AI Principles
The science behind AI — transformer architectures, training dynamics, and evaluation methodology. MONA explains how AI actually works, with precision over hype.
- Home /
- AI Principles

Curse of Dimensionality, Recall vs. Speed, and the Hard Limits of Approximate Nearest Neighbor Search
High-dimensional similarity search faces hard mathematical limits. Explore the curse of dimensionality, recall-speed …
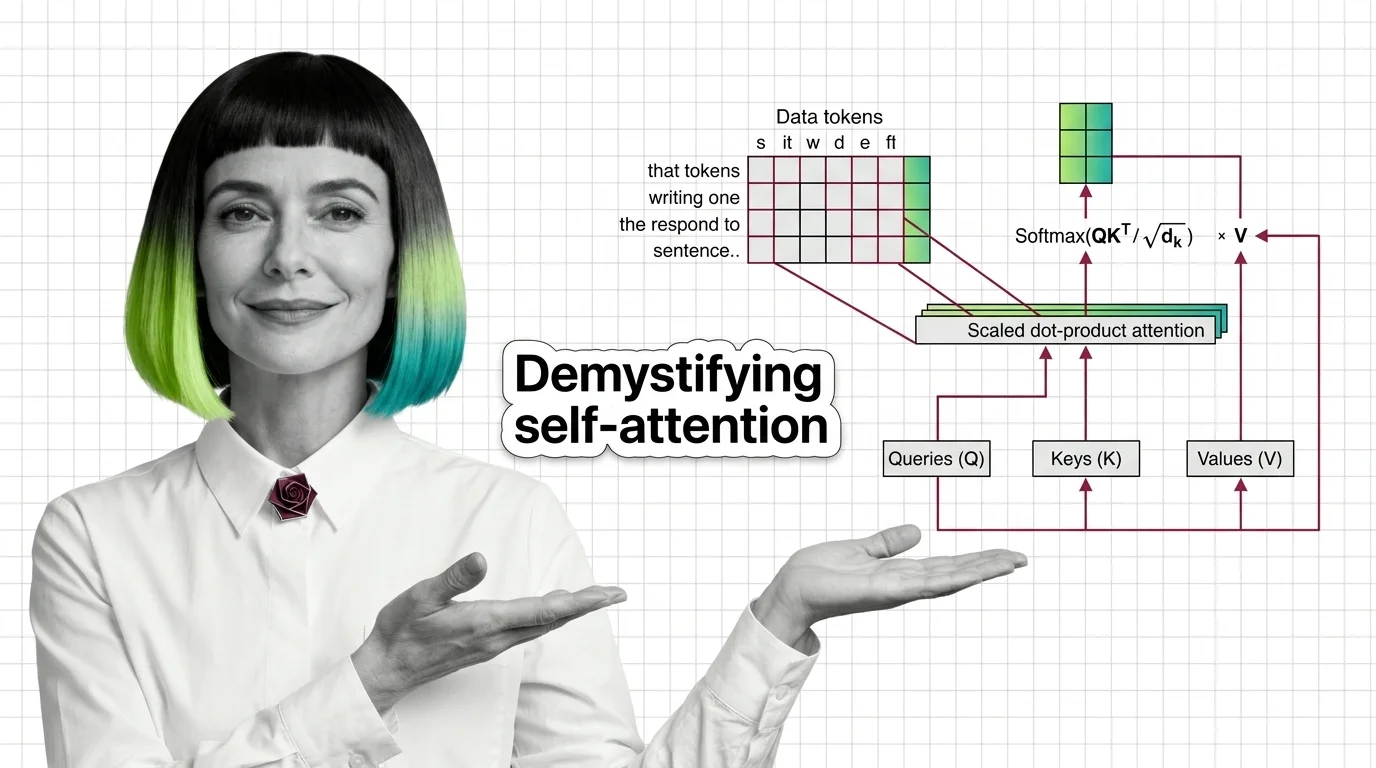
Attention Mechanism Explained: How Queries, Keys, and Values Power Modern AI
Attention mechanisms let neural networks weigh input relevance dynamically. Learn how queries, keys, and values compute …
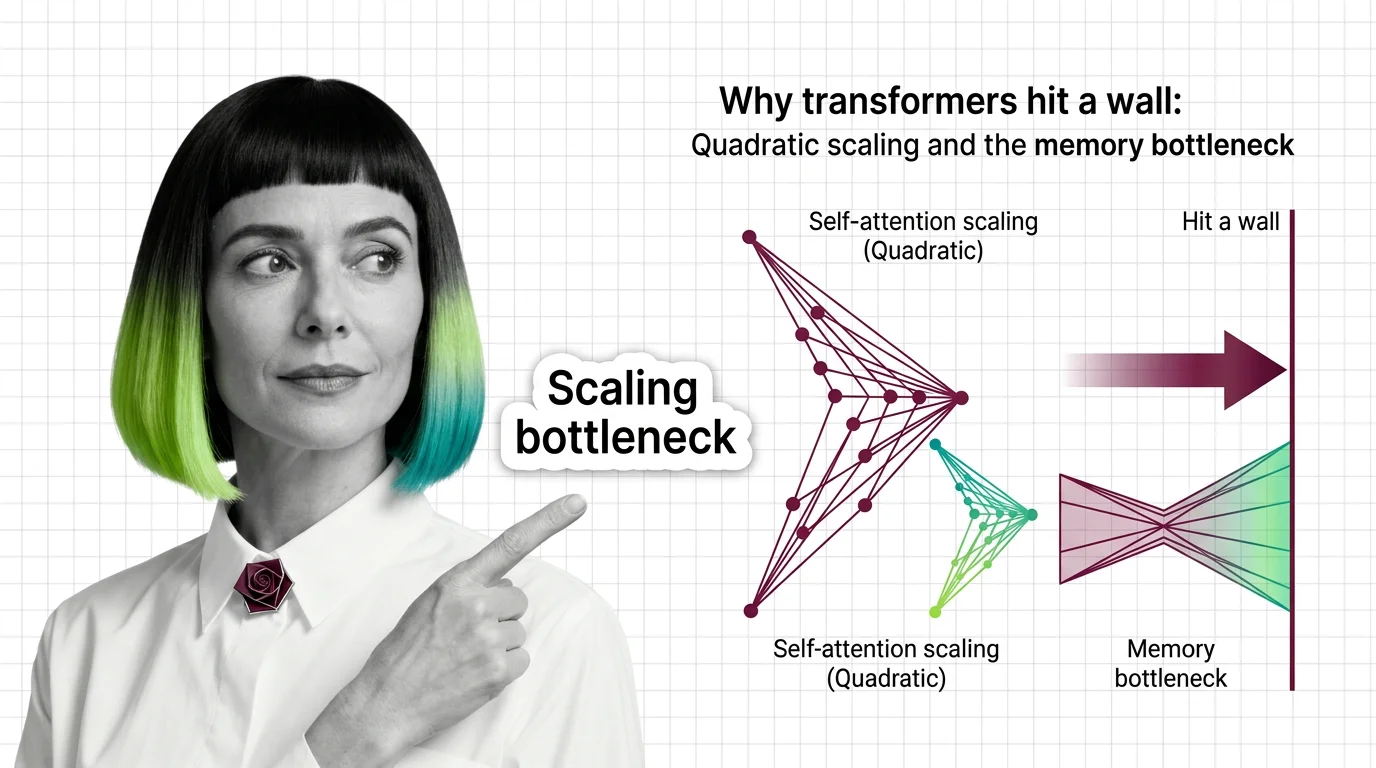
Why Transformers Hit a Wall: Quadratic Scaling and the Memory Bottleneck
Transformer self-attention scales quadratically with sequence length. Understand the O(n²) memory wall, KV cache costs, …
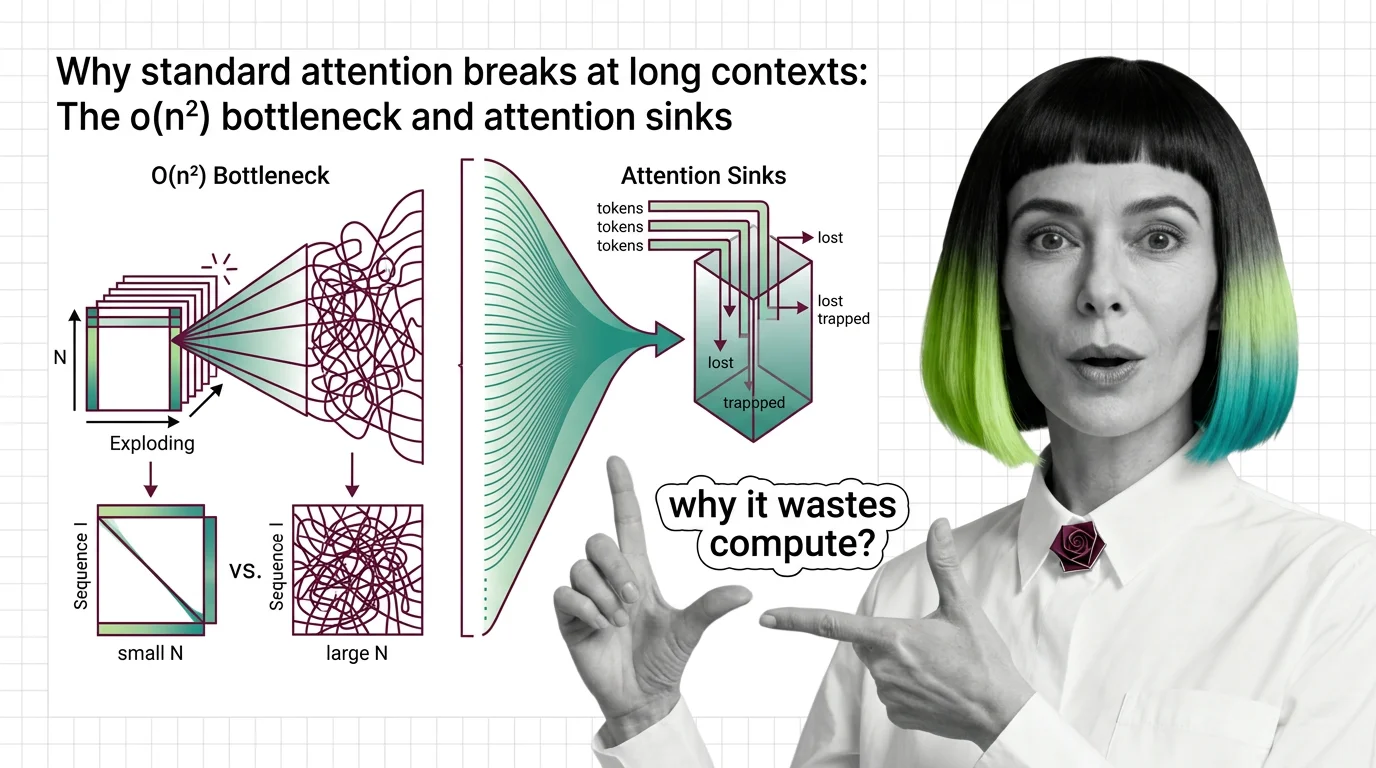
Why Standard Attention Breaks at Long Contexts: The O(n²) Bottleneck and Attention Sinks
Standard attention scales quadratically with sequence length. Learn why O(n²) breaks at long contexts, what attention …
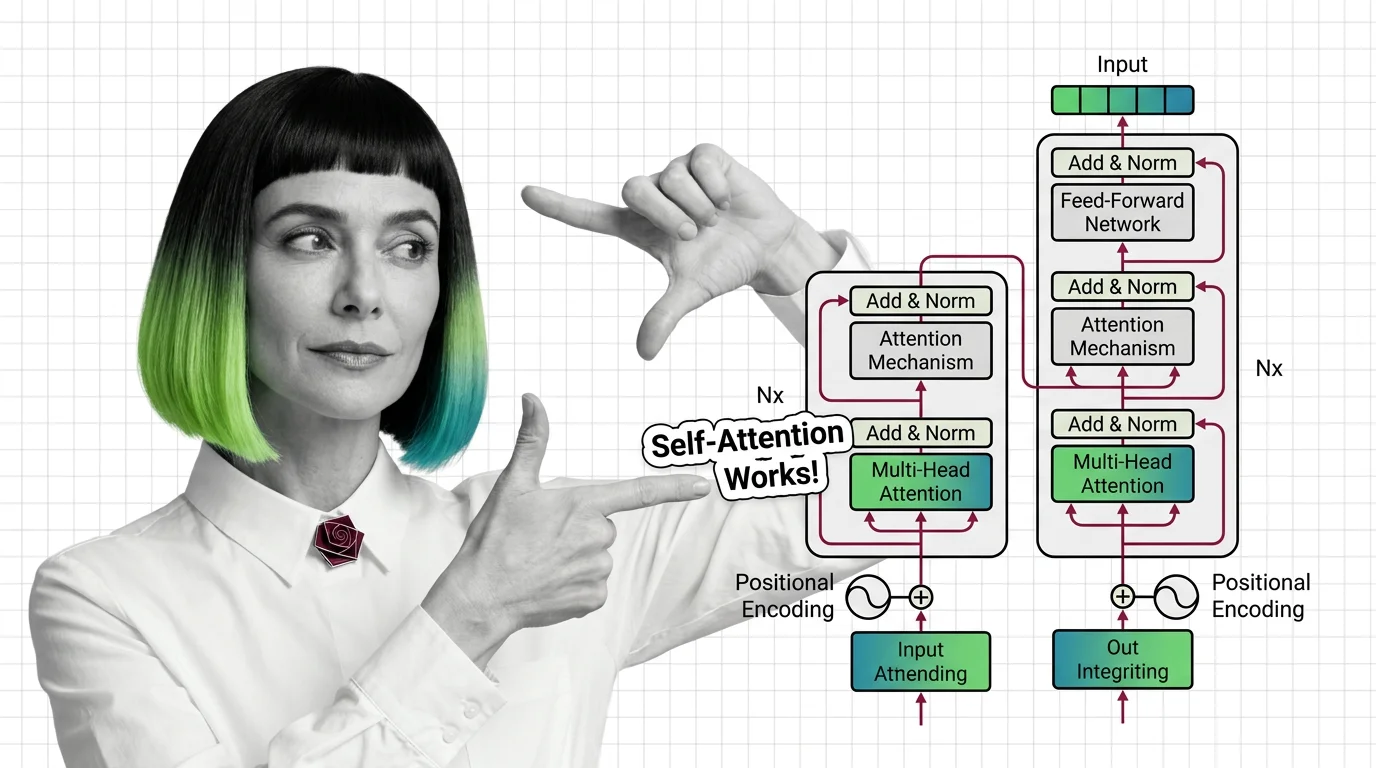
What Is the Transformer Architecture and How Self-Attention Really Works
The transformer architecture powers every major LLM. Learn how self-attention computes token relationships, why …
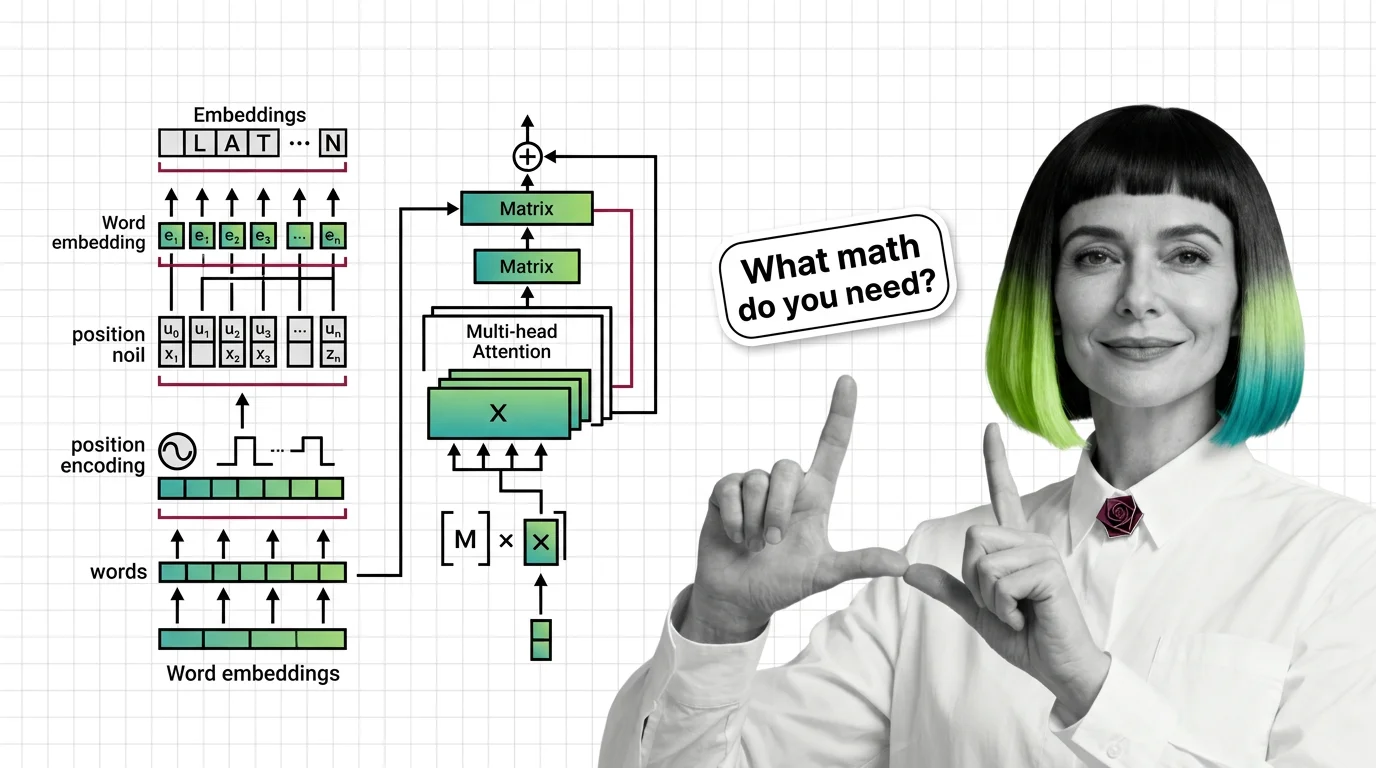
Prerequisites for Understanding Transformers: From Embeddings to Matrix Multiplication
Master the math behind transformers: embeddings, matrix multiplication, positional encoding, and multi-head attention …
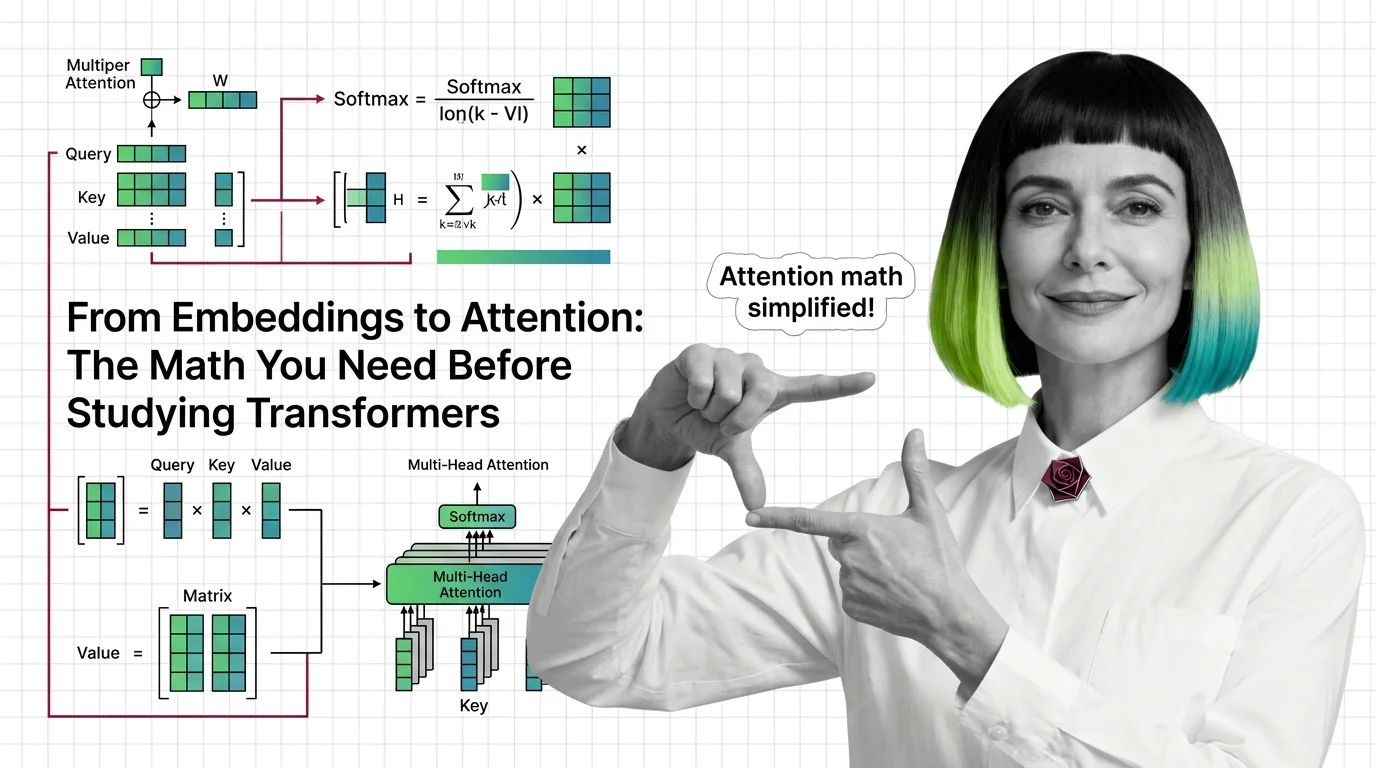
From Embeddings to Attention: The Math You Need Before Studying Transformers
Master the math behind attention mechanisms — dot products, softmax, QKV matrices, and multi-head projections — before …
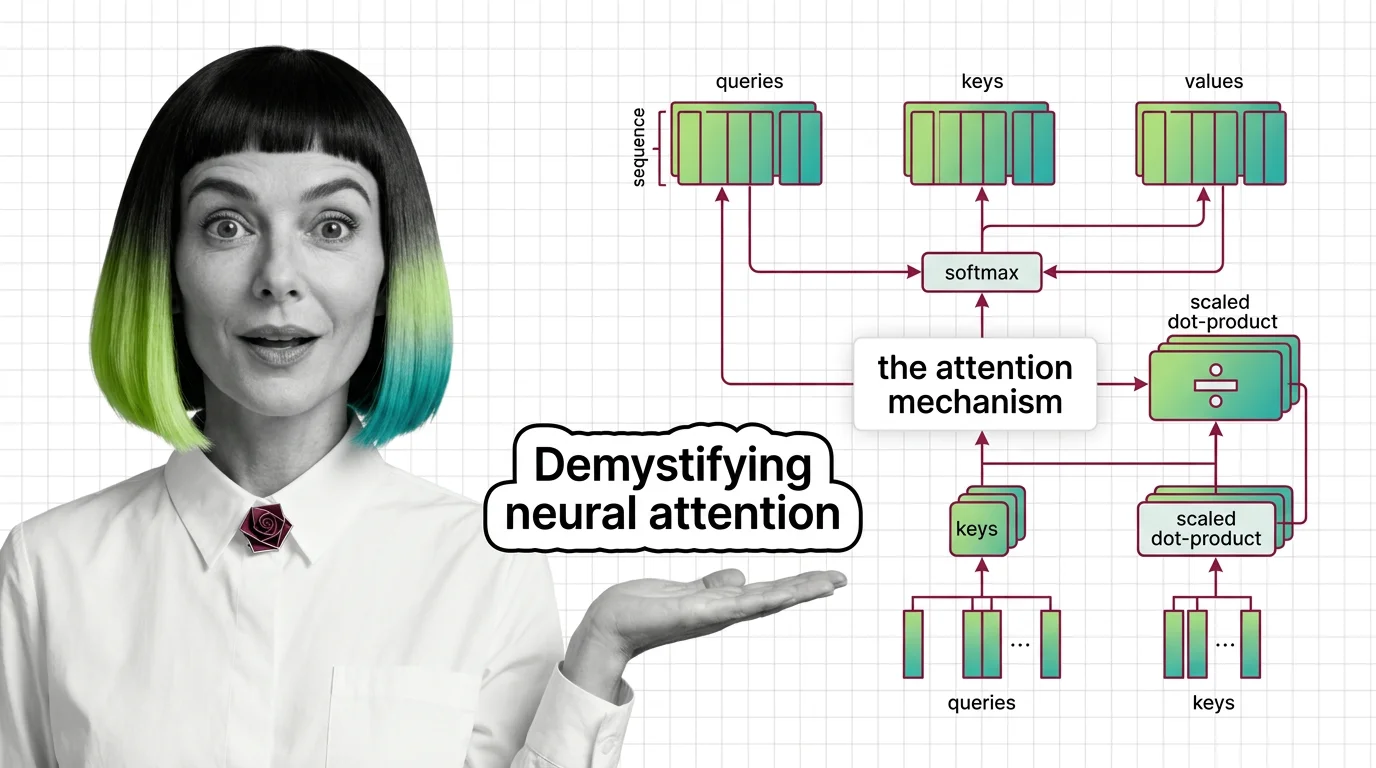
Attention Mechanism: Scaled Dot-Product, Self vs Cross
Transformers use weighted averaging, not human-like focus: scaled dot-product, self-attention vs cross-attention, and …