Building a Data Preprocessing Pipeline with scikit-learn, pandas, and Feature-engine in 2026
TL;DR
- Fit every transformer on training data only. The split comes first — always.
- One branch per data type. Numeric columns and categorical columns travel separate paths through a single ColumnTransformer.
- Wrap the whole thing in a Pipeline object. The spec becomes the code that runs, and the leak has nowhere to hide.
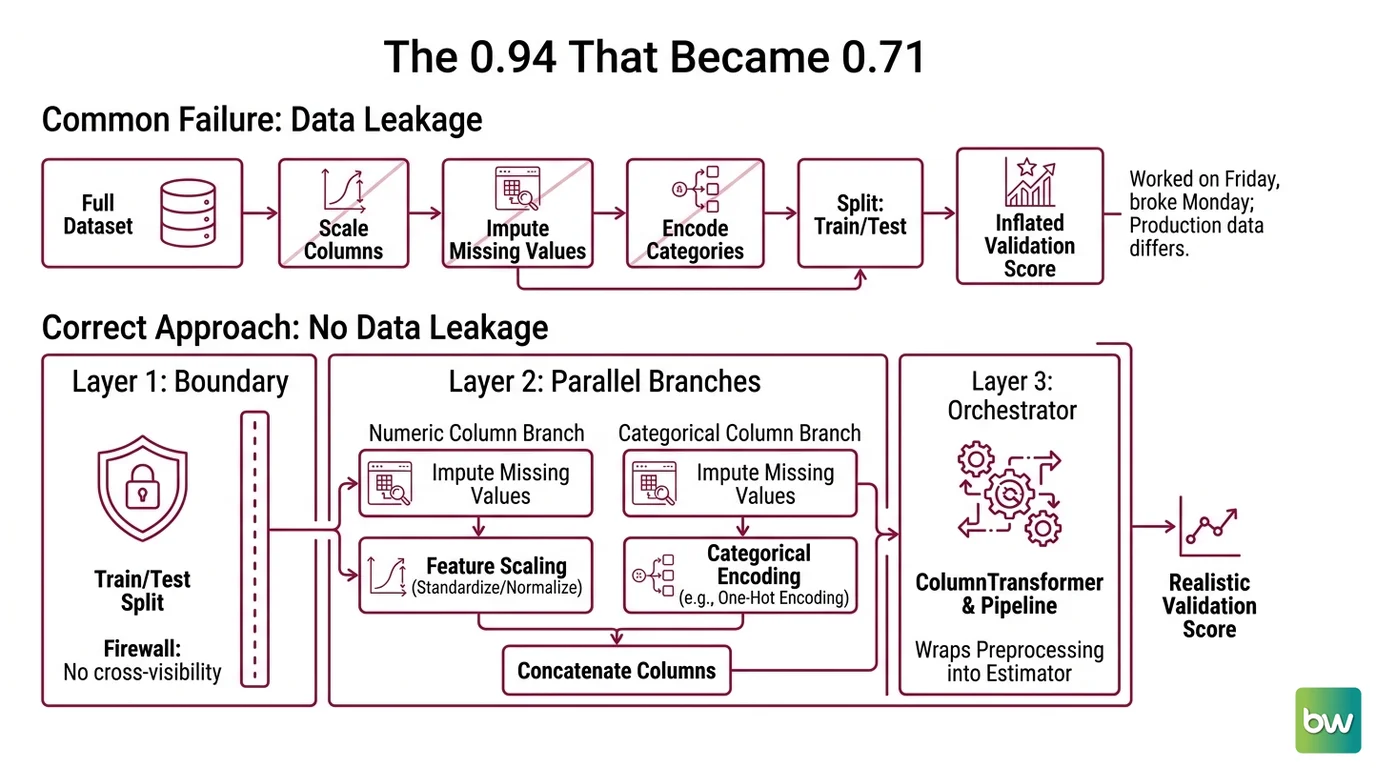
Your model scored 0.94 on validation. In production it dropped to 0.71. Nobody touched the model. The architecture is identical. The only thing that changed is that the training set is no longer secretly informing the test set — because in production, there is no test set to leak from. The preprocessing was the bug. It always is.
Before You Start
You’ll need:
- An AI coding tool — Claude Code, Cursor, or Codex — to generate the implementation
- A working grasp of Data Preprocessing and why a Train Test Split exists
- A clear picture of your dataset: which columns are numbers, which are categories, which leak the target
This guide teaches you: how to decompose preprocessing into independent, order-aware components so your AI tool builds a pipeline that fits on training data only — and proves it.
The 0.94 That Became 0.71
Here is the most common failure I see. Someone loads the full dataset, scales every numeric column, imputes the missing values, encodes the categories — and then splits into train and test. The scaler computed its mean from rows that include the test set. The imputer learned its fill values from data the model is supposed to have never seen. That is Data Leakage, and it inflates every validation score you look at.
It worked on Friday because validation looked great. On Monday it broke, because production data arrives one row at a time with no test set to borrow statistics from, and the model was never actually trained for that world.
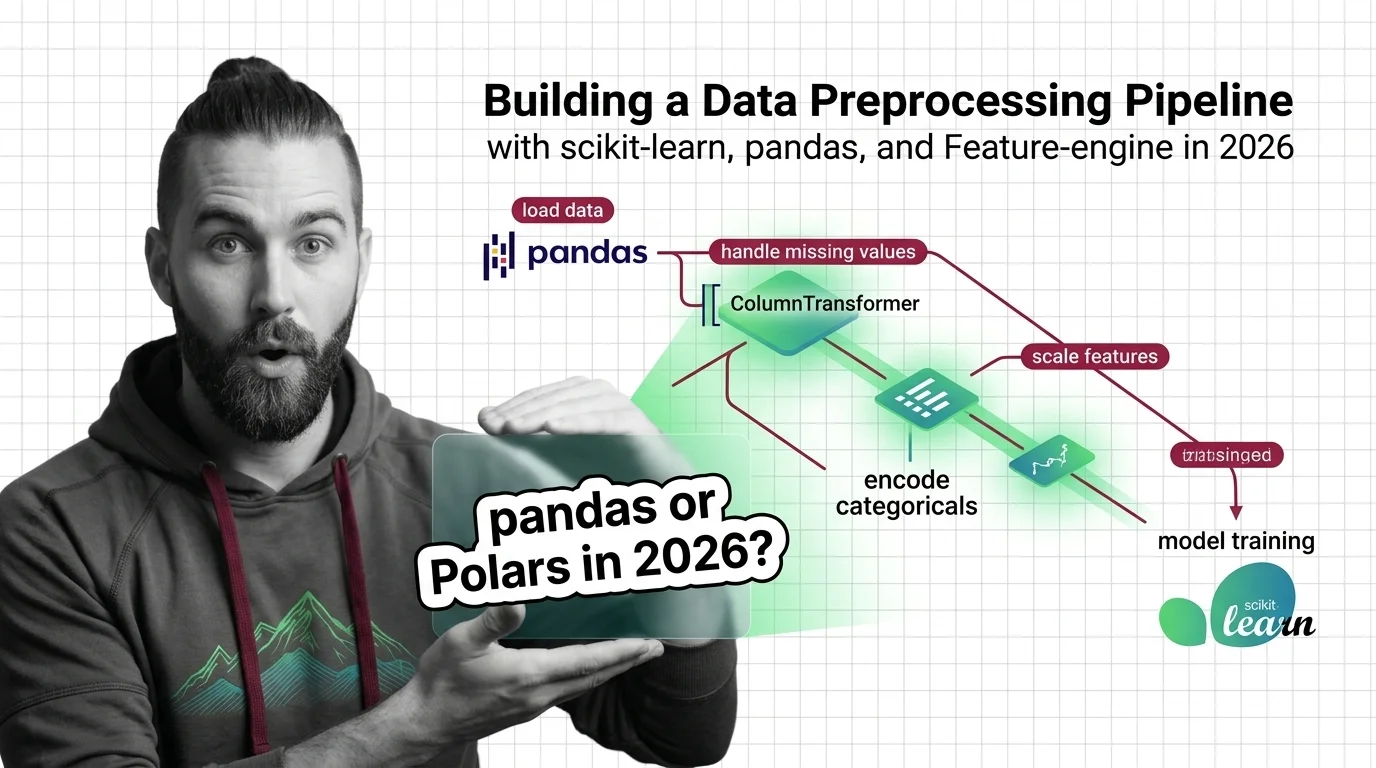
Step 1: Map the Preprocessing as a Graph, Not a Script
Stop thinking of preprocessing as a sequence of lines you run top to bottom. Think of it as a graph with one hard boundary and two parallel branches. If you can draw it, the AI can build it.
Your system has these parts:
- The split boundary —
train_test_splitruns first and acts as a firewall. Nothing fitted may see across it. - The numeric branch — Missing Data Imputation followed by Feature Scaling ( Standardization or Normalization, depending on your model).
- The categorical branch — imputation followed by Categorical Encoding, usually One Hot Encoding for low-cardinality columns.
- The orchestrator — a
ColumnTransformerthat routes each column to the right branch, wrapped in aPipelinethat chains preprocessing into the estimator.
The Architect’s Rule: If you can’t explain the system in three layers — boundary, branches, orchestrator — the AI can’t build it either.
Step 2: Lock Down the Contract
The AI defaults to whatever its training data saw most often. That means fit-on-everything, because that is what most tutorials show. You have to specify the firewall explicitly, or it disappears.
Context checklist:
- Library versions pinned. scikit-learn 1.9.0 supports Python 3.11 through 3.14 and added narwhals for dataframe interoperability (scikit-learn Docs). Pandas 3.0.3 makes PyArrow a required dependency and turns on Copy-on-Write by default (pandas Blog).
- Column types declared — which columns are numeric, which are categorical, by name not by guess.
- Imputation strategy chosen per branch — median for skewed numerics, most-frequent or a constant sentinel for categories.
- Encoding strategy chosen — and a rule for unseen categories at inference time (
handle_unknown="ignore"is not optional in production). - The fit contract stated in one sentence: every transformer is fitted inside cross-validation folds, on training rows only.
- Output type decided — Feature-engine 1.9.4 returns pandas DataFrames with named features through standard
fit()/transform()methods (Feature-engine Docs), which keeps your feature names alive downstream instead of collapsing to an anonymous array.
The Spec Test: If your context doesn’t say “fit only on the training fold,” the AI will fit on the full frame, your cross-validation scores will look better than reality, and you will not find out until production.
Step 3: Wire the Branches in the Right Order
Order is not cosmetic here. It is the difference between a leak and a firewall. Build it in the only sequence that holds the boundary.
Build order:
- Split first —
train_test_splitbefore any transformer is touched, because every downstream fit must be blind to the test rows. - Build each branch as its own mini-pipeline — impute then transform, because scaling a column that still has NaNs produces garbage, and the dependency runs imputation → scaling, never the reverse.
- Compose with ColumnTransformer last — because it integrates the numeric and categorical branches into one object that the estimator and cross-validation can both see.
For each component, your context must specify:
- What it receives — the named subset of columns it owns
- What it returns — transformed columns, with names preserved if you route through Feature-engine
- What it must NOT do — never call
fitoutside the cross-validation loop - How to handle failure — unseen categories ignored, missing values imputed, no silent row drops
Step 4: Prove the Leak Is Gone
You do not trust a pipeline because it ran without error. You trust it because you checked the things that fail silently.
Validation checklist:
- Fit happens inside cross-validation — failure looks like: validation accuracy noticeably higher than a held-out test set you never touched.
- Feature names survive the transform — failure looks like: a downstream step references a column by name and throws a KeyError.
- Unseen categories handled at inference — failure looks like: a crash on the first production row containing a value not present at training time.
- Outlier Detection applied before scaling, not after — failure looks like: a standard scaler whose mean is dragged by extremes you meant to clip.
Security & compatibility notes:
- pandas 3.0 (Copy-on-Write): PyArrow is now a required dependency and Copy-on-Write is the default. Chained-assignment mutation patterns from 2.x no longer behave as before (pandas Blog). Action: refactor in-place edits to explicit
.locassignments or fresh copies before you pin 3.x in a preprocessing job.- scikit-learn 1.9.0 (Python floor): Drops support for Python below 3.11 and adds the narwhals dependency (scikit-learn Docs). Action: confirm your runtime is Python 3.11+ before upgrading.
Common Pitfalls
| What You Did | Why AI Failed | The Fix |
|---|---|---|
| Scaled and imputed before splitting | The AI followed the most common tutorial pattern, which leaks | Specify “split first, fit transformers on training folds only” |
| Passed columns as one undifferentiated block | The AI guessed numeric vs. categorical and mislabeled some | Declare column types by name in your context |
| Skipped the unseen-category rule | The AI generated happy-path encoding only | Add handle_unknown="ignore" to the encoding spec |
| Let the transform return a raw array | The AI optimized for fewer lines, dropping feature names | Route through Feature-engine to keep named DataFrame output |
Pro Tip
The Pipeline object is your specification made executable. Anything that touches the data and learns from it — a fill value, a mean, a category vocabulary — must live inside that object, not in a loose cell above it. The moment a transformation happens outside the pipeline, your cross-validation is lying to you, because that step already saw the data it is about to be tested on. Treat the Pipeline boundary as the same kind of contract you would put around any module: state goes in through one door, or it does not go in at all.
Frequently Asked Questions
Q: How to build a preprocessing pipeline with scikit-learn ColumnTransformer and Pipeline?
A: Define two branch pipelines — numeric and categorical — each ordering imputation before transformation. Route columns by name through a ColumnTransformer, then wrap that in a Pipeline ending in your estimator. The detail tutorials skip: pass remainder="drop" so stray columns never leak in unspecified.
Q: How to handle missing values and encode categorical features for model training?
A: Impute numerics with the median, categories with most-frequent or a constant sentinel, then one-hot encode. The trap most teams hit: set handle_unknown="ignore" on the encoder, or the first unseen category in production crashes the entire inference call.
Q: When should you use pandas vs Polars for data cleaning in 2026?
A: Use pandas when your data feeds straight into scikit-learn — it is the native integration path. Reach for Polars on large upstream cleaning jobs, where benchmarks report it running several times faster. The catch: Polars does not plug into the sklearn Pipeline, so convert to pandas before fitting.
Your Spec Artifact
By the end of this guide, you should have:
- A component map — the firewall, the two branches, and the orchestrator, drawn before any code exists
- A constraint list — pinned versions, column types by name, per-branch imputation and encoding rules, the unseen-category rule, and the fit-on-training-only contract
- A validation criteria set — fit happens inside cross-validation, feature names survive, unseen categories are handled, outliers are clipped before scaling
Your Implementation Prompt
Paste this into your AI coding tool after replacing every bracket with your own values. It mirrors the four steps above, so what you specified is exactly what the tool builds.
Build a scikit-learn preprocessing pipeline. Do not fit any transformer
outside cross-validation.
CONTEXT (pin these):
- scikit-learn [1.9.0], pandas [3.0.x], Feature-engine [1.9.4], Python [3.11+]
- Numeric columns: [list by name]
- Categorical columns: [list by name]
- Target column: [name] — must never enter a transformer
STEP 1 — STRUCTURE:
- Run train_test_split FIRST as the firewall.
- Numeric branch: imputation([median]) -> scaling([standardization/normalization]).
- Categorical branch: imputation([most_frequent/constant]) -> encoding([one-hot],
handle_unknown="ignore").
- Combine both branches in a ColumnTransformer with remainder="drop".
STEP 2 — CONTRACT:
- Every transformer is fitted on training folds only.
- Preserve feature names (use Feature-engine transformers where possible).
- Unseen categories at inference must not crash.
STEP 3 — ORDER:
- Impute before transform in each branch.
- Wrap the ColumnTransformer + [estimator] in a single Pipeline.
STEP 4 — VALIDATE:
- Report cross-validated scores, not a single train/test number.
- Confirm the pipeline runs on a held-out row containing an unseen category.
Ship It
You now read preprocessing as a graph with a firewall, not a script you run top to bottom. You can point at the exact line where a leak enters, and you can specify it out of existence before the AI writes a single transformer. That mental model travels to every dataset you touch next.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors