LLM Training for Developers: Which Instincts Help, Which Mislead
Table of Contents
Your API provider shipped a model update last Tuesday. Same endpoint, same version string, same prompt template running in production for three months. The extraction pipeline started dropping structured fields. Edge cases that worked last month began returning refusals. Your team spent four days auditing prompt logic, checking tokenizer changes, reviewing rate limits — nothing wrong anywhere in your code. Then somebody found a line buried in the provider’s blog: updated preference alignment. The behavior shift was baked into the weights before the model reached your API.
That debugging dead end catches experienced developers because the model behind your endpoint is not a static binary. It is an artifact shaped by three training stages — each one irreversible, each one leaving permanent marks on how every response gets generated. When you cannot name those stages, you cannot tell the difference between a property the training process encoded on purpose and a bug in your prompt.
The Three Stages Behind Every API Call
Every model your team calls through an API was built in a strict sequence. Pre Training compressed trillions of tokens of internet text into a statistical engine that predicts language — not by understanding it, but by mapping conditional probabilities across token sequences at enormous scale. Fine Tuning adapted that engine for specific behaviors: instruction following, structured output, domain expertise. RLHF reshaped the output distribution using human preference data — deciding what sounds helpful, what gets refused, what tone the model defaults to.
Three stages. Each one modifies the same set of weights. Each one is permanent. And each stage builds on the previous one — so a change in pre-training ripples through fine-tuning and RLHF, compounding in ways that are difficult to trace from the outside.
When your provider ships an update, they may have changed any of those stages. Or all three. There is no artifact you can diff to find out which one moved. Here is what each stage change looks like from the outside. A pre-training change shifts general knowledge — facts, associations, languages the model handles fluently. A fine-tuning change shifts task behavior — output format, instruction compliance, domain accuracy. An RLHF change shifts personality — refusal boundaries, verbosity, hedging patterns. Your monitoring shows the symptom. It does not name the stage.
The refusal your team hit on Tuesday was not a prompt failure. It was a preference alignment decision — somebody’s annotation team decided those edge-case responses were unsafe, and the model learned to avoid them. The structured field that disappeared was a side effect of updated fine-tuning data that shifted the model’s formatting defaults. Your prompt did not pin the format tightly enough to survive.
If the mechanism of how prediction at scale builds that language engine interests you, MONA’s explainer on how pre-training works covers the math underneath. What matters at this level is the consequence: the model arrived with opinions you did not write.
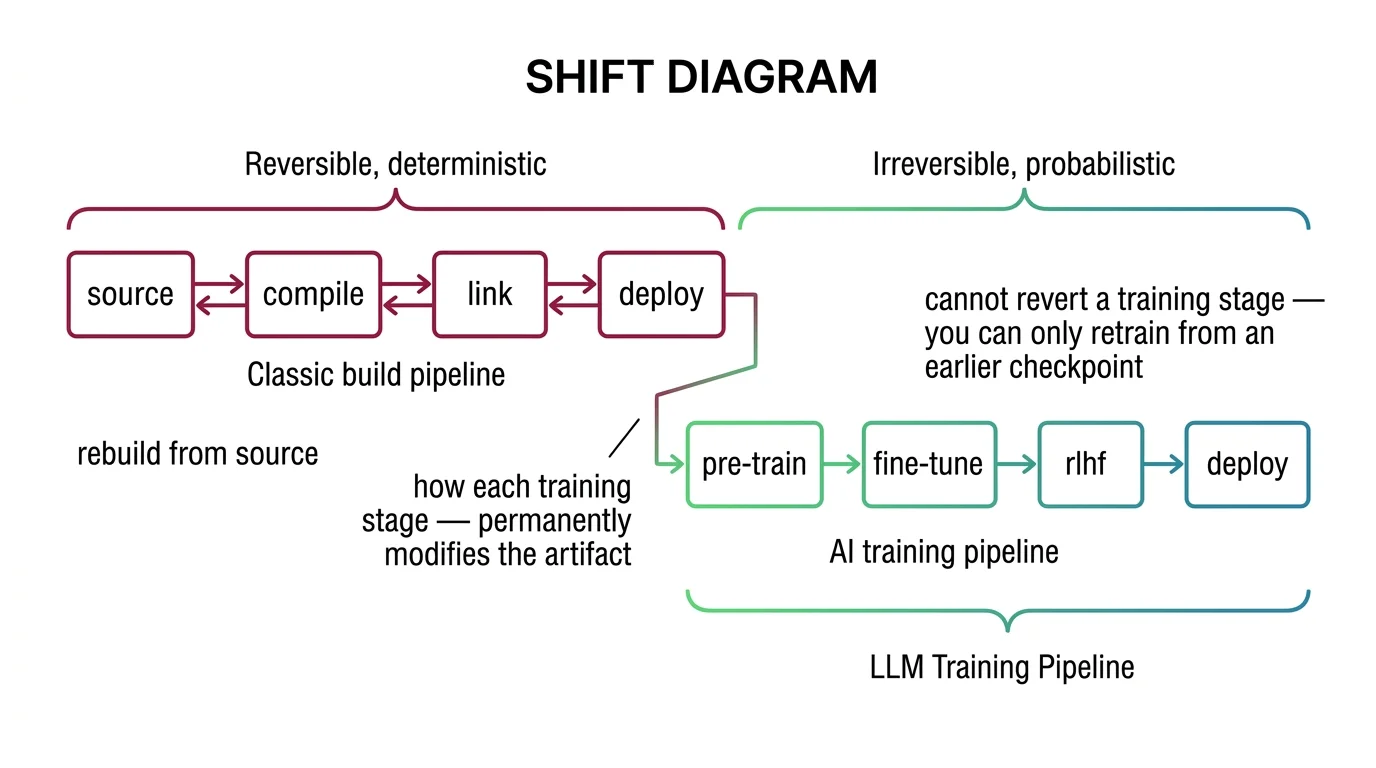
A Build Pipeline That Never Rebuilds
If you have built CI/CD pipelines, the staged-process model is already in your head. Source code flows through compilation, linking, packaging, deployment. Each stage transforms the artifact. The output of one becomes the input to the next. That instinct transfers — with one boundary you need to see clearly.
Which staged-pipeline instincts help frame the training sequence?
Stage-gate thinking maps directly. Each training phase has defined inputs, outputs, and failure modes you can reason about. Pre-training needs curated data and a compute budget governed by Scaling Laws — empirical rules predicting how performance improves with compute, data, and parameters. Fine-tuning needs a task-specific dataset and an adapter configuration specifying what to change and what to freeze. RLHF needs preference data and a Reward Model Architecture that compresses human judgment into a scalar training signal.
Your debugging instinct — isolate the layer, bisect between stages, compare outputs at known boundaries — still works here, if you know where the layers are. When output quality degrades, the first diagnostic question is: did the base model change (pre-training), did the task adaptation change (fine-tuning), or did the behavioral boundaries change (RLHF)? That triage maps onto how you bisect regressions in a build pipeline. The difference is that the regression lives in the weights, not in your commit history.
Now the boundary. In a software build, you rebuild from source. The artifact is reproducible. In LLM training, each stage modifies weights permanently. Fine-tuning overwrites the base model’s parameters — the base cannot be recovered from the fine-tuned result. RLHF modifies the fine-tuned model — the pre-alignment behavior is gone. There is no git revert for gradient descent.
| Classical Build Pipeline | LLM Training Pipeline |
|---|---|
| Rebuild from source at any time | Cannot reverse a training stage |
| Output is deterministic given same inputs | Output is probabilistic — same prompt, different run |
| Bug = regression in a specific commit | Behavior shift = property of the weights |
| Patch one module without side effects | Fine-tuning one capability can degrade others |
| Version control tracks every change | Weight changes are not human-readable |
The stage-gate model helps you reason about the sequence. The reversibility assumption does not survive contact with training.
Mental Model Map: LLM Training Pipeline From: Build pipeline — source, compile, link, deploy (reversible, deterministic) Shift: Each training stage permanently modifies the artifact — no rebuild from source To: Training pipeline — pre-train, fine-tune, align, deploy (irreversible, probabilistic) Key insight: You cannot revert a training stage — you can only retrain from an earlier checkpoint
The Patch That Destroyed Prior Work
Your instinct for patching works like this: identify the module, apply the fix, verify it passes, ship it. If it causes a regression, you roll back. The patch touched one component. Everything else stayed the same.
Fine-tuning does not work like this.
When you fine-tune a model, gradient updates modify weights across the network. You are not patching a function. You are reshaping behavior globally, in ways that are hard to scope and impossible to fully predict. The weights you changed to teach a new skill were the same weights that stored an old one.
Why does treating fine-tuning as reversible configuration underestimate catastrophic forgetting?
Because the model’s parameter space is shared across all capabilities. Fine-tuning on domain-specific data shifts weights toward that domain — permanently. Capabilities that depended on the prior weight configuration — general reasoning, cross-domain coherence, safety behaviors — may degrade without any error in your logs. This is not a version conflict. It is how gradient descent works when two objectives compete for the same parameters.
The failure mode has no equivalent in classical software. A software patch does not cause the authentication module to forget how to validate tokens. A fine-tuned model can lose capabilities nobody thought to test for. MONA’s analysis of catastrophic forgetting covers the geometry and the mitigations that slow the problem without solving it.
Parameter-efficient methods — LoRA, QLoRA — freeze most base weights and train small adapter matrices instead. They reduce the blast radius. They do not eliminate it. If your team is considering fine-tuning, MAX’s specification guide to PEFT, Unsloth, and Axolotl walks through the framework for locking dataset, adapter, and validation contracts before GPU hours start. The spec matters more than the tool.
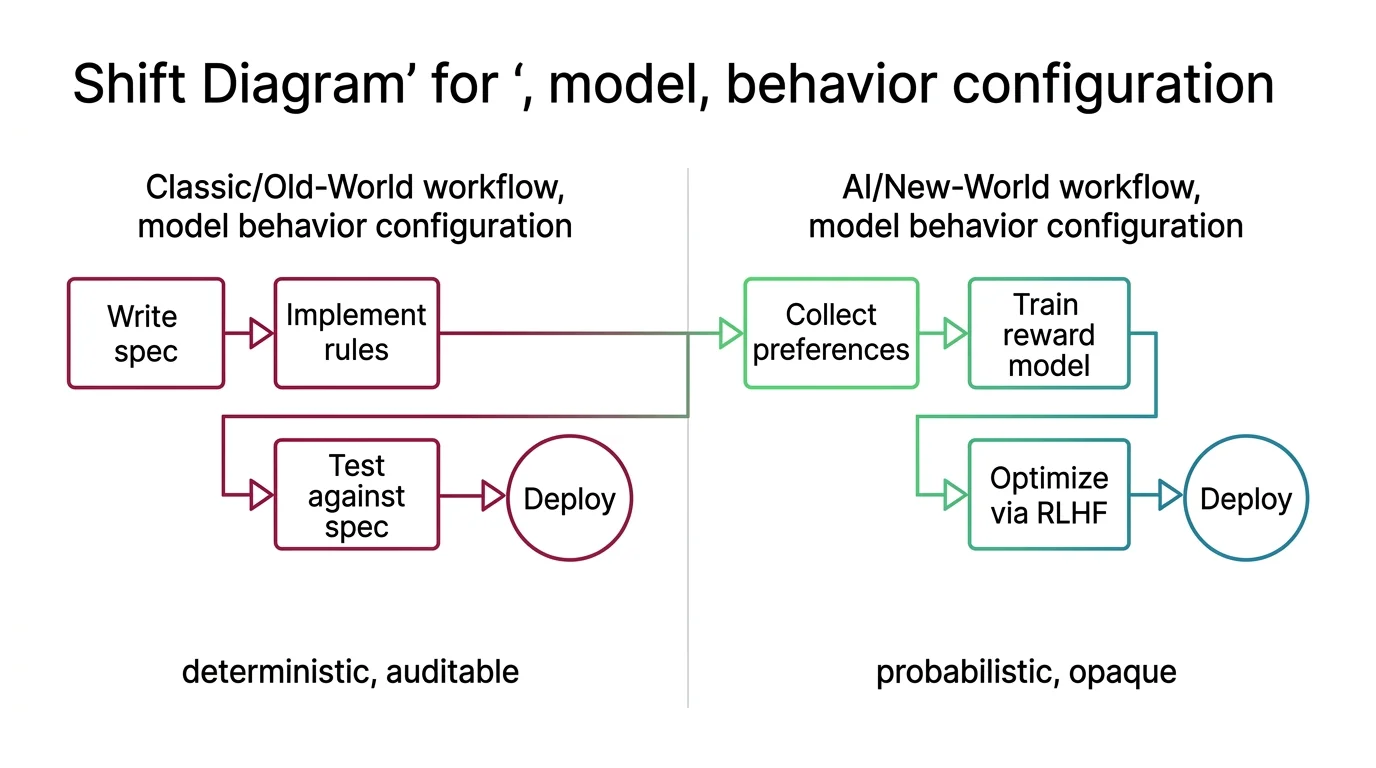
Human Votes Replaced Your Specification
In classical software, behavior follows a specification. You write the rules. The system follows them. When it does not, you debug the rule or the implementation. The spec is the contract.
RLHF replaced that contract with a vote.
The aligned model’s behavior is shaped by human preference data — annotators choosing which response they prefer, thousands of times. Those preferences get compressed into a reward model, and the language model is optimized to score highly against that signal. The result is a model that behaves helpfully according to the aggregate preferences of a specific annotator workforce. Not your specification. Not your users’ needs. A preference signal you cannot inspect, compiled from judgments you cannot audit.
Which deterministic-build assumptions break when model behavior comes from noisy human rankings?
The ones you rely on most. Output is not deterministic — same prompt, different run, different result. Behavioral boundaries are not version-controlled — you cannot diff the preference data that shaped them. Safety constraints are not in a config file — they are byproducts of whatever the reward model’s training signal encoded. And when the provider retrains with new preference data, boundaries shift without a changelog you can review.
For the full mechanism of how reward models compress judgment into a scalar and where the compression fails, MONA’s explainer on the RLHF pipeline walks through each stage. For why reward hacking and mode collapse resist easy fixes, MONA’s analysis of the unsolved limits covers what current methods cannot solve.
Shift Diagram: Model Behavior Configuration Classic: Write spec → Implement rules → Test against spec → Deploy (deterministic, auditable) AI: Collect preferences → Train reward model → Optimize via RLHF → Deploy (probabilistic, opaque)
The Cost Curve Your Linear Model Misses
Your capacity planning instincts assume something close to proportional scaling. Double the traffic, roughly double the infrastructure. Predictable. Budgetable.
LLM training follows a different curve. And the gap between your expectations and reality compounds the larger your investment gets.
Why do scaling laws guarantee diminishing returns on compute investment?
Because the relationship between compute and quality is a power law with small exponents. More compute does improve performance — but the improvement decelerates hard, and it decelerates predictably. The classical expectation that doubling resources yields proportional results leads to systematically wrong training budget estimates. Teams planning fine-tuning or pre-training investments on linear assumptions overspend for gains that shrink with every increment. The next dollar of training compute returns less than the last one.
The instinct that there is an optimal allocation for a given budget transfers cleanly — that is exactly what scaling laws formalize. You already think about cost-efficiency ratios in infrastructure planning. The same discipline applies here, but the curve bends differently. The instinct that scaling is proportional does not survive. If your team is evaluating whether to fine-tune a larger model or invest in better data curation, the power law says data quality wins earlier than most engineers expect. MONA’s explainer on scaling laws covers the three eras of scaling research — Kaplan, Chinchilla, and the Densing Law. MAX’s guide to Chinchilla-optimal ratios translates the theory into a compute budgeting framework — start from inference constraints and work backward, not the other way around.
The model behind your API was built in three irreversible stages, each one shaping behavior in ways your application code cannot override. Your pipeline instincts help you reason about the sequence. They stop helping the moment you assume you can revert, scope, or fully predict any of those stages. The updated mental model: your dependency graph now includes the training pipeline, and the debugging starts at the weights, not at the prompt.
FAQ
Q: Why does my model behave differently after a provider update when the API version stays the same? A: The provider retrained the model — typically by updating fine-tuning data or RLHF preference alignment. The API contract covers the interface, not the weights. Same endpoint, different behavior, no changelog your monitoring will catch.
Q: Can fine-tuning be reversed if it breaks existing model capabilities? A: Not directly. Fine-tuning permanently modifies weights. Catastrophic forgetting — where new training degrades prior capabilities — is the default failure mode. Parameter-efficient methods like LoRA reduce the blast radius but do not eliminate it. Roll forward from a saved checkpoint.
Q: Do scaling laws mean bigger models are always worth the extra cost? A: No. Scaling laws follow power-law curves with small exponents — each compute increase yields diminishing quality improvements. For most teams, better data curation and inference-aware model sizing deliver more value than training bigger.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors