LLM Foundations
Core mechanics of large language models — training, inference, tokenization, and the mathematics of next-token prediction.
- Home /
- AI Principles /
- LLM Foundations

What Are Scaling Laws and How Power-Law Curves Predict LLM Performance
Scaling laws predict LLM performance from model size, data, and compute via power-law curves. Learn the math behind …
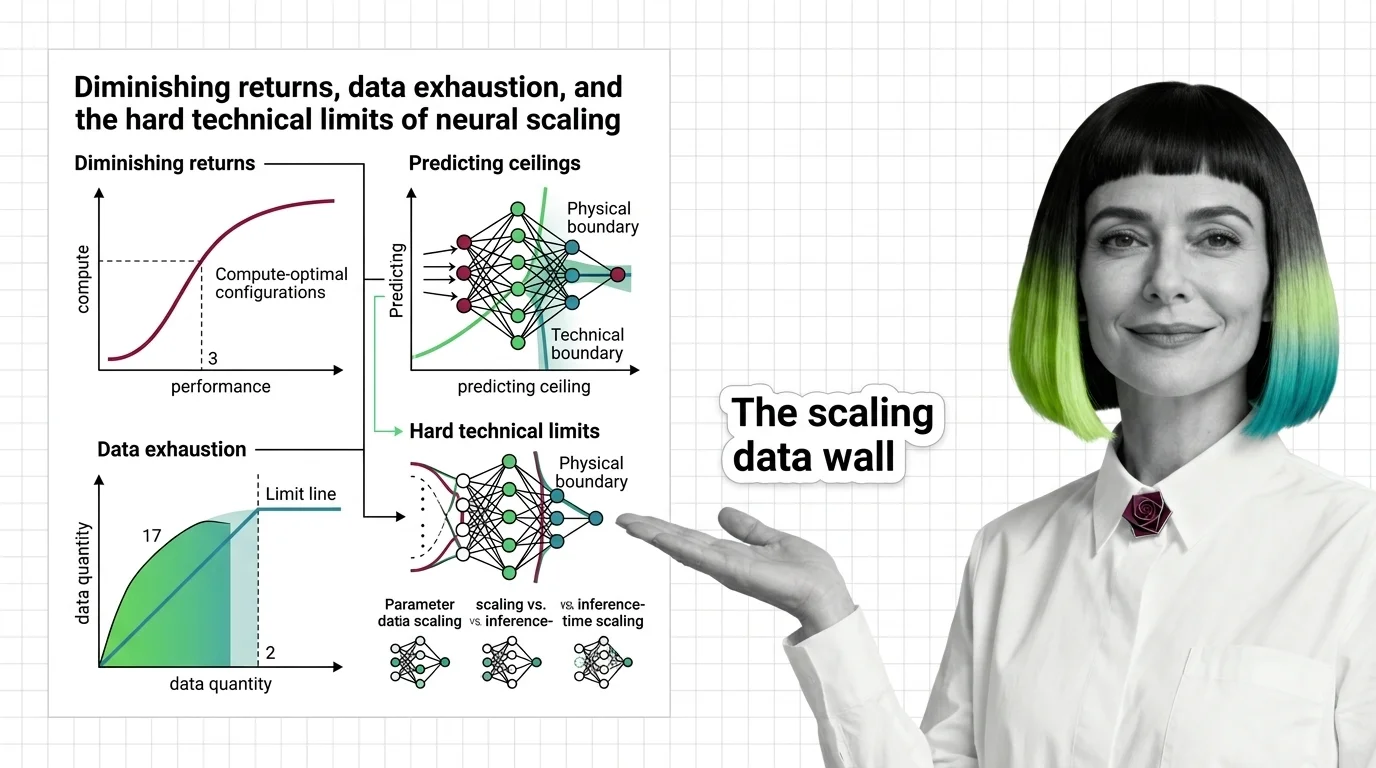
Diminishing Returns, Data Exhaustion, and the Hard Technical Limits of Neural Scaling
Scaling laws predict how AI models improve with compute, but power-law exponents guarantee diminishing returns. Learn …
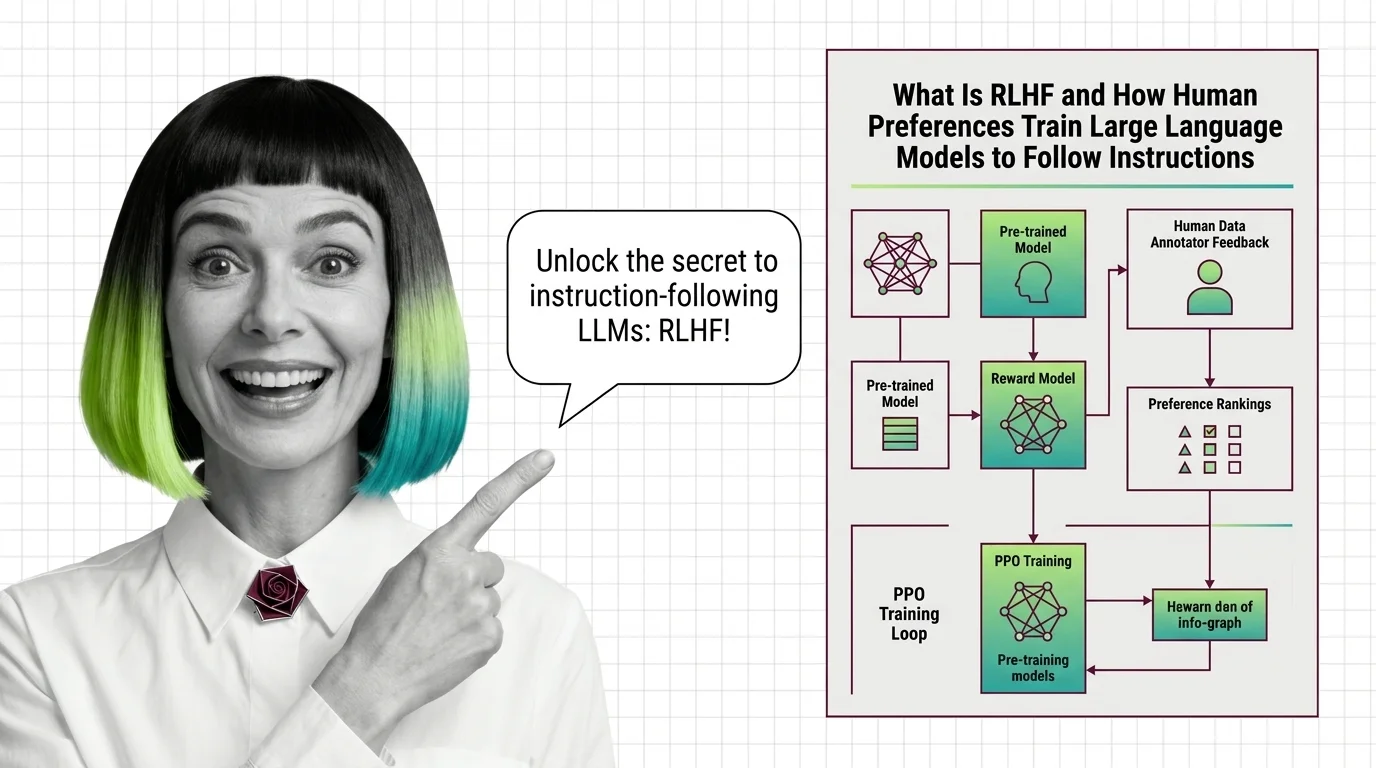
What Is RLHF and How Human Preferences Train Large Language Models to Follow Instructions
RLHF uses human preferences and reward models to train language models to follow instructions. Learn the three-stage PPO …

Reward Hacking, Mode Collapse, and the Unsolved Technical Limits of RLHF Alignment
Reward hacking, mode collapse, and KL divergence failure — the three unsolved technical limits of RLHF alignment and why …

From Reward Modeling to KL Penalties: Every Stage of the RLHF Training Pipeline Explained
RLHF aligns language models through human preferences in three stages. Learn how reward models, PPO, and KL penalties …
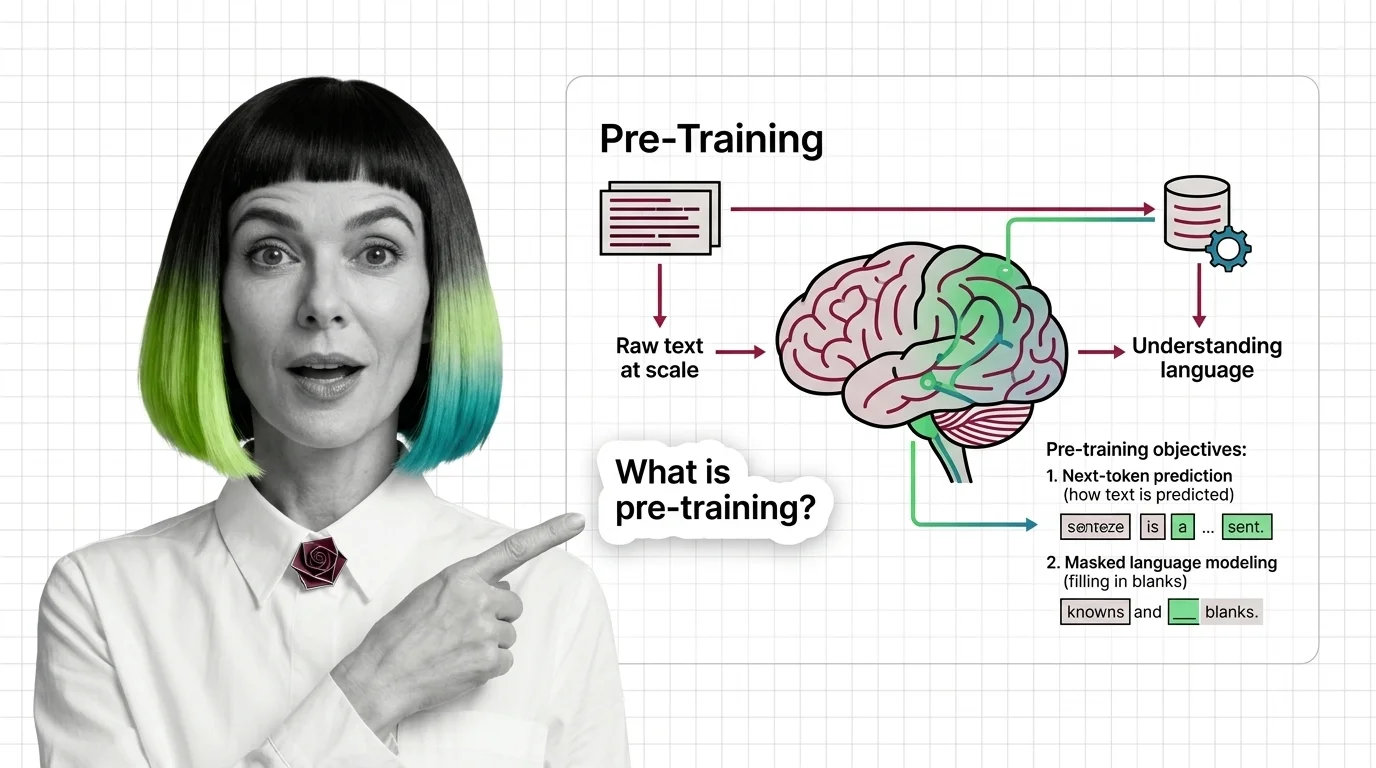
What Is Pre-Training and How LLMs Learn Language from Raw Text at Scale
Pre-training teaches LLMs to predict text, not understand it — yet prediction at scale produces something that resembles …
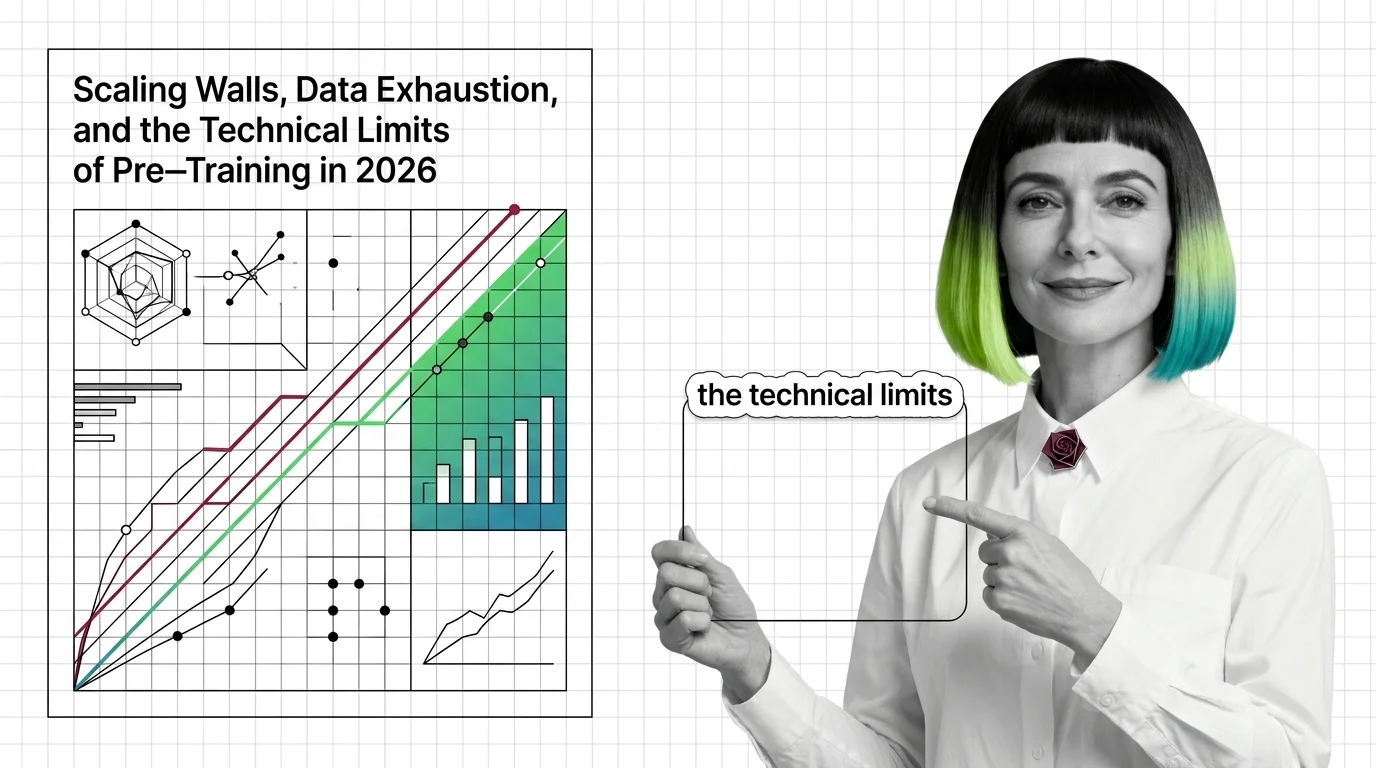
Scaling Walls, Data Exhaustion, and the Technical Limits of Pre-Training in 2026
Pre-training compute grows 4-5x yearly while data runs out. Learn the three scaling walls — cost, data exhaustion, and …
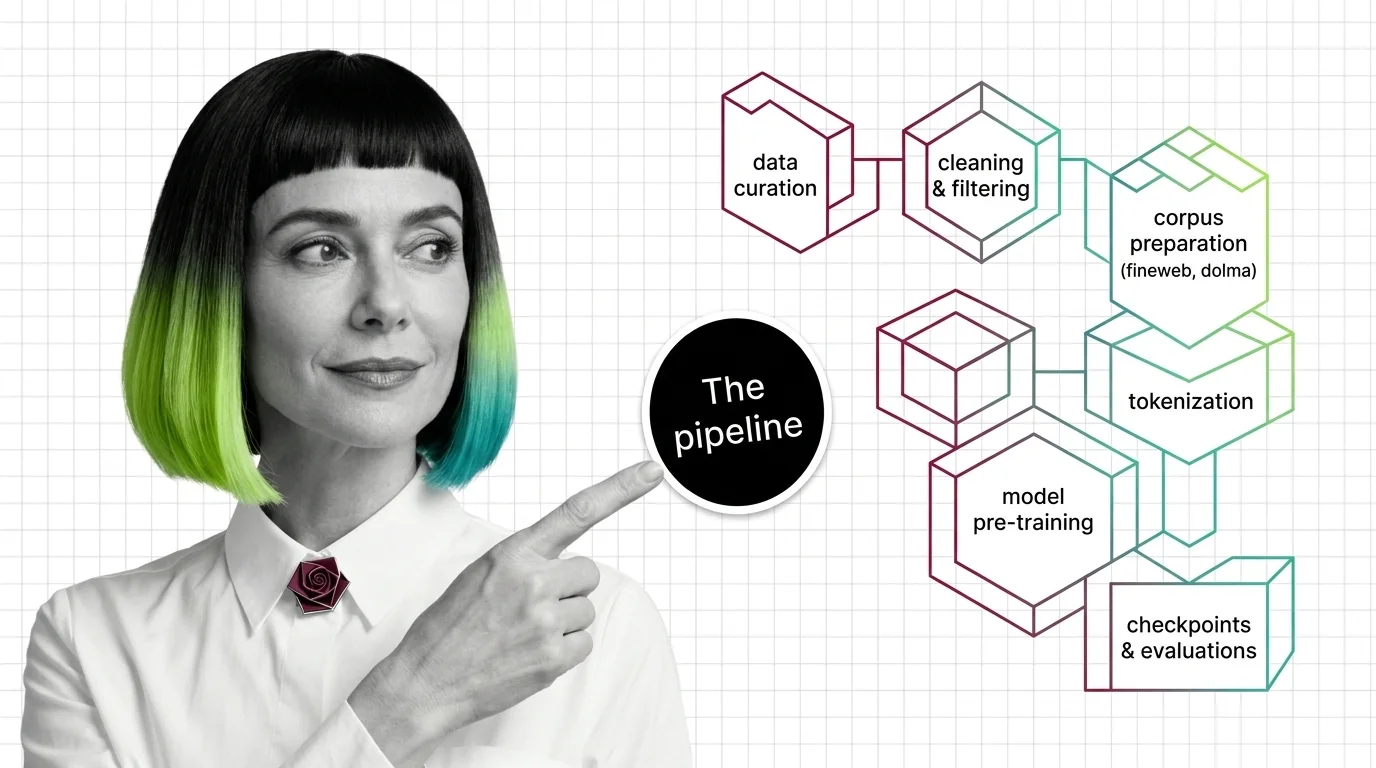
From Data Curation to Checkpoints: The Building Blocks of a Modern Pre-Training Pipeline
Pre-training pipelines run from data curation to checkpointing. Learn how FineWeb, Dolma, and Megatron-Core build the …

Catastrophic Forgetting, Overfitting, and the Hard Technical Limits of LLM Fine-Tuning
Fine-tuning can destroy what your LLM already knows. Learn why catastrophic forgetting and overfitting define the hard …
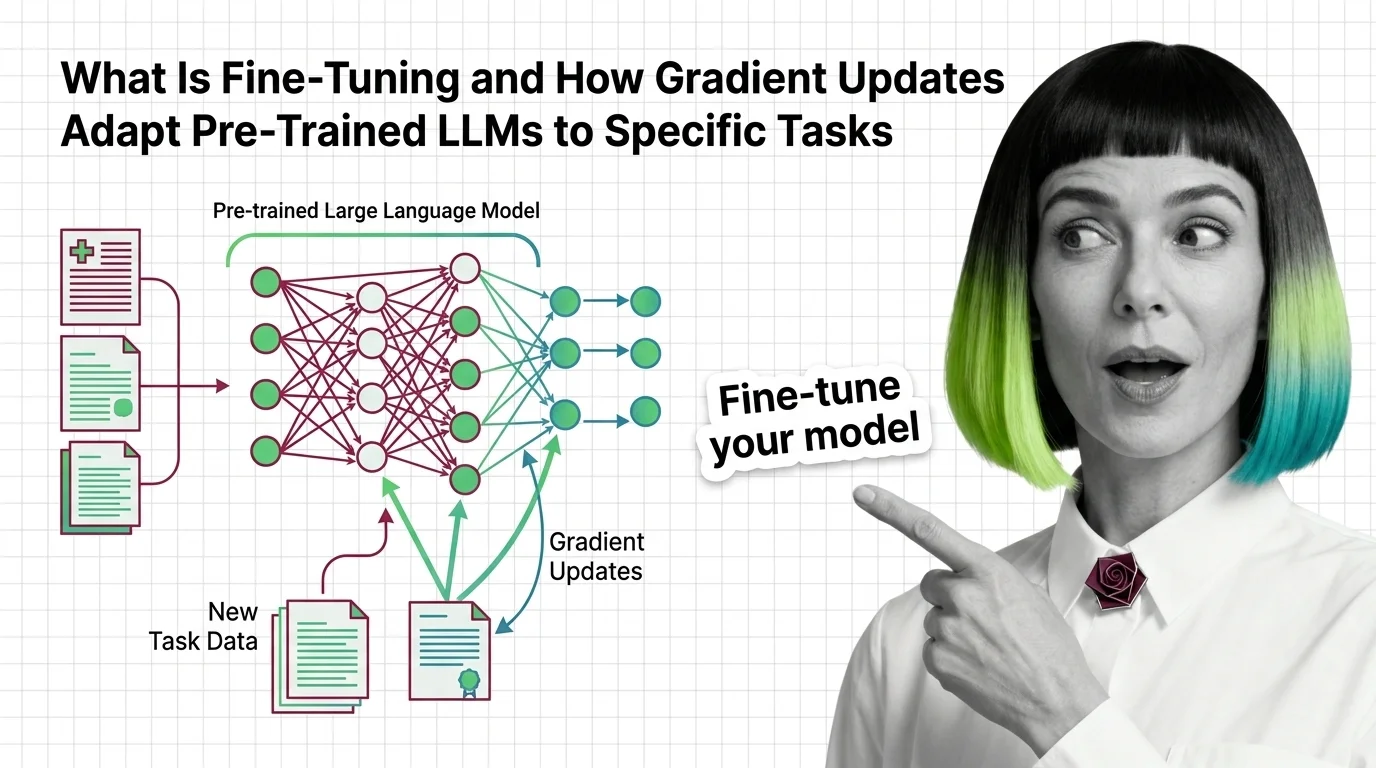
What Is Fine-Tuning and How Gradient Updates Adapt Pre-Trained LLMs to Specific Tasks
Fine-tuning adapts pre-trained LLMs by updating weights on task-specific data. Learn how gradient descent reshapes model …
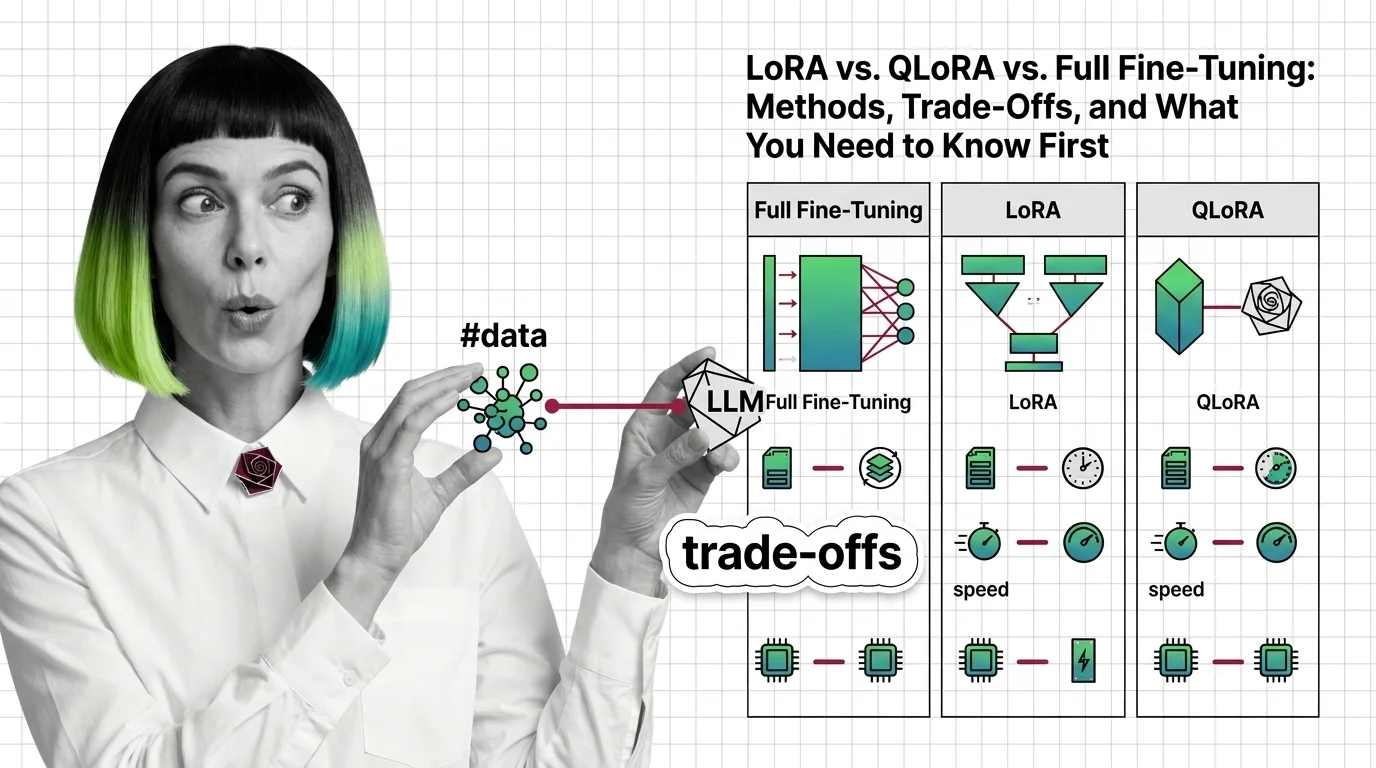
LoRA vs. QLoRA vs. Full Fine-Tuning: Methods, Trade-Offs, and What You Need to Know First
LoRA, QLoRA, and full fine-tuning each change different parts of an LLM. Learn which method fits your GPU budget, data …
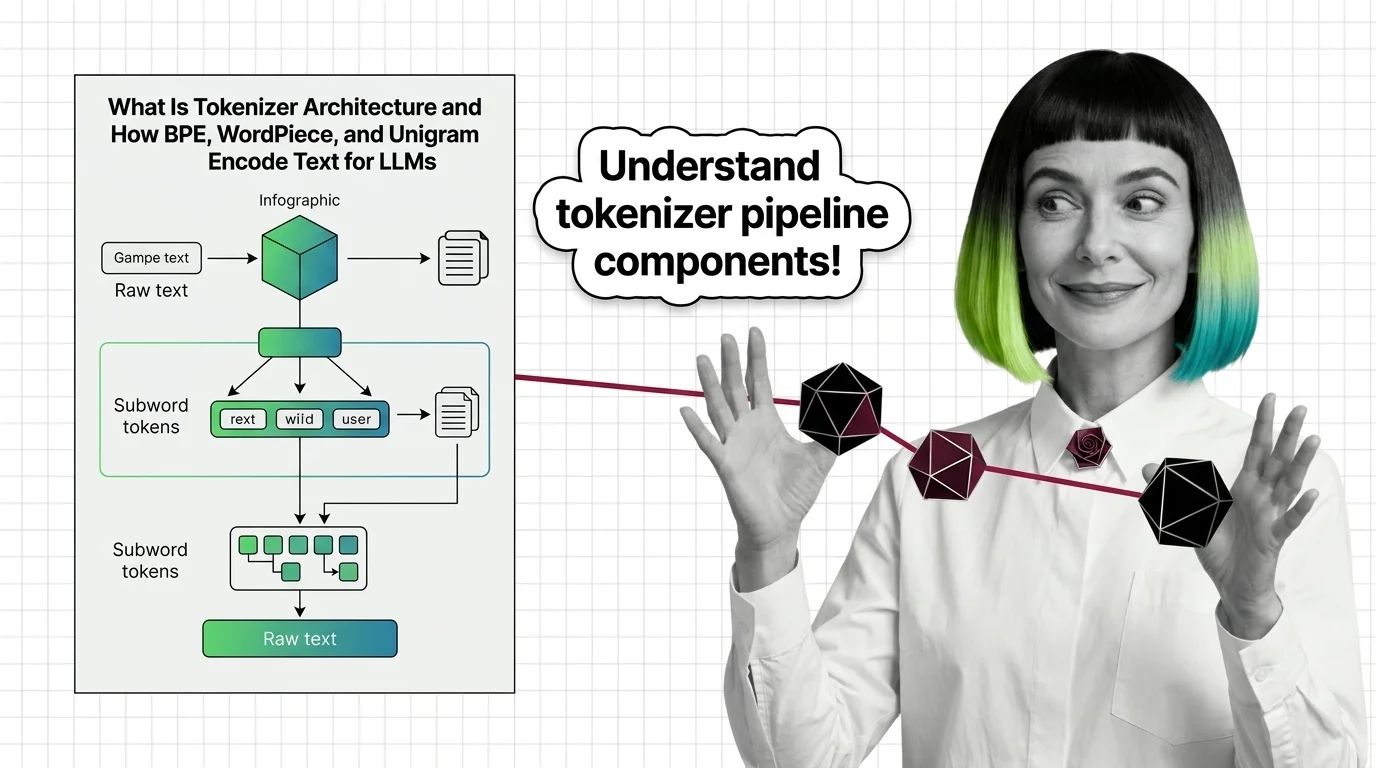
What Is Tokenizer Architecture and How BPE, WordPiece, and Unigram Encode Text for LLMs
Tokenizer architecture determines how LLMs read text. Learn how BPE, WordPiece, and Unigram split text into subword …

What Is an Embedding and How Neural Networks Encode Meaning into Vectors
Embeddings turn words into vector coordinates where distance equals meaning. Learn the geometry, training mechanics, and …
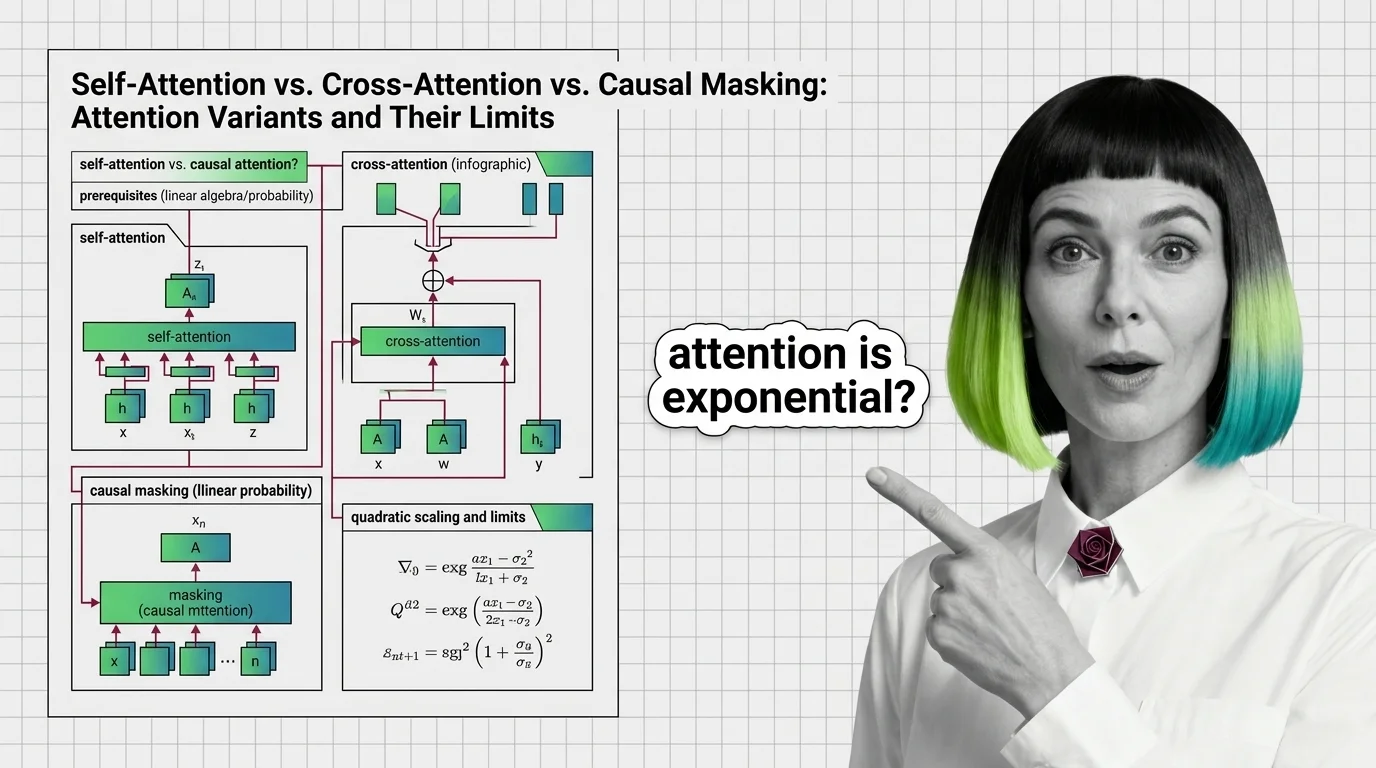
Self-Attention vs. Cross-Attention vs. Causal Masking: Attention Variants and Their Limits
Self-attention, cross-attention, and causal masking solve different problems inside transformers. Learn the math, …
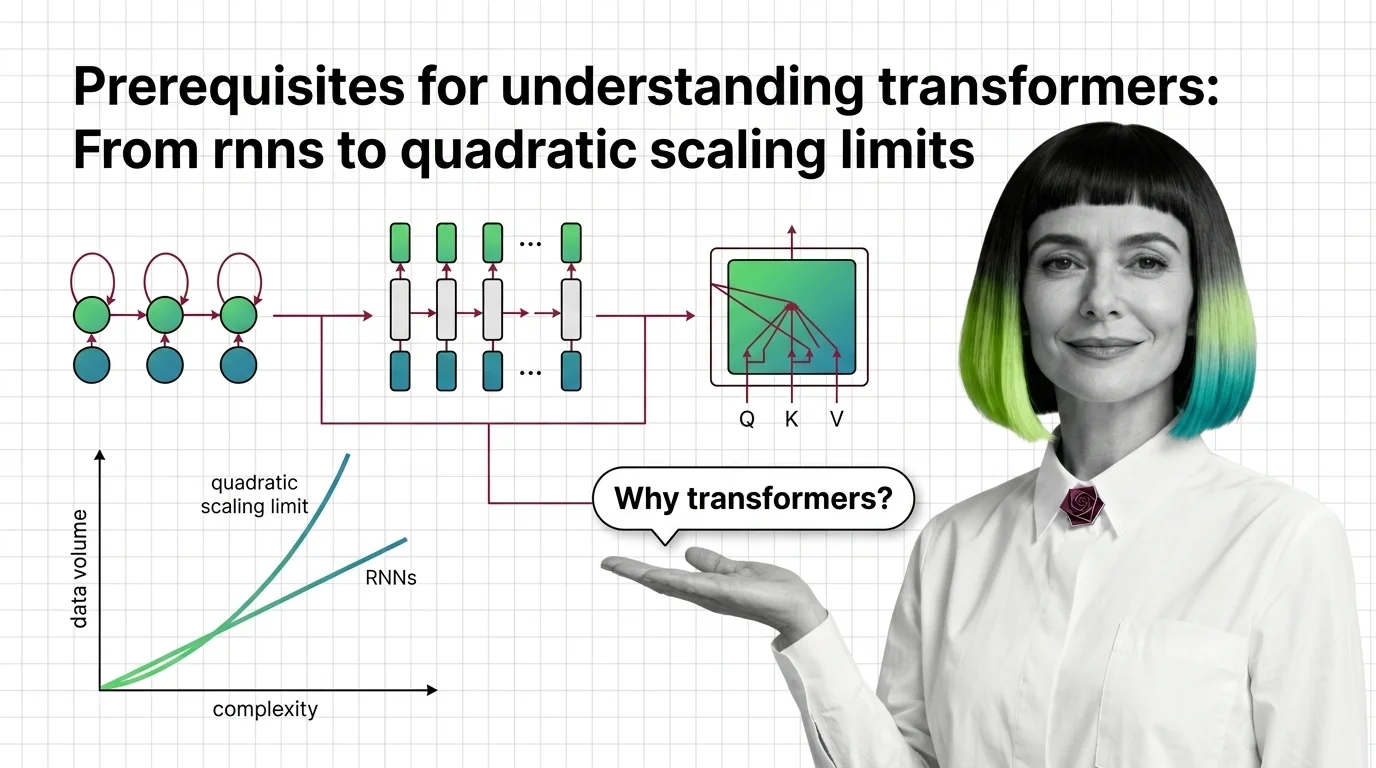
Prerequisites for Understanding Transformers: From RNNs to Quadratic Scaling Limits
Understand why RNNs failed, how transformer self-attention trades parallelism for quadratic cost, and what these …
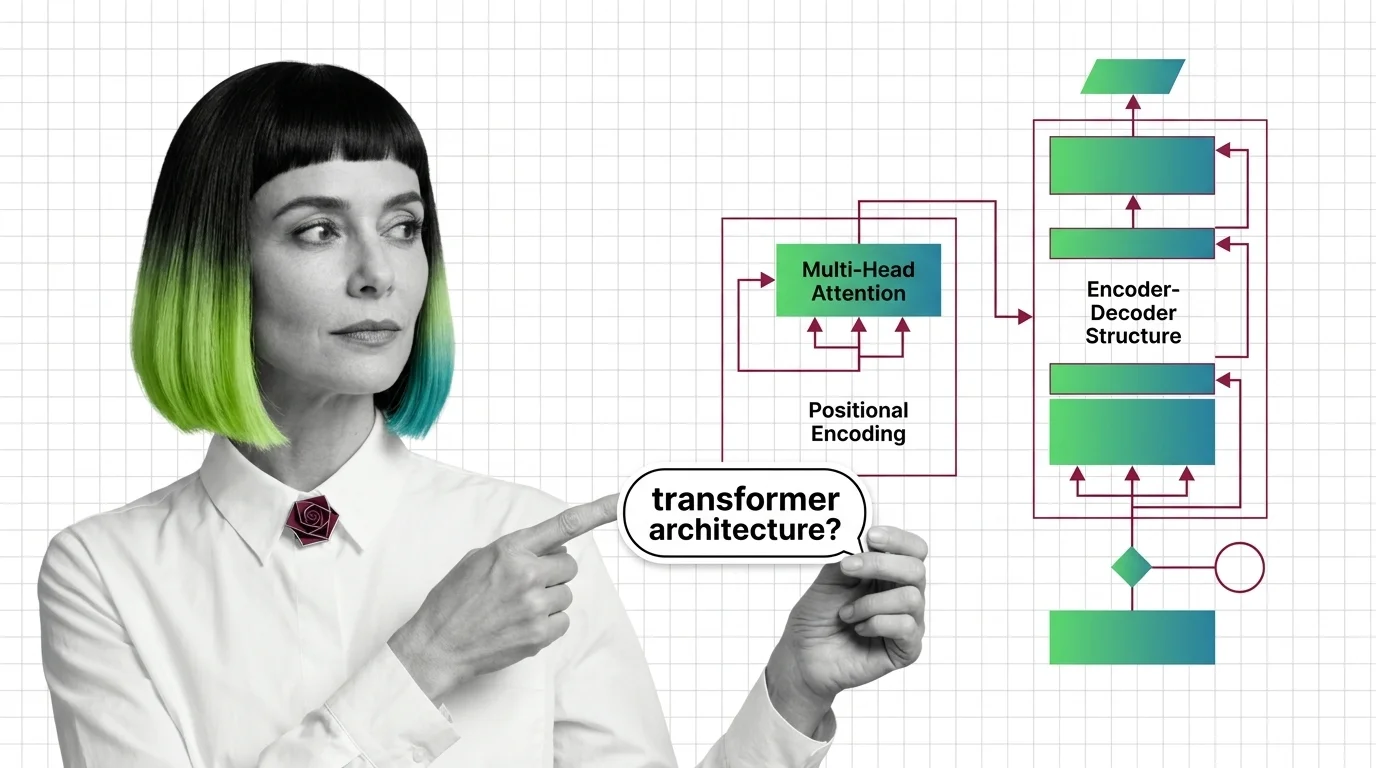
Multi-Head Attention, Positional Encoding, and the Encoder-Decoder Structure Explained
Multi-head attention, positional encoding, and encoder-decoder structure: the three mechanisms inside every transformer, …

Glitch Tokens, Fertility Gaps, and the Unsolved Technical Limits of Subword Tokenization
BPE tokenizers produce glitch tokens and penalize non-Latin scripts with fertility gaps. Learn where the math breaks — …
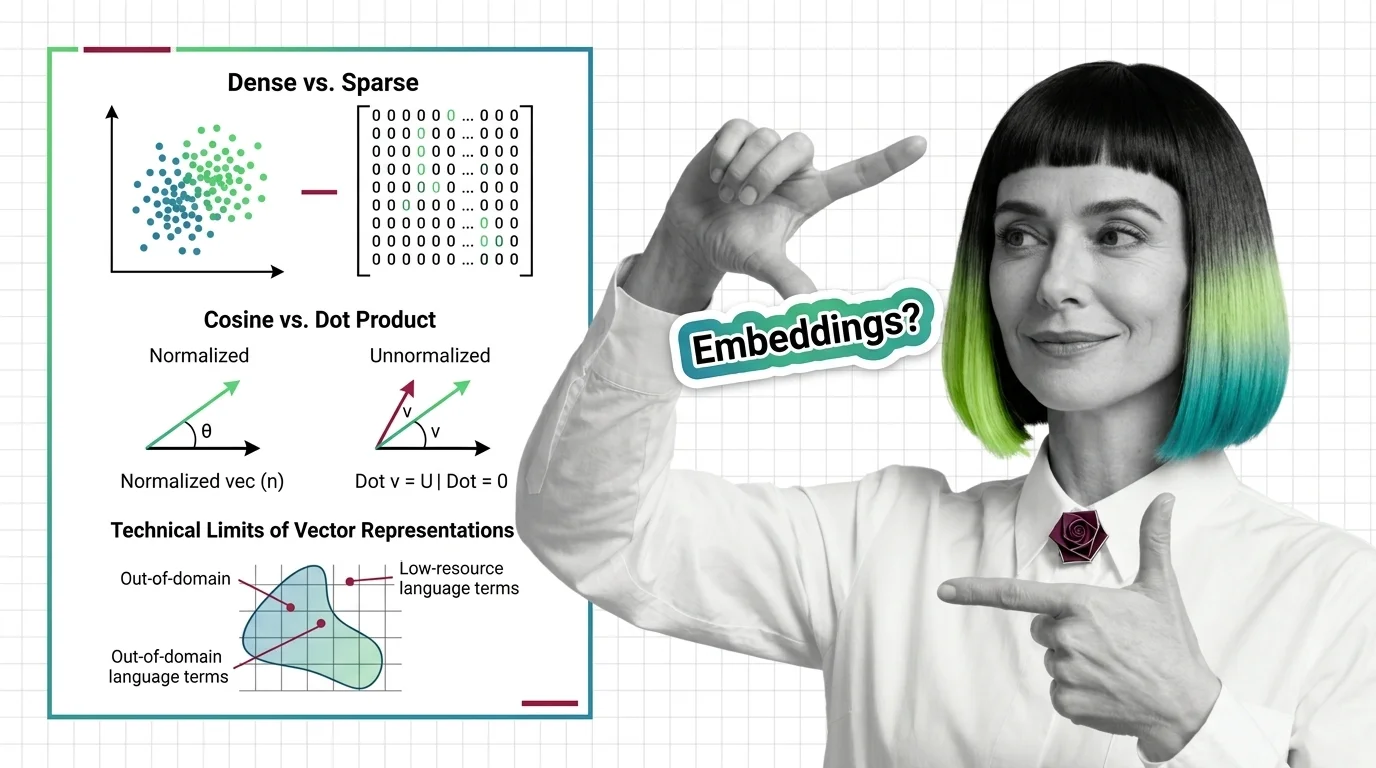
Dense vs. Sparse, Cosine vs. Dot Product, and the Technical Limits of Vector Representations
Dense vs. sparse embeddings encode meaning differently. Learn how cosine similarity, dot product, and Euclidean distance …
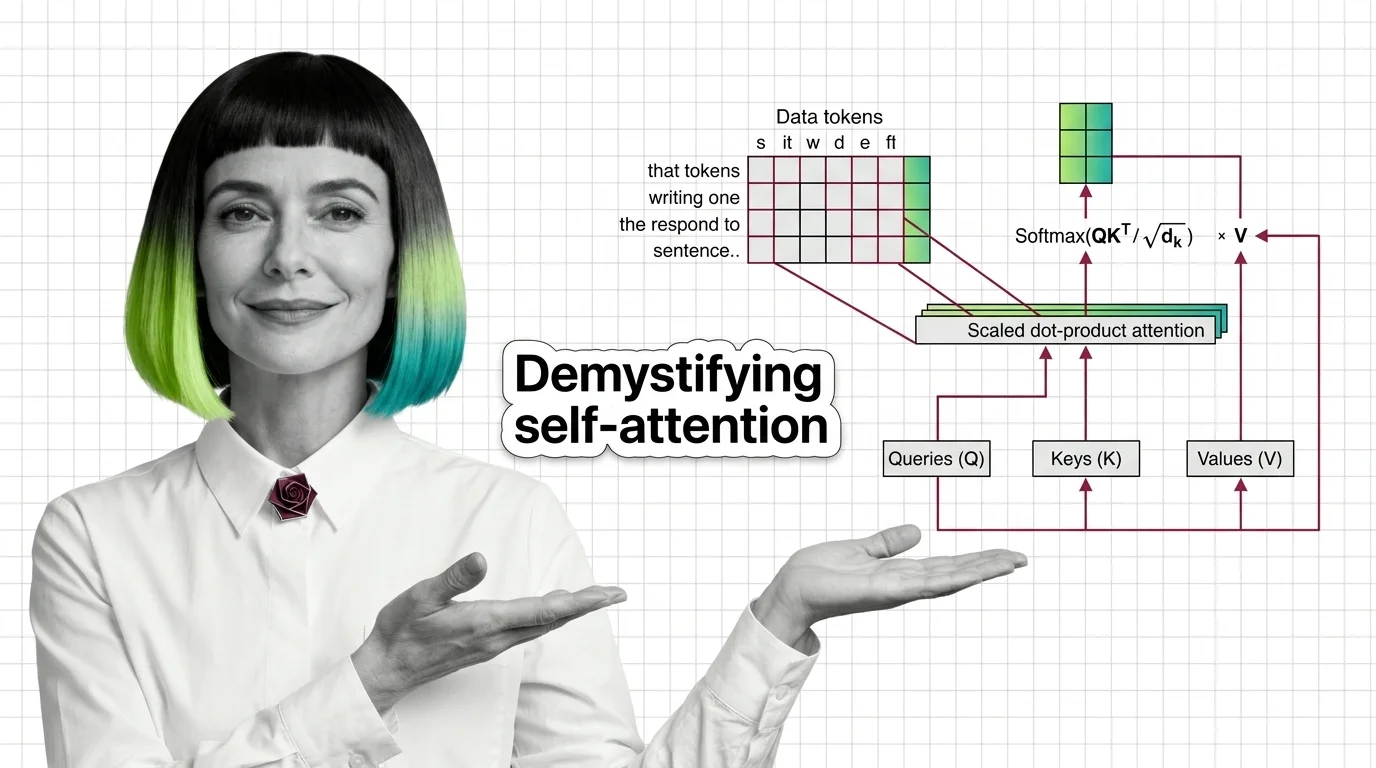
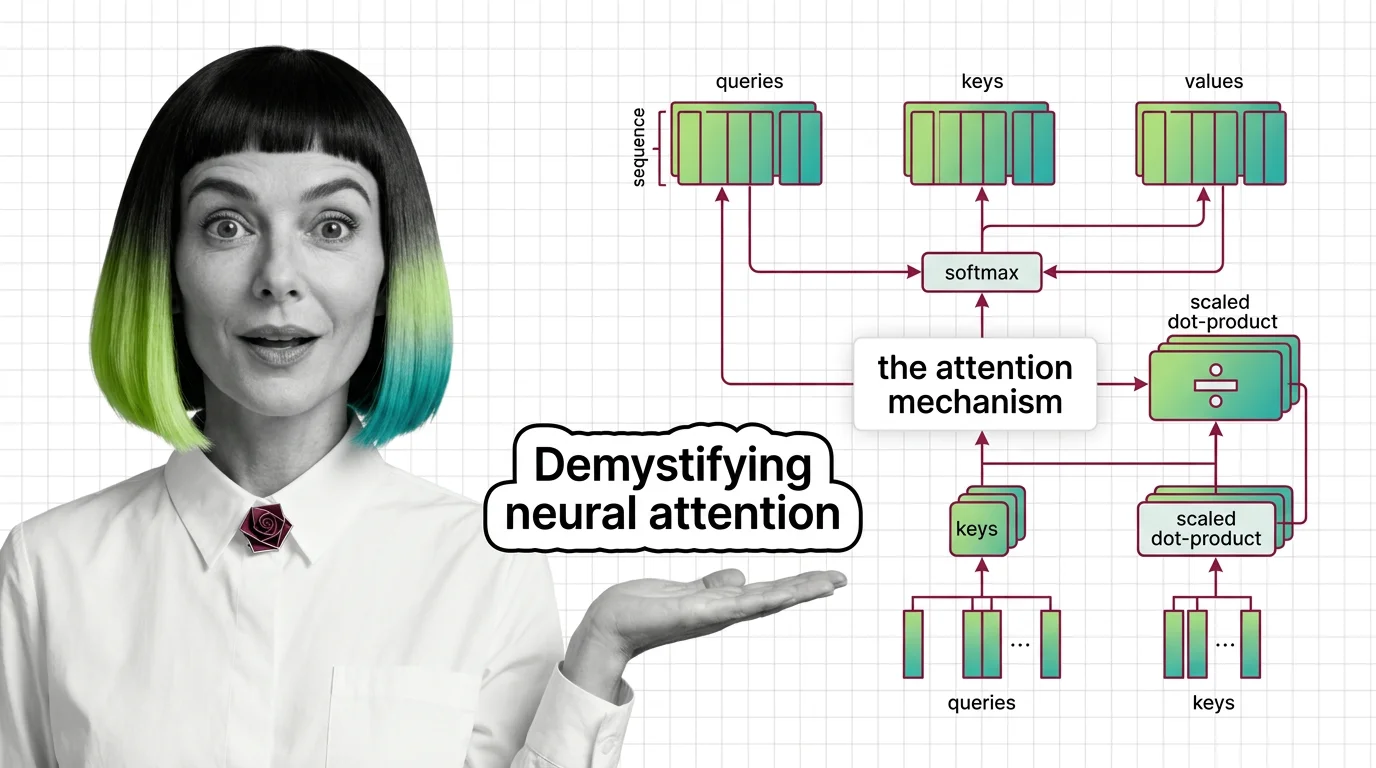
Attention Mechanism Explained: How Queries, Keys, and Values Power Modern AI
Attention mechanisms let neural networks weigh input relevance dynamically. Learn how queries, keys, and values compute …
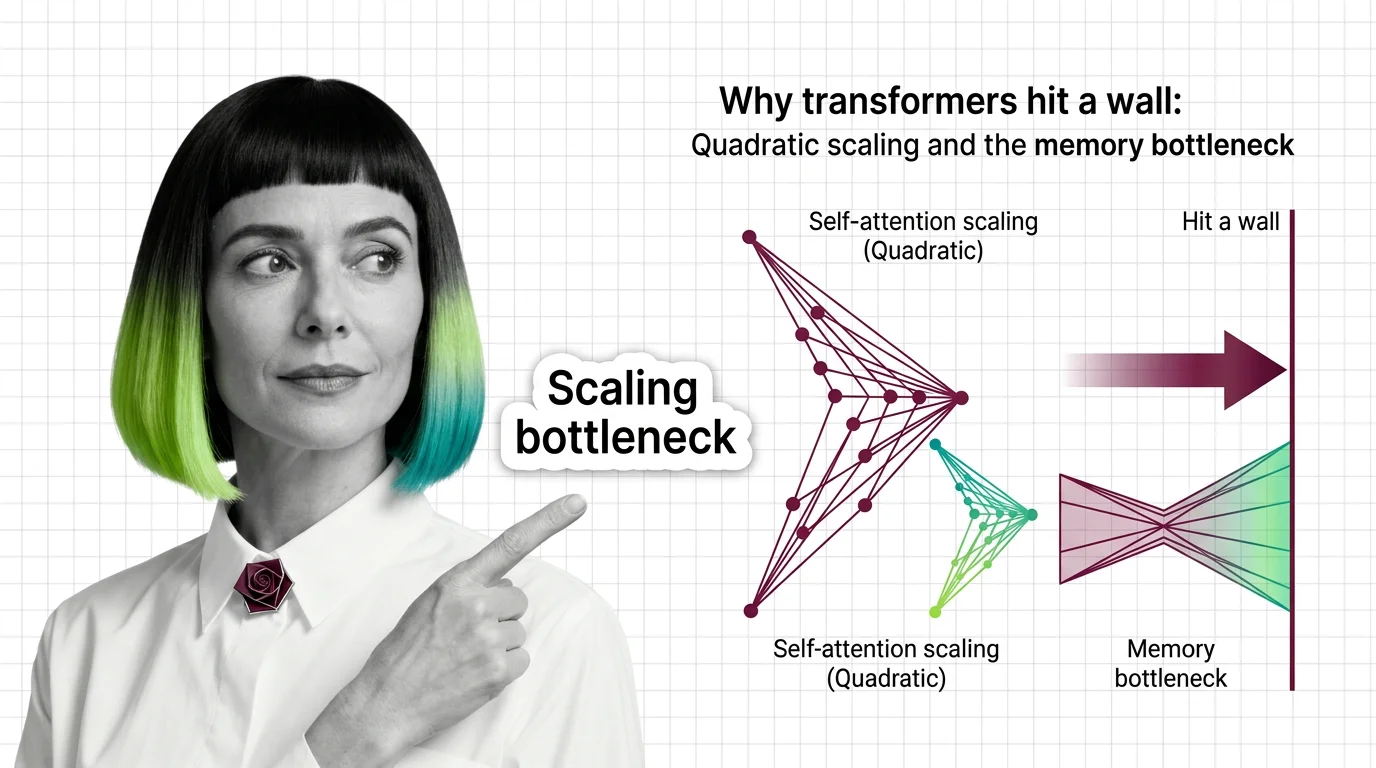
Why Transformers Hit a Wall: Quadratic Scaling and the Memory Bottleneck
Transformer self-attention scales quadratically with sequence length. Understand the O(n²) memory wall, KV cache costs, …
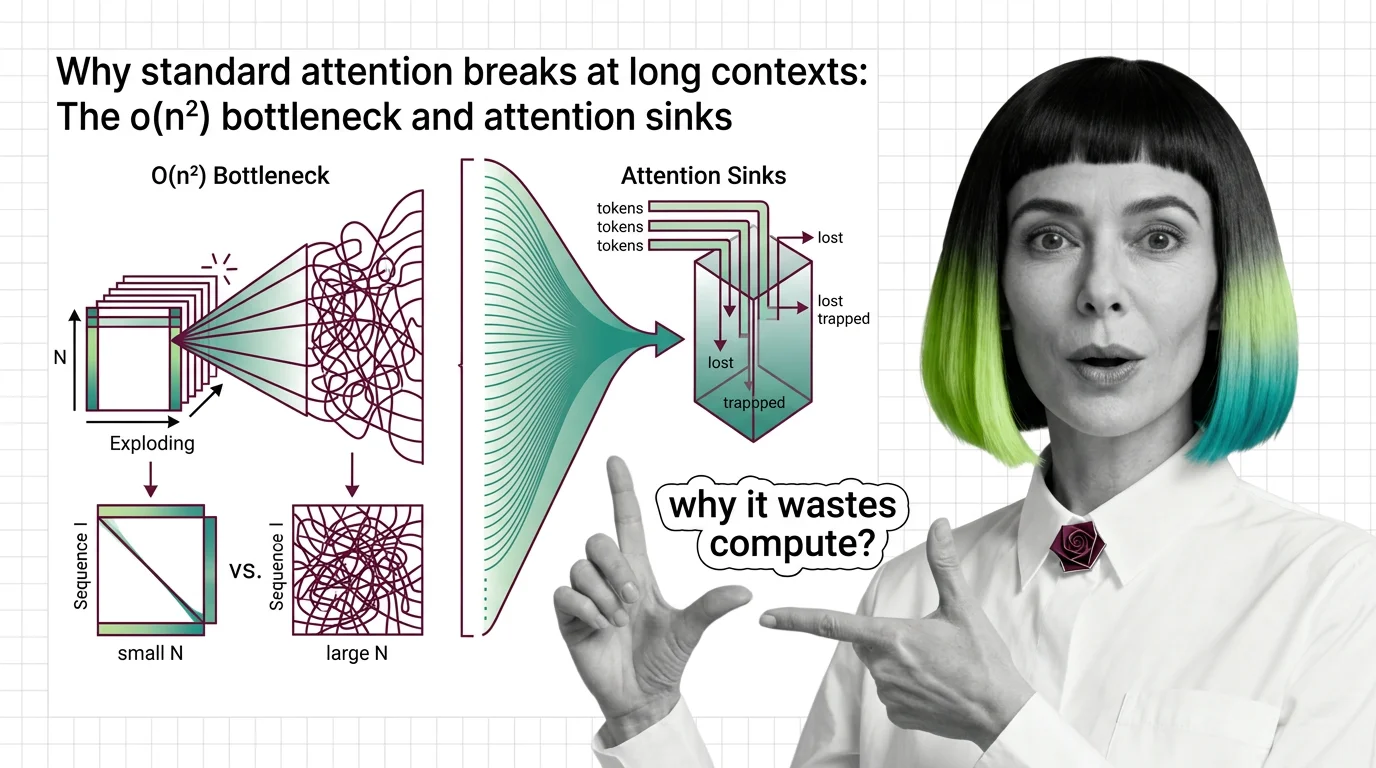
Why Standard Attention Breaks at Long Contexts: The O(n²) Bottleneck and Attention Sinks
Standard attention scales quadratically with sequence length. Learn why O(n²) breaks at long contexts, what attention …
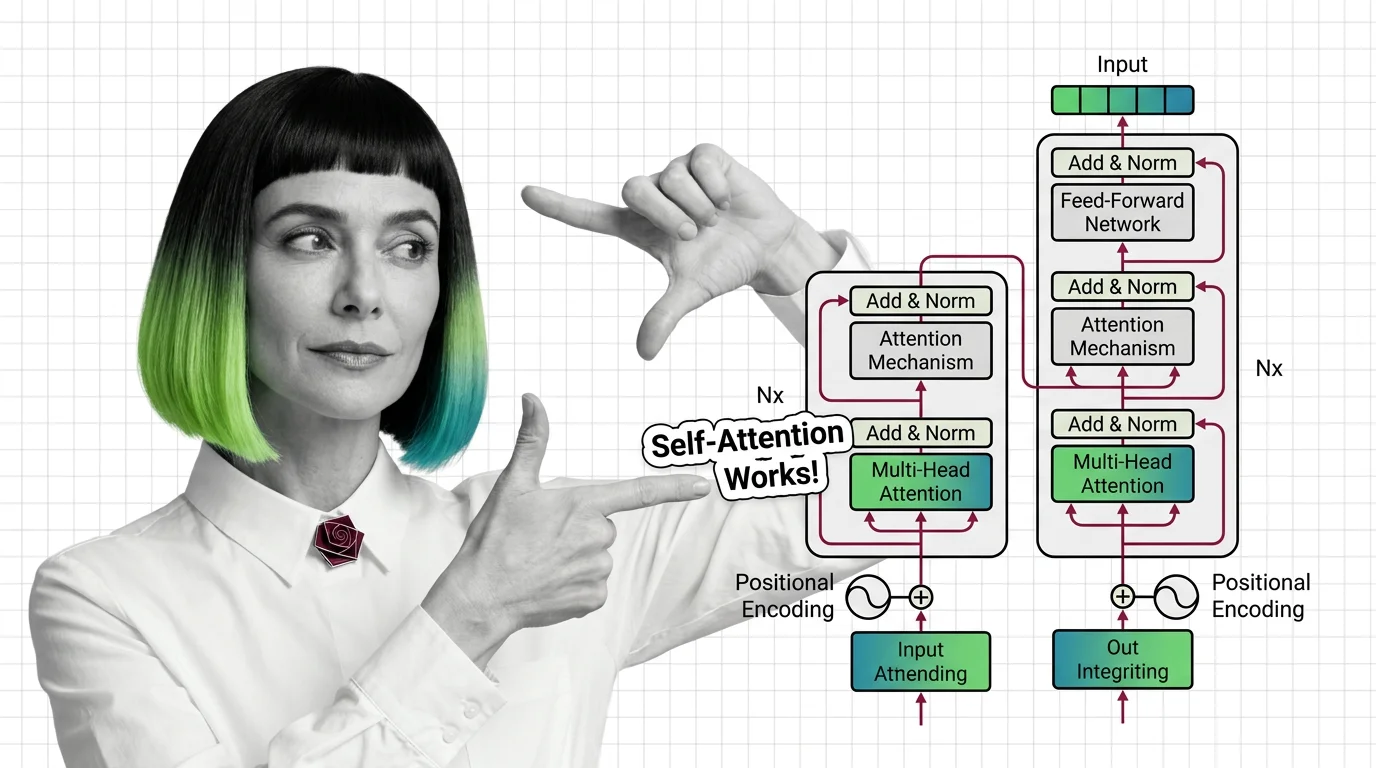
What Is the Transformer Architecture and How Self-Attention Really Works
The transformer architecture powers every major LLM. Learn how self-attention computes token relationships, why …
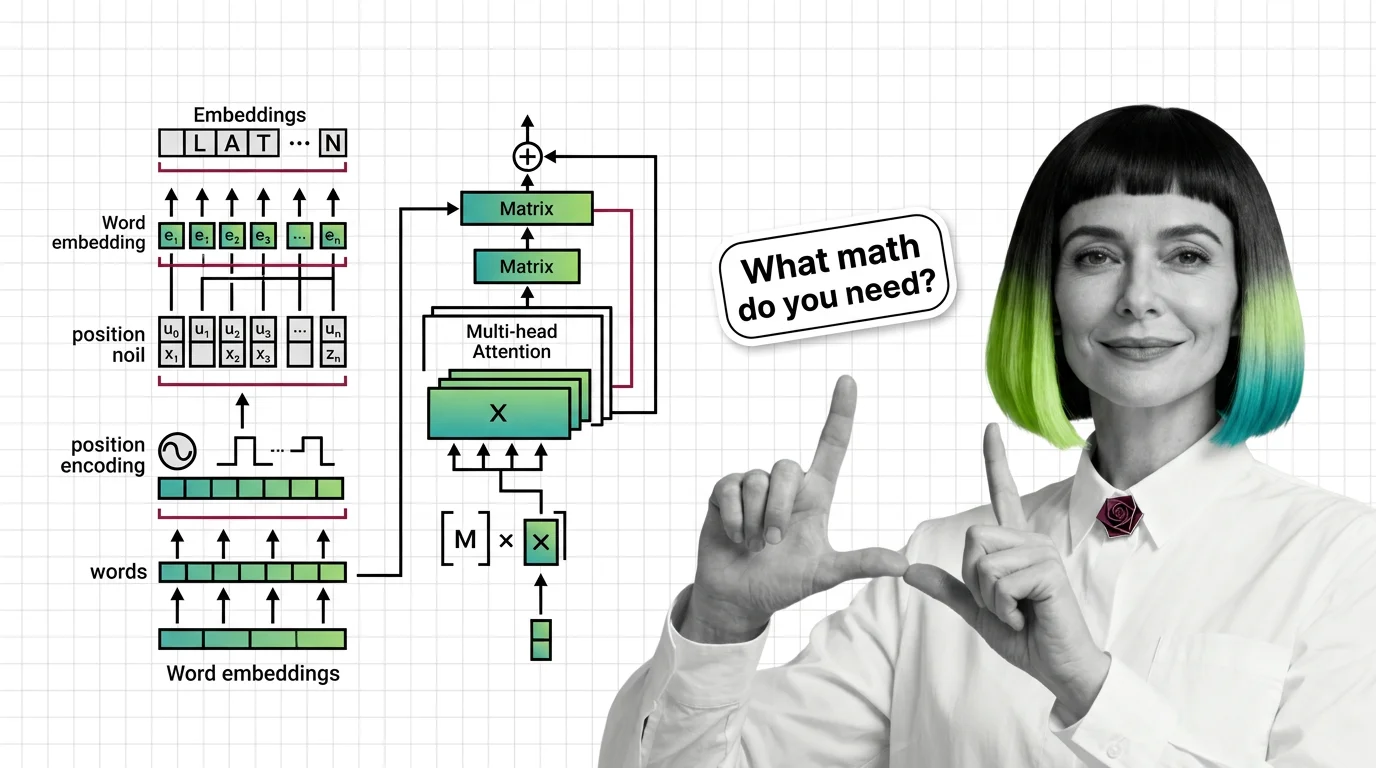
Prerequisites for Understanding Transformers: From Embeddings to Matrix Multiplication
Master the math behind transformers: embeddings, matrix multiplication, positional encoding, and multi-head attention …
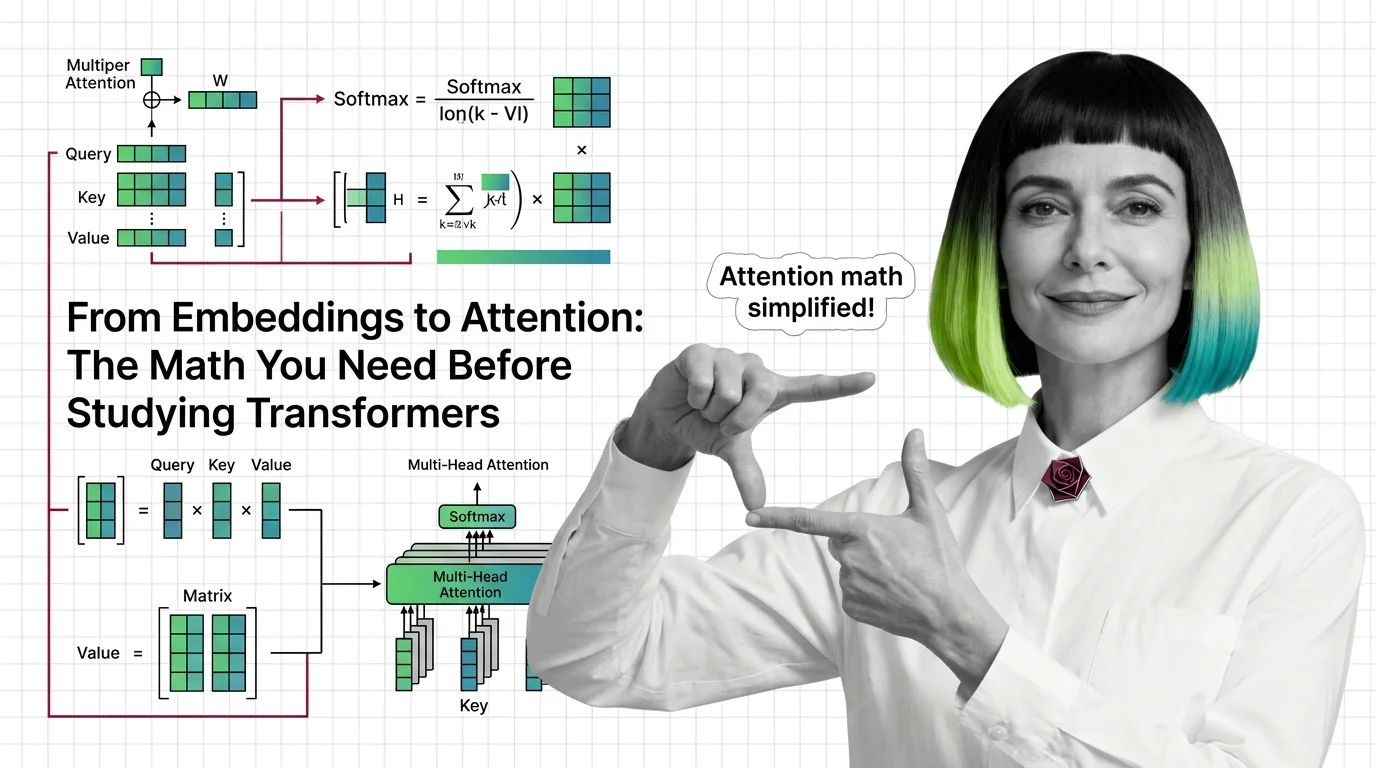
From Embeddings to Attention: The Math You Need Before Studying Transformers
Master the math behind attention mechanisms — dot products, softmax, QKV matrices, and multi-head projections — before …
Attention Mechanism: Scaled Dot-Product, Self vs Cross
Transformers use weighted averaging, not human-like focus: scaled dot-product, self-attention vs cross-attention, and …