
Who Judges the Judge? Bias and Accountability When AI Evaluates AI
Who Judges the Judge? Bias and Accountability When AI Evaluates AI The Hard Truth

Teaching to the Test: How Benchmark Optimization Distorts AI Progress
Teaching to the Test: How Benchmark Optimization Distorts AI Progress The Hard Truth

When Synthetic Replaces Real: Bias Laundering and Accountability in Generated Datasets
When Synthetic Replaces Real: Bias Laundering and Accountability in Generated Datasets The Hard …

Does Active Learning Amplify Dataset Bias? The Ethics of Letting Models Choose What Humans Label
Does Active Learning Amplify Dataset Bias? The Ethics of Letting Models Choose What Humans Label The …
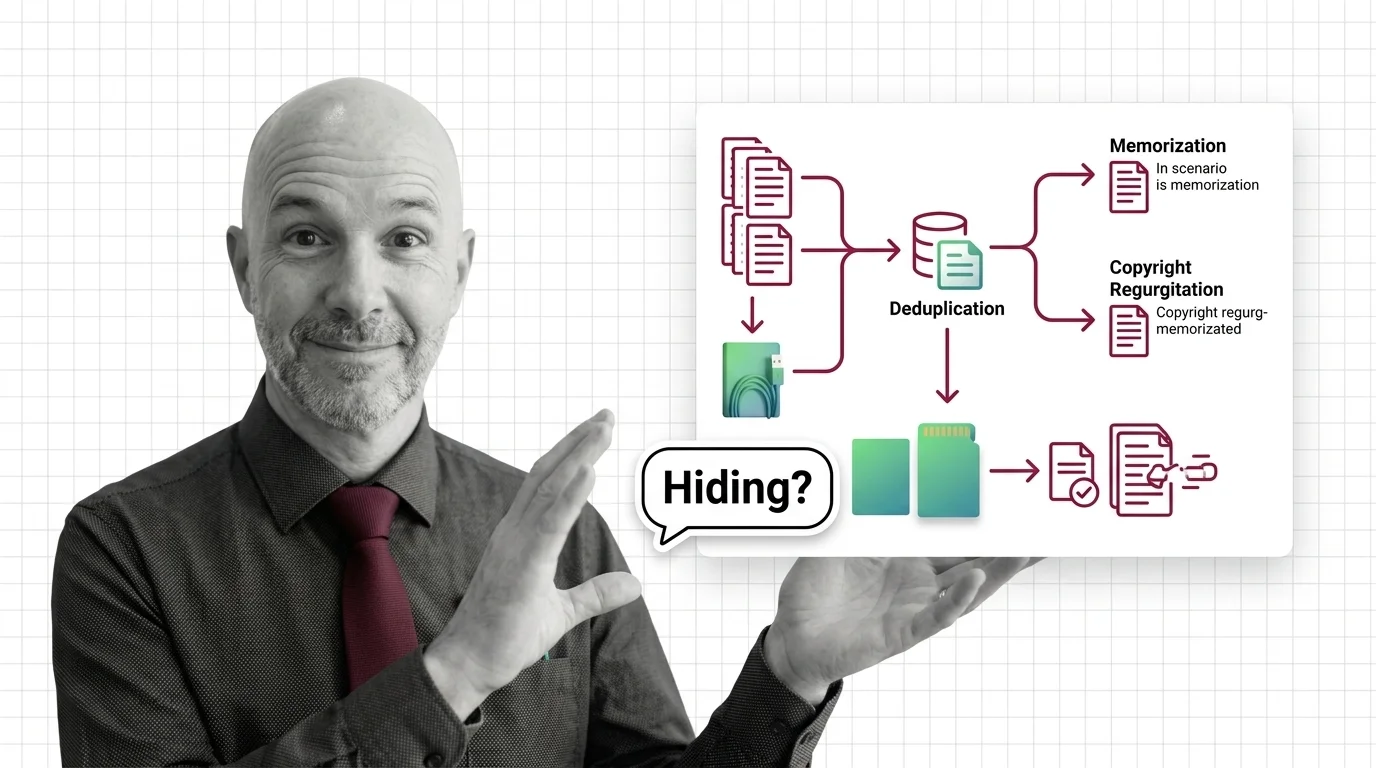
Does Deduplication Fix Memorization and Copyright Regurgitation, or Just Hide It?
Does Deduplication Fix Memorization and Copyright Regurgitation, or Just Hide It? The Hard Truth
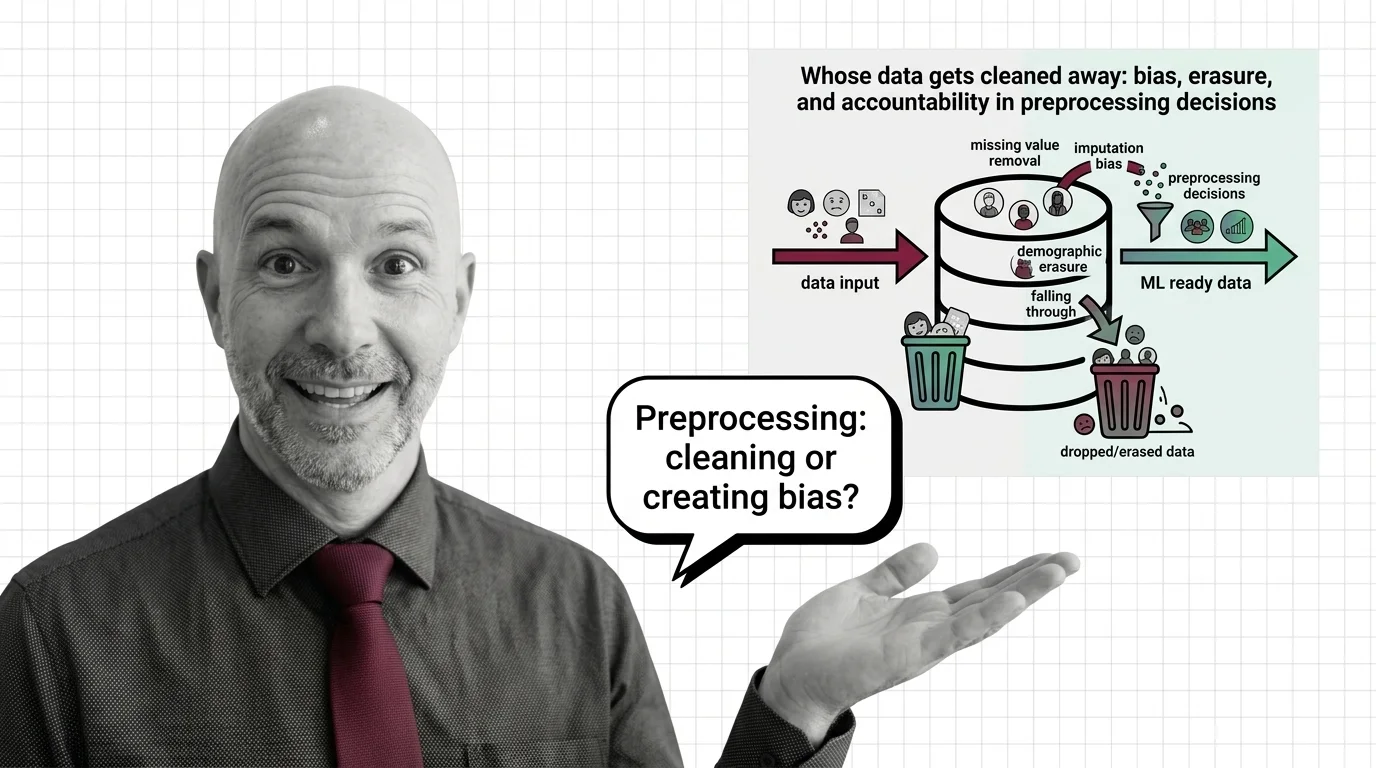
Whose Data Gets Cleaned Away: Bias, Erasure, and Accountability in Preprocessing Decisions
Whose Data Gets Cleaned Away: Bias, Erasure, and Accountability in Preprocessing Decisions The Hard …

Underpaid Annotators and Hidden Bias: The Ethical Cost of the Data Labeling Industry
Underpaid Annotators and Hidden Bias: The Ethical Cost of the Data Labeling Industry The Hard Truth

Augmenting Bias: The Ethical Risks of Synthetic and LLM-Generated Training Data
Augmenting Bias: The Ethical Risks of Synthetic and LLM-Generated Training Data The Hard Truth

