Catastrophic Forgetting, Overfitting, and the Hard Technical Limits of LLM Fine-Tuning

Table of Contents
ELI5
Fine-tuning teaches a model new skills by changing its weights — but those same changes can erase what it already knew. The technical name for this erasure is catastrophic forgetting.
You train a model on medical terminology for three days. It generates flawless clinical summaries. Then you ask it to write a simple email, and the output reads like a patient intake form — stilted, overspecialized, stripped of the fluency it had last week. The model didn’t break in any way a log file would show you. It forgot.
This is the central tension of Fine Tuning: the mechanism that enables learning is the same mechanism that enables destruction. Every weight update that moves the model closer to your task moves it further from everything else it once knew. The question isn’t whether this happens — it’s whether the math gives you enough control over how much.
The Geometry of Adaptive Forgetting
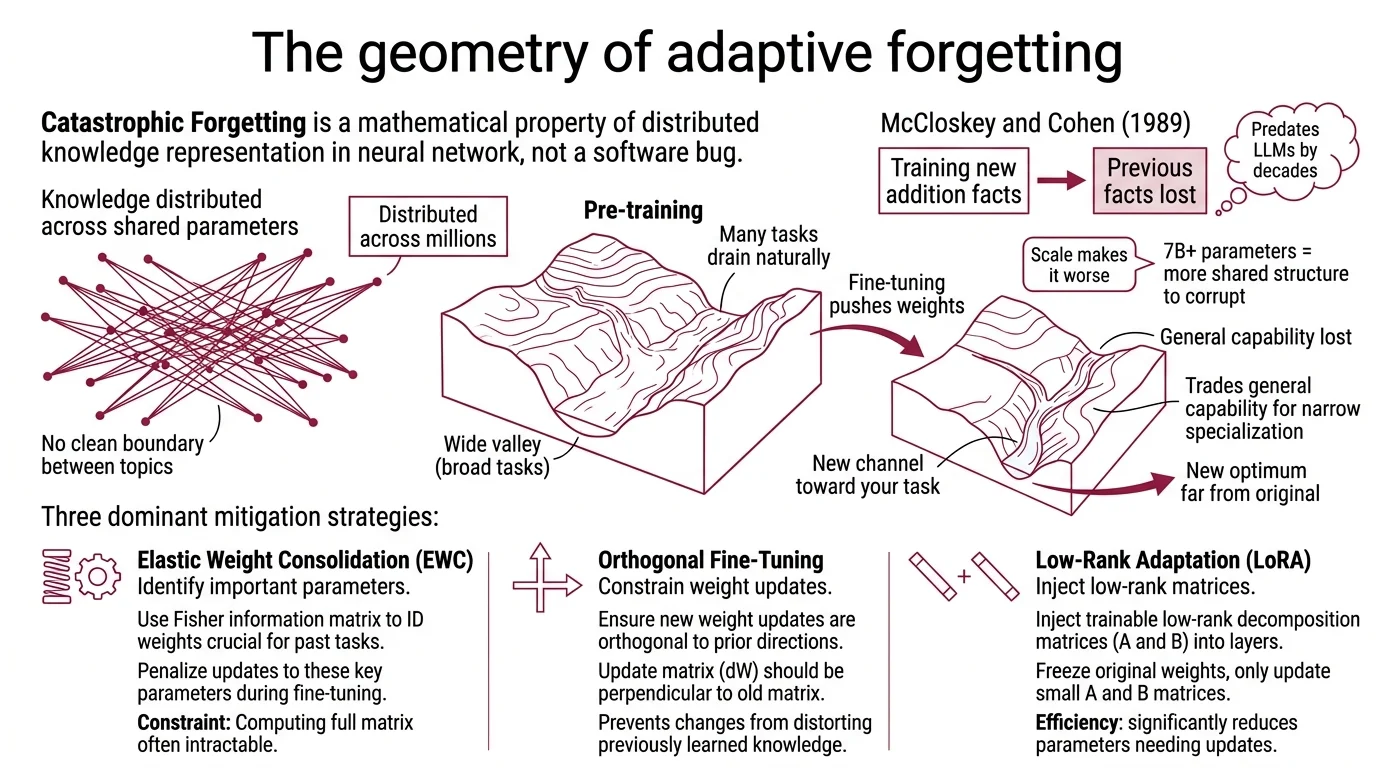
Catastrophic Forgetting is not a software bug. It is a mathematical property of how neural networks store knowledge — distributed across millions of shared parameters, with no clean boundary between what the model knows about cardiology and what it knows about comma placement.
McCloskey and Cohen demonstrated this in 1989: training a network on new addition facts caused near-complete loss of previously learned facts. The problem predates large language models by decades. Scale makes it worse, not better, because a 7-billion-parameter model has more shared structure to corrupt, and the entanglement between tasks runs deeper through the weight space.
What is catastrophic forgetting in fine-tuning and how to prevent it
The mechanism is geometric. During pre-training, the model’s weights settle into a region of parameter space that performs well across a broad distribution of language tasks. Fine-tuning pushes those weights toward a new optimum — one that minimizes loss on your specific dataset. If the new optimum sits far from the original in parameter space, the model trades general capability for narrow specialization.
Think of a landscape carved by a river. The pre-trained model occupies a wide valley where many tasks drain naturally. Fine-tuning digs a new channel toward your task — but the water that flows there stops flowing everywhere else. The topology of the loss surface determines how much you lose.
Three mitigation strategies dominate the current literature, each attacking a different axis of the problem:
Elastic Weight Consolidation (EWC) uses the Fisher information matrix to identify which parameters matter most for previously learned tasks, then penalizes updates to those parameters during fine-tuning. Kirkpatrick et al. introduced EWC in 2017, and the core insight remains sound: not all weights are equally important, so don’t treat them equally. The constraint is that computing the Fisher matrix adds overhead, and the protection is approximate — it slows forgetting rather than preventing it.
Parameter Efficient Fine Tuning sidesteps the problem differently: freeze most of the original weights entirely. LORA — the most widely adopted PEFT method — injects small trainable low-rank matrices alongside the frozen layers. The original weights stay untouched; the adapter learns the delta. A starting rank of r=16, scaling to r=32-64 for significant domain shifts (Unsloth Docs), recovers a substantial portion of full fine-tuning quality — though the gap widens on complex reasoning tasks where the low-rank approximation limits expressiveness.
QLORA pushes the hardware boundary further. Quantizing the frozen base model to 4-bit precision enables fine-tuning a 7B model on a single RTX 4090 — hardware that couldn’t approach the memory demands of full fine-tuning (Introl Blog). The trade-off is quantization noise, but for most instruction-tuning tasks, it’s noise the model absorbs without measurable regression.
SA-SFT (Self-Augmentation Fine-Tuning) takes a different approach entirely: the model generates synthetic self-dialogues before task-specific training, then mixes this self-generated data with the task data during fine-tuning. No external data required. The effect is a kind of rehearsal — the model practices its existing capabilities while acquiring new ones, reducing the displacement in parameter space (EMNLP 2025).
When the Loss Curve Lies
Here is a training run that looks perfect: loss drops steadily across three epochs, validation accuracy climbs, the model generates increasingly polished outputs. Every chart trends in the right direction.
Then you hand it a prompt it hasn’t seen, and the output is either a near-verbatim recitation of a training example or syntactic noise.
Not a failure of training. A failure of evaluation.
Overfitting is subtler than catastrophic forgetting, and in some ways more dangerous — because the signal that something is wrong hides inside metrics that look healthy. The model memorized your dataset. It didn’t learn the distribution underneath.
The threshold to watch: training loss dropping below 0.2 indicates likely overfitting (Unsloth Docs). At that point, the model isn’t extracting generalizable patterns — it’s encoding specific examples into its weights. The loss curve looks healthy right up until generalization collapses on out-of-distribution inputs.
Three hyperparameters control this boundary, and none of them is optional:
Epochs. One to three passes through the dataset is the standard range. Beyond three, overfitting risk compounds with diminishing returns (Unsloth Docs). Each additional epoch gives the model another opportunity to memorize rather than abstract.
Learning Rate. For standard LoRA and QLoRA, 2e-4 balances learning speed against stability; for RL-based fine-tuning methods like DPO, 5e-6 is the safer starting point (Unsloth Docs). Too high, and the model overshoots useful minima. Too low, and it converges to a local optimum that doesn’t generalize.
Dataset composition. This is the variable no hyperparameter can rescue. Duplicate examples teach the model to repeat. Inconsistent labels teach it to hedge. Sparse coverage teaches it to hallucinate into gaps. Scaling Laws describe how performance scales with data volume during pre-training, but fine-tuning scaling behavior is less predictable and far more sensitive to the shape of the data distribution than to its size.
When Rewriting Weights Is the Wrong Fix
Not every failure of fine-tuning is a technical failure. Sometimes the technique was never the right tool for the problem.
When does fine-tuning fail compared to prompt engineering or RAG
The question isn’t “should I fine-tune?” The question is “what am I actually trying to change about this model’s behavior?”
Transfer Learning — the broader principle behind fine-tuning — assumes your task requires behavioral changes that the base model cannot achieve through input conditioning alone. But most tasks don’t require weight modification. A well-structured prompt with examples solves the majority of formatting, tone, and instruction-following problems in hours, not weeks (IBM).
The escalation has a logic: start with prompt engineering for tasks where the base model has the knowledge but lacks the output structure. Move to retrieval-augmented generation when the model needs information beyond its training distribution — real-time data, proprietary documents, domain-specific facts that change. Fine-tune only when you need deep behavioral specialization that neither prompting nor retrieval can produce: a model that consistently reasons in a domain-specific way, or one that must conform to a style so specialized that few-shot examples fail to capture it.
Where DPO fits is instructive. Direct Preference Optimization replaces the reward model in RLHF with a simpler objective — learning directly from human preference pairs. The cost difference is roughly an order of magnitude: RLHF training runs into the hundreds of thousands of dollars, while DPO achieves comparable alignment quality at a fraction of that cost, though exact figures vary widely by model size and dataset (Together AI). But DPO is still fine-tuning. It still modifies weights. It still carries the risk of forgetting, and it still demands careful evaluation design.
As of early 2026, OpenAI’s o4-mini supports fine-tuning at $100/hr training cost, with inference at $4/$16 per million tokens for input and output respectively (OpenAI Pricing). Model availability for fine-tuning changes frequently — verify current options before committing infrastructure.
What the Weight Updates Predict
If you understand the mechanisms above, several practical predictions follow — and each one is testable against your own training runs.
If your fine-tuning dataset covers a narrow domain, expect regression in adjacent domains. The narrower the data, the further the weight updates push from the pre-trained optimum. LoRA with a conservative rank limits the displacement; full fine-tuning amplifies it.
If your training loss drops rapidly in the first epoch, your dataset is either too small or too homogeneous. The model is memorizing, not learning a distribution. Add more diverse examples before adding more epochs.
If your fine-tuned model performs well on held-out test data but poorly on real-world inputs, your test set likely shares distributional quirks with your training data. The overfitting isn’t visible because your evaluation is overfitted too.
Rule of thumb: if prompt engineering gets you within reach of acceptable performance, the risk-to-reward ratio of fine-tuning rarely favors the weights.
When it breaks: Fine-tuning breaks hardest when the task domain is narrow, the dataset is small, and the evaluation metrics mirror the training distribution too closely to catch memorization. In those conditions, every mitigation — EWC, LoRA, learning rate scheduling — reduces the damage but cannot eliminate it. Parameter-efficient methods freeze most weights and limit the blast radius; they do not make specialization free. The math does not allow zero-cost adaptation.
Security & compatibility notes:
- HF Transformers v5: Requires PEFT v0.18.0 or later. Older PEFT versions will break on upgrade. Update PEFT before migrating to Transformers v5.
- HF PEFT v0.18.0: Dropped Python 3.9 support. OFT checkpoints created with pre-v0.16.0 are incompatible with current releases.
The Data Says
Catastrophic forgetting and overfitting are not edge cases to plan around — they are the default failure modes of fine-tuning, held at bay by engineering rather than eliminated by it. Parameter-efficient methods preserve base model knowledge; EWC and SA-SFT protect critical weights through smarter update strategies. But every mitigation trades something — model capacity, training time, implementation complexity — and the fundamental tension between specialization and generalization remains a property of the weight space itself, not a problem waiting for a better optimizer.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors