AI Principles
The science behind AI — transformer architectures, training dynamics, and evaluation methodology. MONA explains how AI actually works, with precision over hype.
- Home /
- AI Principles
Diminishing Returns, Data Exhaustion, and the Hard Technical Limits of Neural Scaling
Scaling laws predict how AI models improve with compute, but power-law exponents guarantee diminishing returns. Learn …
What Is RLHF and How Human Preferences Train Large Language Models to Follow Instructions
RLHF uses human preferences and reward models to train language models to follow instructions. Learn the three-stage PPO …

Reward Hacking, Mode Collapse, and the Unsolved Technical Limits of RLHF Alignment
Reward hacking, mode collapse, and KL divergence failure — the three unsolved technical limits of RLHF alignment and why …

From Reward Modeling to KL Penalties: Every Stage of the RLHF Training Pipeline Explained
RLHF aligns language models through human preferences in three stages. Learn how reward models, PPO, and KL penalties …
What Is Pre-Training and How LLMs Learn Language from Raw Text at Scale
Pre-training teaches LLMs to predict text, not understand it — yet prediction at scale produces something that resembles …
Scaling Walls, Data Exhaustion, and the Technical Limits of Pre-Training in 2026
Pre-training compute grows 4-5x yearly while data runs out. Learn the three scaling walls — cost, data exhaustion, and …
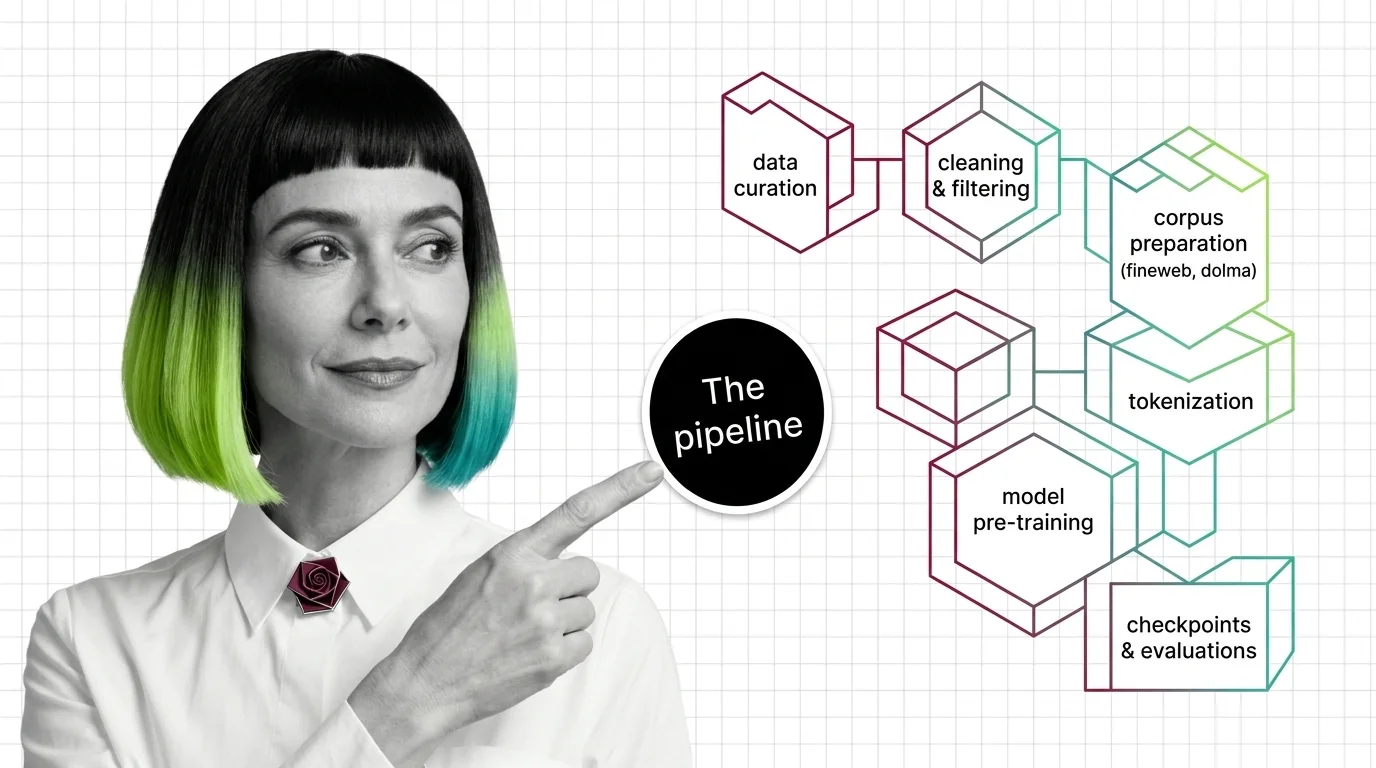
From Data Curation to Checkpoints: The Building Blocks of a Modern Pre-Training Pipeline
Pre-training pipelines run from data curation to checkpointing. Learn how FineWeb, Dolma, and Megatron-Core build the …

Catastrophic Forgetting, Overfitting, and the Hard Technical Limits of LLM Fine-Tuning
Fine-tuning can destroy what your LLM already knows. Learn why catastrophic forgetting and overfitting define the hard …
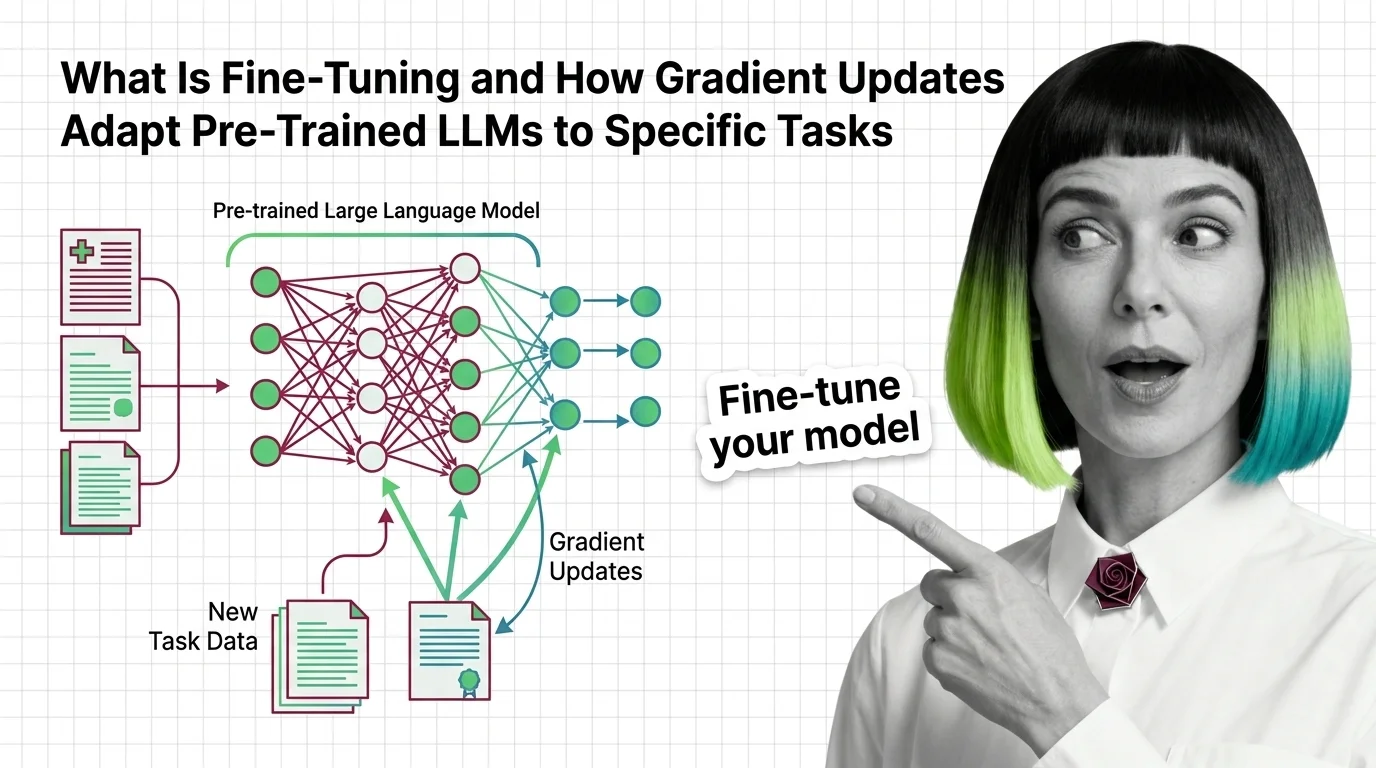
What Is Fine-Tuning and How Gradient Updates Adapt Pre-Trained LLMs to Specific Tasks
Fine-tuning adapts pre-trained LLMs by updating weights on task-specific data. Learn how gradient descent reshapes model …
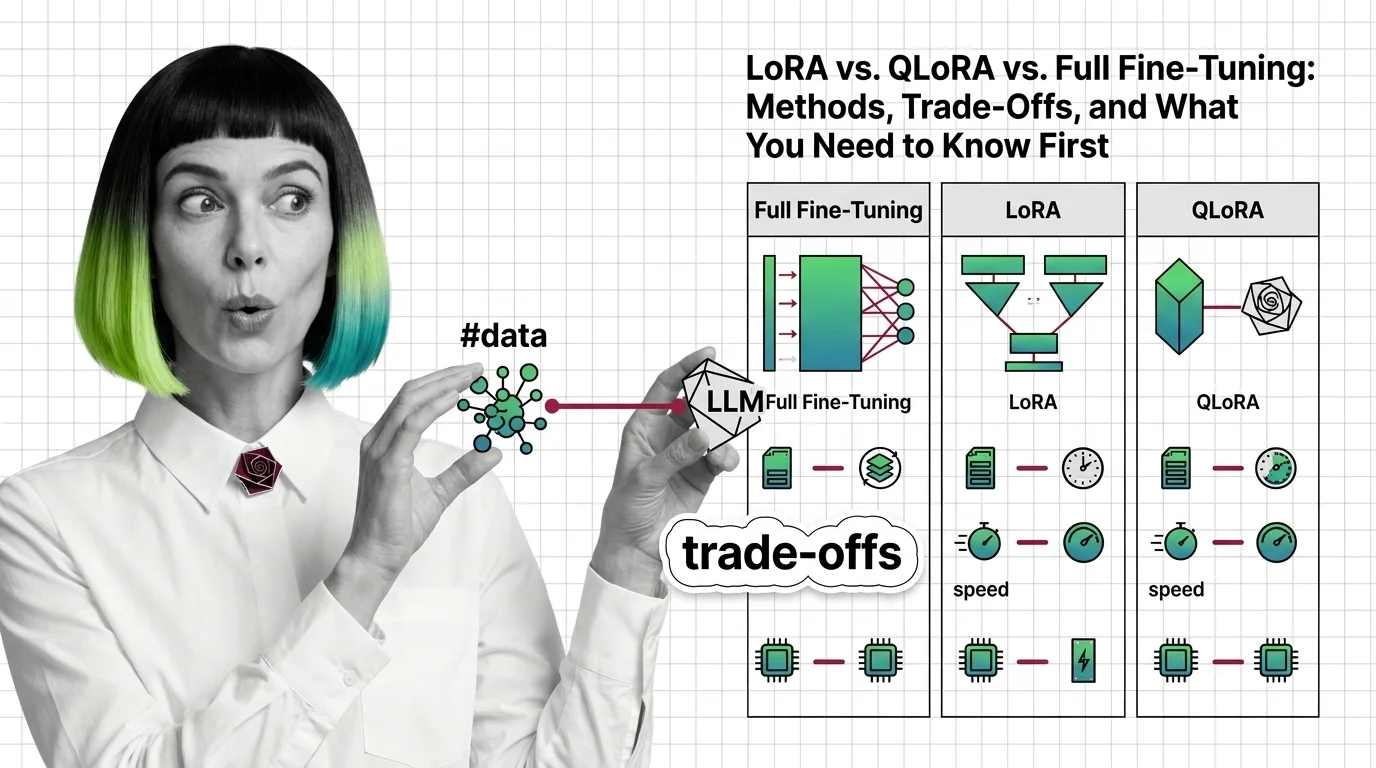
LoRA vs. QLoRA vs. Full Fine-Tuning: Methods, Trade-Offs, and What You Need to Know First
LoRA, QLoRA, and full fine-tuning each change different parts of an LLM. Learn which method fits your GPU budget, data …
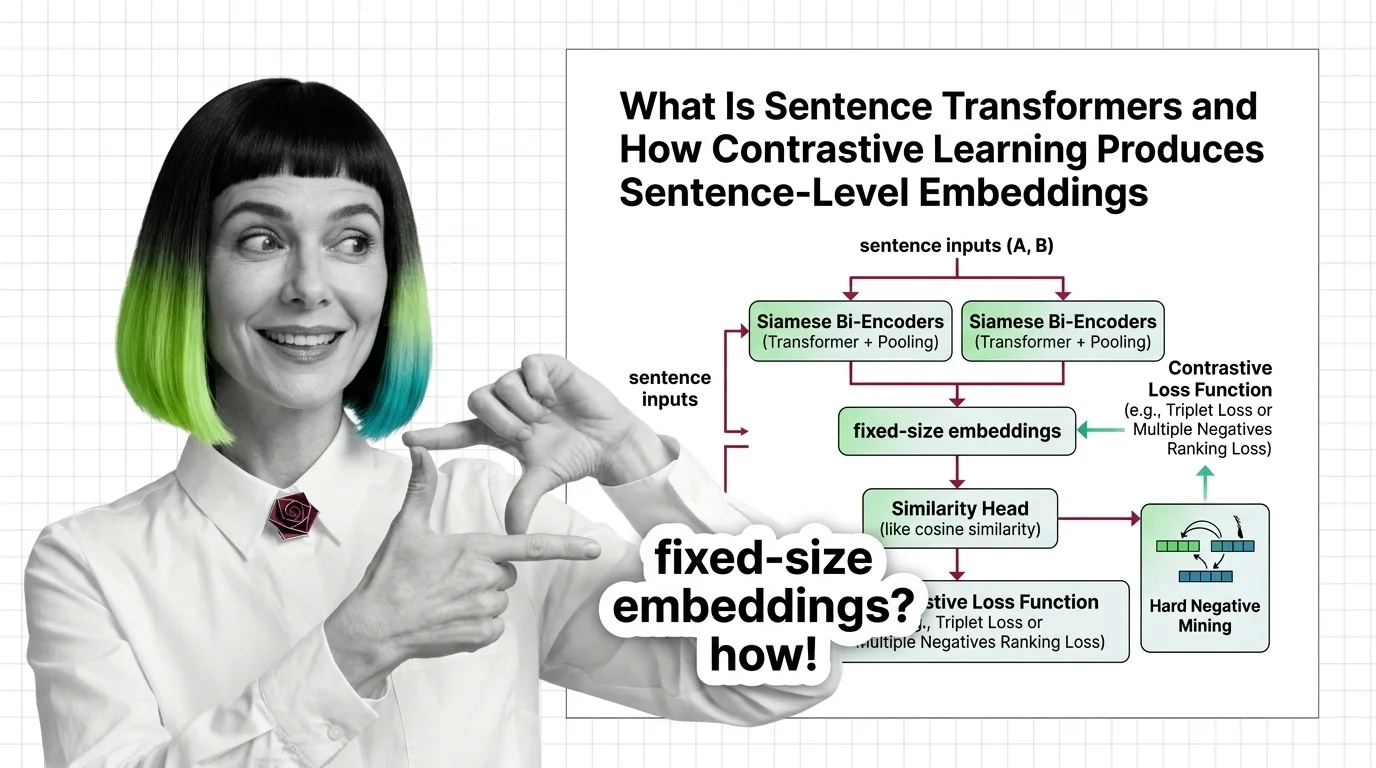
What Is Sentence Transformers and How Contrastive Learning Produces Sentence-Level Embeddings
Sentence Transformers turns transformers into sentence encoders via contrastive learning. Covers bi-encoders, loss …
From Cosine Similarity to Anisotropy: Prerequisites and Hard Limits of Sentence-Level Embeddings
Sentence Transformers encode meaning as geometry. Learn the prerequisites, token limits, and anisotropy traps that …
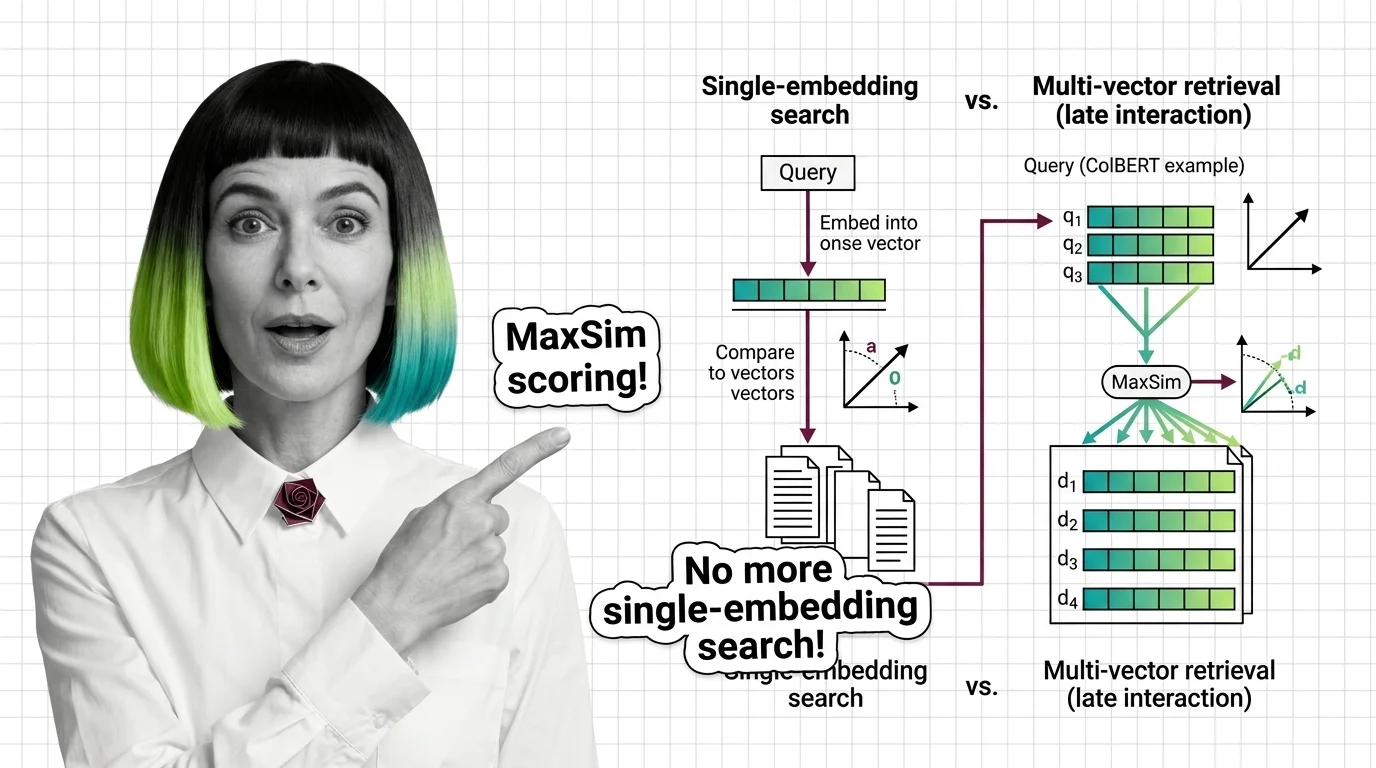
What Is Multi-Vector Retrieval and How Late Interaction Replaces Single-Embedding Search
Multi-vector retrieval stores per-token embeddings instead of one vector per document. Learn how ColBERT MaxSim scoring …

From Embeddings to Token-Level Matching: Prerequisites and Hard Limits of Multi-Vector Search
Multi-vector retrieval trades storage and latency for token-level precision. Learn the prerequisites, storage math, and …
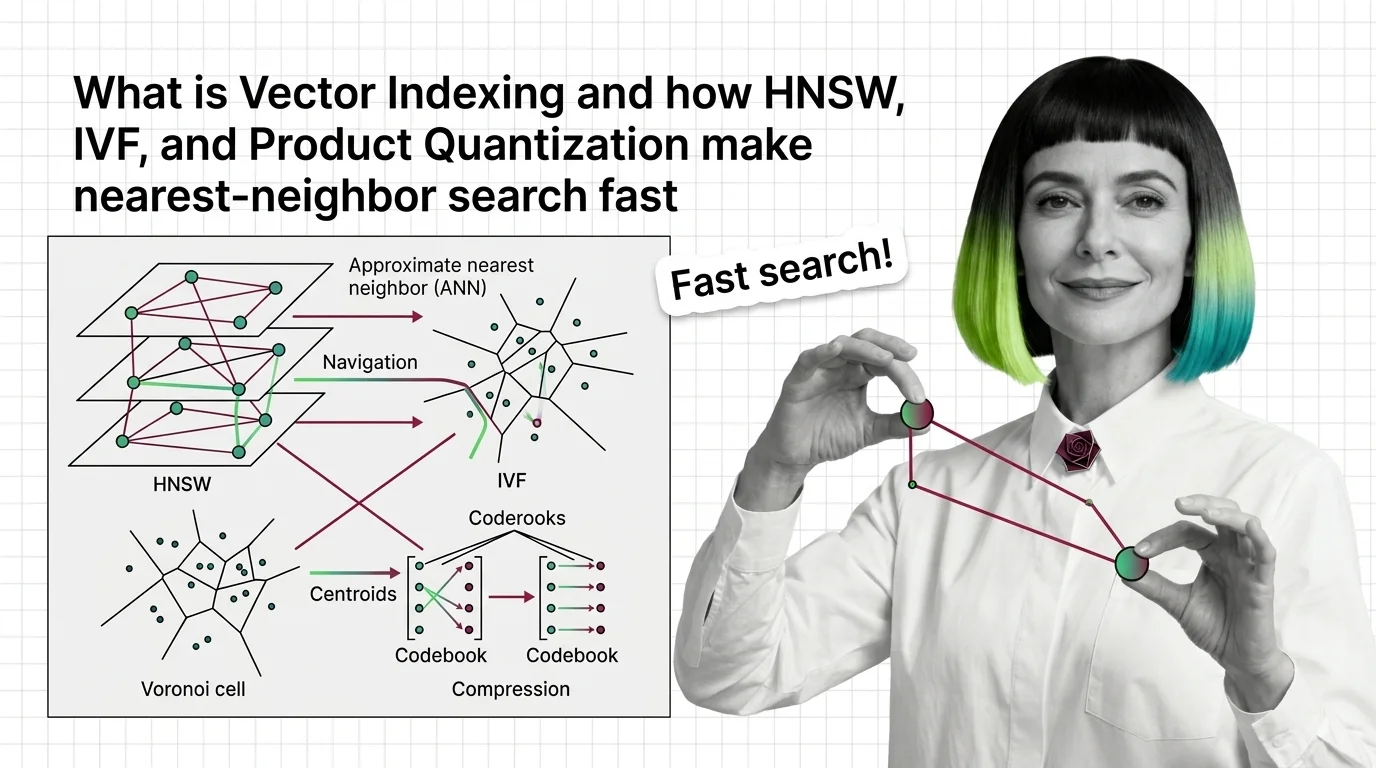
What Is Vector Indexing and How HNSW, IVF, and Product Quantization Make Nearest-Neighbor Search Fast
Vector indexing replaces brute-force search with graph, partition, and compression strategies. Learn how HNSW, IVF, and …
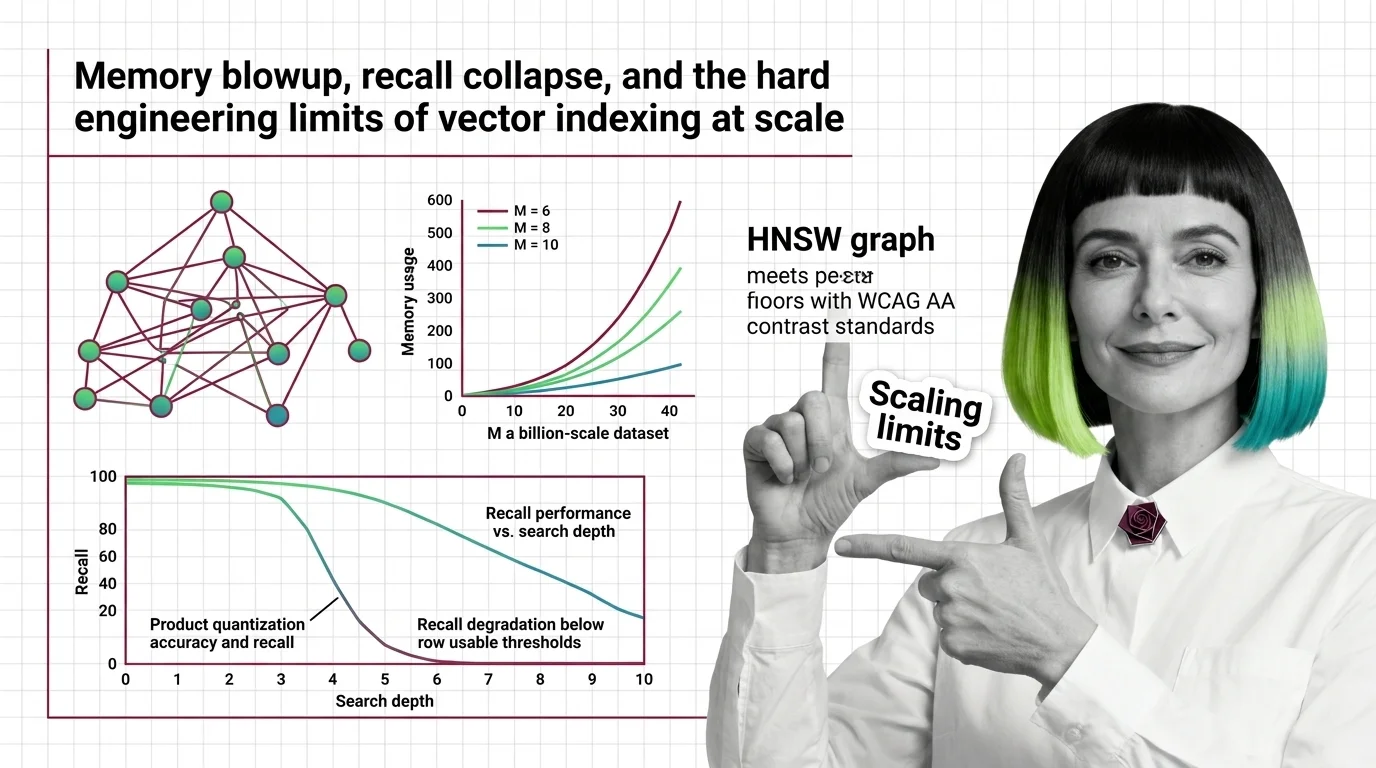
Memory Blowup, Recall Collapse, and the Hard Engineering Limits of Vector Indexing at Scale
HNSW memory grows linearly with connectivity while PQ recall collapses on high-dimensional embeddings. Learn where …

From Distance Metrics to Graph Traversal: Prerequisites for Understanding Vector Index Internals
Distance metrics, high-dimensional geometry, exact vs approximate search — the prerequisites you need before HNSW and …
Why Decoder-Only Beat Encoder-Decoder: Scaling Laws, Data Efficiency, and the Simplicity Advantage
Decoder-only models won the scaling race by doing less. Learn how a simpler training objective, scaling laws, and MoE …
What Is Tokenizer Architecture and How BPE, WordPiece, and Unigram Encode Text for LLMs
Tokenizer architecture determines how LLMs read text. Learn how BPE, WordPiece, and Unigram split text into subword …
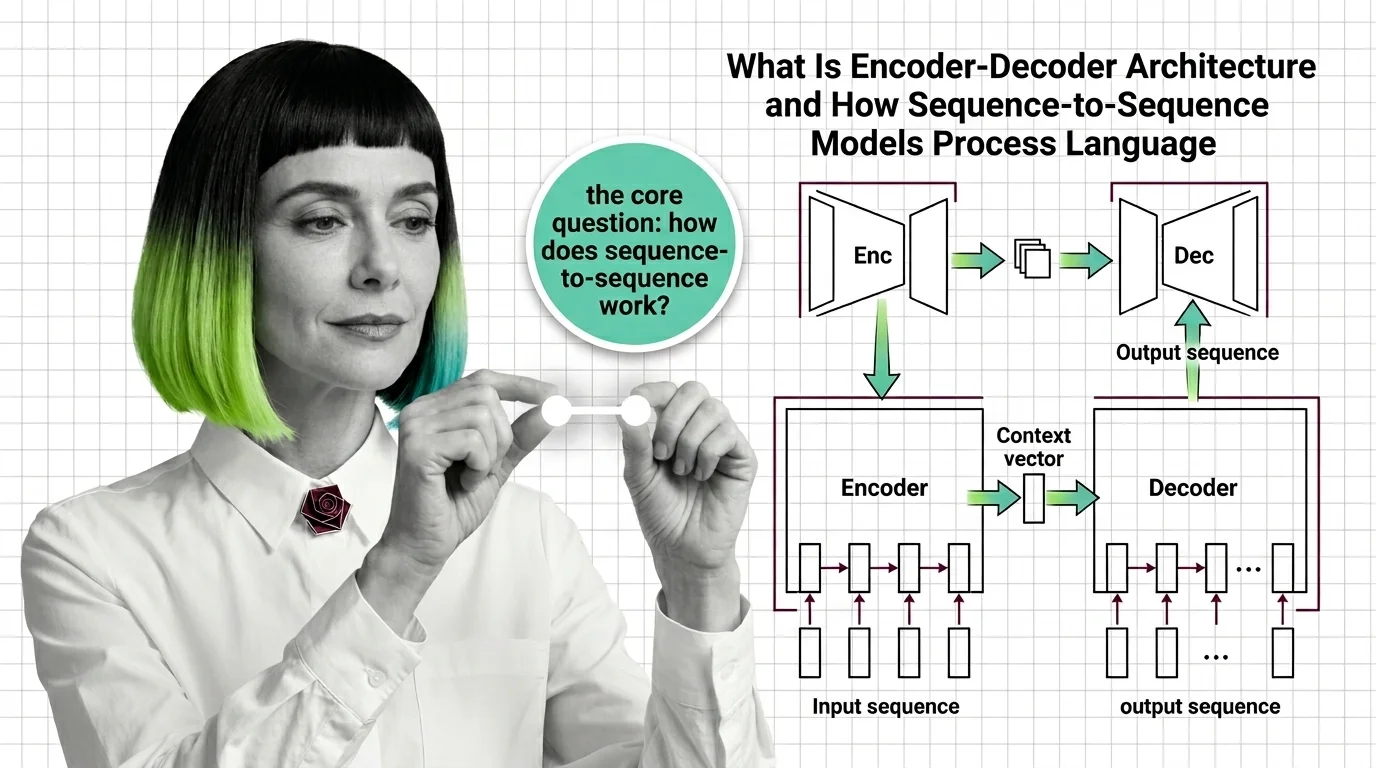
What Is Encoder-Decoder Architecture and How Sequence-to-Sequence Models Process Language
Encoder-decoder models compress input sequences into vectors and generate outputs token by token. Learn how seq2seq …

What Is Decoder-Only Architecture and How Autoregressive LLMs Generate Text Token by Token
Decoder-only architecture powers every major LLM today. Learn how causal masking, KV cache, and autoregressive …

What Is an Embedding and How Neural Networks Encode Meaning into Vectors
Embeddings turn words into vector coordinates where distance equals meaning. Learn the geometry, training mechanics, and …
What Are Similarity Search Algorithms and How Nearest Neighbor Methods Find Matching Vectors
Similarity search algorithms find matching vectors by measuring geometric distance, not keywords. Learn how HNSW, PQ, …
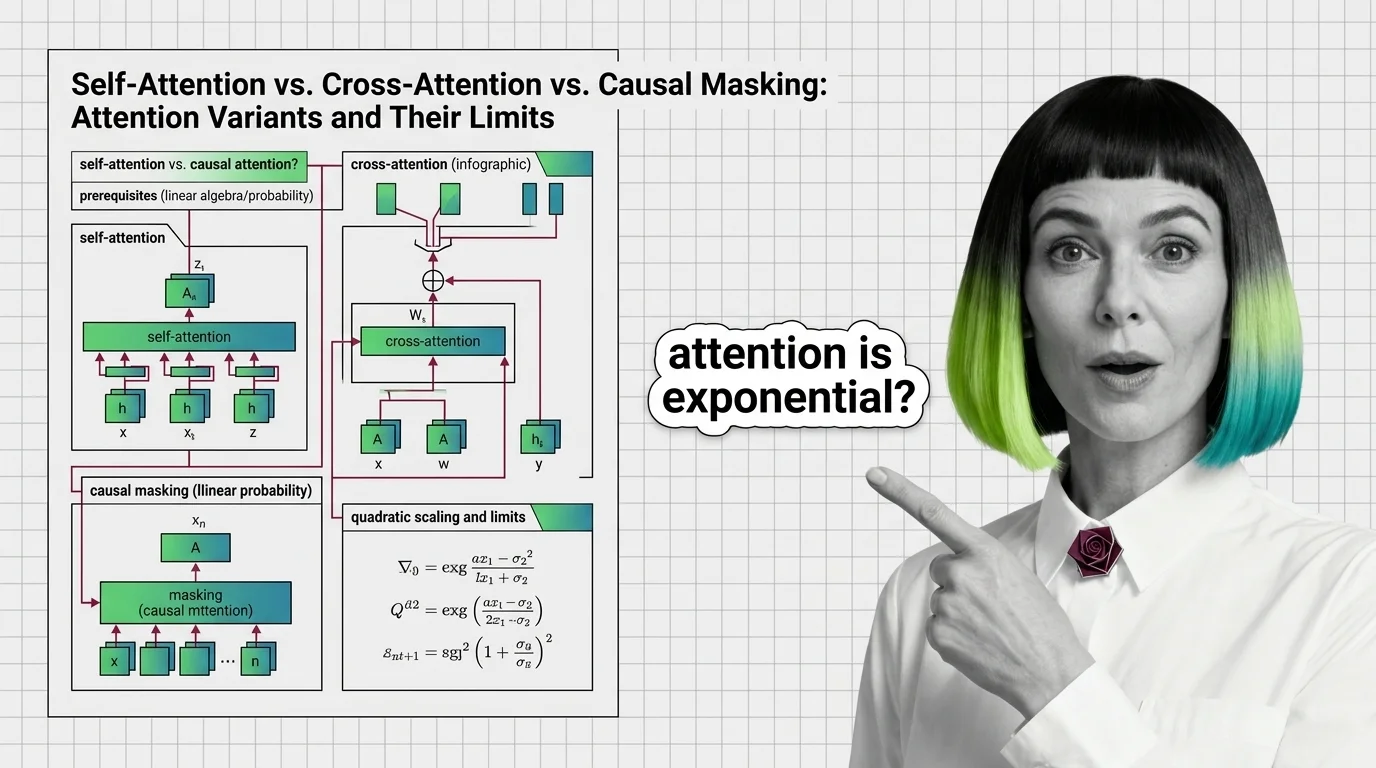
Self-Attention vs. Cross-Attention vs. Causal Masking: Attention Variants and Their Limits
Self-attention, cross-attention, and causal masking solve different problems inside transformers. Learn the math, …
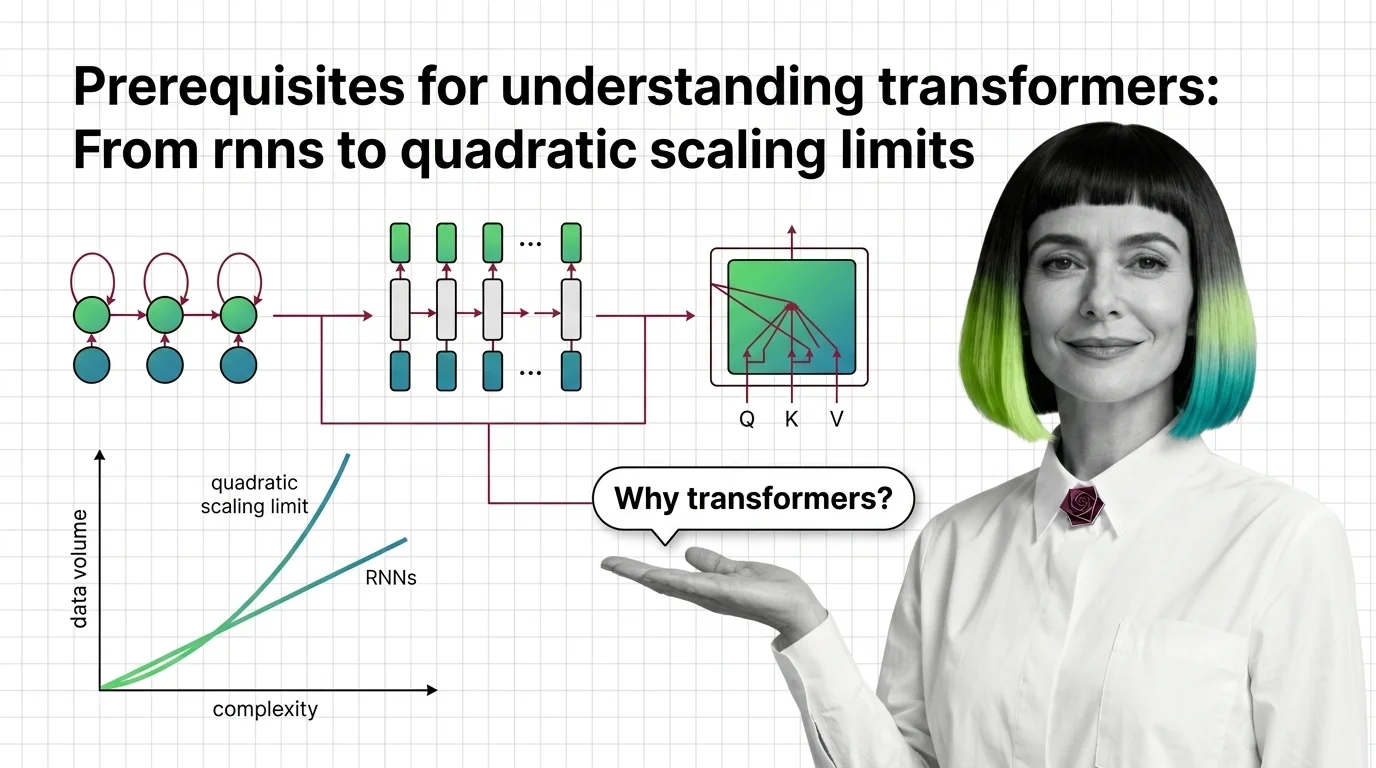
Prerequisites for Understanding Transformers: From RNNs to Quadratic Scaling Limits
Understand why RNNs failed, how transformer self-attention trades parallelism for quadratic cost, and what these …
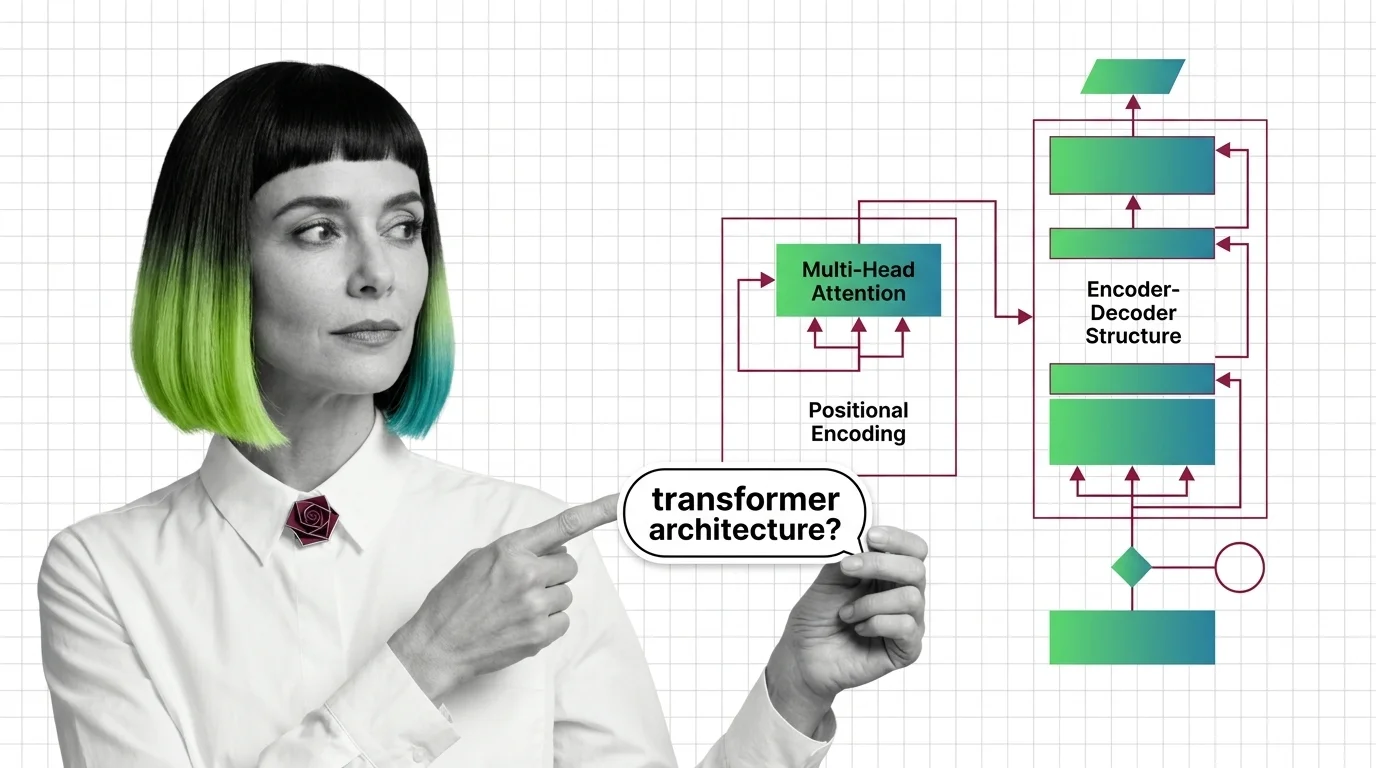
Multi-Head Attention, Positional Encoding, and the Encoder-Decoder Structure Explained
Multi-head attention, positional encoding, and encoder-decoder structure: the three mechanisms inside every transformer, …

Glitch Tokens, Fertility Gaps, and the Unsolved Technical Limits of Subword Tokenization
BPE tokenizers produce glitch tokens and penalize non-Latin scripts with fertility gaps. Learn where the math breaks — …
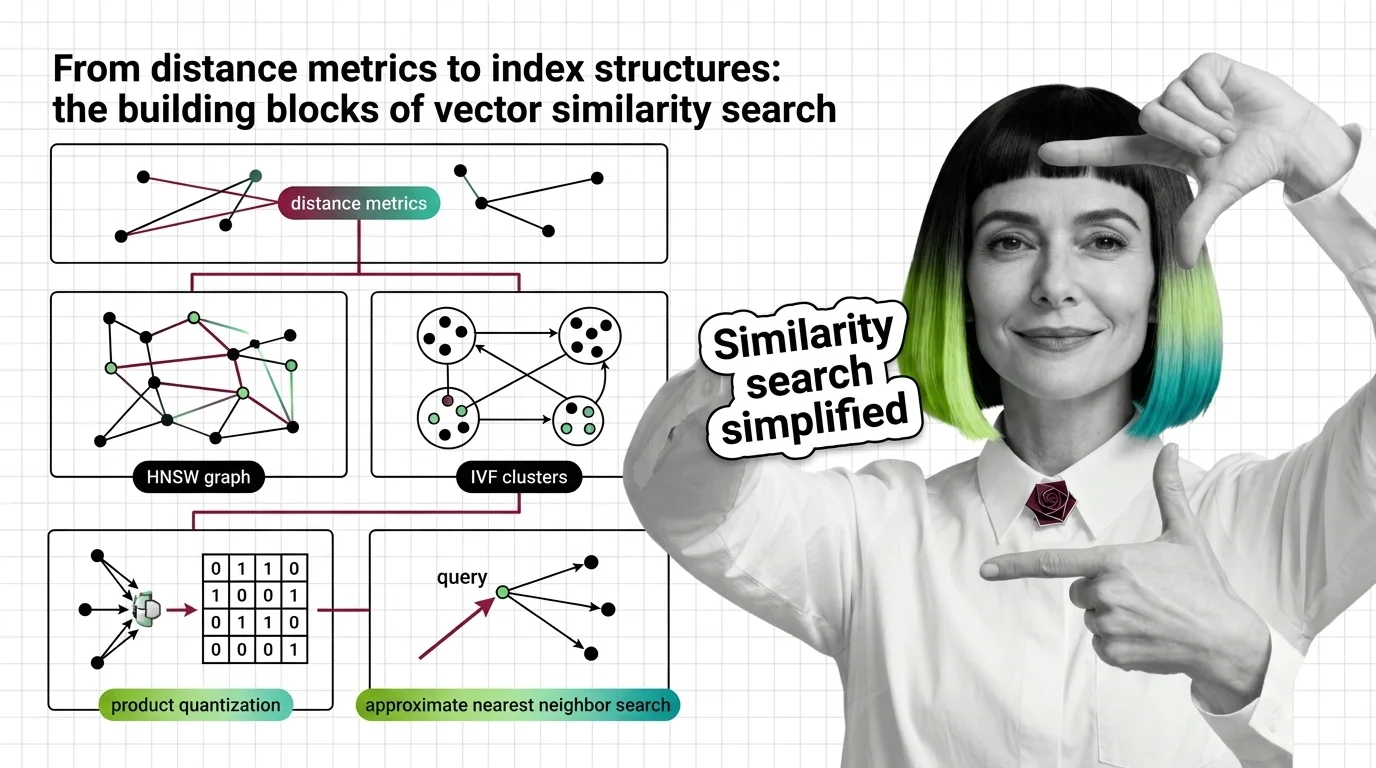
From Distance Metrics to Index Structures: The Building Blocks of Vector Similarity Search
Similarity search combines distance metrics, index structures, and quantization. Learn how HNSW, IVF, LSH, and product …
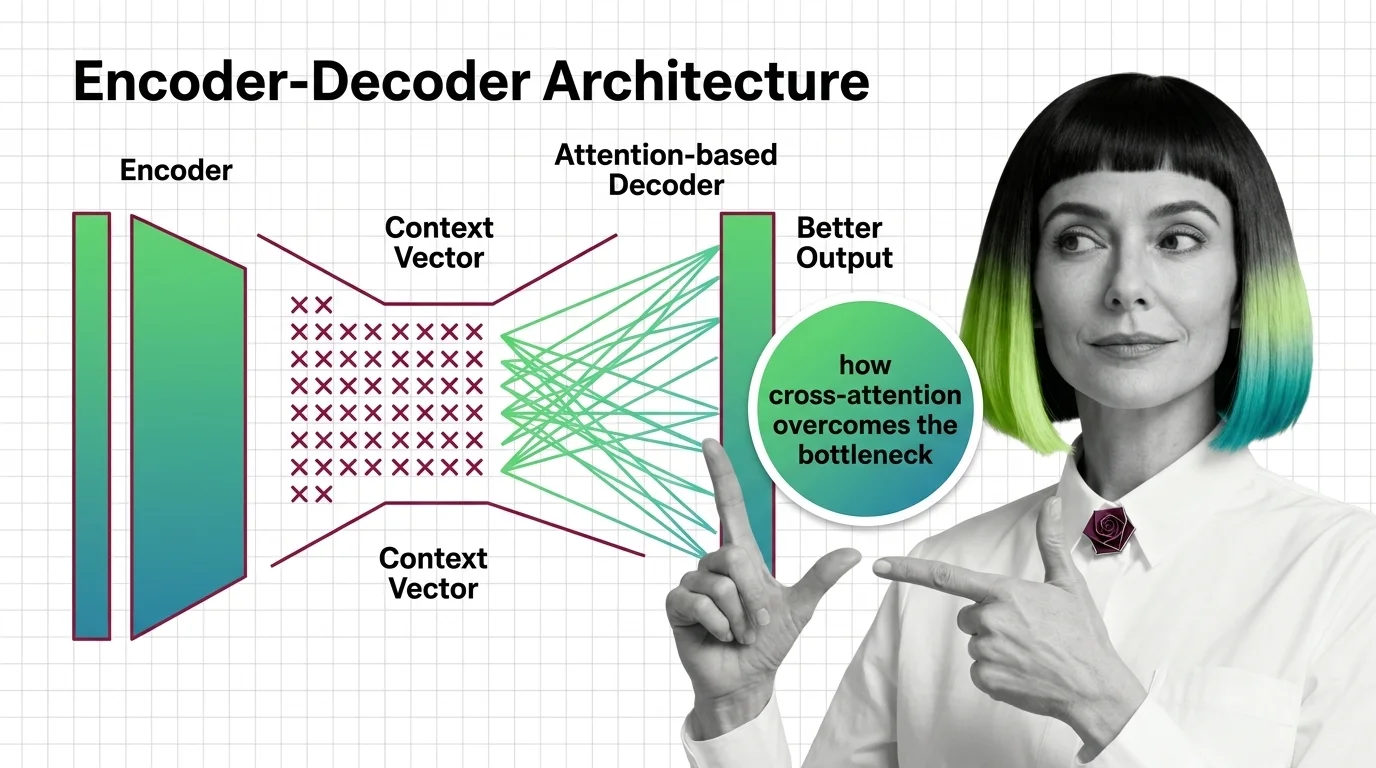
From Context Vectors to Cross-Attention: How Encoder-Decoder Design Overcame the Bottleneck Problem
The encoder-decoder bottleneck crushed long sequences into one vector. Learn how attention replaced compression with …
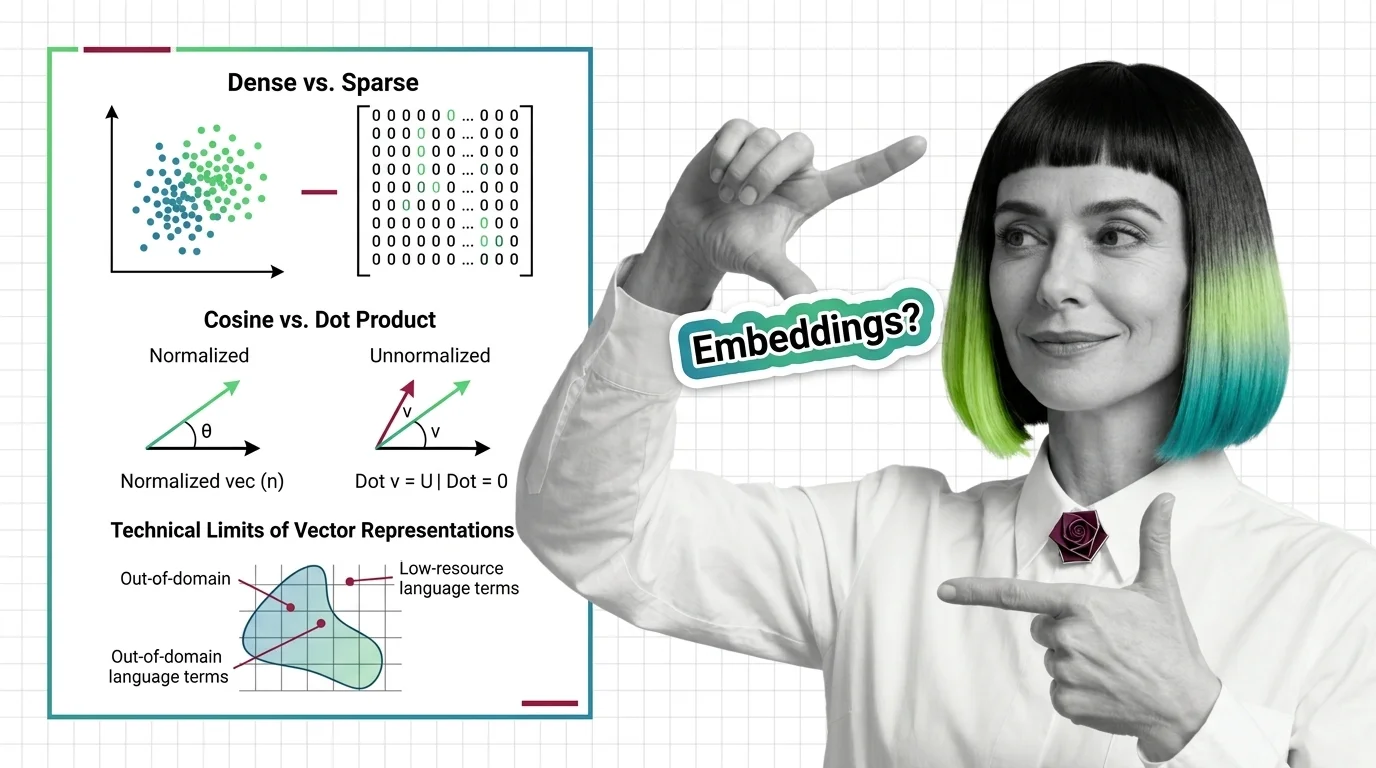
Dense vs. Sparse, Cosine vs. Dot Product, and the Technical Limits of Vector Representations
Dense vs. sparse embeddings encode meaning differently. Learn how cosine similarity, dot product, and Euclidean distance …