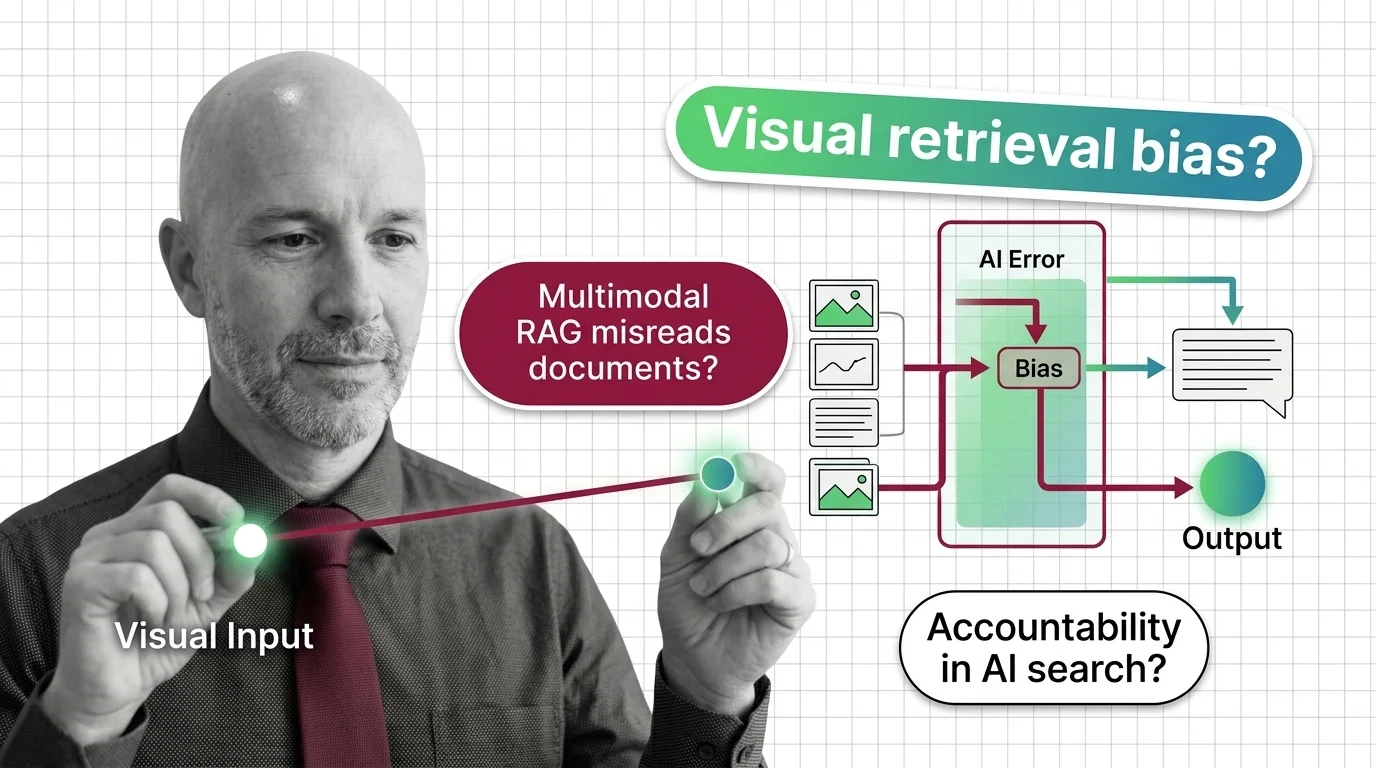
When Multimodal RAG Misreads the Document: Accountability and Bias in Visual Retrieval
Multimodal RAG decides what counts as relevant before a human reads the page. When the retriever misreads, who is …
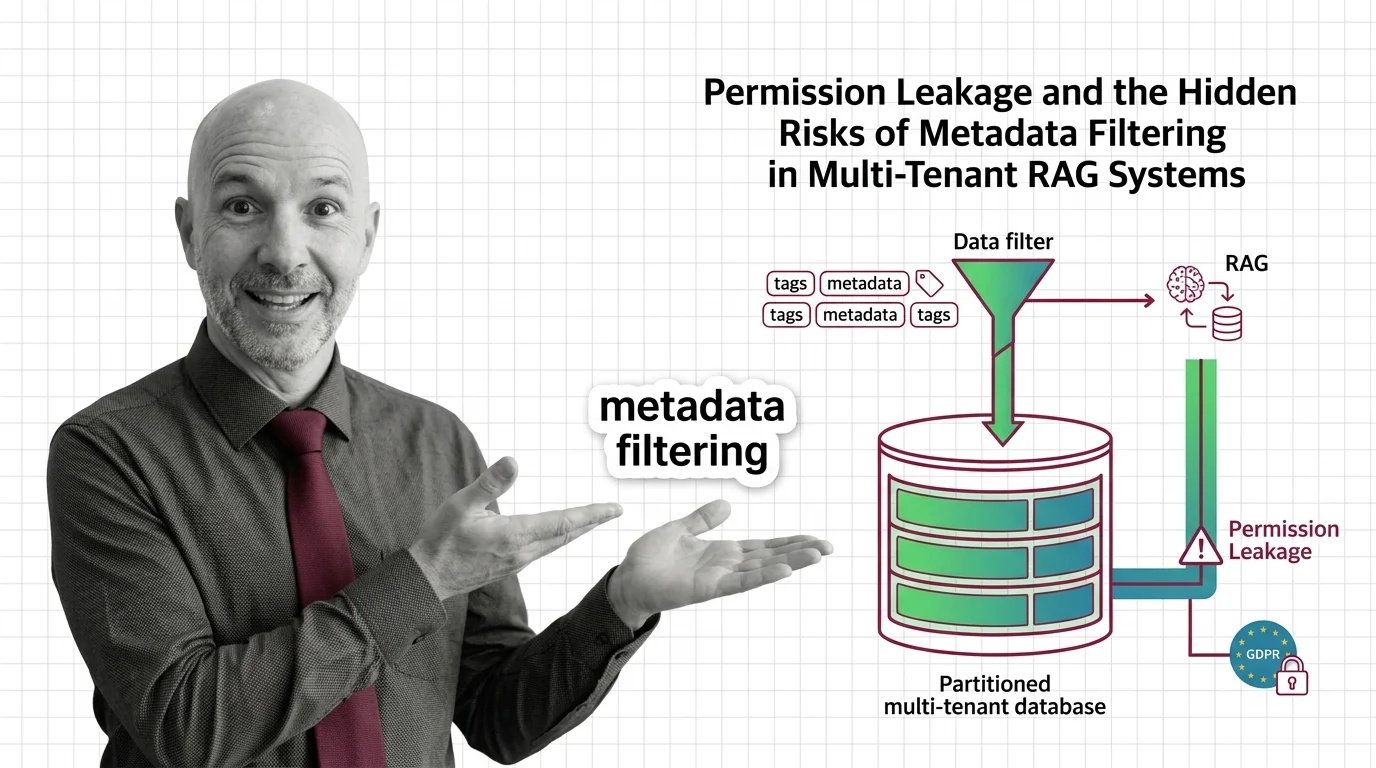
Permission Leakage: Hidden Risks of Metadata Filtering in RAG
Metadata filtering looks like access control, but isn't. The ethical and GDPR cost of using a query optimization as a …
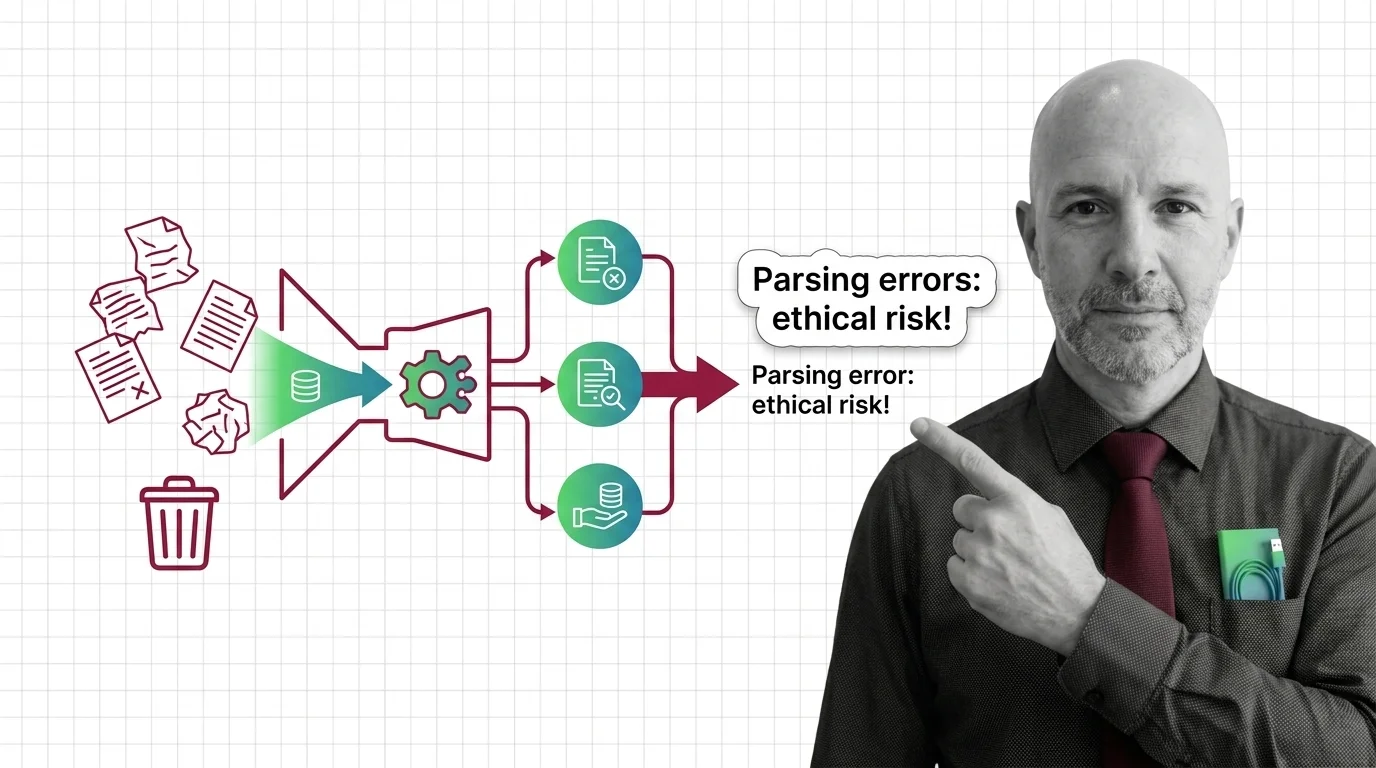
Garbage In, Garbage Out: The Ethical Cost of RAG Parsing Errors
Document parsing errors in high-stakes RAG aren't just engineering bugs — they are moral failures with cascading …
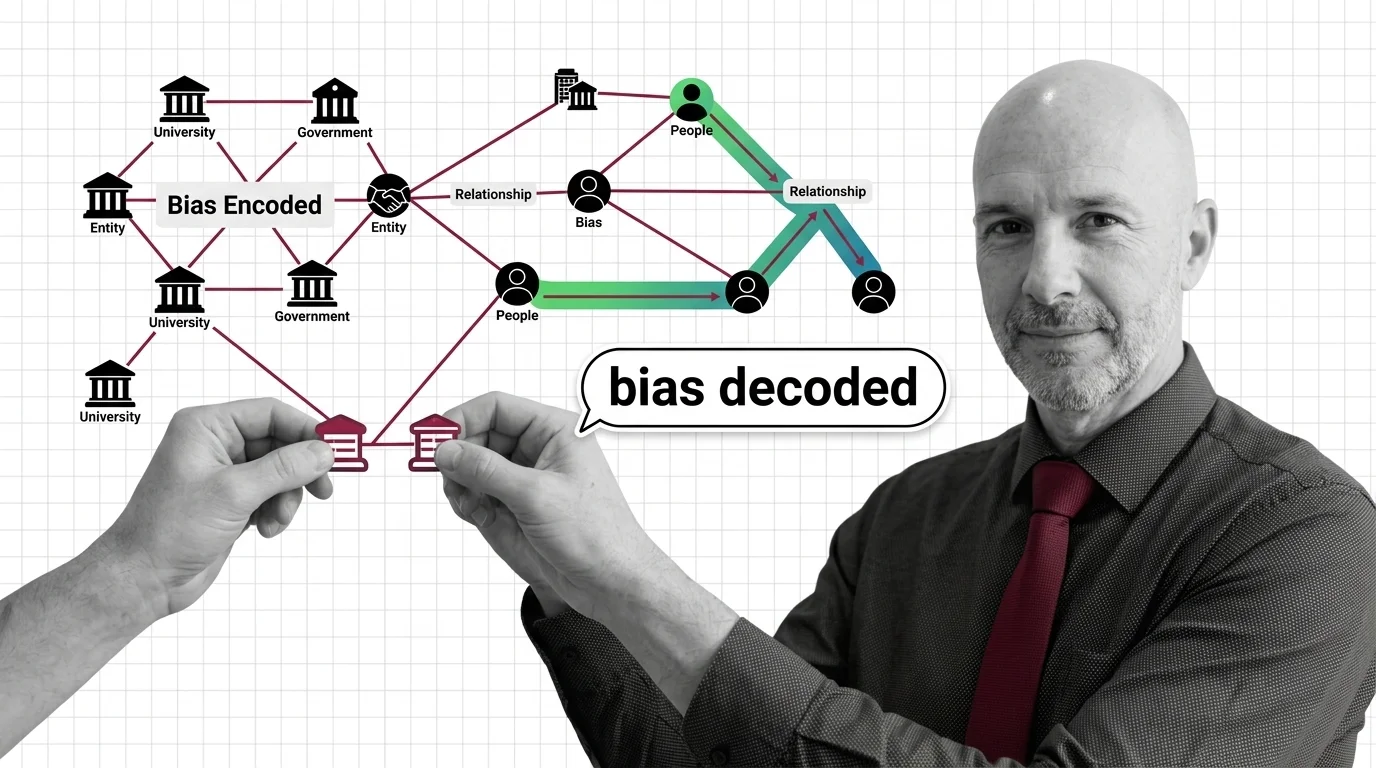
When the Graph Decides What's True: Bias in Knowledge Graph RAG
Knowledge Graph RAG is sold as the audit-friendly answer to hallucination. But every graph encodes a worldview — and at …

When RAG Confidence Scores Mislead in High-Stakes Decisions
RAG faithfulness scores can hit 0.95 and still produce wrong answers. Why confidence numbers fail in healthcare, legal, …

Interpretable but Not Innocent: The Ethics of Sparse Retrieval
Sparse retrieval is sold as interpretable search for high-stakes domains. But interpretable is not innocent — the …
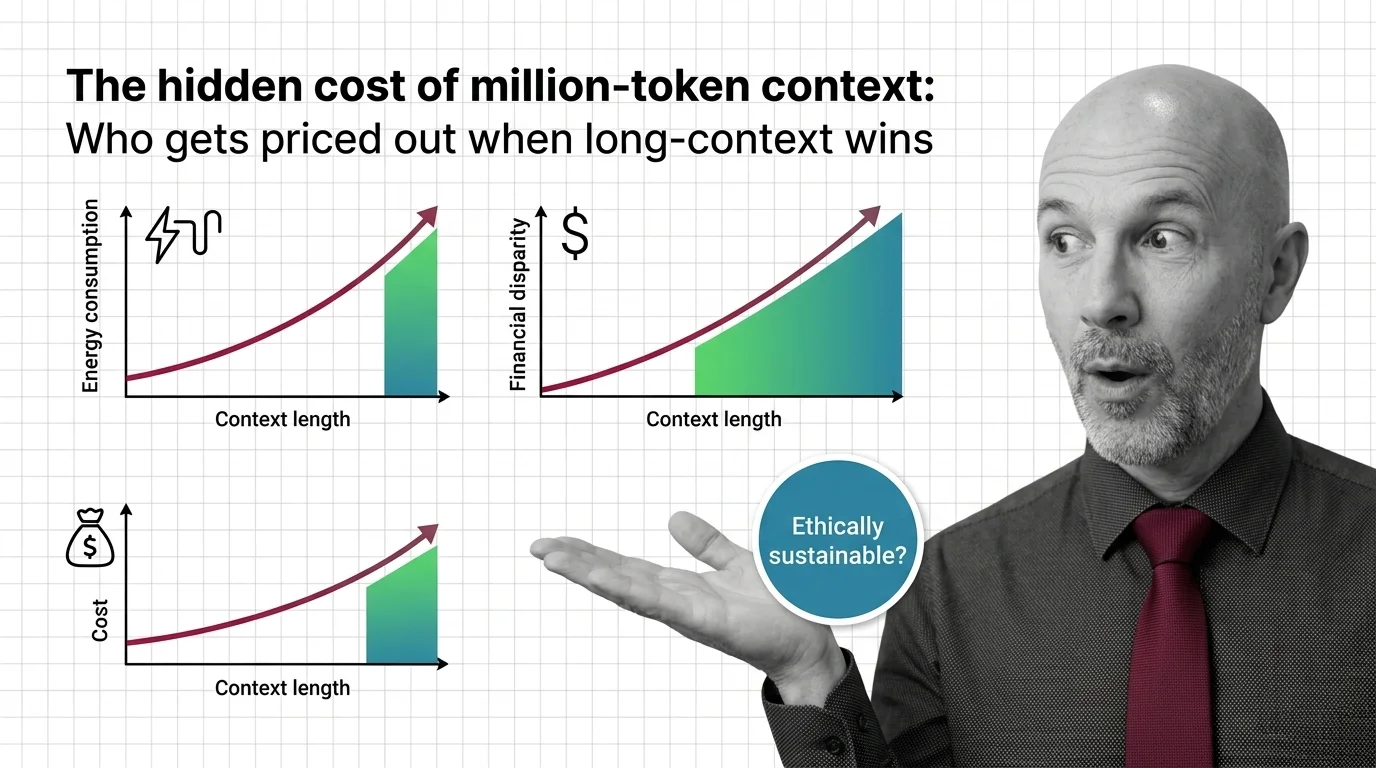
The Hidden Cost of Million-Token Context: Who Gets Priced Out
Million-token context windows shift cost, energy, and access burdens. An ethical look at who pays — and who gets priced …
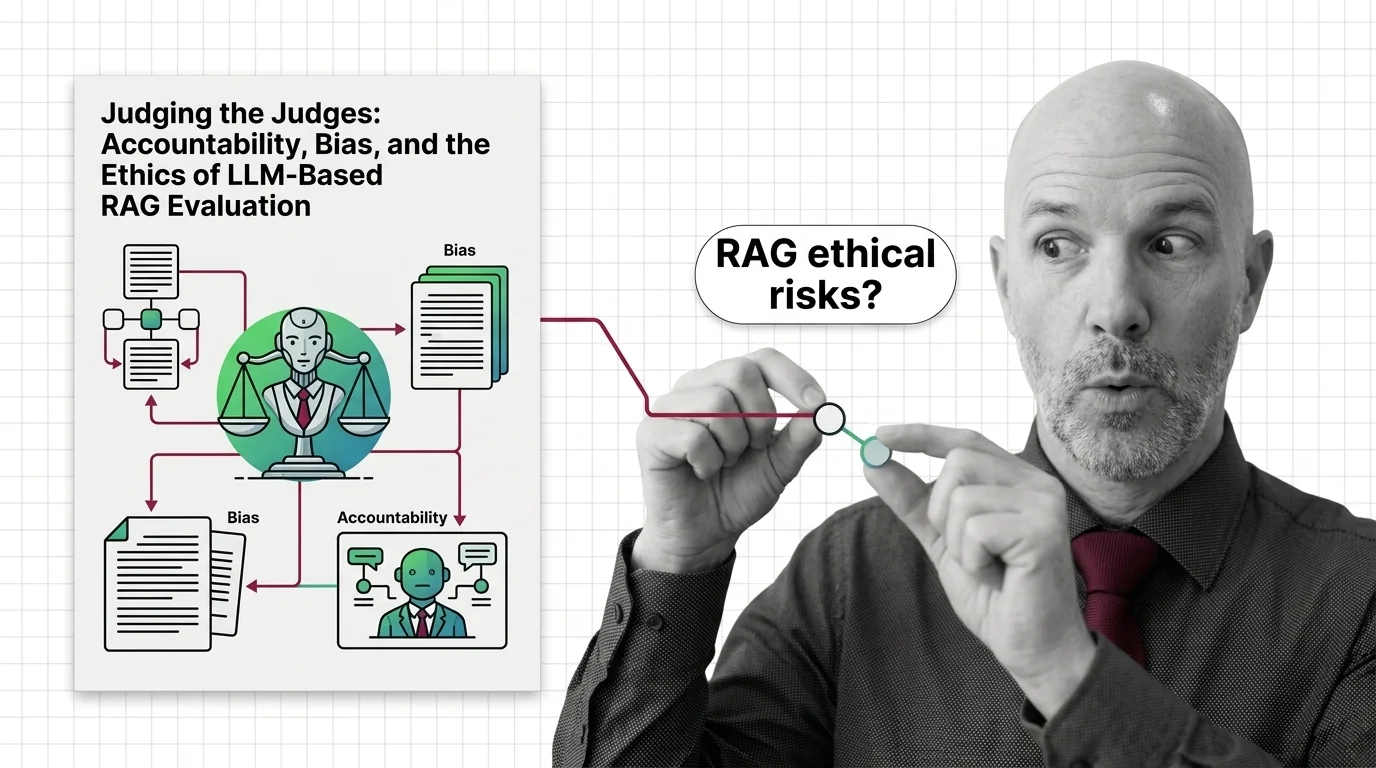
Judging the Judges: Bias and Ethics of LLM-Based RAG Evaluation
LLM-as-judge promises scalable RAG evaluation but inherits documented biases, opacity, and a quiet accountability gap. …

When the Agent Picks Sources: Accountability in Agentic RAG
Agentic RAG hands source selection to autonomous LLM agents. The accountability stack — from corpus skew to bias …

Whose Documents Get Found? The Ethical Stakes of Contextual Retrieval in High-Recall Search
Contextual retrieval improves recall by deciding which context counts. When that decision shapes hiring, credit, and …

Closed APIs and Opaque Scoring: The Ethics of Outsourced Reranking
Top rerankers come with non-commercial licenses or closed APIs. Reranking quality is rising; our ability to inspect the …

Whose Query Gets Transformed? Bias Amplification and Accountability in LLM-Rewritten Retrieval
When LLMs silently rewrite your query before retrieval, who is accountable for the answer? An ethical look at RAG bias …
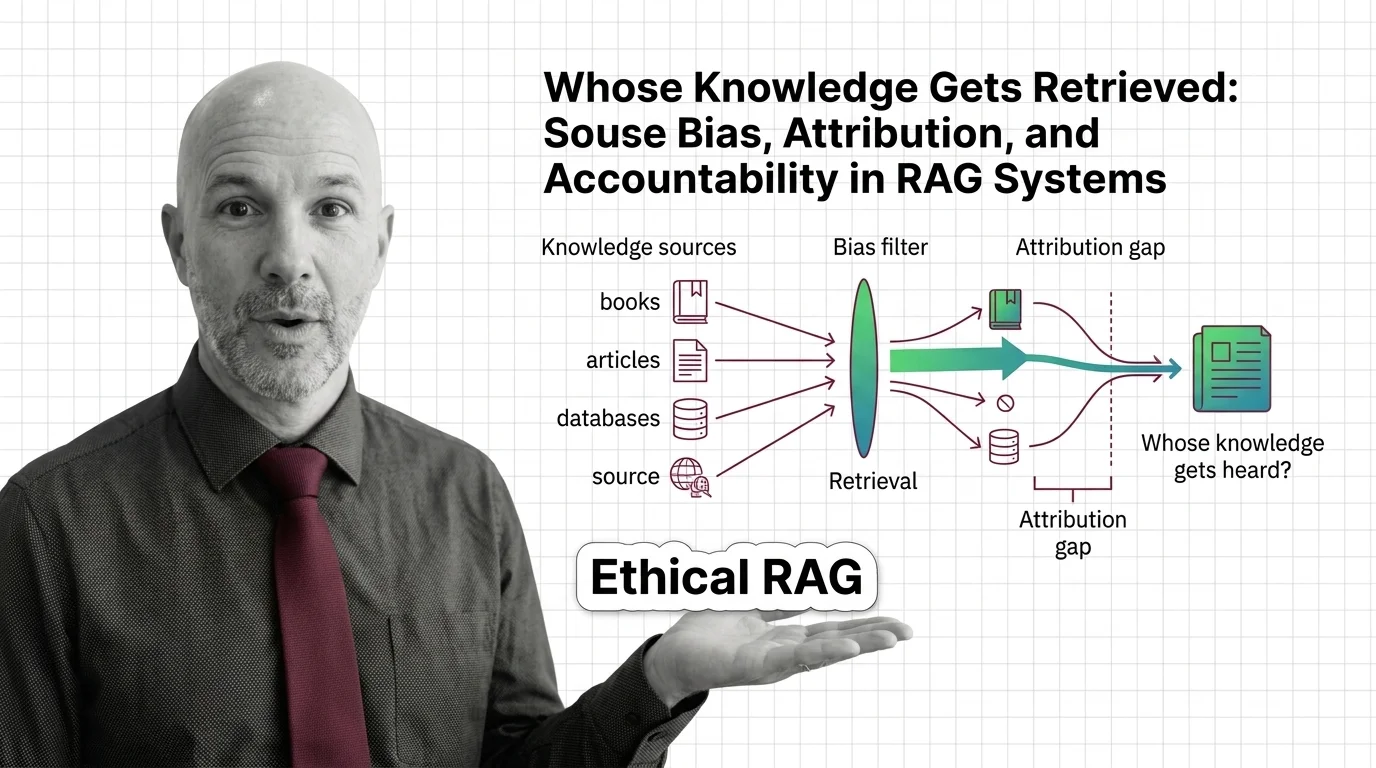
Whose Knowledge Gets Retrieved: Bias and Accountability in RAG
Retrieval-augmented generation isn't neutral. Source bias, attribution gaps, and corpus poisoning quietly decide whose …

Hybrid Search Looks Neutral but Isn't: Lexical Bias and the Languages BM25 Leaves Behind
Hybrid search looks neutral. But BM25's tokenizer favors English, and the languages it leaves behind reveal what …

Deepfakes, Scraped Art, Consent: The Ethical Reckoning of Diffusion Models
Diffusion models scraped the internet before asking. Now lawsuits, legislation, and artist tools are forcing a consent …
Surveillance, Deepfakes, Consent: Multimodal AI's Ethical Crisis
Multimodal AI can now see, hear, and speak in one pass. The ethics haven't caught up. What consent, surveillance, and …
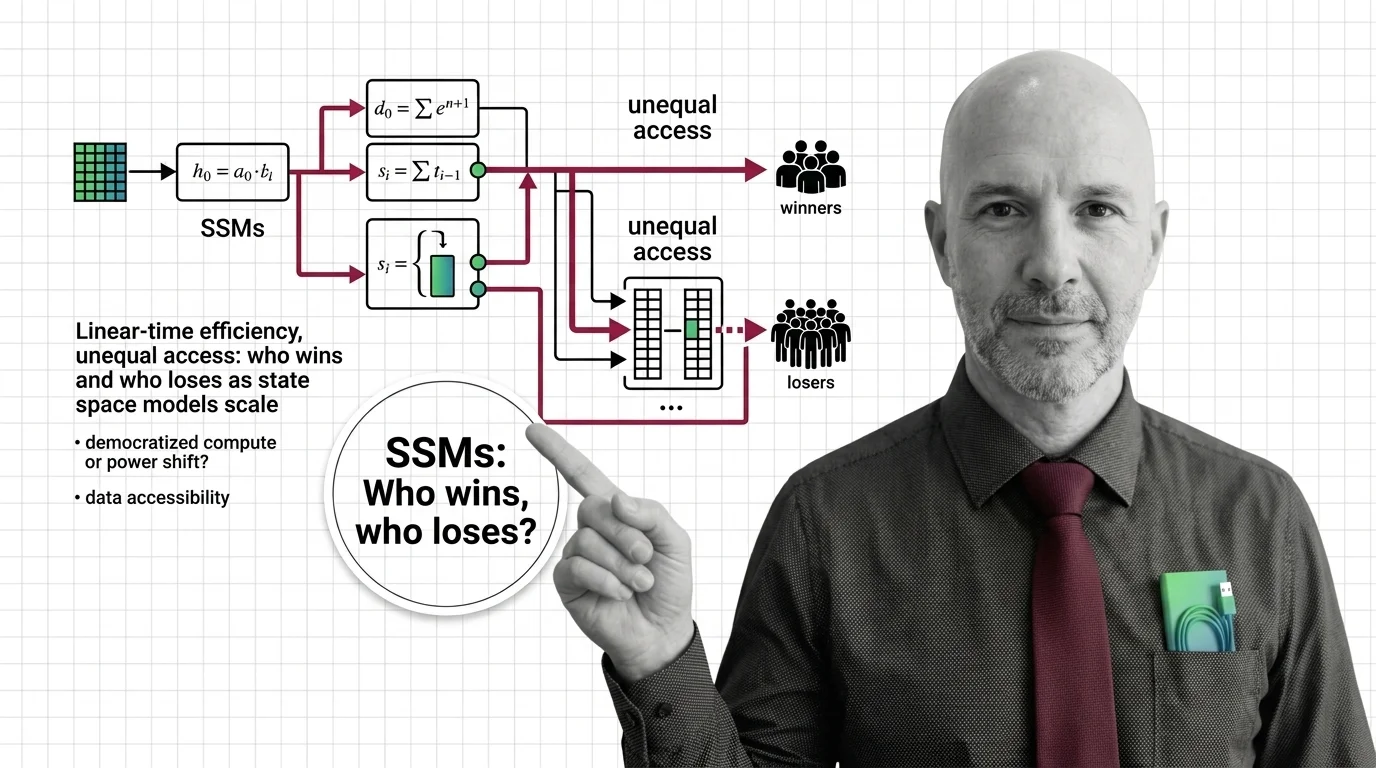
Linear-Time Efficiency, Unequal Access: Who Wins and Who Loses as State Space Models Scale
State space models slash inference costs and open long-context AI. But cheaper compute reshapes who holds power — and …
Biased Training Data and Patch-Level Attacks: The Ethical Risks of Vision Transformers in High-Stakes Systems
Vision Transformers deployed in healthcare and surveillance inherit bias from web-scraped datasets. From LAION to …
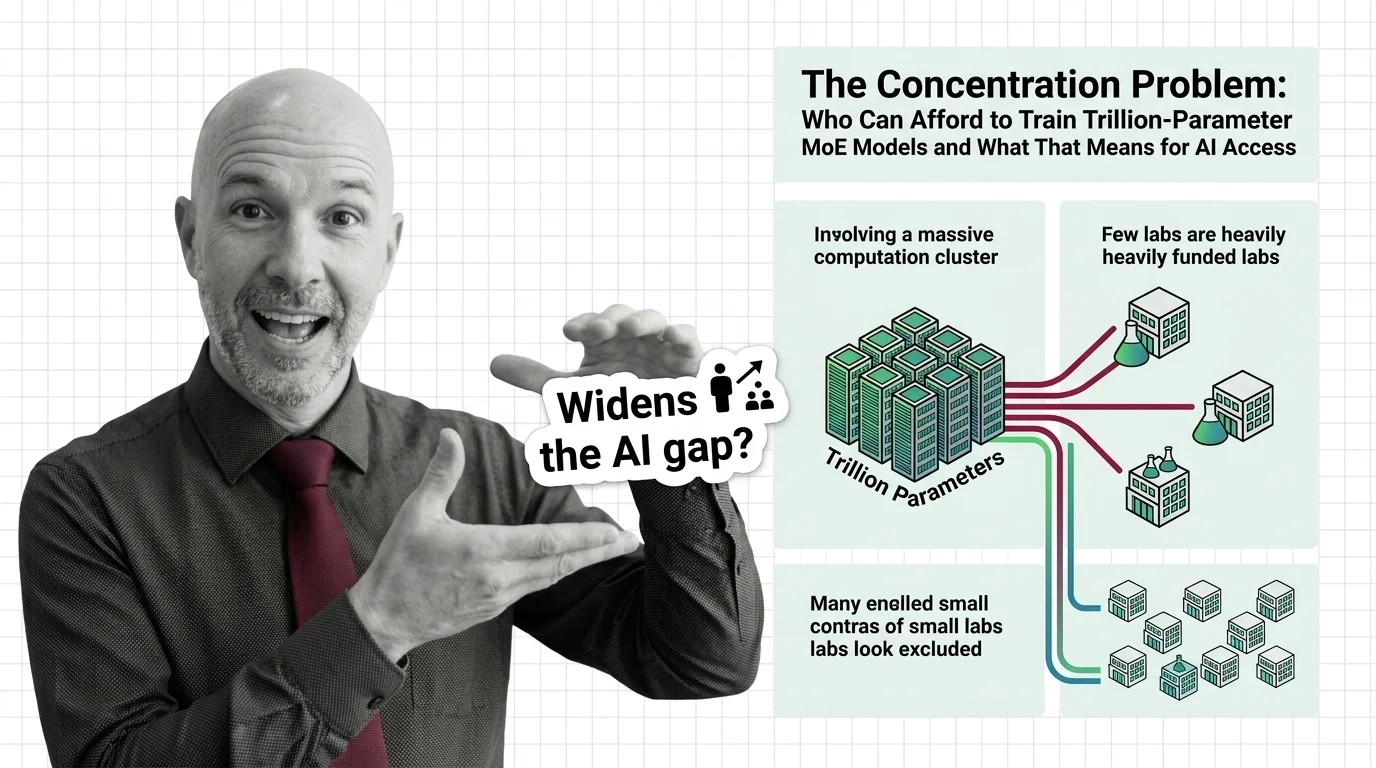
The Concentration Problem: Who Can Afford to Train Trillion-Parameter MoE Models and What That Means for AI Access
Trillion-parameter MoE models promise efficiency through sparse activation. But training costs keep rising, and the …
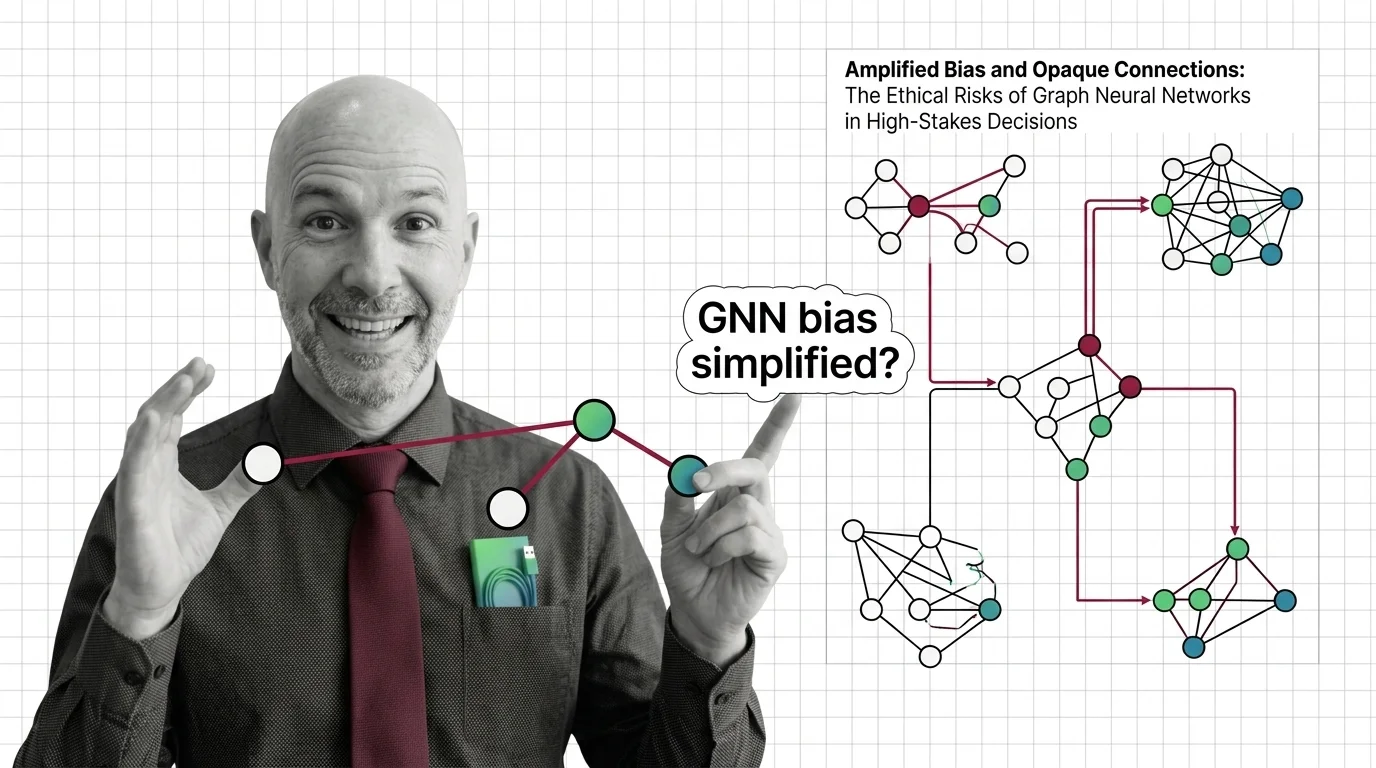
Amplified Bias and Opaque Connections: The Ethical Risks of Graph Neural Networks in High-Stakes Decisions
Graph neural networks judge people by connections. When those relationships encode historical inequality, bias amplifies …
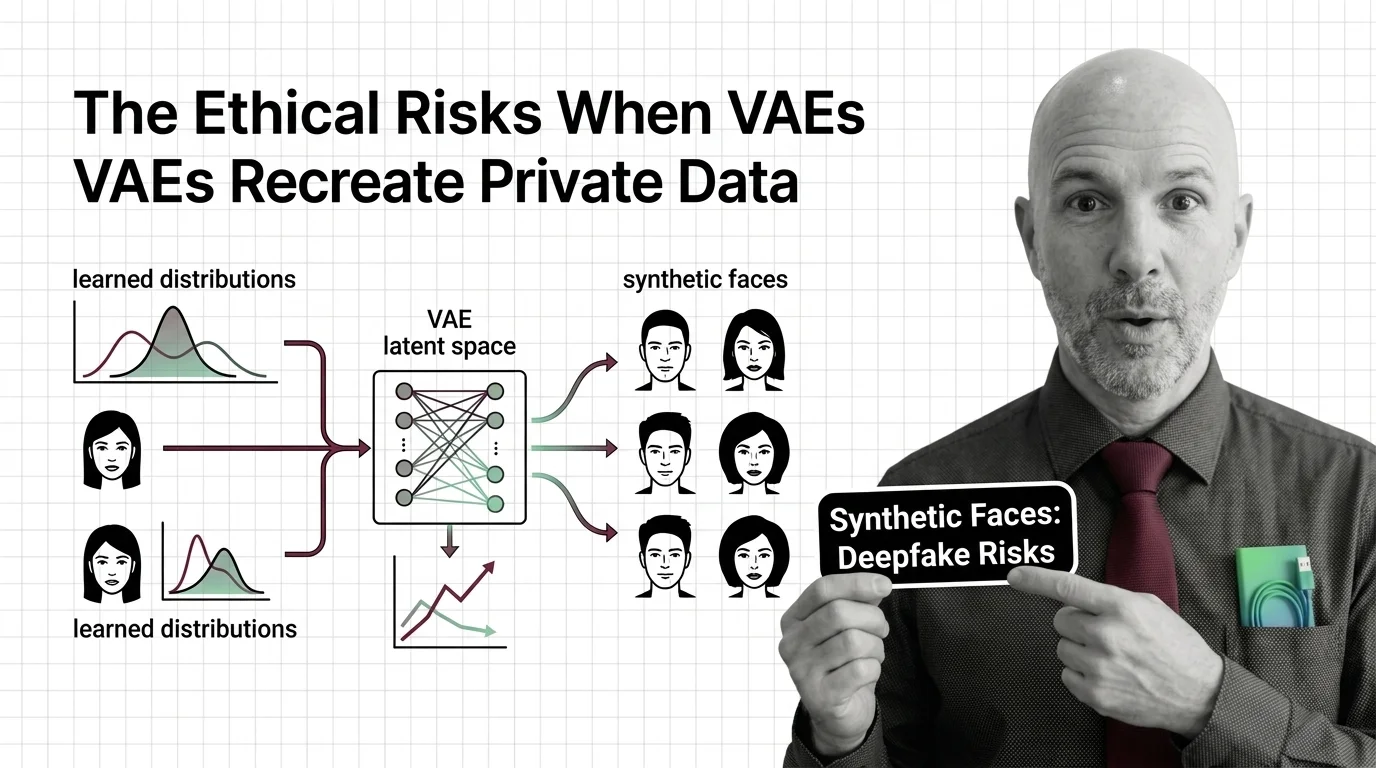
Synthetic Faces and Learned Distributions: The Ethical Risks When VAEs Recreate Private Data
Variational autoencoders can memorize and recreate private training data. Why synthetic faces and medical records are …