Vector Search for Developers: What Transfers and What Breaks
Table of Contents
Your search feature worked. Then your embedding provider shipped a model update. Same endpoint, same response shape, same dimensions. Integration tests passed. Monitoring stayed green. Users started filing tickets: results felt “off.” Not broken — just less relevant. You spent three days reviewing application code before someone asked the right question: did the vectors change? They had. Every stored vector was now geometrically incompatible with every new query vector. Same column, same shape — useless content. No error anywhere in your stack.
That is the debugging dead end that nobody’s runbook covers. And it is the first sign that Embedding systems follow rules your database instincts did not prepare you for.
Your Index Runs Fine. Your Results Are Wrong.
Vector search entered your stack through one of four doors: semantic search, recommendation feeds, RAG-powered assistants, or deduplication pipelines. In each case, the integration looks familiar. You send text, you get results, you rank and display. The API contract feels like any data service you have operated before.
The difference is underneath. A relational query either matches or it does not. A vector query returns the closest results it can find — and “closest” is an opinion shaped by three things you did not configure: the embedding model, the distance metric, and the index algorithm. When any of those change, results shift. No error. No log entry. Just a different geometric definition of “similar.”
This is not a bug. It is how Similarity Search Algorithms work. The system is designed to return approximate answers — fast, scalable, and slightly wrong. If you have been treating vector search results with the same confidence you give a SQL WHERE clause, that assumption is already costing you. MONA’s explainer on how embeddings encode meaning into vectors covers the geometry underneath. What matters here is the consequence: your search system has opinions you did not write.
The Units Changed, the Instincts Didn’t
Your infrastructure instincts are not wrong. They are mis-calibrated.
Which database capacity-planning instincts still apply when sizing vector search infrastructure?
Memory budgeting, index selection, and query-latency profiling all carry over. The units changed.
In a relational database, you estimate storage from row count, average row size, and replication factor. In a vector index, the formula is the same shape: vector count times dimensions times bytes per dimension, plus algorithm overhead. If you run HNSW — the most common graph-based index — each vector also stores neighbor connections in RAM. The point for capacity planning: at modern embedding dimensions, a billion vectors can demand over a terabyte of RAM before replication. MONA’s analysis of HNSW memory scaling walks through the exact formula and the compression tradeoffs.
Index selection maps too. You already know that choosing between a B-tree and a hash index means trading write speed for read speed, or memory for throughput. Vector Indexing presents the same structural choice with different variables:
| Decision | Relational Database | Vector Index |
|---|---|---|
| Index type | B-tree vs. hash vs. GIN | HNSW vs. IVF-PQ vs. DiskANN |
| Primary tradeoff | Write speed vs. read speed | Recall vs. latency vs. memory |
| Scaling axis | Rows and joins | Dimensions and vector count |
| Tuning knobs | fill factor, work_mem | M, ef_search, nprobe |
| Failure mode | Slow queries | Silently missing results |
How does a database index trading write speed for read speed help frame the recall-vs-latency tradeoff?
The mapping is direct. A B-tree index slows writes to speed reads. An HNSW index spends RAM and build time to speed search. An IVF-PQ index compresses vectors to cut memory — at the cost of recall. The tradeoff structure is identical. The consequence is different: when a B-tree slows down, you get a slow query. When a vector index saves time, you get a result set that is slightly incomplete. That last row in the table — “silently missing results” — is the one that has no equivalent in your current debugging playbook. MAX’s guide to similarity search pipelines breaks down which index type fits which constraint set.
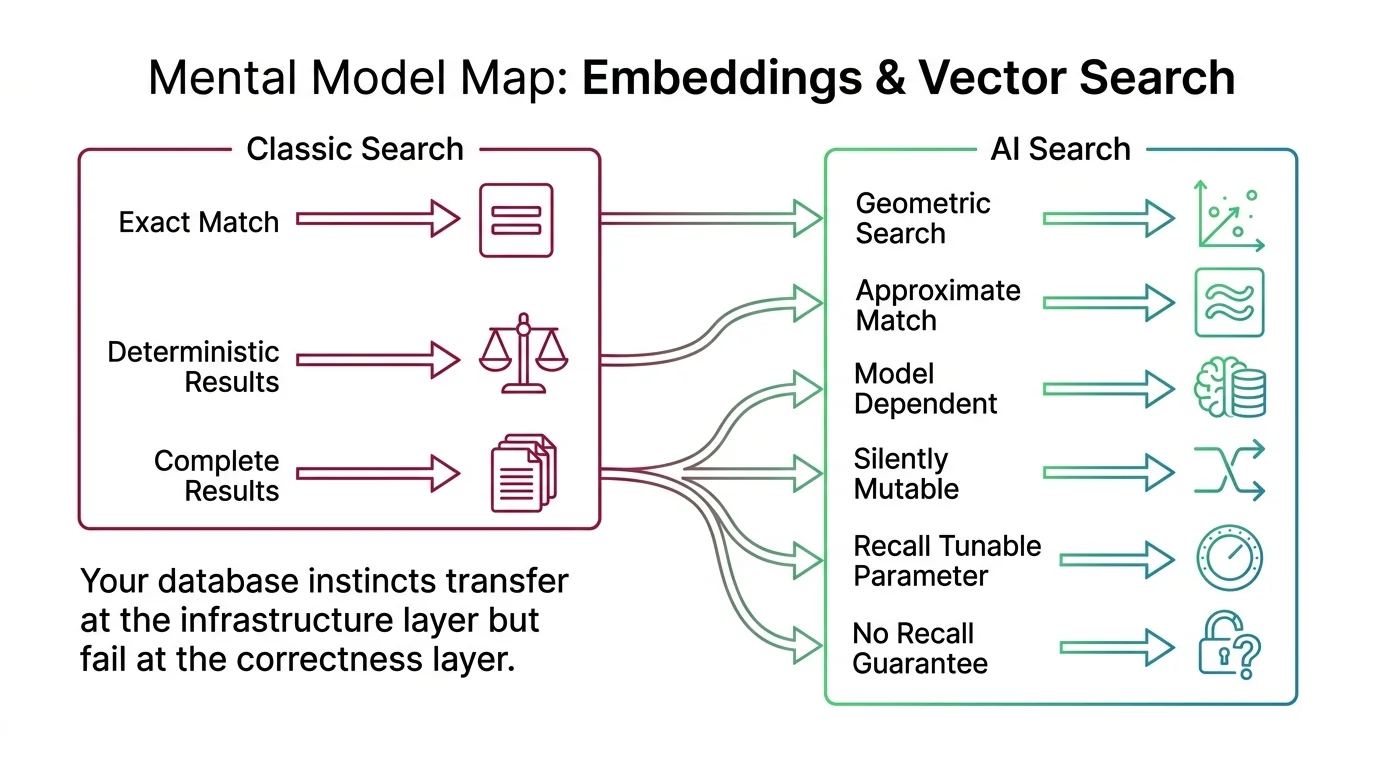
Mental Model Map: Embeddings & Vector Search From: Exact-match search — every query returns deterministic, complete results Shift: Search becomes geometric — results are approximate, model-dependent, and silently mutable To: Approximate-match search — recall is a tunable parameter, not a guarantee Key insight: Your database instincts transfer at the infrastructure layer but fail at the correctness layer
Your Schema Just Became the Model
In a relational database, schema changes are managed events. You write a migration, test it, deploy it. Existing rows survive because the migration transforms them. Data persists across schema versions.
Vector search has no equivalent.
Why does swapping the embedding model version silently invalidate every stored vector, unlike a schema migration that preserves existing rows?
Each embedding model defines its own coordinate system. A vector produced by Model A occupies a position in Model A’s geometry — and that position is meaningless in Model B’s geometry. Same dimensionality, same data types, same distance metric. Different meaning.
This has operational consequences you will not catch with integration tests. If your embedding provider ships a new model version — even one that is “backward compatible” at the API level — and your ingest pipeline starts writing new vectors while old vectors remain in the index, search quality degrades with every document added. The degradation is statistical, not binary. No alert fires. MONA’s explainer on Sentence Transformers and contrastive learning explains why each model’s coordinate system is unique. The practical rule: pin your model version the way you pin your database driver version. Treat model upgrades as full reindexing operations, not rolling updates.
Scores Are Angles, Not Confidence
If you have worked with search relevance scoring, you expect a number between 0 and 1 to mean something like “how good this match is.” In vector search, that assumption creates a specific class of production bug.
Why does treating cosine similarity scores like confidence percentages lead to wrong ranking thresholds in production?
Cosine similarity measures the angle between two vectors. A score of 1.0 means the vectors point in the same direction. A score of 0.0 means they are perpendicular. That is a geometric relationship — not a probability, not a confidence level, not a relevance grade.
The failure shows up when you set threshold filters. A developer hardcodes threshold = 0.85 because it “feels right” — and the system either floods users with irrelevant matches or filters out valid ones. The problem: different embedding models produce different score distributions. A model trained with cosine loss might concentrate semantically related pairs between 0.7 and 0.95. A model trained with dot product loss can produce scores well above 1.0. The number 0.85 means something different in each coordinate system.
It gets worse with mixed metrics. If you switch from cosine similarity to unnormalized dot product without adjusting your pipeline, longer documents and higher-magnitude vectors dominate results — not because they are more relevant, but because they are louder. Euclidean distance introduces yet another scale, where smaller numbers mean closer matches. Three metrics, three different answer orderings for the same query against the same data. The metric is not a preference. It is a geometric commitment your ranking depends on.
The diagnostic: run your actual queries against your actual index and plot the score distribution before setting any threshold. If your embedding model changes, your threshold is invalid until re-evaluated. MONA’s deep dive on dense vs. sparse representations and distance metrics covers why the metric must match the training objective — and what breaks when it does not. For retrieval approaches that preserve finer-grained matching at the token level, MONA’s Multi Vector Retrieval explainer covers the architecture tradeoffs.
Missing Results That No Bug Caused
This is where the database analogy breaks hardest.
What changes when search results are approximate by design?
In a relational database with a properly maintained index, a SELECT query returns every row that matches the predicate. That is a contract. B-trees guarantee completeness.
Approximate nearest neighbor search makes no such guarantee. The algorithms — HNSW, IVF, LSH — are designed to skip most of the dataset to stay fast. The tradeoff is called recall: the fraction of true nearest neighbors the algorithm actually returns. At 95% recall, one in twenty true matches is absent from your result set. No error. No timeout. Just a result set that is silently incomplete.
Which database analogy breaks hardest: the assumption that a vector index guarantees returning every matching result?
That one. And it breaks in a way your existing monitoring will not catch. A relational query that misses a matching row is a bug — you file an issue, you trace the index, you fix it. A vector query that misses a neighbor is working as designed. The recall parameter controls how many neighbors it skips. If you did not set that parameter, the library default set it for you.
This means your test suite needs a different assertion. Instead of “result set contains expected item,” you need “result set contains expected item at least N percent of the time across representative queries.” That is a statistical test, not a deterministic one — and most integration test frameworks are not built for it. The teams that catch recall regressions early are the ones that benchmark recall on their own data before deploying, and re-benchmark after every index configuration change.
MONA’s analysis of the curse of dimensionality and ANN hard limits covers the mathematical wall behind this tradeoff. ALAN’s examination of what gets lost when indexing decides which results you see asks the harder question about where those missing results matter most.
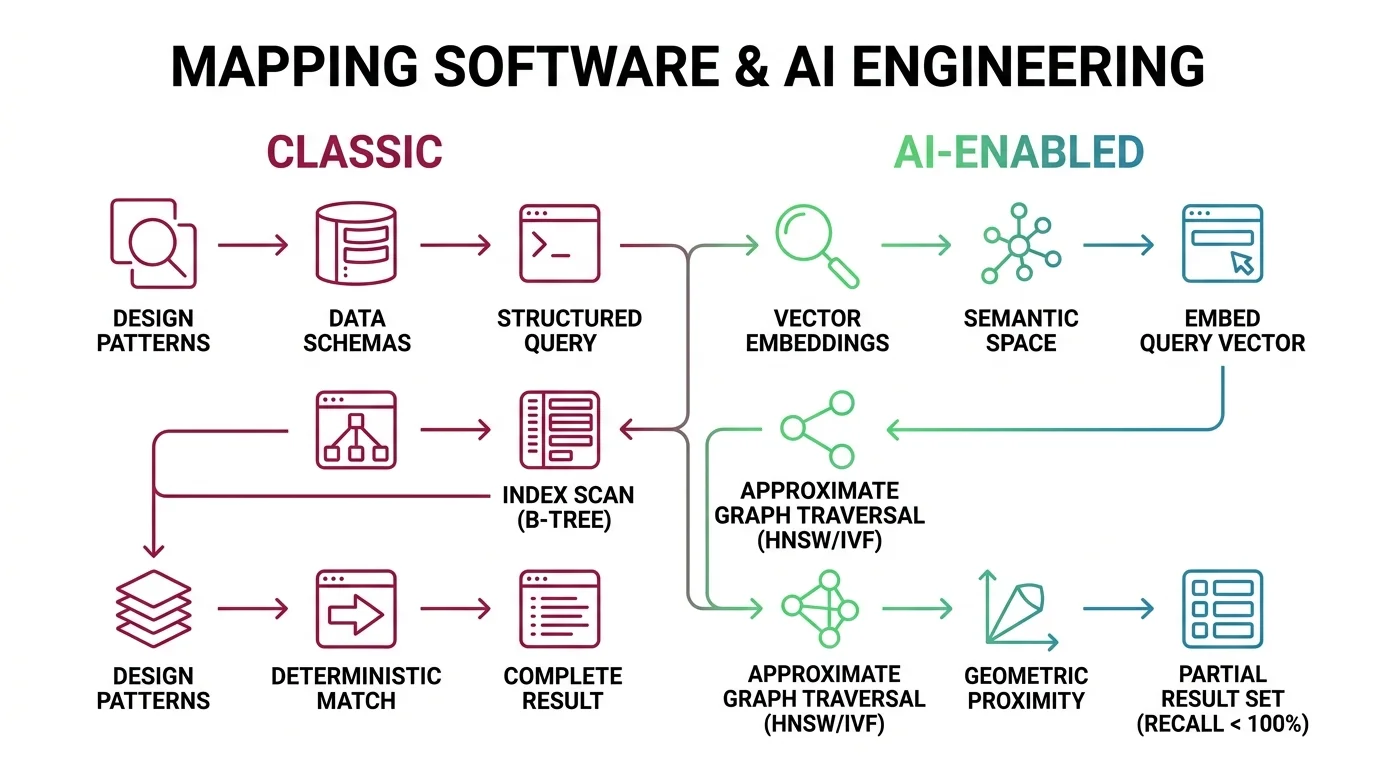
Shift Diagram: Embeddings & Vector Search Classic: Write SQL query → Index scan (B-tree) → Deterministic match → Complete result set AI: Embed query vector → Approximate graph traversal (HNSW/IVF) → Geometric proximity → Partial result set (recall < 100%)
Vector search is not a drop-in replacement for database search. It is a different contract — approximate results, model-dependent geometry, and silent degradation modes your existing monitoring was not built to catch. The database instincts that help you plan capacity and select index types are real and worth keeping. The instincts that expect deterministic completeness, stable schemas, and score thresholds that mean the same thing tomorrow — those will mislead you. Know the boundary between what transfers and what breaks. Build from there.
For the mechanism underneath, start with the embedding explainer. When you are ready to build, MAX’s similarity search pipeline guide is built for spec-first development with AI coding tools.
FAQ
Q: Do I need to understand linear algebra to work with vector search? A: Not to integrate it. You need to understand that results are approximate, model changes invalidate stored vectors, and distance scores are geometric measurements — not confidence levels. The math is behind the API; the consequences show up in your production behavior.
Q: Can I use my existing PostgreSQL database for vector search? A: Yes — pgvector adds vector indexing to PostgreSQL. Your capacity planning instincts apply. Your correctness assumptions do not: pgvector uses approximate indexes like HNSW, so the recall tradeoff still exists. It is not a SELECT with a different column type.
Q: What happens if my embedding provider updates their model? A: New vectors and old vectors become geometrically incompatible. Search quality degrades gradually as new documents enter the index alongside old ones. Pin your model version, monitor score distributions for drift, and treat model updates as full reindexing operations.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors