AI in the Developer Workflow: What Transfers and What Breaks
Table of Contents
A test failed in your pipeline at 2 a.m. An AI classifier looked at it, labeled the failure flaky, and the runner retried it. Second pass, still red. Third pass, green. The merge went through and the dashboard stayed clean. Three weeks later the same defect surfaced in production, and the on-call engineer burned two days finding out the “flaky” test had been catching a real regression the whole time.
Nothing in that story is exotic. The pipeline did exactly what it was configured to do. The gap is that a probabilistic verdict got read like a deterministic one — and that gap is where almost every disappointment with AI in CI/CD Pipelines starts. AI is arriving in your delivery workflow the same way most infrastructure arrives: through a vendor release, a platform upgrade, a CTO directive. You inherited the failure modes. Your classical engineering instincts are about half-right here, and the half that is wrong is the expensive half.
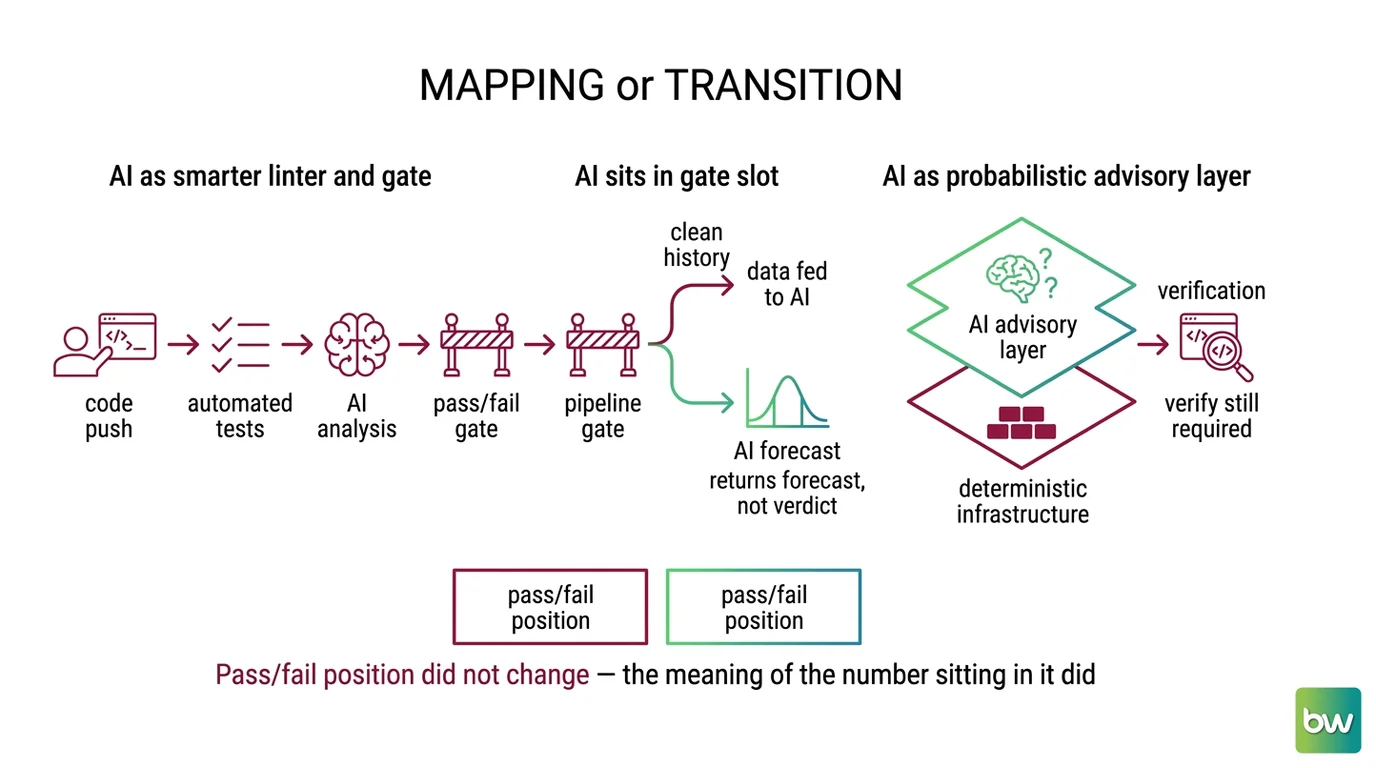
Mental Model Map: AI in software engineering workflows From: AI is a smarter linter and a faster gate bolted onto the pipeline I already run Shift: AI sits in the gate’s slot but returns a forecast, not a verdict, and depends on the clean history I feed it To: AI is a probabilistic advisory layer on top of deterministic infrastructure I still own and still have to verify Key insight: the pass/fail position in your pipeline did not change — the meaning of the number sitting in it did
Why Your Gate Forecasts Instead of Deciding
A classic CI/CD gate is a turnstile. The condition is deterministic: coverage at or above the threshold, zero failing tests, the linter clean. Same input, same answer, every run. You wrote the rule, so you can predict the rule.
AI sits in that same slot and behaves like an air-traffic controller instead. It looks at the history your pipeline was already producing — pass/fail logs, durations, commit metadata — and estimates something a rule cannot: how likely this build is to fail, which tests are worth running first, how risky this deploy is. The position in your workflow is unchanged. The output changed from a verdict to a forecast.
Your old instincts mostly transfer. Pipeline-as-code still matters — agents reason far better against a declarative, version-controlled config than against a pile of hand-clicked UI settings, so your clean pipeline definition is now an asset, not just hygiene. Build steps, contracts, and interfaces between stages still hold. What breaks is the reflex to treat the number in the gate as ground truth. A risk score of 0.8 is not a failing build. It is a bet, calibrated against a baseline, and if you have no baseline the score is decoration. MONA’s explainer on how these pipelines read risk walks the verdict-to-forecast shift in detail.
Reviewing Generated Code Is Still Code Review
Here is the instinct that transfers cleanly: your discipline for reviewing a fast junior teammate’s pull request is the right discipline for reviewing Code LLMs output. Read it. Run the tests. Never merge what you have not read. The model writes plausible code the way a confident junior does — correct in shape, occasionally wrong in a way that compiles.
The volume is what changed, and it changed the math on review. When a large share of new code is machine-generated, your review queue floods and your debt backlog grows from the same tap. A survey of professional developers found a majority merge code they do not fully understand — and that habit predates AI; AI just industrialized the rate. The danger isn’t that the model writes bad code. It’s that it writes more code than any review process was built to absorb.
There is a second trap at the gate. The AI reviewer answers to scope and cost, not to correctness. Point it at every PR with default settings and it will comment on style your linter already owns, drown the real signal, and get muted by the team inside a sprint. That is a specification failure, not a tooling failure: you never told it which job it was doing. For the working setup — separating the review job from the test-selection job, each with its own inputs and cost cap — MAX’s pipeline integration guide has the spec.
Where Deterministic Thinking Breaks
The pipeline mindset you brought from classical software is built on reproducibility. AI features bend three of your assumptions at once, and naming them is the difference between debugging the tool and debugging your own expectations. Two questions developers actually ask cut to the center of it.
Where does deterministic pipeline thinking break with an AI risk score?
A linter flags a rule violation the same way every run. You can read its output as a measurement because the rule is fixed and the result is reproducible. An AI risk score sits in the same report and looks like the same kind of fact — but it is a prediction, and predictions carry a confidence band the dashboard never shows you. Treat the forecast as a verdict and you start making wrong release decisions in both directions: blocking clean deploys because the model panicked at noise it was never told to ignore, and waving through risky ones because the score happened to land low. The fix is a contract. Specify what the score is allowed to gate, what it can only advise on, and what it must never block alone. MAX’s deployment-risk guide treats each AI decision point as its own contract — the decision it makes, the inputs it reads, the actions it must never take.
Why is an AI technical-debt score a correlate, not a measurement?
Because AI For Technical Debt cannot see debt directly. Debt is a consequence — pain you feel later — not a quantity sitting in the source. Every tool that claims to measure it is really measuring a proxy: cyclomatic complexity, code churn, or a model’s read of a diff. That gap is not academic. One vendor reports a false-positive rate near the low single digits across its own corpus; an independent study of the same class of tool found only a fraction of its warnings were true positives. Same category of tool, wildly different numbers, because the proxy and the configuration differ. So the honest question is never “how much debt do I have?” It is “which proxy produced this number, and what does it systematically miss?” MONA’s breakdown of what these tools actually measure is the one to read before you trust a debt dashboard.
| Pipeline element | Classic behavior | AI behavior | What this changes for you |
|---|---|---|---|
| Quality gate | Deterministic pass/fail on a fixed rule | Probabilistic risk forecast | Read it as advice to calibrate, not a verdict to obey |
| Linter / static check | Same flags every run | Score that shifts with history and config | Interrogate the proxy before you act on the number |
| Flaky-test handling | You quarantine by hand | Classifier labels and auto-retries | A real regression can be hidden as “flaky” |
| Test ordering | Static suite, runs in full | History-driven selection by predicted failure | Speedup is real, but only on clean version-controlled data |
The flaky-test row is the one that bites hardest. A real regression and a genuinely flaky test look identical on a single run — both are “a test that failed.” The classifier produces false positives (a real bug mislabeled flaky) and false negatives (the intermittent pattern it was built to catch, missed). Treat an AI flaky verdict as advisory, never authoritative. MONA’s piece on the technical limits is blunt about why messy CI history turns an AI speedup into confidently wrong answers.
The Green Number Means Less Than You Think
You spent years training one reflex: green build, ship it. The build-status badge earned that trust because it measured something real and reproducible. Carry the reflex onto an AI gate and it betrays you, because a green debt score or a passing AI check means “predicted maintainability risk is low” — not “this code is correct.”
This is where the most expensive habit forms. The number turns green and the team stops looking. A randomized study of experienced developers using AI tooling found they were measurably slower with it, yet finished convinced they had been faster — the confidence and the reality pointed opposite directions. That is automation bias, and a green number is its perfect trigger. The wasted debugging that follows is invisible until production surfaces it, because nobody re-opened a verdict that looked settled.
The transfer instinct still helps: you already know a passing build is necessary, not sufficient. Keep that exact skepticism and aim it one layer higher. ALAN’s argument on false confidence and the accountability piece on auto-merged fixes both circle the same hole: when the system did it, someone on your team still owns the incident.
What Still Transfers — and the One Thing That Doesn’t
Your strongest instinct survives intact. You already decompose a build step or a service contract into the decision it makes, the inputs it reads, and the actions it must never take. Apply that exact move to any AI pipeline feature and it stops being a mystery line on the invoice. The release-gate AI, the test selector, the debt scorer — each is a contract you can spec, measure, and prove before it ever gates a real release.
The one assumption that does not transfer: that the tool works on whatever data you happen to have. AI test selection and log triage only earn their speedup on top of a clean, deterministic, version-controlled history. Feed them flaky tests, hard-coded config, and missing history and auto-fix becomes auto-confusion. The discipline AI demands is higher than the discipline classical CI/CD demanded, not lower.
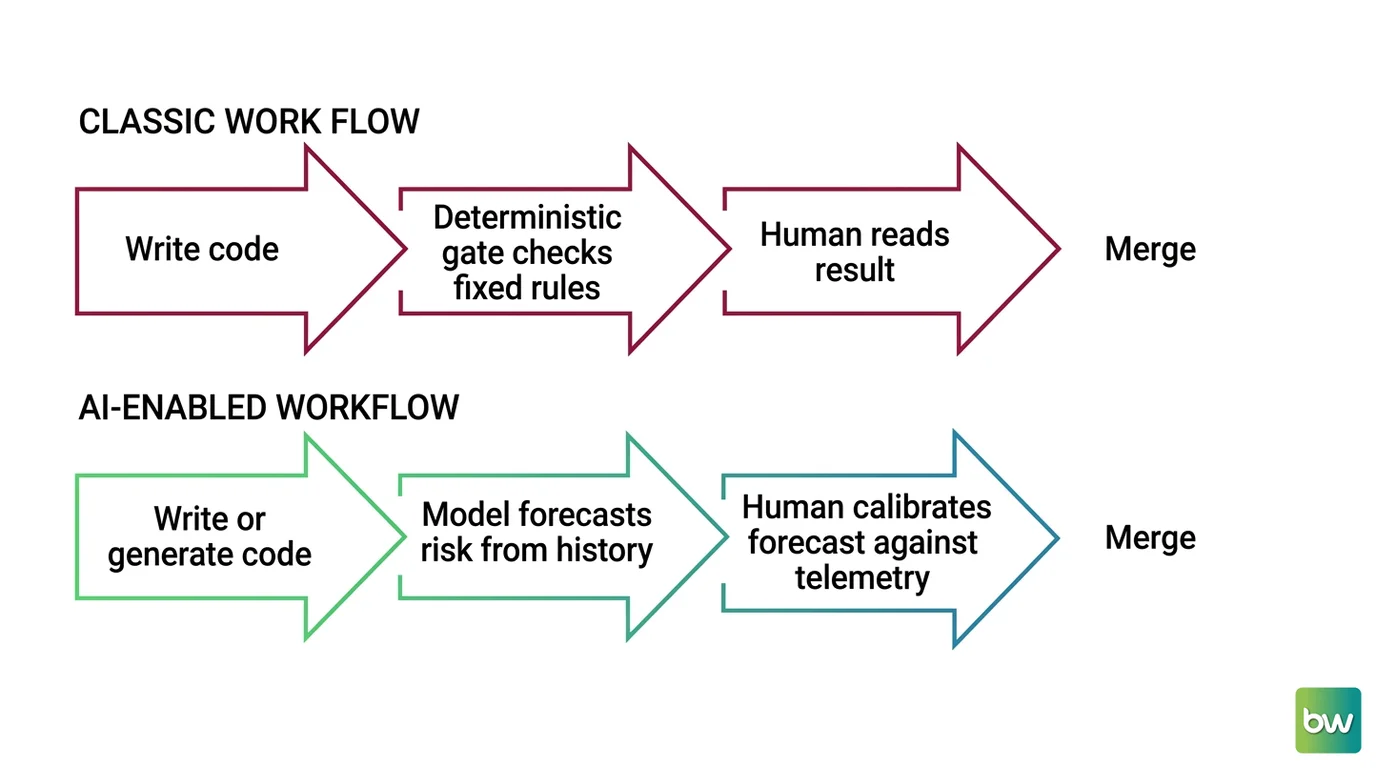
Shift Diagram: AI in the delivery workflow Classic: write code → deterministic gate checks fixed rules → human reads result → merge AI: write or generate code → model forecasts risk from history → human calibrates forecast against telemetry → merge
One more thing changes on your desk if you work somewhere that cannot ship source to a third-party API — and banking, insurance, and health systems usually cannot. You are no longer stuck choosing between a frontier API and nothing. Open-weight code models under permissive licenses now run on your own hardware, good enough for the routine bulk of generation, with the hard cases routed to a stronger model. DAN’s comparison of dedicated code models versus the frontier lays out the routing decision, and MAX’s self-hosting guide covers bringing one up in dependency order.
The mental model that survives all of this: AI did not replace your pipeline’s logic, it stacked a forecasting layer on top of it and made your data quality the load-bearing wall. Spec each AI decision as a contract, calibrate every score against your own telemetry, and keep reading the code the way you would read a fast junior’s PR.
FAQ
Q: Should I trust an AI flaky-test classifier to auto-retry failures? A: Treat its verdict as advisory, not authoritative. A real regression and a flaky test look identical on a single run, so a classifier can hide a genuine bug by labeling it flaky and retrying until it passes. Verify before you quarantine.
Q: Does an AI technical-debt score measure how much debt I actually have? A: No. It measures a proxy — complexity, churn, or a model’s read of a diff — because debt is a consequence you feel later, not a quantity in the source. Ask which proxy produced the number and what it systematically misses.
Q: Can I run a code LLM without sending my source code to a third-party API? A: Yes. Open-weight code models under permissive licenses run on your own hardware, which matters in banking, insurance, and health. Route routine generation to the local model and reserve the hard, multi-file problems for a stronger one.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors