
DeepSeek-V4 at 256 Experts, Grok 5 at 6 Trillion Parameters: How MoE Became the Default Frontier Architecture in 2026
Mixture of experts is now the default frontier architecture. Why every major lab chose MoE over dense models, and what …
PyG vs DGL, GNN+LLM Fusion, and Where Graph Neural Networks Are Heading in 2026
NVIDIA is consolidating on PyG and dropping DGL support. Learn which GNN framework wins, how GNN+LLM fusion changes …
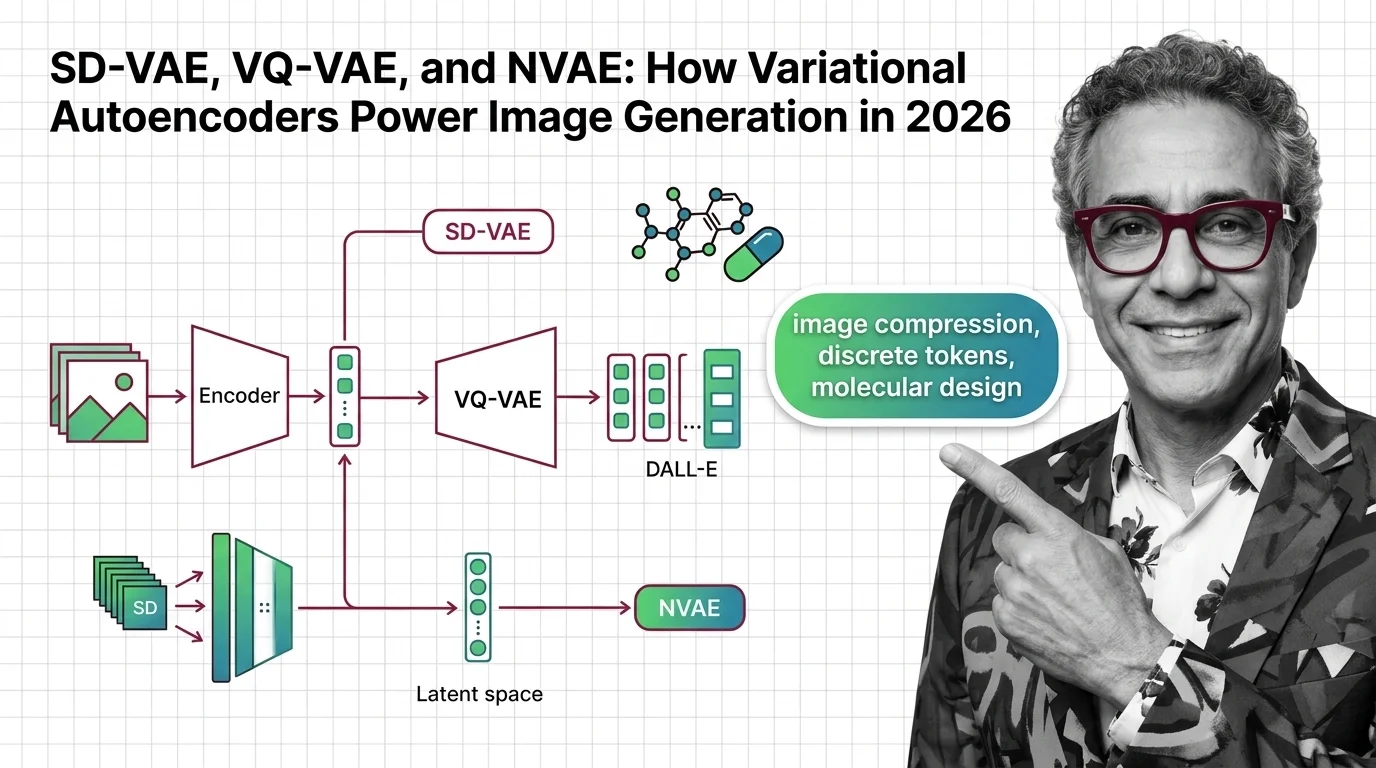
SD-VAE, VQ-VAE, and NVAE: How Variational Autoencoders Power Image Generation in 2026
SD-VAE evolved from 4 to 32 channels while rivals eliminate the encoder entirely. See which VAE strategies lead image …
GigaGAN, Real-ESRGAN, and the Diffusion Rivalry: Where GANs Still Compete in 2026
GANs aren't dead — they're specializing. GigaGAN, Real-ESRGAN, and R3GAN prove adversarial networks still dominate …
xLSTM, minLSTM, and the Recurrent Revival: How RNN Ideas Are Challenging Transformers in 2026
xLSTM, minLSTM, and Mamba-3 prove recurrent architectures rival transformer quality at linear cost. What the hybrid …
Neural Networks in Action: How GPT and LLaMA Differ and What's Changing in 2026
GPT-5, LLaMA 4, and Gemini 3 all bet on routing and MoE — but their approaches diverge. What the architecture split …

From Radiology to Autonomous Vehicles: How CNNs Power Real-World Computer Vision in 2026
CNNs aren't fading — they're merging with transformers and powering FDA-cleared diagnostics, robotaxis, and real-time …
Inspect AI, DeepEval, and the Open-Source Evaluation Race Reshaping LLM Benchmarking in 2026
LLM evaluation has split into three lanes: government safety, enterprise CI/CD, and academic benchmarks. Here's who …

MMLU Leakage, LiveCodeBench, and the 2026 Race to Build Contamination-Proof AI Evaluation
MMLU scores dropped up to 17 points when contamination was removed. How LiveBench, MMLU-CF, and new detection methods …
Ablation Studies: From ResNet to AblationMage Analysis by 2026
Ablation studies evolved from manual methods to LLM-powered tools. Track the shift from ResNet to AblationMage and the …
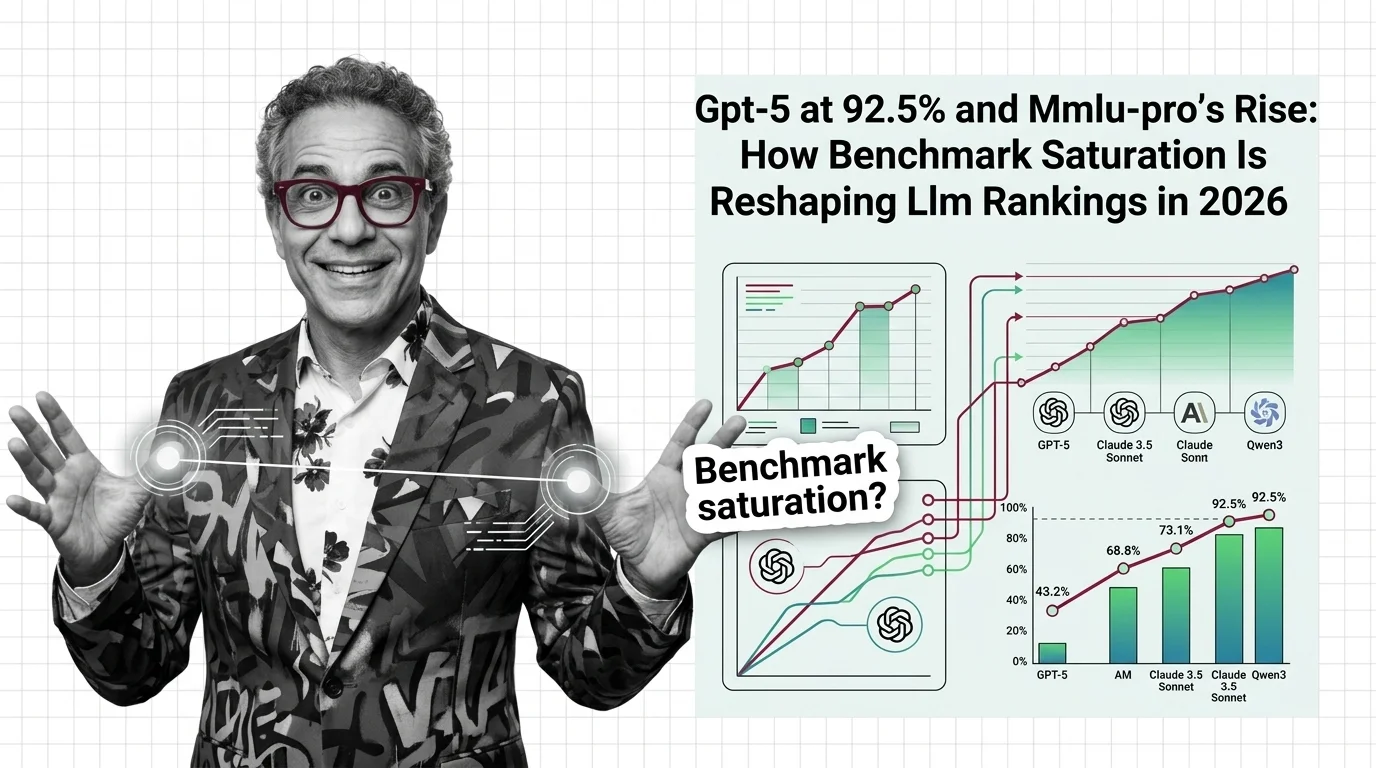
GPT-5 at 92.5% and MMLU-Pro's Rise: How Benchmark Saturation Is Reshaping LLM Rankings in 2026
Frontier LLMs cluster within 4 points on MMLU, making the benchmark useless for differentiation. See how saturation is …

Confusion Matrix: Real-World Misclassifications in 2026
COMPAS and FDA recalls demonstrate how confusion matrix analysis shifts from post-mortem diagnostic tools to automated …
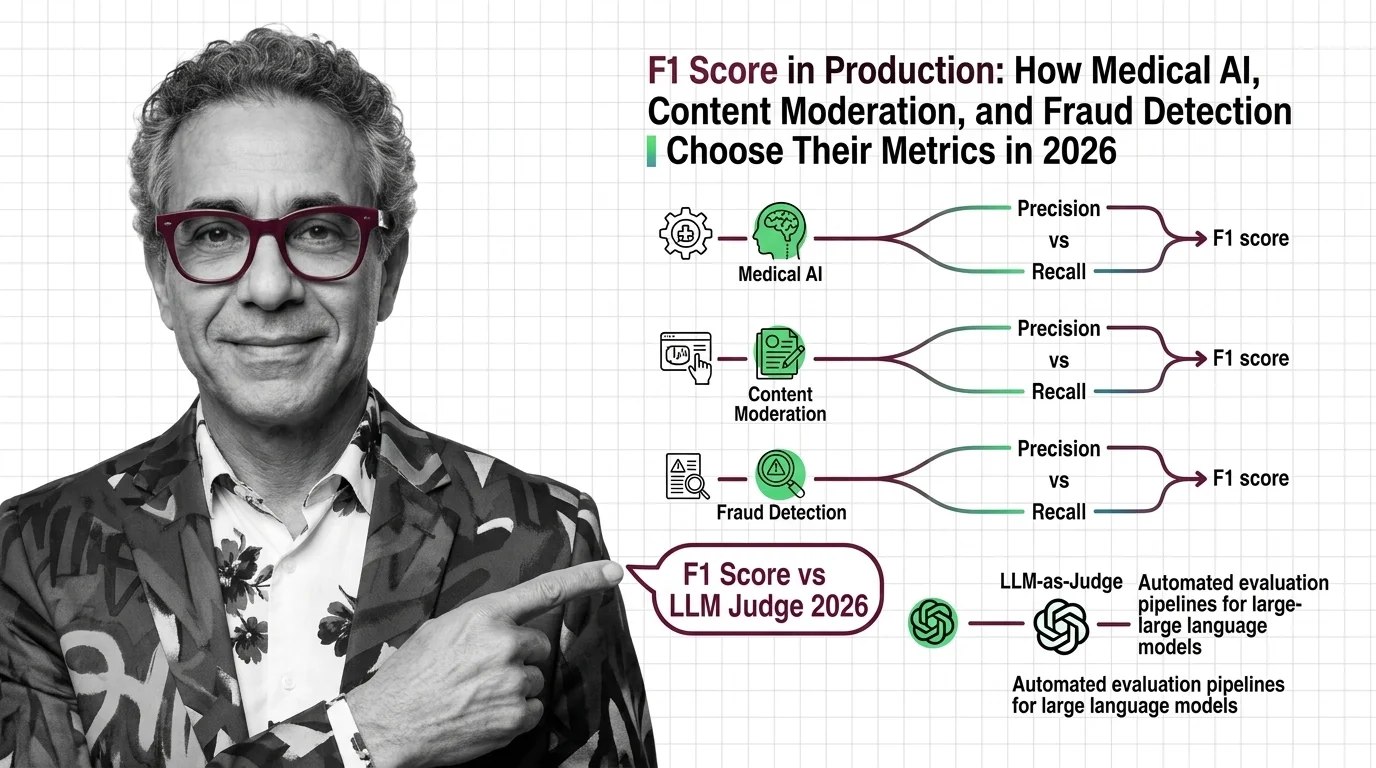
F1 Score vs Domain Metrics: Medical, Fraud, Moderation in 2026
F1 score is no longer the default in production. Medical AI, fraud detection, and content moderation each prioritize …
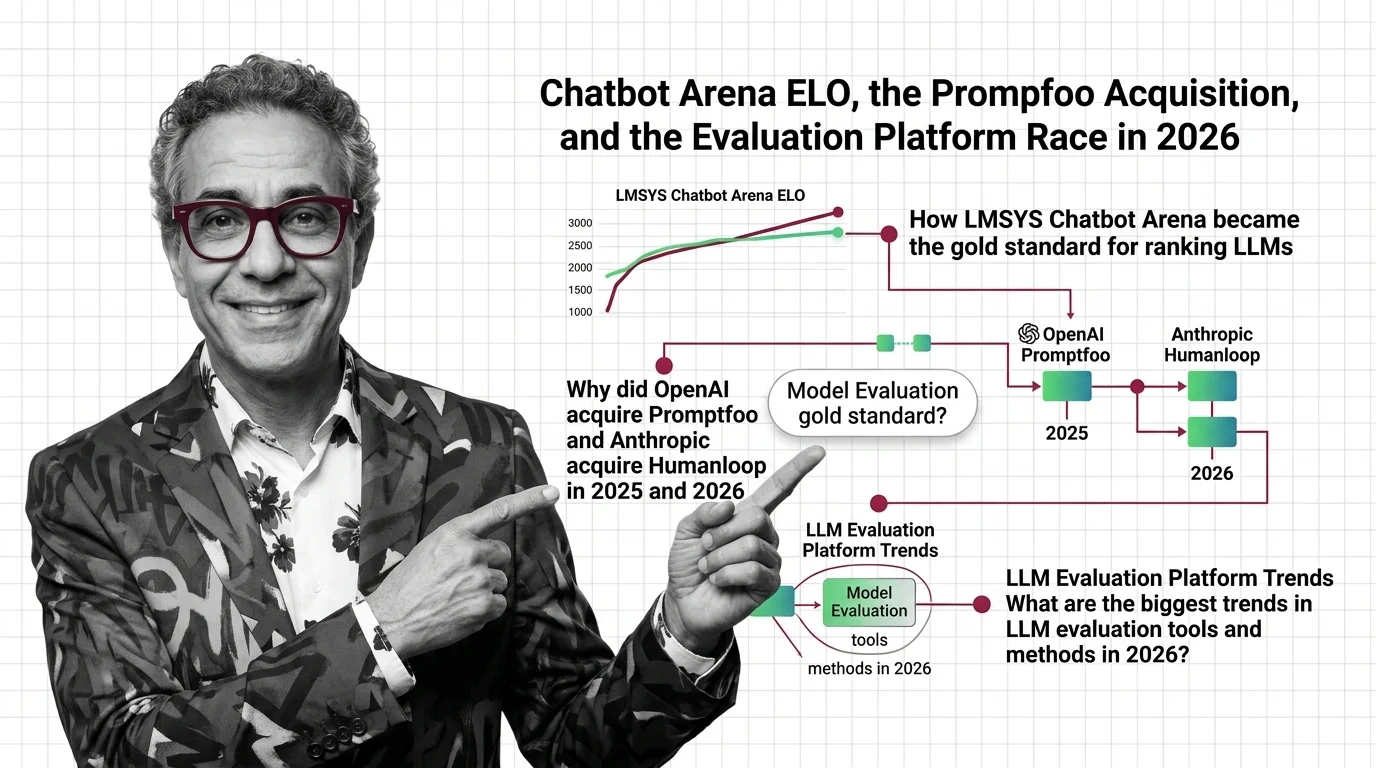
Chatbot Arena ELO, the Promptfoo Acquisition, and the Evaluation Platform Race in 2026
OpenAI acquired Promptfoo, Anthropic acqui-hired Humanloop, and Arena hit a $1.7B valuation. Here's why the evaluation …

From COMPAS to the EU AI Act: Fairness Metrics Reshaping AI Accountability in 2026
Fairness metrics moved from research papers to courtrooms. COMPAS, EU AI Act enforcement, and bias lawsuits are …

AI Safety Tools: Llama Guard 4, DuoGuard, ISC-Bench 2026
Open-source guard models outperform commercial APIs on speed, accuracy. ISC-Bench revealed alignment failures. The AI …
From GPT-4 Pre-Launch to Frontier Model Audits: How AI Red Teaming Became Industry Standard by 2026
AI red teaming went from OpenAI's voluntary GPT-4 audit to a federal procurement requirement in under three years. …
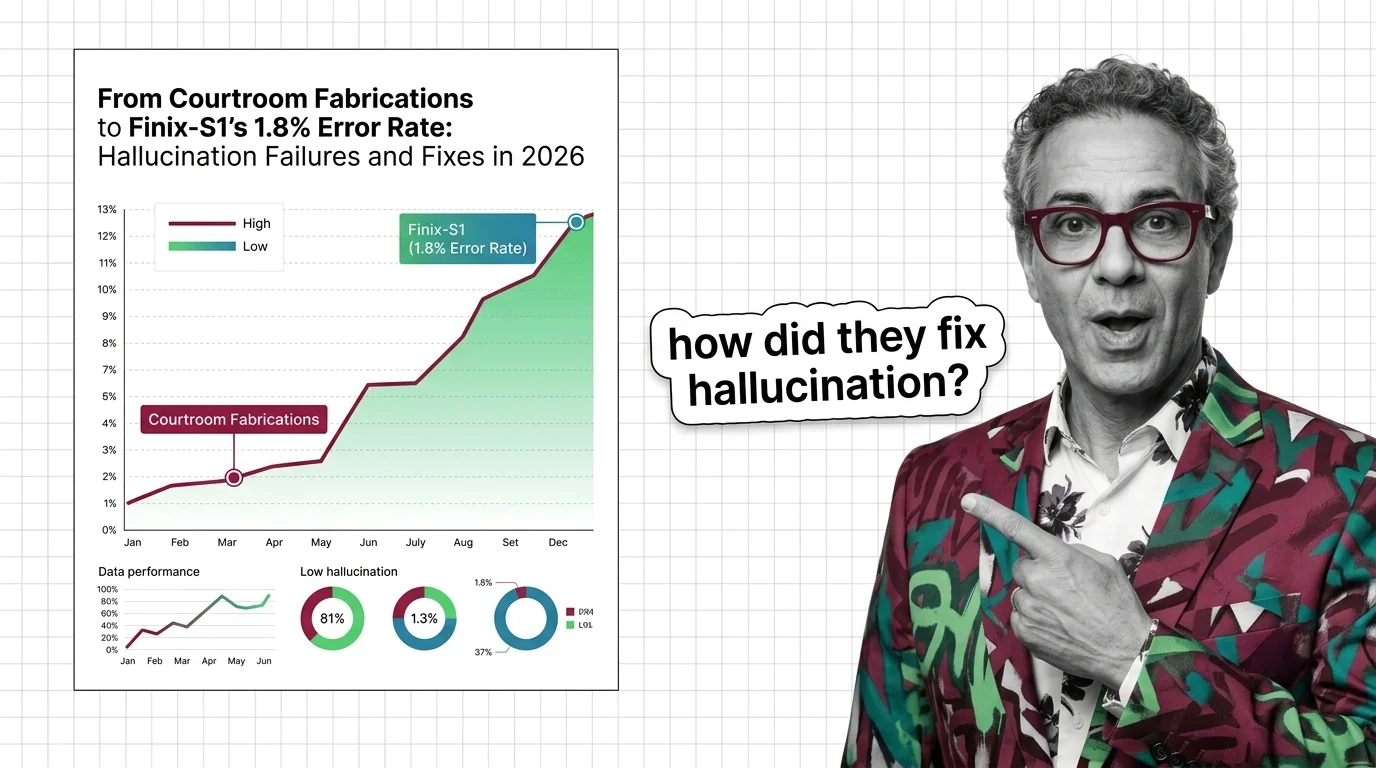
From Courtroom Fabrications to Finix-S1's 1.8% Error Rate: Hallucination Failures and Fixes in 2026
Frontier LLMs still hallucinate over 10% on hard benchmarks while courts levy six-figure fines. The two-tier accuracy …
BitNet, FP8 Native, and the 1-Bit Frontier: Where Quantization Is Heading in 2026
Quantization has split into three tiers — native 1-bit, hardware FP8/FP4, and post-training compression. See which bet …
Locked Temperatures, Min-P Adoption, and the Sampling Parameter Shifts Reshaping LLMs in 2026
OpenAI locked temperature on reasoning models. Open-source stacks adopted min-p. The sampling parameter surface …
Cerebras vs. Groq vs. GPU Clouds: The Custom Silicon Bet Reshaping Inference Economics in 2026
Cerebras, Groq, and SambaNova challenge GPU dominance in LLM inference. The 2026 custom silicon race, real cost shifts, …

QRM-Gemma, Skywork Reward, and the LM-as-a-Judge Pivot: The Reward Model Race in 2026
A 1.7B reward model just dethroned a 70B giant. Here's how Skywork V2, QRM-Gemma, and LM-as-a-judge are reshaping the …
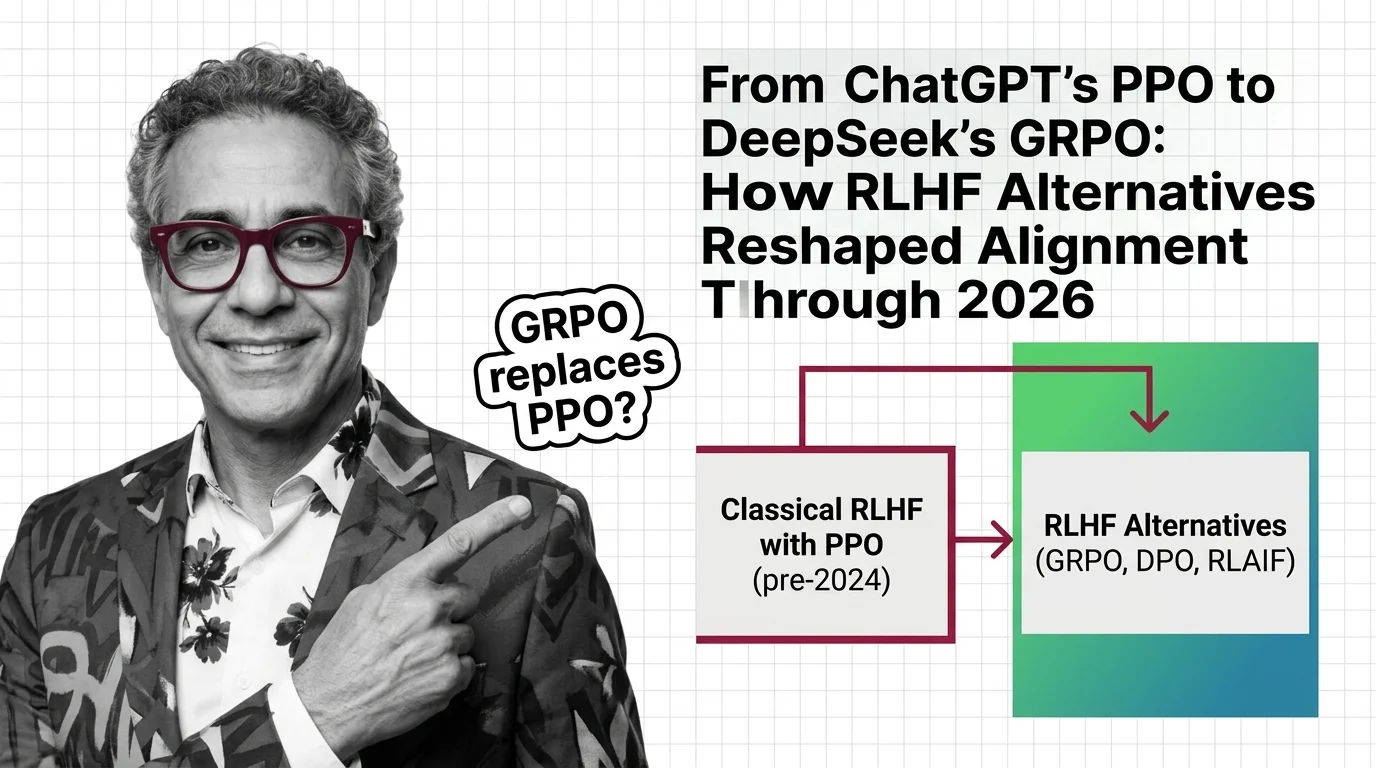
From ChatGPT's PPO to DeepSeek's GRPO: How RLHF Alternatives Reshaped Alignment Through 2026
Classical RLHF with PPO launched ChatGPT, but DPO and GRPO now dominate LLM alignment. See how reward-model-free methods …

GLM-5, FineWeb2, and the 28-Trillion-Token Race: Pre-Training Breakthroughs Reshaping AI in 2026
GLM-5, Qwen3, and Llama 4 are rewriting pre-training records. The real race is data quality, synthetic augmentation, and …

Together AI at $0.48/M, Unsloth 5x Speedups, and the Fine-Tuning Platform Race in 2026
Together AI's $0.48/M pricing and Unsloth's training speedups are reshaping LLM fine-tuning economics. Here's who wins …
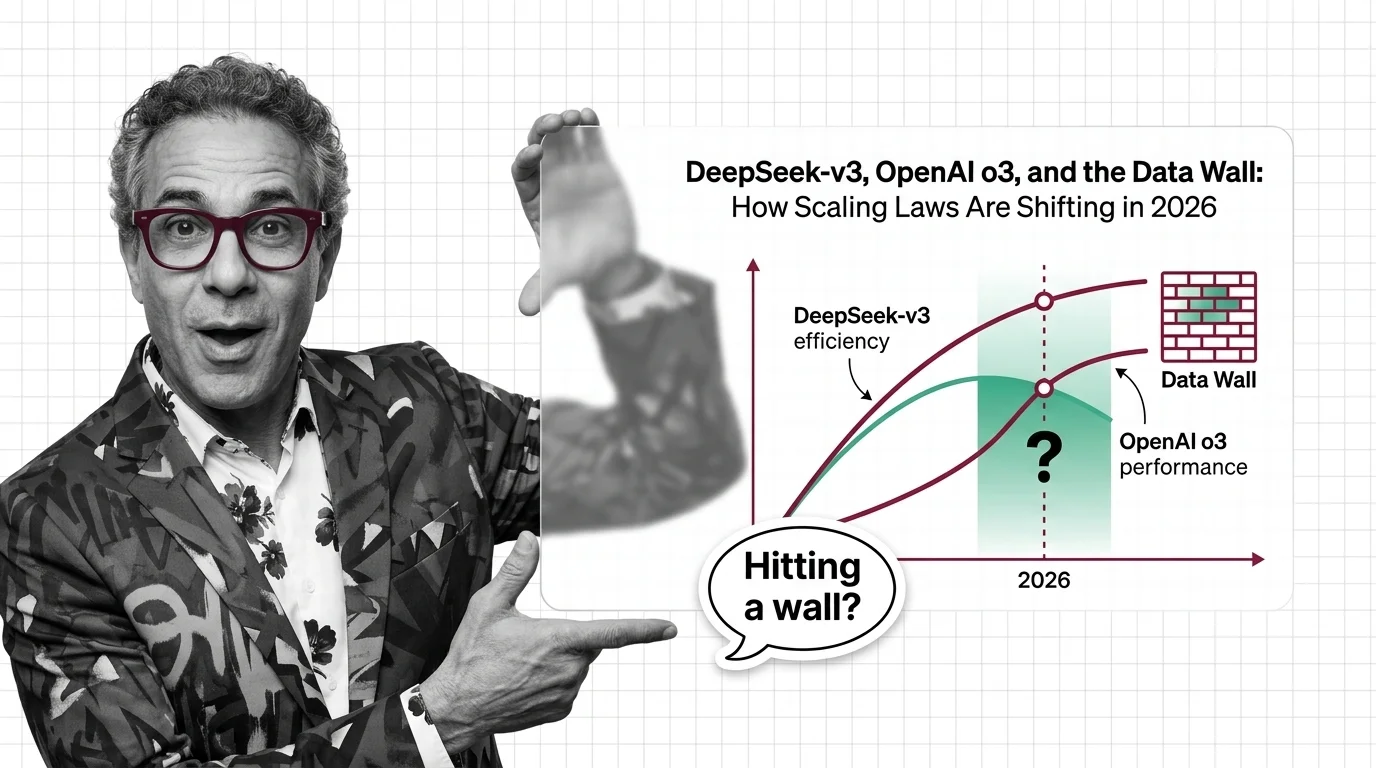
DeepSeek-v3, OpenAI o3, and the Data Wall: How Scaling Laws Are Shifting in 2026
Scaling laws split in 2025 along three axes. DeepSeek proved efficiency, o3 proved inference-time compute, and the data …
Sentence Transformers v5.3 vs Gemini & NV-Embed: MTEB 2026
v5.3 introduces new contrastive losses as Gemini Embedding claims MTEB #1. Why framework innovation matters more than …
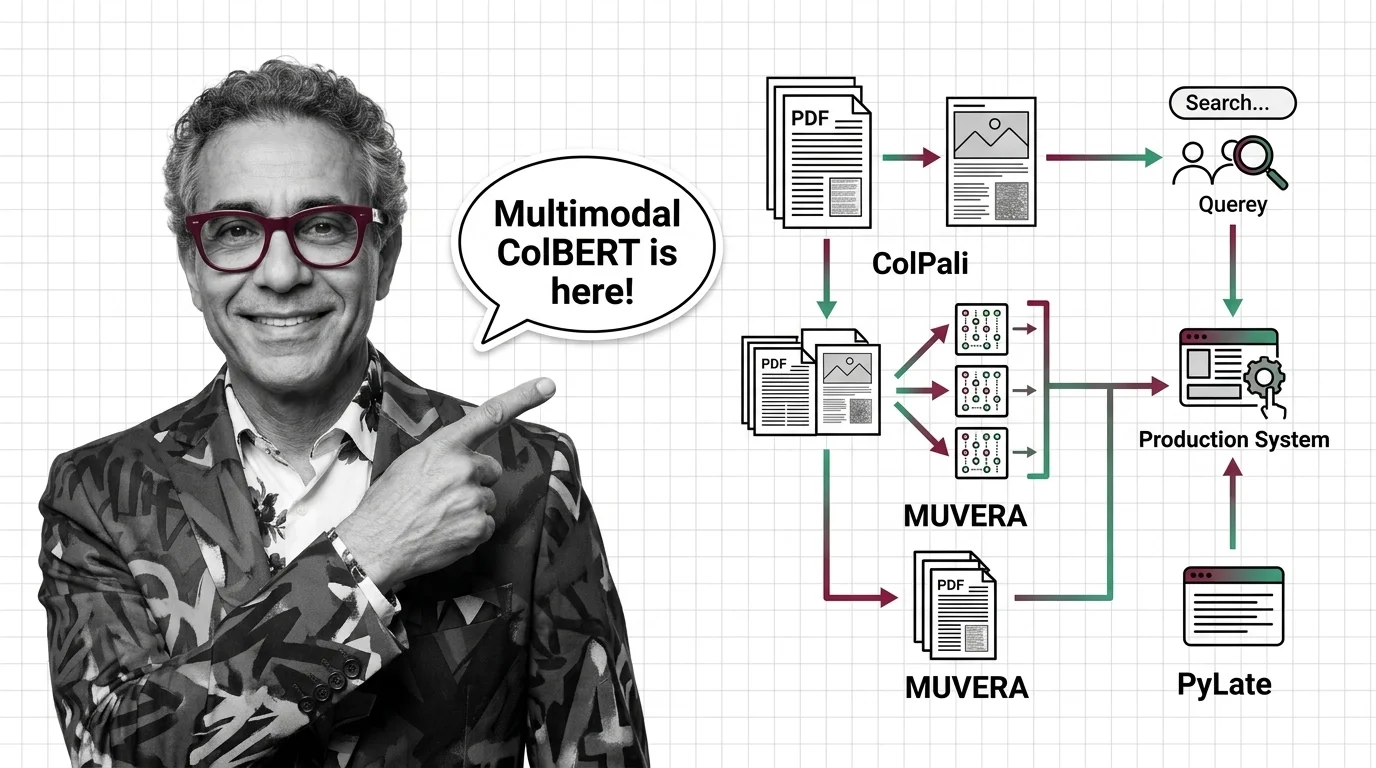
ColPali, MUVERA, and PyLate: How Multi-Vector Retrieval Went Multimodal in 2026
ColPali, MUVERA, and PyLate converged to make multi-vector retrieval multimodal and production-ready. Here's what the …
ScaNN, DiskANN, and Glass: The 2026 ANN-Benchmarks Race and Where Vector Indexing Is Heading
SymphonyQG, Glass, and ScaNN are rewriting ANN benchmark rankings. Learn which vector indexing strategies win at scale …
Why Google's T5Gemma 2 Bets on Encoder-Decoder Architecture
T5Gemma 2 brings 128K context and multimodal input via encoder-decoder, defying the decoder-only trend. Learn why Google …