
Sequential Bias and Opaque Memory: The Ethical Risks of Recurrent Networks in High-Stakes Decisions
RNNs carry opaque sequential memory into high-stakes decisions. Explore why hidden states resist auditing and what that …
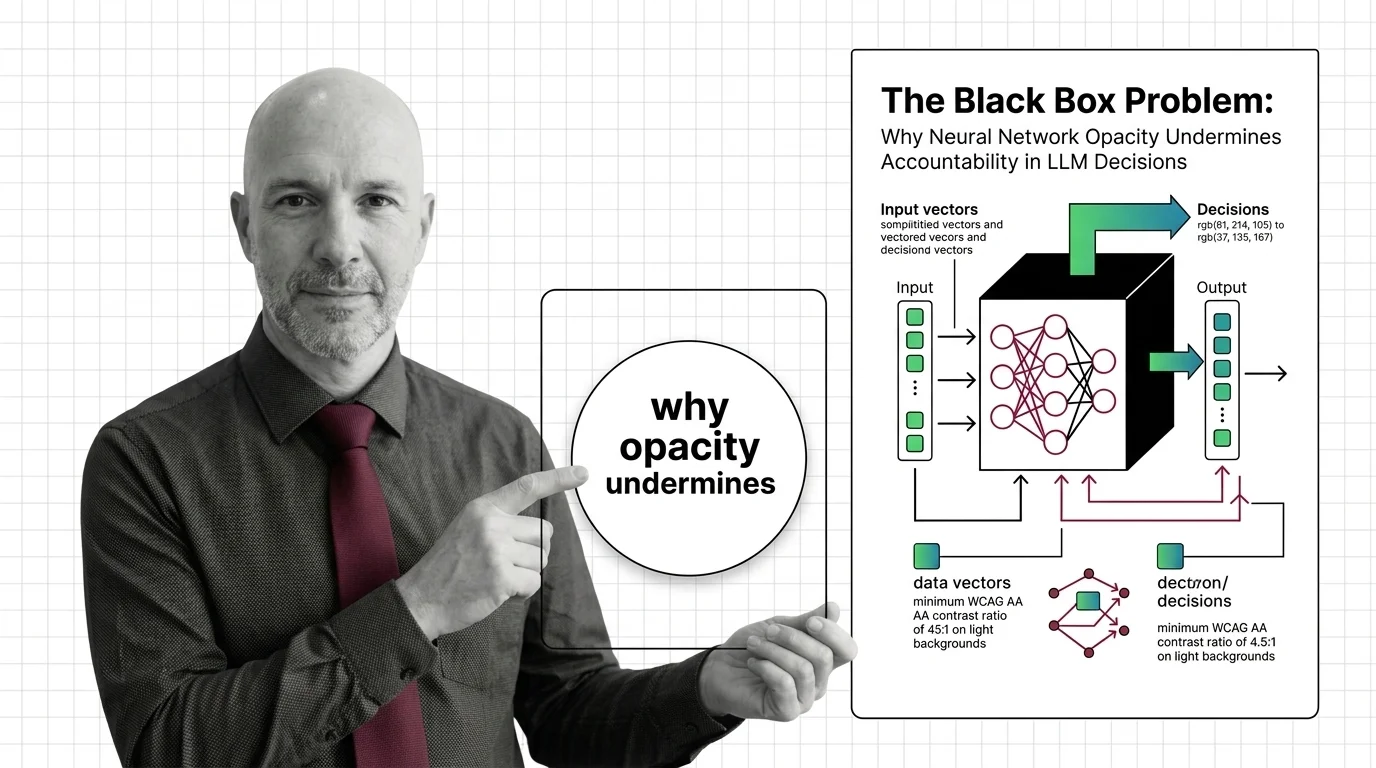
The Black Box Problem: Why Neural Network Opacity Undermines Accountability in LLM Decisions
Neural networks powering LLM decisions are opaque by design. This essay traces why that opacity creates an …

Trained on Bias, Deployed on Faces: The Ethical Cost of CNN-Powered Surveillance Systems
CNN-powered facial recognition hits 98% on benchmarks but fails along racial and gender lines. The ethical cost of …

Who Decides What Gets Measured: The Accountability Gap in Standardized LLM Evaluation
Standardized LLM evaluation harnesses shape which AI models succeed, yet their design choices go unaudited. Explore the …

Inflated Scores, Misplaced Trust: The Ethical Cost of Benchmark Contamination in AI Procurement
Inflated benchmark scores shape AI procurement in healthcare and finance. An ethical examination of contamination, …
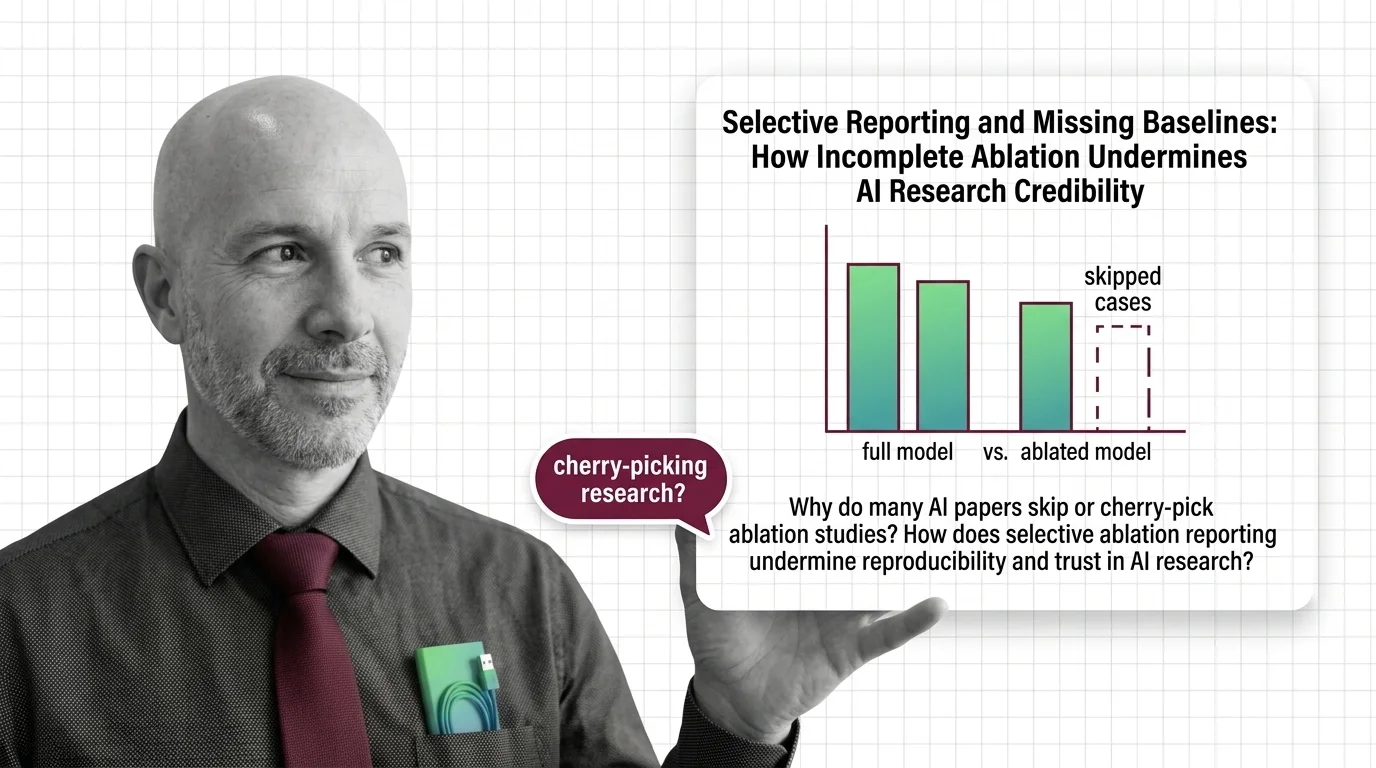
Selective Reporting and Missing Baselines: How Incomplete Ablation Undermines AI Research Credibility
Selective ablation reporting hides whether AI breakthroughs are real. Explore how missing baselines erode research trust …
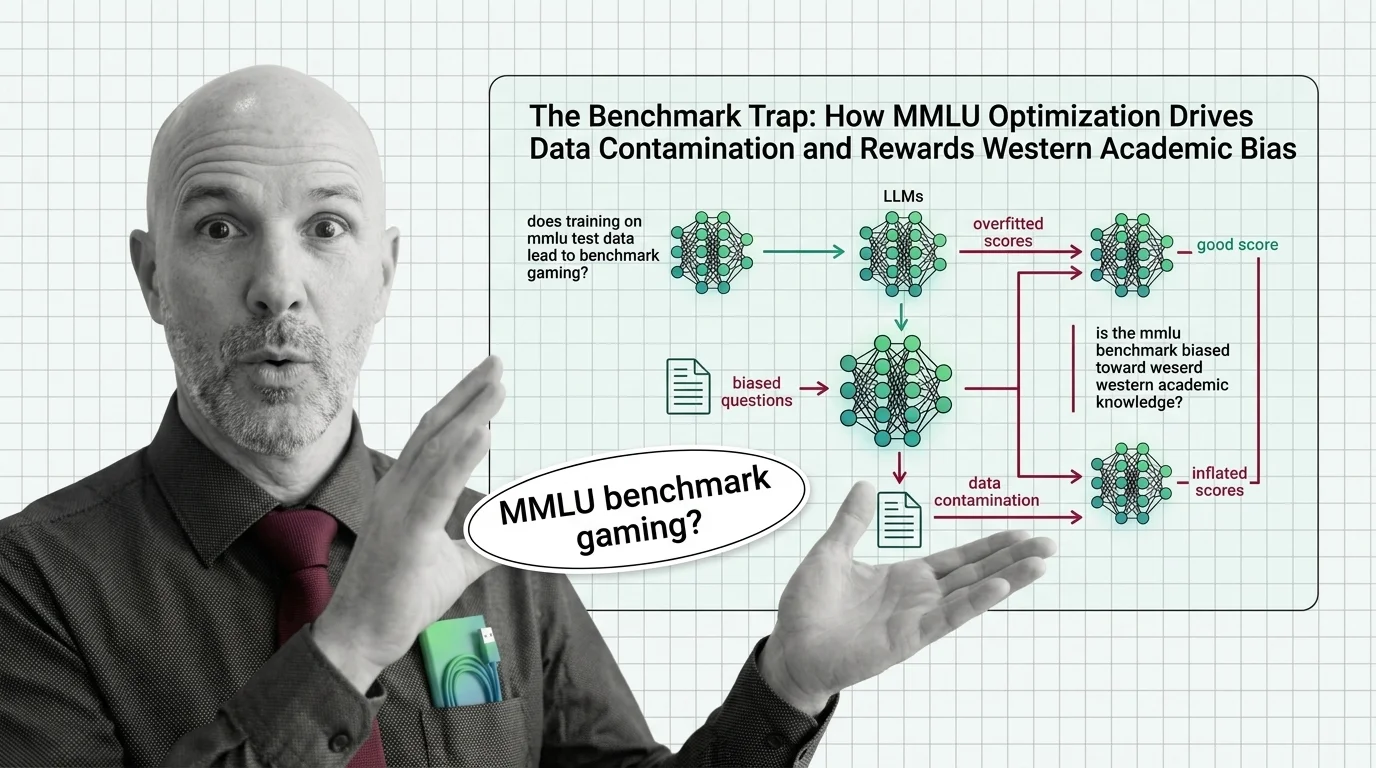
The Benchmark Trap: How MMLU Optimization Drives Data Contamination and Rewards Western Academic Bias
MMLU scores dominate AI headlines, but data contamination and cultural bias undermine what they actually measure. An …

Accuracy Theater: How Confusion Matrices Obscure Bias in High-Stakes AI Decisions
Overall accuracy hides who bears the cost of AI errors. Explore how confusion matrices obscure racial and gender bias in …

Who Decides What Good Means: Cultural Bias and Power Asymmetry in LLM Benchmarks
LLM benchmarks encode their creators' cultural values. Explore how geographic bias, moral stereotyping, and power …

Who Decides Toxicity? Bias, Overcensorship, Power in AI Safety
AI toxicity classifiers embed cultural bias, creating disparate censorship of marginalized communities. Examine how …

Optimizing for the Wrong Number: How F1 Score Masks Disparate Impact in High-Stakes Classification
F1 score can mask racial and gender bias in hiring and criminal justice. Learn why aggregate metrics fail fairness and …
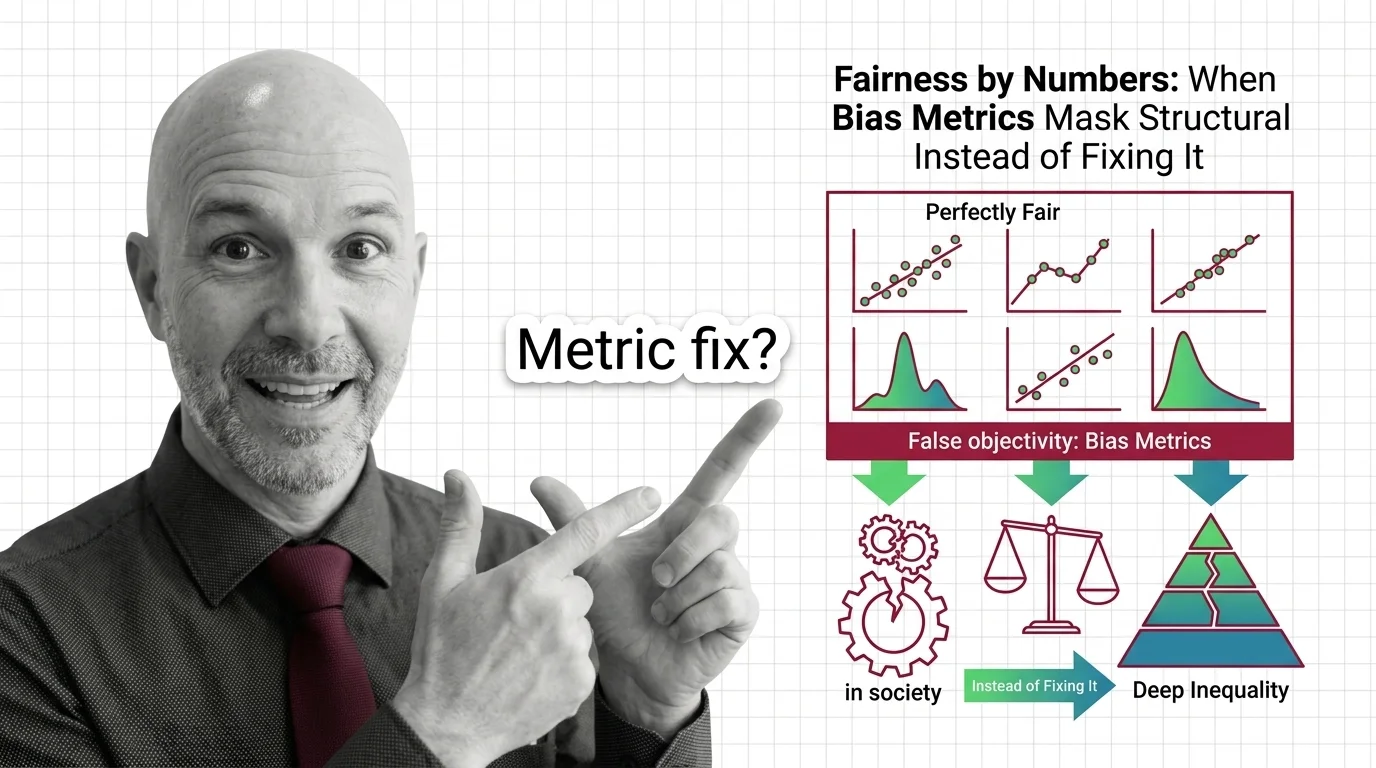
Fairness by Numbers: When Bias Metrics Mask Structural Inequality Instead of Fixing It
Fairness metrics promise objectivity but can mask structural inequality. Learn why statistical parity fails to deliver …
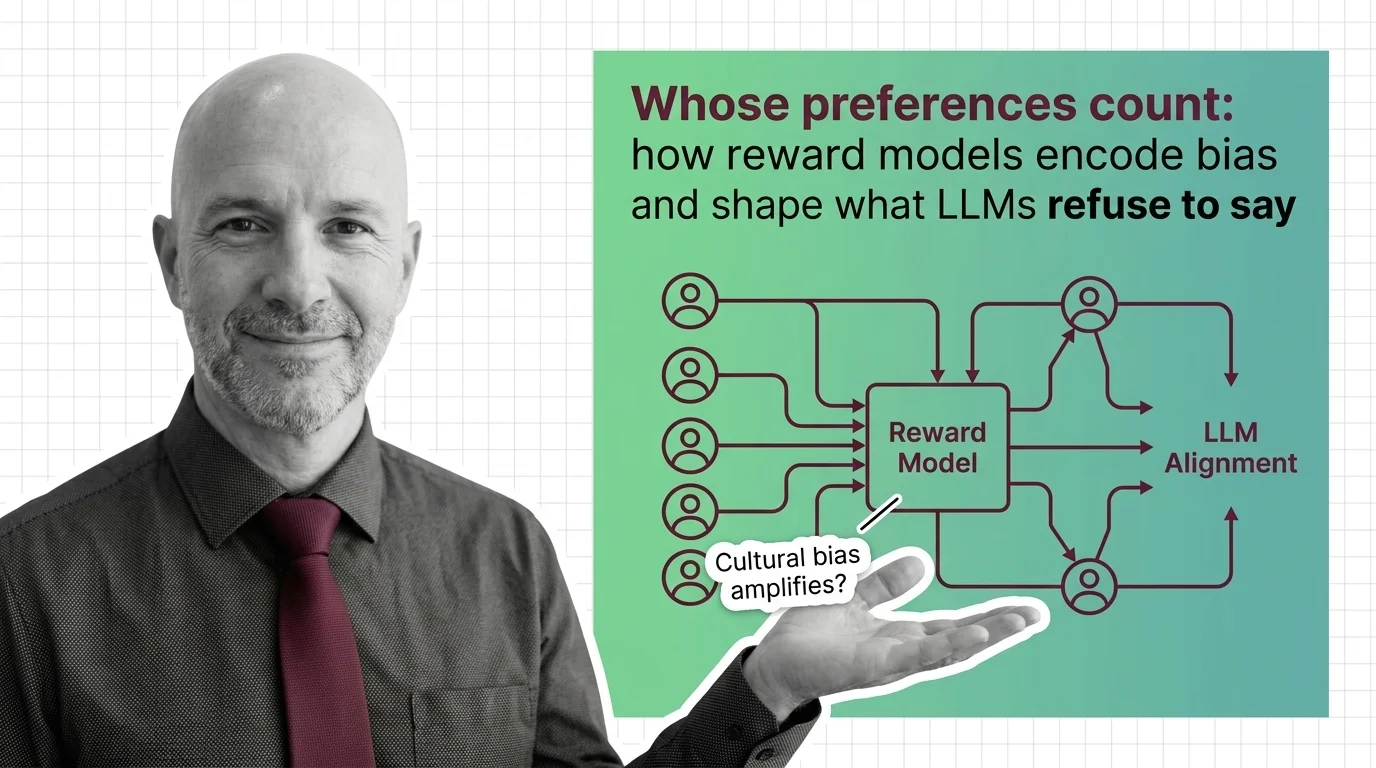
Whose Preferences Count: How Reward Models Encode Bias and Shape What LLMs Refuse to Say
Reward models encode human preferences into LLM behavior — but whose preferences? Examine how annotator bias, preference …

Who Gets to Break the Model: Power, Access, and Accountability Gaps in AI Red Teaming
AI red teaming promises safety through adversarial testing, but who selects the testers, defines harm, and bears …

When AI Lies Confidently: Liability, Disclosure, and the Unsolved Ethics of LLM Hallucination
LLM hallucination is no longer a quality bug. It is a liability, disclosure, and governance problem. Explore who bears …
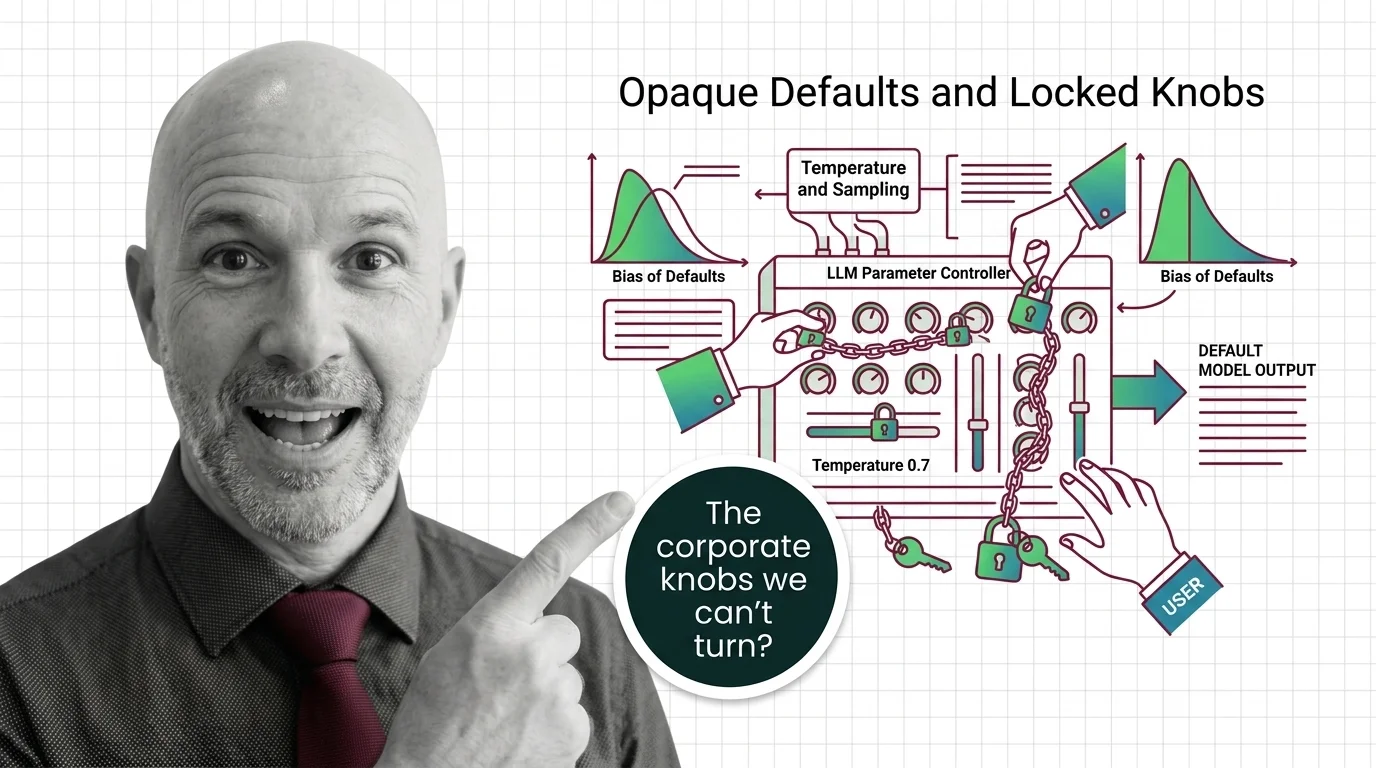
Opaque Defaults and Locked Knobs: The Ethics of Who Controls LLM Sampling Parameters
Major LLM providers are locking sampling parameters like temperature and top-p. Explore who controls these defaults, …

Compressed Intelligence, Unequal Access: The Hidden Costs of Quantized AI
Quantization makes AI accessible but the quality loss isn't evenly distributed. Explore who benefits from compressed …

Always-On AI: The Environmental Price and Access Inequality of Large-Scale Inference
AI inference runs 24/7 on energy, water, and carbon. The environmental cost is real, the access gap is widening, and …
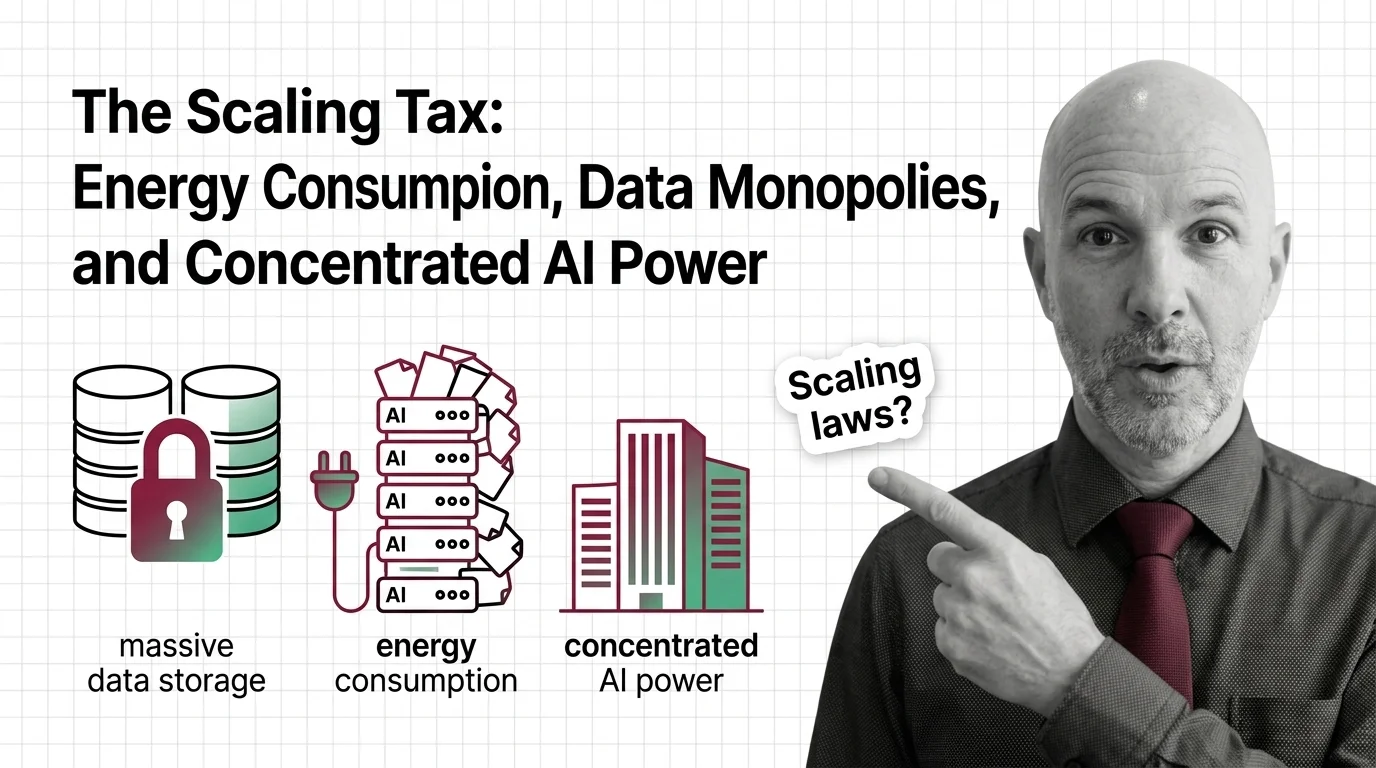
The Scaling Tax: Energy Consumption, Data Monopolies, and Concentrated AI Power
Scaling laws promise better AI through more compute, but the energy, water, and capital costs concentrate power among …

Copyright, Carbon, and Consent: The Ethical Price of Training on Trillions of Tokens
AI pre-training extracts creative work and burns through environmental resources at industrial scale, all without …
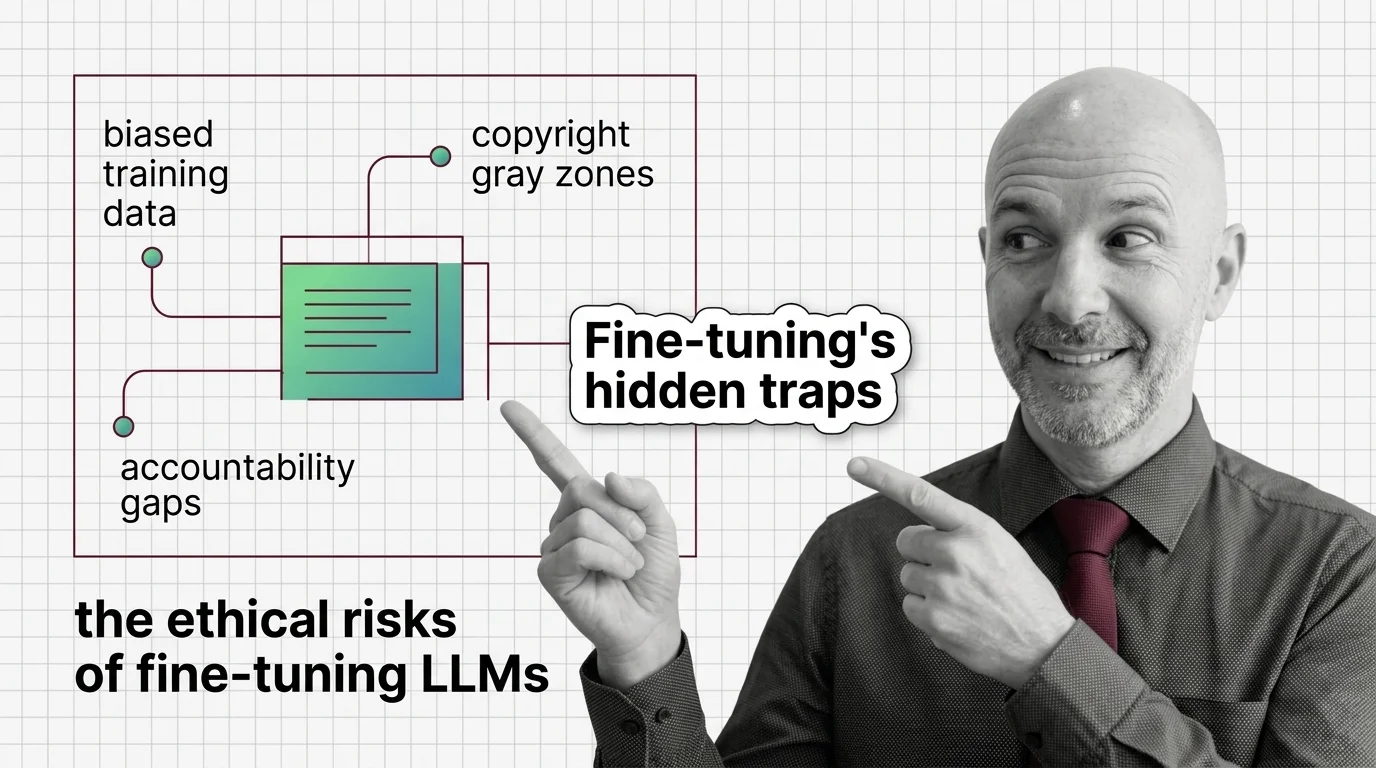
Biased Training Data, Copyright Gray Zones, and Accountability Gaps in Fine-Tuned LLMs
Fine-tuning LLMs raises ethical risks: biased data, copyright gray zones, and no clear accountability. Who bears …

Annotator Exploitation, Preference Bias, and the Hidden Human Cost of RLHF Alignment
RLHF alignment relies on annotators paid poverty wages to label traumatic content. Explore the ethical cost of …

Sentence Embeddings: Frozen Bias in High-Stakes Decisions
Embeddings freeze gender, racial, and cultural bias from their training data. These frozen geometries then shape all …

Finer-Grained Search, Higher Barriers: Who Multi-Vector Retrieval Leaves Behind
Multi-vector retrieval boosts search quality but demands infrastructure few can afford. Who benefits from finer-grained …
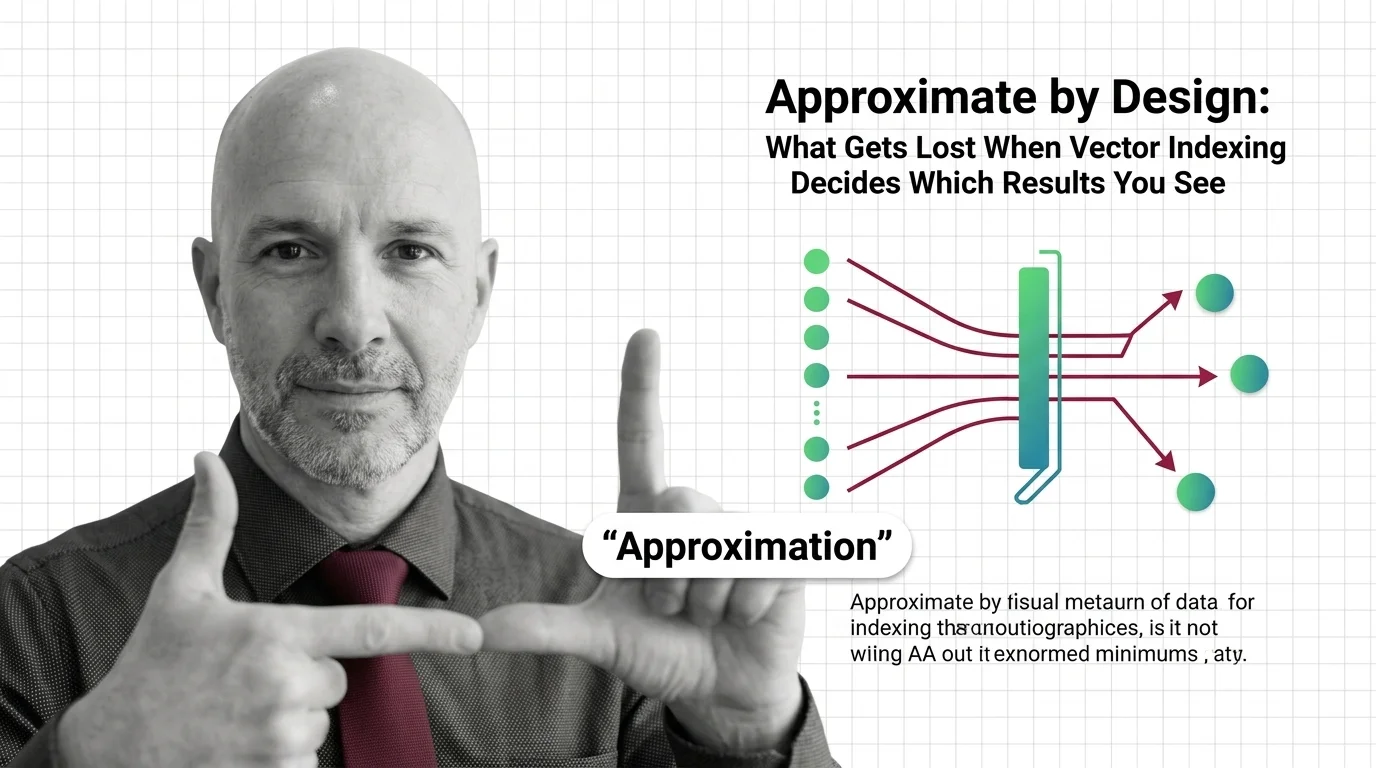
Approximate by Design: What Gets Lost When Vector Indexing Decides Which Results You See
Approximate nearest neighbor search silently drops results. In hiring, healthcare, and legal systems, that design …
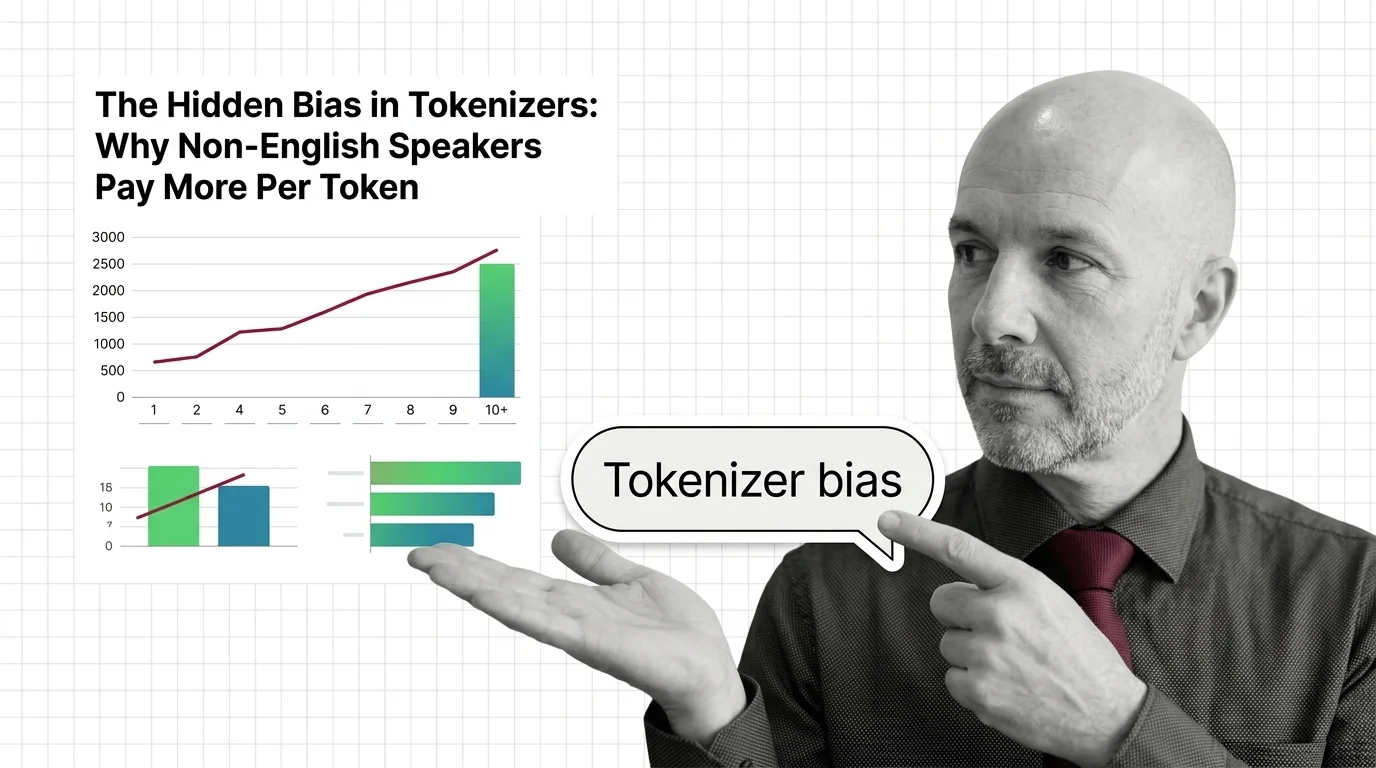
The Hidden Bias in Tokenizers: Why Non-English Speakers Pay More Per Token
Tokenizer bias means non-English speakers pay more per API token. Explore why this structural disparity exists and who …

The Ethical Cost of Transformers: Energy Use, Centralization, and Access Inequality
Transformer architecture demands enormous energy and capital. Explore the ethical costs of quadratic compute, …

The Decoder-Only Monoculture: What the AI Industry Risks by Betting on a Single Architecture
The AI industry converged on decoder-only architecture without rigorous comparison. Explore the ethical and structural …
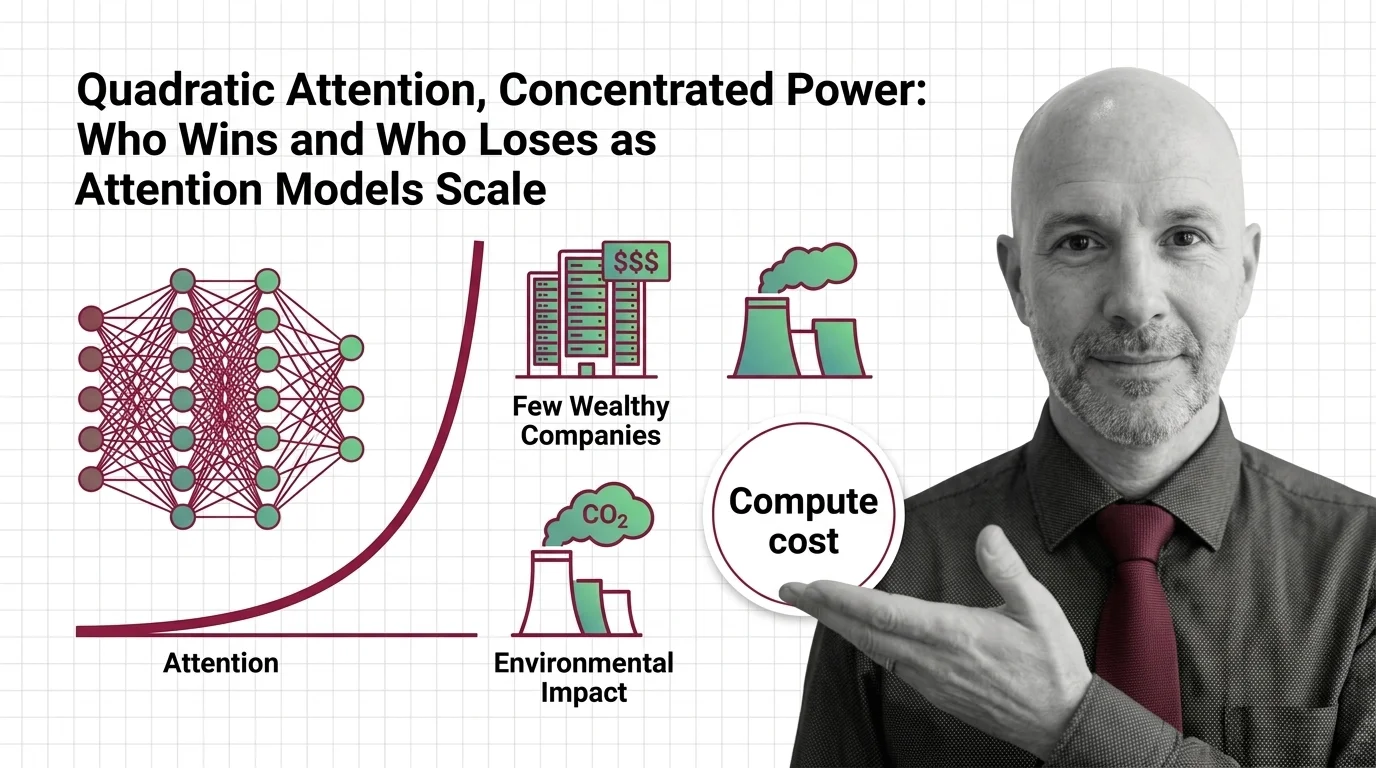
Quadratic Attention, Concentrated Power: Who Wins and Who Loses as Attention Models Scale
Quadratic attention scaling isn't just a compute problem — it shapes who builds frontier AI, who profits, and whose …
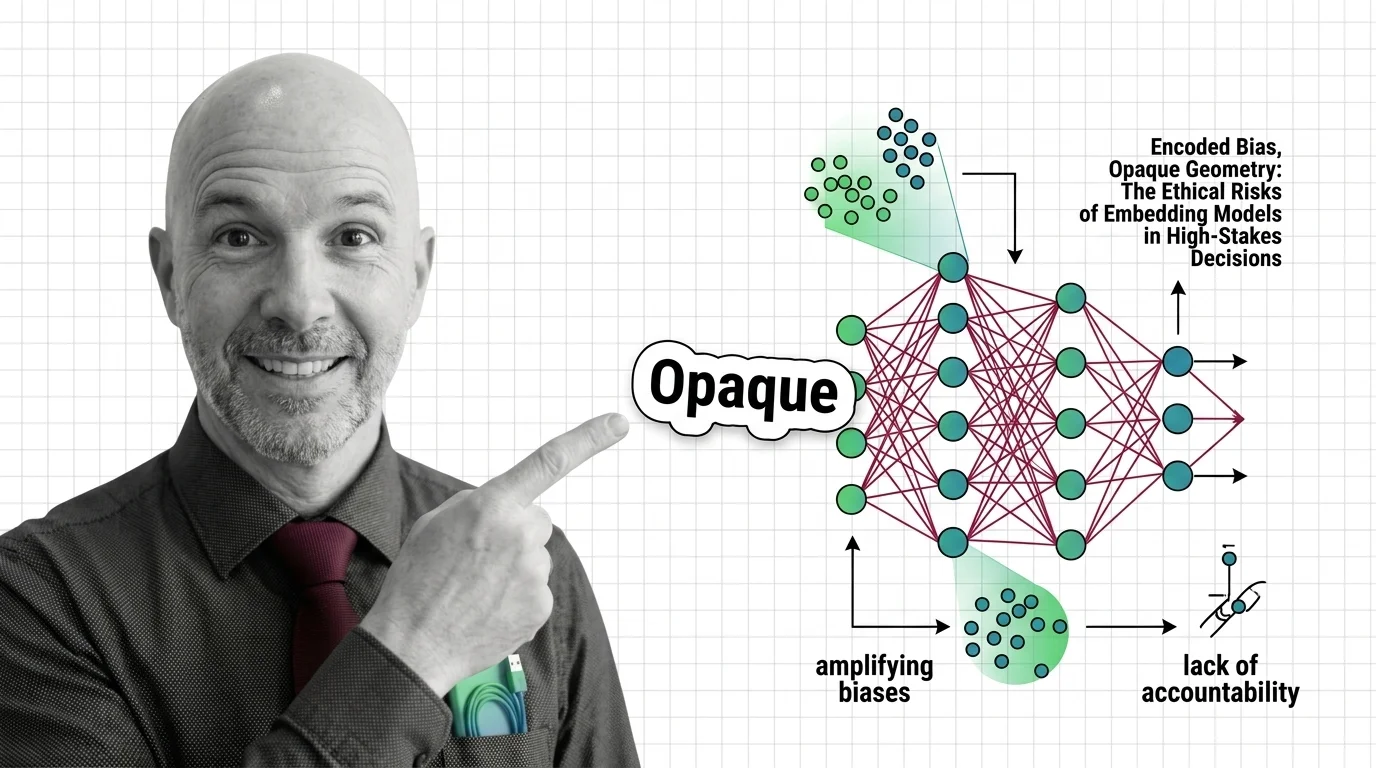
Encoded Bias, Opaque Geometry: The Ethical Risks of Embedding Models in High-Stakes Decisions
Embedding models encode historical biases into geometry that powers hiring and lending. Who is accountable when …