Inference Optimization for Developers: What Transfers and What Breaks
Table of Contents
Your inference bill tripled in March. Traffic was flat — same model, same endpoint, same daily active users. The one change: a product manager bumped the context window from 4K to 16K tokens so the assistant could remember more conversation history. Three weeks later, finance flagged the spend. Nobody on the team could explain it, because nobody had a cost model where input length changes the price.
That gap — between how you expect serving costs to scale and how Inference costs actually scale — is the first of several places where reliable engineering instincts quietly produce wrong predictions in this part of the stack.
Your Cost Model Breaks at the Token
You budget for APIs by request volume. More users, more requests, proportionally higher cost. That arithmetic works for REST endpoints, database calls, and third-party services — anywhere the cost of a single request is roughly constant regardless of what the payload contains.
LLM inference does not work like that.
Every request runs through two phases. The prefill phase processes your entire input prompt in a single parallel pass — its cost scales with input length. The decode phase generates output tokens one at a time, each conditioned on everything before it — its cost scales with output length and the accumulated context. Your pipeline-stage instinct transfers here. Prefill is the read path — compute-heavy, parallelizable, fast. Decode is the write path — memory-heavy, sequential, and the phase that determines how long your user waits. That framing is useful. It stops helping when you try to predict cost, because the decode phase reads a growing attention history from GPU memory, and that memory cost scales with context length in ways your per-request pricing model cannot capture.
Why does LLM inference break per-request cost budgeting that works for REST APIs and database queries, and what cost model should replace it?
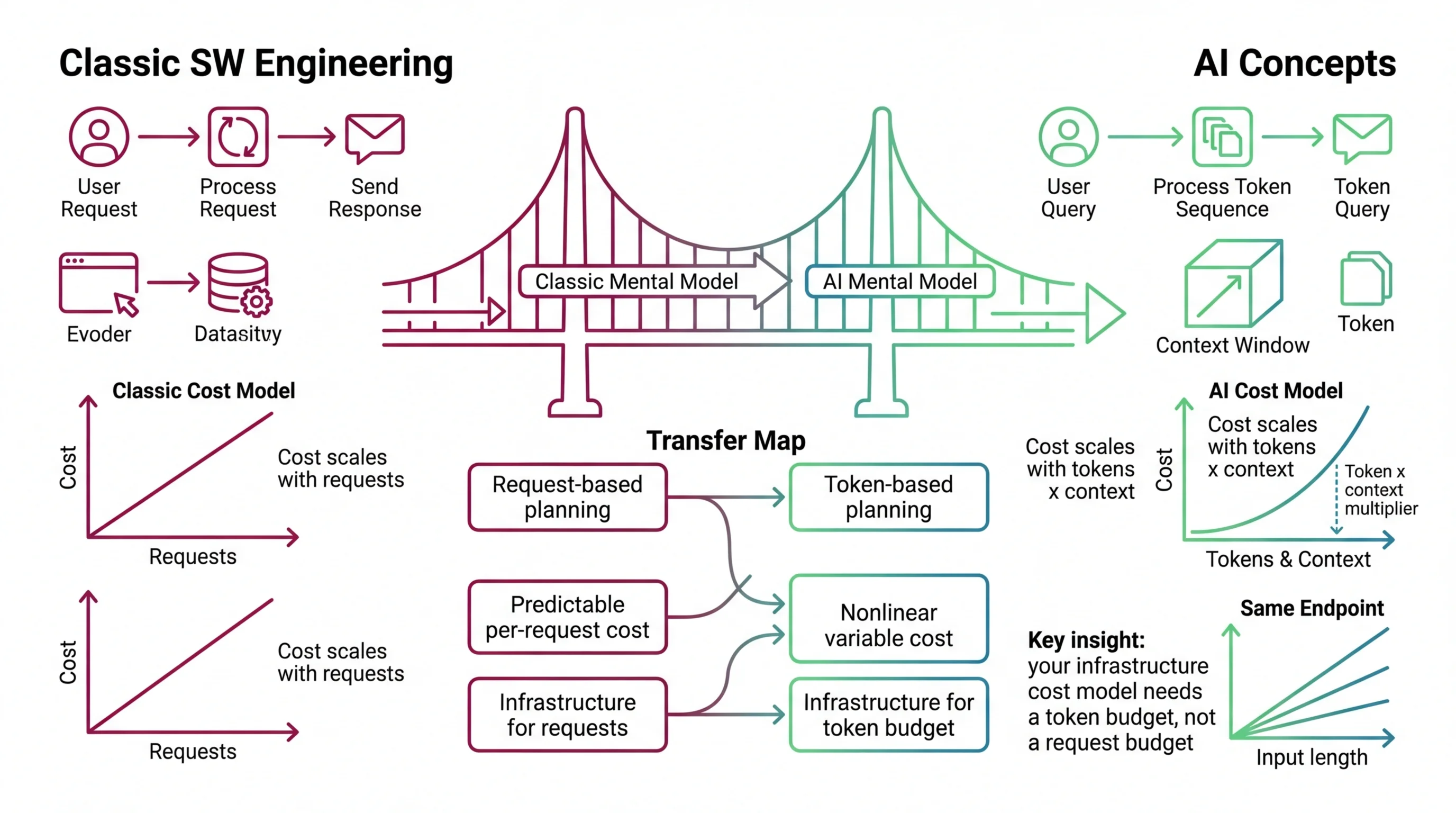
Because the unit of work is the token, not the request. Two calls to the same endpoint can differ in cost by an order of magnitude depending on prompt length and response length. The replacement: budget by token volume with context-length multipliers, not by request count.
| Classic REST API | LLM Inference | |
|---|---|---|
| Cost unit | Request | Token (input + output) |
| Cost scaling | Linear with request count | Nonlinear — context length multiplies memory and compute |
| Payload impact | Negligible | Dominant — same endpoint, 10x cost variance per request |
| Predictability | High | Low without token-level monitoring |
| Budget lever | Rate limiting | Token caps + context window limits |
MONA traces the quadratic memory wall that makes context length the dominant cost driver. If you need the math behind why doubling context more than doubles cost, that is the article.
Cost is the first variable that breaks. The second is the one your monitoring dashboard reports as healthy.
Mental Model Map: Inference Optimization From: Cost scales with request volume — more users, proportionally more spend Shift: The unit of cost is the token, and context length multiplies it nonlinearly To: Cost scales with tokens times context — the same endpoint can cost 10x more per request depending on input length Key insight: Your infrastructure cost model needs a token budget, not a request budget
The Bottleneck Your Profiler Cannot See
You hit a latency wall. You did what works everywhere else — added instances. Latency stayed flat. GPU utilization showed 40%. The profiler said the hardware was barely working. Users said responses were slow.
Why does scaling out with more instances not fix inference latency the way it fixes throughput in stateless services — and what is the actual bottleneck?
In a stateless web service, latency under load is a contention problem. Too many requests, too few threads. Add capacity, latency drops. The assumption underneath: each request’s processing time does not depend on how many other requests exist.
LLM inference breaks that assumption. Single-request latency is memory-bandwidth-bound, not compute-bound. During the decode phase, the GPU spends most of its time fetching model weights and attention history from high-bandwidth memory. The tensor cores sit idle, waiting for data to arrive. Faster arithmetic does not help a system that is waiting on a memory read.
The scheduling side maps onto familiar ground. Continuous Batching works like a connection pool — incoming requests share GPU resources, and finished requests release their slots immediately so waiting requests fill them. That transfers. What does not: the KV cache. Every active request accumulates attention history in GPU memory, and that memory cannot be freed until the request finishes or gets evicted and fully recomputed. A long-running request holds memory in a way a long database connection does not.
MONA’s explainer on KV-cache and PagedAttention covers how memory management borrowed from operating systems solved the fragmentation problem underneath. If you are planning a self-hosted deployment, MAX’s guide to engine selection and parameter tuning separates the spec decisions that turn a demo into a production endpoint.
Memory is the constraint. The next question is how much of it your model actually needs.
Compression That Breaks by Task
You have a 70-billion parameter model that needs 140 GB of GPU memory at full precision. You have 24 GB. Quantization closes the gap — compress the model’s weights from 16-bit to 4-bit, cut memory by 75%, run on hardware you can actually afford.
The chat demo looks indistinguishable from the full-precision version. You ship it. Three months later, a customer reports the math extraction pipeline returns garbage. Chat is fine. Code generation is fine. The one task that requires multi-step reasoning — the one your standard test suite does not exercise — collapsed.
How far does the analogy between lossy compression (JPEG quality levels) and model quantization carry before it starts producing wrong deployment decisions?
The JPEG analogy helps — up to a point. Both techniques discard precision to save space. Both produce results that look nearly identical at moderate compression. At 4-bit precision, models retain roughly 95% of baseline quality on standard benchmarks. For chat, summarization, and classification, that is more than enough.
The analogy breaks where it costs you. JPEG quality degrades uniformly: every pixel gets the same treatment. Quantization degrades selectively. Reasoning tasks fail faster than conversational tasks. Underrepresented languages lose more quality than English. Smaller models collapse more dramatically than larger ones. Below 4-bit precision, models under eight billion parameters cross a cliff — not a gradual decline, but a structural failure that concentrates in exactly the capabilities your evaluation is least likely to cover.
MONA’s analysis of where the accuracy cliff sits is the article to read before you lock a bit-width. For the practical decision — which format, which hardware, which engine — MAX’s quantization deployment guide starts from your GPU and works backward.
You compressed the model. You matched the hardware. One more assumption is about to break.
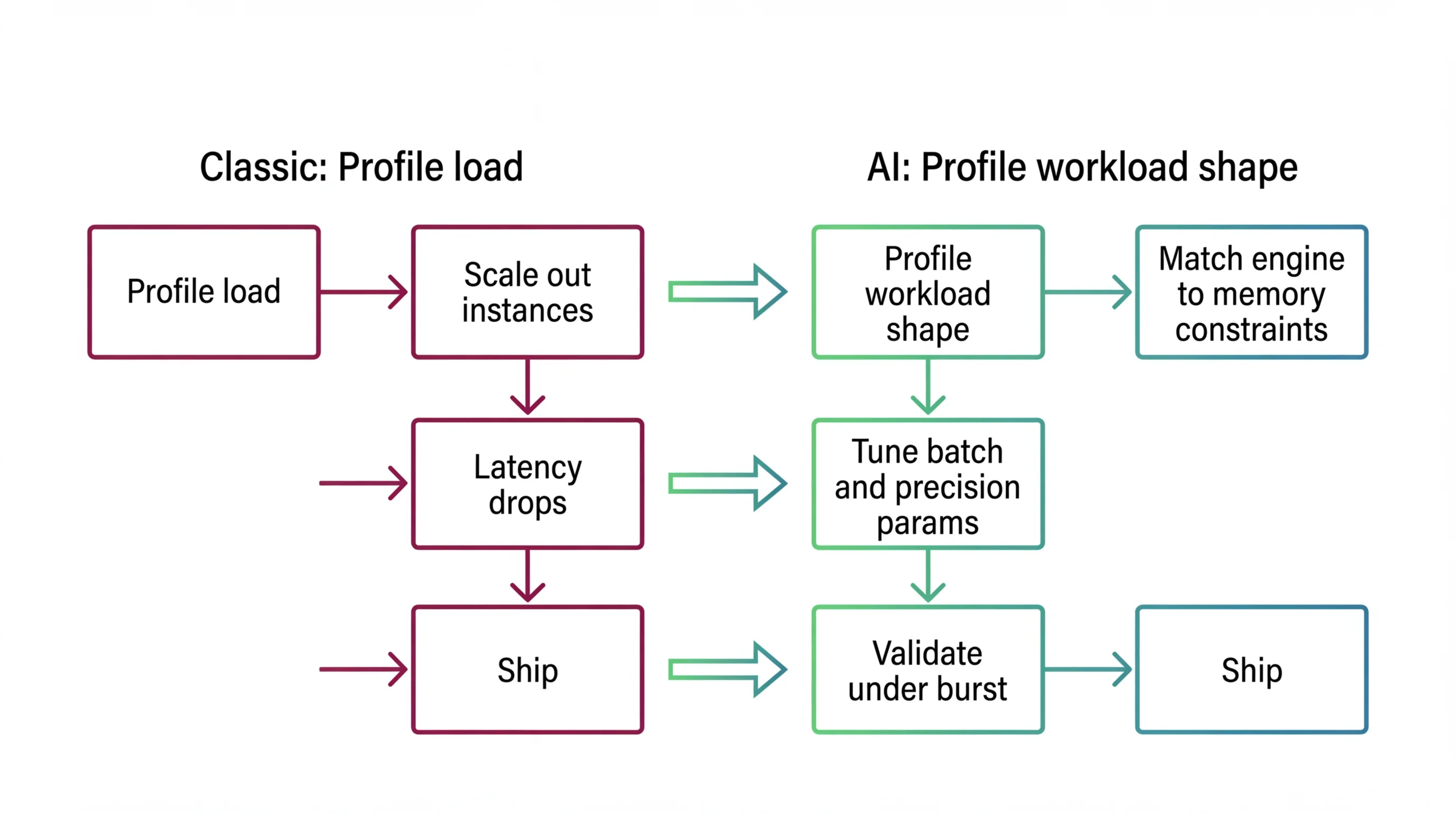
Shift Diagram: Inference Optimization Classic: Profile load → Scale out instances → Latency drops → Ship AI: Profile workload shape → Match engine to memory constraints → Tune batch and precision params → Validate under burst → Ship
Same Input, Different Output
You wrote a regression test. Same prompt, same parameters, expected output. Staging passed. In production, the same prompt returns different text on each run. Not wrong — different. Your caching layer serves stale results because the cache key assumed deterministic responses. Your replay-based debugging fails because yesterday’s trace does not reproduce today’s behavior.
Where does the assumption that identical inputs produce identical outputs fail, and what does that change about caching, testing, and replay-based debugging?
Temperature And Sampling parameters control how the model picks tokens from a distribution. At temperature 0, the model selects the highest-scoring token every time — deterministic in theory. In practice, floating-point arithmetic on parallel hardware introduces bit-level variation. Identical API calls at temperature 0 can return different results.
Above temperature 0, non-determinism is by design. The model samples from a shaped distribution, and the sampling process is deliberately random. That is the feature. But it breaks three things backend developers carry into every system.
Caching breaks first. The same input does not guarantee the same output, so cache keys must operate at the semantic level — user intent, not literal prompt text. Exact-match caching wastes storage and serves stale results.
Testing breaks second. Exact-match assertions always flake. Replace them with distribution checks: run the same prompt ten times and assert results fall within an acceptable range of similarity.
Debugging breaks third. You cannot reproduce a failure without the full sampling state — prompt, parameters, model version, and random seed. Not every provider exposes a seed.
The control surface is splitting too. Proprietary APIs are locking parameters — OpenAI’s reasoning models ship with temperature fixed. Open-source stacks are adding finer controls. A sampling configuration that works on one provider does not transfer without validation. MONA explains why temperature is a divisor, not a creativity dial. MAX’s sampling guide covers how to match parameters to tasks and prove they hold across providers.
Where Optimization Meets Your Job Title
Where in the stack — API gateway, service layer, cost dashboard — does inference optimization become the developer’s responsibility rather than the ML team’s?
If you call a cloud API, the inference engine is someone else’s problem. Yours starts at the integration boundary: context window caps that keep costs predictable, token-level spend monitoring, and sampling parameters that match the output behavior your spec requires.
If your team self-hosts — vLLM, TensorRT-LLM, SGLang — the boundary moves. Engine selection, memory configuration, batch tuning, and burst validation are systems engineering problems. They map onto skills you already have. The failure mode is not complexity. It is carrying assumptions from stateless services into a stateful, memory-bound system.
The diagnostic question is always the same: what is your workload shape? If you cannot name your p95 latency target, your peak concurrent users, and whether your requests share prefixes, you are not ready to pick an engine. MAX’s deployment guide starts from those three questions. If cost is the pain point, DAN’s analysis of the custom silicon market explains how inference pricing is being repriced from the hardware up. MAX’s continuous batching guide covers parameter-by-parameter tuning for each engine.
Inference optimization is a stack of trade-offs — memory, compute, precision, randomness — where the right answer depends on your workload. The instincts that built your current systems still predict most of the behavior. The places they fail are where the money disappears.
FAQ
Q: Why did my LLM inference bill increase when traffic stayed flat? A: LLM inference costs scale with token volume and context length, not request count. Extending the context window or generating longer responses increases per-request cost even when the number of requests holds steady. Monitor token-level spend, not just API call volume.
Q: Why doesn’t adding more GPUs reduce LLM inference latency? A: The decode phase of LLM generation is memory-bandwidth-bound. The GPU waits on memory reads, not arithmetic. Adding compute capacity to a memory-bound system does not reduce single-request latency — it only improves throughput if requests can be batched effectively.
Q: Does INT4 quantization affect LLM output quality? A: At 4-bit precision, models retain roughly 95% of baseline quality on common tasks like chat and summarization. But degradation is selective — reasoning, math, and underrepresented languages lose more quality. Always test on your actual workload before shipping a quantized model.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors