
How to Build a VAE in PyTorch and Apply It to Anomaly Detection and Data Augmentation in 2026
Build a variational autoencoder in PyTorch 2.11 the specification-first way. Decompose, specify, and validate your VAE …
How to Build a GAN with PyTorch and Apply It to Super-Resolution and Synthetic Data in 2026
Build a GAN in PyTorch by decomposing the architecture into generator, discriminator, and training loop specs. Covers …
How to Build an LSTM in PyTorch and Where RNNs Still Outperform Transformers in 2026
Learn when LSTMs beat transformers in 2026 — edge deployment, anomaly detection, time series — and how to specify an …

PyTorch CNN: EfficientNetV2 vs ResNet vs ConvNeXt (2026)
Evaluate EfficientNetV2, ResNet, and ConvNeXt. Get a clear decision framework to choose the right PyTorch model for your …

How to Build a Neural Network Language Model from Scratch with PyTorch in 2026
Decompose a neural network language model into four specification layers for AI-assisted development. Covers …

How to Benchmark LLMs with lm-evaluation-harness, HELM, and OpenCompass in 2026
Choose the right LLM evaluation harness — lm-evaluation-harness, HELM, or OpenCompass — with a spec-first workflow for …

How to Detect and Prevent Benchmark Contamination with CoDeC, CCV, and LiveBench in 2026
Detect benchmark contamination in LLMs using CoDeC, CCV, and LiveBench. A step-by-step workflow for auditing evaluations …

How to Design and Run Rigorous Ablation Experiments with ABLATOR, W&B Sweeps, and PyTorch in 2026
Design rigorous ablation experiments with ABLATOR, W&B Sweeps, and PyTorch 2.11. Specify, isolate, and prove which of …
How to Run MMLU Evaluation and Interpret Benchmark Scores for Model Selection in 2026
Run MMLU and MMLU-Pro evaluations correctly, avoid common configuration mistakes, and interpret benchmark scores to …

Confusion Matrices: scikit-learn, TorchMetrics & W&B (2026)
Specify, build, and validate confusion matrix pipelines with scikit-learn 1.8, TorchMetrics 1.9, and Weights & Biases …
How to Calculate and Tune Precision, Recall, and F1 Score with scikit-learn and TorchMetrics in 2026
Specify precision, recall, and F1 score evaluation in scikit-learn 1.8 and TorchMetrics 1.9. A framework to prevent …
How to Audit ML Models for Bias Using AI Fairness 360, Fairlearn, and What-If Tool in 2026
Audit ML models for bias with AI Fairness 360, Fairlearn, and What-If Tool. Specification framework for fairness …
AI Safety Evaluation: Llama Guard, Perspective API, promptfoo 2026
Production AI safety pipeline with Llama Guard 4, ShieldGemma, and promptfoo. Covers taxonomy design, model evaluation, …
How to Evaluate LLMs for Your Use Case with DeepEval, Langfuse, and Custom Benchmarks in 2026
Build an LLM evaluation pipeline with DeepEval, Langfuse, and Promptfoo. Covers metrics selection, production tracing, …

How to Detect and Reduce LLM Hallucinations with DeepEval, RAGAS, and RAG Grounding in 2026
Build a hallucination detection pipeline with DeepEval, RAGAS, and RAG grounding checks. Step-by-step framework for …
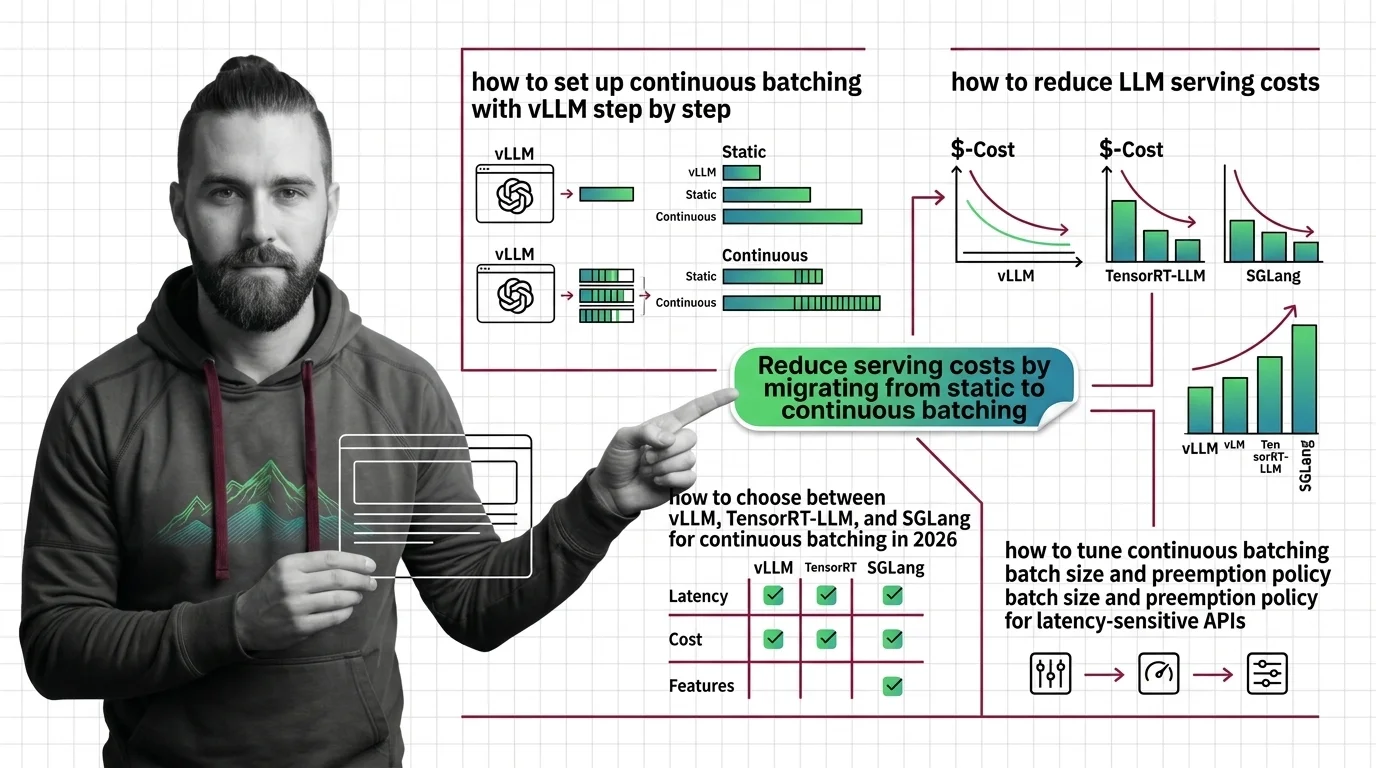
How to Deploy Continuous Batching with vLLM, TensorRT-LLM, and SGLang in 2026
Deploy continuous batching with vLLM, TensorRT-LLM, or SGLang using a parameter-by-parameter framework. Covers engine …

How to Choose and Configure Temperature, Top-P, and Min-P for Every LLM Use Case in 2026
Configure temperature, top-p, and min-p for code generation, creative writing, and RAG pipelines across OpenAI, …
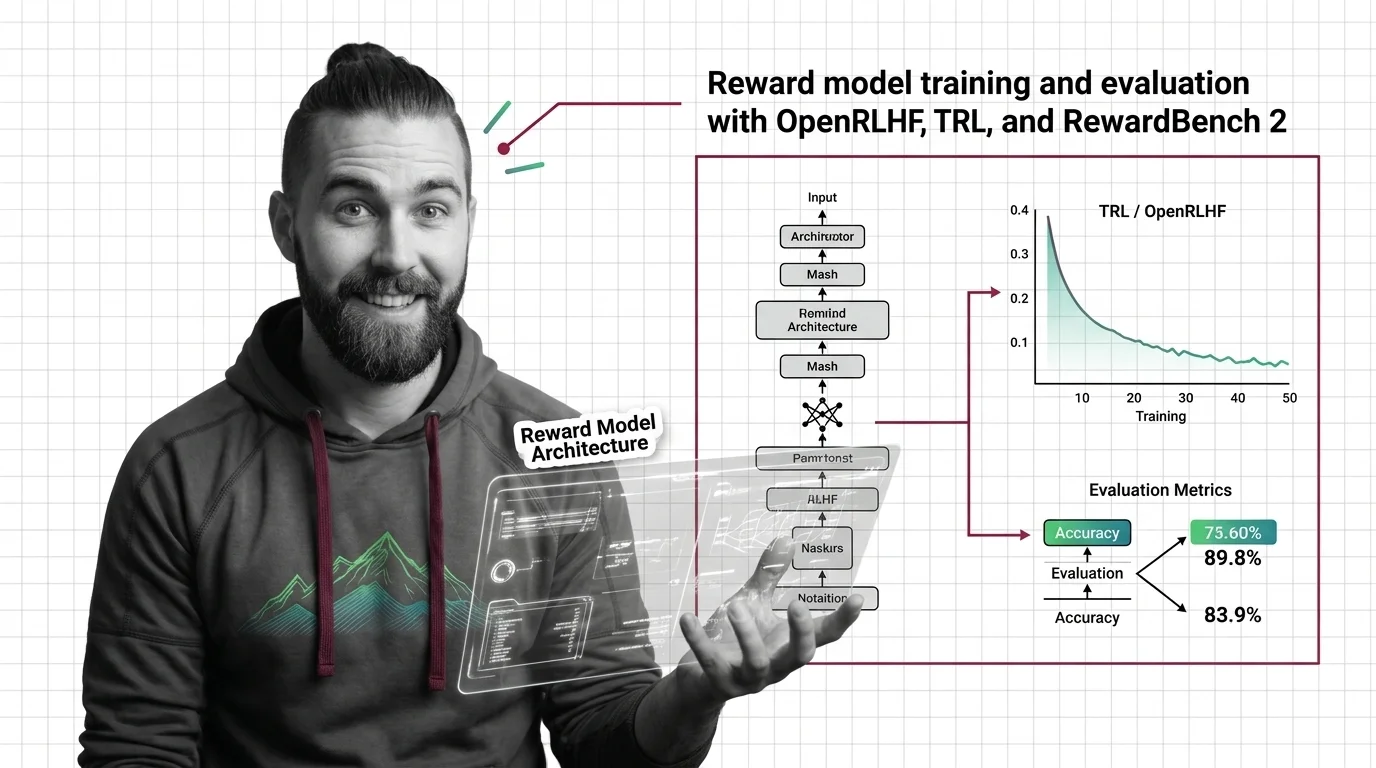
How to Train and Evaluate a Reward Model with OpenRLHF, TRL, and RewardBench 2 in 2026
Train a reward model using TRL or OpenRLHF, then evaluate with RewardBench 2. Spec-first guide covering architecture, …

How to Red Team an LLM with Promptfoo, PyRIT, and Garak in 2026
Build an LLM red teaming pipeline with Promptfoo, PyRIT, and Garak. Map attack surfaces, run multi-turn tests, and score …
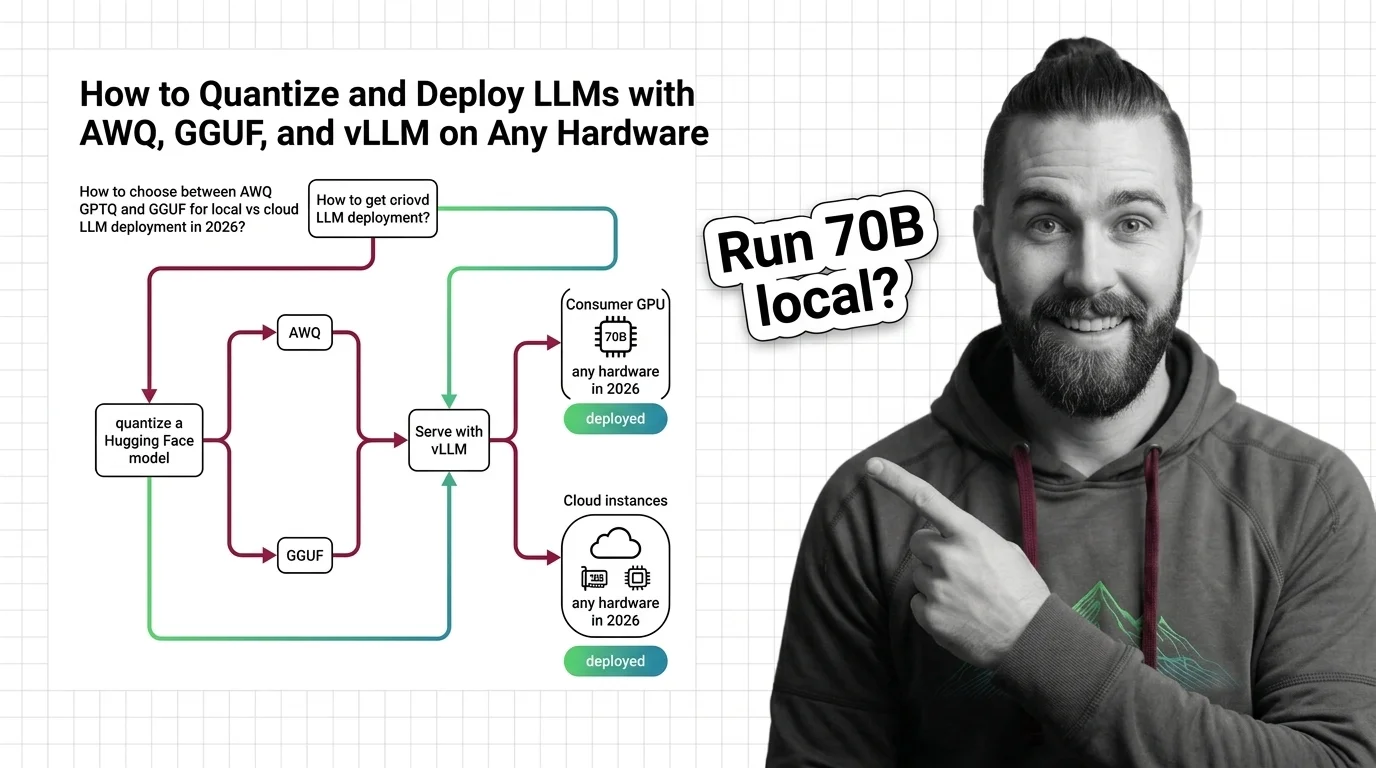
How to Quantize and Deploy LLMs with AWQ, GGUF, and vLLM on Any Hardware in 2026
Choose the right LLM quantization format for your hardware. AWQ, GPTQ, and GGUF compared — plus current vLLM and …
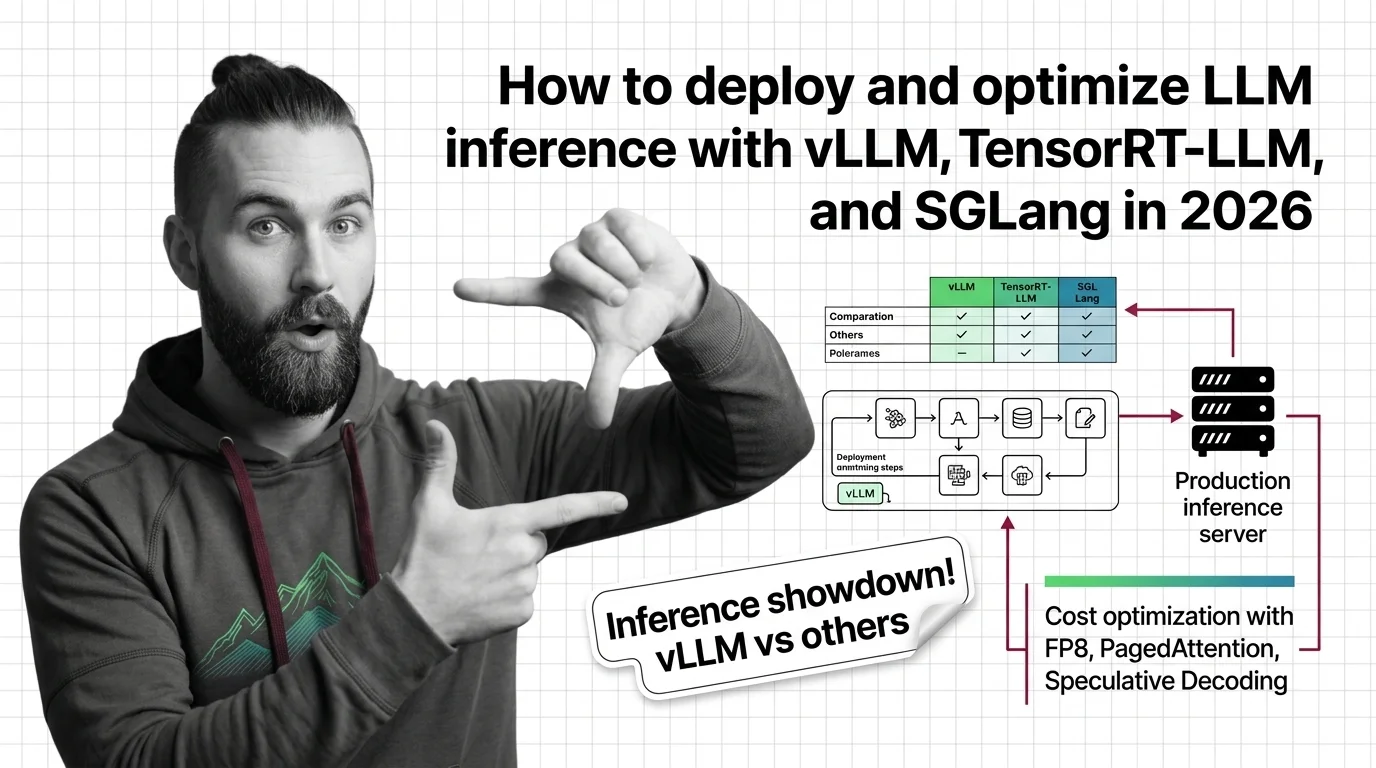
How to Deploy and Optimize LLM Inference with vLLM, TensorRT-LLM, and SGLang in 2026
Deploy production LLM inference with vLLM, TensorRT-LLM, or SGLang. Covers workload profiling, engine selection, FP8 …
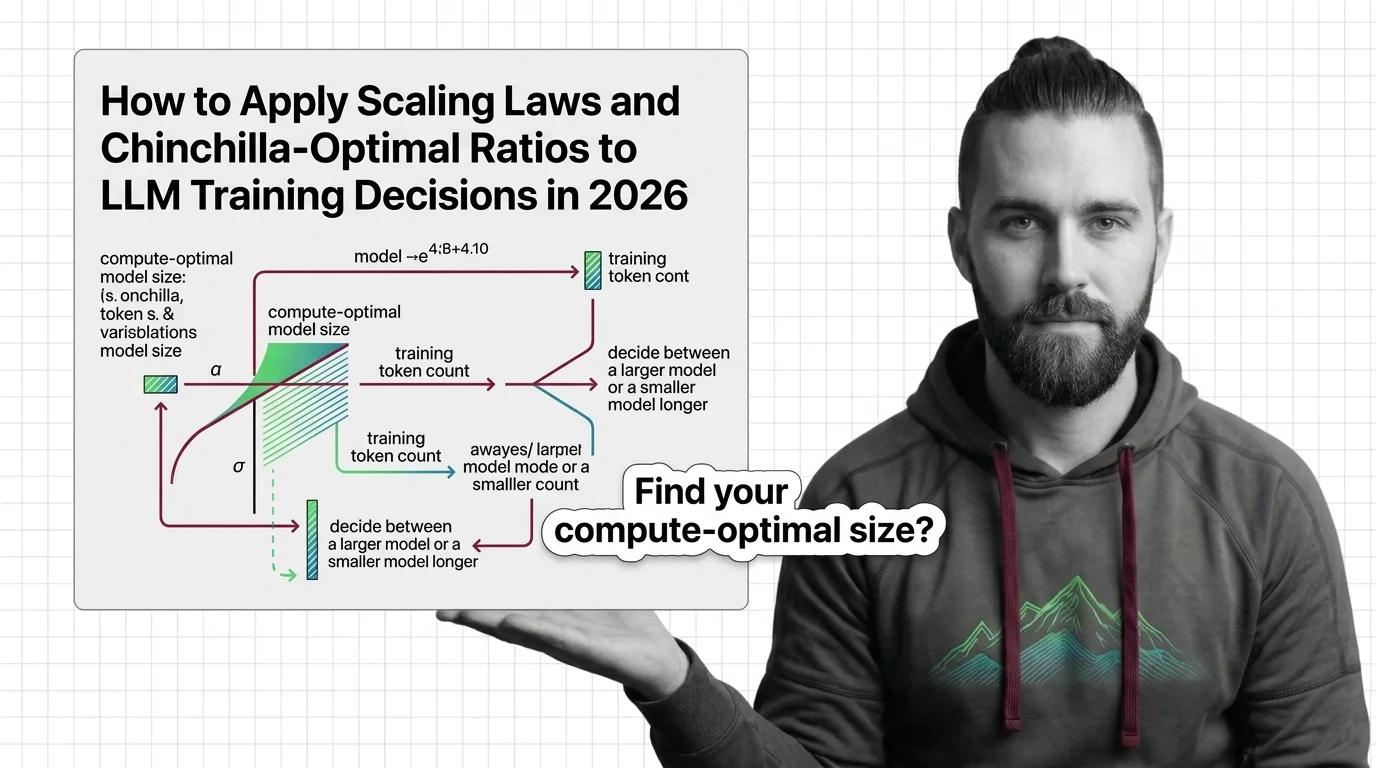
How to Apply Scaling Laws and Chinchilla-Optimal Ratios to LLM Training Decisions in 2026
Apply scaling laws and Chinchilla-optimal ratios to real LLM training decisions. Compute budgeting, model sizing, and …

How to Train a Language Model with RLHF Using OpenRLHF and TRL in 2026
Decompose, specify, and validate a full RLHF training pipeline with OpenRLHF and TRL in 2026. Covers SFT, reward …
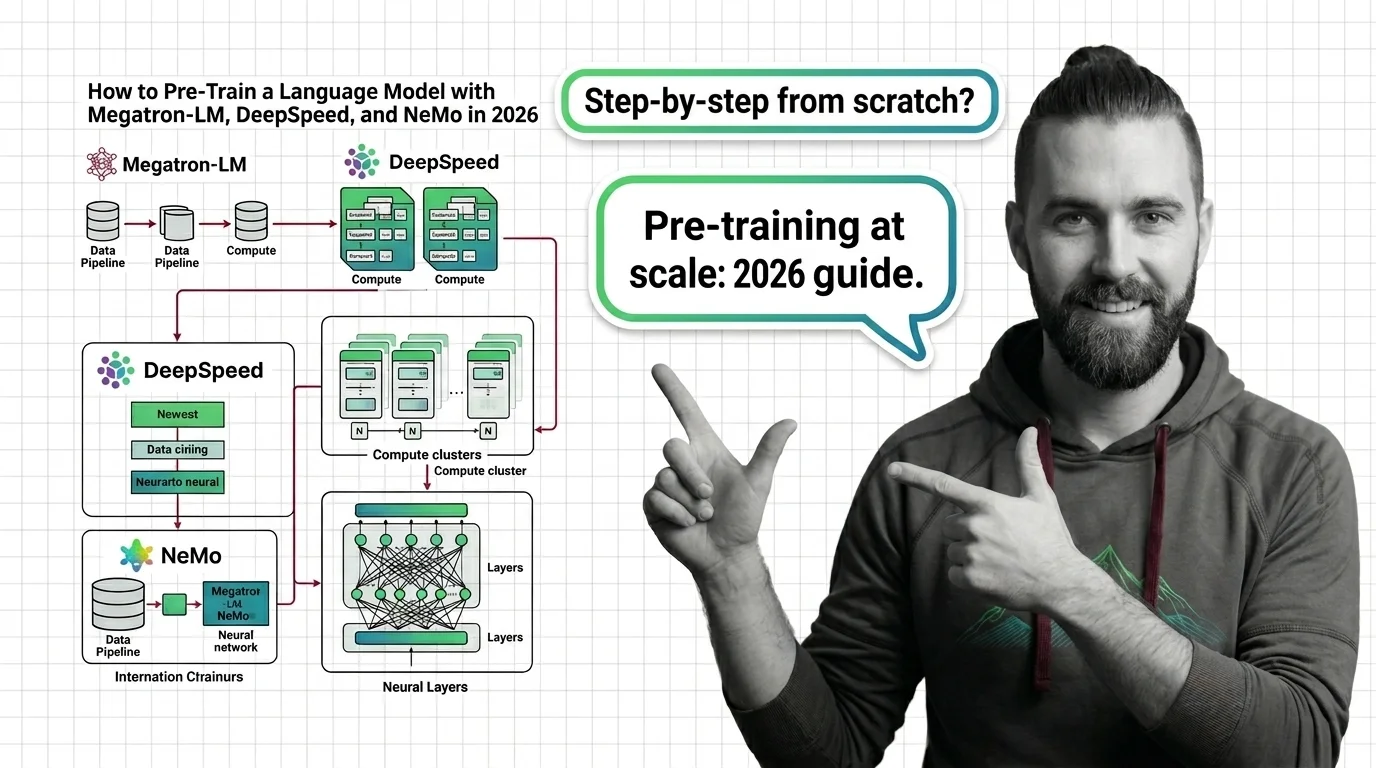
How to Pre-Train a Language Model with Megatron-LM, DeepSpeed, and NeMo in 2026
Pre-train a language model using Megatron-LM, DeepSpeed, and Megatron Bridge in 2026. Specification-first guide to …
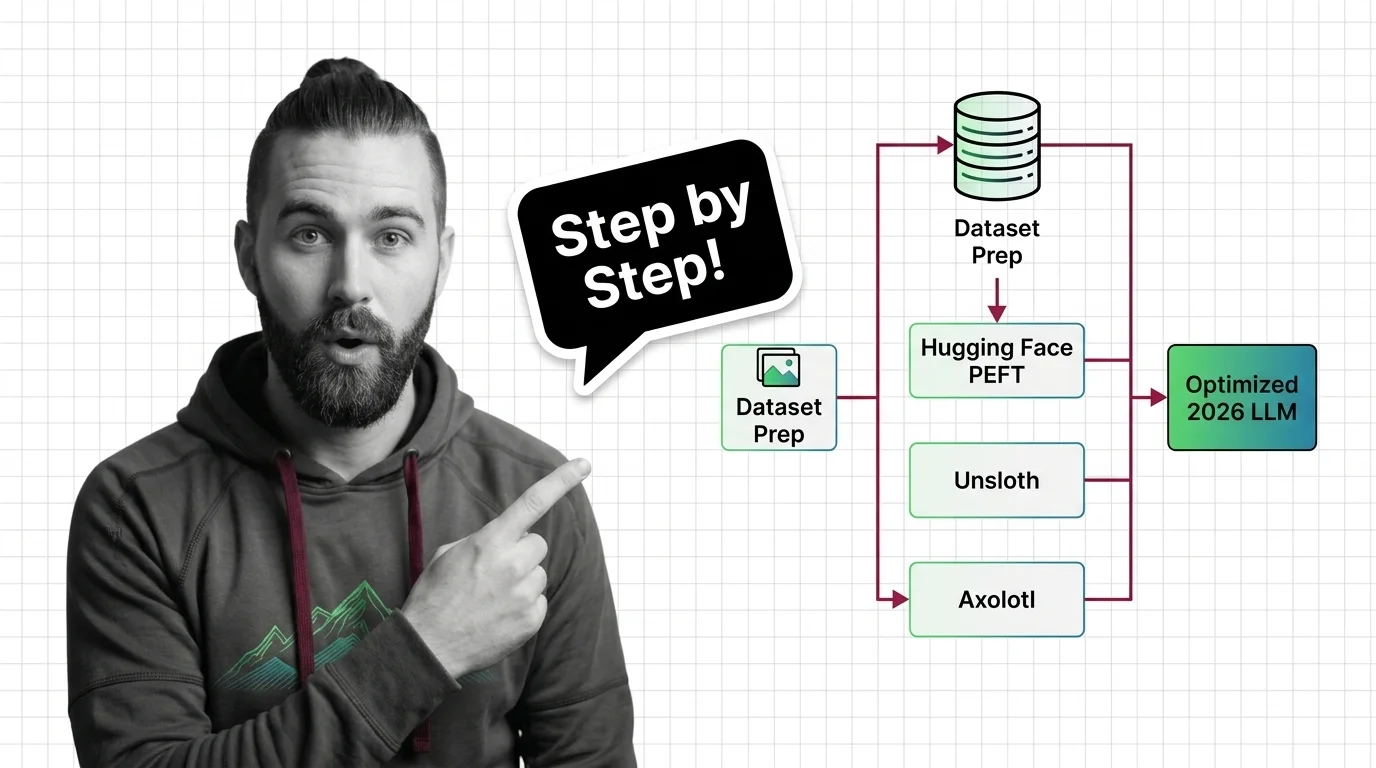
How to Fine-Tune an Open-Source LLM with Hugging Face PEFT, Unsloth, and Axolotl in 2026
Fine-tune open-source LLMs with PEFT, Unsloth, and Axolotl using a specification-first framework. Dataset prep, LoRA …

How to Fine-Tune and Deploy Sentence Transformers for Semantic Search and Clustering in 2026
Fine-tune Sentence Transformers v5.3 for semantic search and clustering. Covers MultipleNegativesRankingLoss, Matryoshka …
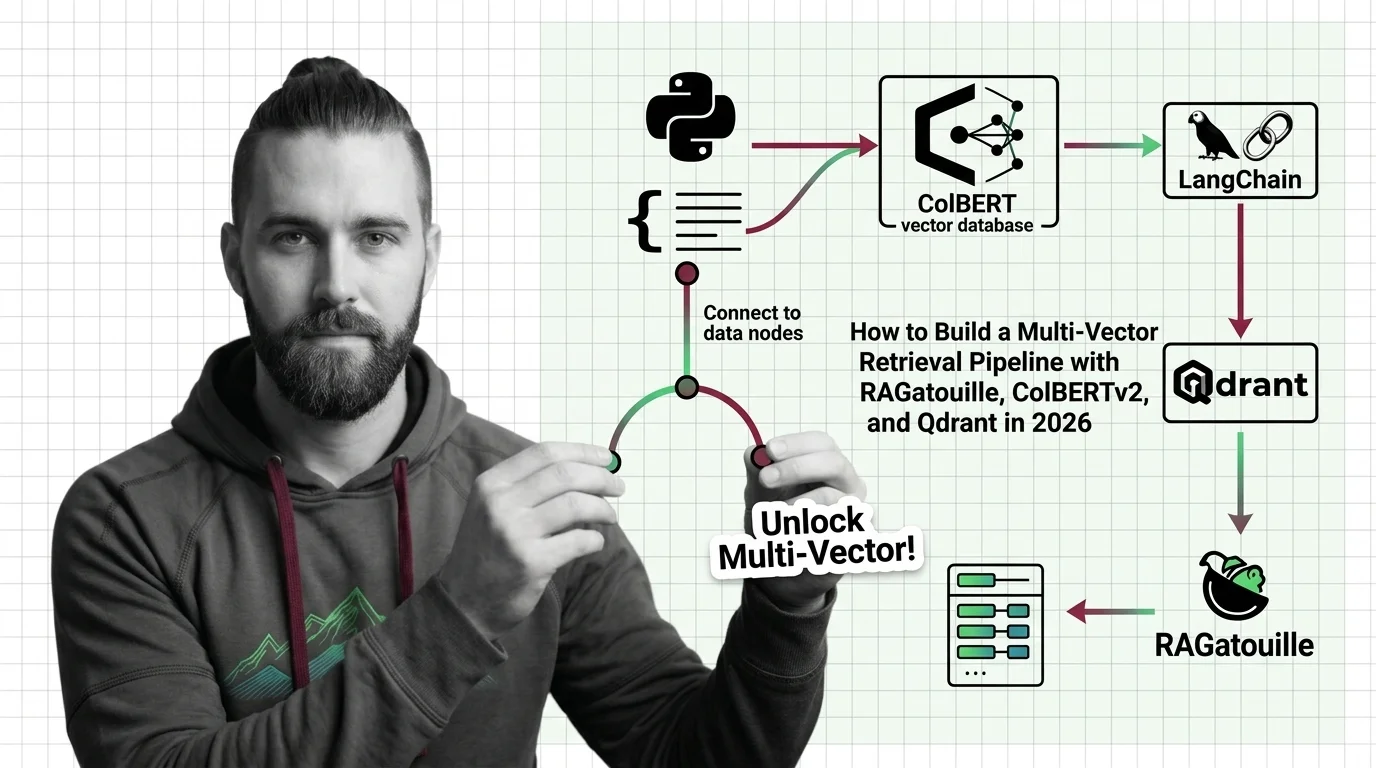
How to Build a Multi-Vector Retrieval Pipeline with RAGatouille, ColBERTv2, and Qdrant in 2026
Build a production multi-vector retrieval pipeline with ColBERTv2, RAGatouille, and Qdrant. Specification-first …
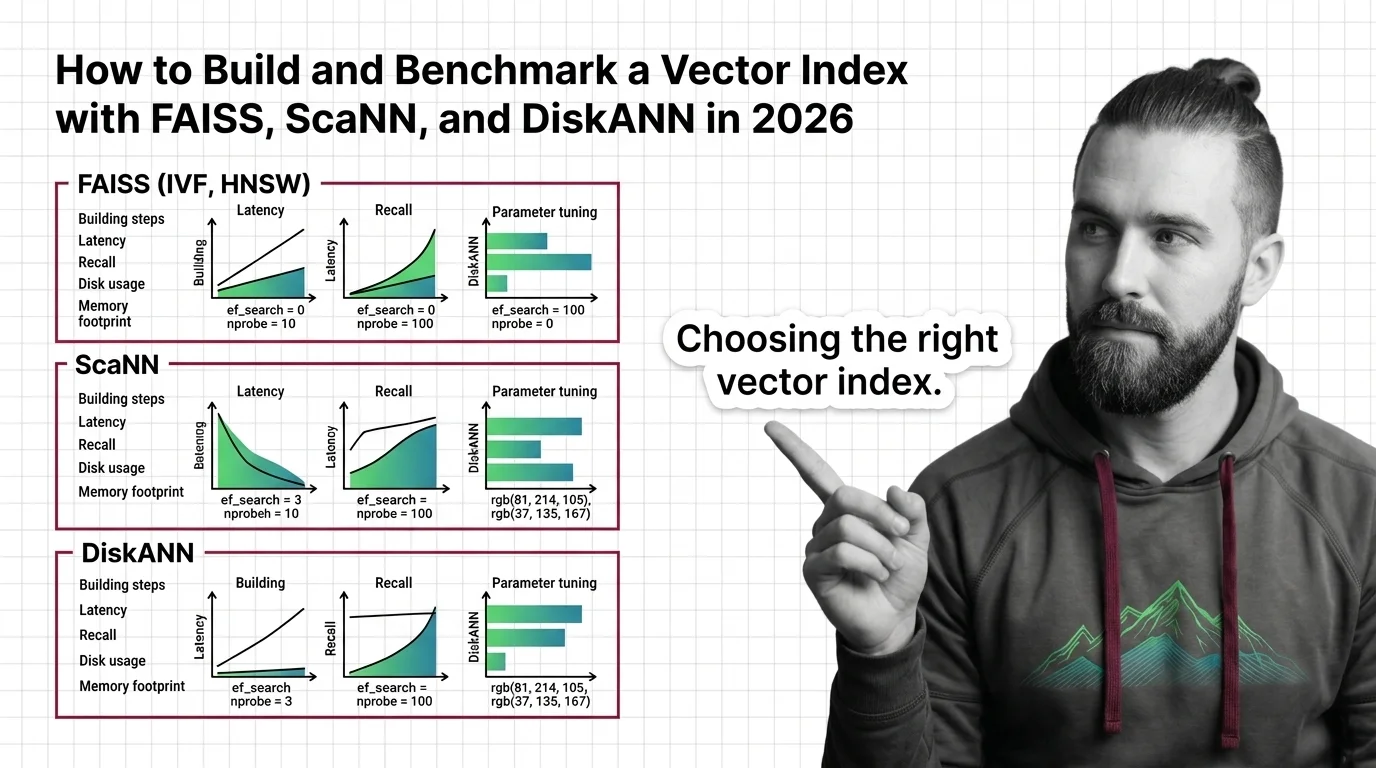
How to Build and Benchmark a Vector Index with FAISS, ScaNN, and DiskANN in 2026
Build and benchmark vector indexes with FAISS, ScaNN, and DiskANN. Choose index types by dataset size, tune parameters …
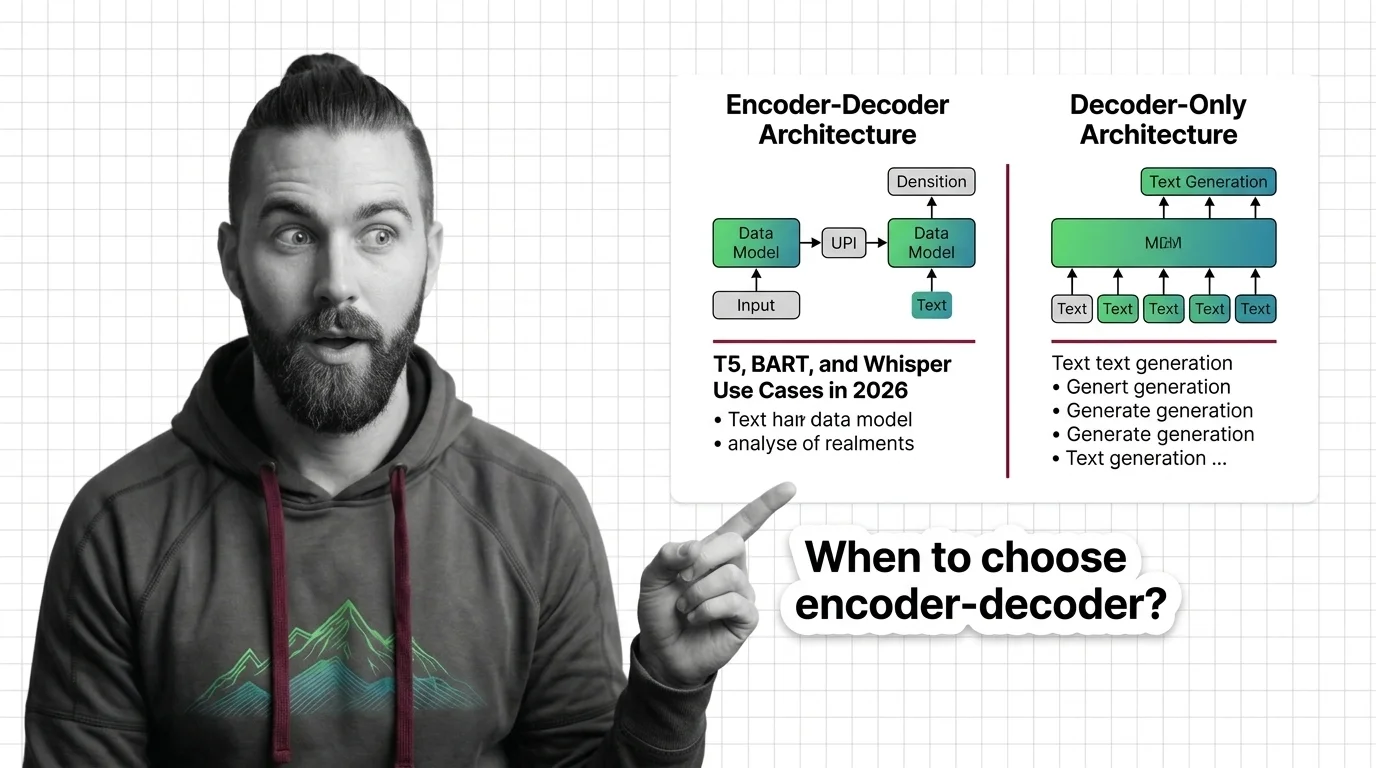
When to Choose Encoder-Decoder Over Decoder-Only: T5, BART, and Whisper Use Cases in 2026
Learn when encoder-decoder models like T5, BART, and Whisper outperform decoder-only alternatives. A spec framework for …
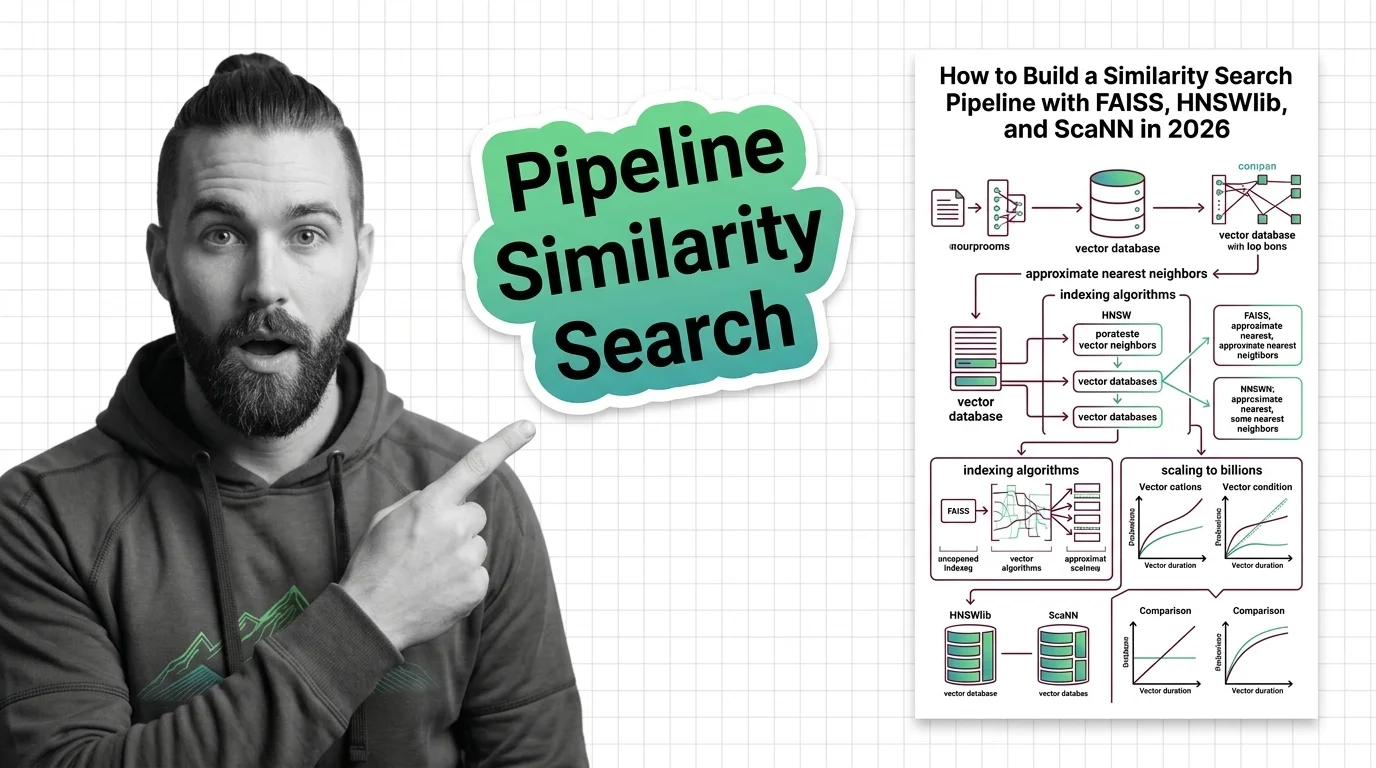
Similarity Search Pipeline: FAISS, HNSWlib, ScaNN (2026)
Select between FAISS, HNSWlib, and ScaNN for production vector search. Specification-first approach covering index …