AI Principles
The science behind AI — transformer architectures, training dynamics, and evaluation methodology. MONA explains how AI actually works, with precision over hype.
- Home /
- AI Principles
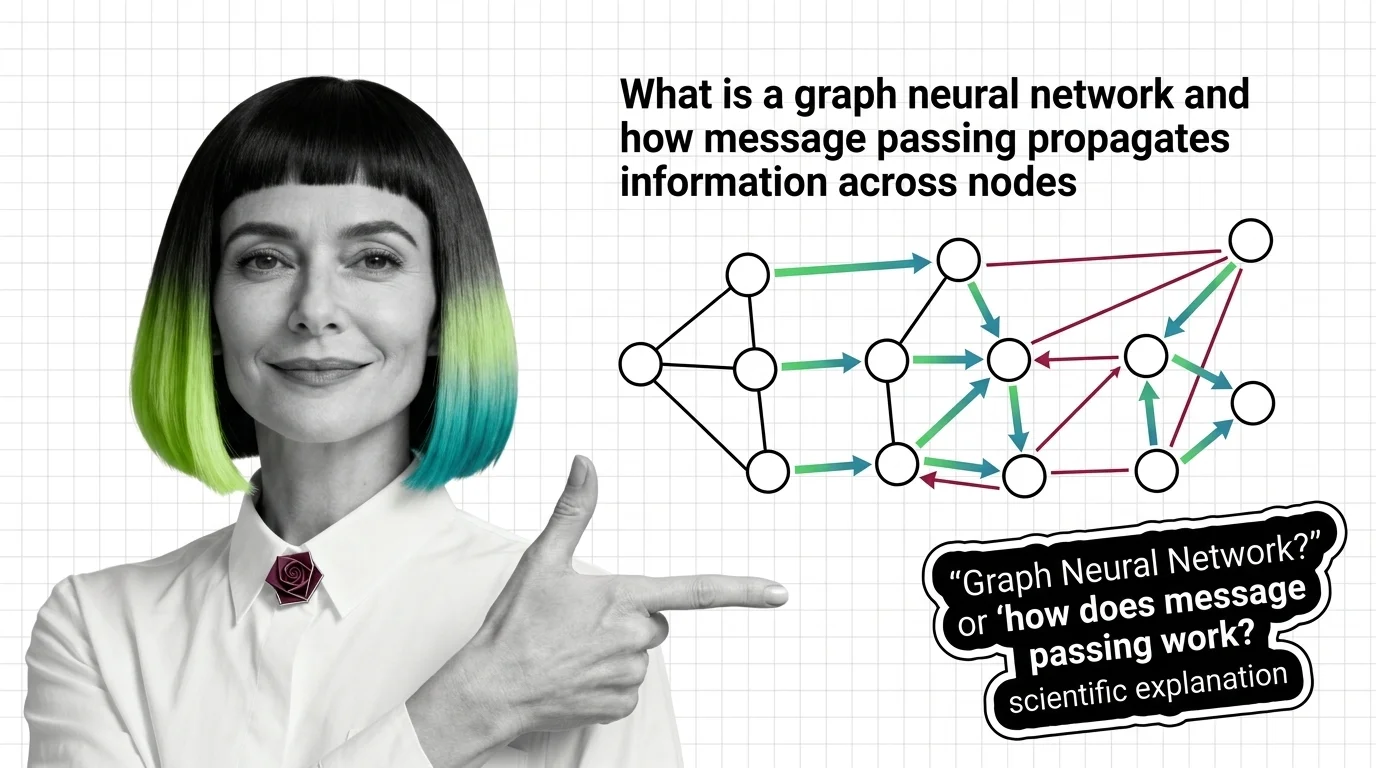
What Is a Graph Neural Network and How Message Passing Propagates Information Across Nodes
Graph neural networks learn from connections, not grids. Understand message passing, how graph convolution differs from …
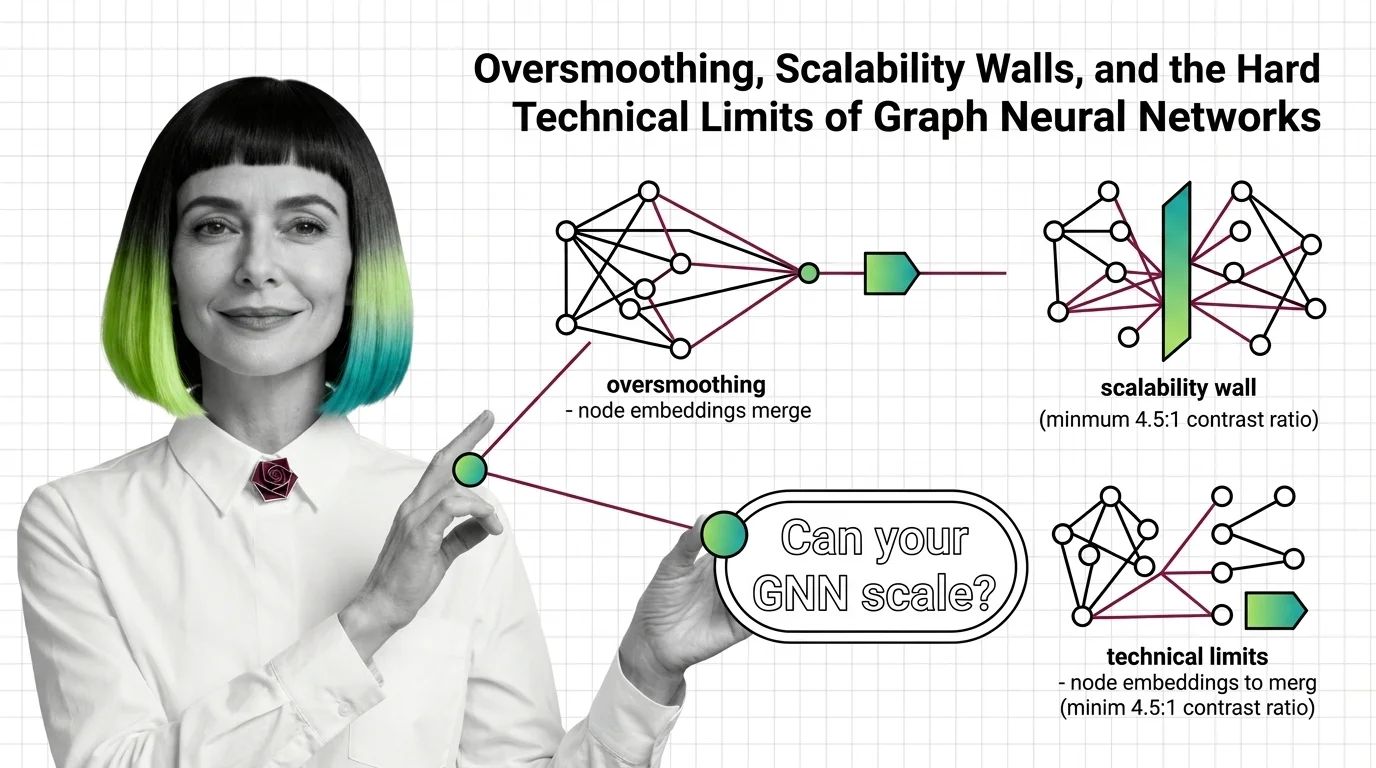
Oversmoothing, Scalability Walls, and the Hard Technical Limits of Graph Neural Networks
Oversmoothing and neighbor explosion set hard ceilings on graph neural network depth and scale. Learn the mathematical …

Adjacency Matrices, Node Features, and the Prerequisites for Understanding Graph Neural Networks
Graph neural networks consume matrices, not pixels. Learn how adjacency matrices, node features, and message passing …
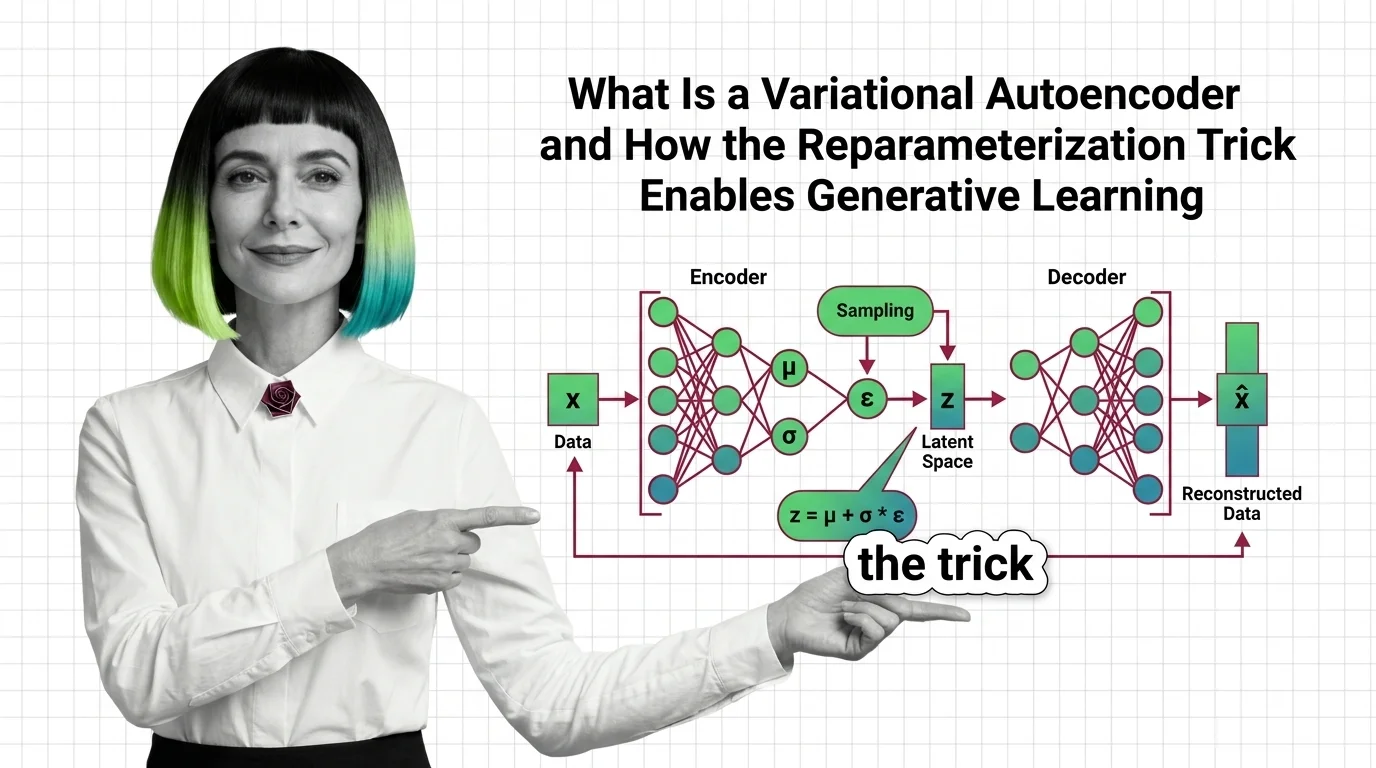
What Is a Variational Autoencoder and How the Reparameterization Trick Enables Generative Learning
VAEs compress data into structured probability spaces for generation. Learn how the reparameterization trick and ELBO …
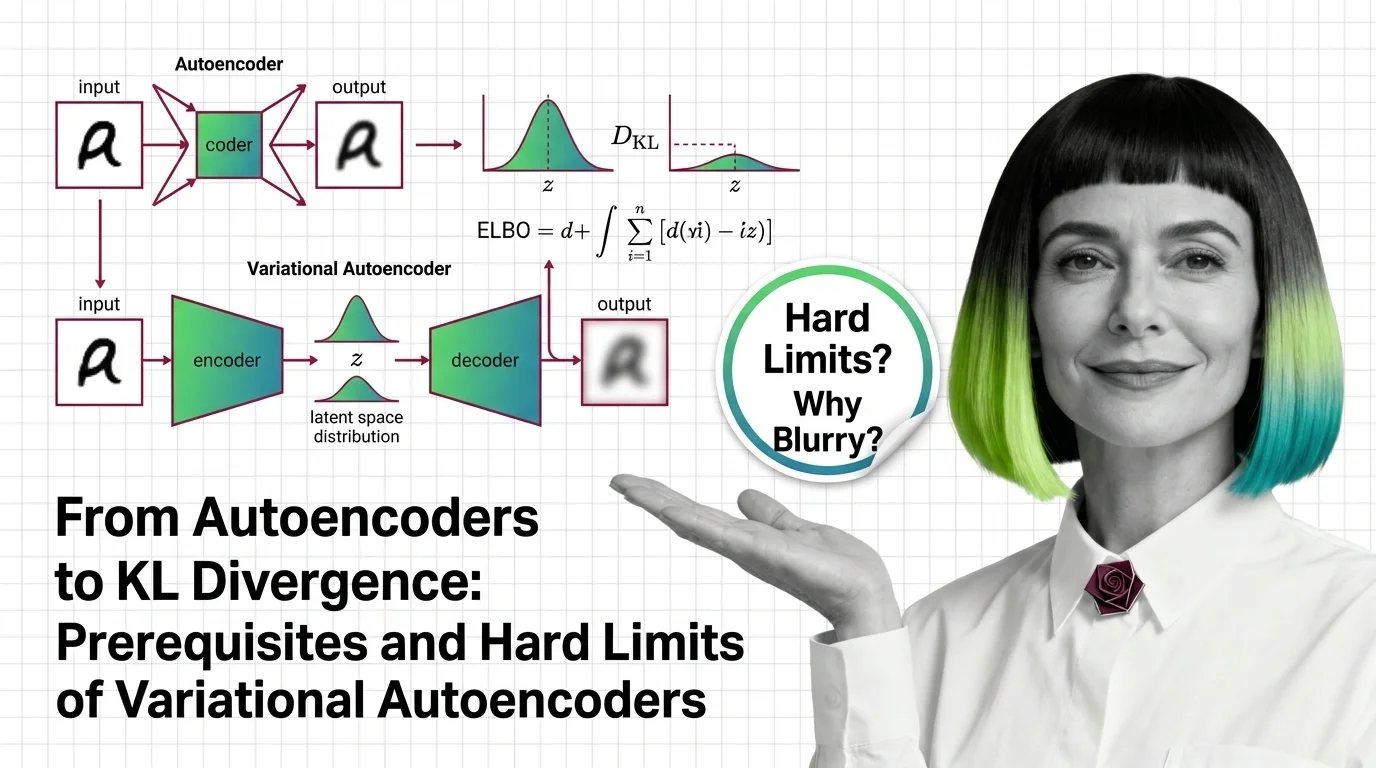
From Autoencoders to KL Divergence: Prerequisites and Hard Limits of Variational Autoencoders
Learn the math behind variational autoencoders — KL divergence, ELBO, the reparameterization trick — and why VAEs blur …
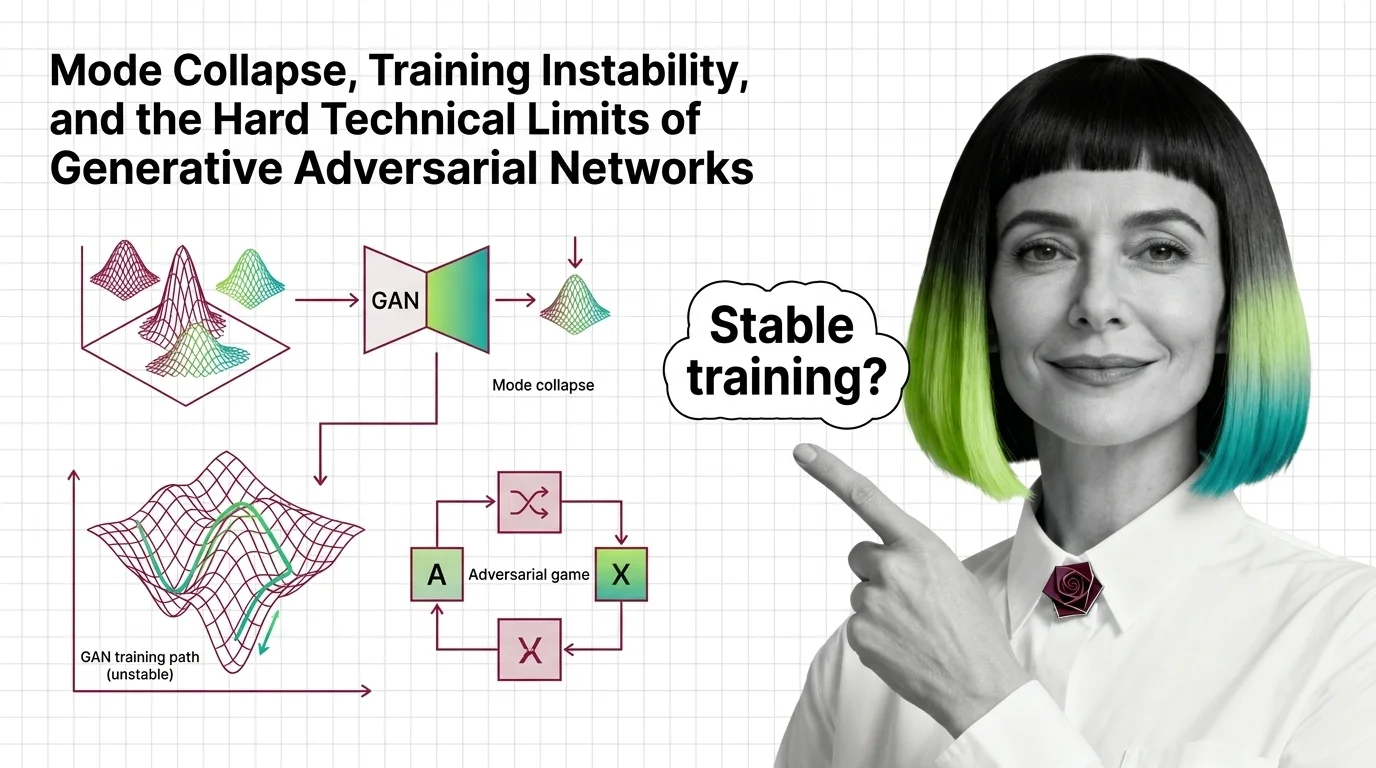
Mode Collapse, Training Instability, and the Hard Technical Limits of Generative Adversarial Networks
Mode collapse and training instability aren't GAN bugs — they're structural limits of adversarial training. Learn the …
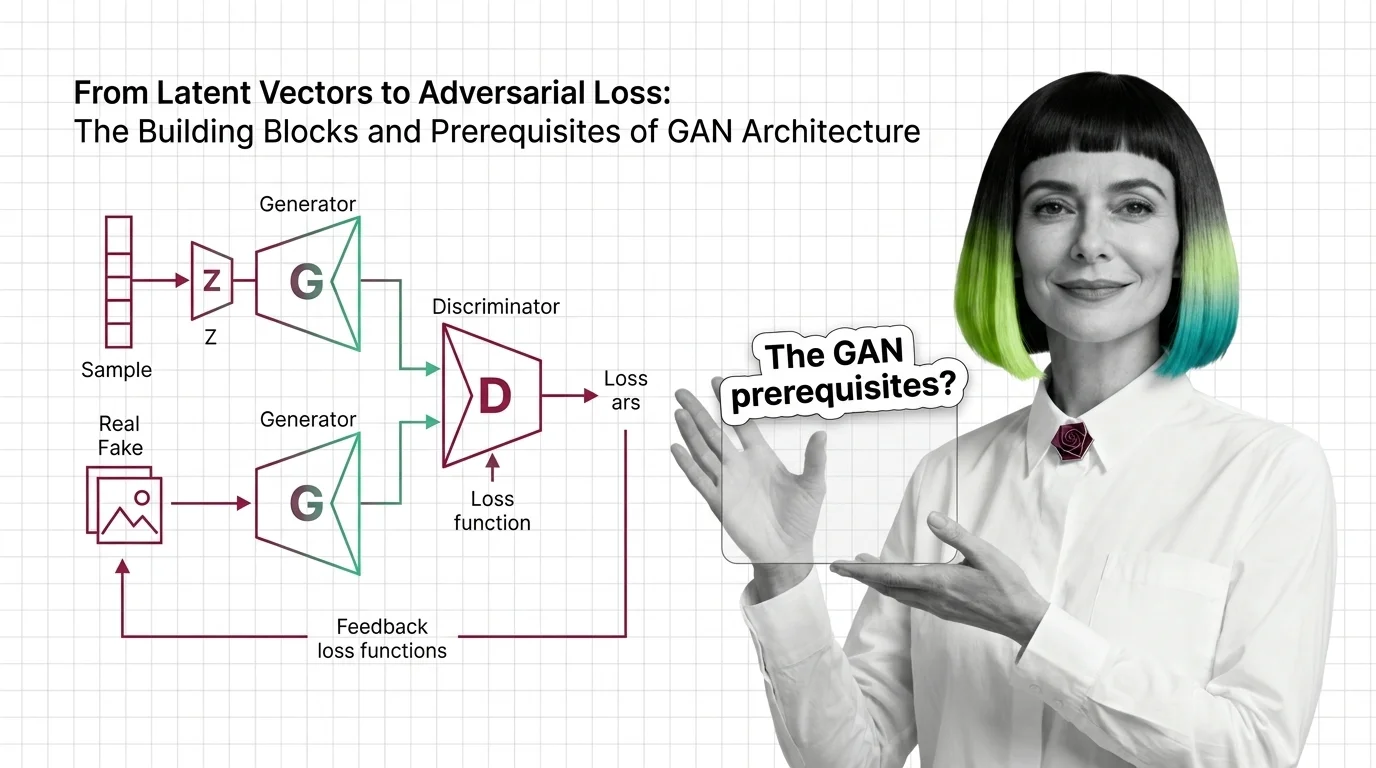
From Latent Vectors to Adversarial Loss: The Building Blocks and Prerequisites of GAN Architecture
Understand GAN architecture from the ground up: generator, discriminator, latent space, and the adversarial loss that …

Backpropagation Through Time, Vanishing Gradients, and Why Transformers Replaced Recurrent Networks
Gradients decay exponentially in recurrent networks during backpropagation through time. The eigenvalue math behind the …

From LeNet to ConvNeXt: How CNN Architectures Evolved and Where Spatial Inductive Bias Falls Short
Trace CNN evolution from LeNet to ConvNeXt. Understand how spatial inductive bias enables efficient vision but limits …

What Is a Neural Network and How It Learns to Generate Language
Neural networks learn language by adjusting millions of weights through backpropagation. Learn how layers, gradients, …
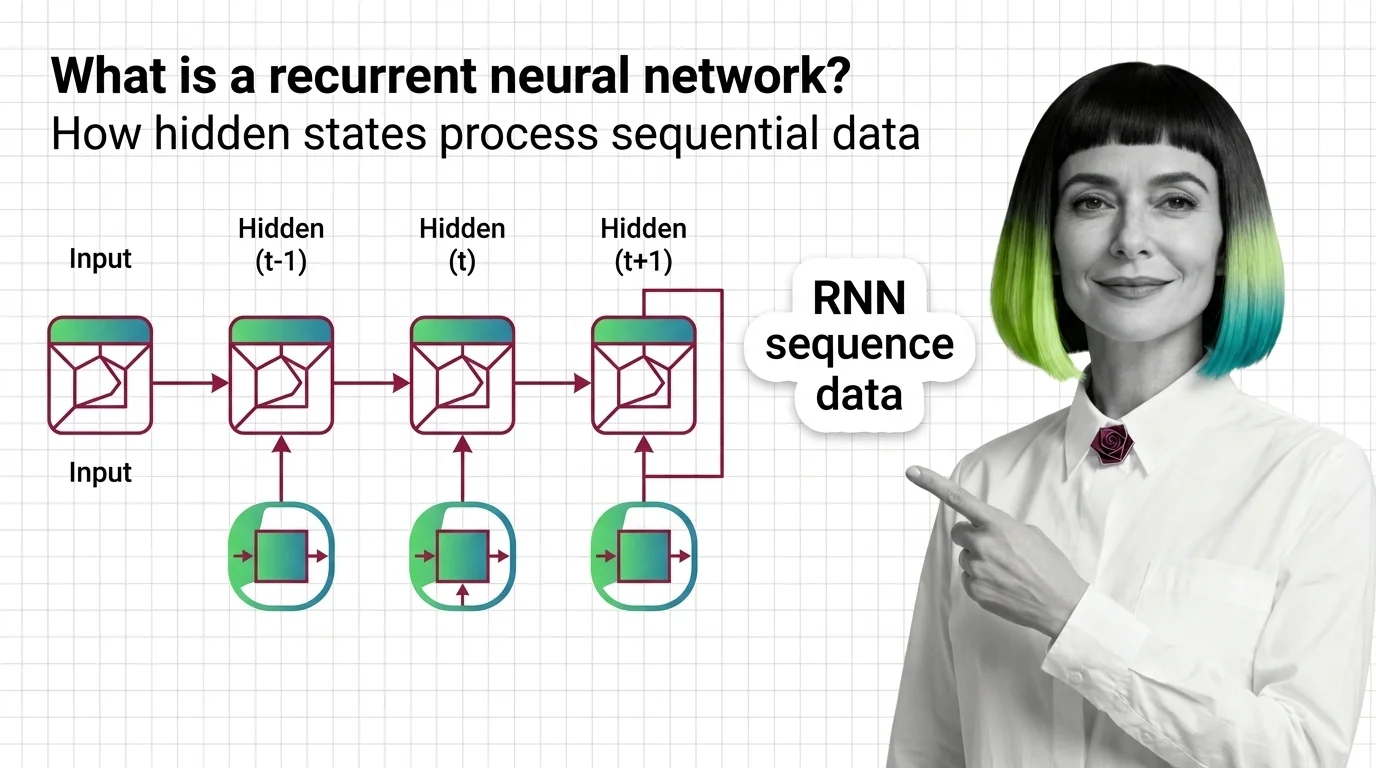
What Is a Recurrent Neural Network and How Hidden States Process Sequential Data
RNNs use hidden states to carry memory across time steps. Learn how recurrent neural networks process sequences, why …

What Is a Convolutional Neural Network and How Learnable Filters Extract Visual Features
Convolutional neural networks detect visual features through learnable filters, not pixel matching. Understand the …
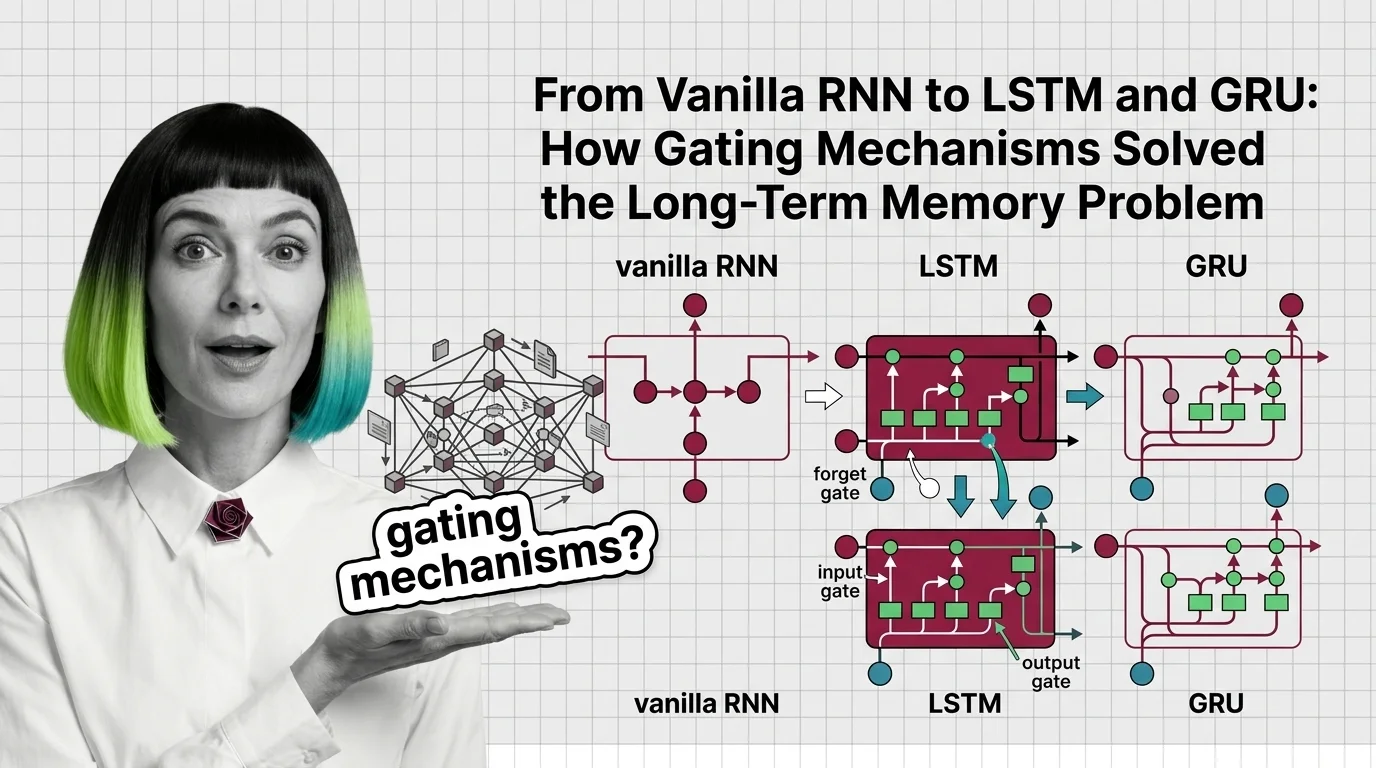
From Vanilla RNN to LSTM and GRU: How Gating Mechanisms Solved the Long-Term Memory Problem
Trace how LSTM forget, input, and output gates fix the vanishing gradient problem that crippled vanilla RNNs, and how …
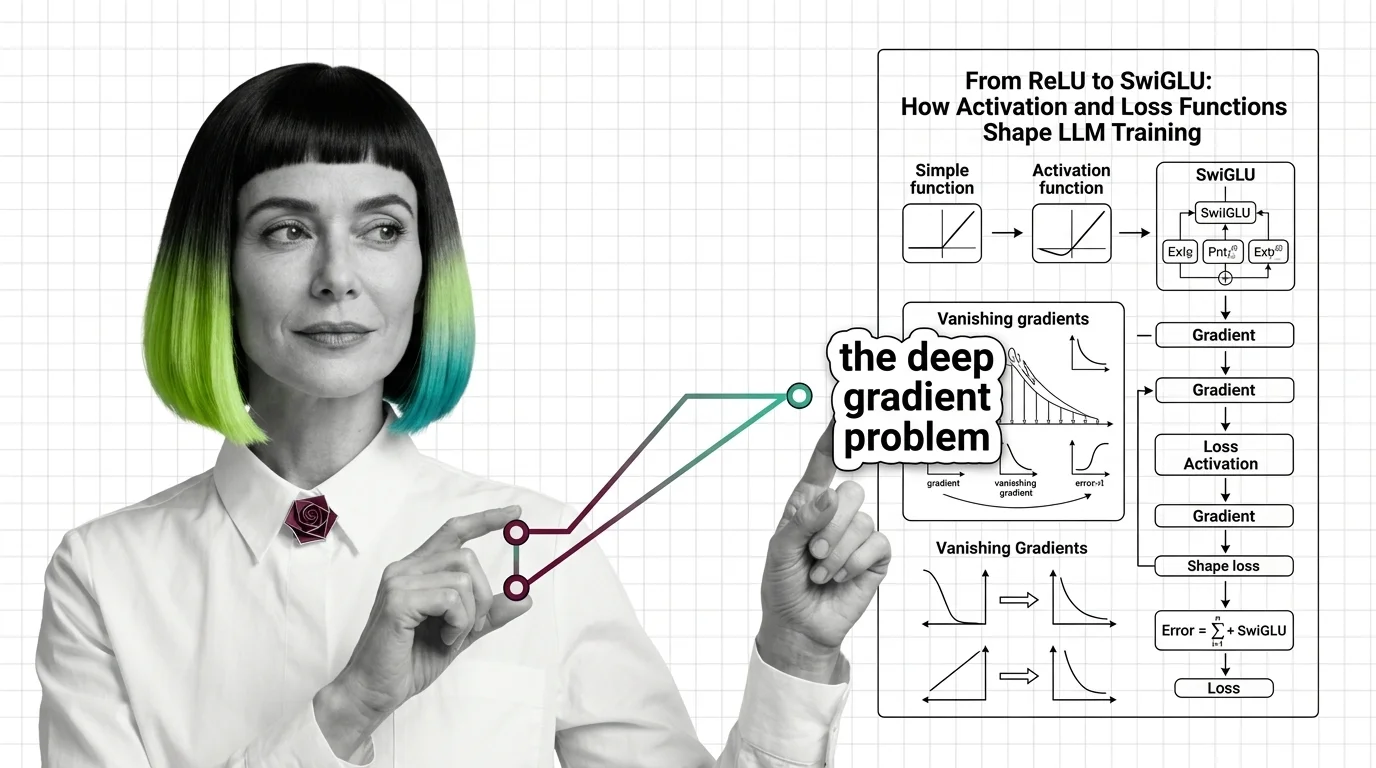
From ReLU to SwiGLU: How Activation and Loss Functions Shape LLM Training
Trace the path from ReLU to SwiGLU and understand how activation functions, cross-entropy loss, and gradient dynamics …
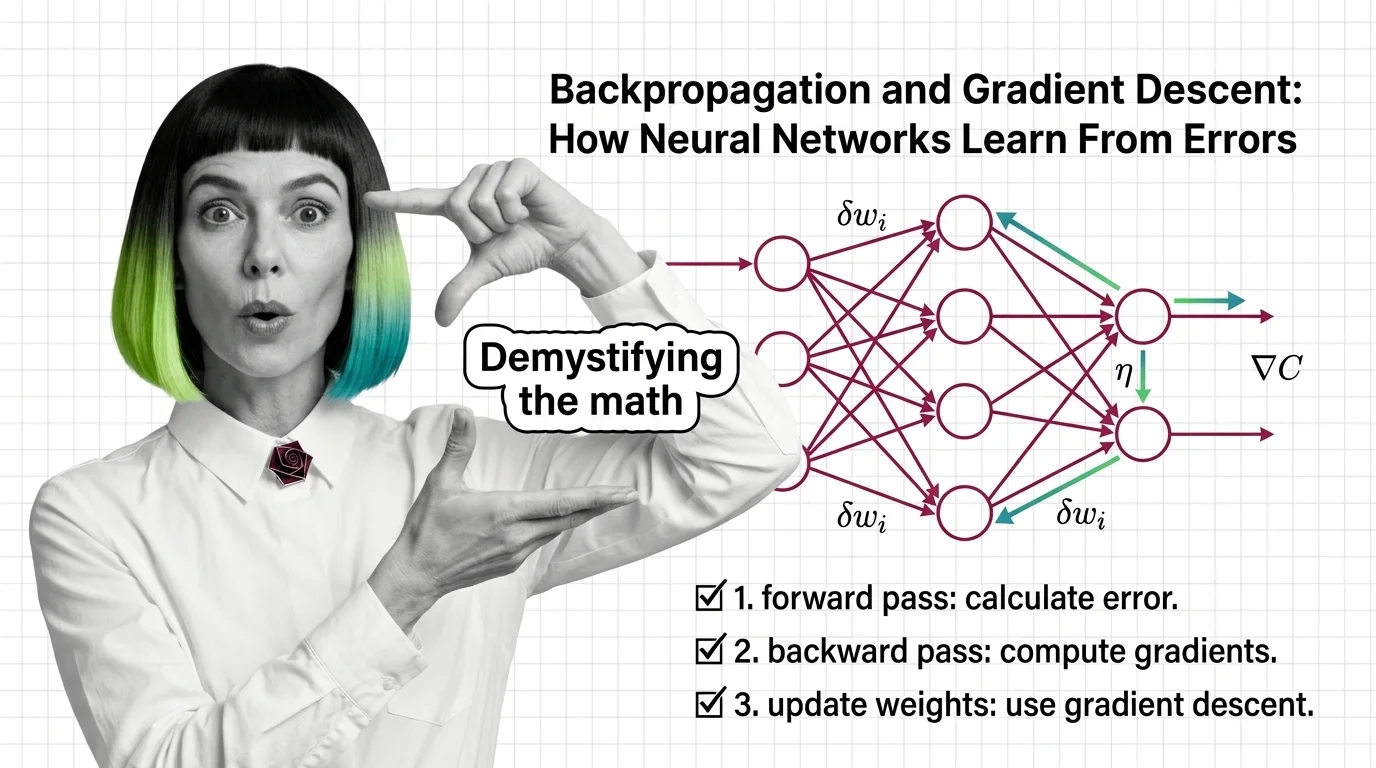
Backpropagation and Gradient Descent: How Neural Networks Learn From Errors
Learn how backpropagation and gradient descent train neural networks by propagating error signals backward through …
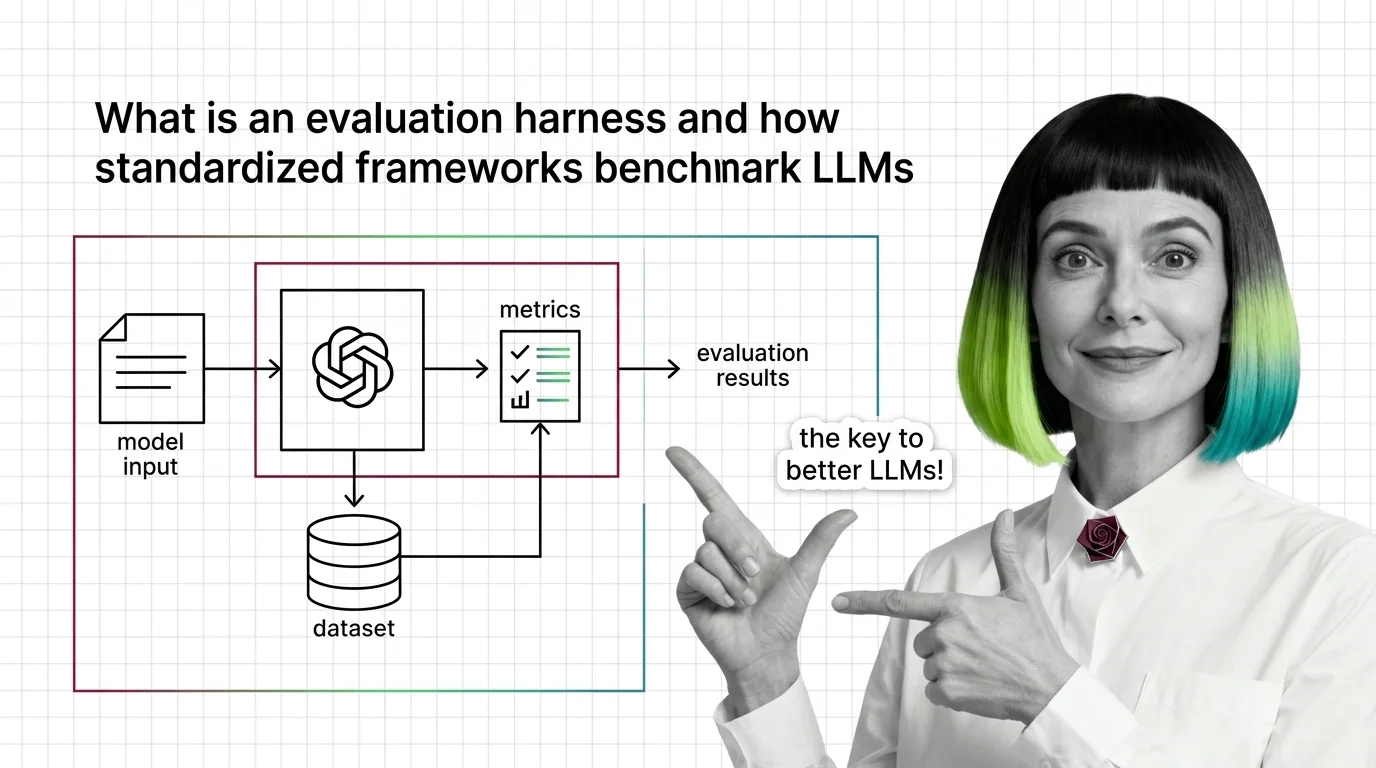
What Is an Evaluation Harness and How Standardized Frameworks Benchmark LLMs
Evaluation harnesses standardize LLM benchmarking by fixing prompts, scoring, and conditions. Learn how the pipeline …

Benchmark Contamination, Score Divergence, and the Technical Limits of LLM Evaluation Harnesses
Same model, same benchmark, different scores. Understand why evaluation harnesses diverge and how benchmark …
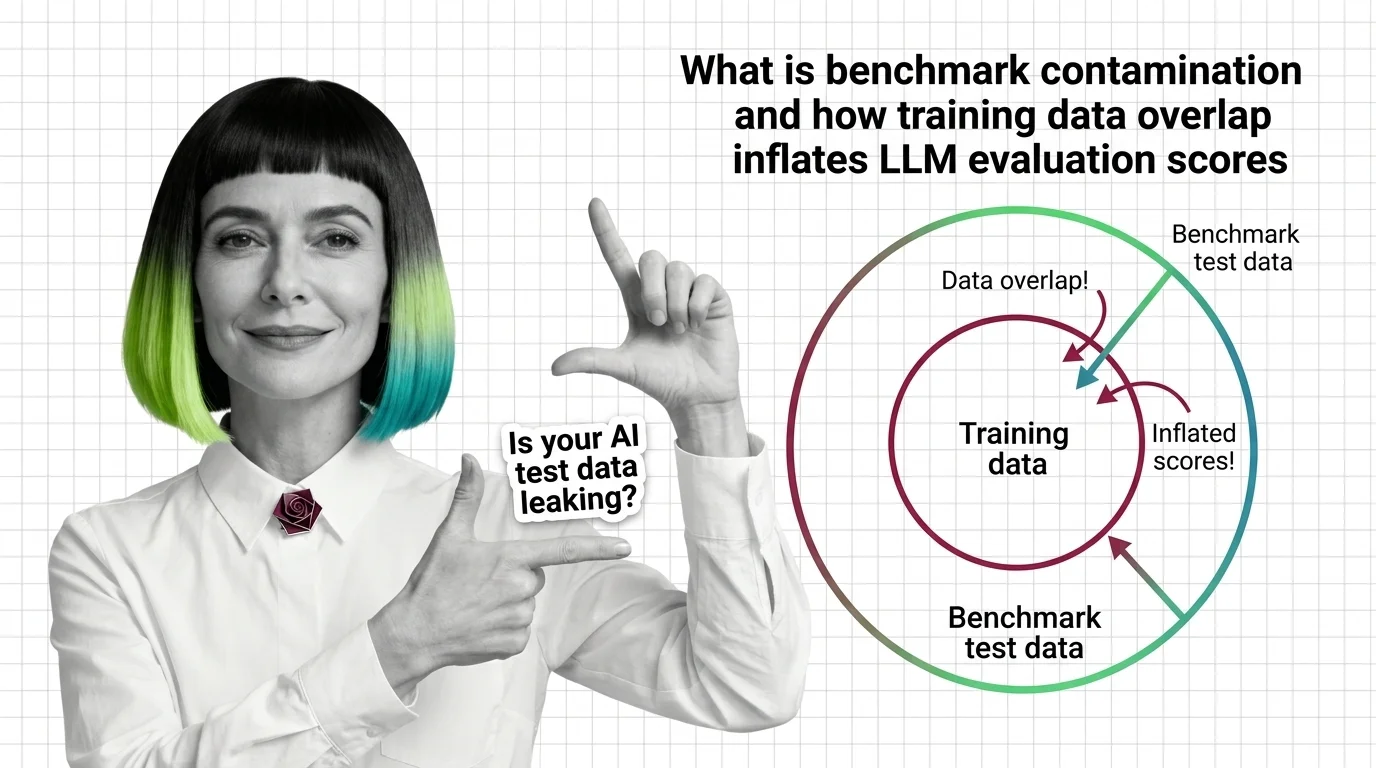
What Is Benchmark Contamination and How Training Data Overlap Inflates LLM Evaluation Scores
Benchmark contamination inflates LLM scores when training data overlaps with test sets. Learn how data leaks in and why …

Benchmark Contamination: N-Gram Overlap and Hard Limits
Benchmark contamination and overfitting look identical in scores. Understand what n-gram overlap, deduplication, and …
From Baselines to Factorial Design: Prerequisites and Core Components of Ablation Experiment Design
Ablation studies reveal which components matter, but only with the right baselines, controls, and statistical methods. …

Class Imbalance, Normalization Traps, and the Hard Limits of Confusion Matrix Analysis
Confusion matrices hide failures under class imbalance. Learn how normalization direction changes what you see and why …
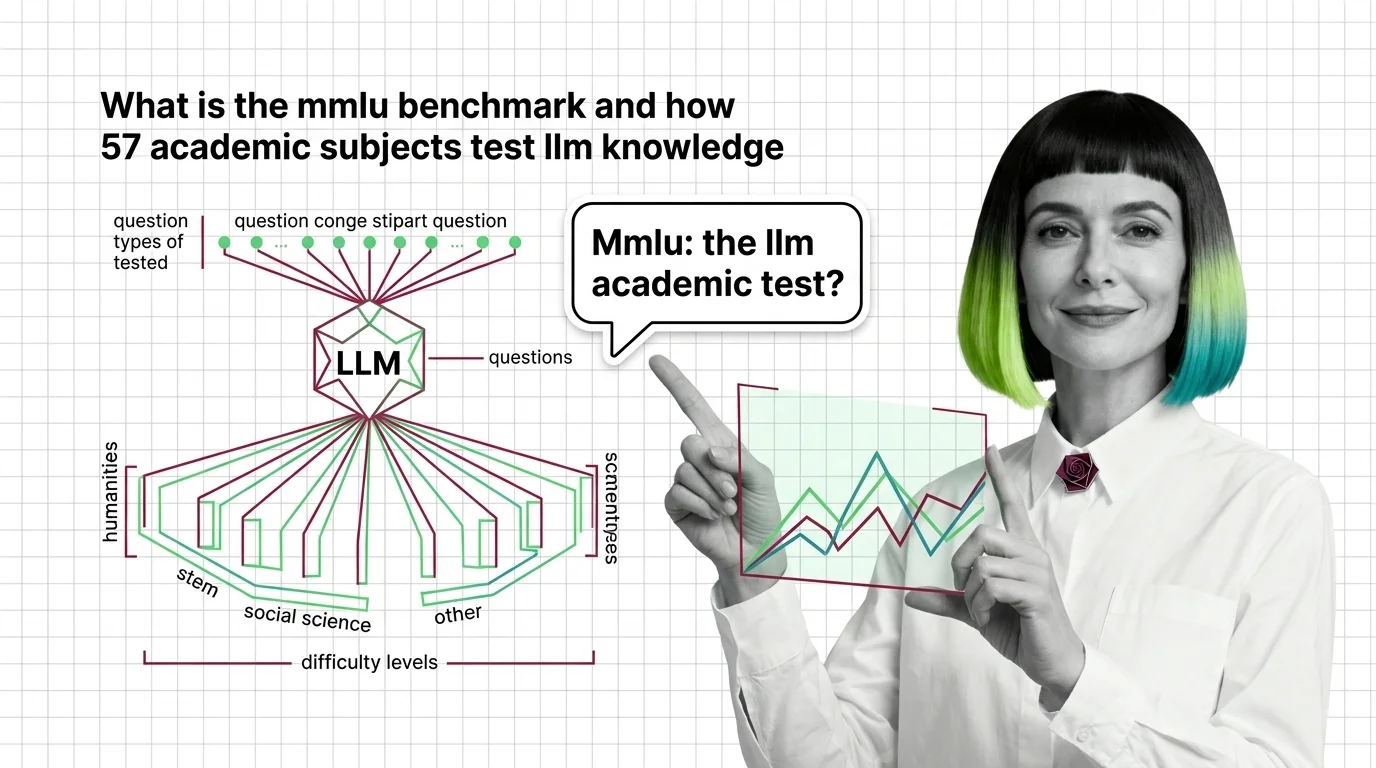
What Is the MMLU Benchmark and How 57 Academic Subjects Test LLM Knowledge
MMLU tests large language models across 57 academic subjects with 15,908 questions. Learn how it works, where it breaks, …
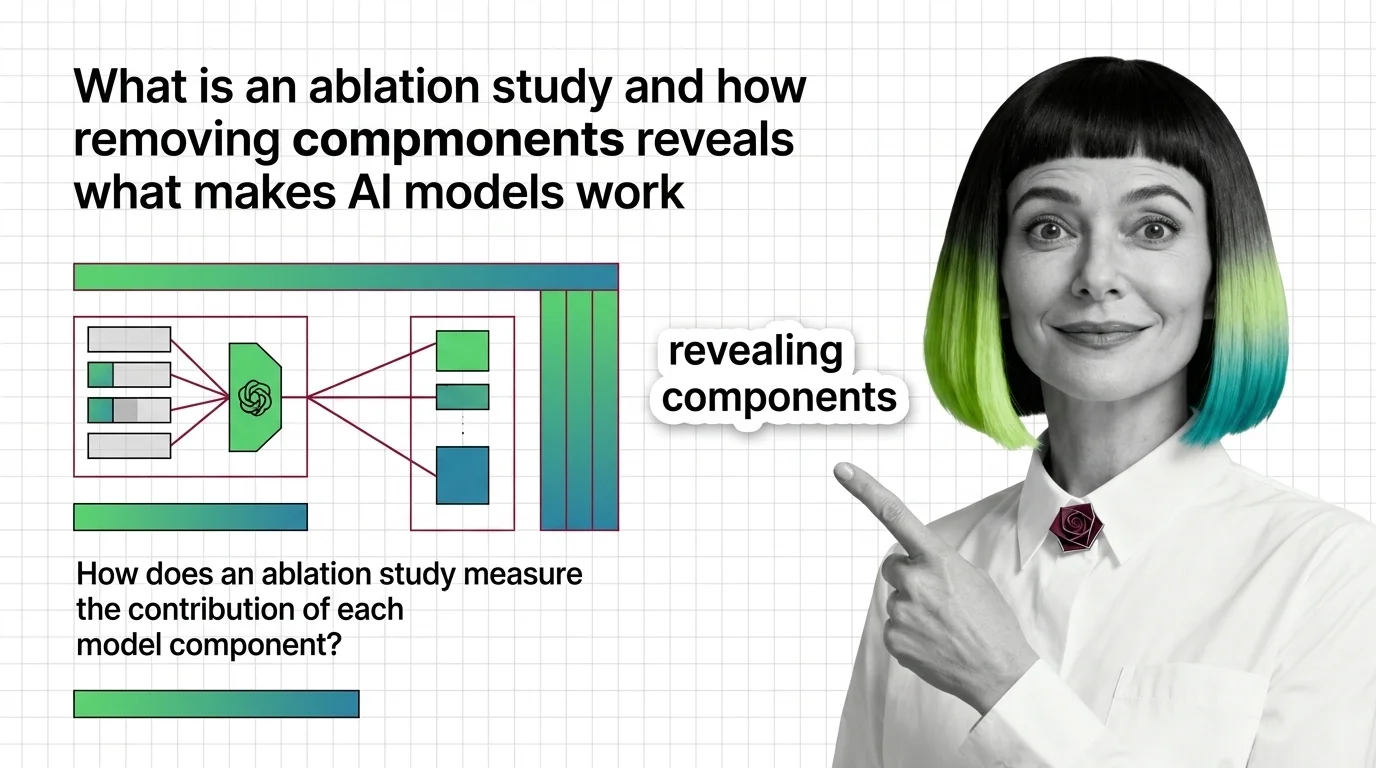
What Is an Ablation Study and How Removing Components Reveals What Makes AI Models Work
Ablation studies reveal what each model component does by removing it. Learn the experimental design and failure modes …

What Is a Confusion Matrix and How It Reveals Where Your Classifier Fails
A confusion matrix reveals exactly where classifiers fail. Understand true positives, false negatives, and why accuracy …

MMLU's 6.5% Label Error Rate and Benchmark Score Saturation
MMLU's 6.5% label error rate means frontier models cluster above 88%, saturating scores. Score saturation explains why …
From Perplexity to Few-Shot Prompting: Prerequisites for Understanding Evaluation Harness Internals
Evaluation harness scores depend on perplexity, few-shot prompting, and tokenization most teams skip. Learn the …
From Binary to Multi-Class: Deriving Precision, Recall, and F1 from a Confusion Matrix
The confusion matrix scales from four binary cells to N² in multi-class problems. What the diagonal and margins record …
Combinatorial Explosion, Interaction Effects, and the Hard Limits of Ablation Studies at Scale
Ablation studies hit a wall at scale: combinatorial explosion and non-additive interactions make exhaustive testing of …

Why F1 Score Fails on Imbalanced Datasets: MCC, PR-AUC, and the Limits of Harmonic Averaging
F1 score hides classifier failures on imbalanced datasets by ignoring true negatives. Learn why MCC and PR-AUC reveal …
Precision, Recall, F1 Score: What the Confusion Matrix Reveals
What accuracy won't show: precision, recall, and F1 score expose true classifier performance. The confusion matrix …