AI Safety Testing for Developers: What Maps and What Breaks
Table of Contents
Your toxicity filter flagged a support agent’s message as harmful. The agent was speaking African American English. Same week, a five-word prompt injection extracted your system instructions into a public conversation. You filed one as a false positive and the other as a security incident. Both trace to the same root cause: your safety classifier learned the surface of language, not what it means.
That dual failure is not a misconfiguration you can fix with a threshold change. It is the default behavior of every probabilistic safety layer running in production today. Your existing testing instincts explain part of the problem. They miss the rest. And the gap between what those instincts predict and what the system actually does is where the expensive surprises hide.
The Filter That Fails in Both Directions
The first safety issue most developers encounter is not an adversarial attack. It is a support ticket. A user whose legitimate message was blocked, with no clear reason and no useful error.
If you come from backend work, the instinct is to treat a Toxicity And Safety Evaluation classifier like input validation. A gate that checks a rule. Pass or block. If it blocks wrong, adjust the rule.
That analogy holds for architecture: the classifier sits between user input and your model, enforcing a boundary. It breaks at the mechanism. Input validation checks deterministic properties — string format, value range, schema shape. A toxicity classifier runs text through a second model that outputs a probability score. The block decision is a threshold applied to that score. Same shape. Different physics.
The second model learned what “toxic” looks like from training data that skews toward mainstream English. African American English, Spanish-influenced code-switching, dialect markers from the Global South — these trigger higher toxicity scores on equivalent content. That is not a misconfiguration. It is what the model learned. MONA traces the root cause in her explainer on dialect bias and adversarial bypasses: classifiers learned surface features of harm rather than its semantics.
The mirror failure is just as severe. Adversarial prompts engineered to avoid those surface patterns — encoding tricks, role-play escalation, multi-turn social engineering — slide through the same classifier that blocked a legitimate user. The filter fails in both directions by design.
You cannot fix this by tuning the threshold. Lower it and you miss more attacks. Raise it and you block more legitimate users. The fix is architectural: layer classifiers with different failure geometries, add output-level checking, and monitor both false positive and false negative rates in production. MAX’s safety pipeline guide walks through the decomposition.
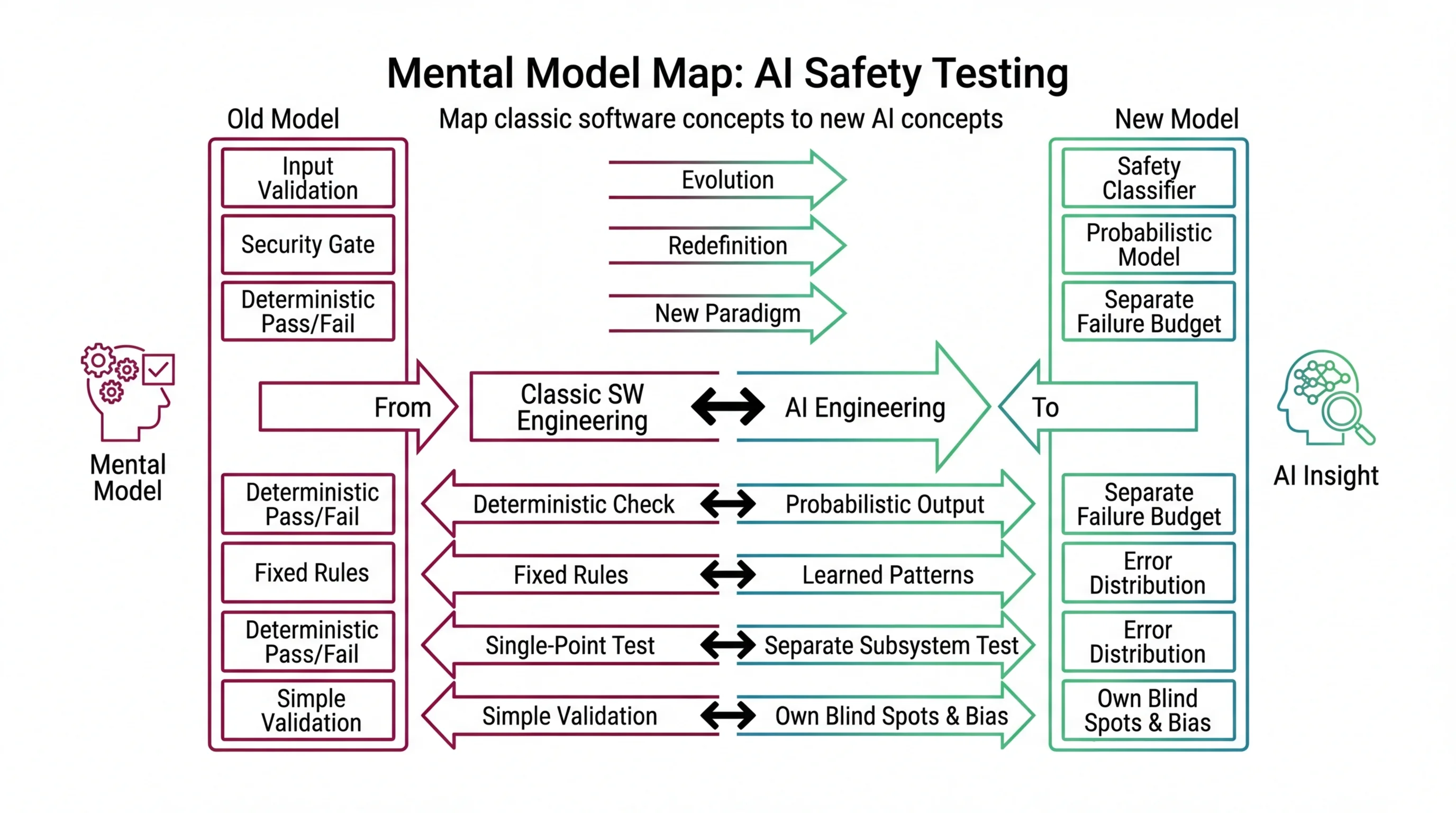
Mental Model Map: AI Safety Testing From: Safety filter = deterministic pass/fail gate (same as input validation) Shift: Safety classifier = a second probabilistic model with its own blind spots and bias To: Safety layer = an engineering subsystem that needs its own testing, monitoring, and failure budget Key insight: Your guard model is not a gate. It is another model with its own error distribution that you must test separately.
What Transfers From Your Security Playbook
Not everything you know is wrong. Three testing instincts transfer to AI safety — and knowing where they stop helps you skip the approaches that look productive but miss the actual failure surface.
Your fuzz testing instinct transfers to Red Teaming For AI: generate unusual inputs, observe unexpected behavior, file findings. Your regression instinct transfers too — when a red team discovers a vulnerability, capture it as a permanent test case. And your coverage instinct finds a home in frameworks like the OWASP LLM Top 10 and MITRE ATLAS, which give you a structured taxonomy of known attack categories, the same way OWASP web vulnerabilities give you a checklist for traditional application security.
The caveats land in the rightmost column of this table:
| Dimension | Classic Security Testing | AI Safety Testing |
|---|---|---|
| Input space | Finite, typed, enumerable | Infinite natural language |
| Failure behavior | Deterministic and reproducible | Probabilistic — same input, different output |
| Regression value | High — fix persists indefinitely | Moderate — model updates reintroduce failures |
| Coverage meaning | Percentage of code paths exercised | Percentage of known attack categories probed |
| Pass confidence | “These code paths are verified” | “These attack patterns did not succeed today” |
Every transfer point works for known attack categories. None of them help with attacks nobody has categorized yet. In AI safety, the unknown category is where the worst damage originates. MAX’s Promptfoo, PyRIT, and Garak guide maps those frameworks to specific tools and shows how to structure the pipeline.
Where Testing Intuitions Quietly Break
Your security playbook gave you three useful instincts. Here is where those same instincts start producing wrong predictions — and where the cost of trusting them shows up as production incidents.
Why does a passing safety test suite not certify LLM safety the way a passing unit test suite certifies deterministic correctness?
In deterministic software, a passing test suite is a proof of behavior for the tested paths. If the code has not changed, the tests still pass. The system is verified for those inputs.
In a probabilistic system, a passing safety scan proves exactly one thing: the attack patterns you tested did not succeed on that run. The same model can produce different outputs on the same input because of sampling. New attack techniques emerge monthly — and they do not look like old ones. The input space is natural language. It is effectively infinite.
Research from this cluster quantifies the gap. Automated red teaming outperforms human testing on known attack categories — wider coverage, faster execution. But human testers discover attack paths that exist in no taxonomy and match no existing template. Neither method alone certifies safety, because the failure taxonomy is always growing and never complete. MONA covers the structural proof in her analysis of coverage gaps in adversarial testing.
Why do AI safety failures look like intermittent bugs when they are statistical coverage gaps?
If you have ever debugged a race condition, you know the pattern: the failure appears once, vanishes on retry, and leaves no useful stack trace. AI safety failures produce the same developer experience. The model passed checks on Monday. On Tuesday, a user hits a jailbreak that works once in a few dozen attempts. You cannot reproduce it reliably.
The instinct is to treat it like an intermittent bug — a timing issue, a configuration gap, something that stabilizes with the right fix. That instinct is wrong. The failure is not intermittent. It is a statistical event drawn from a distribution you have not fully characterized. The fix is not a patch. It is a monitoring and detection layer that catches the failure at the rate it actually occurs in production. MONA’s explainer on what makes the AI attack surface unbounded traces why this is structural, not incidental.
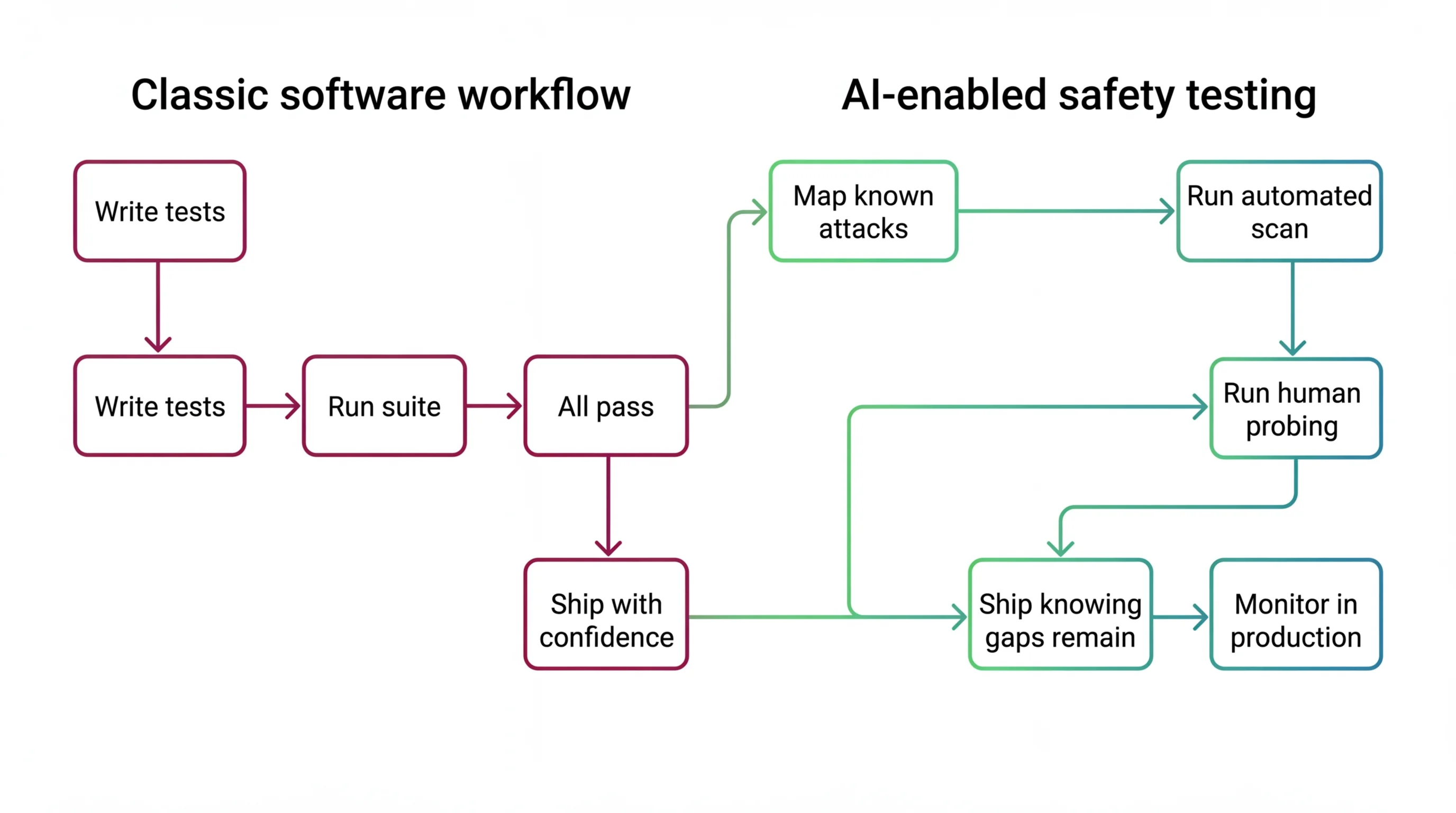
Shift Diagram: AI Safety Testing Classic: Write tests → Run suite → All pass → Ship with confidence AI: Map known attacks → Run automated scan → Run human probing → Ship knowing gaps remain → Monitor in production
Hallucination Is Architecture, Not a Bug Ticket
This is the misconception that costs the most engineering time.
The instinct: Hallucination is a defect. The model generates confident falsehoods because the prompt is vague, the data is missing, or the version is outdated. Better prompts will fix it. More data will fix it. The next release will fix it.
The reality: hallucination is a mathematical consequence of how language models generate text. Next-token prediction rewards statistical likelihood, not truth. Researchers have formally proven that calibrated language models must hallucinate — it is not a deficiency in the current version but a structural property of the architecture. MONA traces the proof and its engineering implications in her explainer on why zero-hallucination LLMs remain impossible.
The practical consequence is a two-tier split. Constrained summarization tasks — short documents, bounded scope — approach reliability. Complex reasoning tasks — legal analysis, medical recommendations, multi-source synthesis — remain dangerously unreliable, with frontier models still hallucinating above ten percent on realistic enterprise-length benchmarks.
If your team believes hallucination disappears with better prompts, nobody builds the verification layer. Nobody adds grounding checks. Nobody sets domain-specific thresholds for what counts as an acceptable error rate. Then the model fabricates a legal citation, or a medical dosage, or a customer-facing statistic — and nobody catches it because the system was designed for a world where the model is always right. RAG reduces hallucination rates significantly, but changes where hallucinations originate, not whether they happen. MAX’s detection guide covers how to build the measurement layer that catches what the model misses.
What You Own When the Provider Won’t
Your model sits behind an API. The provider runs internal red teaming. The model card says “aligned.” Safety features ship enabled by default.
You might assume safety is the provider’s problem.
It is not. Provider guardrails cover generic harmful content at the model level. Your application context — your specific users, your regulatory domain, your safety taxonomy — is not their concern. When your toxicity classifier blocks legitimate users because your user base speaks dialects the classifier was not trained on, that is not the provider’s bug. When the model behind the API updates silently and output quality shifts, your SLA is what breaks. When a red teaming technique the provider has not tested reaches your users, your incident response is what fires.
You own: the application-specific safety taxonomy that defines what “harmful” means in your domain. The threshold calibration that balances false positives against false negatives for your user population. The hallucination detection pipeline that catches fabrication before it reaches customers. The monitoring that detects when behavior drifts. And the incident plan when safety fails.
Your next move depends on where the gap is widest:
- If you need the adversarial testing pipeline: MAX’s Promptfoo, PyRIT, and Garak guide covers the three-layer framework.
- If you need the safety evaluation architecture: MAX’s Llama Guard and promptfoo guide decomposes it into classifier, scorer, and red-team layers.
- If hallucination is the primary risk: MAX’s DeepEval and RAGAS guide covers detection, grounding, and domain-tuned thresholds.
- If you need the mechanism behind why classifiers fail the way they do: MONA’s guard model explainer maps the scoring layer and its structural limits.
AI safety is not a feature your provider ships. It is an engineering discipline you own — with its own testing tools, its own failure taxonomy, and coverage gaps no amount of testing fully closes. Build the pipeline. Monitor what you ship.
FAQ
Q: Do I need AI red teaming if I use a hosted model API with built-in safety filters? A: Yes. Provider filters cover generic harmful content at the model level. Your application-specific attack surfaces — domain context, user demographics, regulatory requirements — are yours to test. The provider does not know your users.
Q: What is the difference between AI red teaming and traditional penetration testing? A: Traditional pen testing targets deterministic systems with finite attack surfaces. AI red teaming targets probabilistic systems where the input space is infinite natural language. A passing scan proves you tested specific patterns, not that the system is safe.
Q: Can better prompts or RAG eliminate AI hallucination completely? A: No. RAG reduces hallucination rates by grounding output in retrieved documents, but does not eliminate fabrication. Hallucination is a structural property of next-token prediction. Build verification into every output path instead of waiting for zero.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors