RAG Pipelines for Developers: What Maps from Search, What Breaks
Table of Contents
On Monday, your team shipped a knowledge assistant. Documents indexed, embeddings stored, retrieval API responding under 80ms with the right chunk in the top-3. By Tuesday, support tickets started arriving. The model cited a paragraph it had clearly read — and answered the wrong question with calm authority. Your retrieval traces showed the correct document. Your monitoring stayed green. The output was still wrong.
That is the failure mode nobody’s runbook covers. And it is the first sign that Retrieval Augmented Generation is not “search engine glued to an LLM” — it is a pipeline of five components, each with its own failure surface, and most of them break in ways your existing observability was never built to catch.
The Five-Box Pipeline Hiding Behind “RAG”
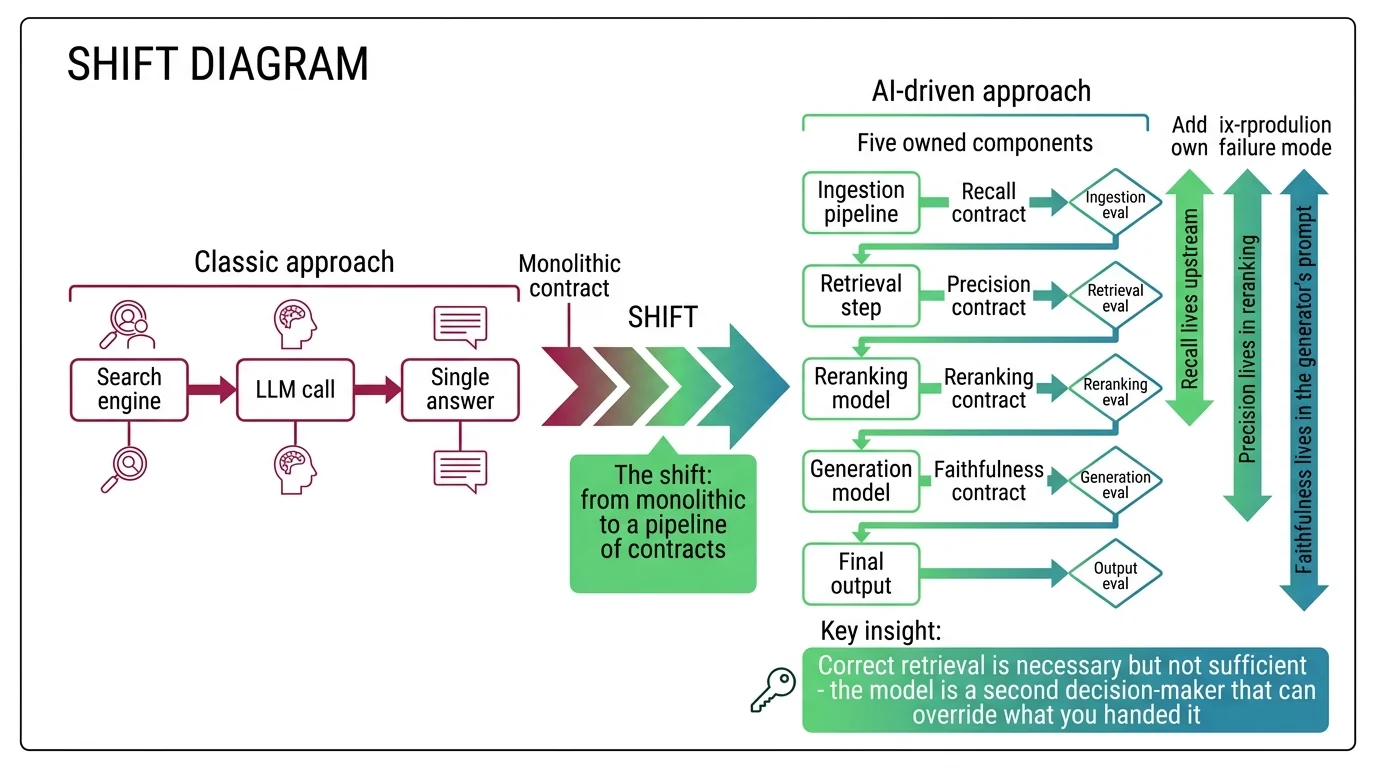
Most engineers describe RAG as “search plus an LLM.” That framing is the source of the wrong chunk size, the wrong embedding model, and the wrong fusion logic — and it is also why the team that wrote the demo cannot debug the production incident. A real RAG pipeline decomposes into five owned components: chunker, embedder, vector store, retriever, and generator — usually with a reranker between retriever and generator. Each one is a separate contract, with separate inputs, separate outputs, and separate failure modes.
This decomposition is the same engineering move you already make for read-heavy backend systems. You do not write one query plan that fans out across cache, primary, and replica. You name the layers, contract them separately, and route requests through them in a known order. RAG asks for the same discipline. The retriever owns recall — it either pulls the right chunks into the candidate set or it does not. The reranker owns precision — it can sharpen what the retriever found, but it cannot recover documents the retriever missed. The generator owns synthesis — and it can ignore everything you handed it if your prompt does not specify the conflict-resolution rule.
When does a developer actually need a RAG pipeline at all?
When the corpus you need to ground on changes faster than you want to retrain, when you need citations the user can verify, and when stuffing the whole corpus into the context window is too expensive or too slow. If your reference data fits comfortably inside a long-context call and update frequency is monthly, a longer prompt may be the cheaper engineering choice. If your data is a moving target — internal docs, support tickets, product catalogs, regulatory text — RAG is the path the production leaders have already taken. Notion, Perplexity, and Glean all standardized on hybrid retrieval at scale, per the Notion Blog, Perplexity Research, and Glean’s published architecture notes.
Why Correct Retrieval Still Lies
The first failure surface — retrieval missing the right chunk — is the one your search-engineering instincts will catch. Recall@k thinking transfers. Inverted-index sizing transfers. Query-latency profiling transfers. The next two failure surfaces do not, and they are why your top-3 retrieval logs can be green while the answer is wrong.
Why does technically correct retrieval still produce confidently wrong answers?
Two structural properties of the architecture cause this, and neither is a bug to be patched at the chunking layer.
The first is position bias inside the LLM context. Liu et al. (TACL 2024) documented the U-shape: relevant information at the start or end of a long context is retrieved well, while relevant information in the middle is systematically under-attended — Liu et al. measured roughly a 30-percentage-point accuracy drop on multi-document QA when the gold document sat in the middle of a 20-document context window versus at the very beginning or end. Your retriever did its job. The model still under-read the document because of where it landed in the prompt.
The second is knowledge conflict. The model has parametric memory baked in during training, and that memory does not gracefully defer to your retrieved context. The ReDeEP team traced this to specific feed-forward layers that over-emphasize parametric knowledge in the residual stream while attention heads responsible for copying retrieved content fight to keep up — per the analysis in MONA’s failure-modes explainer. When the corpus and the model disagree, the answer is the louder voice, not the correct one. Until you write the disagreement protocol explicitly into the system — as a prompt instruction, an evaluator pass, or fact-level conflict modeling — your pipeline will hallucinate in exactly the cases where the user most needs it not to.
The actionable rule: measure retrieval recall and answer faithfulness as separate metrics. Never collapse them into a single “RAG quality” score, because the fixes for each are different.
Mental Model Map: RAG Pipeline Design From: Search engine glued to an LLM — one query, one answer, monolithic contract Shift: Five owned components — each with its own contract, its own failure mode, and its own evaluation gate To: A pipeline of contracts — recall lives upstream, precision lives in reranking, faithfulness lives in the generator’s prompt Key insight: Correct retrieval is necessary but not sufficient — the model is a second decision-maker that can override what you handed it
Hybrid Search Is Two Number Lines
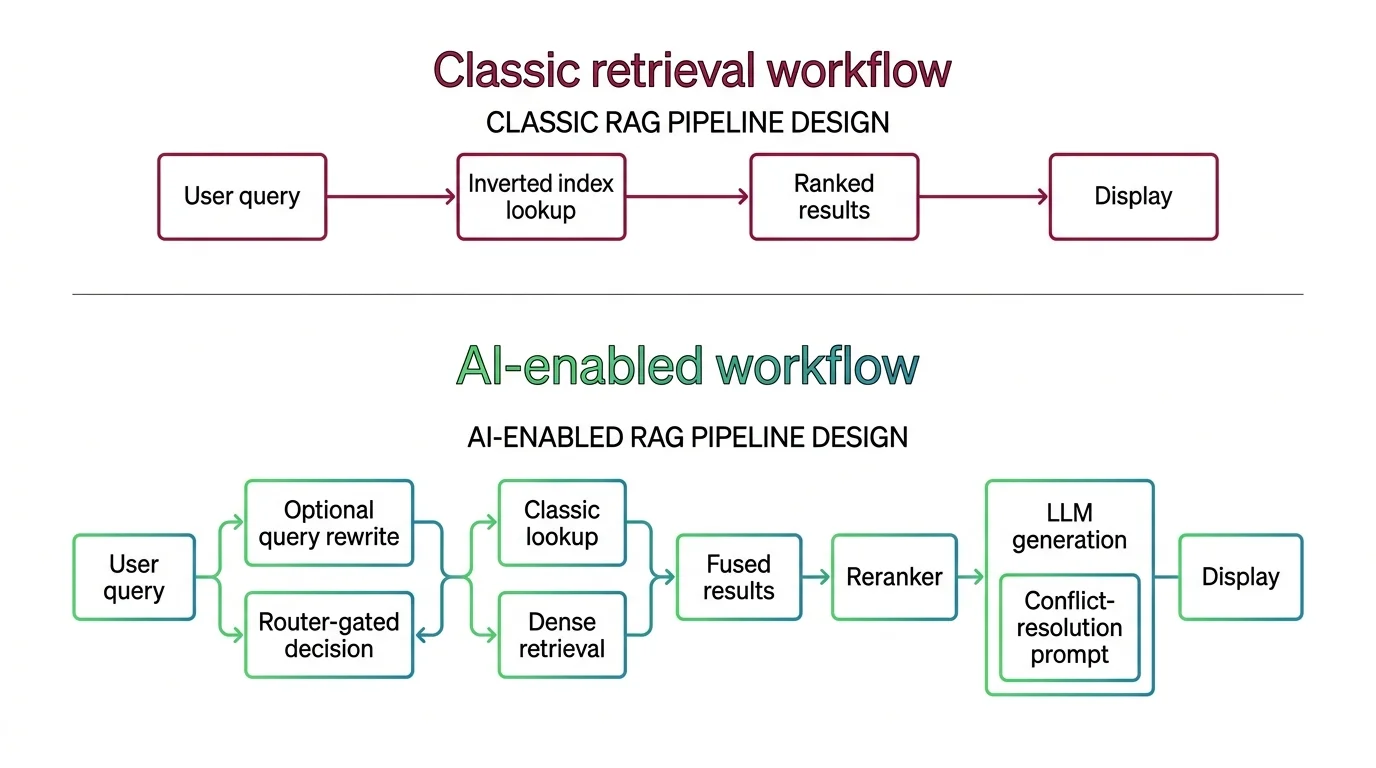
Once the team agrees that pure-vector retrieval misses exact-match terms — product SKUs, error codes, regulatory IDs, function names — the next move is Hybrid Search: combine BM25 keyword retrieval with dense vector retrieval, then merge the ranked lists. This is the consensus 2026 production pattern. It is also where developers fluent in classical search make their first wrong call.
The reflex from classical search is to add the scores. That reflex is wrong, and the reason is not a bug — it is two different number lines. BM25 scores are unbounded; on a typical English corpus they range from roughly 0 to a few tens, with the upper bound set by document statistics rather than any normalization. Cosine similarity from a dense embedding lives in [-1, 1]. These are not just two scales — they are two distributions, with different shapes, different variances, and different sensitivities to corpus drift.
This is why most hybrid retrievers default to Reciprocal Rank Fusion. RRF, introduced by Cormack, Clarke, and Büttcher at SIGIR 2009, ignores raw scores entirely and combines documents by rank position with a smoothing constant k. The folk claim is that k=60 is robust, traceable to Cormack’s original pilot. The trap: that robustness is a property of the original benchmarks, not of the algorithm. Qdrant defaults to k=2 (Qdrant Docs); Elasticsearch defaults to k=60 (Elastic Reference). Code copied from a non-Qdrant tutorial assuming k=60 will silently produce different rankings on Qdrant unless k is passed explicitly. Vendors call equivalent fusion methods by different names, and the score-based variants — Weaviate’s relativeScoreFusion, Qdrant’s Distribution-Based Score Fusion — solve a different problem in exchange.
| Decision | Classical Search Instinct | What Hybrid RAG Adds |
|---|---|---|
| Score combination | Weighted sum of normalized scores | RRF (rank-based) or DBSF (distribution-based); raw addition is a bug |
| Default constant | One canonical value | Vendor-specific (k=60 vs k=2) — pin it explicitly |
| What “good fusion” means | Higher relevance signal wins | Failure-mode tradeoff — pick which way the system is allowed to be wrong |
| Tuning loop | Click-through and DCG | Retrieval recall and answer faithfulness, measured separately |
The actionable spec rule: name the fusion algorithm in your context file. If your context says “use Weaviate hybrid search” without naming the fusion algorithm, the AI tool will copy whichever one was popular in its training data — and your relevance scores will silently drift on the next dependency upgrade.
Why More Stages Can Hurt Quality
The last instinct that fails hardest comes from cache-layer thinking: adding a layer monotonically improves the system. With a cache, more layers means more hits and shorter tails. With RAG stages, adding a layer can silently degrade quality on certain query shapes while improving them on others — and the degradation does not show up in any single retrieval metric.
Query Transformation is the clearest example. HyDE, multi-query, and step-back prompting each address a different geometric mismatch between question and answer, and the mechanism that makes each work is also what predicts where it fails. Multi-query expansion helps on ambiguous conversational queries — recent production guidance reports recall lift on that shape. On already-specific corpora — financial documents, structured records, well-formed queries — the same technique delivers negligible improvement and adds latency. HyDE generates a hypothetical answer document and embeds it; when the LLM lacks domain knowledge, the encoder cannot filter the wrong premise, and retrieval grounds itself in fabricated text. Anthropic’s Contextual Retrieval announcement explicitly lists HyDE among approaches that “still fail to provide substantial improvements” relative to chunk-side context augmentation (Anthropic Contextual Retrieval).
Reranking compounds the same lesson. A reranker is a precision pass on a candidate pool the retriever already nailed — it can fix the order, never the recall. If your stage-one retriever does not put the right document anywhere in the top-50, no cross-encoder reranker on earth will lift it to rank 1. Reranker latency is also a structural cost: it scales linearly with the number of candidates and quadratically with token length per pair, per the Brenndoerfer scaling tables cited in MONA’s reranker-limits explainer. Doubling your top-N doubles your reranker bill and tail latency. Doubling chunk length quadruples per-pair compute.
The diagnostic question for any new stage: which query shapes does this stage help, and which does it actively hurt? If you cannot answer that with measurements on your own data, you do not have a pipeline — you have a stack of defaults that will regress on you the moment your traffic distribution shifts.
Shift Diagram: RAG Pipeline Design Classic: User query → Inverted index lookup (BM25) → Ranked results → Display AI: User query → Optional rewrite (router-gated) → Hybrid retrieval (BM25 + dense, fused) → Reranker → LLM generation with conflict-resolution prompt
Where to Read Next
You now have a working map: five components, two number lines that need explicit fusion math, and three structural failure surfaces that do not respect cache-layer intuition. The next move depends on what you need to build. For the geometry underneath — chunking, embedding, indexing — start with MONA’s RAG components explainer. When you are ready to build, MAX’s production RAG guide with LangChain, Qdrant, and Cohere Rerank covers the spec-first decomposition that survives a dependency upgrade. If your retrieval works but answers are still wrong, MONA’s structural-failures piece maps the three surfaces — retrieval misses, position bias, knowledge conflict — that explain why.
The pipeline is a chain of contracts. Spec each one. Measure each one separately. The defaults will not save you when your traffic shifts.
FAQ
Q: What is the difference between RAG and fine-tuning for grounding an LLM in proprietary data?
A: Fine-tuning bakes data into model weights, requires retraining when data changes, and produces no citations. RAG keeps data in an external index, updates on document ingest, and surfaces source passages the user can verify. RAG is the default when your corpus changes faster than monthly.
Q: Do I need a vector database for hybrid search, or can I use Elasticsearch?
A: Either works. Elasticsearch ships RRF as a generally available retriever and handles dense vectors via HNSW alongside native BM25. Vector-native engines like Qdrant and Weaviate added BM25 to close the gap from the other direction. Pick the engine that fits the workloads around retrieval — algorithms travel cleanly between them.
Q: Why does adding a reranker not always improve RAG quality?
A: A reranker is a precision pass — it fixes the order of a candidate pool but cannot recover documents the retriever missed. If your top-50 retrieval does not contain the right document, no reranker will surface it. Measure stage-one recall before turning on a reranker.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors