Model Evaluation for Developers: What Maps and What Misleads
Table of Contents
Your team evaluated three LLMs for a document-processing pipeline. The procurement spreadsheet had one decisive column: MMLU score. The winner scored 93%. Integration took three weeks. In production, the model hallucinated contract clauses that did not exist in the source documents — confidently, fluently, with no error in your logs. Your monitoring showed normal latency. Every API response returned 200 OK. The failure was invisible to every diagnostic in your stack because the model was doing what benchmarks predicted: generating fluent, confident text. It just was not generating text faithful to the documents your pipeline fed it.
You selected on the wrong scorecard. The evaluation instincts you carried from software testing — where a passing suite means the code works — had no category for this failure mode. That gap between benchmark rank and production behavior is where Model Evaluation stops being a report card and starts being an engineering discipline you have not mapped yet.
The Score Entered Your Procurement
Model evaluation showed up in your workflow the way most AI dependencies do: through someone else’s decision. A vendor proposed an LLM. The sales deck cited benchmark scores. Your architect compared the numbers in a spreadsheet, and the model with the highest score won.
The instinct is reasonable. You benchmark databases by throughput. You benchmark web frameworks by requests per second. Higher means better for your workload. That mapping works for infrastructure benchmarks because the test conditions match your production conditions.
MMLU Benchmark does not make that promise. It tests factual recall across 57 academic subjects with multiple-choice questions. HumanEval tests whether a model can generate Python functions that pass unit tests. Both measure real capabilities — but the capabilities they measure may have nothing to do with your production task. A model that aces MMLU can hallucinate when summarizing legal documents. A model that tops HumanEval can fail multi-step instructions in a support workflow.
The benchmark is not lying. It is answering a question you did not ask.
MONA’s explainer on how benchmarks, metrics, and human judgment measure LLM quality covers the full evaluation taxonomy — static benchmarks, human preference platforms, and LLM-as-judge methods. What matters here is the consequence: the number that selected your model measured a property that does not predict production fitness.
Same Model, Three Different Scores
Your software test suite is deterministic. Same code, same assertions, same result. Run it ten times, get ten identical reports. That expectation runs so deep you probably stopped noticing it is an assumption.
It does not hold here.
Why can the same model produce different benchmark scores depending on evaluation harness configuration — prompt format, few-shot count, tokenization — when identical software test suites always return the same result for the same code?
An Evaluation Harness is the framework that runs a benchmark against a model — loading questions, formatting prompts, extracting answers, computing scores. Think of it as the test runner for LLMs. The analogy starts strong: like JUnit or pytest, it standardizes execution so results are comparable across models.
Where it breaks: the harness configuration changes the score. The same model tested on the same benchmark by two different harnesses can produce scores that diverge by up to five percentage points. The gap comes from prompt formatting, few-shot example count, tokenization handling, and answer extraction logic. None of these are model differences. All of them are measurement artifacts.
| Property | Software Test Suite | Model Evaluation Harness |
|---|---|---|
| Determinism | Same code, same result | Same model, different score per config |
| What varies | Code under test | Prompt format, few-shot count, extraction |
| Failure signal | Pass/fail with stack trace | Score on a continuum |
| Reproducibility | Pin dependency versions | Pin harness, prompt template, tokenizer |
| Failure mode | You see the error | You see a different number |
If you compare models using scores from different sources — a vendor’s marketing page, a leaderboard, your own evaluation run — those numbers may not be comparable. The score is a property of the model-plus-harness configuration, not the model alone.
MONA’s analysis of harness divergence and score reproducibility covers the exact mechanisms behind score variability. The practical rule: pin your evaluation harness the way you pin your test framework. Same harness version, same prompt template, same few-shot count. Otherwise you are comparing measurements taken with different rulers.
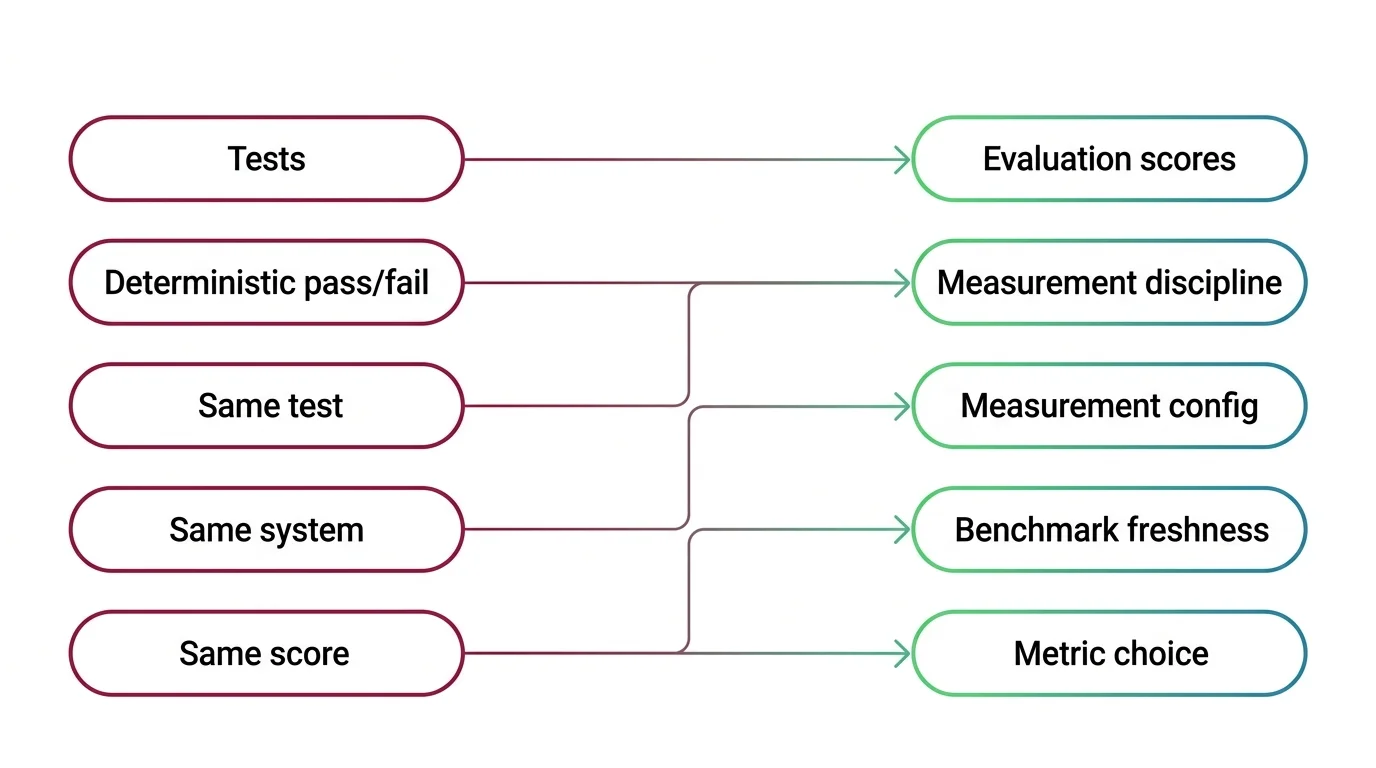
Mental Model Map: Model Evaluation & Benchmarks From: Tests give deterministic pass/fail — same test, same system, same score Shift: Scores depend on measurement configuration, not just model capability To: Evaluation is a measurement discipline — harness config, benchmark freshness, and metric choice shape the number Key insight: The score is a property of the model-plus-harness configuration, not the model alone
When High Scores Mean Memorization
In software testing, a test that passes means the logic works. The code produced the correct output for the given input. There is no scenario where the code memorized the expected output without implementing the logic.
LLM benchmarks break that assumption.
What happens to model selection decisions when benchmark contamination means high scores may reflect memorization of test answers rather than genuine capability?
Benchmark Contamination occurs when a model’s training data includes the test questions it will be scored on. The model has seen the answers before. It retrieves instead of reasons. The score inflates without any improvement in the capability the benchmark was designed to measure.
This is structural, not hypothetical. SWE-bench Verified — a coding benchmark used to rank AI coding tools — was retired after an audit found the majority of its tasks flawed or unsolvable. The replacement, SWE-bench Pro, immediately cut top scores from the 70-80% range to roughly 23%. Same models. Harder test. Scores that actually reflect engineering ability instead of pattern recall.
MMLU tells a parallel story. Frontier models cluster above 88%, and evaluation providers have begun replacing the original MMLU with MMLU-Pro for frontier comparisons. The original benchmark’s questions have been publicly available since 2020 — years of training runs later, the score ceiling says more about data overlap than model capability.
The practical question for your next model selection: how old is this benchmark, and has anyone checked for training-data overlap? If the test has been public for more than a year, treat the score with the same suspicion you would give a performance benchmark run on hardware tuned specifically for that benchmark. MONA’s explainer on how training data overlap inflates evaluation scores covers the detection methods and the scale of the problem.
Your CI/CD Instincts Transfer Here
Not everything breaks. Some instincts from software quality engineering carry over directly — they just need different assertion types.
Which instincts from designing software test suites and CI/CD quality gates still apply when building an LLM evaluation pipeline?
Version pinning transfers directly. Pin your model version, your evaluation harness version, and your prompt templates. When any of these change, re-run your evaluation suite — the way you re-run tests after a dependency upgrade.
Quality gates transfer. Wire evaluation metrics into your CI/CD pipeline. If a prompt change drops your faithfulness score below a threshold, the gate blocks deployment. The structure is identical to blocking a merge when unit tests fail. MAX’s evaluation pipeline guide walks through the four-layer framework for wiring this into your pipeline.
How does the software engineering practice of regression testing transfer to tracking model quality across version upgrades and prompt changes?
The structure transfers: run evaluations after every change, fail the build if quality drops. The assertion type changes. Instead of “output equals expected,” you check “faithfulness score exceeds threshold across a representative test set.” Statistical assertions, not exact-match.
Production monitoring transfers too. You already watch latency, error rates, and throughput. For LLM systems, add metric-level tracking: faithfulness, hallucination rates, answer relevancy over time. A model version bump from your API provider can silently degrade quality the way a database driver update can shift query plans. Your monitoring should catch both.
What does not transfer: the assumption that a passing evaluation means production readiness. A strong evaluation catches known failure modes. It does not catch edge cases from user inputs you did not anticipate. Your evaluation is a safety net, not a certificate.
Classification Metrics Don’t Grade Text
If your AI integration involves classification — spam detection, fraud screening, content moderation — your existing metrics vocabulary carries over cleanly.
Precision, Recall, and F1 Score measure what they always measured. The Confusion Matrix shows you where the classifier fails. Whether to optimize for precision or recall is still a domain decision: in fraud detection, missing a fraud case costs more than flagging a legitimate transaction. That tradeoff has not changed.
What changed is the output type.
When the output is a label — positive/negative, fraud/legitimate — F1 is the right instrument. When the output is generated text, F1 measures nothing useful. You cannot compute precision on a conversation. There is no ground-truth reference for “summarize this legal contract” against which to calculate recall.
The field has moved to different instruments for generative outputs: LLM-as-judge scoring, where a separate model grades your primary model on rubric dimensions; human preference ranking through platforms like Arena; and task-specific metrics like faithfulness and answer relevancy for RAG systems. Each measures a different property. None replaces F1 — they answer different questions for different output types.
The diagnostic for your evaluation strategy: list every model output your system produces. For each, name the metric that would catch the failure mode you care about most. If you cannot name the metric, your evaluation has a gap. If the metric is F1 and the output is free text, you have the wrong instrument.
Match your metric to your output type, not to your familiarity with the formula. MONA’s explainer on perplexity, BLEU, ROUGE, and Elo covers what each metric measures and where each one goes blind. For Ablation Study techniques that isolate which pipeline components affect your evaluation outcomes, MONA’s explainer on ablation methodology covers the experimental design.
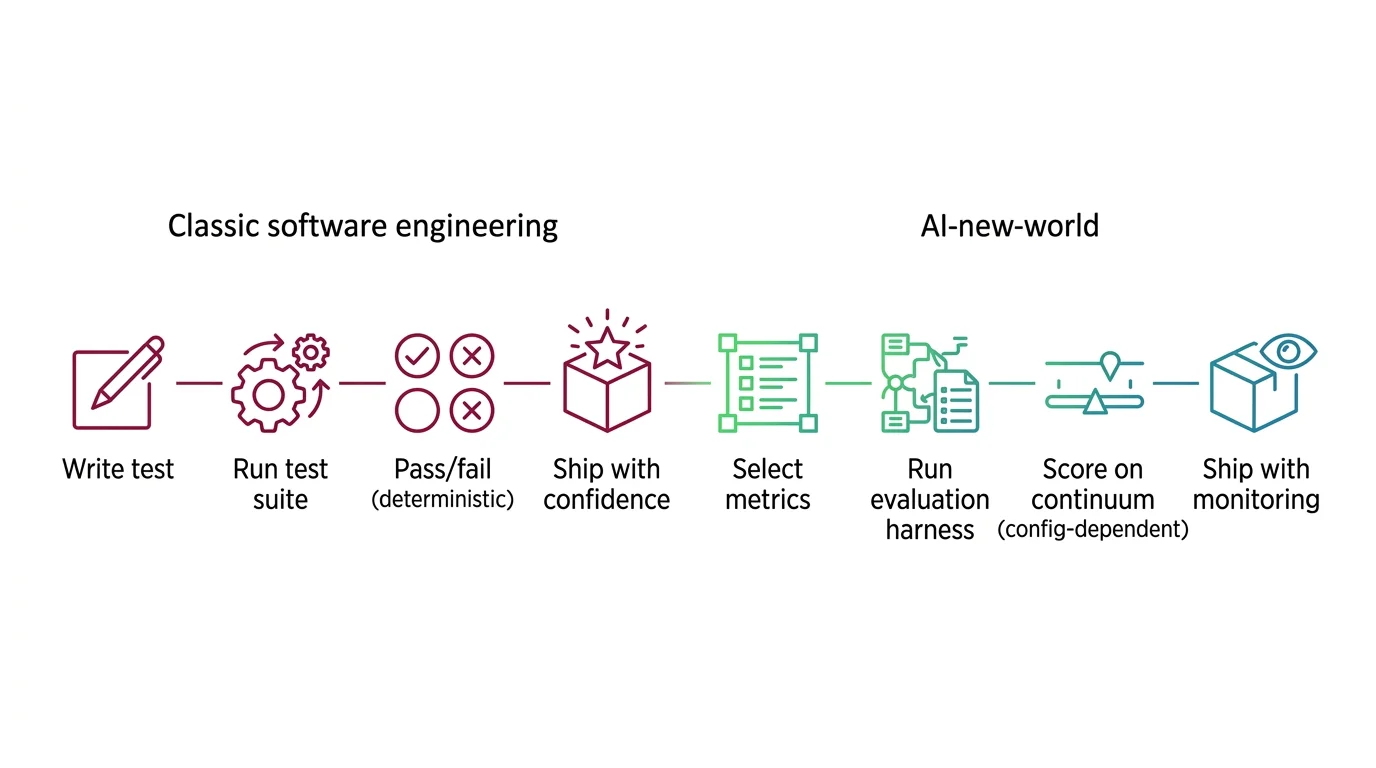
Shift Diagram: Model Evaluation & Benchmarks Classic: Write test → Run test suite → Pass/fail (deterministic) → Ship with confidence AI: Select metrics → Run evaluation harness → Score on continuum (config-dependent) → Ship with monitoring
Model evaluation is not software testing with different inputs. It is a measurement discipline where instrument configuration shapes the result, test data can be compromised, and output type determines which metrics apply. The instincts that help: version pinning, regression gates, production monitoring. The instincts that mislead: expecting determinism, trusting a single score, treating a passing evaluation as a shipping guarantee.
If you need the mechanism underneath benchmarks and metrics, start with MONA’s model evaluation explainer. When you are ready to build the pipeline, MAX’s evaluation guide is built for spec-first development.
FAQ
Q: Do I need to run my own benchmarks before selecting an LLM? A: Yes, if production performance matters. Public benchmarks test generic capabilities. Build a small evaluation set from real production queries, run it against candidate models under your actual conditions, and compare results using the same harness configuration.
Q: Can I use F1 score to evaluate an LLM chatbot? A: Not directly. F1 needs a correct/incorrect label for each prediction. Chatbot outputs are generative text with no single correct answer. Use task-specific metrics like faithfulness, answer relevancy, or human preference scoring instead.
Q: What is benchmark contamination and should I worry about it? A: Benchmark contamination means the model’s training data included the test questions — the model memorizes answers instead of learning the capability. Worry about it when evaluating models using benchmarks public for over a year, especially MMLU and HumanEval where contamination is documented.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors