AI Ethics
The human side of AI — bias, privacy, societal impact, and governance. ALAN asks the hard questions about who benefits and who pays the cost.
- Home /
- AI Ethics

Who Judges the Judge? Bias and Accountability When AI Evaluates AI
Who Judges the Judge? Bias and Accountability When AI Evaluates AI The Hard Truth

Teaching to the Test: How Benchmark Optimization Distorts AI Progress
Teaching to the Test: How Benchmark Optimization Distorts AI Progress The Hard Truth

When Synthetic Replaces Real: Bias Laundering and Accountability in Generated Datasets
When Synthetic Replaces Real: Bias Laundering and Accountability in Generated Datasets The Hard …

Does Active Learning Amplify Dataset Bias? The Ethics of Letting Models Choose What Humans Label
Does Active Learning Amplify Dataset Bias? The Ethics of Letting Models Choose What Humans Label The …
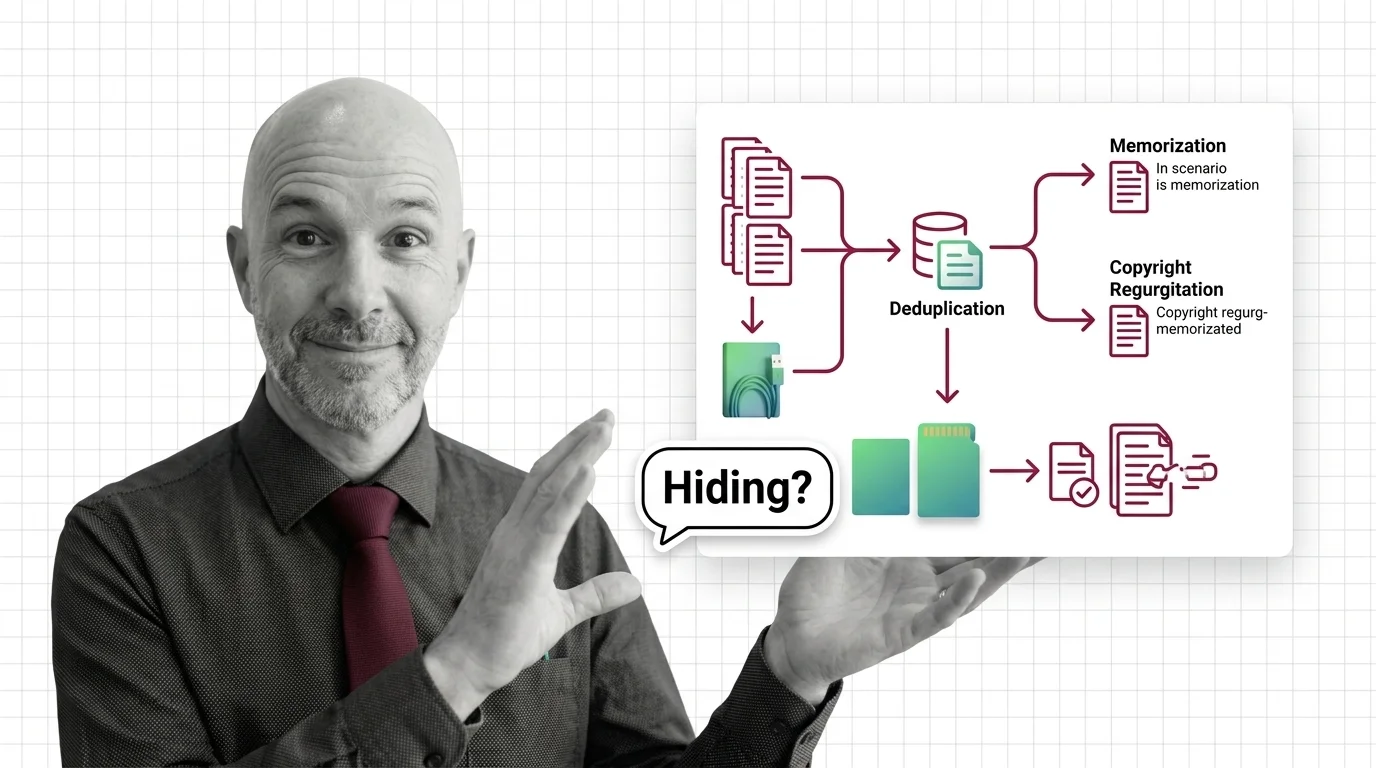
Does Deduplication Fix Memorization and Copyright Regurgitation, or Just Hide It?
Does Deduplication Fix Memorization and Copyright Regurgitation, or Just Hide It? The Hard Truth
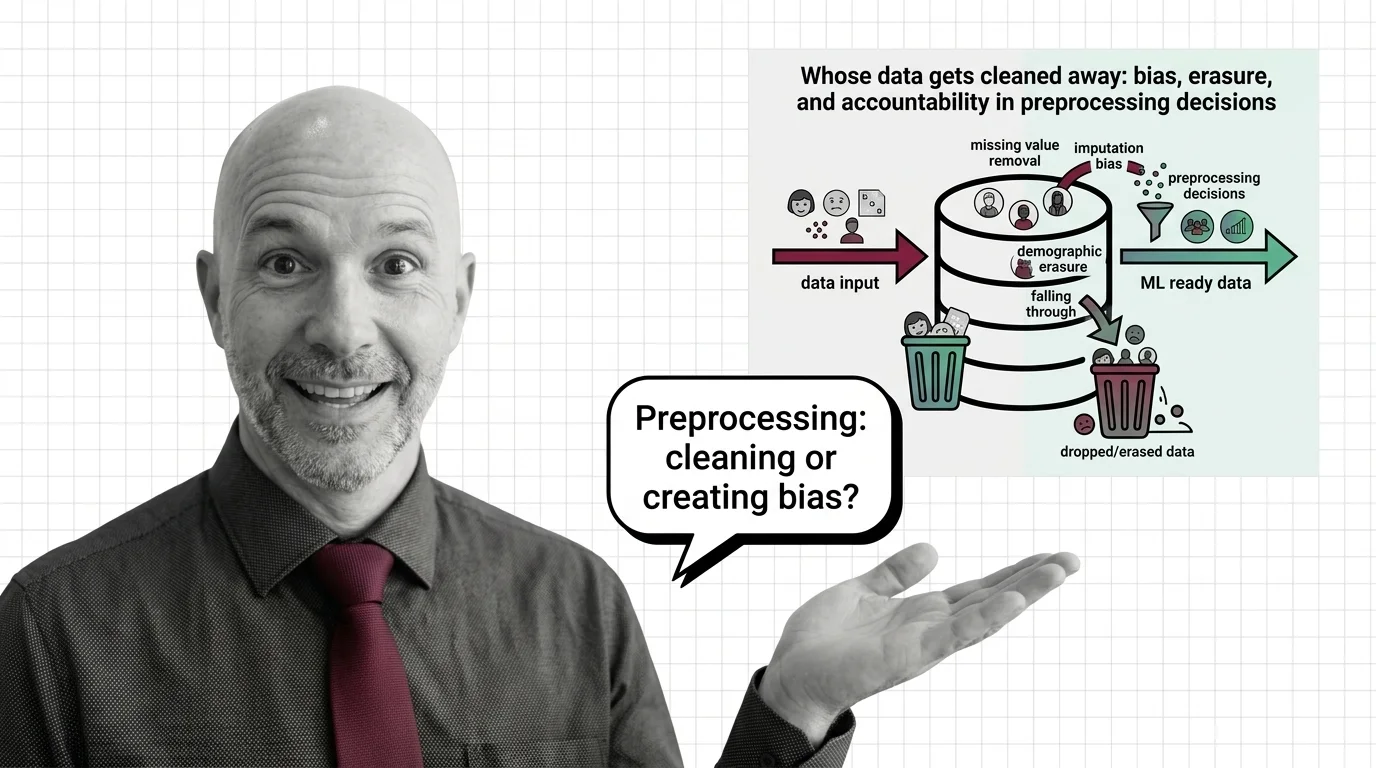
Whose Data Gets Cleaned Away: Bias, Erasure, and Accountability in Preprocessing Decisions
Whose Data Gets Cleaned Away: Bias, Erasure, and Accountability in Preprocessing Decisions The Hard …

Underpaid Annotators and Hidden Bias: The Ethical Cost of the Data Labeling Industry
Underpaid Annotators and Hidden Bias: The Ethical Cost of the Data Labeling Industry The Hard Truth

Augmenting Bias: The Ethical Risks of Synthetic and LLM-Generated Training Data
Augmenting Bias: The Ethical Risks of Synthetic and LLM-Generated Training Data The Hard Truth


Does AI Really Pay Down Technical Debt? Automation Bias, Accountability, and False Confidence
Does AI Really Pay Down Technical Debt? Automation Bias, Accountability, and False Confidence The …

Who's Accountable When AI Auto-Merges a Broken Fix? The Ethics of Autonomous CI/CD
Who’s Accountable When AI Auto-Merges a Broken Fix? The Ethics of Autonomous CI/CD The Hard …

Trained on Scraped Code: Licensing, Attribution, and the Ethics of Code LLMs
Trained on Scraped Code: Licensing, Attribution, and the Ethics of Code LLMs The Hard Truth

Who Owns the Code an Agent Writes? Accountability, Job Displacement, and the Ethics of Autonomous Coding Agents
Who Owns the Code an Agent Writes? Accountability, Job Displacement, and the Ethics of Autonomous …

When the AI Writes the Code: Accountability, Skill Erosion, and the Ethics of Vibe Coding
When the AI Writes the Code: Accountability, Skill Erosion, and the Ethics of Vibe Coding The Hard …

Whose Code Counts: Context Engineering, Privilege, and the Ethics of AI-Assisted Development
Whose Code Counts: Context Engineering, Privilege, and the Ethics of AI-Assisted Development The …

Who Owns the Bug When AI Rewrites Your Codebase? Accountability in Automated Migration
Who Owns the Bug When AI Rewrites Your Codebase? Accountability in Automated Migration The Hard …

