LLM Foundations
Core mechanics of large language models — training, inference, tokenization, and the mathematics of next-token prediction.
- Home /
- AI Principles /
- LLM Foundations

What Is Transformer Architecture and How Self-Attention Replaced Recurrence
Transformers replaced sequential recurrence with parallel self-attention. Understand QKV computation, multi-head …
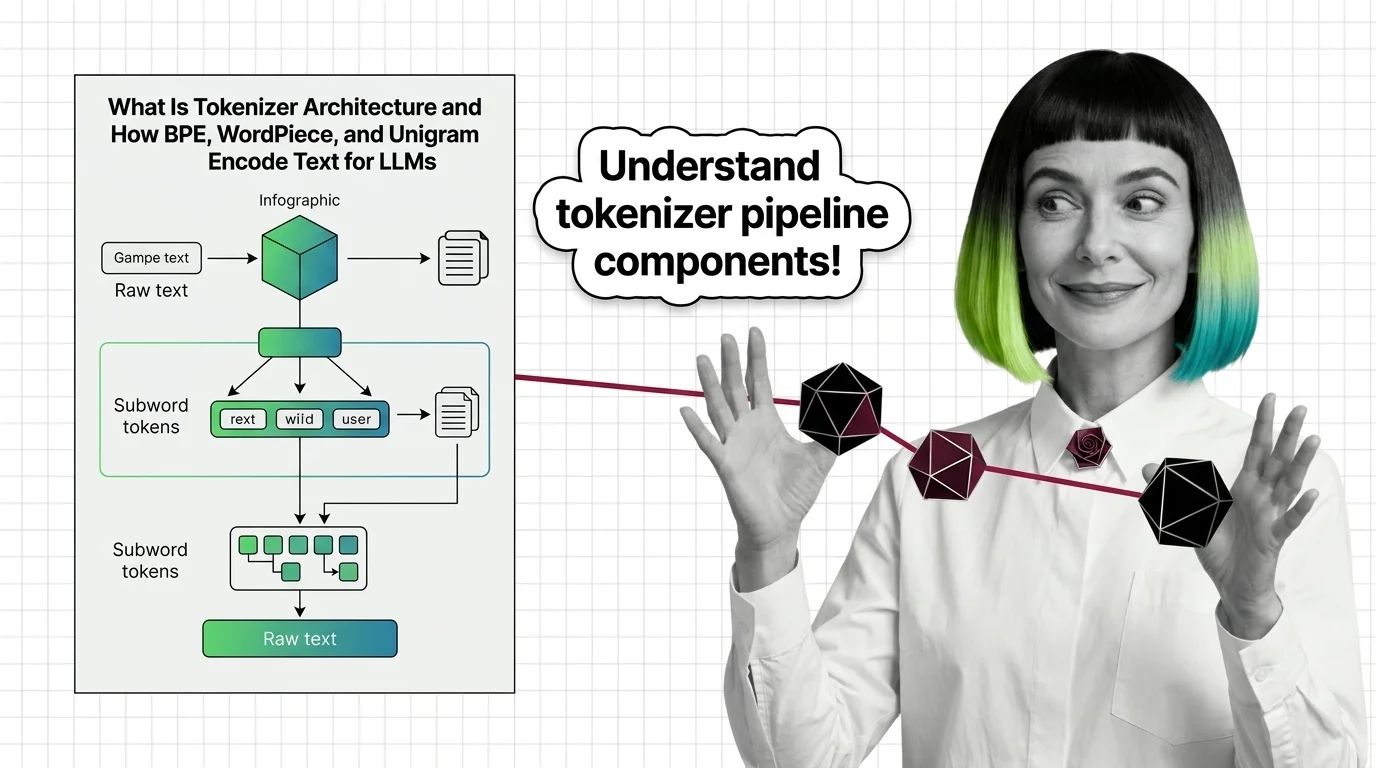
What Is Tokenizer Architecture and How BPE, WordPiece, and Unigram Encode Text for LLMs
Tokenizer architecture determines how LLMs read text. Learn how BPE, WordPiece, and Unigram split text into subword …

What Is an Embedding and How Neural Networks Encode Meaning into Vectors
Embeddings turn words into vector coordinates where distance equals meaning. Learn the geometry, training mechanics, and …
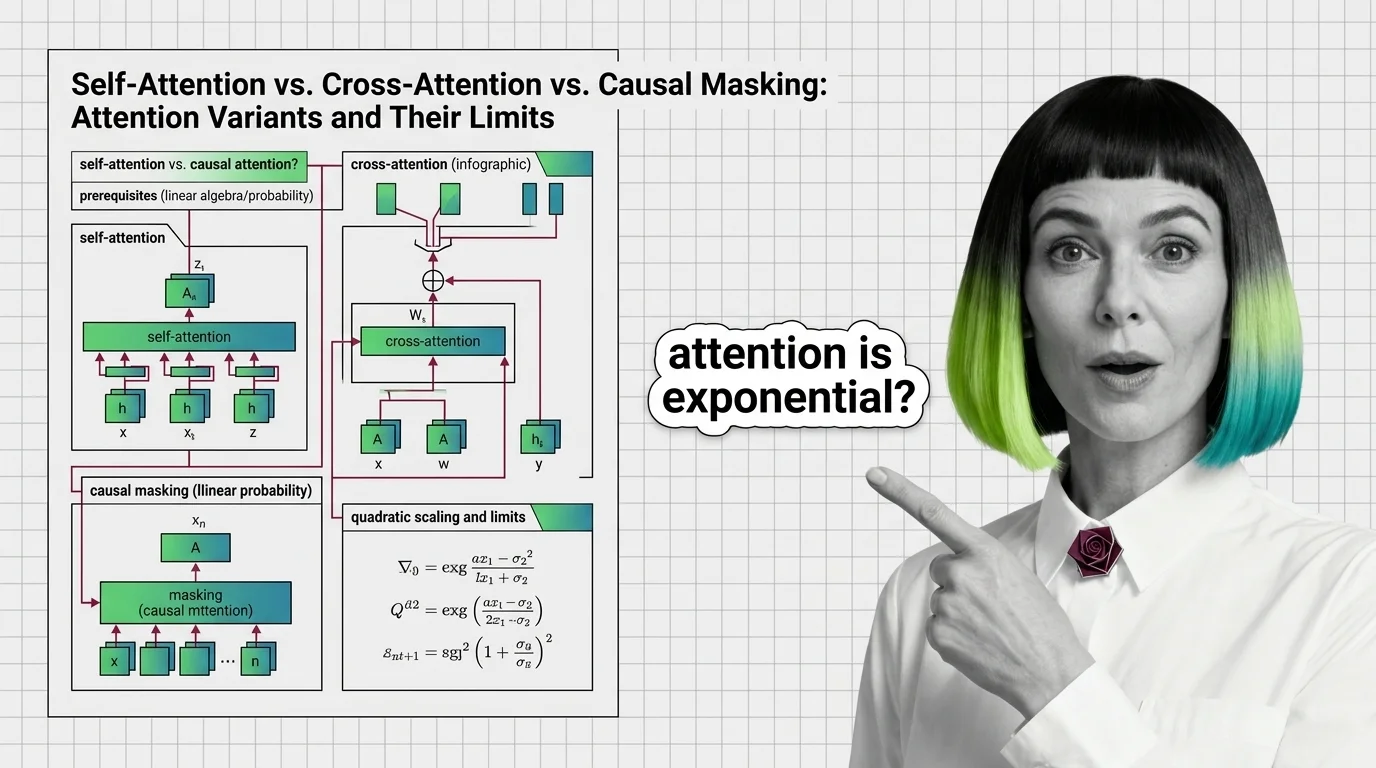
Self-Attention vs. Cross-Attention vs. Causal Masking: Attention Variants and Their Limits
Self-attention, cross-attention, and causal masking solve different problems inside transformers. Learn the math, …
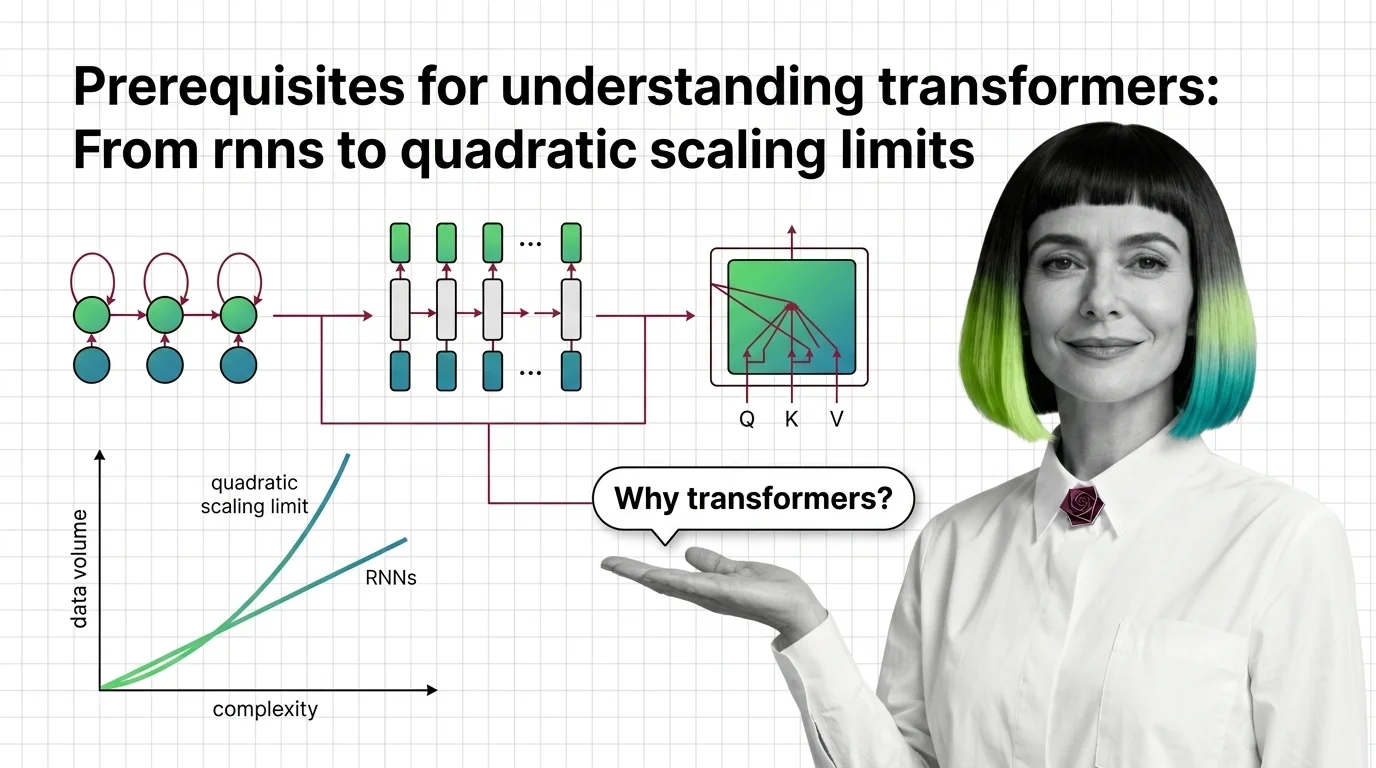
Prerequisites for Understanding Transformers: From RNNs to Quadratic Scaling Limits
Understand why RNNs failed, how transformer self-attention trades parallelism for quadratic cost, and what these …
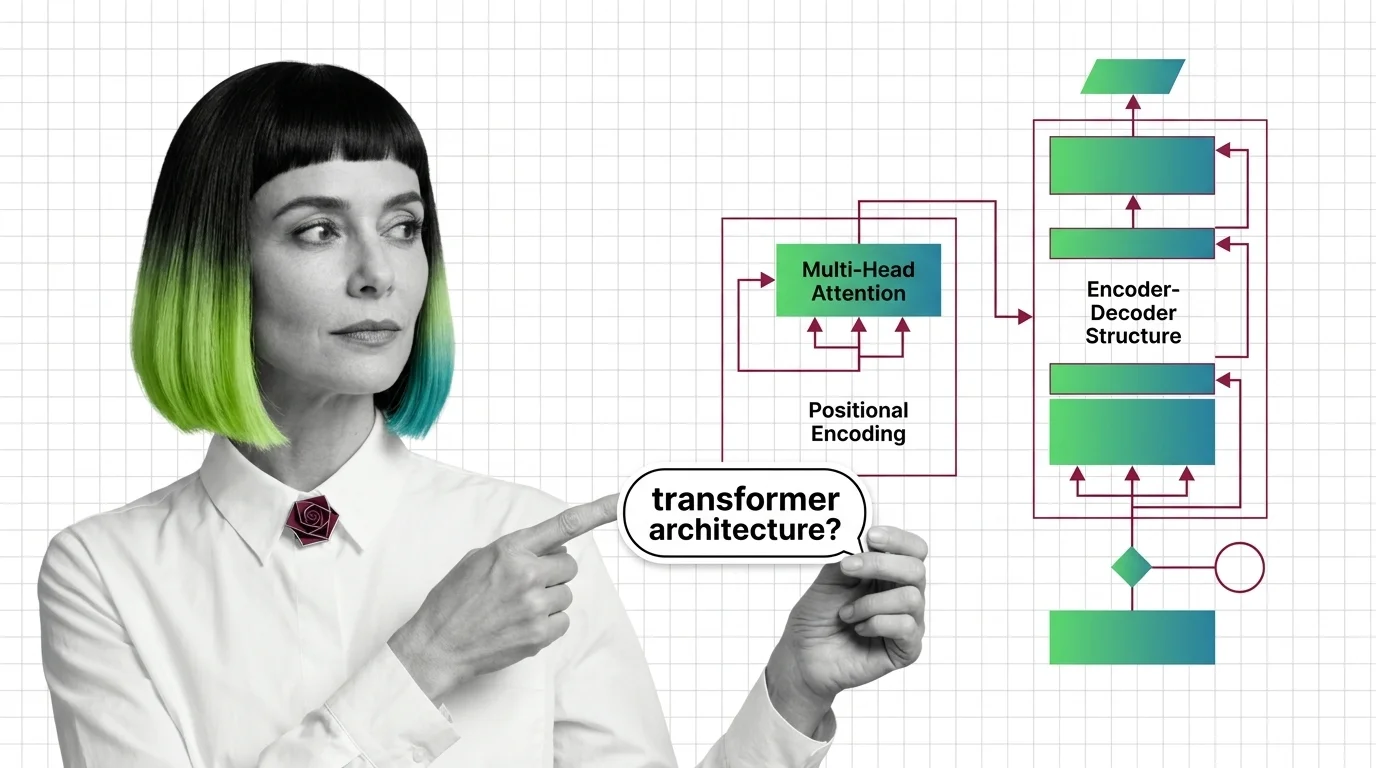
Multi-Head Attention, Positional Encoding, and the Encoder-Decoder Structure Explained
Multi-head attention, positional encoding, and encoder-decoder structure: the three mechanisms inside every transformer, …

Glitch Tokens, Fertility Gaps, and the Unsolved Technical Limits of Subword Tokenization
BPE tokenizers produce glitch tokens and penalize non-Latin scripts with fertility gaps. Learn where the math breaks — …
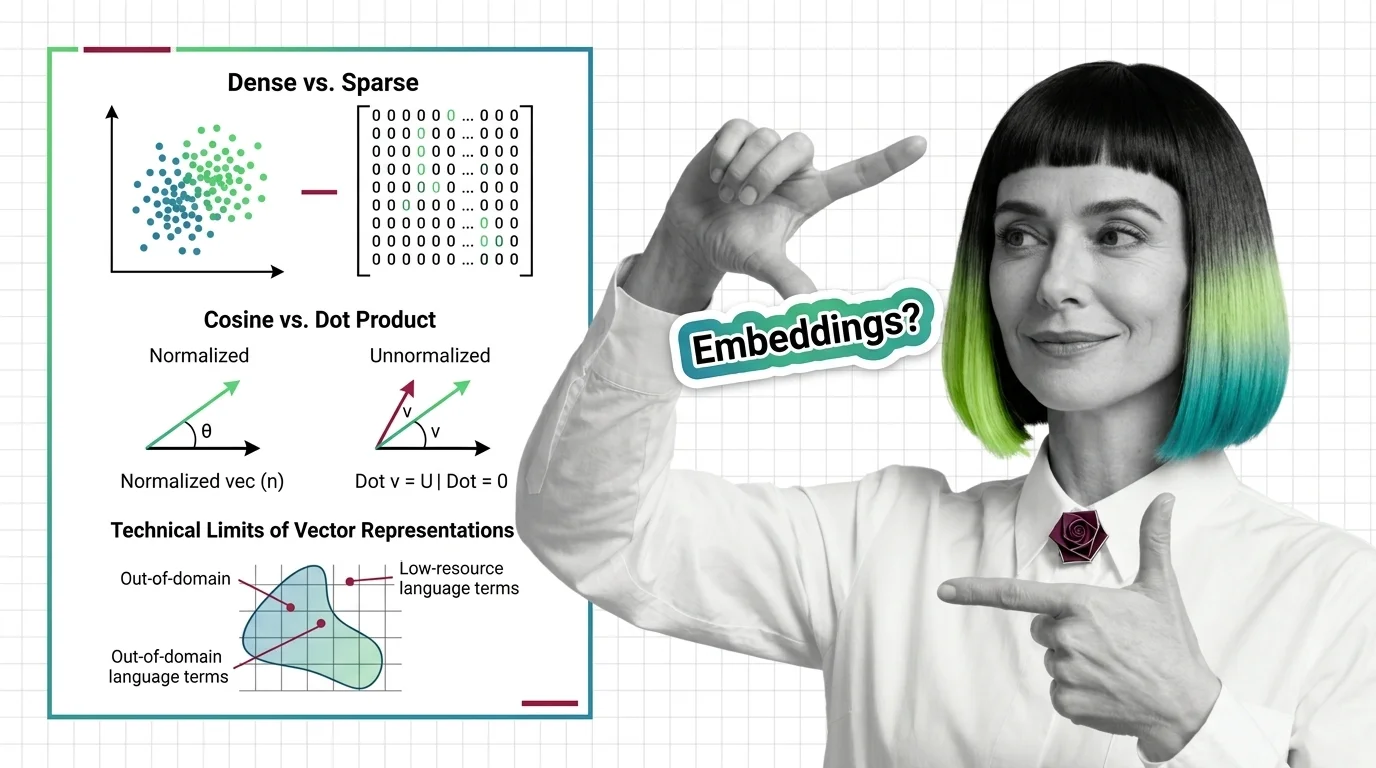
Dense vs. Sparse, Cosine vs. Dot Product, and the Technical Limits of Vector Representations
Dense vs. sparse embeddings encode meaning differently. Learn how cosine similarity, dot product, and Euclidean distance …
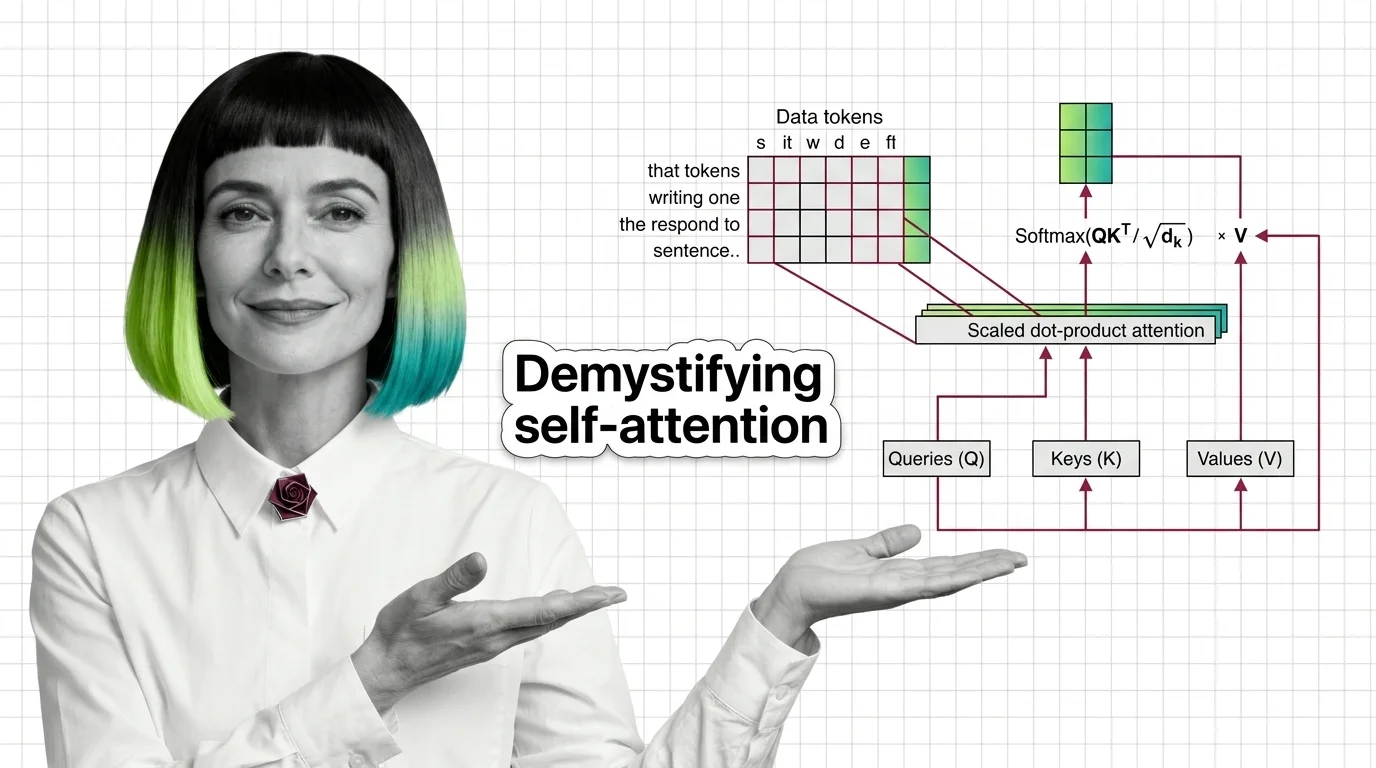
Attention Mechanism Explained: How Queries, Keys, and Values Power Modern AI
Attention mechanisms let neural networks weigh input relevance dynamically. Learn how queries, keys, and values compute …
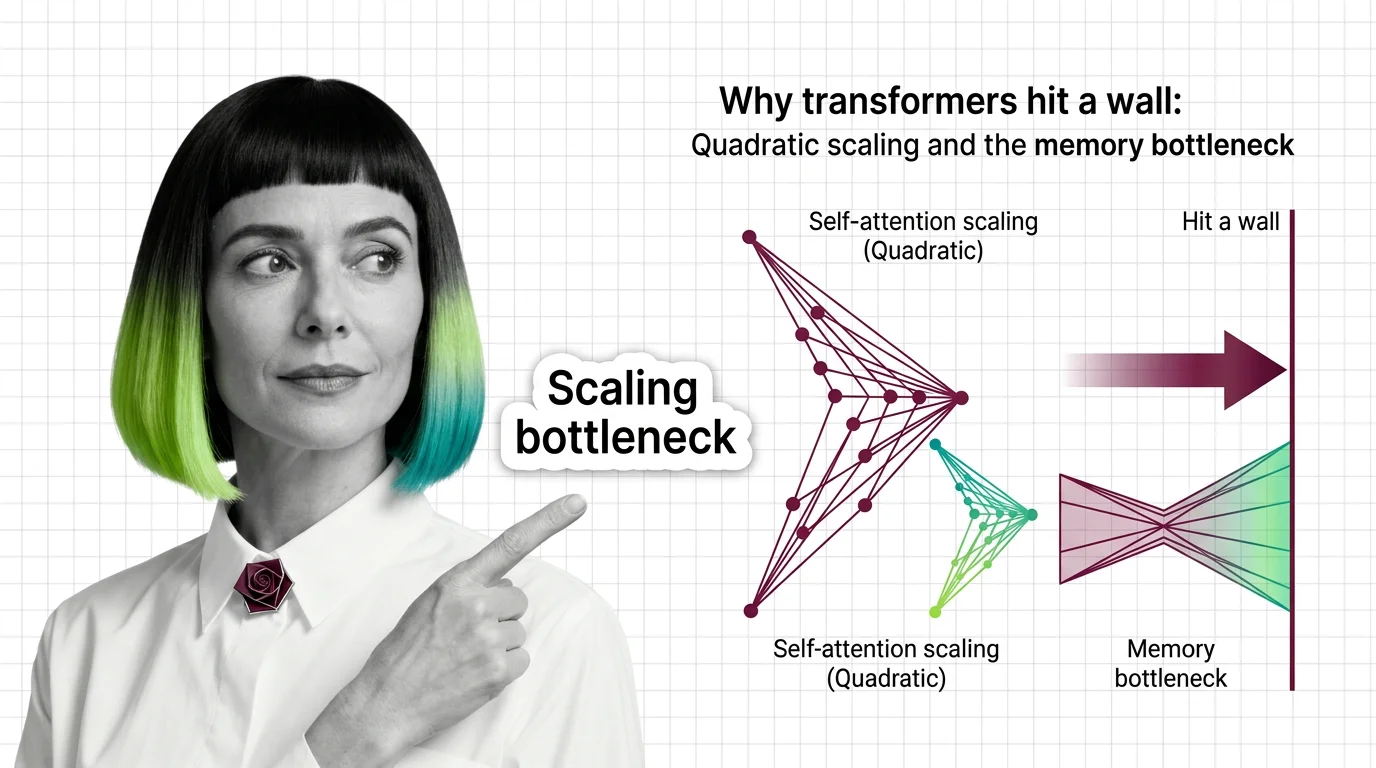
Why Transformers Hit a Wall: Quadratic Scaling and the Memory Bottleneck
Transformer self-attention scales quadratically with sequence length. Understand the O(n²) memory wall, KV cache costs, …
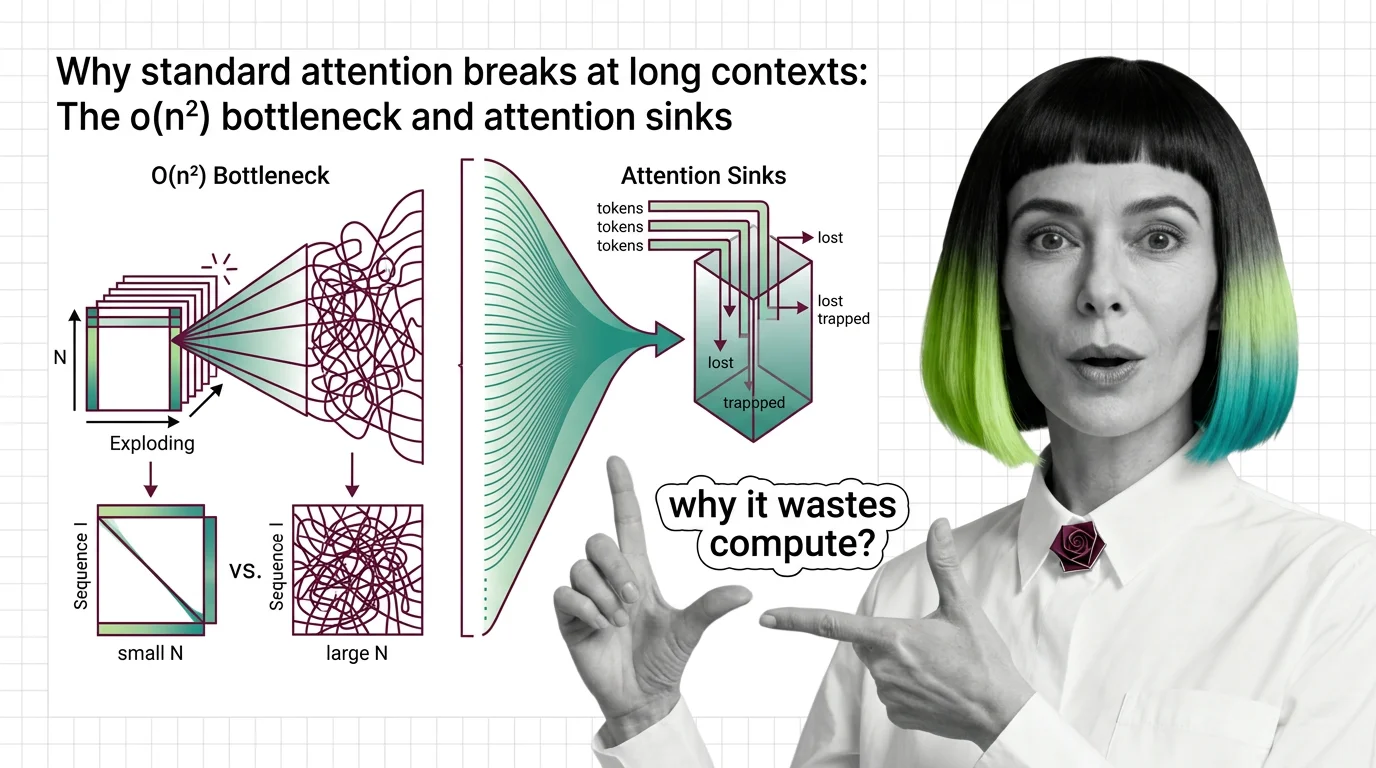
Why Standard Attention Breaks at Long Contexts: The O(n²) Bottleneck and Attention Sinks
Standard attention scales quadratically with sequence length. Learn why O(n²) breaks at long contexts, what attention …
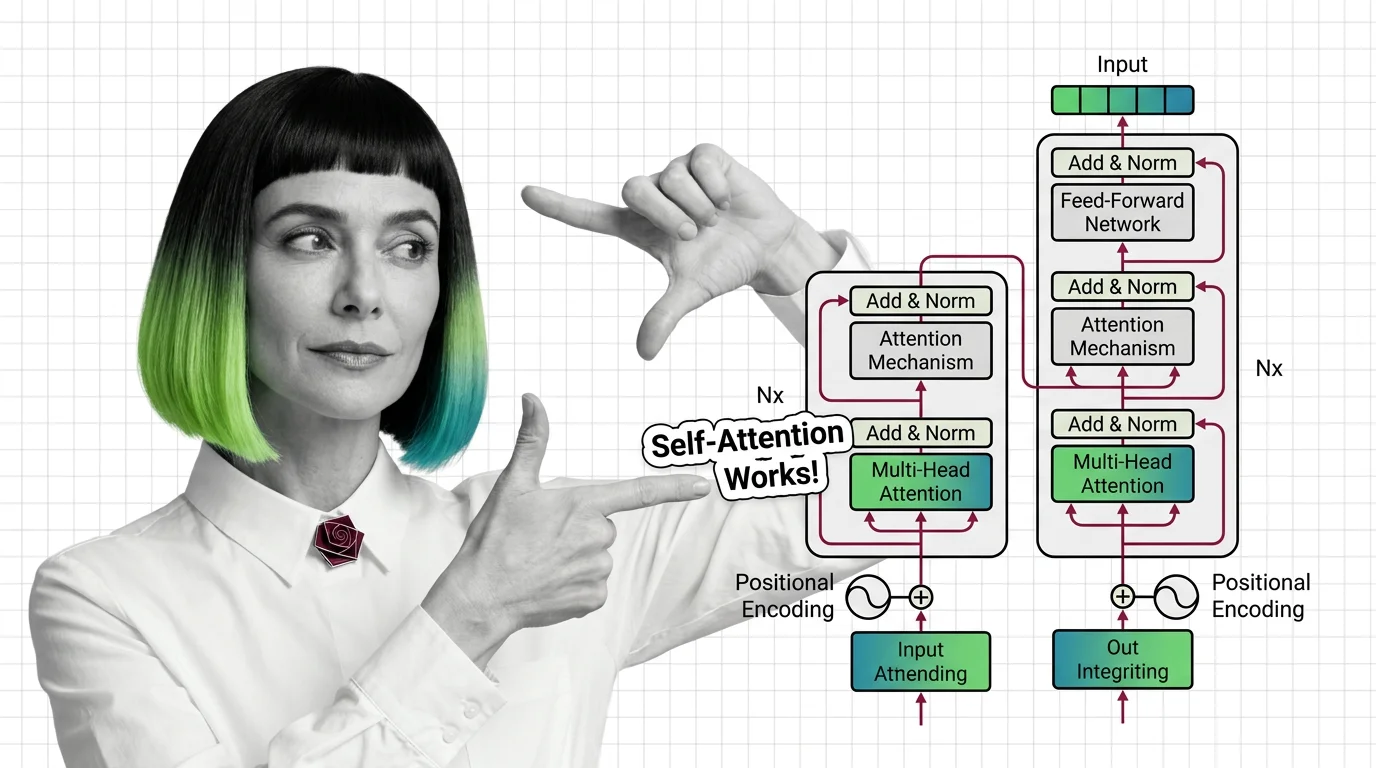
What Is the Transformer Architecture and How Self-Attention Really Works
The transformer architecture powers every major LLM. Learn how self-attention computes token relationships, why …
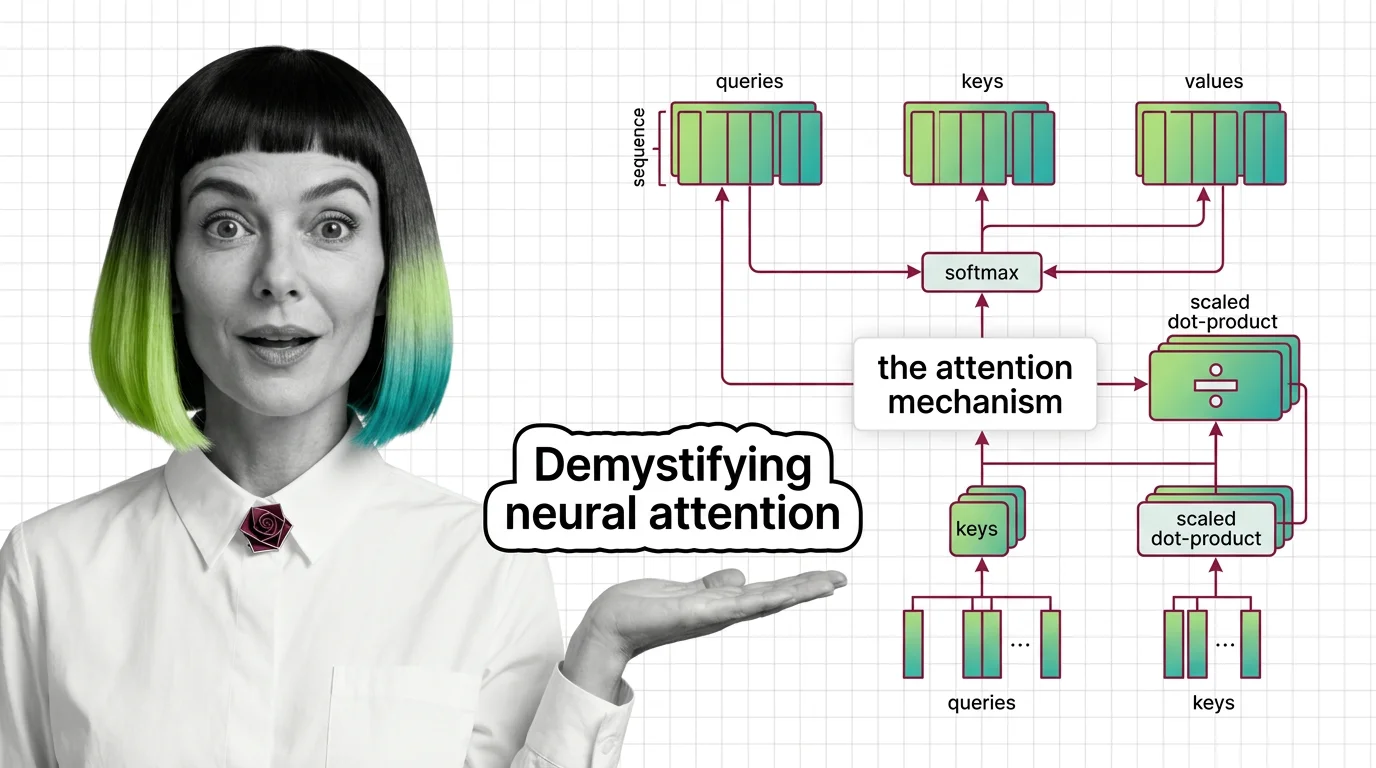
What Is the Attention Mechanism: Scaled Dot-Product, Self-Attention, and Cross-Attention Explained
Understand how the attention mechanism works inside transformers. Covers scaled dot-product attention, self-attention vs …
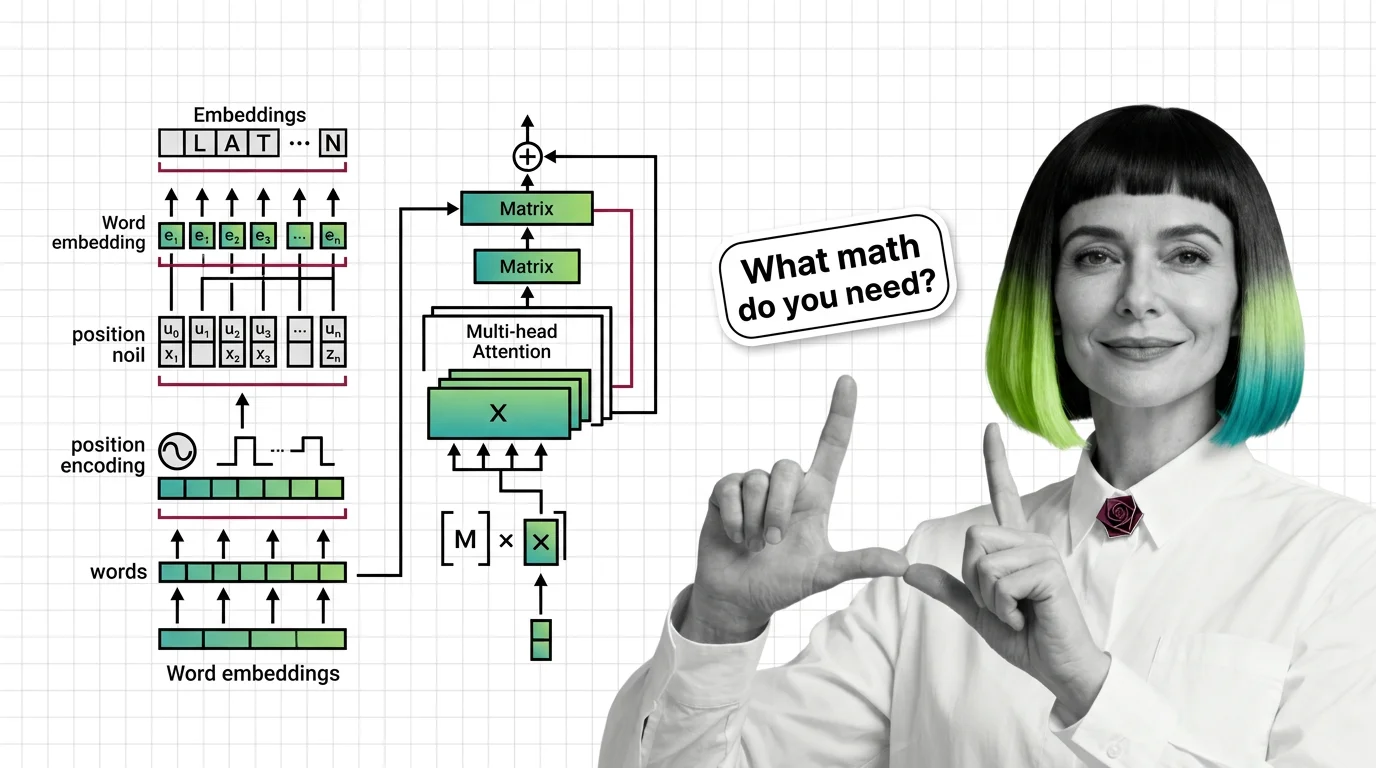
Prerequisites for Understanding Transformers: From Embeddings to Matrix Multiplication
Master the math behind transformers: embeddings, matrix multiplication, positional encoding, and multi-head attention …
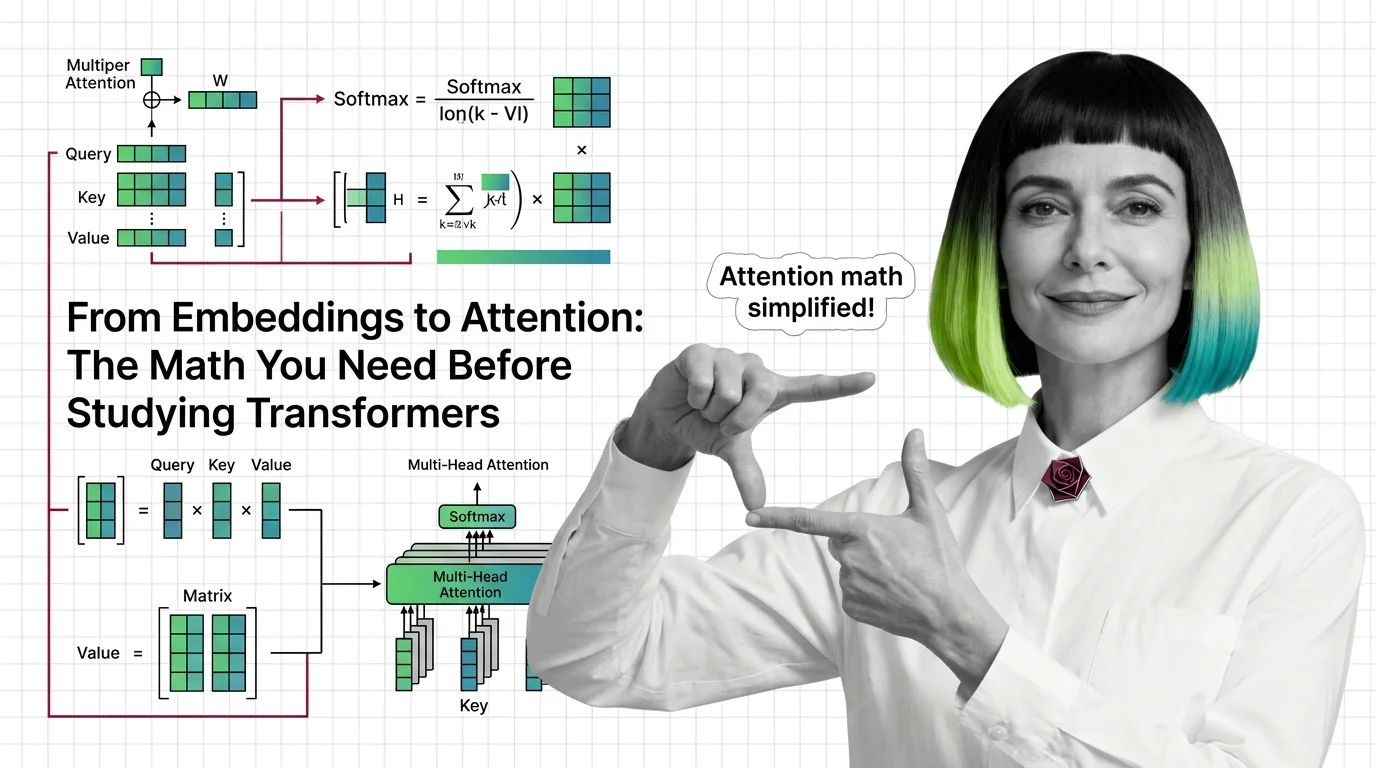
From Embeddings to Attention: The Math You Need Before Studying Transformers
Master the math behind attention mechanisms — dot products, softmax, QKV matrices, and multi-head projections — before …