Model Architectures
How AI models are built — transformers, attention mechanisms, mixture-of-experts, and the design decisions that shape capability.
- Home /
- AI Principles /
- Model Architectures
Transformer Internals for Developers: What Maps, What Breaks
Transformer internals mapped for backend developers. Learn which service-architecture instincts still apply, where …
Why Decoder-Only Beat Encoder-Decoder: Scaling Laws, Data Efficiency, and the Simplicity Advantage
Decoder-only models won the scaling race by doing less. Learn how a simpler training objective, scaling laws, and MoE …
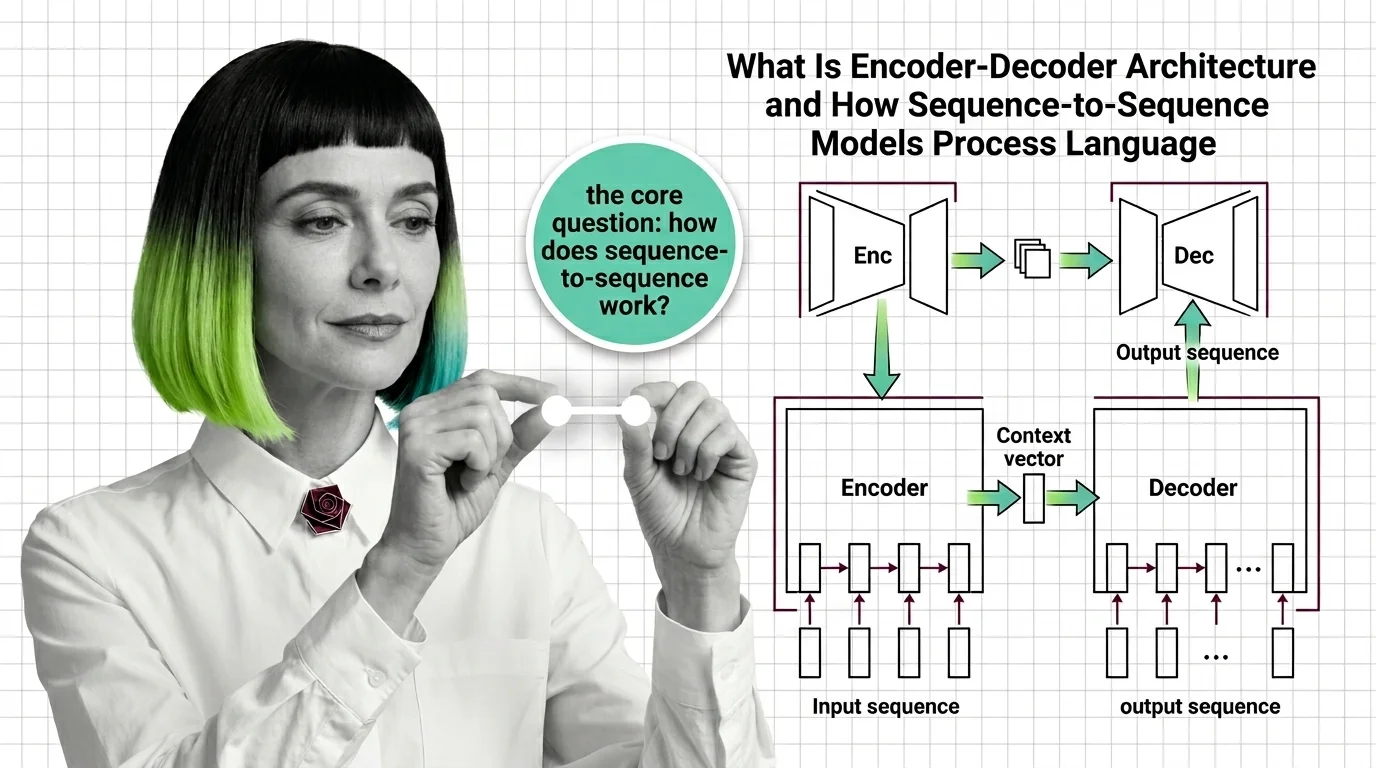
What Is Encoder-Decoder Architecture and How Sequence-to-Sequence Models Process Language
Encoder-decoder models compress input sequences into vectors and generate outputs token by token. Learn how seq2seq …

What Is Decoder-Only Architecture and How Autoregressive LLMs Generate Text Token by Token
Decoder-only architecture powers every major LLM today. Learn how causal masking, KV cache, and autoregressive …
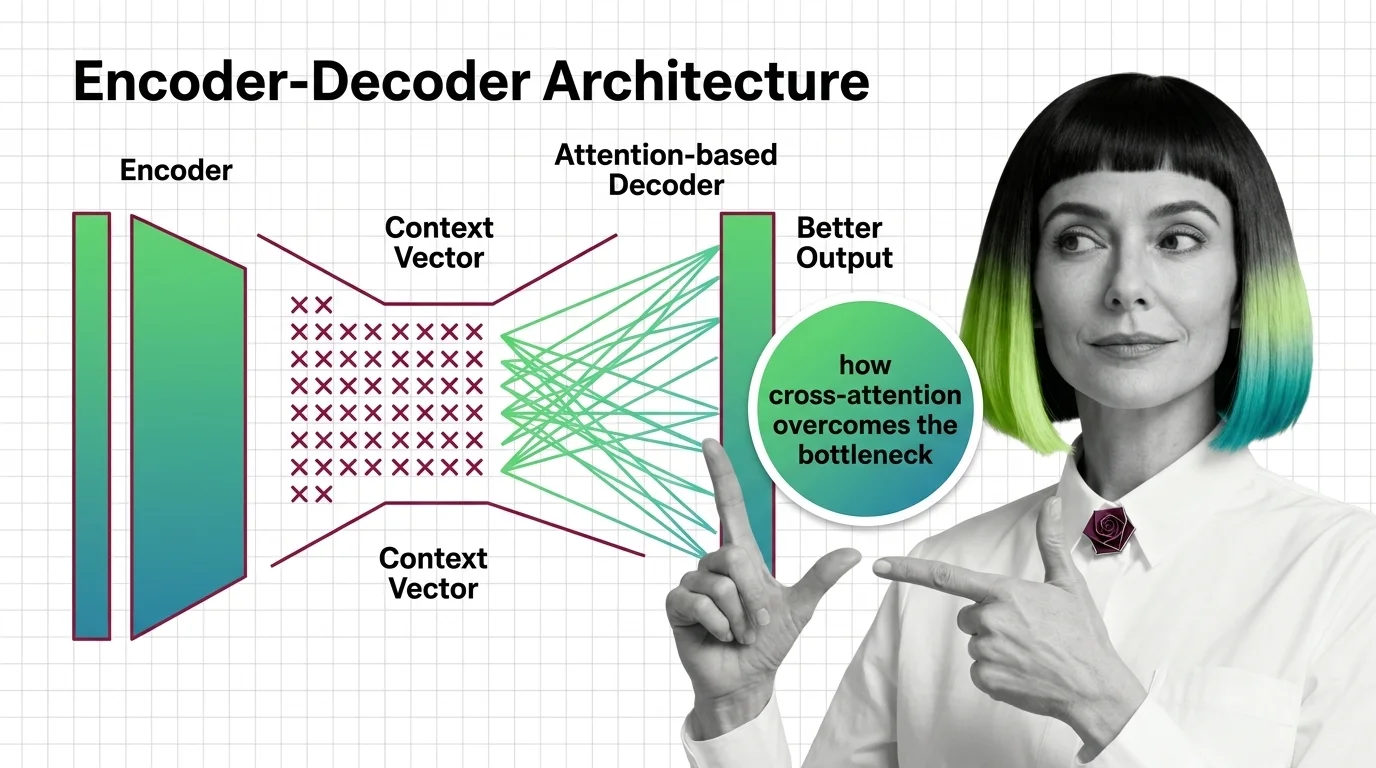
From Context Vectors to Cross-Attention: How Encoder-Decoder Design Overcame the Bottleneck Problem
The encoder-decoder bottleneck crushed long sequences into one vector. Learn how attention replaced compression with …