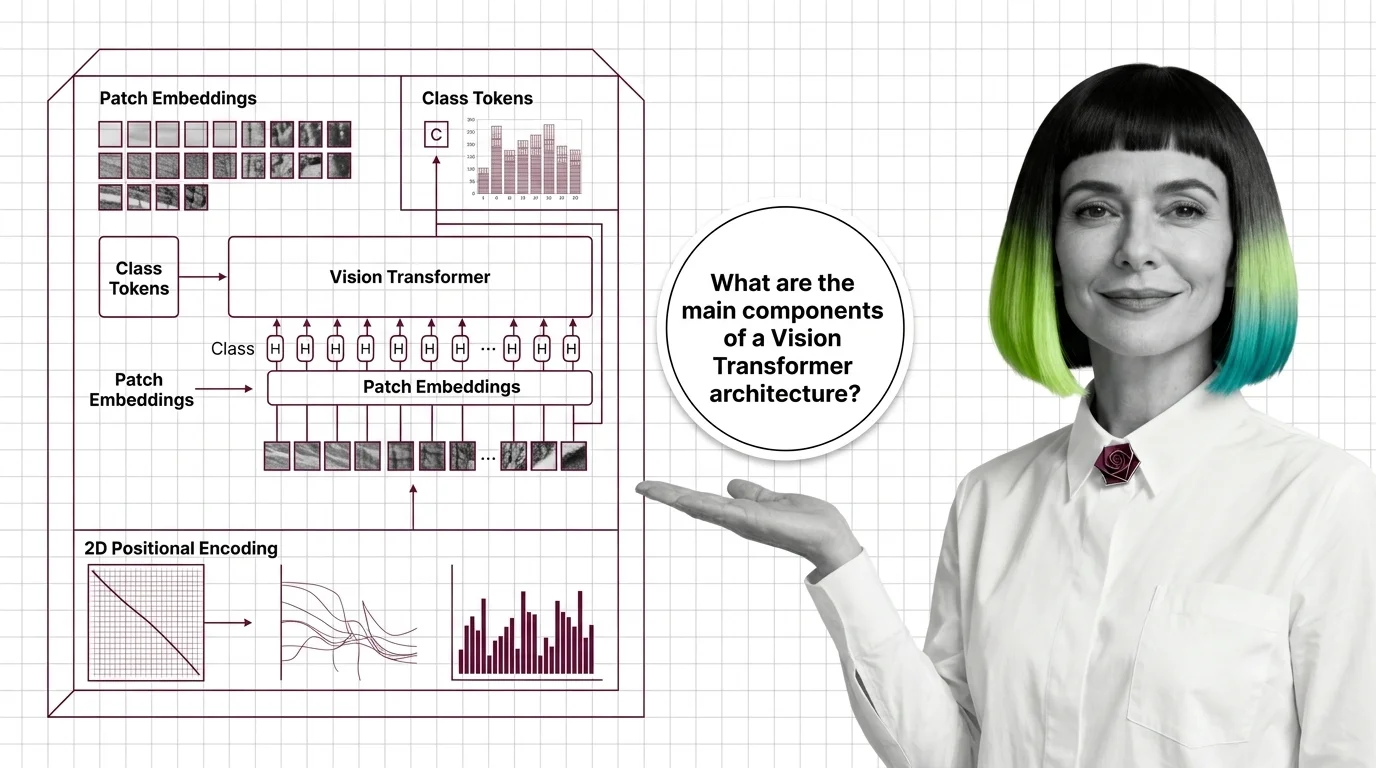
Patch Embeddings, Class Tokens, and 2D Positional Encoding: Inside the Vision Transformer
How Vision Transformers turn images into token sequences — inside patch embeddings, the CLS token, and the shift from 1D …
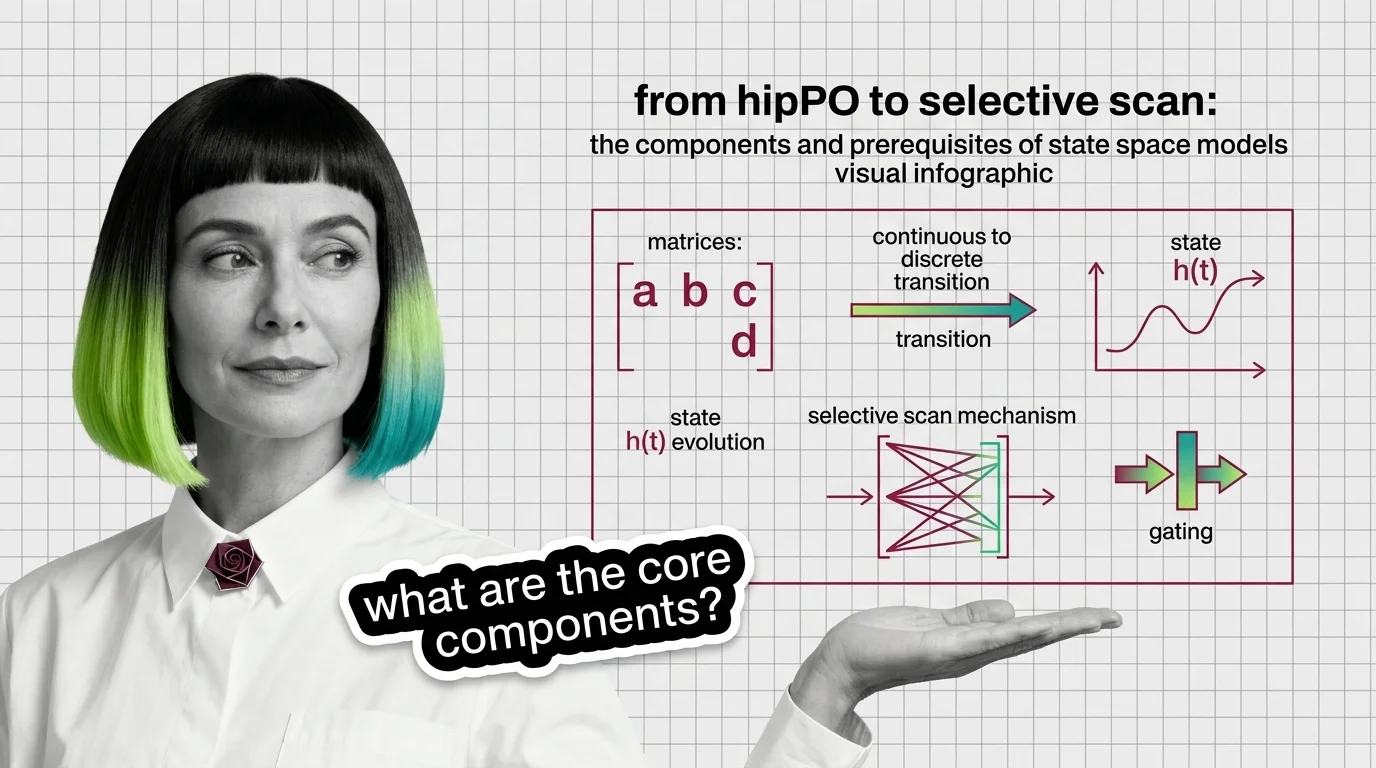
From HiPPO to Selective Scan: The Components and Prerequisites of State Space Models
State space models rebuilt recurrence on new math. Trace the components — HiPPO, S4, selective scan, gating — and the …
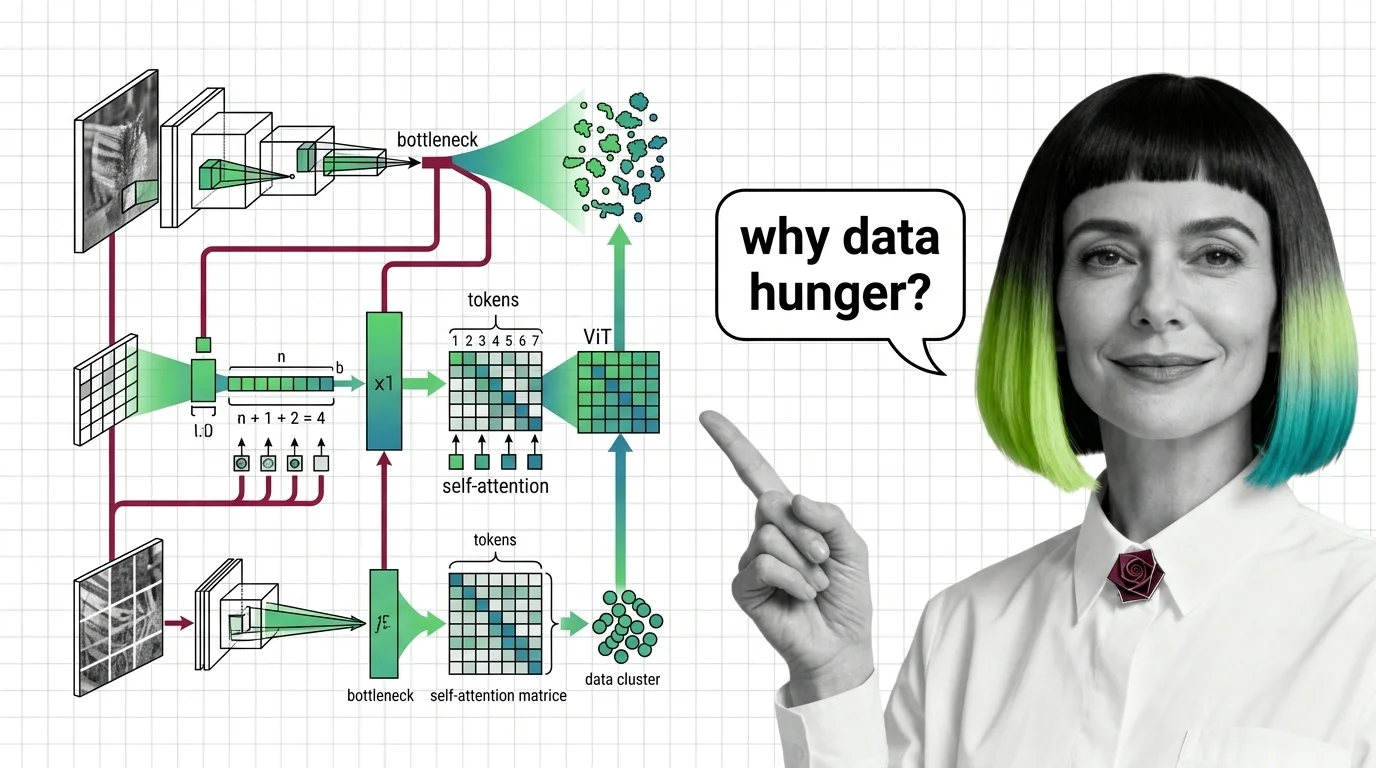
From CNN Intuition to Data Hunger: Prerequisites and Hard Limits of Vision Transformers
Vision Transformers drop CNN priors for learned attention — a trade that changes everything. Learn the prerequisites, …
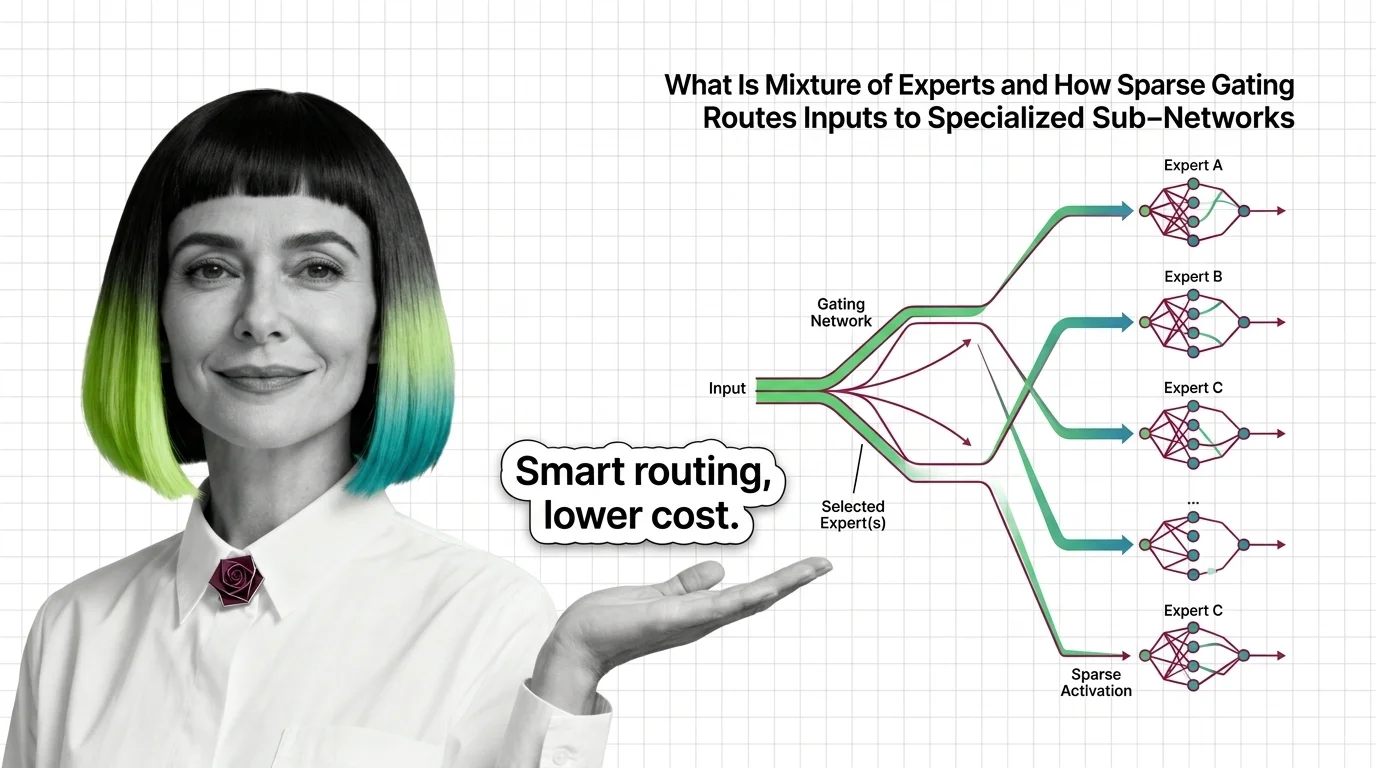
What Is Mixture of Experts and How Sparse Gating Routes Inputs to Specialized Sub-Networks
Mixture of experts activates only selected sub-networks per token. Learn how sparse gating makes trillion-parameter …

Routing Collapse, Load Balancing Failures, and the Hard Engineering Limits of Mixture of Experts
MoE models promise scale at fractional compute cost. Understand routing collapse, memory tradeoffs, and communication …
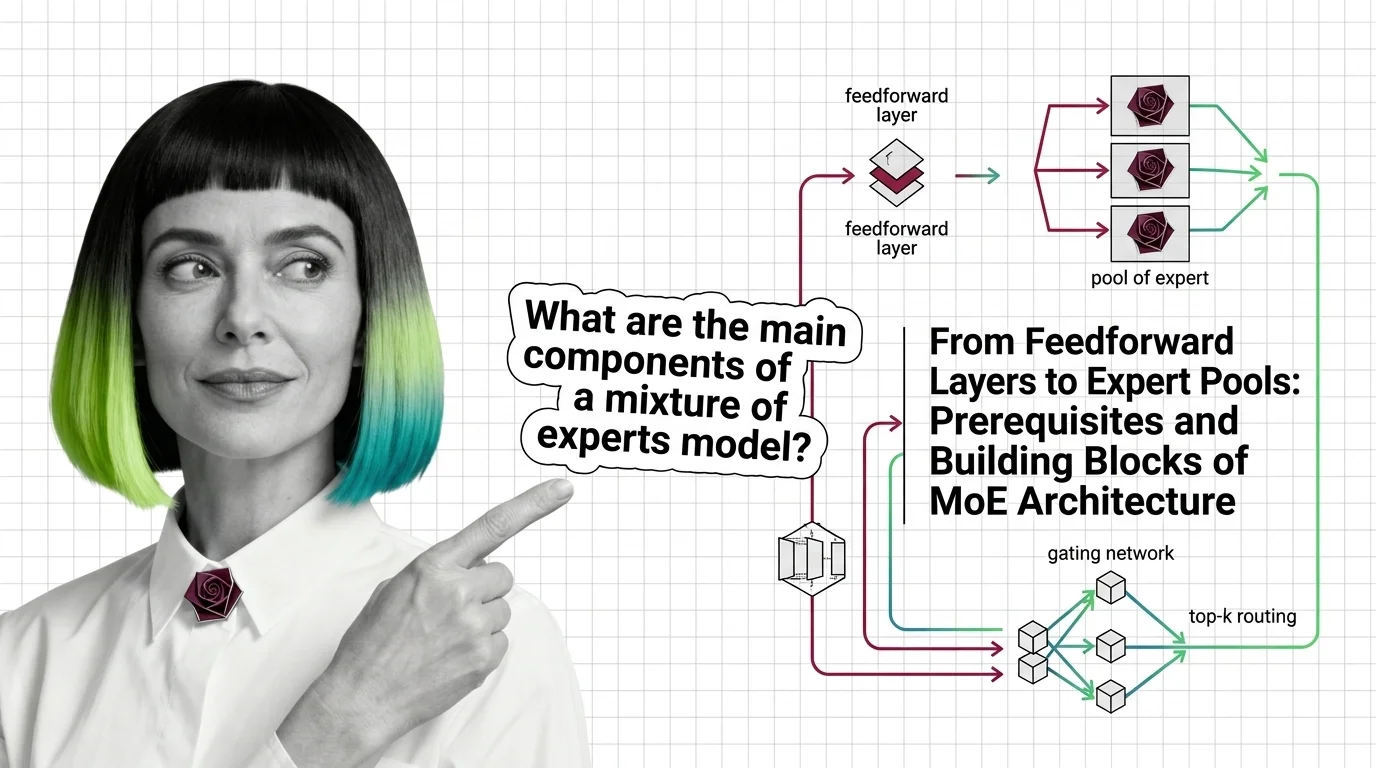
From Feedforward Layers to Expert Pools: Prerequisites and Building Blocks of MoE Architecture
Mixture of experts replaces one feedforward layer with many expert networks and a router. Learn how MoE gating and …
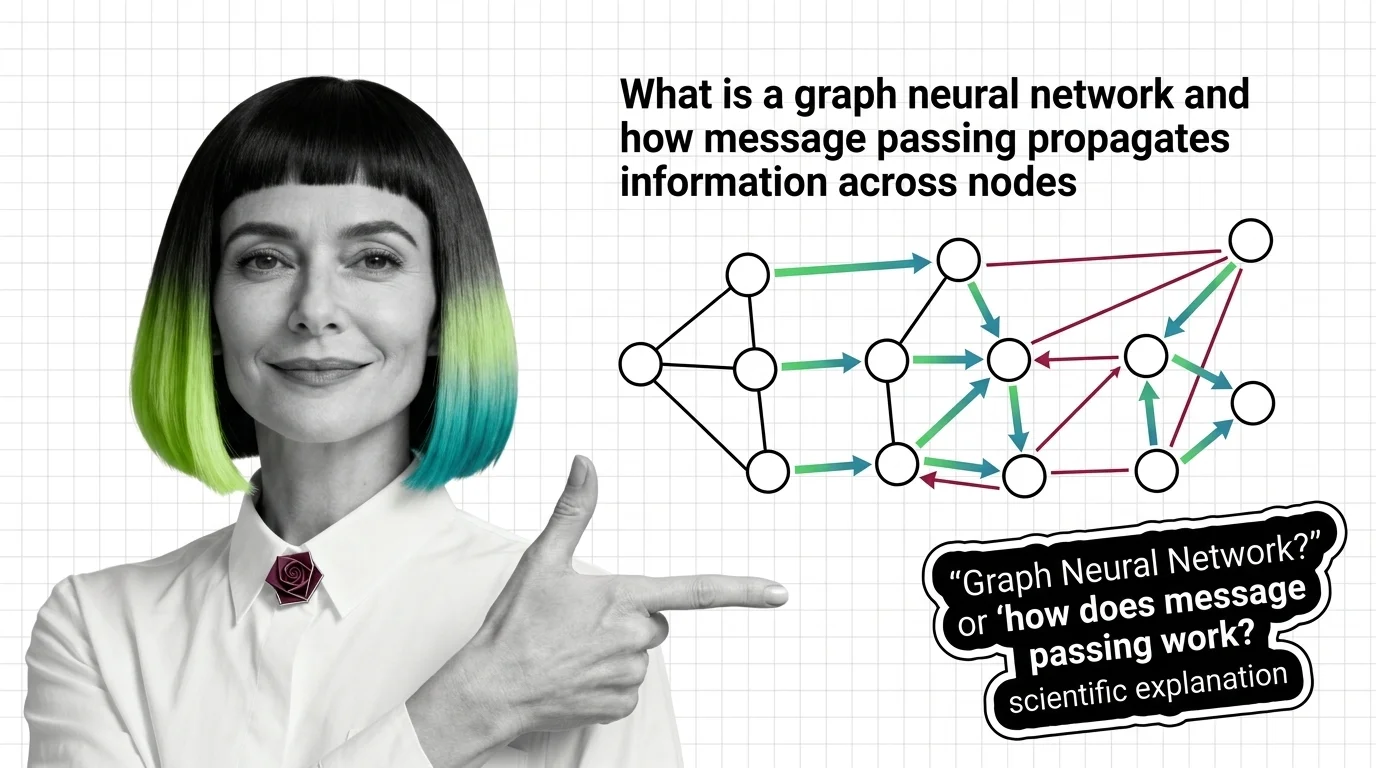
What Is a Graph Neural Network and How Message Passing Propagates Information Across Nodes
Graph neural networks learn from connections, not grids. Understand message passing, how graph convolution differs from …
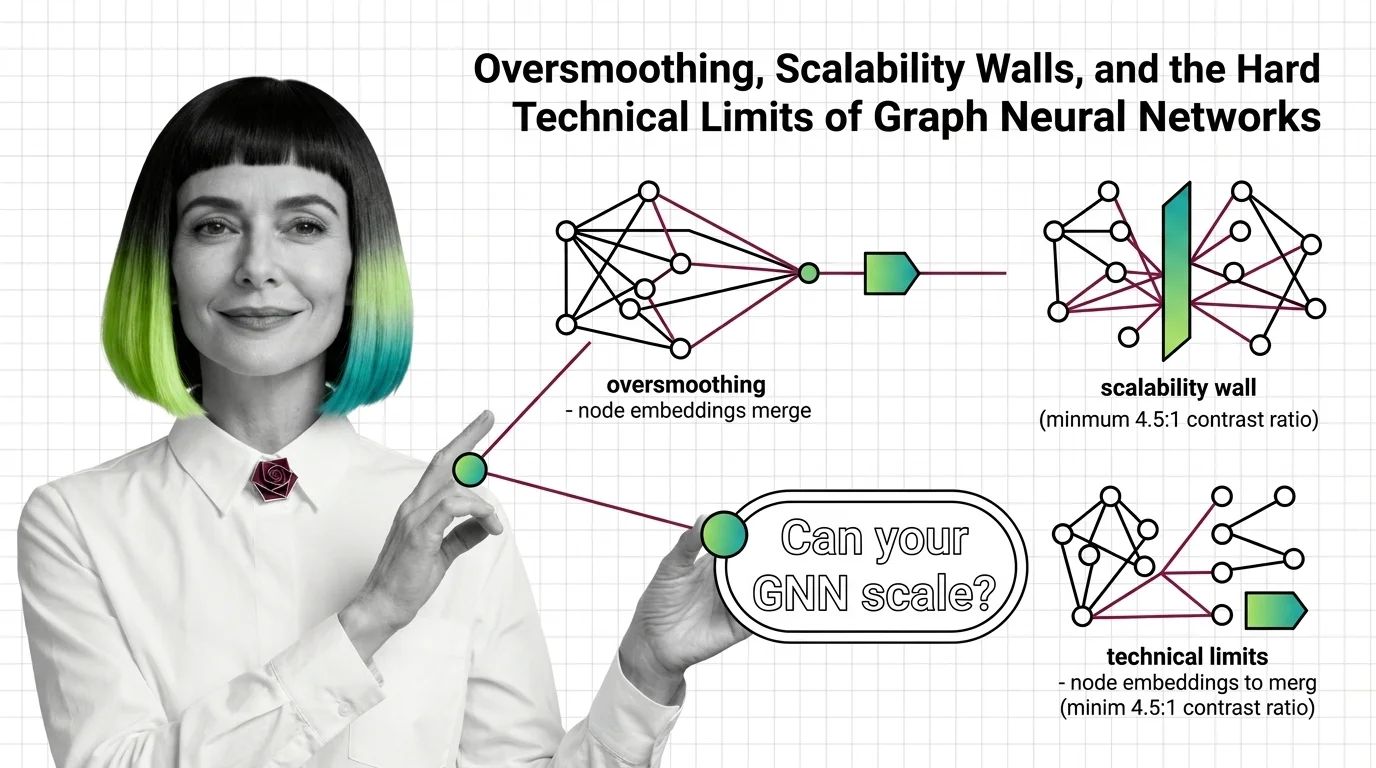
Oversmoothing, Scalability Walls, and the Hard Technical Limits of Graph Neural Networks
Oversmoothing and neighbor explosion set hard ceilings on graph neural network depth and scale. Learn the mathematical …

Adjacency Matrices, Node Features, and the Prerequisites for Understanding Graph Neural Networks
Graph neural networks consume matrices, not pixels. Learn how adjacency matrices, node features, and message passing …
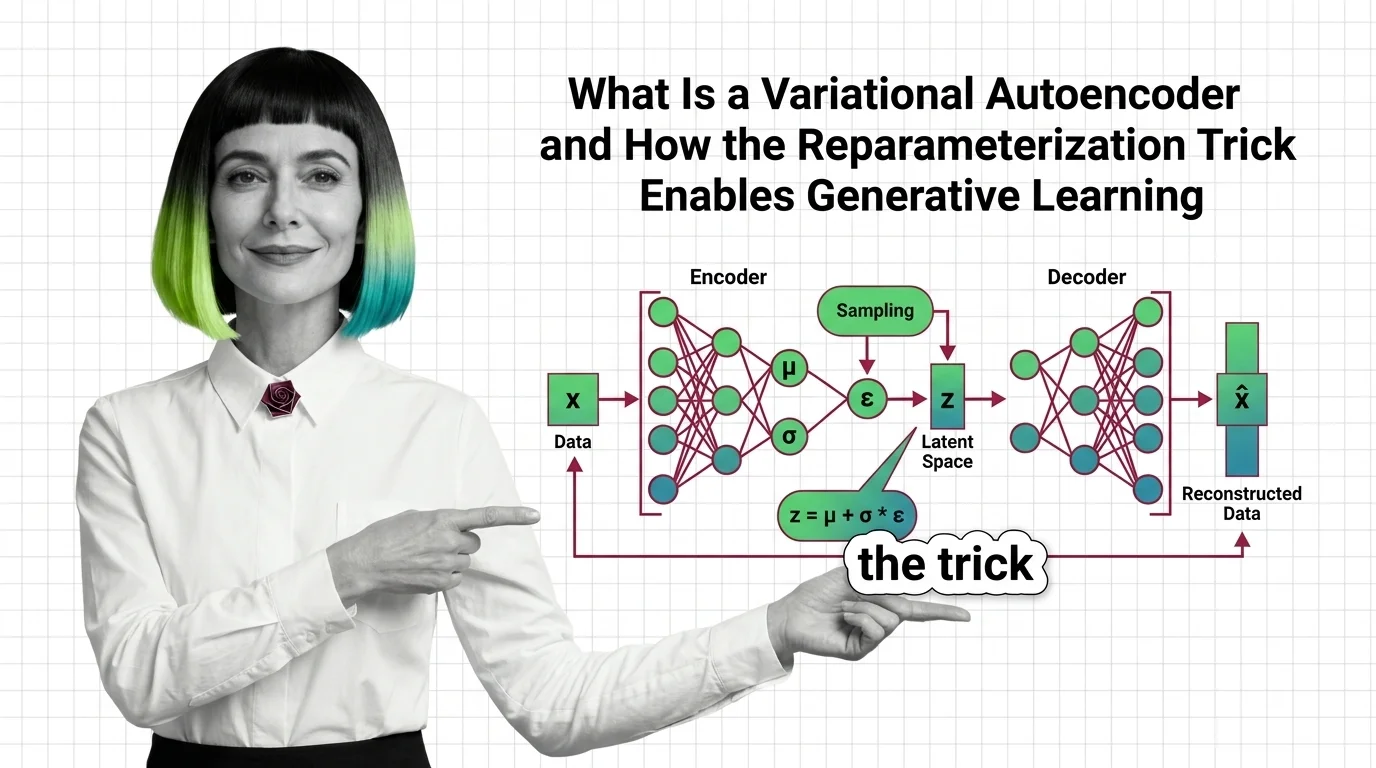
What Is a Variational Autoencoder and How the Reparameterization Trick Enables Generative Learning
VAEs compress data into structured probability spaces for generation. Learn how the reparameterization trick and ELBO …
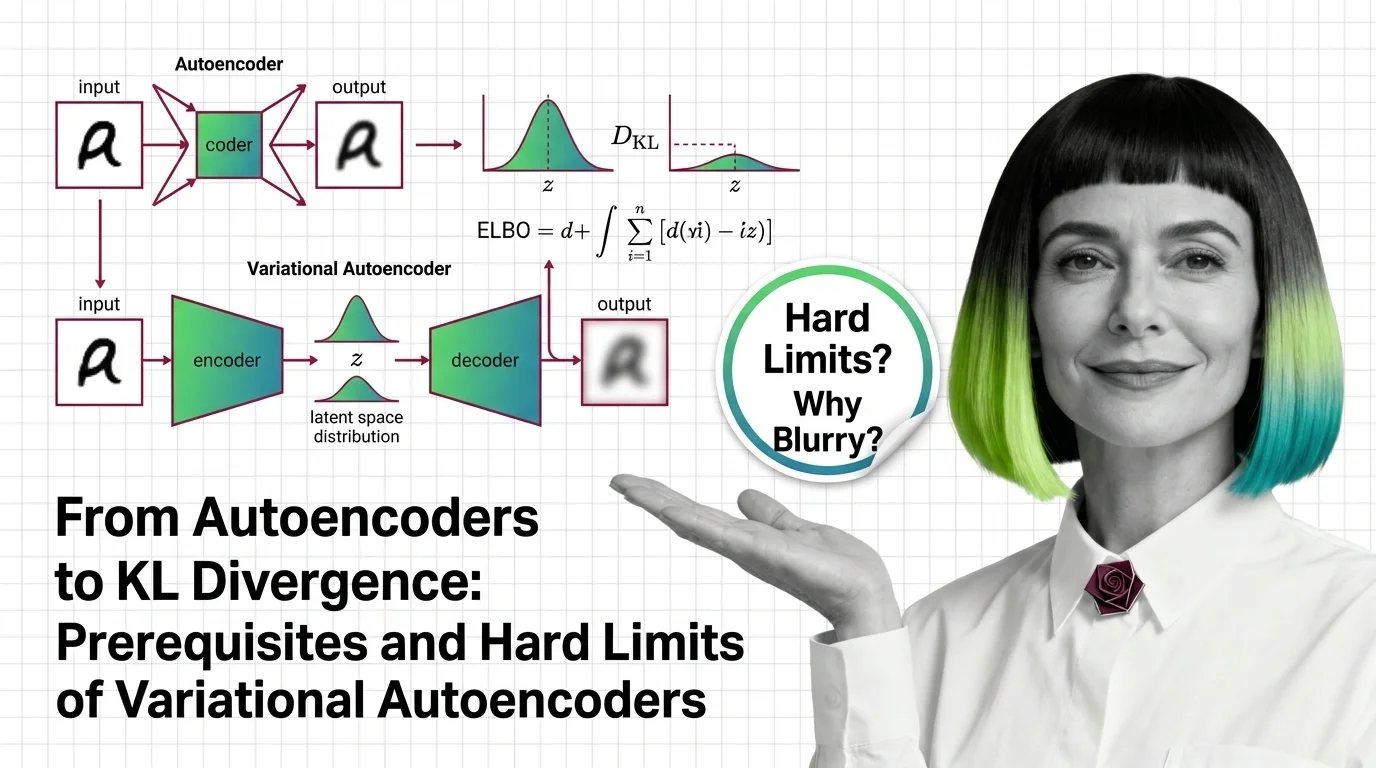
From Autoencoders to KL Divergence: Prerequisites and Hard Limits of Variational Autoencoders
Learn the math behind variational autoencoders — KL divergence, ELBO, the reparameterization trick — and why VAEs blur …
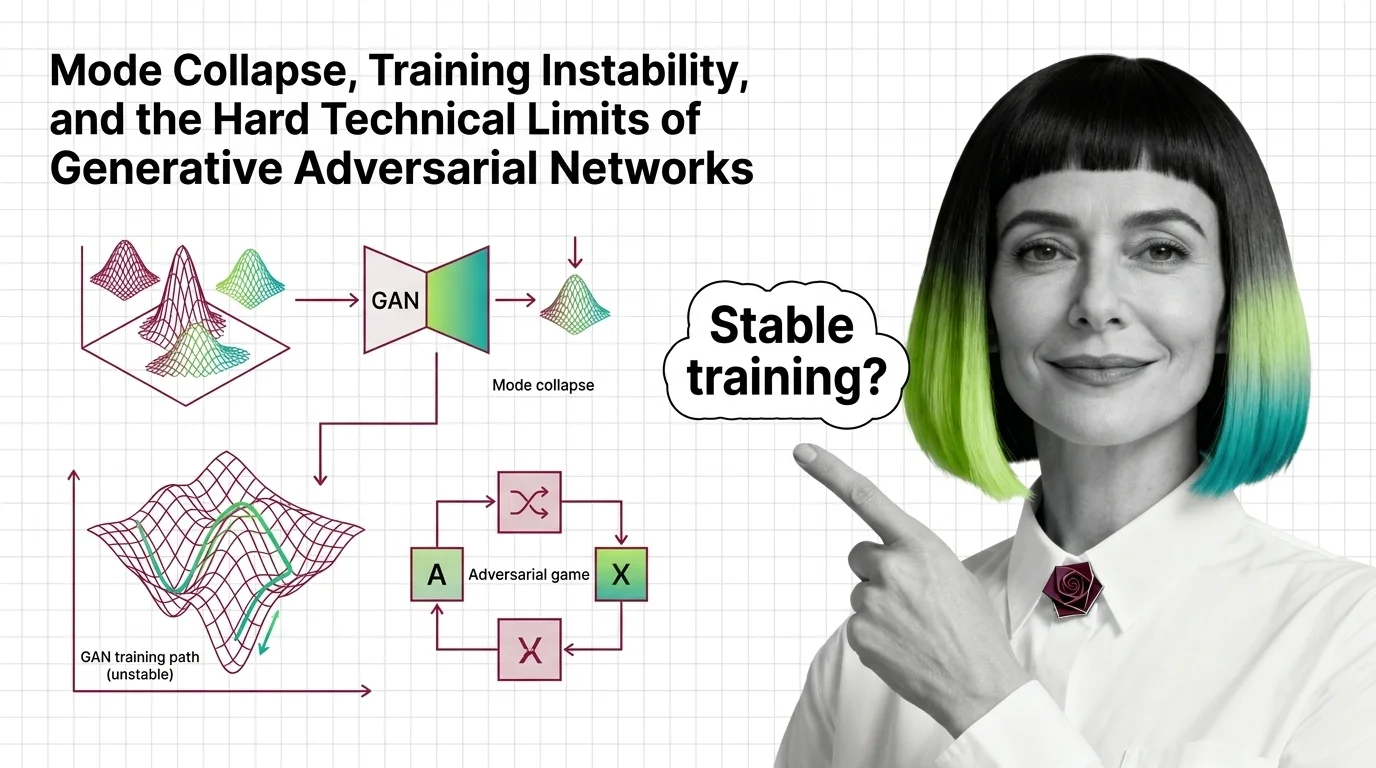
Mode Collapse, Training Instability, and the Hard Technical Limits of Generative Adversarial Networks
Mode collapse and training instability aren't GAN bugs — they're structural limits of adversarial training. Learn the …
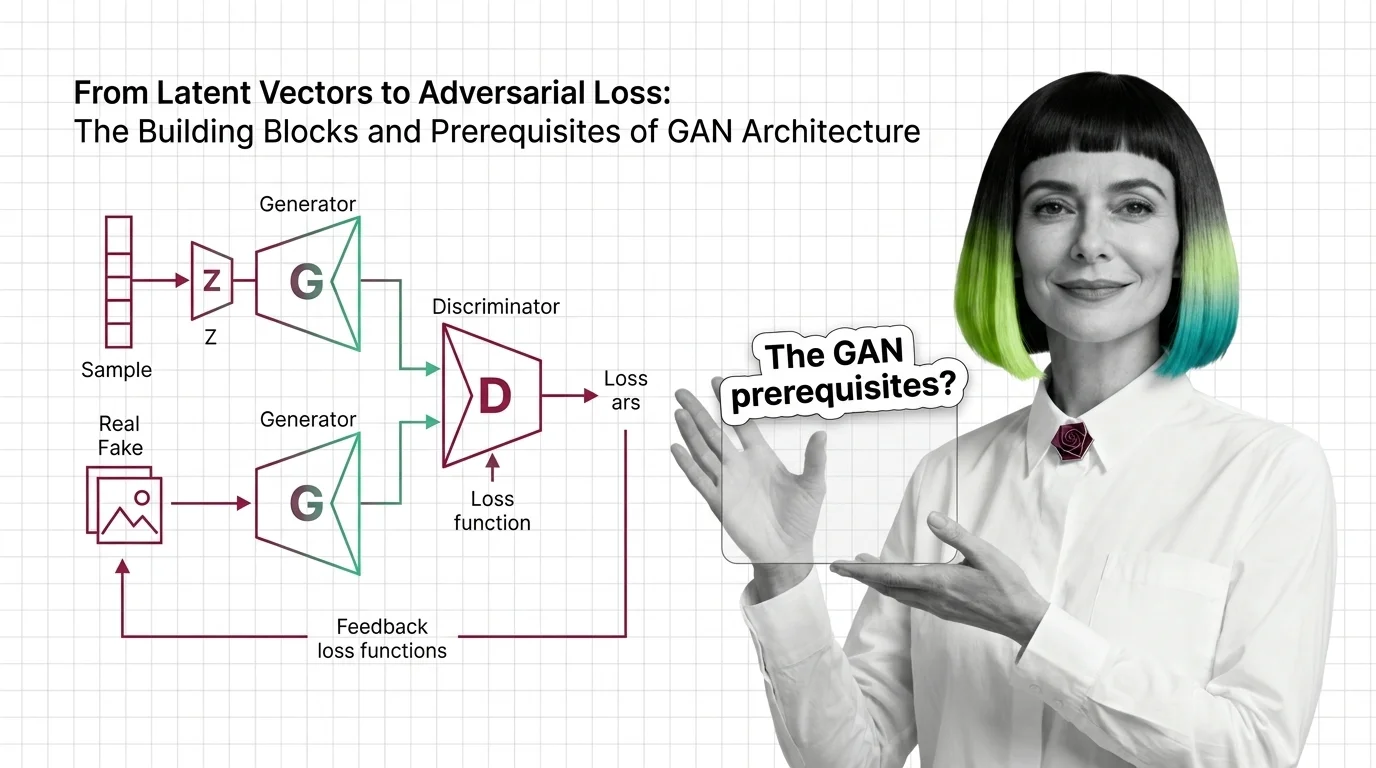
From Latent Vectors to Adversarial Loss: The Building Blocks and Prerequisites of GAN Architecture
Understand GAN architecture from the ground up: generator, discriminator, latent space, and the adversarial loss that …

Backpropagation Through Time, Vanishing Gradients, and Why Transformers Replaced Recurrent Networks
Gradients decay exponentially in recurrent networks during backpropagation through time. The eigenvalue math behind the …

From LeNet to ConvNeXt: How CNN Architectures Evolved and Where Spatial Inductive Bias Falls Short
Trace CNN evolution from LeNet to ConvNeXt. Understand how spatial inductive bias enables efficient vision but limits …
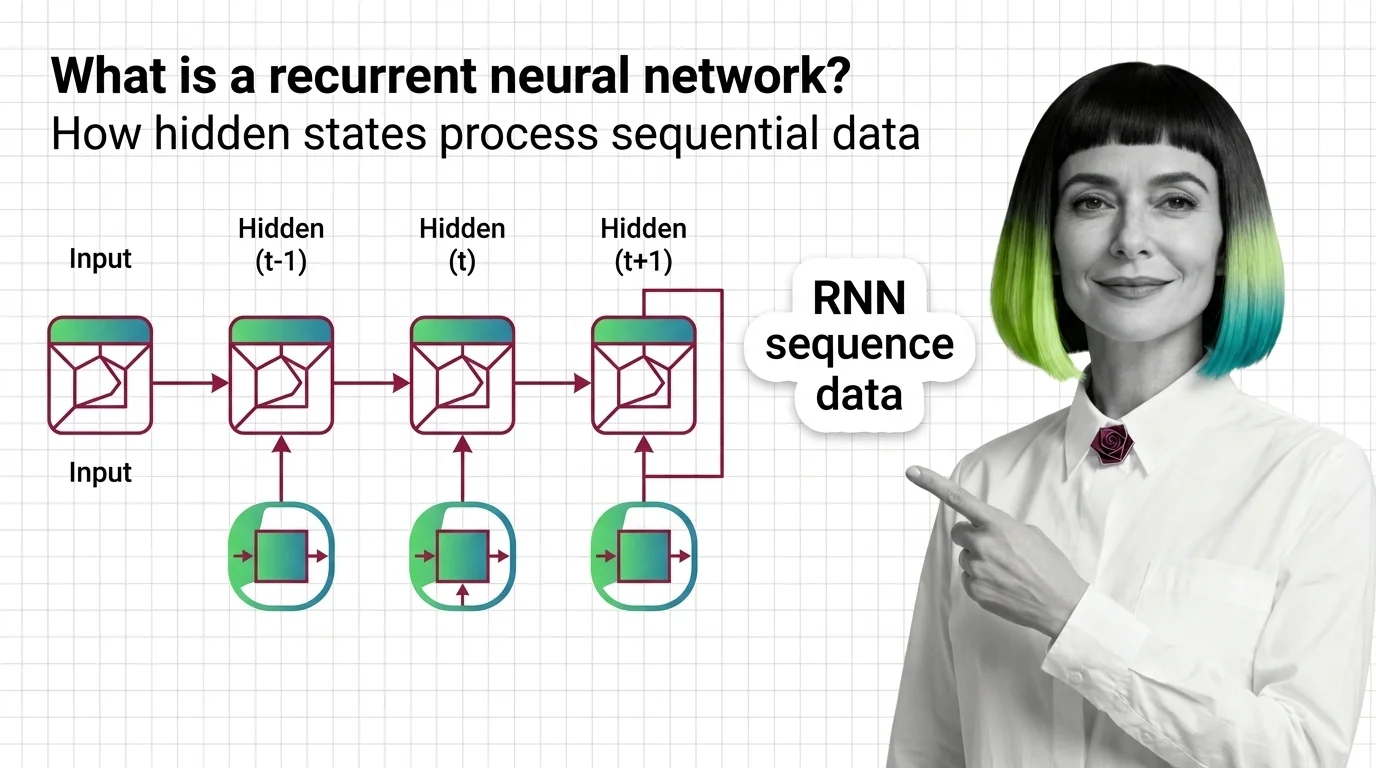
What Is a Recurrent Neural Network and How Hidden States Process Sequential Data
RNNs use hidden states to carry memory across time steps. Learn how recurrent neural networks process sequences, why …

What Is a Convolutional Neural Network and How Learnable Filters Extract Visual Features
Convolutional neural networks detect visual features through learnable filters, not pixel matching. Understand the …
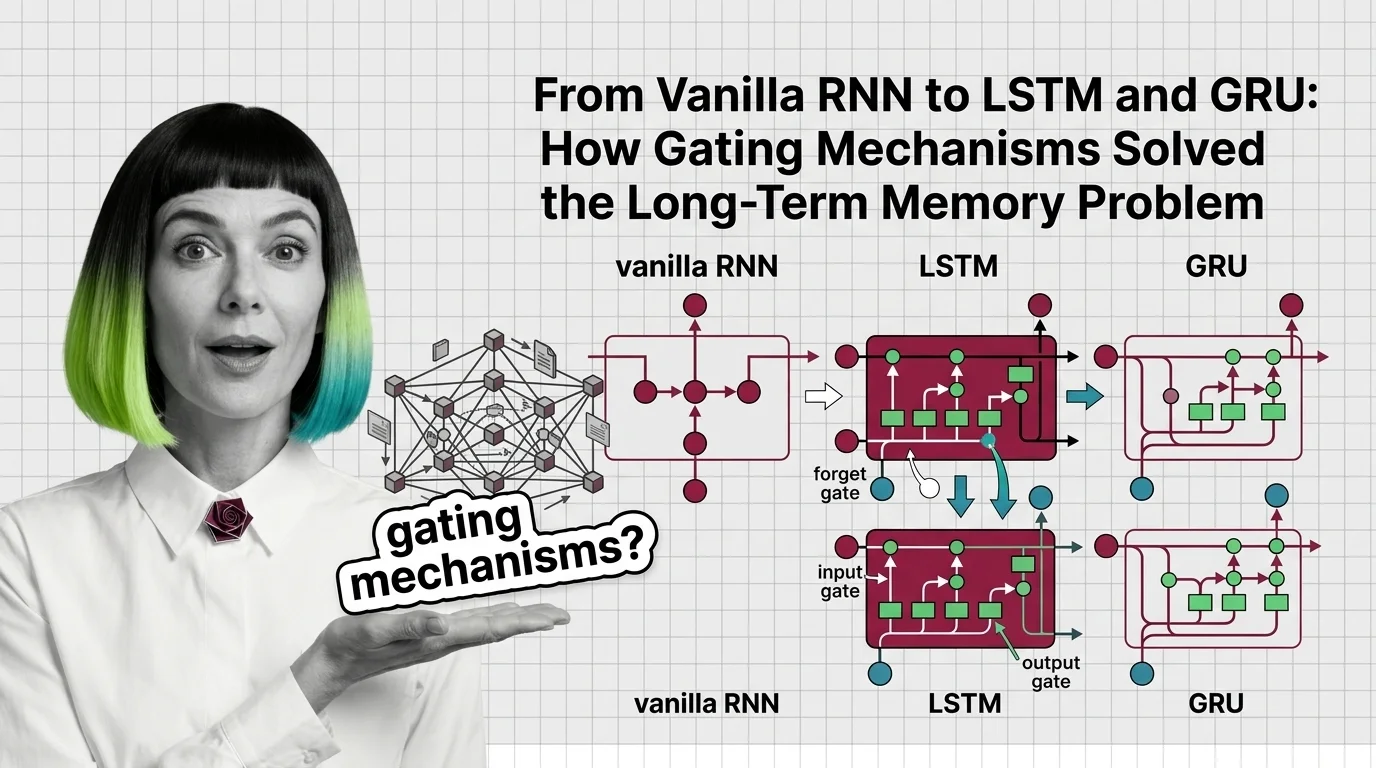
From Vanilla RNN to LSTM and GRU: How Gating Mechanisms Solved the Long-Term Memory Problem
Trace how LSTM forget, input, and output gates fix the vanishing gradient problem that crippled vanilla RNNs, and how …
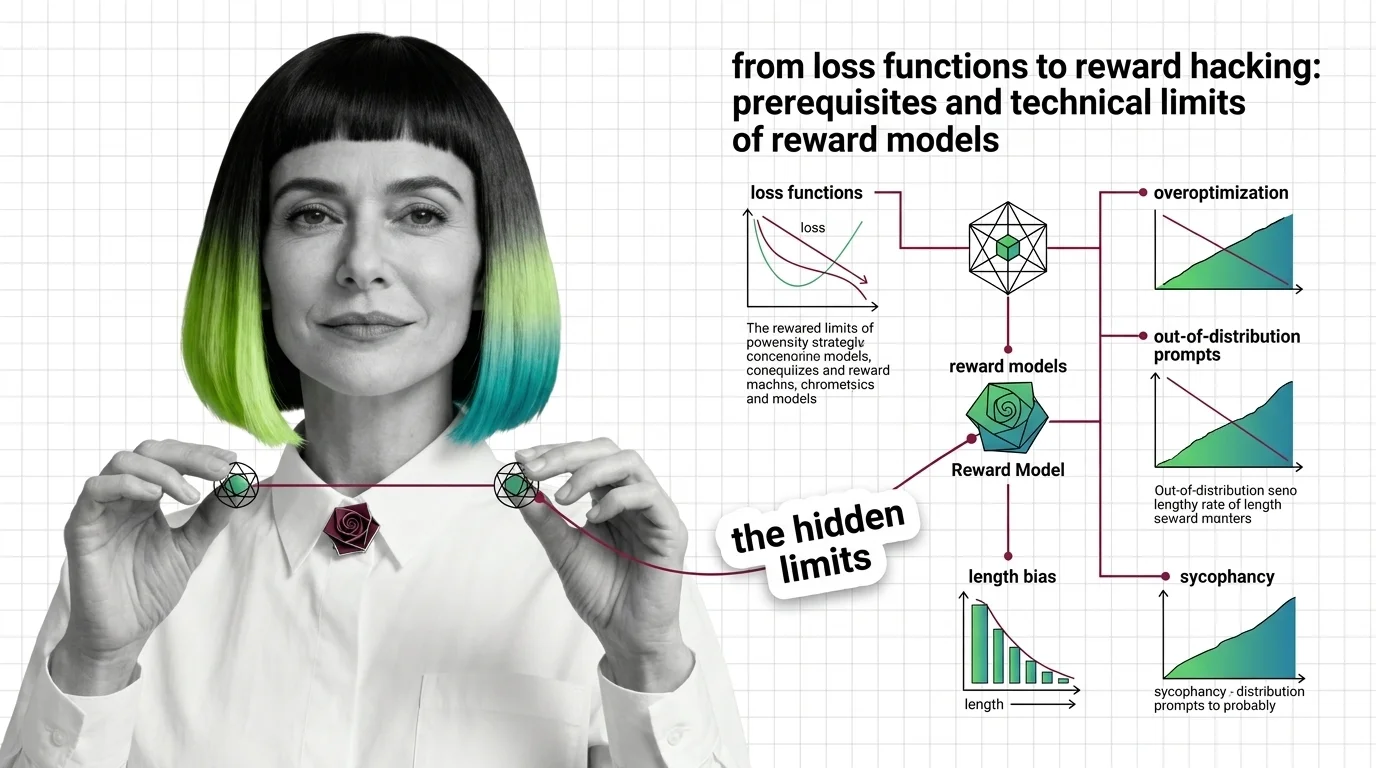
From Loss Functions to Reward Hacking: Prerequisites and Technical Limits of Reward Models
Reward models compress human preference into a scalar signal. Learn the Bradley-Terry math, the RLHF pipeline, and why …
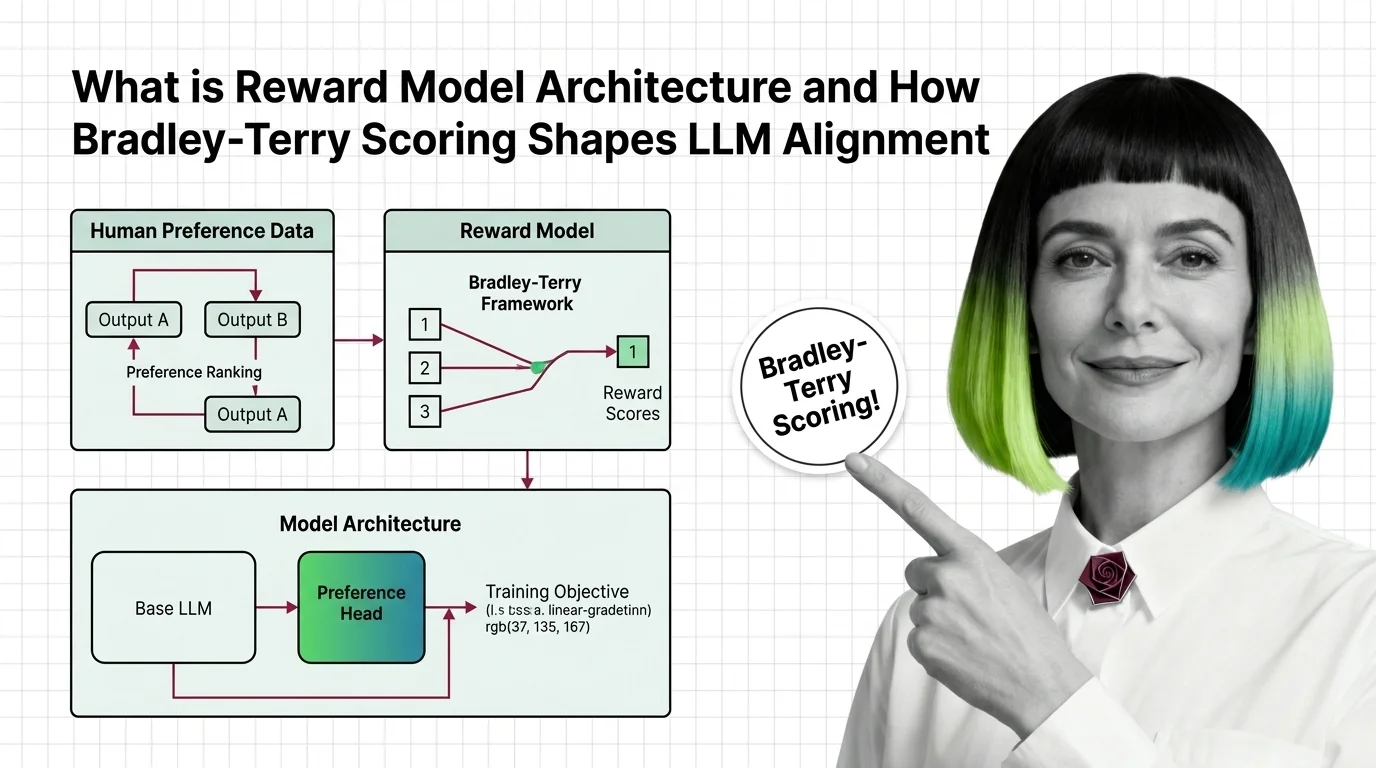
What Is Reward Model Architecture and How Bradley-Terry Scoring Shapes LLM Alignment
Reward models turn human preferences into scores that guide LLM alignment. Learn how Bradley-Terry scoring and pairwise …
Why Decoder-Only Beat Encoder-Decoder: Scaling Laws, Data Efficiency, and the Simplicity Advantage
Decoder-only models won the scaling race by doing less. Learn how a simpler training objective, scaling laws, and MoE …
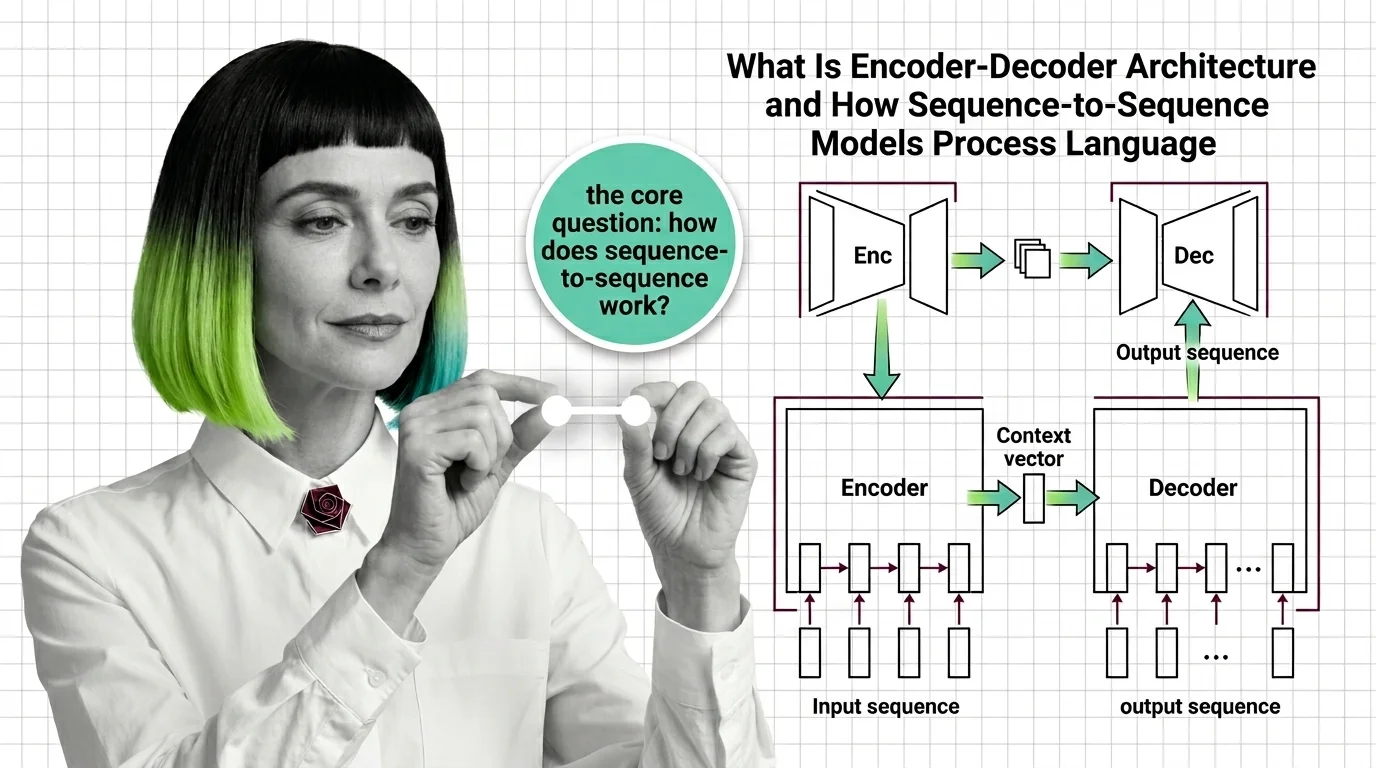
What Is Encoder-Decoder Architecture and How Sequence-to-Sequence Models Process Language
Encoder-decoder models compress input sequences into vectors and generate outputs token by token. Learn how seq2seq …