Should You Trust Third-Party MCP Servers? Data Exposure, Unvetted Code, and Governance
Should You Trust Third-Party MCP Servers? Data Exposure, Unvetted Code, and Governance The Hard …
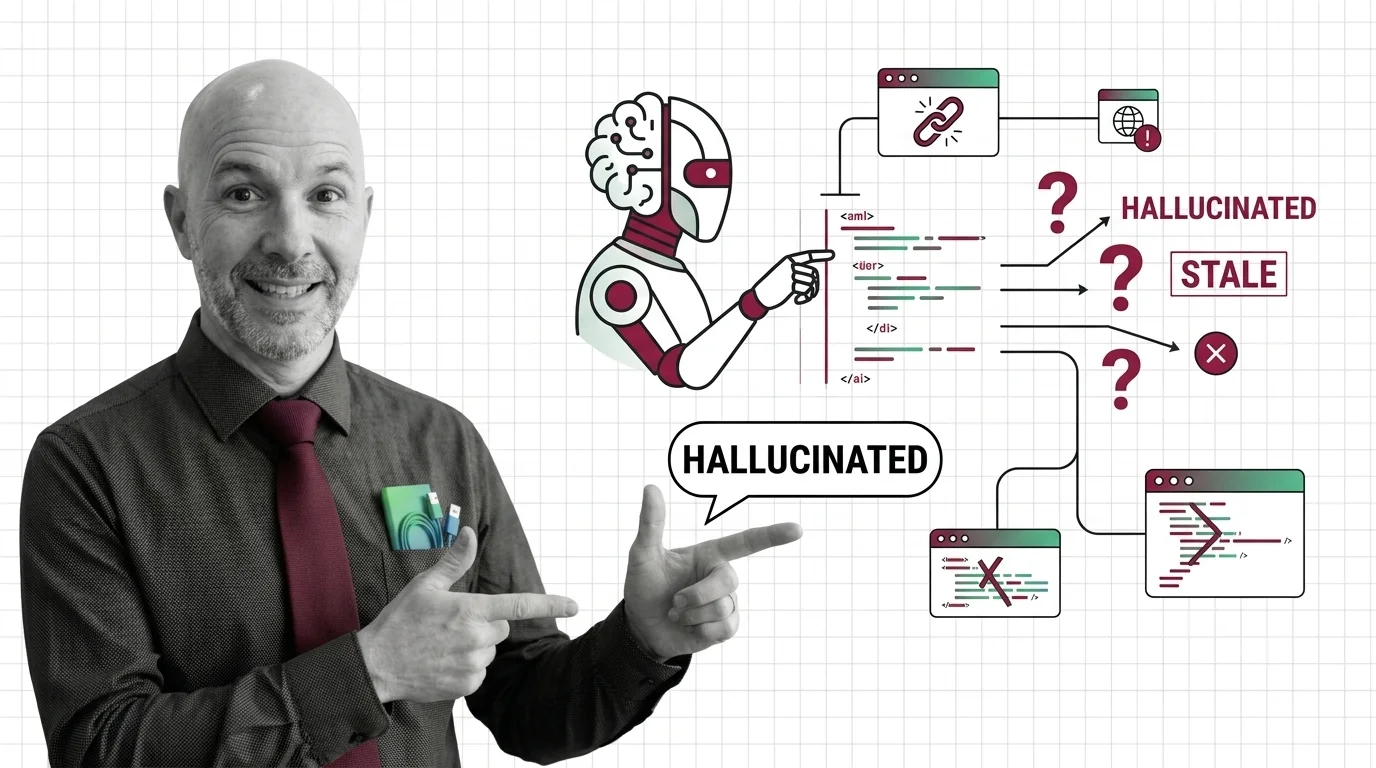
When AI Docs Lie: Hallucinated APIs, Stale Examples, and the Accountability Gap
When AI Docs Lie: Hallucinated APIs, Stale Examples, and the Accountability Gap The Hard Truth

When AI Refactors Code Nobody Reviews: Accountability, Hidden Defects, and Developer Deskilling
When AI Refactors Code Nobody Reviews: Accountability, Hidden Defects, and Developer Deskilling The …
When the AI Fixes the Wrong Bug: Accountability, Trust, and the Ethics of Letting Models Patch Production Code
When the AI Fixes the Wrong Bug: Accountability, Trust, and the Ethics of Letting Models Patch …

When AI Writes the Tests That Validate AI Code: Accountability Gaps in Automated Test Generation
When AI Writes the Tests That Validate AI Code: Accountability Gaps in Automated Test Generation The …
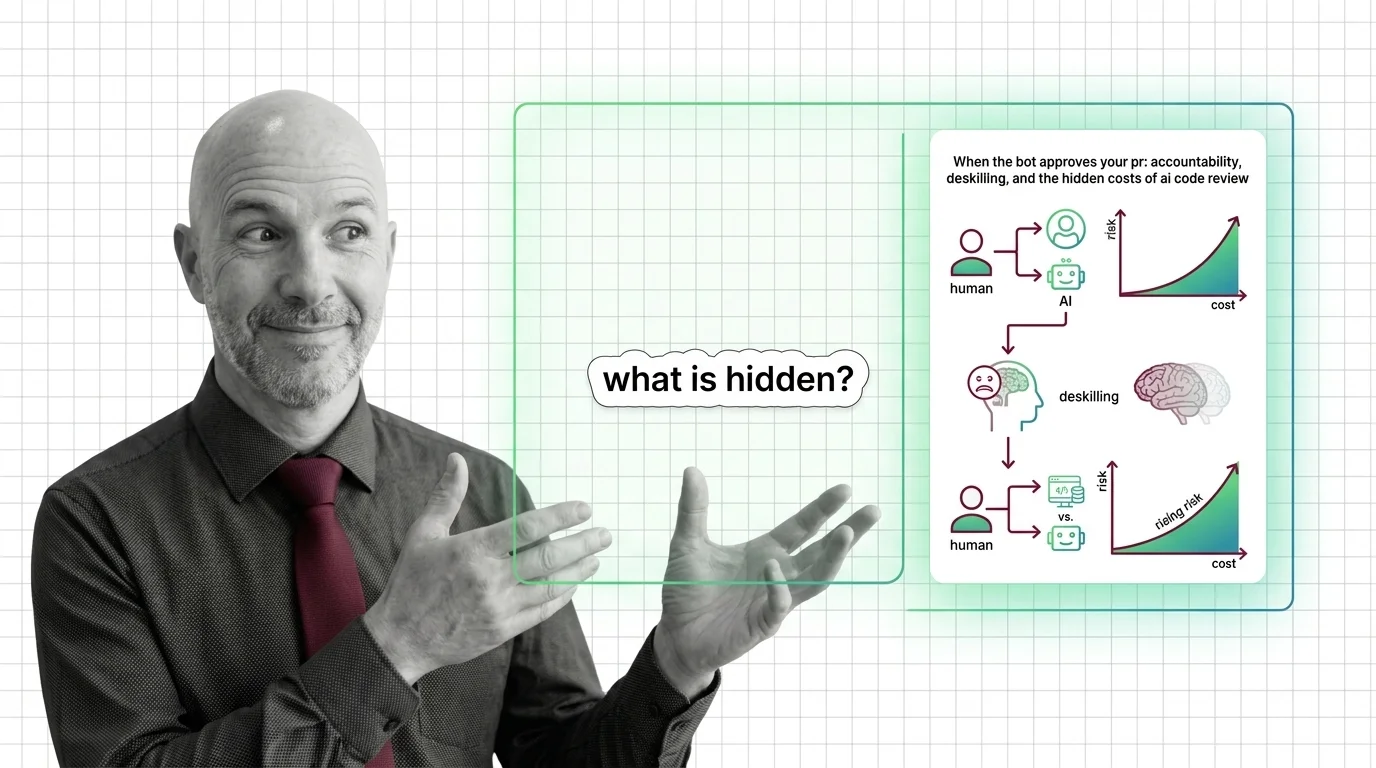
When the Bot Approves Your PR: Accountability, Deskilling, and the Hidden Costs of AI Code Review
When the Bot Approves Your PR: Accountability, Deskilling, and the Hidden Costs of AI Code Review …
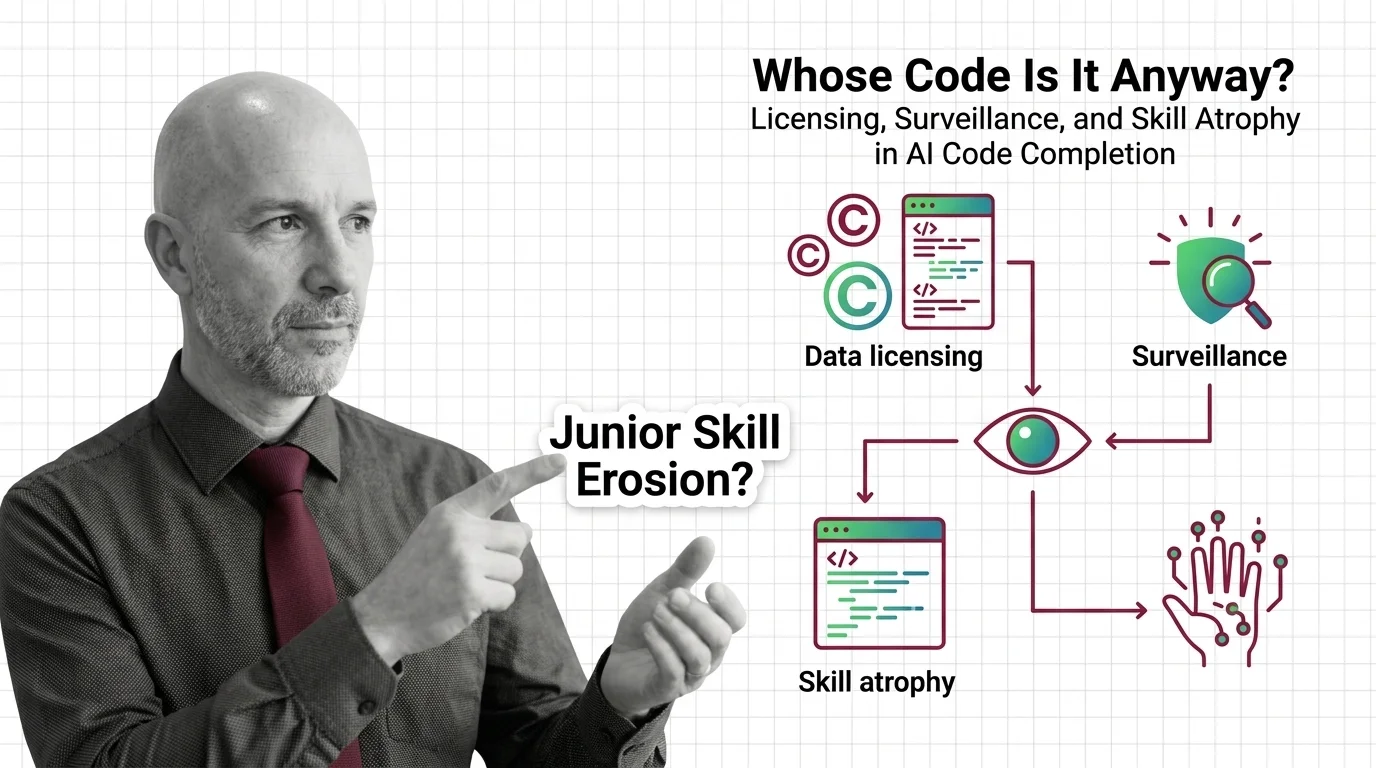
Whose Code Is It Anyway? Licensing, Surveillance, and Skill Atrophy in AI Code Completion
Whose Code Is It Anyway? Licensing, Surveillance, and Skill Atrophy in AI Code Completion The Hard …
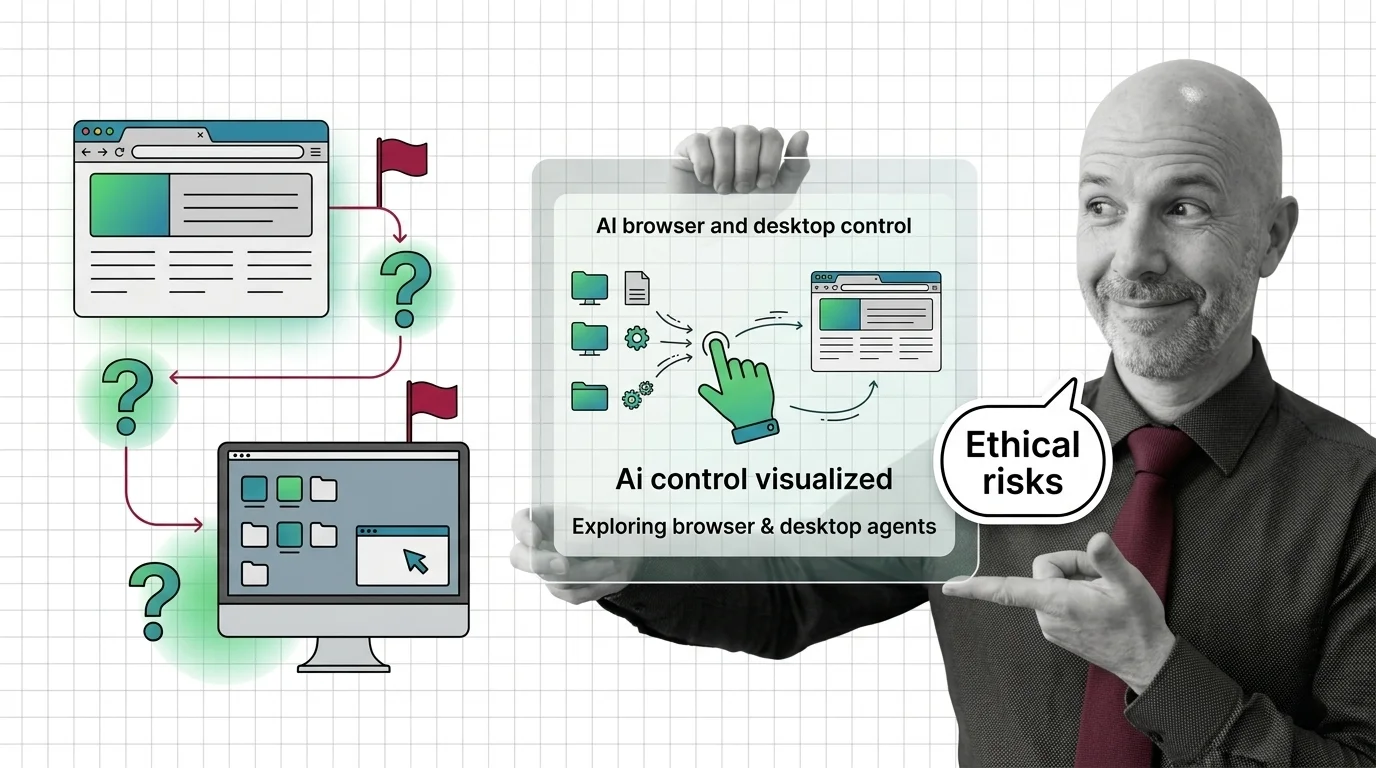
Agents That Click for You: The Ethical Risks of Giving AI Control Over Your Browser and Desktop
Agents That Click for You: The Ethical Risks of Giving AI Control Over Your Browser and Desktop The …
When Agents Retrieve the Wrong Truth: Accountability and Ethical Risks of Retrieval-Augmented Agents
When Agents Retrieve the Wrong Truth: Accountability and Ethical Risks of Retrieval-Augmented Agents …

When LLMs Run Code They Wrote: Accountability and the Ethics of Autonomous Execution
When LLMs Run Code They Wrote: Accountability and the Ethics of Autonomous Execution The Hard Truth
When Orchestration Hides the Failure: Accountability Gaps in Automated AI Workflows
When Orchestration Hides the Failure: Accountability Gaps in Automated AI Workflows The Hard Truth
When AI Agents Fail Silently: The Ethics of Graceful Degradation
Graceful degradation lets AI agents fail without crashing. That sounds humane. It also lets failure hide. A look at the …

Recording Every Step: Privacy and Ethics of Agent Traces
Agent observability captures every prompt, tool call, and screenshot. The privacy cost stays invisible — until the …

Cheap Models, Hidden Costs: Routing Agents to the Lowest Bidder
Routing AI agents to cheaper models cuts cost — but pushes hallucination, jailbreak, and accountability risk onto the …