AI Coding Assistants for Developers: What Transfers, What Breaks
Table of Contents
The pull request landed at 2:14 on a Tuesday. Forty-two files touched, all green in CI, three approving comments from a review bot that had read the diff in under a minute. By Wednesday afternoon, the on-call channel was on fire — a refactor had moved a signal handler that registered at module load into a lazily imported module the scheduler never touched. The billing job stopped firing. No exception. No regression in the test suite. The AI-generated tests around the affected class were at ninety-one percent line coverage and zero mutation score.
Three different AI coding tools touched that pull request — completion in the editor, an agentic refactor across files, a test generator filling in the suite. None of them threw. None of them lied either, exactly. They behaved exactly as advertised. The gap was between what the engineer thought they were buying and what these systems actually do.
A Layered System Hiding Inside One Product
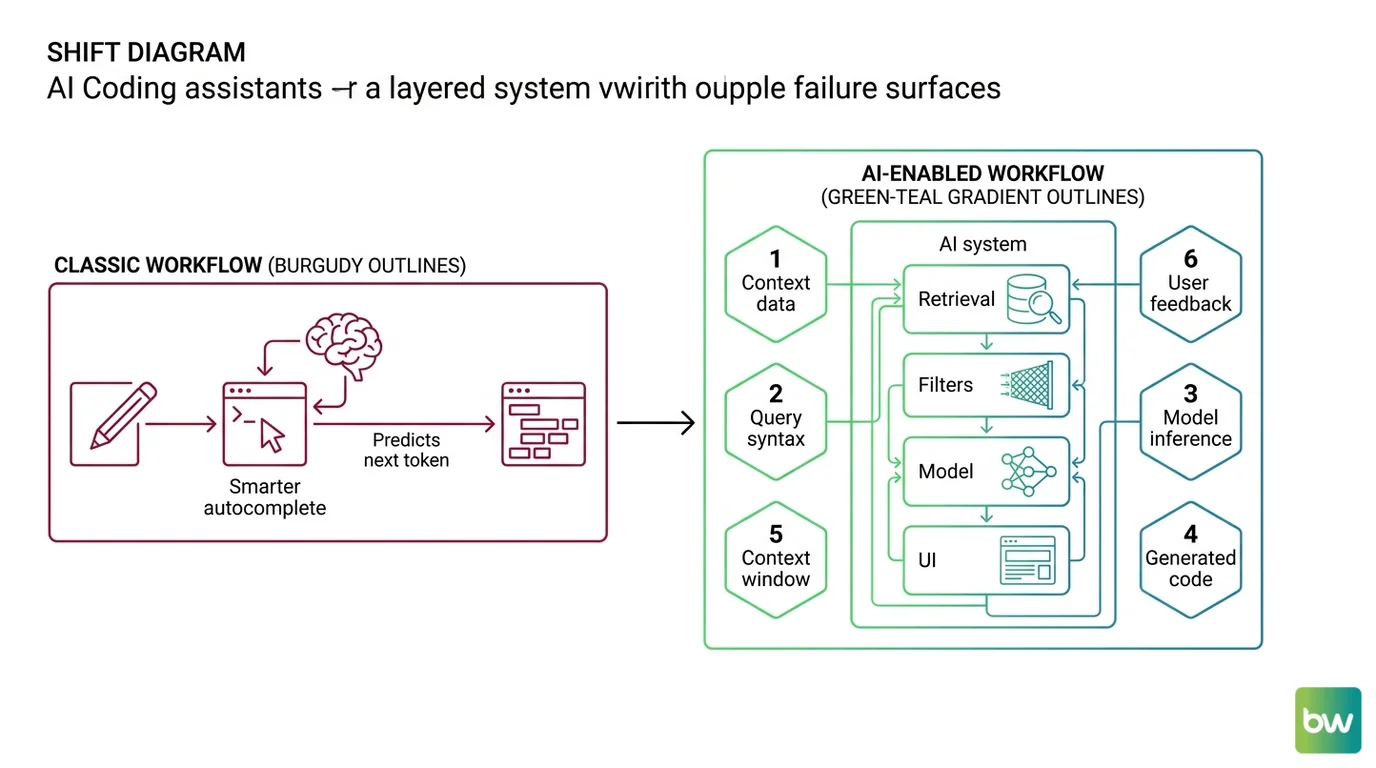
You did not buy “AI coding assistants.” You bought, at most, two product names. But six things landed in your engineering loop, each one a different layered system: a model, a retrieval layer, a static analysis pass, a set of filters, a UI surface. The vendor’s marketing collapses them into one button. The failure modes do not collapse.
The six surfaces, named the way your incidents will name them:
| Surface | What it does | Where the SW instinct breaks |
|---|---|---|
| Inline completion | Predicts the next tokens as you type | Long-file context dilutes — a 1M-token model behaves like a 4K-token one per keystroke |
| PR review | Comments on diffs against the repo | Static RAG cannot follow imports across linked repositories |
| Test generation | Writes unit tests against existing code | Coverage rises; mutation score does not |
| Debugging | Reads stack traces, proposes fixes | The model sees tokens, you see runtime state |
| Documentation | Generates docstrings, API refs, architecture docs | Hallucinated APIs recur on the same prompt |
| Refactoring | Restructures code across files | Behavior preservation is not the optimization target |
Each row is a place where a classical instinct still helps and a separate place where it stops predicting. Read the row you do not believe yet first.
Mental Model Map: AI Coding Assistants for Developers From: AI coding tools are smarter autocomplete — one model, predicting the next token. Shift: Each one is a layered system — model + retrieval + filters + UI — landing on a different surface of your workflow. To: Reliability is a coverage problem across six surfaces, each with its own failure mode. Key insight: The vendor sells you one product. The on-call rotation inherits six.
Your Code-Review Instincts Still Hold
Most of your senior-engineer reflexes still work — they just point at different layers now. Skepticism about a confident-sounding patch. Reading the diff with the dependency graph in your head. Asking what the change costs at the contract boundary, not at the line it touches. These instincts transfer almost verbatim into AI Code Review workflows. The bot can flag a missing null check; it cannot tell you whether the function should have been deleted instead.
The transfer that holds: a code change is a contract change first, an implementation second. When CodeRabbit, Qodo, or Greptile post fifteen comments on a diff, your job is the same as it was with a human reviewer — find the comment about the contract and ignore the comments about style. MAX’s review integration guide walks the decomposition: surface, spec, sequence, validation. The same four-step pattern you would apply to onboarding a junior reviewer.
What breaks: the assumption that the bot saw what you saw. A pre-indexed retrieval layer cannot follow an import into a sibling repository. A diff-only reviewer cannot reason about the change against the runtime config the change interacts with. If your team has split a system across two repositories and the AI reviewer is configured against one of them, the comments on the second-order effects will not appear — not because the bot missed them, but because the bot never had eyes there.
The Monday-morning diagnostic: take last quarter’s worst incident. Could the AI reviewer, configured exactly as you have it today, have seen the file that actually caused the cascade? If the answer is “no, it lives in another repo,” your review surface has a known blind spot you have not specified.
Where Determinism Quietly Stops Predicting
Classical software has one property your dashboards quietly depend on: the same input produces the same output. AI coding assistants do not have that property, and the places this matters are not the places you expect.
Why does the same prompt return different completions across runs?
Because the AI Code Completion engine samples from a probability distribution at non-zero temperature, and the prompt assembly itself is non-deterministic — the retrieval layer pulls different surrounding context depending on cache state, file recency, and which IDE features fired in the last second. The completion that worked on your branch yesterday may not appear tomorrow on the same keystroke. Treat the suggestion as a hypothesis, not a memo from a colleague who will say the same thing twice.
Why does a green test suite stop meaning what it used to mean?
Because AI Test Generation tools optimize for tests that compile and execute — not for tests that catch faults. A generated suite at ninety-one percent line coverage can sit at a thirty-four percent mutation score; the tests run, the lines are touched, the assertions pass against the behavior the code already has, including the bugs the code already has. “Green” no longer means “safe.” It means “the volume metric increased.” MONA’s mutation-testing explainer maps the gap and the measurement that closes it.
Where does the cost surprise come from?
Not from token usage in the obvious sense. From cache invalidation you did not specify. Prompt caches return value only when their preconditions hold exactly — a timestamp injected at the front of a context, a tool definition added in a different order, a model version bump from the vendor, and the cache misses. The agent still works. The invoice tripled.
When Coverage Is Not Verification
This is the cliff that turns into a postmortem the fastest. Classical CI gates assume that tests passing is evidence the change is correct. AI-assisted workflows quietly invert that — the tests passing is evidence that the tests passed, nothing more. Meta’s TestGen-LLM deployment is the cleanest published version of the right architecture: generate candidates, filter by build, filter by execution, filter by coverage delta. Skip any filter and the volume metric grows while the safety metric does not.
The transfer that holds: a test suite is a specification of behavior, written in code that runs. That definition predates LLMs by forty years and survives them intact. The transfer that breaks: the assumption that a tool which produces tests is producing a specification. An LLM trained on tests that compile will reliably produce tests that compile. It has no training signal for “this test would catch the kind of bug your team actually ships.”
The diagnostic that works on Monday: pick the module with the most AI-generated tests. Run a mutation testing pass — PIT for the JVM, Stryker for JavaScript and TypeScript. Look at the surviving mutants. They will cluster around boundary conditions, error paths, and domain invariants — exactly the regions an LLM cannot infer from source code alone, because they are not in the source code. They are in the requirements the source code is supposed to implement. That gap is not closed by another generation pass. It is closed by a human writing tests against intent, not against existing behavior.
The Refactor That Compiles and Lies
Of the six surfaces, AI-Assisted Refactoring is the one most likely to lull a senior engineer into trusting it for the wrong reasons. Classical refactoring tools — ReSharper, Roslyn, Babel — operated on the Abstract Syntax Tree and were rigorously behavior-preserving by construction. Extract Method either worked exactly or refused to run. AI refactoring is not constructed that way. It is a language model proposing transformations across files, validated downstream by whatever test suite you happened to have.
That asymmetry breaks a contract you might not have noticed you depended on. Martin Fowler’s original definition was disciplined: a series of small behavior-preserving transformations, each verifiable. An LLM agent can rename a function, move its definition, fix the call sites that lit up in the linter, and ship a diff that compiles green — while quietly altering a module-load side effect that no test in your suite exercises. The build is green. The behavior is gone. MONA’s prerequisites for AI refactoring names the four things — behavior preservation, test coverage, AST awareness, hallucination mitigation — that have to all hold for the transformation to be a refactor instead of a rewrite.
The instinct that helps: ask, before any agent runs, what specifically is preserved. Not the public API — the import-time effects, the ordering invariants, the cleanup hooks, the things your test suite never had a reason to assert. If you cannot list them in one paragraph, the AI cannot preserve them either.
The Patch That Fixed the Symptom
The last surface is the one where the SW debugger habit fails the most quietly. You paste a stack trace into AI-Assisted Debugging. Twelve minutes later you have a patch that compiles, three new comments explaining the bug, and the failing test now passes. By Monday the same error surfaces with a different stack because the AI patched the symptom in one caller and the second caller still passed the malformed value.
The model is not running your program. It is sampling tokens from a probability distribution over text that looks like what a debugger output and a fix would look like together. About sixty-five percent of code errors observed in 2026 benchmarks are invented symbols — function names, methods, imports, APIs — that look plausible but do not exist. MONA’s debugging prerequisites walks the failure surface the architecture predicts.
The transfer that holds: verify the fix against the original symptom, not against “the new test passes.” This is the discipline that already separated good debuggers from bad ones before AI. The transfer that breaks: trusting the explanation that ships with the patch. Plausible prose is not evidence. A reproducer that fails before the patch and passes after is. Same as it ever was.
A related blind spot lives one layer up. AI Documentation Generation reads the source and writes prose — confident prose, often beautifully formatted, sometimes describing an endpoint that does not exist, a parameter that was renamed two releases ago, or an install command for a package that was never published. The documentation looks right. The reader treats it as the spec. The spec was never reviewed. That is a different class of incident from a wrong patch, and it is the class your team will discover only when a customer files an issue against an API method that lives only in your generated docs.
What the Bridge Buys You
The bridge stops here, before the deep guides start. You now have the six-surface map and the failure mode each surface introduces — enough to read a vendor pitch and ask the right next question, not enough to specify the workflow that defends against it. Pick the surface you have the most exposure on this quarter, read the deep article behind it, and rewrite your local playbook against the spec.
FAQ
Q: Why do AI code completion suggestions feel less accurate on large files?
A: Long-file context dilutes attention even when the advertised context window is large. A 1M-token model spending only 2K-4K tokens per completion request behaves like a 4K-token model in your IDE. Retrieval scope, not raw window size, decides what the model sees per keystroke.
Q: Why are AI-generated tests passing while bugs still ship?
A: Coverage measures execution; mutation score measures fault sensitivity. AI generators are trained on tests that compile and execute, not on tests that catch faults. A green suite at high coverage can sit at a low mutation score, which means the tests pass against any behavior the code already has — including the bugs.
Q: Can an AI refactor a legacy codebase without breaking it?
A: Only if four prerequisites hold: behavior is preserved at observable boundaries, test coverage exists for those boundaries, the tool is AST-aware, and hallucination mitigation is wired in. Skip any one and the diff that compiles green is no longer a refactor — it is a rewrite with a probability distribution for a co-author.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors