RAG Quality for Developers: What Testing Instincts Still Apply
Table of Contents
Your RAG dashboard showed a faithfulness score of 0.94. The retrieval logs confirmed the right policy document came back at rank one. The customer who asked about your refund window still got the wrong answer — confidently, with a clean inline citation pointing at a paragraph that said the opposite of what the model wrote.
That is the failure mode your existing test suite was never built to catch. Your retriever did its job. Your monitoring stayed green. The Faithfulness score even cleared the threshold the platform team set in CI. And the user got a confident lie with a footnote.
This is the bridge cluster nobody told you you were on call for. It is not the prototype demo with the Streamlit UI. It is the moment RAG Evaluation and RAG Guardrails And Grounding stop being a research topic and start being a CI gate, an on-call alert, and an incident postmortem you have to actually write.
Mental Model Map: RAG quality and guardrails for developers From: “RAG quality is a single score I gate on, like a test pass rate” Shift: “RAG quality is two failure surfaces graded by a non-deterministic judge, plus a layered guardrail stack” To: “Score the retriever and the generator separately, treat the judge as instrumentation, and gate on direction not absolute number” Key insight: A faithfulness score is a measurement, not an authorization — and the grader is itself an LLM with documented biases.
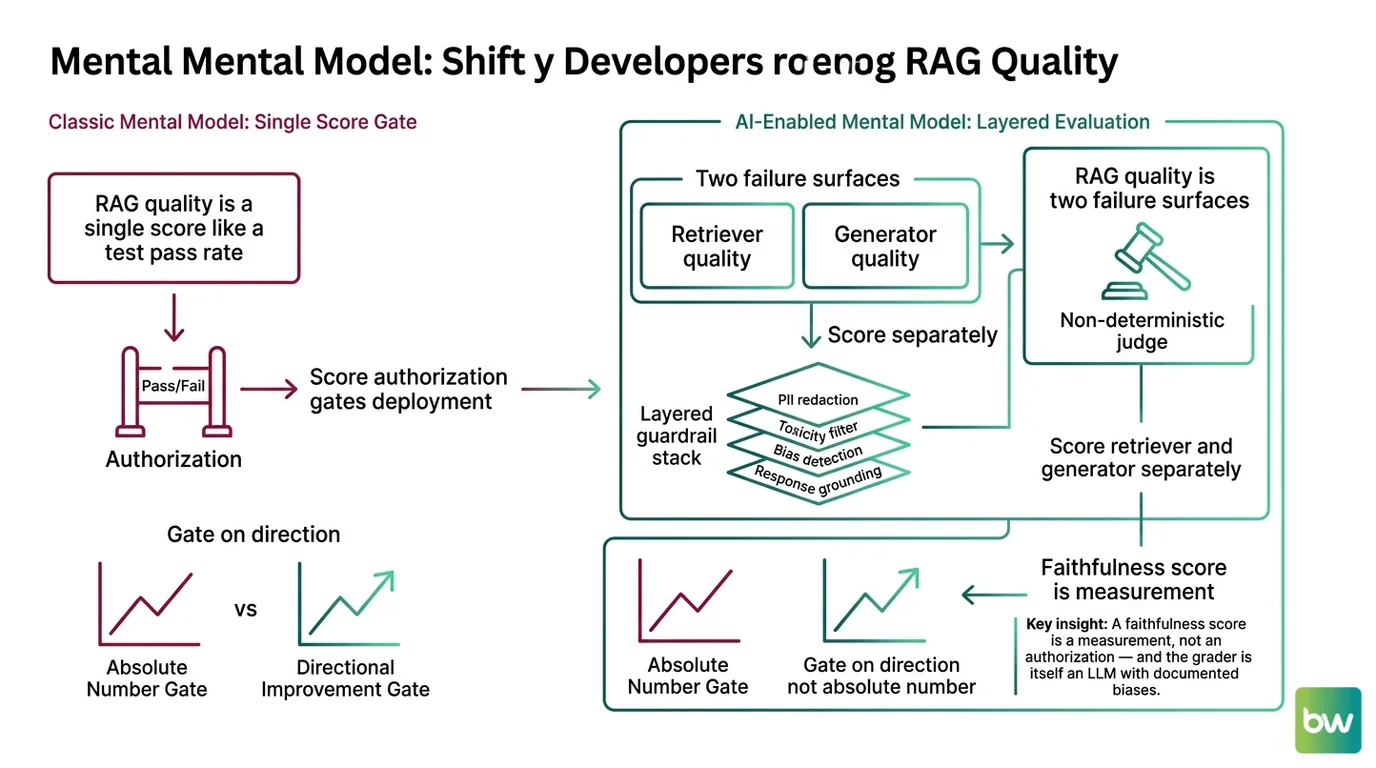
The 0.95 Score That Was Lying To You
You expect a score of 0.95 to mean roughly 95% correct. That instinct comes from a decade of unit tests, code coverage reports, and SLA dashboards where the number is the truth. In RAG quality, the number is a witness statement from a non-deterministic LLM with documented biases. Treating it as ground truth is the assumption that costs you the postmortem.
Frameworks like RAGAS and TruLens compute faithfulness by decomposing the answer into atomic claims and asking a judge LLM whether each claim is supported by the retrieved context (Ragas Docs). The mechanic is simple. The properties are not. A 2024 systematic review documented twelve distinct biases in LLM As Judge setups — verbosity bias, position bias, authority bias, sentiment bias, self-preference, and others — per Justice or Prejudice (Ye et al., CALM). Tweag’s analysis of the same RAG pipeline scored by different judges produced materially different faithfulness distributions — same answers, different judge, different number, per Tweag’s “Evaluating the evaluators.”
Why can’t you treat a faithfulness score the way you treat a unit-test pass?
Because the grader is non-deterministic and the grader has biases. A unit test that returns true on Monday returns true on Tuesday. A faithfulness score of 0.84 from a GPT-4-class judge can become 0.79 when the same library calls a different frontier model — a routine upgrade nobody flagged, per Tweag’s analysis. The score moved. The pipeline did not.
The CI implication is sharp. You cannot gate on absolute thresholds the way you gate on test pass rate. You gate on direction and delta — drops greater than X relative to last week’s baseline, scored by a pinned judge model with a pinned prompt template. The judge identity is now part of the metric. If you do not pin it, you are measuring two things at once and pretending they are one.
This is also the answer to the question regulated-industry teams keep asking the wrong way. A 0.95 faithfulness score in a healthcare or financial RAG flow does not mean 95% correct, and it never did. It means a judge model — itself trained on data you cannot inspect, with biases you partially know — found that most decomposed claims could be traced to retrieved passages. If the retrieved passage is itself wrong, the score is high and the answer is still false. The Atlan analysis of major frameworks puts it directly: a RAG system can score 0.95 faithfulness and still produce wrong answers when the retrieved context is stale or incorrect (Atlan).
Two Subsystems, Two Scoreboards
The cleanest engineering instinct that transfers cleanly to RAG is the one you already use to localize outages. When an upstream data layer and a downstream API both look healthy but the user sees a wrong response, you do not score the system end-to-end. You decompose. You measure each contract separately and you find the side that broke.
A RAG pipeline has two failure surfaces, and any honest evaluation needs at least one metric per surface. Ragas, TruLens, and DeepEval all encode this split — retrieval-side metrics like Context Precision and Context Recall, generation-side metrics like Faithfulness and Answer Relevancy. Treating end-to-end answer quality as a single scalar is the fastest way to ship a system whose failures you cannot diagnose, per the Ragas team.
Why do faithfulness, grounding, and context-precision metrics matter even if your team only consumes a RAG endpoint?
Because the failure shows up in your incident, not theirs. When the retriever team raises Context Recall but the generator team’s prompt does not specify how to handle conflicting chunks, the user-facing answer regresses. The metric that flags it lives across the boundary you do not own. If your service consumes a RAG endpoint and you do not know which subsystem the SLA covers, you are accepting an opaque dependency you cannot debug.
The TruLens project formalizes this as the RAG Triad — Context Relevance, Groundedness, and Answer Relevance — three independent measurements of three independent failure modes (TruLens Docs). The Ragas vocabulary maps almost cleanly: Context Relevance ≈ Context Precision, Groundedness ≈ Faithfulness, Answer Relevance ≈ Answer Relevancy. The names differ. The decomposition does not. For a working harness with this split, MAX’s evaluation harness guide walks the contract before the wiring.
| Failure surface | What it owns | Metric examples | Classical SW analogy |
|---|---|---|---|
| Retriever | Pulls relevant chunks into the candidate set | Context Precision, Context Recall, Recall@K, MRR | Upstream data service / read replica |
| Generator | Synthesizes an answer grounded in those chunks | Faithfulness, Answer Relevancy, Groundedness | Downstream API / business-logic layer |
| Joint system | End-to-end response correctness | RAG Triad composite, end-to-end accuracy | Full request span / user-visible latency |
Why More Context Made It Worse
You expect more data to improve answer quality. The classical instinct — bigger buffer, more retrieved chunks, longer prompt — is wrong in a way that took the field a research paper to name. In one experimental setup from a 2025 ICLR study, a model’s incorrect-answer rate jumped from 10.2% with no retrieved context to 66.1% when the retrieved context was insufficient — adding documents made the model more wrong, not less, per the Google Research blog.
That is not a marginal effect. It is a six-fold increase in wrong answers caused by feeding the model more material to work with. The mechanism is straightforward once you see it: insufficient context still looks topical to the model, the model writes a fluent answer that weaves the chunk’s surface vocabulary into a confident statement, and the Hallucination clears the faithfulness check because every claim sort-of attaches to something on the page.
This is the part where RAG guardrails and grounding stop being one box on a diagram and becomes three layers doing different jobs: citation generation (which passage supports which claim), confidence scoring (how strong the support is), and abstention (refusing to answer when support is too weak). The architectural commitment matters because the failure modes are different — a correct citation can still be unfaithful, per the ICTIR 2025 paper “Correctness is not Faithfulness in RAG Attributions.” For the full layer breakdown, MONA’s three-layer faithfulness explainer covers the mechanism.
The Retriever Is Now A Security Boundary
Your retriever used to be a query layer. It is now part of your security model. This is the shift senior backend engineers miss longest, because the failure mode does not look like a security incident — it looks like a wrong answer.
A poisoned document inside the retrieval index can steer the generator through Prompt Injection embedded in the chunk text. EchoLeak (Microsoft 365 Copilot) and CVE-2026-22200 (osTicket via PHP filter chains, weaponized through agentic RAG tools) showed that retrieved context is now an exfiltration vector — not a hypothetical, a published exploit class. The implication: retrieval index hygiene is a security control. Whoever can add documents to your corpus can shape your model’s output.
Recent research finds that benign retrieved documents flip both input and output guardrail judgments at non-trivial rates — guardrails calibrated on clean prompts are not robust to RAG-style contexts (arxiv 2510.05310). A guardrail that worked in the playground does not necessarily work once retrieval enters the loop. Your old instinct — treat user input as untrusted, treat your own data store as trusted — does not hold here. Both sides need scrutiny.
The actionable shift: defend the index with the same rigor you defend user input. Authenticate ingestion. Log who added what. Run content-safety rails on retrieved chunks before they reach the generator, not just on the user query. NVIDIA NeMo Guardrails v0.20.0 wraps a response gate plus an I/O rail engine that runs content-safety, topic-safety, and jailbreak detection in parallel for exactly this reason (NVIDIA NeMo Guardrails Docs).
Long Context Didn’t Make RAG Optional
The pitch sounded clean. Frontier labs shipped 1M-token windows. Just paste the corpus in. Skip the retriever. Simpler architecture, fewer moving parts, less to monitor. By April 2026, Claude Opus 4.7, Opus 4.6, and Sonnet 4.6 had all gone GA at standard pricing on a 1M-token window (Anthropic Docs). Gemini 2.5 Pro reached 1M GA. GPT-5.5 followed.
Enterprises tripled their retrieval spend instead of cutting it. VentureBeat’s Q1 2026 enterprise read reported intent to adopt hybrid retrieval rose from roughly 10% to 33% in a single quarter. The 1M-token race ended in a tie, and the prize went to retrieval. Why?
Two reasons your classical “bigger buffer = simpler architecture” instinct misses. First, the gap between marketed and effective context. BABILong (Kuratov et al. 2024) found models effectively use only ten to twenty percent of their advertised context — the rest is window dressing the model cannot reliably attend to. Chroma’s 2025 reproduction across eighteen frontier models confirmed every model degrades as input length grows. Second, the cost asymmetry. Elasticsearch Labs measured a roughly 1,250× cost ratio and 45× latency ratio between full-context inference and RAG retrieval over the same million-token corpus (Elasticsearch Labs).
Compatibility & freshness notes:
- Gemini 2.5 Pro context: 1M tokens GA as of May 2026. The marketed 2M expansion has not shipped — code assuming a 2M window will fail. Route 2M workloads to the older Gemini 1.5 Pro.
- Claude long-context pricing: 1M context is GA at standard pricing on Opus/Sonnet 4.6 and Opus 4.7 since March 13, 2026. Older articles quoting premium tiers above 200K are stale.
- Long Context Vs RAG positioning: Pre-2025 leaderboard numbers and benchmark comparisons are not directly comparable to current ones — different documents, different difficulty.
The decision framework is not “long-context or RAG” — it is “which constraints does my workload have.” For the routing logic, MAX’s decision framework covers the spec. The 2026 production answer is hybrid because the components compose. Retrieval narrows the input. Long context absorbs the survivors. Evaluation grades both sides separately.
Shift Diagram: From single-score RAG testing to layered guardrails Classic: Write tests → Run CI → Pass / fail → Ship AI: Decompose retriever + generator → Score each with pinned judge → Layer guardrails (citation, confidence, abstention) → Gate on direction
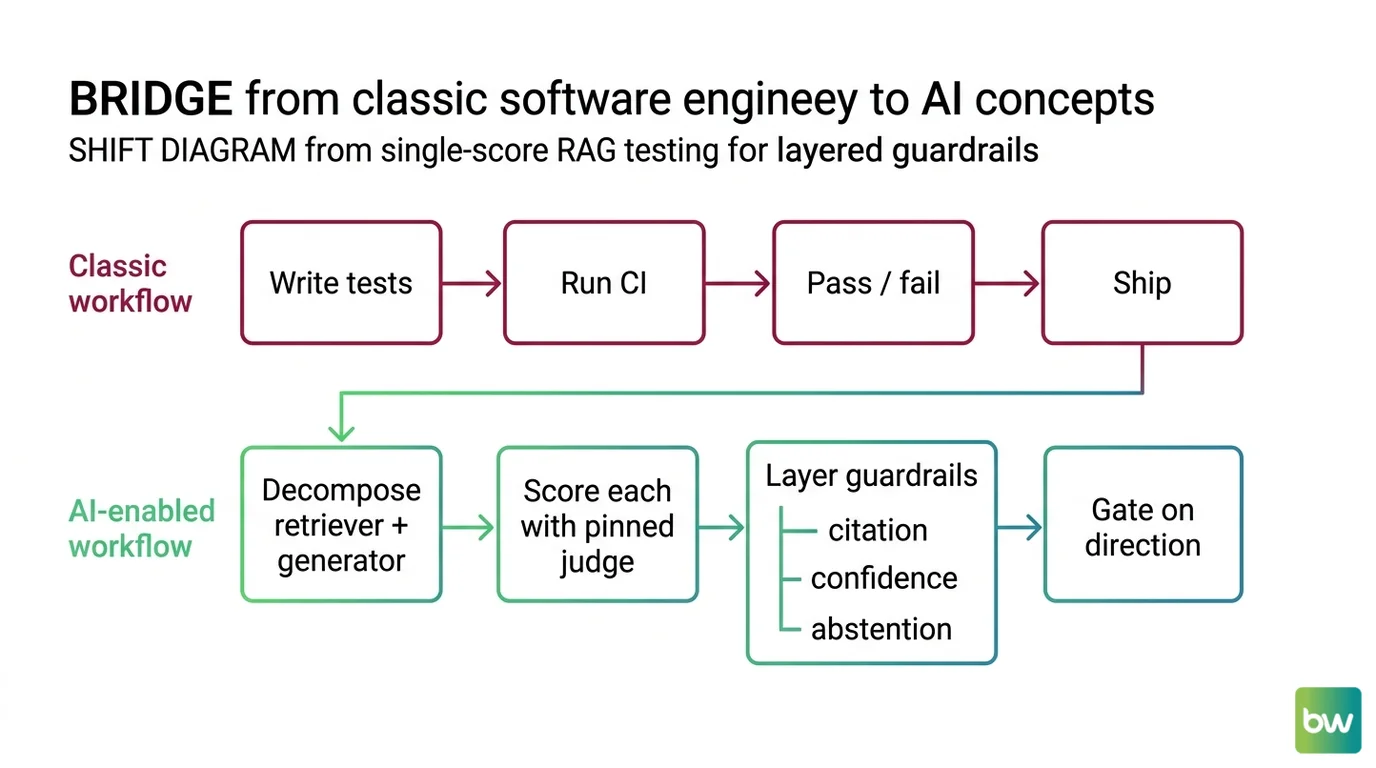
What Your CI Should Actually Gate
Your old testing instincts still help. Decompose. Pin your dependencies. Score each contract separately. Run regression detection on a fixed evaluation set. These all transfer.
What changes is what you treat as authoritative. The pinned judge LLM is now part of your metric definition. Thresholds are starting points, not SLAs. Layered guardrails — citation generation, confidence scoring, abstention — replace the single faithfulness number you wanted to gate on. The score is instrumentation. The gate is policy.
The updated mental model: RAG quality is a measurement discipline, not a test pass. Your next action is to write down — in one document, before you wire any tool — what “grounded” means for your domain, which judge model scores it, and which delta in which metric blocks a deploy. The teams that win the on-call war in 2026 are the ones with the tightest scoring contract.
FAQ
Q: What is the difference between RAG faithfulness and RAG correctness? A: Faithfulness measures whether claims in the answer are supported by the retrieved context. Correctness measures whether the answer is actually true. A faithful answer to a wrong retrieved chunk is still false — and the score will not flag it.
Q: Why does my RAG pipeline get different evaluation scores after upgrading the judge model? A: Because the judge LLM is part of the metric definition. Different judges have different biases — verbosity, position, self-preference — documented across twelve effects in the LLM-as-judge literature. Pin the judge, version it, and gate on relative deltas instead of absolute thresholds.
Q: Should I gate CI on a fixed faithfulness threshold like 0.9? A: Use thresholds as starting points, not SLAs. Gate on regression — drops greater than a defined delta against last week’s baseline scored by a pinned judge — and add layered checks (context precision, citation validity, abstention rate) so a single noisy score cannot block a clean deploy.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors