Knowledge Retrieval for Engineers: What Transfers, What Breaks
Table of Contents
On Monday, the legal team uploaded six hundred scanned 1990s contracts to your ingestion pipeline. By Tuesday morning, the rolling parser bill had tripled, an answer in a customer session cited a paragraph from another tenant’s policy, and a multi-hop compliance question — “which counterparties of Subsidiary X are also exposed to Sanctioned Entity Y through any chain of ownership?” — came back with the three most semantically similar chunks and missed the chain entirely. Your retrieval logs were green. Your unit tests passed. The product team asked, calmly, whether RAG was working.
That is the failure mode the Retrieval Augmented Generation tutorials do not cover. Once your team builds past the first vector index, retrieval stops being one component and becomes four — graph traversal, document parsing, metadata filtering, multimodal embedding — each with its own architectural property, its own bill, and its own way of breaking the assumptions you carried in from twenty years of backend work.
When Parser Cost Replaces Storage Cost
Most engineers price ingestion the way they price ETL: cost grows with data volume. You have a per-page rate, you multiply by document count, the finance team gets a defensible number. Document Parsing And Extraction breaks that line on the first batch of scans. Cost scales with document complexity, not document count — and complexity is a property of the source corpus, not the parser.
What changes when parsing stops being “OCR plus cleanup”?
Modern document parsing is three reconstruction problems stacked on top of each other: characters (OCR), 2D layout (where each block sits and which is the reading order), and structure (tables, formulas, hierarchy). On a clean printed text-PDF, classical OCR like Tesseract still hits 98-99% accuracy (per Koncile). On the same engine, scanned PDFs drop to 90-95%, complex layouts to 70-85%, and handwriting to 50-80% — and a 95% accurate parser sounds fine in aggregate until you remember it is the upstream layer for chunking, embedding, and retrieval, each of which is also lossy.
The 2026 inversion is sharper than the accuracy gap suggests. Sub-1B specialist vision-language models — MinerU 2.5-Pro at 95.75 on OmniDocBench v1.6, GLM-OCR at 95.22 with 0.9B parameters — now beat Gemini 3 Pro (90.33 on v1.5) and GPT-5.2 (85.4) on real-world PDFs (per the OmniDocBench leaderboard and LlamaIndex blog). Self-hosted GLM-OCR runs at roughly $0.09 per 1,000 pages; GPT-4o on the same workload runs $15+ per 1,000 pages — over 100× more expensive (LlamaIndex blog). If your RAG ingestion still routes everything through a frontier model because “the biggest model is safest,” your 2026 budget is about to get an awkward review.
The actionable rule: triage before you parse. Profile your document mix — what percentage is text-PDF, scanned, DOCX, slide deck, table-heavy — and route by complexity. A flat parser tier is a flat tax. A routed pipeline is a cost curve you can shape, and the per-route line item is the one finance can audit. For the spec-first decomposition, MAX’s parsing pipeline guide covers the four-layer architecture; for the architectural reasons the bottleneck has moved from characters to structure, MONA’s parsing limits explainer traces it.
Metadata Filtering Is Not a WHERE Clause
The first time you point a
Metadata Filtering predicate at a vector index, the API will look exactly like SQL. WHERE tenant_id = 'acme' AND created_at > '2026-01-01'. Your team will assume the query planner behaves the way Postgres does. It does not. The behavior diverges in ways that your existing observability cannot see.
Mental Model Map: Knowledge Retrieval Systems From: Vector index with a WHERE clause — one query, one result set, one cost line Shift: Four independent retrieval surfaces — graph traversal, parsing pipeline, filter strategy, modality routing — each with its own planner, its own bill, and its own failure mode To: Knowledge retrieval as a stack of contracts where the cost cliff, the recall cliff, and the permission boundary live in three different layers Key insight: Old data-engineering intuition still routes the architecture; it stops predicting cost, recall, and isolation as soon as the index is built on top of an HNSW graph
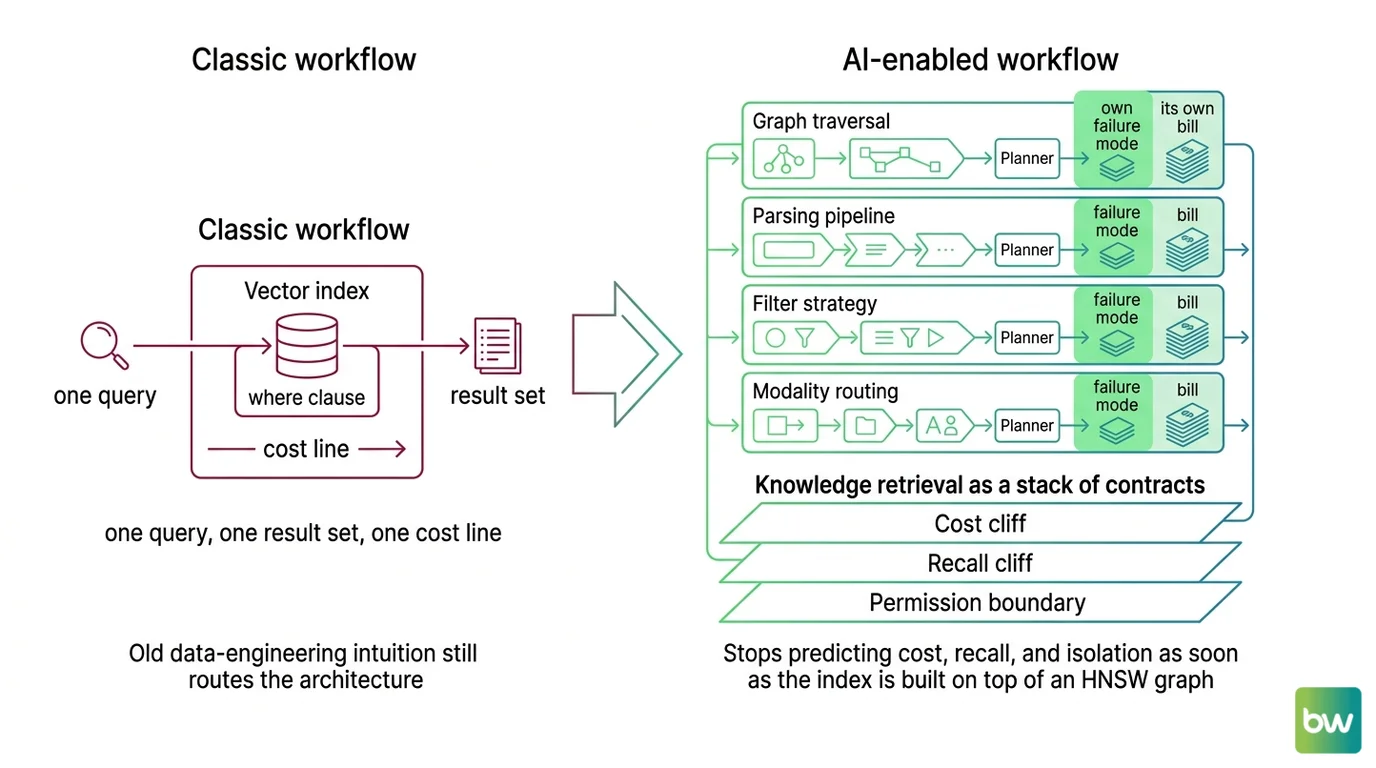
How far does SQL query-planner intuition transfer to filtered vector search?
The decomposition transfers. The cost model does not. Every modern vector store with metadata support — Qdrant, Weaviate, Milvus, pgvector, Pinecone — implements one of three filtering strategies: post-filter, pre-filter, or filtered-HNSW. The user-visible API is identical. The planner decides which strategy at runtime, and it is making a guess about your data on every call.
Post-filtering runs the unfiltered ANN search first, then drops the candidates that fail the predicate. It produces under-filled result sets when the filter is selective. Pre-filtering computes the filter first and then runs ANN over the survivors — but if the surviving set is small and disconnected from the dense regions of the Vector Database graph, the search may scan more than it would have without the filter. Filtered-HNSW (Qdrant’s filterable index, Weaviate’s ACORN since v1.34) extends the graph with extra edges keyed to indexed payload values so the index stays connected after filtering, preserving recall. Weaviate also automatically flips to brute-force flat search around a 15% match-rate threshold (Weaviate Docs).
That is three different bets about how a predicate deforms the index, hidden behind one SDK call. Below Qdrant’s full_scan_threshold (default 10,000), the engine abandons graph traversal entirely and rescores via the payload index. Below pgvector 0.8.0, the engine silently returns under-filled result sets when an iterative_scan is not enabled. The 2024 conversation was unfiltered ANN throughput. The 2026 conversation is filtered recall under tenant isolation, and three open-source engines already rebuilt for that reality (per the Qdrant Blog, Weaviate Blog, and Milvus Blog).
The diagnostic question for any production filter: what is its selectivity profile, and which strategy does my engine pick at each selectivity band? If you cannot answer that, your retrieval is one query distribution shift away from a recall cliff that no dashboard surfaces. For the mechanism, MONA’s filtering-at-scale explainer traces it; for the spec, MAX’s metadata-filtering guide covers tenant, time, and permission decomposition.
Tenant Tags Are Not Permission Boundaries
This is the misconception with the highest blast radius, and the one your integration tests will not catch. Multi-tenant RAG looks like multi-tenant SaaS. In multi-tenant SaaS, you scope every query with a tenant_id, you write a row-level security policy, you sleep at night. In a shared vector index, the same pattern is documented as an anti-pattern by the vendor whose API encourages it.
Why does treating a tenant_id tag as an access-control boundary create a permission-leak risk?
Because the boundary is a string in a JSON field, applied by a planner that is making routing decisions to keep recall acceptable. A bug in the helper function — the new “share search across workspaces” feature that reused the unfiltered retriever; the upgrade that flipped a Weaviate collection’s filter strategy; the stale ACL that never propagated — does not raise an exception. It silently widens the retrieval set. OWASP’s 2025 Top 10 for LLM Applications added LLM08:2025 “Vector and Embedding Weaknesses” as a distinct category specifically for this risk class. The OWASP AISVS C08 control family for vector databases requires per-tenant logical or physical isolation, hard deletes for revoked vectors, and audit logging — none of which a metadata tag delivers on its own.
There is also a class of attacks the relational world never had. The ConfusedPilot work from UT Austin’s Spark Lab documented a confused-deputy attack against RAG systems including Microsoft 365 Copilot, in which a malicious document instructs the assistant to override other documents — and the effect persists even after the offending file is deleted, because its embedding still anchors retrieval. Your row-level-security mental model has nothing to say about that. For the full ethical and architectural argument, ALAN’s permission-leakage piece names the trade.
The actionable rule: a tenant_id tag is a query-time hint, not a physical boundary. If your contract requires isolation, use a per-tenant namespace, partition, or collection. Treat the metadata tag as an additional check, never the only one.
When Vector Search Cannot Walk a Relationship
The next failure surface is the one your search-engineering instincts will never catch, because the question never gets asked of a search engine. A bank’s compliance team wires standard vector RAG over five years of policy documents. They ask: “Which counterparties of Subsidiary X are also exposed to Sanctioned Entity Y through any chain of ownership?” The system returns the three chunks that contain the most semantically similar sentences. The chain is in the corpus. The chain is not in the answer.
That is the multi-hop gap. Vector retrieval pulls semantically similar chunks but lacks awareness of how facts connect — leading to weak multi-hop reasoning, poor entity disambiguation, and limited provenance (per the ScienceDirect 2026 survey on modern RAG). Knowledge Graphs For RAG closes that gap by extracting entities and typed relationships from documents, building a graph, and walking it at query time. Microsoft GraphRAG and HKUDS LightRAG are the two reference patterns; Neo4j is the convergence layer both target.
Why does GraphRAG indexing cost scale with token recursion rather than document size?
This is the architectural property that breaks the most ingestion-budget assumptions. GraphRAG is a multi-pass LLM job, not a vector index — it reads every chunk twice and writes summaries on top of summaries. Each chunk is fed to the LLM with a joint extraction prompt asking for entities, types, and relationships. The graph is partitioned recursively (Microsoft uses Leiden community detection). Every community at every level gets its own LLM-generated summary. Stack the three layers and the indexing token blowup ratio lands around five to ten times the source token count, by Microsoft’s own community-blog estimate.
The cited reference figure is roughly six to seven dollars to index a 32,000-word book using GPT-4o (per Maarga Systems). That number is widely shared and is not an official Microsoft benchmark — exact cost depends heavily on chunk size, LLM choice, and whether community summaries run. A different team scaled the same pipeline to a real enterprise corpus in early 2024 and paid around $33,000 to index it once (per Graph Praxis). Add documents and you do not just append; recomputing communities and rebuilding portions of the graph is a known pain point. LazyGraphRAG defers summary generation until queries arrive and runs at roughly 0.1% of full GraphRAG’s indexing cost (per Microsoft Research) — the cost cliff turns out to be a structural feature, not a tuning problem.
There is a second failure mode that deserves a name. The hallucinated-edge rate in auto-extracted graph structures is roughly 1.5 to 1.9% (per the Pebblous research blog). On a 100,000-edge graph, that is 1,500 to 1,900 fabricated relationships sitting between nodes the auditor can read in plain language — “Marie Curie, Field, Physics” — and the audit trail will not flag the false edge.
For the depth-vs-cost split between Microsoft GraphRAG and LightRAG, DAN’s market-shift piece covers the architectural fork; for the indexing-cost mechanism, MONA’s GraphRAG cost-cliff explainer traces it.
When Pages Stop Being Strings
The last shift is the one that retires an entire category of engineering reflexes. A developer reads “RAG” and reaches for the same playbook that worked on text: parse the PDF, extract strings, chunk, embed, retrieve. On Monday, someone uploads a quarterly slide deck with embedded charts, and every query against those slides comes back empty — because the OCR layer silently dropped the visual structure your prompt was asking about.
Multimodal RAG is a routing problem across distinct vector geometries, not text RAG with image embeddings bolted on, and the architectural choice determines which failure modes you inherit. The 2026 stack split into two: open-source late-interaction (ColPali, ColQwen, Jina v4 in multi-vector mode) and managed single-vector (Cohere Embed v4). Vision-first retrievers like Colpali treat each PDF page as an image and embed patches with ColBERT-style late interaction, outperforming OCR-then-chunk pipelines on visually complex tasks (per the ColPali Paper). Cohere Embed v4 ships on AWS Bedrock, SageMaker, and Azure AI Foundry and accepts interleaved images and text in one call; pricing runs $0.12 per million text tokens and $0.47 per million image tokens (per the MetaCTO pricing roundup).
The metadata story compounds here. In multimodal stacks, modality is itself a metadata field. “Restrict to figure captions from chapter 3” is a filter that prevents whole classes of cross-modal retrieval pathologies before they reach the generator. So the failure modes from the previous three sections — parser cost, planner-deformed recall, tenant-tag-as-boundary — all reappear, with sharper edges, the moment images enter the index.
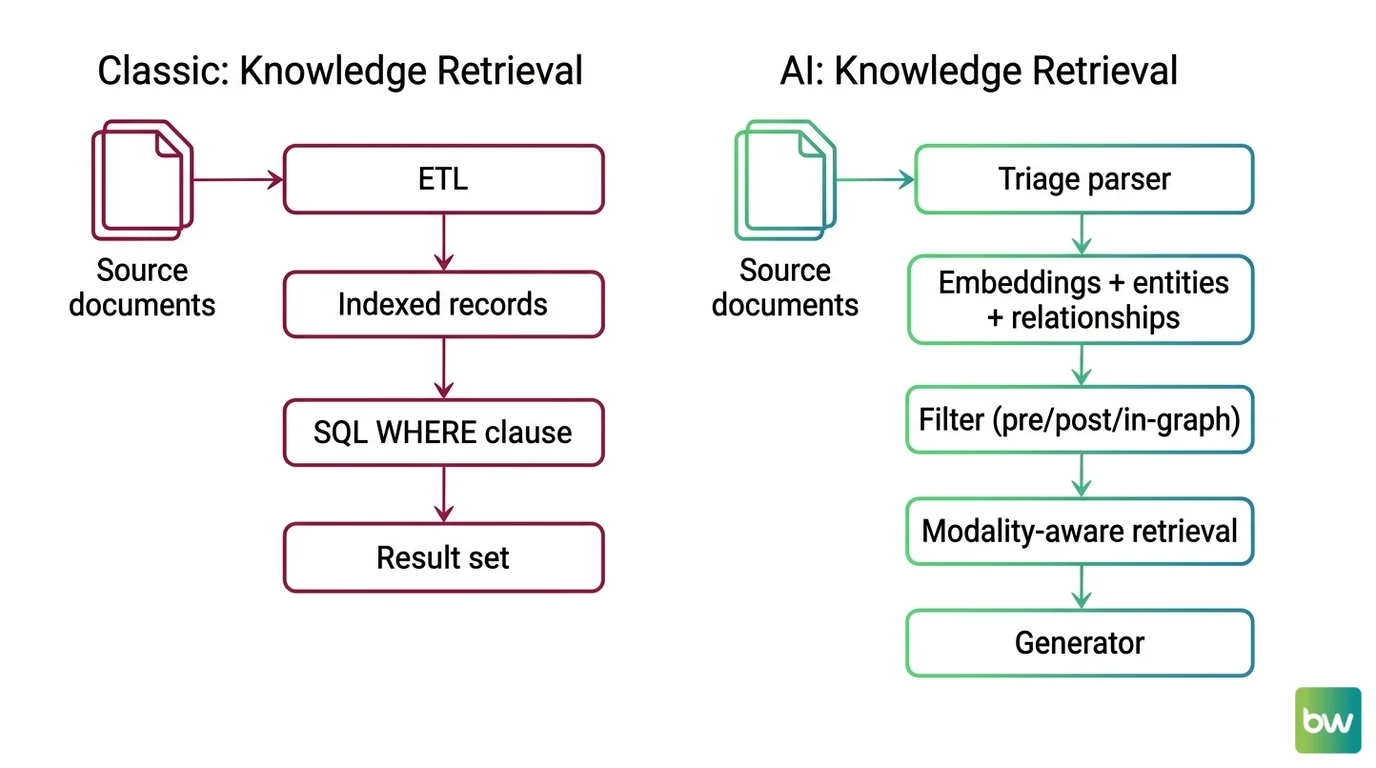
Shift Diagram: Knowledge Retrieval Classic: Source documents → ETL → Indexed records → SQL WHERE clause → Result set AI: Source documents → Triage parser → Embeddings + entities + relationships → Filter (pre/post/in-graph) → Modality-aware retrieval → Generator
For the architectural decisions behind multimodal pipelines, MONA’s multimodal RAG explainer covers the routing logic; for the spec-first build, MAX’s multimodal pipeline guide decomposes the three contracts.
What Transfers and What Stops
| Classical Instinct | Where It Still Helps | Where It Stops Predicting |
|---|---|---|
| ETL pipeline-stage thinking | Decomposing parser, embedder, retriever, generator into owned contracts | Per-page parser cost varies 10× by document complexity, not by row count |
| SQL query-planner intuition | Reasoning about predicates, indexes, and selectivity | The planner picks among three filter strategies that change recall, not just speed |
| Multi-tenant row-level security | Naming tenant as a first-class isolation primitive | A tenant_id JSON tag is advisory; physical partitioning is the boundary |
| Cost grows with data volume | Vector index storage and embedding inference | GraphRAG indexing scales with token recursion, not document count |
| OCR as preprocessing | Clean text-PDF pipelines with simple layouts | Visual documents need vision-first retrievers; OCR becomes a lossy translator |
Knowledge retrieval is four pipelines welded into one and priced as one. The parser, the graph, the filter, and the modality router each have their own planner, their own bill, and their own way of being wrong. Spec each contract before you let an AI tool generate the glue, measure recall and isolation as separate metrics, and remember that the answer your user reads is downstream of decisions four layers deeper than the prompt.
FAQ
Q: Do I really need GraphRAG, or is hybrid vector retrieval enough?
A: Hybrid vector retrieval is enough when your queries are single-hop and your evidence sits in semantically similar passages. GraphRAG earns its indexing bill on multi-hop questions where the answer is a path across entities — counterparty exposure, drug-protein-phenotype chains, regulatory dependencies. Profile your query distribution before you build the graph.
Q: Why is per-tenant metadata filtering not safe even if my filter logic is correct?
A: Because the vectors share an index, an ANN graph, and a query planner. A bug in any helper, a missed ACL update, or an attack like ConfusedPilot can leak a result without raising an exception. OWASP’s 2025 guidance and Pinecone’s own docs recommend per-tenant namespaces or partitions as the physical isolation primitive — the metadata tag is a hint, not a boundary.
Q: Should I keep using OCR for PDFs in 2026, or switch to vision-language parsers?
A: It depends on your corpus. Born-digital text-PDFs with simple layouts run cleanly through OCR-based pipelines like Docling. Scanned, table-heavy, or visually complex documents now belong to sub-1B specialist VLMs — MinerU 2.5, GLM-OCR, PaddleOCR-VL — which beat frontier general-purpose models on OmniDocBench at a fraction of the cost.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors