An Image API Is a Contract Whose Output You Can't Diff
QA opened a ticket on a Tuesday: the product thumbnails looked off. Not broken — off. Slightly warmer skin tones, tighter crops, a font weight that used to render clean and now smeared. You checked the obvious things first. No deploy that week. No config change. No library bump. The image service you wrapped three months ago returns a 200 on every call, same JSON body in, same URL out. The endpoint is identical. The output is not — and there is no line in your logs that says why.
You did not go looking for a nondeterministic dependency. It arrived through an HTTP client you already understood.
When you wrap an image-generation or editing model behind an internal service, you inherit a contract whose output you cannot diff — same prompt does not mean same picture, the version you depend on belongs to the vendor, and the price meters per workload, not per call. The crack is in one assumption your classical model treats as free: that a request-response interface has a definable notion of “same output.” Here it does not. This is not a guide to training image models. It is a guide to the assumptions you inherit the moment you call one.
The Contract You Can’t Diff
The response has a shape you can validate and a value you cannot compare. That is the whole problem in one sentence.
Your API-client instincts still apply, and they apply cleanly. The request is JSON. The response is a URL or a base64 blob. Status codes, retries, timeouts, backoff, idempotency keys on the write path — every gateway habit you built over a decade transfers without a footnote. The trouble starts the moment you reach for the habit you reach for next: pin an input, assert on the output, catch the regression in CI.
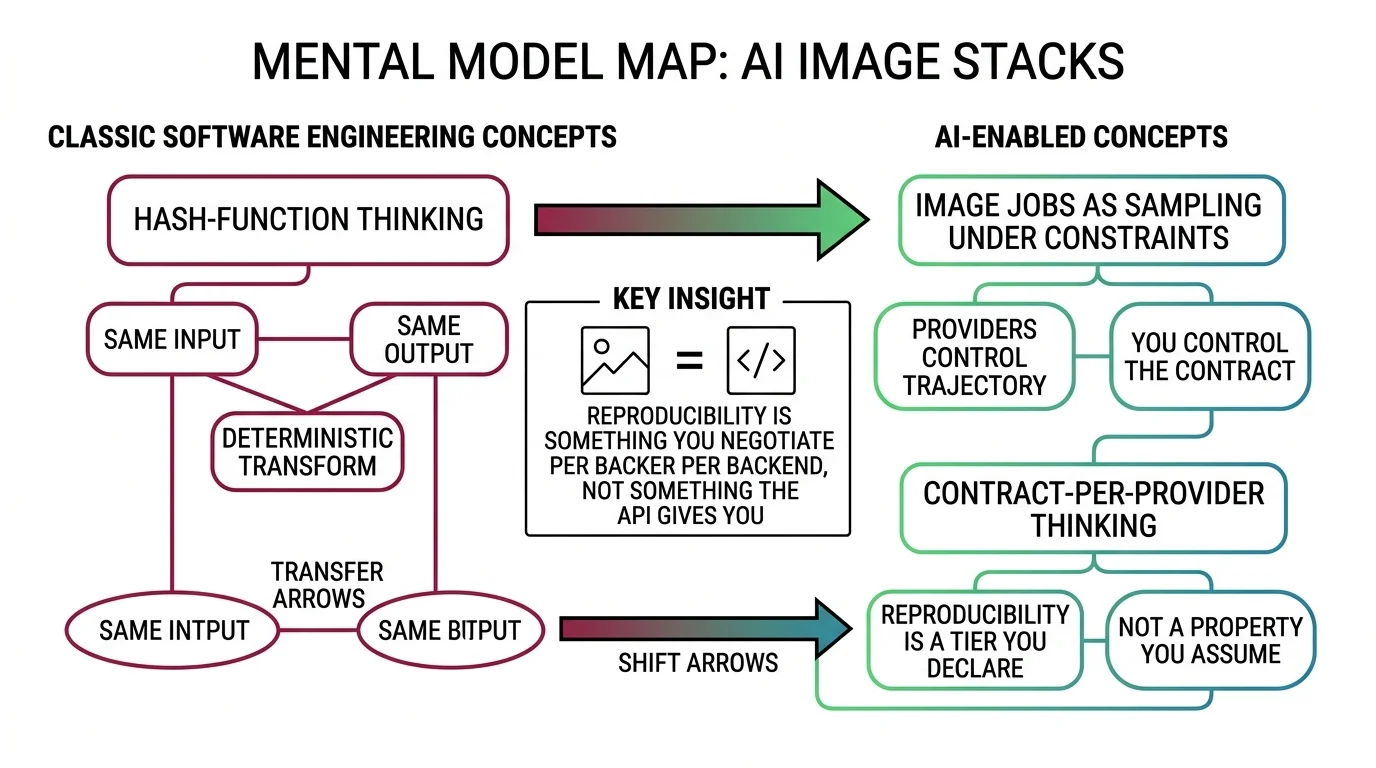
There is no byte-equal output to assert against. An image endpoint is not running a hash function over your prompt; it is running an iterative sampler across a high-dimensional field, and the trajectory through that field depends on a stack of things you never pinned — model weights, scheduler implementation, the GPU’s random number generator, the output resolution, and, on a managed API, an opaque server-side configuration. Hugging Face’s Diffusers documentation states it flatly: you can try to limit randomness, but identical results are not guaranteed even with the same seed across releases, GPUs, and CUDA versions. Even seeded, even pinned, the picture drifts. MONA’s breakdown of why seed reproducibility breaks across model versions walks the exact surfaces that move underneath you.
So you assert on a different thing. Not the bytes — the properties. Perceptual similarity against a reference, embedding distance under a threshold, task-specific checks (“is there one product, centered, on white”). The assertion suite stops being an equality test and becomes a tolerance band. MAX’s walkthrough of a reproducible prompt-testing pipeline with Promptfoo and seed planes is built entirely around this shift, because the naive version — commit a golden PNG, diff on every run — flags failures on outputs that are perfectly correct.
Mental Model Map: Image API Output From: Hash-function thinking — same request, same bytes, diffable in CI Shift: The endpoint samples under constraints the vendor controls; output equality is undefined To: Contract-per-provider thinking — reproducibility is a tolerance tier you declare, not a guarantee you receive Key insight: You test the properties of the output, never the output itself.
In practice, this means your CI gate for anything image-generating needs a similarity metric and a threshold you can defend in a review — not a snapshot file. A red build should mean “the output left the tolerance band,” never “the bytes changed.”
The Prompt Is Your Only Real Interface
The one part of this system you fully author is a string. That string is your interface contract, and right now it is probably a literal buried in a service method, untyped, unschematized, and not versioned the way your REST or gRPC contracts are.
Treat it the way you treat any interface. The transfer here is direct: check the prompt spec into source control as an artifact, pin the provider and model version alongside it, and separate the spec from the prompt. The spec is what the image must be — one product, centered, neutral background, brand palette. The prompt is how a specific model wants to hear that. Those are the same distinction as an interface and its implementation, and keeping them apart is what lets you reason about a model switch at all. Prompt Engineering For Image Generation reads like a soft skill until you have to diff two versions of a prompt in a pull request and realize you never gave it a schema.
Here is where the classical model predicts wrong. The prompt is not a provider-neutral config value you can port. Negative prompts, attention-weight syntax, and seed handling parse one way in Diffusers, another in a web UI, another in Midjourney — and not at all on FLUX.2 or GPT Image, which reject the weighting grammar entirely. Move a prompt from one model to another and you have not swapped an implementation behind a stable interface. You have introduced a translation bug that no type checker will catch. MAX’s field guide to model-specific prompt grammar across Midjourney, SD, Flux, and GPT Image exists because “it worked on the old model” is the most expensive assumption in this cluster, and MONA’s explainer on how diffusion models actually read your text shows why the grammars diverge at the encoder.
The production consequence is small and constant: a prompt is a per-model artifact, so a model migration is a rewrite-and-revalidate task, not a config flip. Budget it as one.
Who Owns the Version Number
The version you depend on is not yours to freeze. That single fact rewrites your change-management assumptions for this entire cluster.
In classical integration, you pin a dependency version and it stays pinned until you choose to move. The pin is a decision you own. With a hosted image model, the vendor owns it. A model-version bump can silently change seed semantics and output behavior behind an endpoint whose URL, request schema, and status codes never moved — a breaking change with no changelog you control. OpenAI documents its seed parameter as best-effort and points you at a system_fingerprint value to detect when the backend may have drifted; that fingerprint is the closest thing you get to a version pin, and it is a signal to watch, not a lock to set.
The providers do not even agree on what “same job” means. Midjourney documents a seeded rerun as “99% identical,” not pixel-identical. FLUX.2 exposes a seed. GPT Image does not expose one at all, and Nano Banana Pro asks you to stabilize output with reference images instead of a seed, because it has no seed parameter to offer. The encoders shift under you too — SD 3.5 bolted on a large T5-XXL text encoder, and FLUX.2 swapped its text stack for a Mistral-class vision-language encoder, changing how the same words land. DAN’s report on the four-way image-editing arena shows how fast the leaders reorder, and MONA’s account of the hard engineering limits of diffusion models explains why even a “better” model can regress a workflow you tuned against the old one.
In practice, this means you need a drift detector, not just a version constant: a small canary set of prompts run on a schedule, compared against a stored baseline, alerting when the vendor moves the model underneath you.
The Bill Is Per-Workload, Not Per-Endpoint
The invoice is usually the first place the cost model announces it was wrong. You budgeted a flat per-request fee, the way you would for any API hit, and the number that came back does not fit that shape.
Your metered-API instincts transfer — count calls, set budgets, alert on anomalies. What breaks is the unit. The price is per-workload, not per-endpoint, and the workload variables are the ones your load test probably left out. Generation on FLUX.2 [pro] meters by output area, roughly three cents a megapixel, so a 4-megapixel render costs multiples of a small preview through the identical endpoint. AI Image Editing and Image Upscaling scale harder: sampling steps, tile count, and reference images each multiply the bill. On fal.ai’s FLUX.2 trainer, a run meters per step — a thousand steps lands near eight dollars — and adding a single reference image to an edit trainer pushes a comparable job several times higher. Fine-tuning a brand with LoRA for Image Generation lets twenty photos and fifteen minutes on a consumer GPU produce a working Diffusion Models adapter, but that cheap-looking training run is a per-step meter too. Validate every one of these numbers against your own account and region before you commit a budget — vendor pricing moves as fast as the models.
MAX’s guide to upscaling with Real-ESRGAN, Magnific, and tiled ComfyUI pipelines is explicit that tiling turns one logical “upscale” into many inferences, and the production background-removal pipeline built on BRIA, Photoroom, and rembg shows how AI Background Removal splits into a self-hosted cost curve and a per-call API curve that price the same cutout very differently.
In practice, this means your cost model needs the workload dimensions — resolution, steps, tiles, references — as first-class inputs, and your load test needs to vary them, or it will lie to you at exactly the scale that matters.
Route the Model, Don’t Marry It
The instinct that saves you here is one you already have: put a swappable backend behind one interface. “Which model produces this output” is a routing decision, not an architecture commitment.
This is the adapter pattern you use for storage engines and payment providers, applied to the fact that no single image model wins every workload for long. MAX’s image-editing pipeline built around Flux Kontext, Qwen Image Edit, and GPT Image treats the model as a routed backend on purpose: add a contract, route a slice of traffic to it, measure, and the rest of the system does not move. When one editor needs a commercial license and another needs raw iteration speed, MAX’s decision guide for Firefly versus Flux Kontext versus GPT Image is a routing table, not a loyalty pledge.
The caveat is the one this whole article keeps circling. Routing gives you a stable interface; it does not give you a stable backend. The route can be clean while the thing behind it drifts a version, reprices a workload, or drops out of the leaderboard’s top cluster between invoices. The background-removal market already forked into open-weight self-hosting and commercial workflow APIs — same output, two different contracts to reason about. Route so you can move; monitor so you know when to.
Shift Diagram: Integrating an Image Model Classic: Pin dependency version → snapshot-test output → deploy on green AI: Declare reproducibility tier → assert on output properties → route per workload, monitor for drift
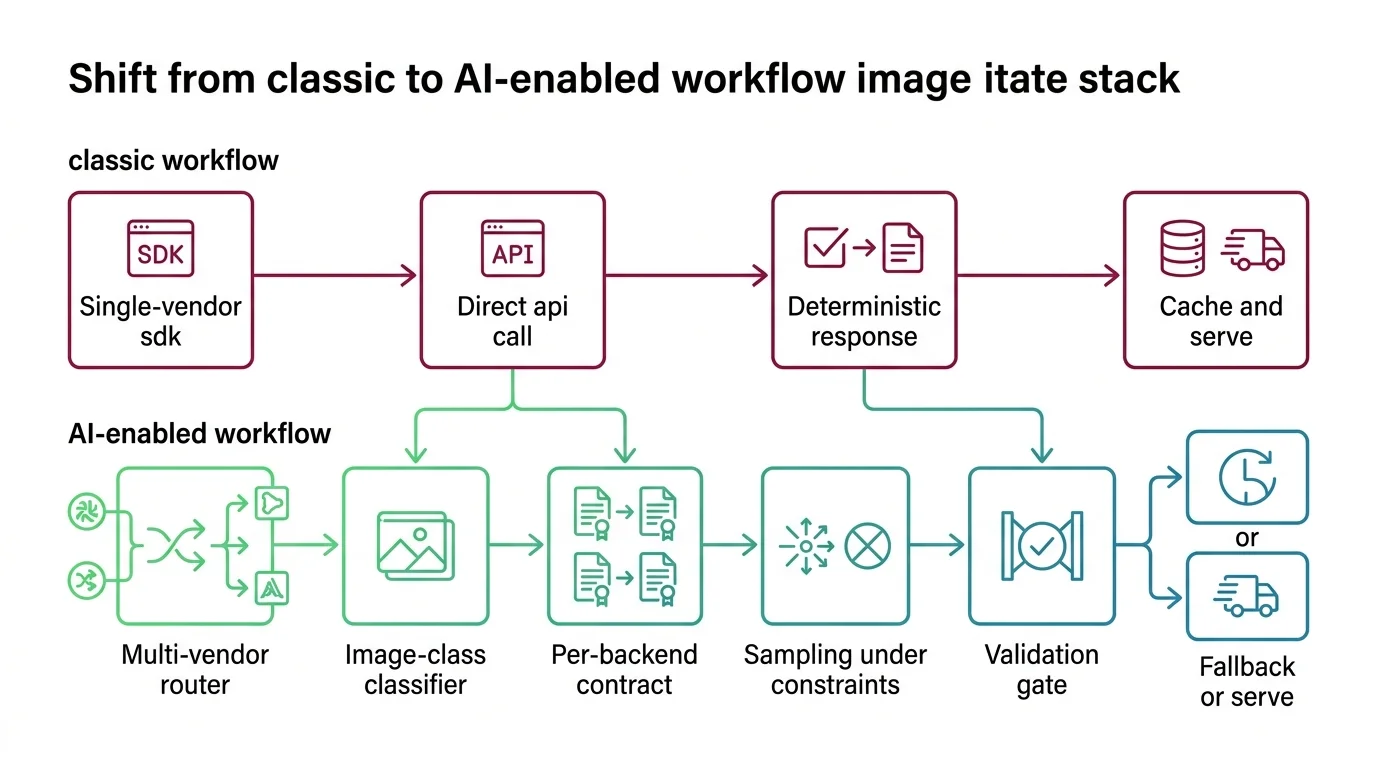
The comparison below is the whole transfer-and-break map on one screen — the part worth screenshotting for the review where someone proposes wiring an image model straight into your service.
| Your classical instinct | Still transfers | Breaks here |
|---|---|---|
| Pin the dependency version | Pin provider + model version in config, watch the fingerprint | You don’t own the version; the vendor bumps it behind an unchanged endpoint |
| Snapshot / regression tests | Assert on the response contract and output properties | No byte-equal artifact exists; pixel diffs fail on correct runs |
| Interface vs implementation | Keep the spec separate from the prompt | The prompt isn’t portable — syntax parses differently, or not at all, per model |
| Flat per-request pricing | Meter and budget the calls | Cost scales with resolution, steps, tiles, references — per-workload |
| Adapter / router pattern | Route “which model” as config | A stable route does not make the backend behind it stable |
Before You Wrap an Image Model
Run these against your own stack before the integration ships. They are not FAQ answers — they are the questions your design review should force you to answer out loud. For the full prerequisite map and common questions, see the topic hub.
| Runtime question | Why it matters |
|---|---|
| What does “still correct” mean for this output, in a metric? | Without a similarity threshold, your CI has nothing to assert and no way to fail a regression |
| Where is the prompt versioned, and is the model version pinned beside it? | An unversioned prompt is an unversioned interface; a floating model version is a silent breaking change |
| How would you detect a vendor-side model update? | If the answer is “a user complaint,” you have no drift detection, and the invoice or the ticket finds it first |
| Do your cost estimate and load test vary resolution, steps, and references? | A flat per-call estimate under-budgets exactly the high-resolution, multi-step workloads that cost the most |
| Can you route to a second model without touching callers? | If a reprice or a quality regression forces a switch, the blast radius should be one adapter, not the service |
Update the model like this: an image endpoint is not a function you call, it is a contract you rent — the output has no diff, the version has an owner who isn’t you, and the price meters per workload. Your next move is small and concrete: before you wrap the next model, write down the similarity metric that defines “correct” and the check that detects a vendor-side change. Everything else in this cluster builds on those two lines.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors