Transformer Internals for Developers: What Maps, What Breaks
Table of Contents
Your team’s LLM API bill tripled in March. Same traffic volume, same endpoints, same payload sizes in bytes. The only change: customer support started sending longer conversation histories as context. Your capacity model predicted cost would track request count. It tracked prompt length instead — and not linearly. That same week, QA filed a defect: the summarization endpoint returned different outputs for identical documents on consecutive calls. No deploy had occurred. No configuration had changed. Two anomalies, both traceable to the same architecture sitting behind the API.
Behaviors Your Runbook Does Not Cover
Your service depends on a hosted LLM endpoint. Or your internal search was migrated to semantic retrieval. Or someone added “intelligent summarization” to a product requirement and you are the one writing the service contract.
However the Transformer Architecture entered your dependency graph, you noticed behaviors your operational playbook does not explain. Latency grows faster than expected with prompt length. Identical inputs produce different outputs. Costs spike on multilingual input at the same character count. Quality degrades mid-conversation and your monitoring flags nothing.
These are not vendor bugs. Each traces to a specific architectural property: quadratic attention scaling, probabilistic token generation, tokenizer efficiency gaps, context-window pressure. You do not need to build these components. You need to name them — because the name changes both the debugging strategy and the capacity plan. The engineer who cannot distinguish a token-limit failure from attention dilution will misdiagnose the root cause. That misdiagnosis costs real time and real money.
You do not need to become a machine learning researcher. You need enough structural understanding of what sits inside the endpoint to ask the right questions when it misbehaves — the same way understanding database internals helps you diagnose a slow query without rewriting the query planner.
What Your Pipeline Instincts Get Right
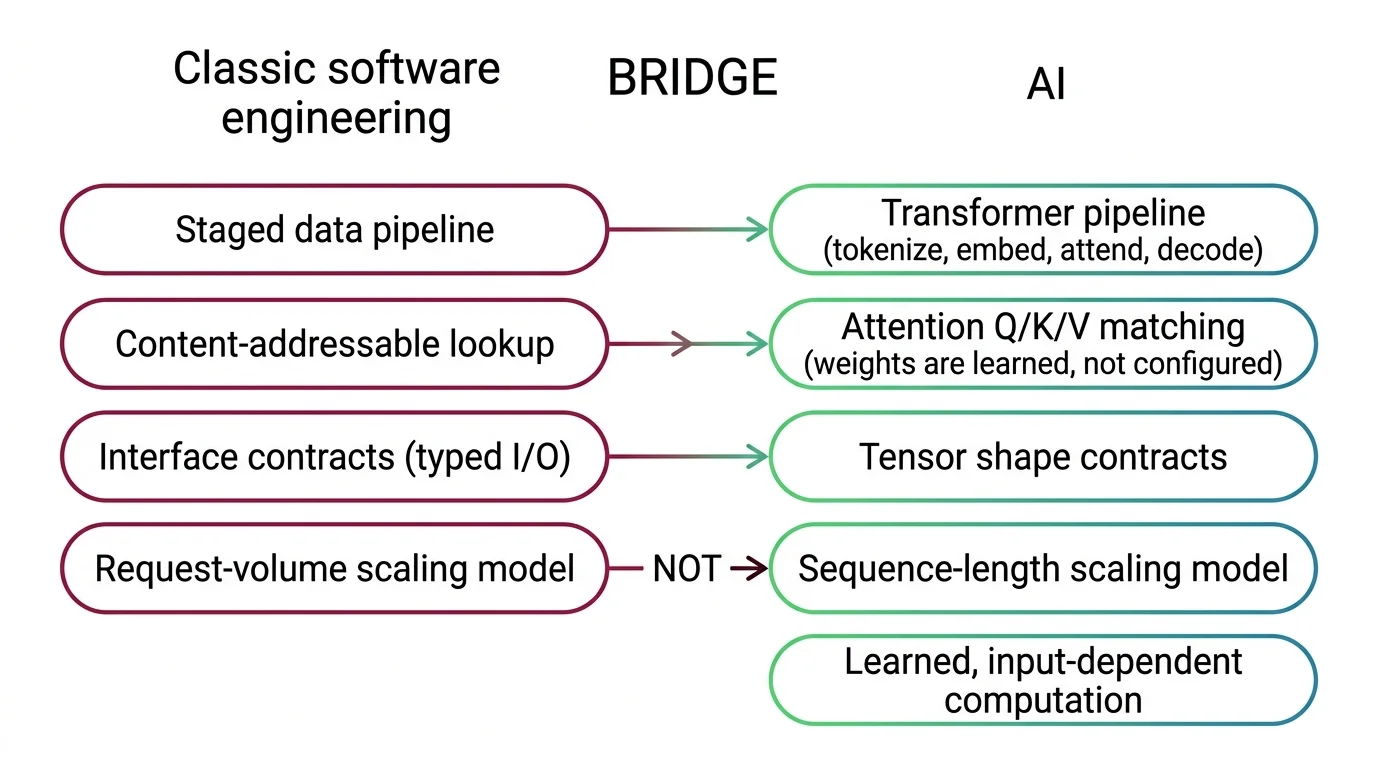
If you think in staged pipelines, interface contracts, and bottleneck analysis, those instincts transfer. Not completely, and not in every direction. But the starting point is closer than the terminology gap suggests.
A transformer processes input through a fixed sequence of stages: the Tokenizer Architecture splits raw text into numerical tokens, an embedding layer maps those tokens into high-dimensional vectors, Attention Mechanism layers compute relevance scores between all token pairs, and a decoder generates output one token at a time. If you have diagrammed a data pipeline with typed contracts at each stage boundary, the structural pattern is one you already know how to read.
The dependency chain is strict and directional. Token IDs must exist before embeddings can be computed. Embeddings must exist before attention can operate. Build components out of sequence and you get the same class of integration failure you see when an upstream service assumes a format the downstream service does not produce. If you need the full decomposition framework for constructing these components, MAX’s specification guide breaks the system into five contracts with explicit interfaces.
Interface contracts transfer cleanly. Every transformer component has an explicit input shape and output shape. The instinct to validate at component boundaries applies directly.
Where the analogy breaks: in a service mesh, routing rules are configured, inspectable, and stable between deploys. In the attention layer, relevance weights are learned from data and recomputed from scratch on every input. There is no routing table to inspect. The routes emerge from trained geometry, not from configuration — a property with no equivalent in configured infrastructure.
Your instinct for stateless request processing also transfers — at the API boundary. Each call is independent, no memory carries between requests, same as REST. But within a single request, the system accumulates internal state as it generates each token. Stateless between requests, stateful within them. If you are designing retry logic or setting timeouts, that boundary matters more than the API spec reveals.
Batching instincts from database or queue processing apply too, though the constraints differ. You batch requests to share GPU compute across multiple prompts, much as you batch database writes to amortize connection overhead. The difference: batch size in transformer inference is bounded by GPU memory, not by network throughput, and each item in the batch can have a different sequence length. A single long prompt in a batch constrains the batch more than a hundred short ones.
Mental Model Map: Transformer Internals From: Configured pipeline with deterministic routing and linear cost scaling Shift: Pipeline stages transfer, but routing is learned, cost is quadratic, and output is probabilistic To: Staged inference pipeline with input-dependent computation and statistical validation Key insight: The structure maps — the behavioral guarantees do not
Why Your Cost Model Breaks
In conventional API billing, double the traffic, roughly double the bill. Capacity planning is linear. You have built that assumption into cost models, scaling policies, and budget forecasts.
Transformer inference violates it in two specific ways.
Why does doubling the input prompt more than double inference cost and memory?
The dominant cost comes from the attention computation, which compares every token in the input against every other token. The comparison is pairwise: N tokens produce N-squared relationships. Double the prompt length and the attention computation quadruples. At 1,024 tokens the attention matrix contains roughly one million entries. At 32,768 tokens — a length modern models handle routinely — it exceeds one billion.
This is not an inefficiency waiting for a patch. It is a structural property of how the architecture computes relevance. The practical consequence: average prompt length matters more than request count, and variance in prompt length matters more than average. A workload with uniform short prompts and a workload with occasional long documents produce vastly different cost profiles at the same request volume.
Your load test told you the system handles a given request throughput. It did — at short prompt lengths. At long prompt lengths, that number drops, and it drops faster than linearly. If you size infrastructure based on request throughput without accounting for the distribution of prompt lengths across your traffic, you will over-provision for short prompts and under-provision for long ones. MONA’s quadratic scaling analysis covers what FlashAttention fixes in practice — memory access patterns — and what it leaves unchanged: the algorithmic lower bound on attention complexity.
Why does the KV cache grow monotonically per request with no eviction or TTL?
Within each request, the model maintains a key-value cache that stores computed states for every generated token. In application-level caching, you design eviction policies — TTL, LRU, size limits. The KV cache has none. It grows with every new token, consuming GPU memory monotonically, and releases only when the request completes.
Your longest responses are your most expensive — not by a linear margin, but by a compounding one. There is no mechanism inside the inference engine to prune intermediate state mid-generation. Batch scheduling, sequence length limits, and response truncation are your controls. All three operate at the orchestration layer, not inside the model. If you have tuned connection pools or request queues, the instinct applies — the knob moved from the network layer to the token-generation boundary. The mechanism behind this per-token state accumulation traces to how decoder-only models generate each token conditioned on all previous ones.
Same Input, Different Output, No Deploy
In your service architecture, debugging means tracing a request from entry to response and finding the decision point that produced the wrong output. That logic is authored by humans, versioned, reviewed, deployed. When the output is wrong, the logic is inspectable.
What changes when the system has no deterministic execution path?
In a transformer, the decision logic — which tokens attend to which, and how strongly — is encoded in billions of learned parameters. No human authored those weights. The attention pattern recomputes for every input. When the model produces unexpected output, there is no line of code to inspect, no conditional branch to trace. The “bug” lives in the statistical geometry of matrix multiplications across more parameters than you could examine in a lifetime.
Every major LLM you interact with uses Decoder Only Architecture — generating output autoregressively, one token at a time, left to right, with no ability to revise earlier tokens. The streaming response in a chat interface is not a UI animation. It is the generation mechanism itself. If token thirty was wrong, tokens thirty-one through one hundred are all conditioned on that error. There is no rollback. No retry of the failed step. No transaction boundary.
The instinct to isolate and reproduce still applies — you can narrow the input that triggers the failure. The expectation of readable, inspectable decision logic does not. What replaces it is distributional validation: testing output patterns across a range of inputs rather than tracing one execution path. You measure consistency across runs, flag output drift against a baseline, and set statistical thresholds for acceptable variation. If your current test suite checks for exact string matches on model output, it will break on every deployment regardless of whether anything is actually wrong. The verification methodology becomes statistical, not structural.
For the full mechanism — how attention computes relevance through geometric projection — the self-attention explainer covers the math this bridge deliberately leaves out.
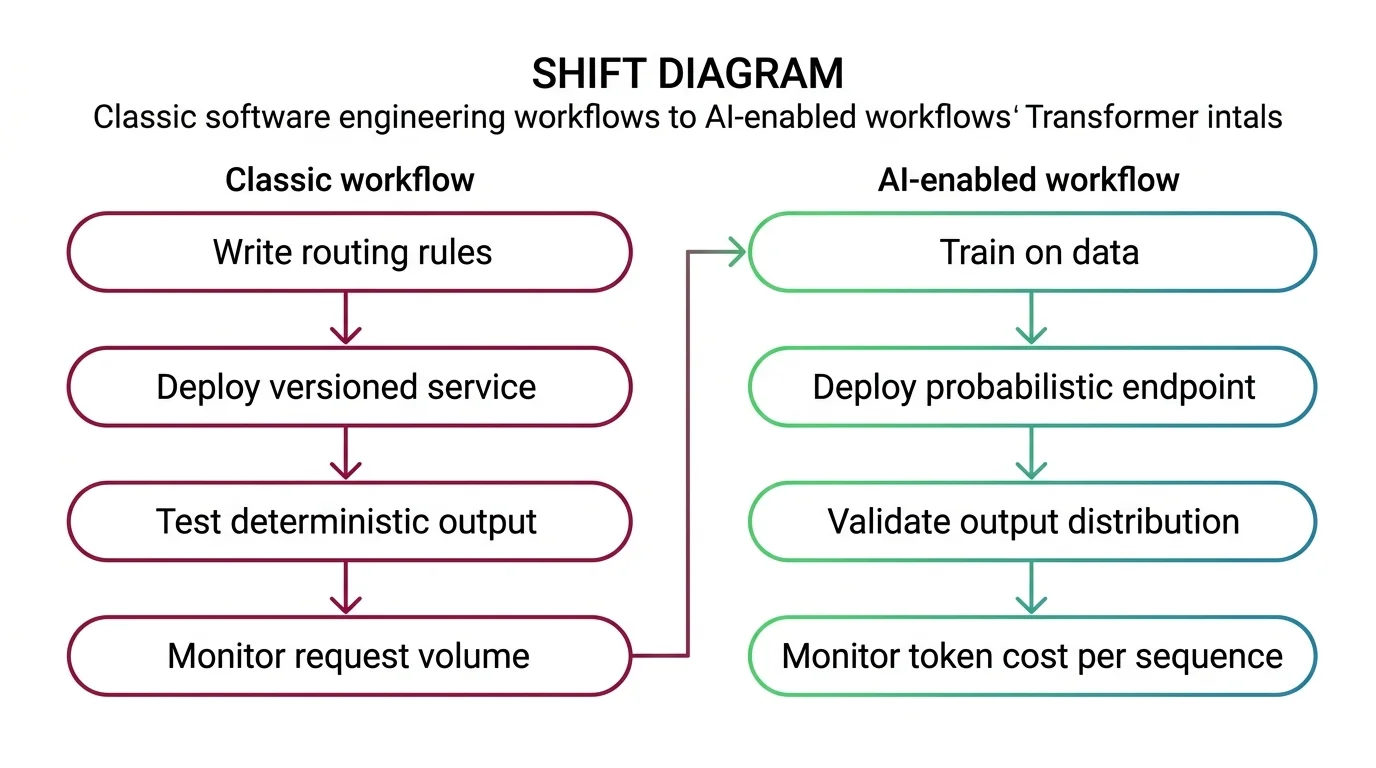
Shift Diagram: Transformer Internals Classic: Write routing rules → Deploy versioned service → Test deterministic output → Monitor request volume AI: Train on data → Deploy probabilistic endpoint → Validate output distribution → Monitor token cost per sequence
Context Is Not Memory
The most dangerous analogy backend developers bring to transformer integration is this one.
Why does treating the context window like addressable memory lead to wrong assumptions about retrieval reliability?
The mapping forms naturally: the context window holds conversation history, the model appears to “remember” earlier instructions, and the parallel to stateful storage feels obvious.
It is precisely wrong at the operational level.
Application memory stores data and retrieves it with consistent fidelity regardless of how much else is stored. A transformer’s context window is an attention budget: every token competes for the model’s limited capacity to compute relevance. More context often dilutes attention — the model spreads its relevance scoring across a larger token space, and critical instructions earlier in the window receive proportionally less weight.
| Property | Application Memory | Transformer Context Window |
|---|---|---|
| Retrieval fidelity | Constant regardless of volume | Degrades as context grows |
| Adding more data | No effect on existing retrieval | Reduces attention weight on all existing tokens |
| Cost model | Fixed per read operation | Quadratic with total token count |
| Eviction policy | Configurable (TTL, LRU) | None — hard cutoff at window limit |
This explains a counterintuitive production failure: a long, detailed prompt sometimes produces worse results than a short, focused one. The instructions are present — no tokens were dropped. But the attention weights that would have concentrated on those instructions are now spread across thousands of additional tokens. Prompt design follows the opposite instinct from what you would expect: less context, not more, with critical instructions placed where they face the least competition.
An Encoder Decoder Architecture handles this pressure differently — the encoder compresses input into a dedicated representation that the decoder queries through cross-attention, separating comprehension from generation. Encoder-decoder models remain active for structured tasks like translation and summarization. But decoder-only models dominate commercial LLM APIs, so the context-window pressure you observe in production is the decoder-only variety. If you need to evaluate when the encoder-decoder split still matters, MAX’s architecture selection guide provides a decision framework.
The transformer is a staged pipeline with learned routing, quadratic cost properties, and probabilistic output. Some engineering instincts transfer — pipeline decomposition, interface validation, stateless request handling at the API boundary. Others break in specific, nameable ways: cost scales with the square of input length, identical inputs produce different outputs, and the context window punishes the instinct to send more data. The names are the starting point. The cluster articles cover the mechanism behind each one.
FAQ
Q: Do I need to understand transformer internals to use LLM APIs? A: Not for basic calls. But understanding quadratic cost scaling, context-window behavior, and non-deterministic output helps you diagnose failures, estimate costs, and write service contracts that account for behaviors API docs rarely cover.
Q: What is the biggest difference between transformer inference and traditional service architecture? A: Non-determinism by design. Traditional services produce consistent output for identical input. Transformers produce probabilistic output that varies between calls, and the underlying model can change without triggering your deploy pipeline.
Q: Should backend developers learn the attention mechanism math? A: Only if you evaluate models at the architecture level. For API integration, understanding pipeline stages, cost scaling, and failure modes matters more. The cluster’s explainers cover the math when you need it.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors