LLM Foundations
Core mechanics of large language models — training, inference, tokenization, and the mathematics of next-token prediction.
- Home /
- AI Principles /
- LLM Foundations
Prompt Engineering for Image Generation: How Diffusion Models Read Text
Image prompts steer probability, not pixels. Learn how diffusion models, cross-attention, and CFG turn text into images …
Negative Prompts, Weights, Seeds: Image Prompting Limits 2026
Negative prompts and weight syntax aren't universal — and seed reproducibility breaks across model versions. Inside the …
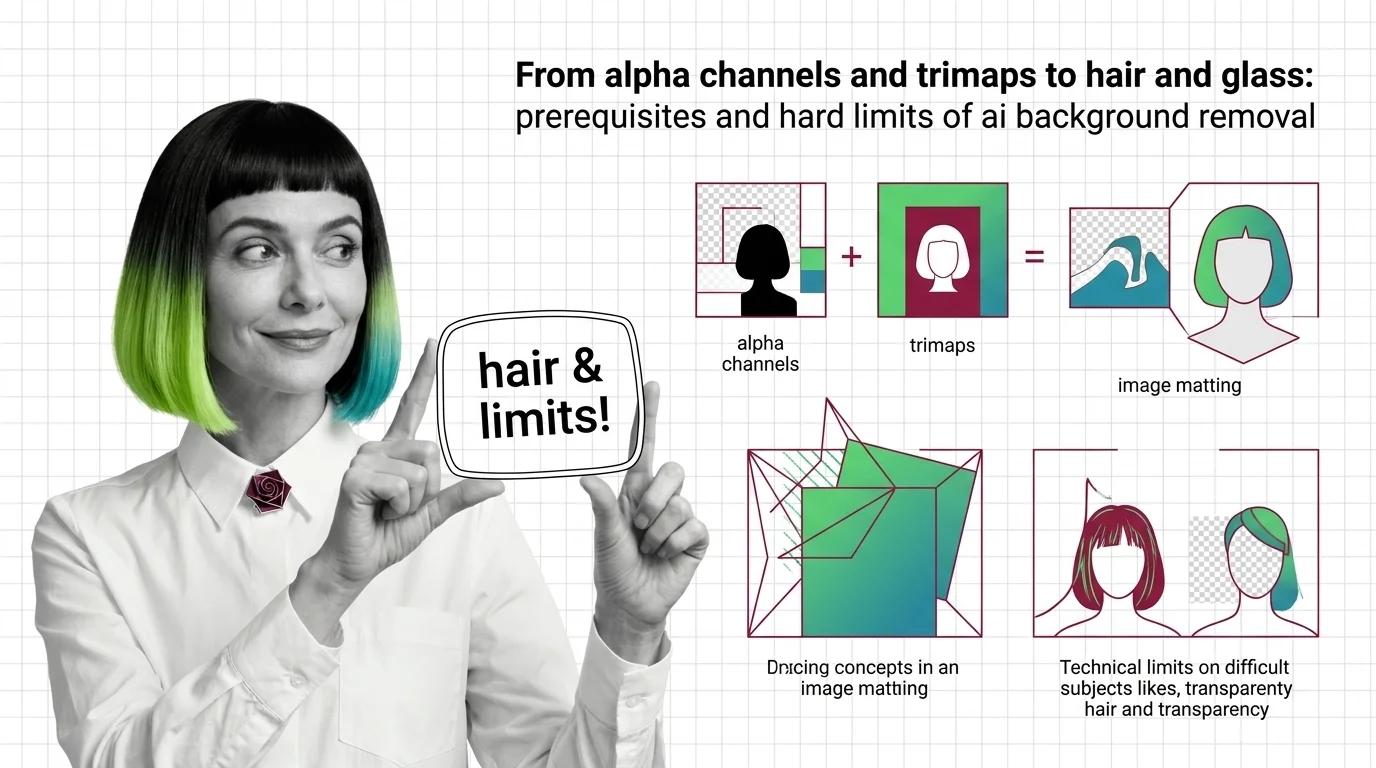
Alpha Channels, Trimaps, and the Hard Limits of AI Background Removal
Background removal is alpha estimation, not subject detection. Learn how trimaps and matting work, and why hair, glass, …
How LoRA Fine-Tunes Diffusion Models for Image Generation
LoRA fine-tunes Stable Diffusion and FLUX without retraining. Learn how rank, alpha, and the BA decomposition turn a …

Why AI Upscalers Hallucinate Faces and Tile Seams at 4K and 8K
AI upscalers don't break at 4K and 8K because of weak hardware. The failures are structural — rooted in diffusion priors …
What Is Image Upscaling and How AI Super-Resolution Reconstructs Detail Beyond the Original Pixels
AI image upscaling doesn't enlarge what was captured — it generates plausible pixels from a learned prior. Learn how GAN …
Training Image LoRAs: Diffusion Math, Rank-Alpha, and VRAM Limits
Image LoRAs retarget diffusion models with small adapter files. Learn the rank-alpha math, VRAM ranges from SD 1.5 to …
From RRDB Blocks to Diffusion Priors: Inside Modern AI Upscalers
How modern AI upscalers are built — from ESRGAN's RRDB blocks and Real-ESRGAN to SUPIR's diffusion prior, plus the …
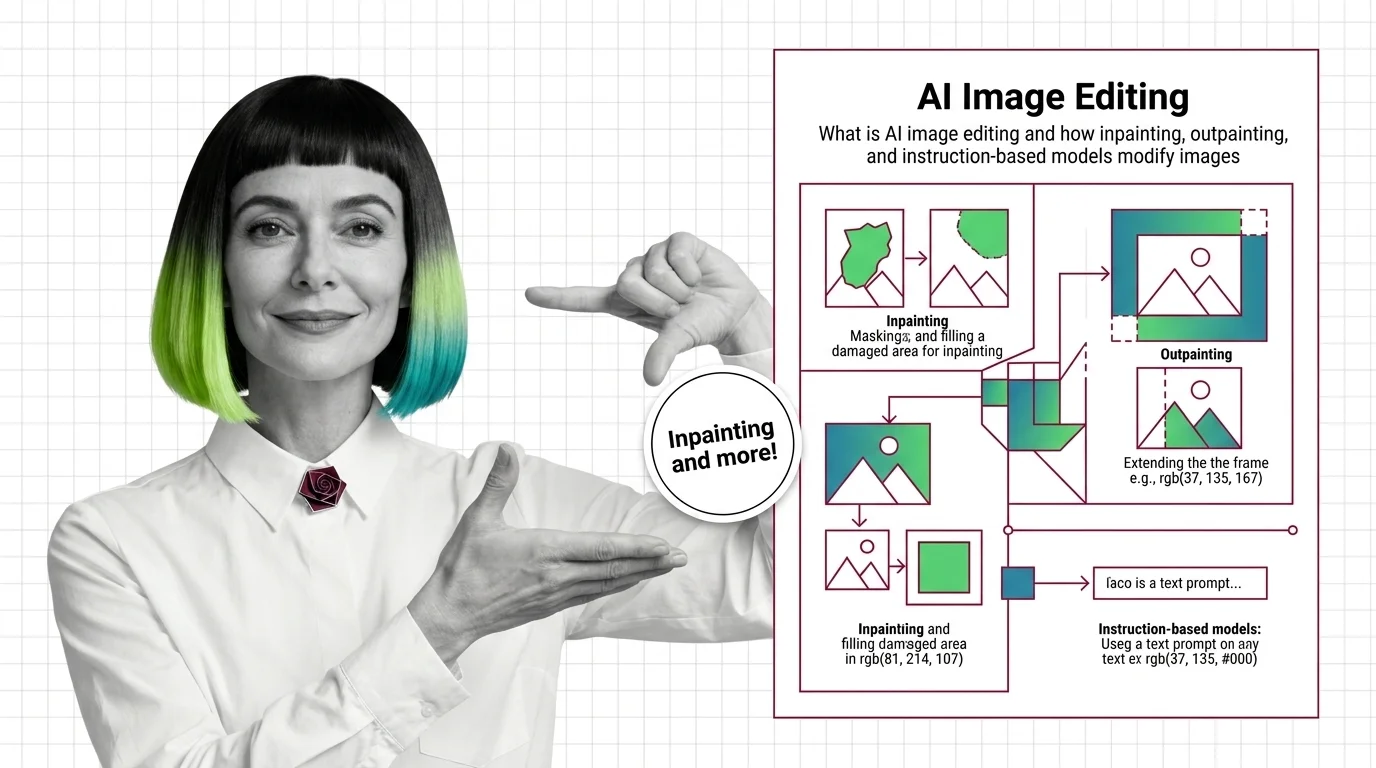
What Is AI Image Editing? Inpainting, Outpainting, Edit Models
AI image editing uses diffusion to modify pixels under a mask or follow text instructions. Learn how inpainting, …

From Diffusion to InstructPix2Pix: AI Image Editing Prerequisites
Before using GPT Image or FLUX, understand diffusion, classifier-free guidance, and why InstructPix2Pix made …

What Is a Neural Network and How It Learns to Generate Language
Neural networks learn language by adjusting millions of weights through backpropagation. Learn how layers, gradients, …
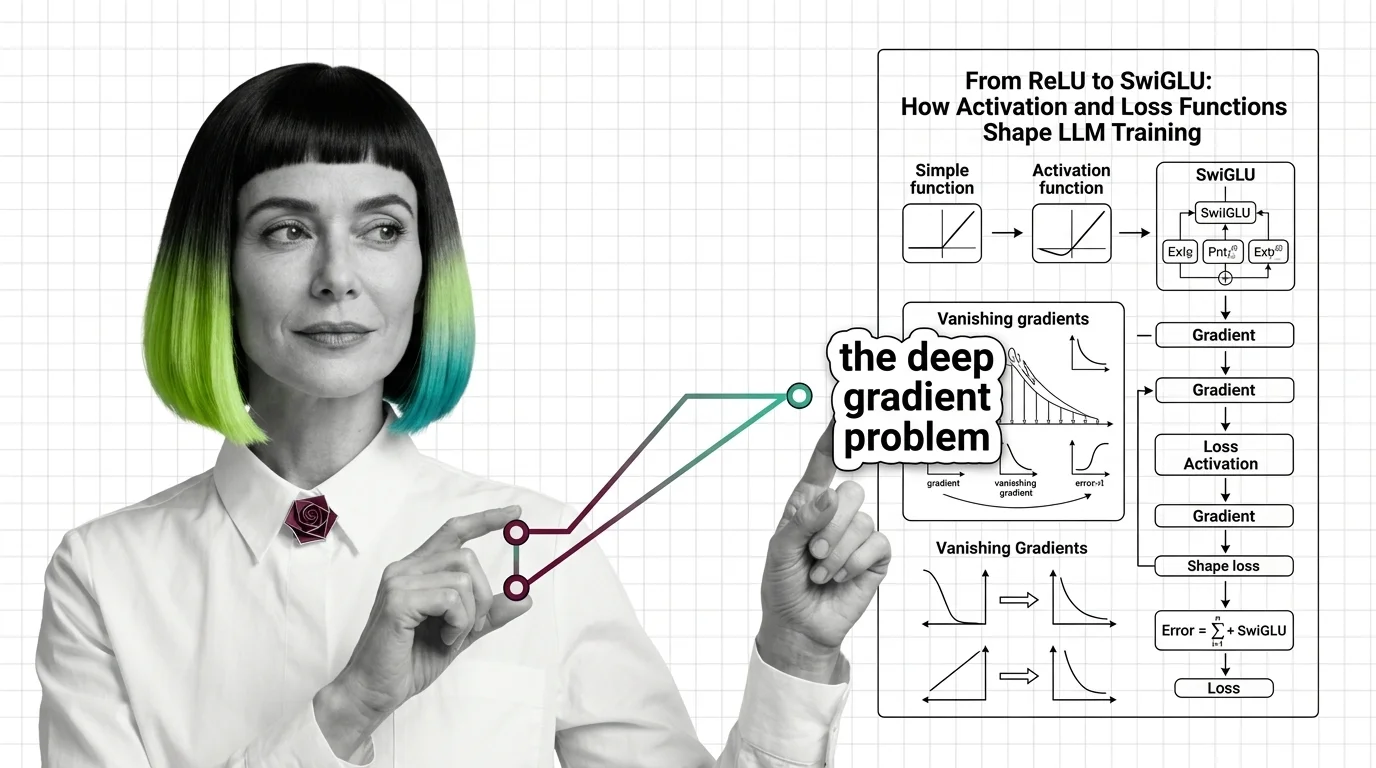
From ReLU to SwiGLU: How Activation and Loss Functions Shape LLM Training
Trace the path from ReLU to SwiGLU and understand how activation functions, cross-entropy loss, and gradient dynamics …
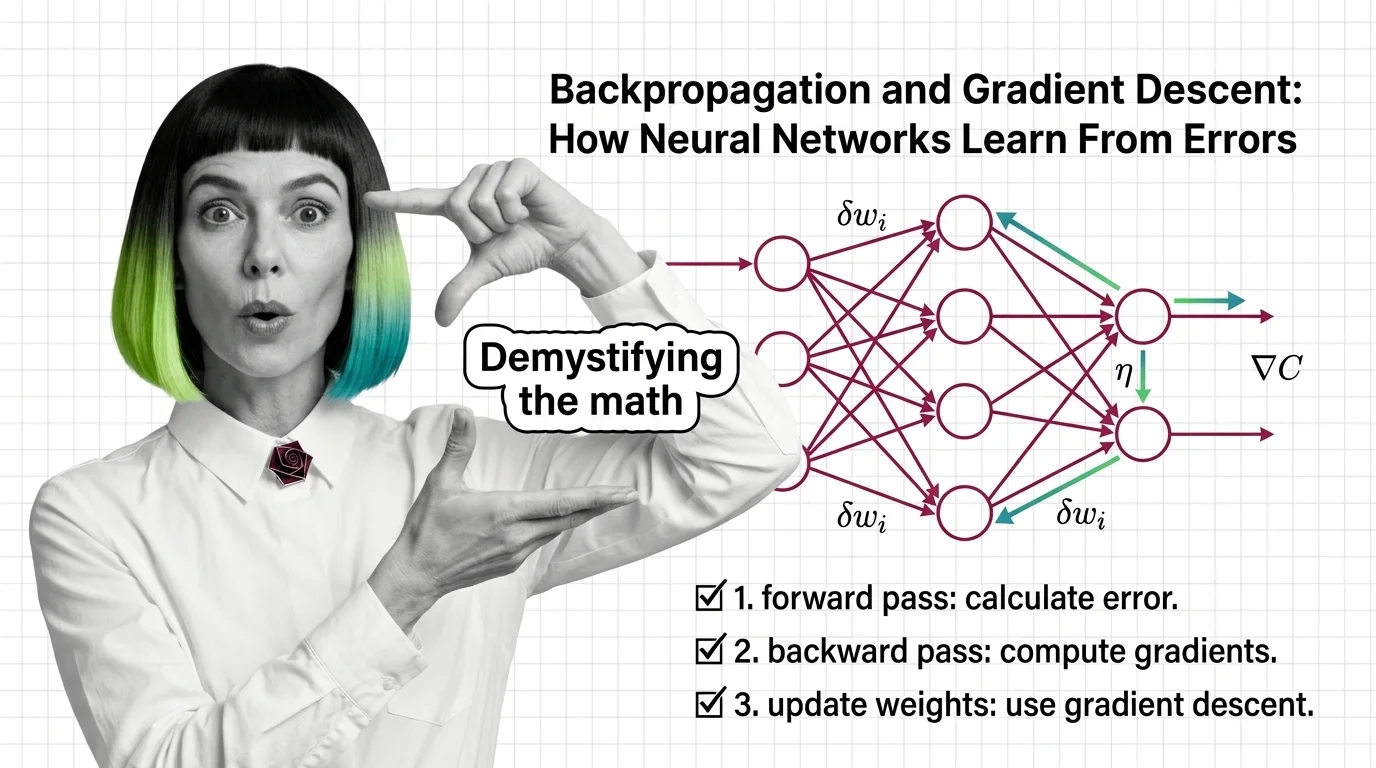
Backpropagation and Gradient Descent: How Neural Networks Learn From Errors
Learn how backpropagation and gradient descent train neural networks by propagating error signals backward through …

What Is Model Evaluation and How Benchmarks, Metrics, and Human Judgment Measure LLM Quality
Model evaluation combines benchmarks, automated metrics, and human judgment to measure LLM quality. Learn why high …

Perplexity, BLEU, ROUGE, and ELO: The Core Metrics Behind LLM Evaluation Explained
Perplexity, BLEU, ROUGE, and Elo measure fundamentally different properties of language models. Learn when each metric …

Benchmark Contamination, Metric Gaming, and the Hard Limits of LLM Evaluation
Benchmark contamination inflates LLM scores while real-world performance lags. Learn why metric gaming and saturated …
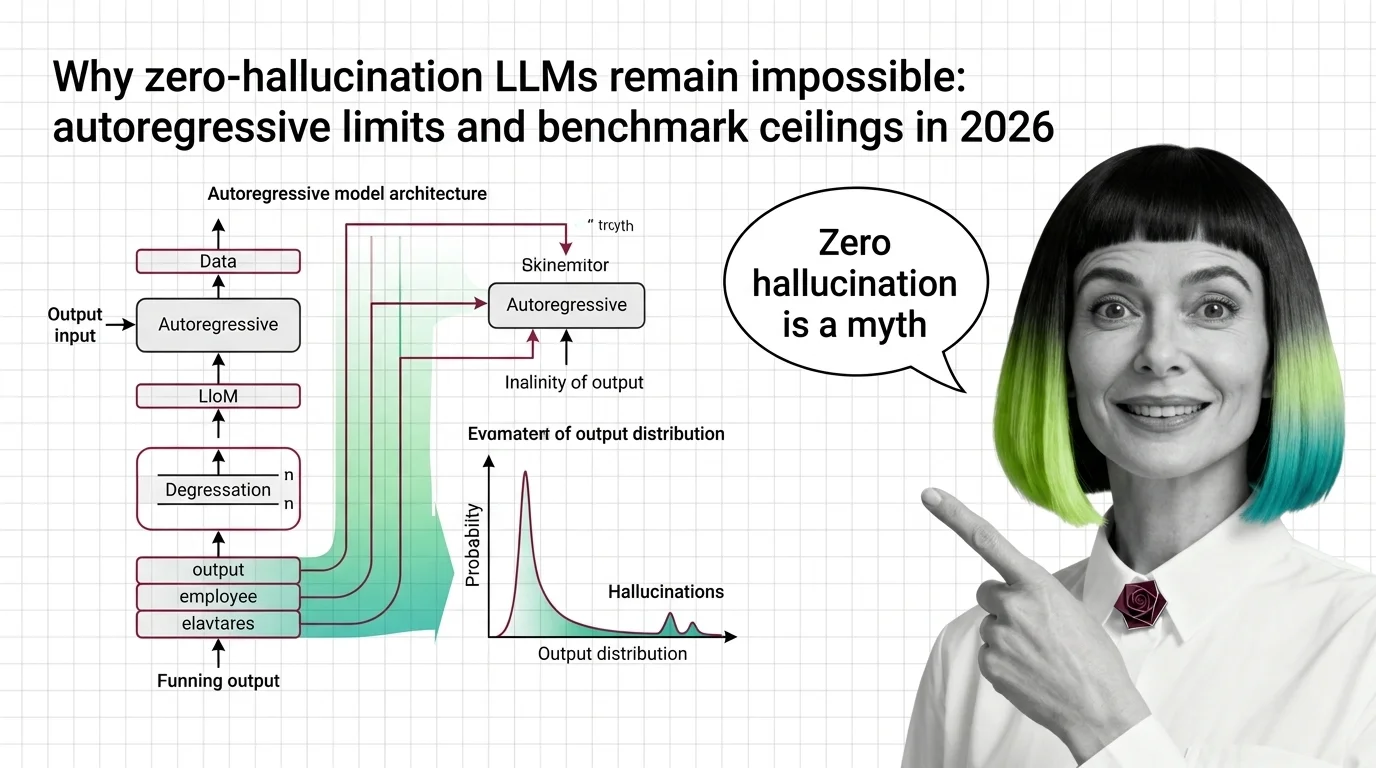
Why Zero-Hallucination LLMs Remain Impossible: Autoregressive Limits and Benchmark Ceilings in 2026
LLM hallucination is mathematically inevitable. Explore the autoregressive limits, benchmark ceilings, and why …

What Is AI Hallucination and How Statistical Next-Token Prediction Creates Confident Falsehoods
AI hallucinations aren't bugs — they emerge from how next-token prediction works. Learn why LLMs produce confident …
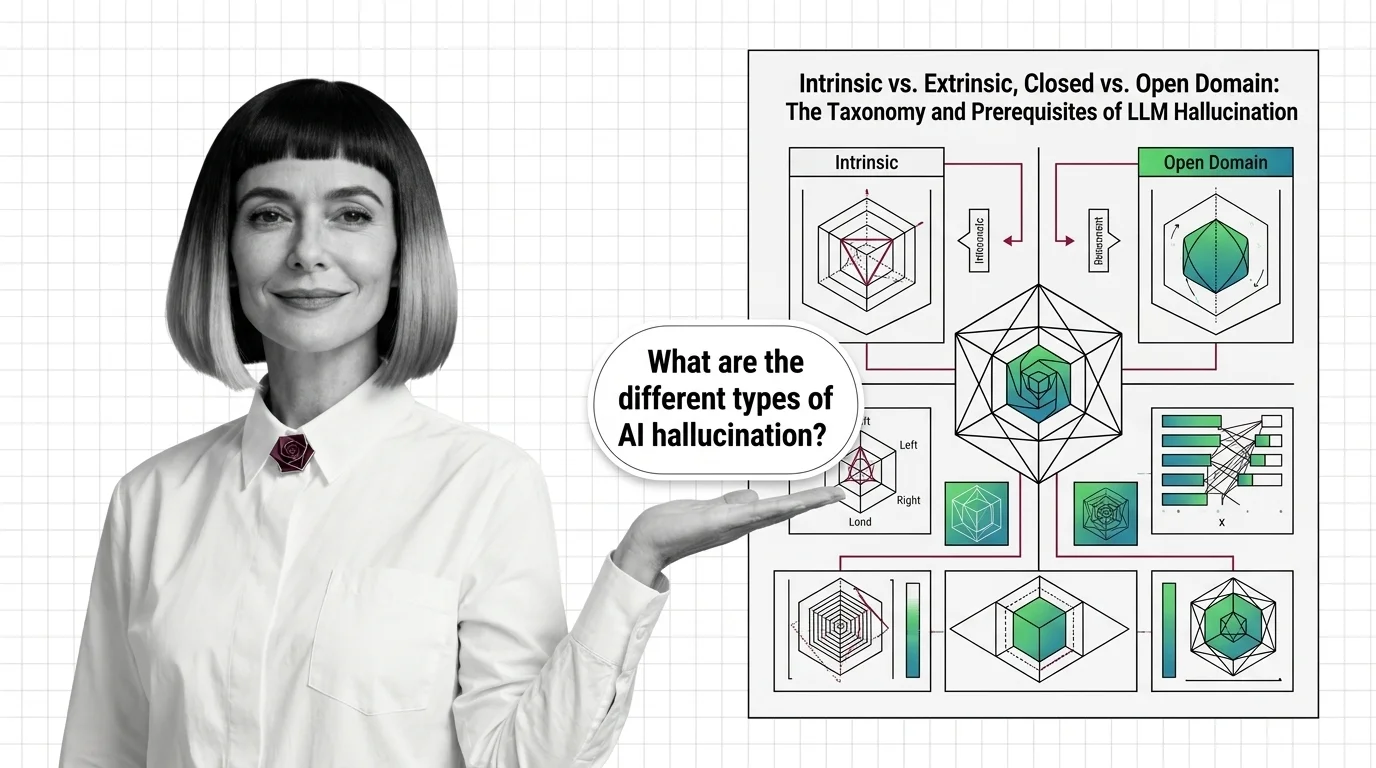
Intrinsic vs. Extrinsic, Closed vs. Open Domain: The Taxonomy and Prerequisites of LLM Hallucination
LLM hallucination isn't one problem — it's four. Learn the intrinsic vs. extrinsic taxonomy, the domain split, and the …
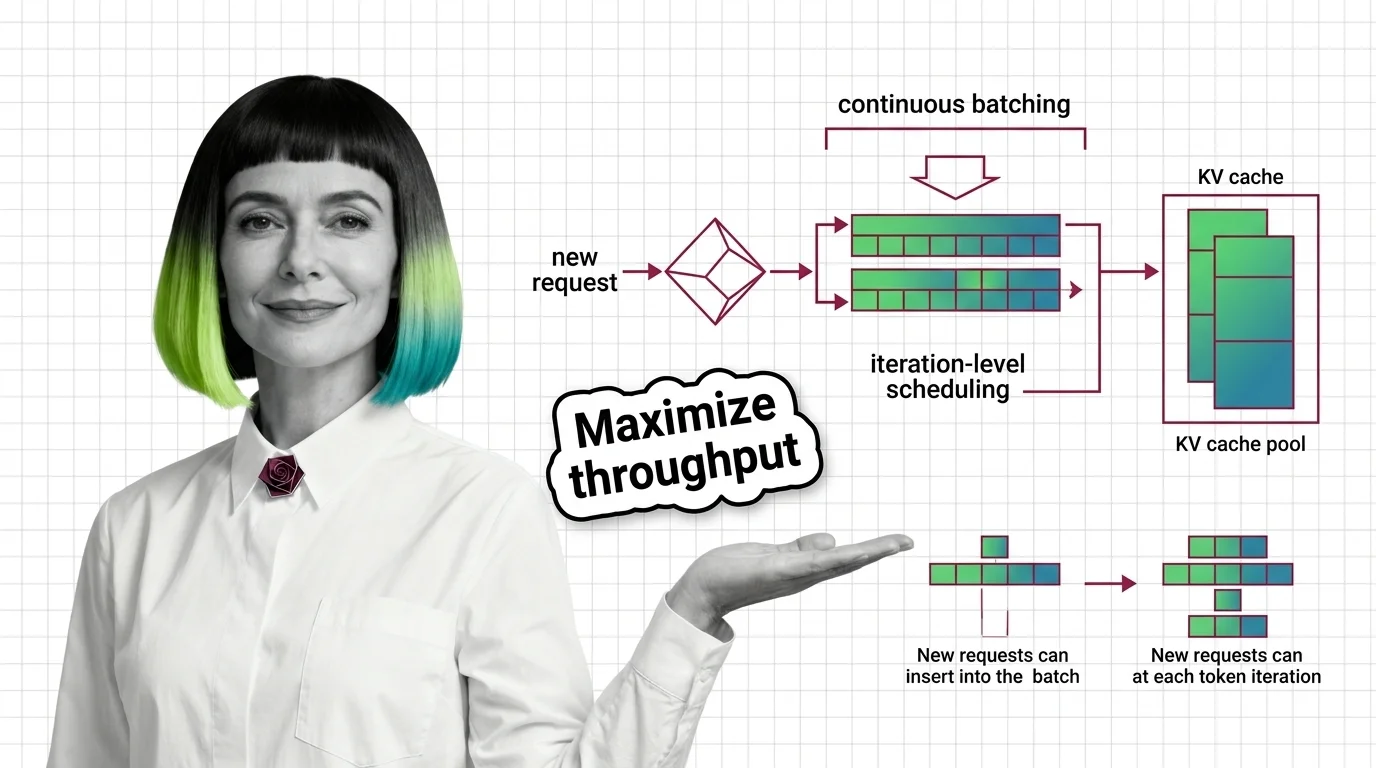
What Is Continuous Batching and How Iteration-Level Scheduling Maximizes GPU Throughput
Continuous batching replaces request-level scheduling with iteration-level scheduling, keeping GPUs busy on every …
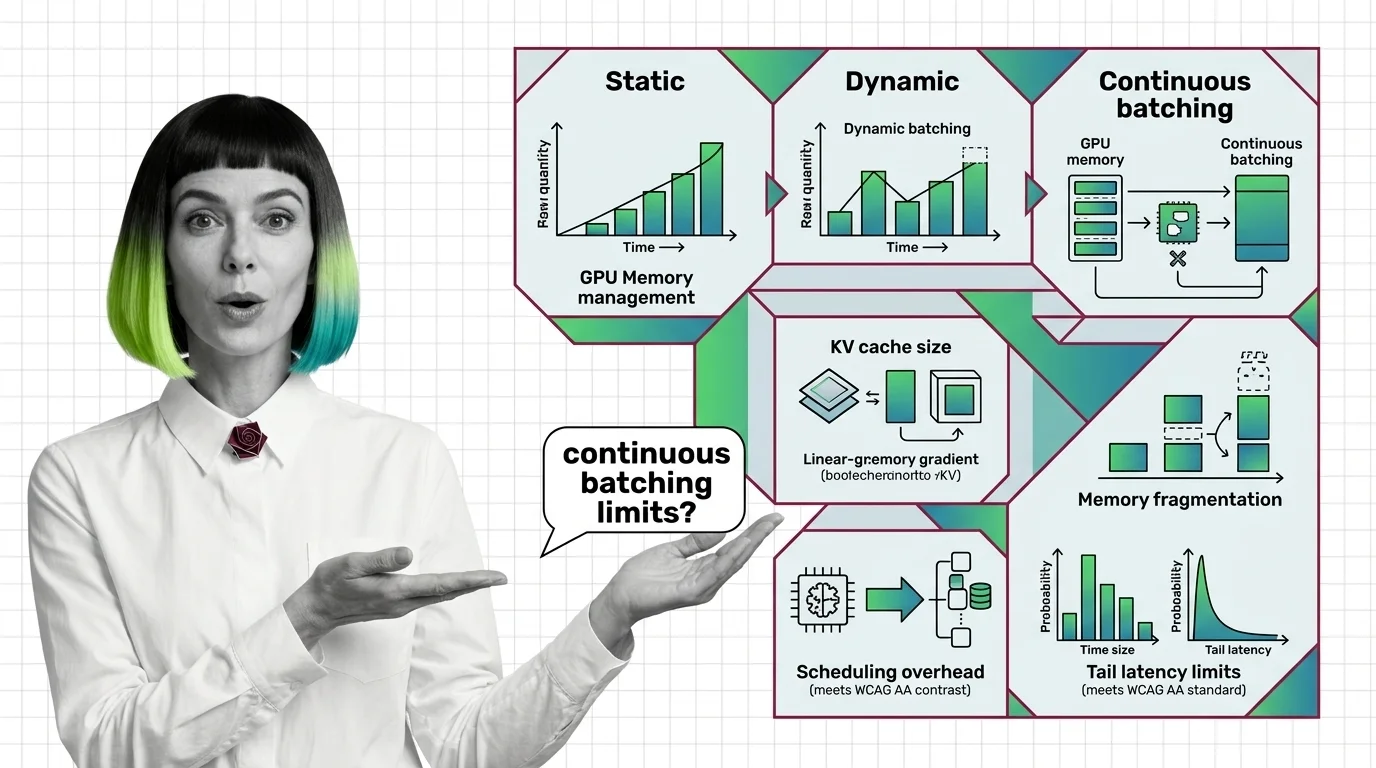
From Static Batching to PagedAttention: Prerequisites and Hard Limits of Continuous Batching
Continuous batching swaps finished LLM requests every decode step. Learn how PagedAttention cuts KV cache waste to under …
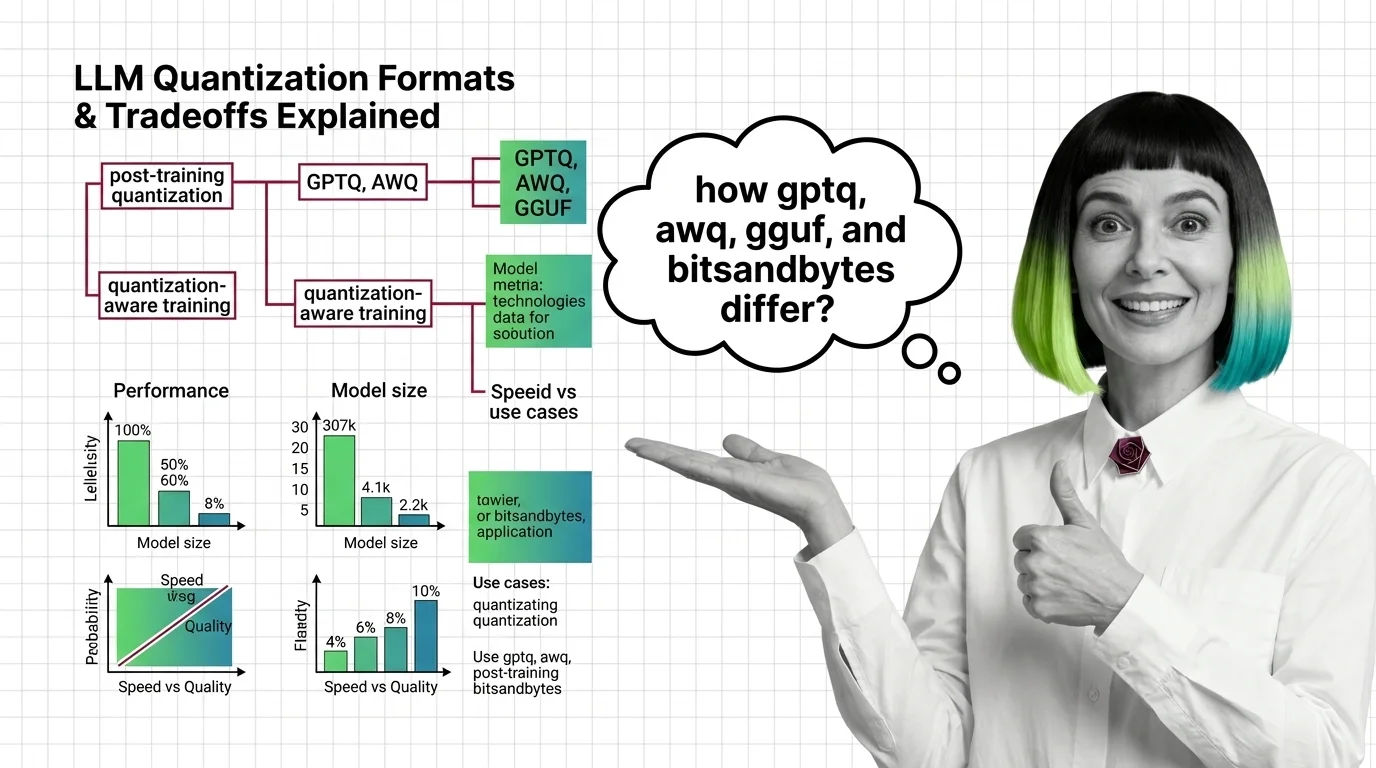
GPTQ vs AWQ vs GGUF vs bitsandbytes: Quantization Formats and Their Tradeoffs Explained
GPTQ, AWQ, GGUF, and bitsandbytes each shrink LLM weights differently. Compare speed, accuracy, and hardware reach to …

Accuracy Collapse, Task-Specific Degradation, and the Hard Limits of Sub-4-Bit Quantization
Sub-4-bit quantization promises smaller LLMs, but accuracy collapses unevenly across tasks and languages. Learn where …
Repetition Loops, Hallucination Spikes, and the Hard Limits of Sampling Parameter Tuning
Wrong sampling parameters trap LLMs in repetition loops or hallucination. Trace the probability math behind both failure …
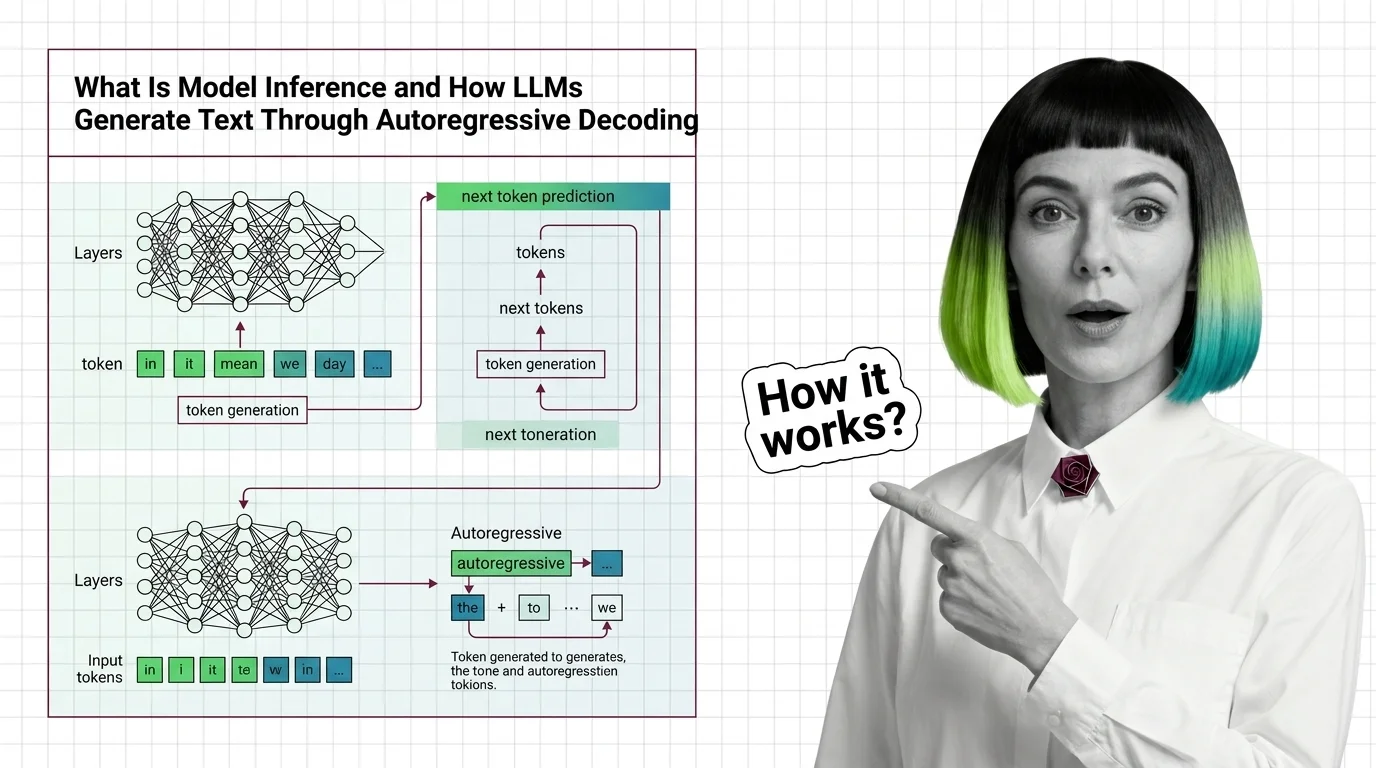
What Is Model Inference and How LLMs Generate Text Through Autoregressive Decoding
Model inference generates LLM text one token at a time via autoregressive decoding. Learn why this sequential bottleneck …
Memory Walls, Quadratic Context Costs, and the Hard Engineering Limits of LLM Inference in 2026
LLM inference hits hard physical walls — memory, quadratic attention, bandwidth. Learn the engineering limits and 2026 …
KV-Cache, PagedAttention, and the Building Blocks Every LLM Inference Pipeline Needs
KV-cache, PagedAttention, and continuous batching form the inference pipeline core. Learn how memory management …
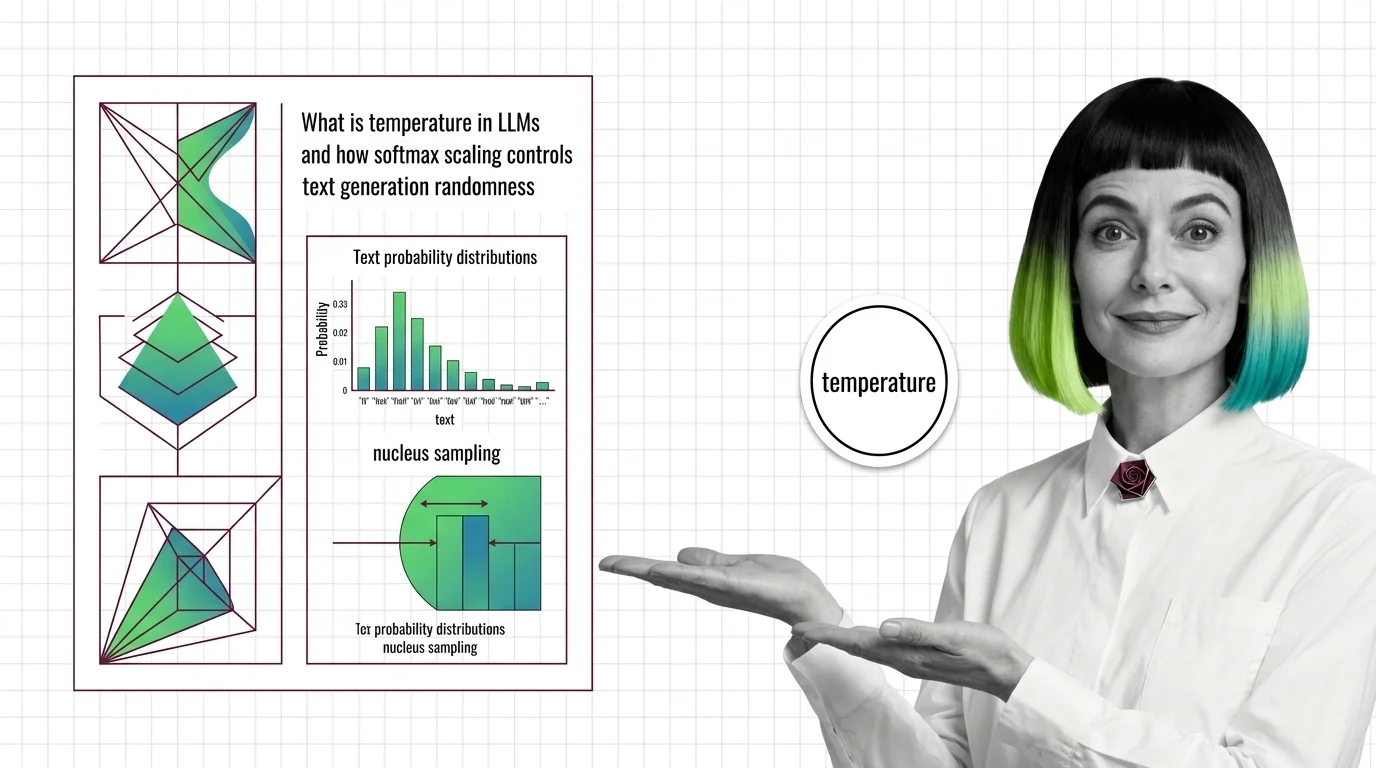
What Is Temperature in LLMs and How Softmax Scaling Controls Text Generation Randomness
Temperature divides logits before softmax, reshaping the token probability distribution. Learn how this parameter, …
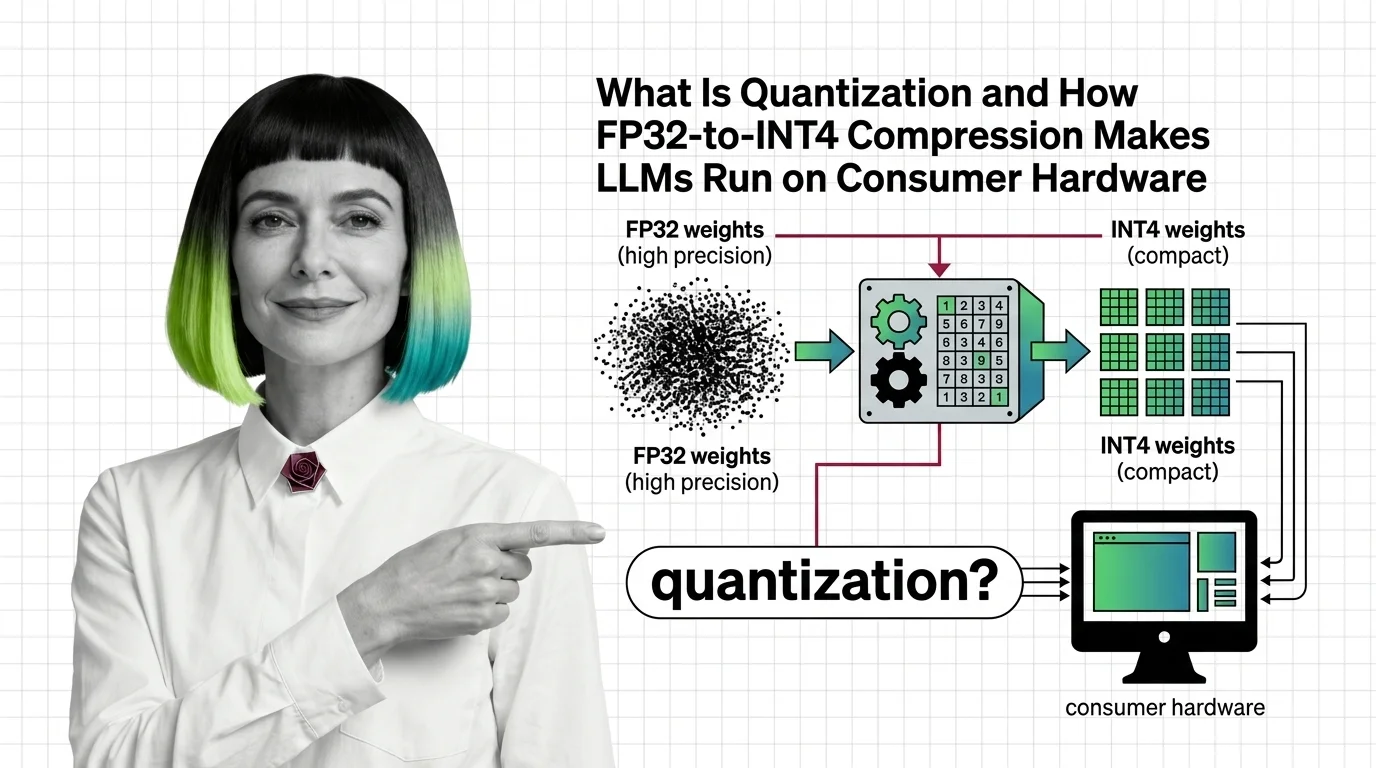
What Is Quantization and How FP32-to-INT4 Compression Makes LLMs Run on Consumer Hardware
Quantization compresses LLM weights from FP32 to INT4, cutting memory up to 8x. Learn how GPTQ, AWQ, and calibration …
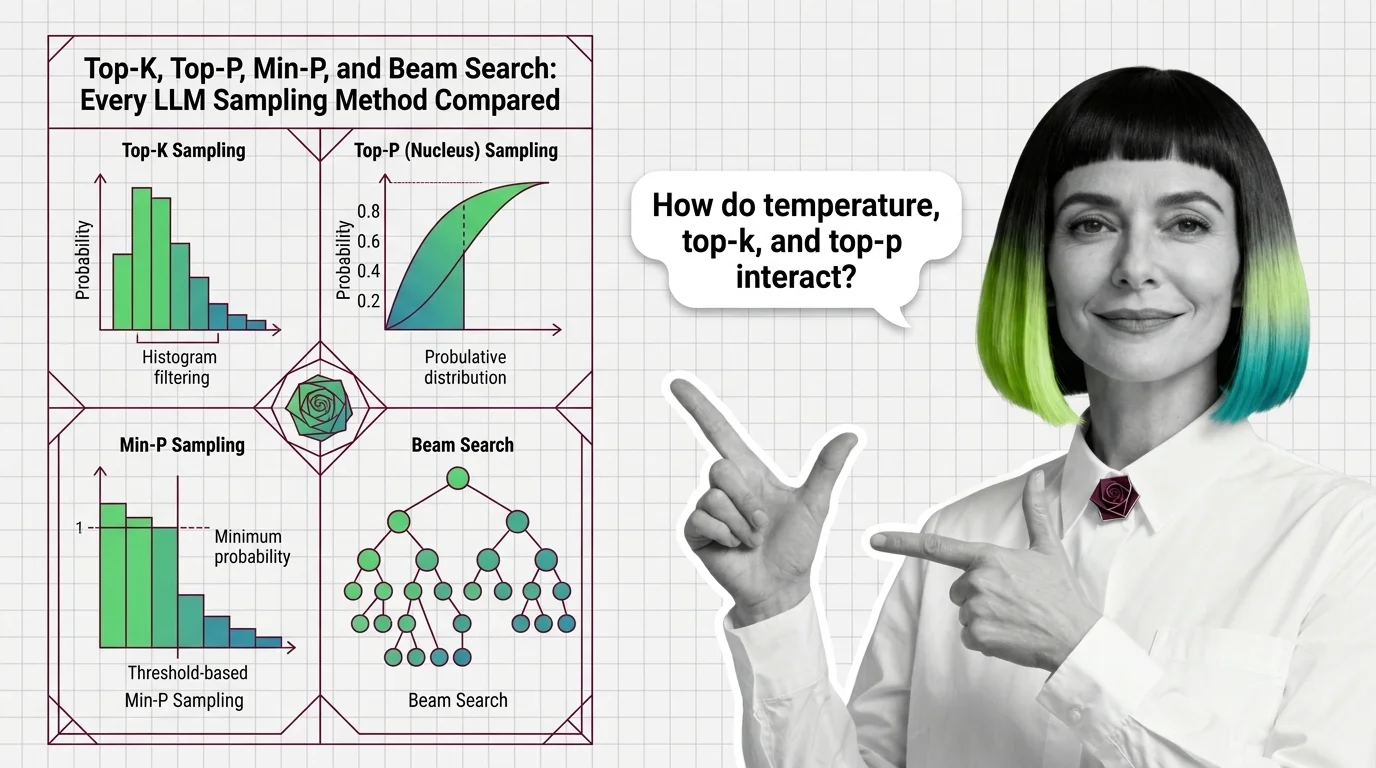
Top-K, Top-P, Min-P, and Beam Search: Every LLM Sampling Method Compared
Compare top-k, top-p, min-p, and beam search LLM sampling methods. Learn how each reshapes probability distributions and …