AI Agent Architecture for Developers: What Transfers, What Breaks
Table of Contents
On Monday, the conversation dict reset during a routine deploy and every active session went amnesiac. On Tuesday, a tool’s response schema shifted by one field and a ReAct loop ran to its iteration cap thirty times before the budget alarm fired. By Friday, the team had tripled the orchestration code and still could not name which layer was broken. Three different bugs. Three different layers. One mental model that did not separate them.
That failure pattern is the first sign that an Agent Frameworks Comparison decision is not really a framework decision. It is a four-layer architecture decision, and the framework is the runtime that hosts whatever shape you specified.
The Four Layers Hiding in “Build an Agent”
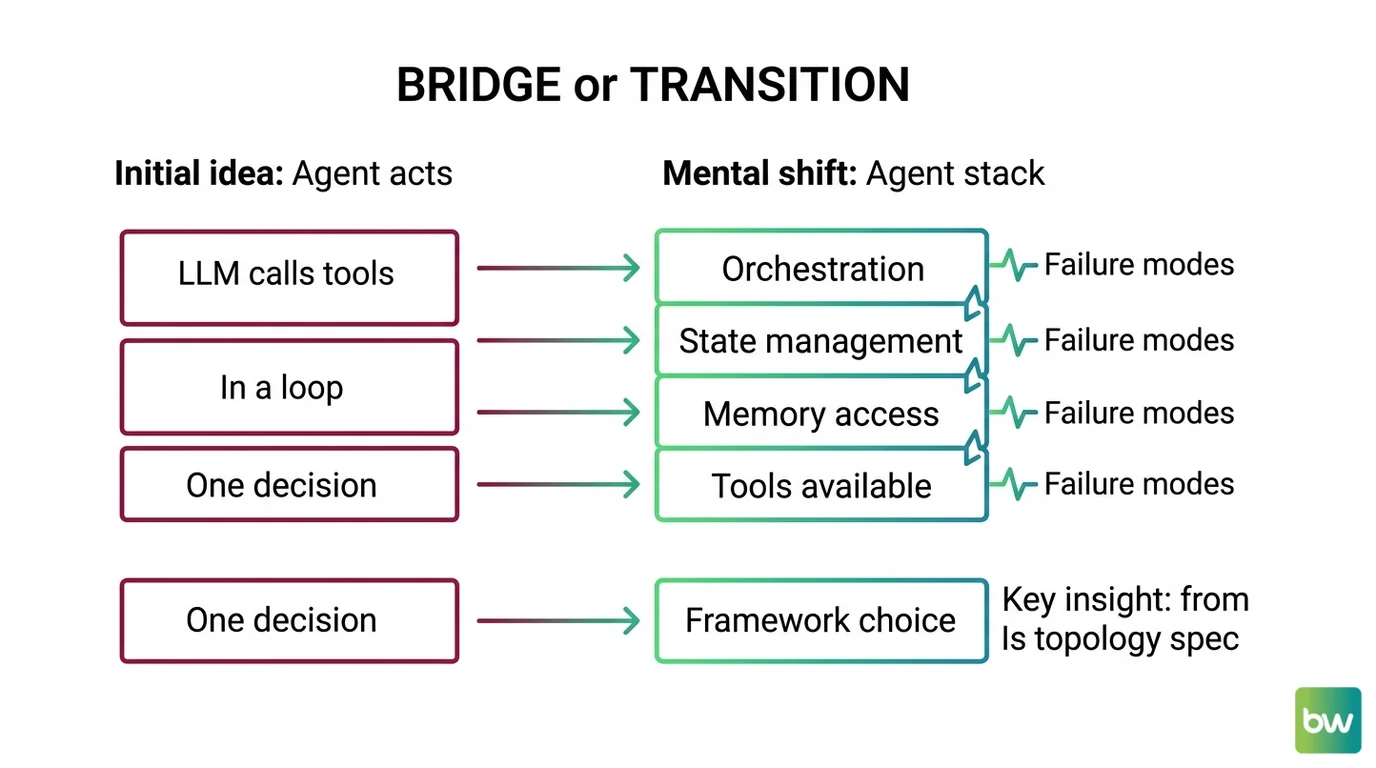
Most engineers describe an agent as “an LLM that calls tools in a loop.” That framing is why a working demo turns into an unfixable production incident two weeks later. A real agent decomposes into four owned layers: orchestration, state, memory, and tools — each a separate contract with separate failure modes.
This decomposition is the same engineering move you already make for stateful backend systems. You do not write one query handler that owns routing, session storage, persistence, and external calls. Orchestration owns the loop shape — ReAct, Plan-and-Execute, supervisor, swarm. State owns thread-scoped persistence. Memory owns cross-session recall. Tools own the external function contracts.
If you cannot draw those four boxes with labeled arrows between them, the framework will not save you. MAX’s framework decomposition guide walks the four layers in detail.
The framework race converges around three names. LangGraph 1.0 went GA on October 22, 2025 with a “no breaking changes until 2.0” guarantee and reached 1.1.10 on April 27, 2026 (LangChain Blog). Microsoft Agent Framework 1.0 hit GA on April 3, 2026, fusing Semantic Kernel with AutoGen v0.4 into one .NET-and-Python SDK (Microsoft Foundry Blog). CrewAI 1.14.4 shipped April 30, 2026 and crossed twelve million agent executions per day (CrewAI). AutoGen v0.4 moved to maintenance mode after the consolidation.
Mental Model Map: AI Agent Architecture From: An agent is an LLM that calls tools in a loop — one component, one decision Shift: An agent is a stack of four owned contracts — orchestration, state, memory, tools — each with its own failure mode To: A framework is the runtime that hosts a topology you specified — pick the topology first, the framework second Key insight: The framework race in 2026 is a topology decision, not an SDK decision — and the topology is your spec
Why Your Stateless Reflex Is Wrong Here
Your backend instinct says “make it stateless and scale horizontally.” The model is genuinely stateless — but the agent is not, and the gap between those two facts is where most production bugs hide.
Why is a “stateful” agent really a stateless model wrapped in a checkpointer that replays snapshots between turns?
A stateful agent in 2026 is a stateless LLM call plus a checkpointer that serializes full graph state to durable storage after every node, plus a thread_id that scopes which snapshot gets reloaded next turn. LangGraph’s PostgresSaver is the production reference — the same checkpointer running internally for Uber, LinkedIn, Klarna, JP Morgan, BlackRock, Cisco, and Rippling (LangChain Blog). More than sixty percent of agent production incidents trace back to state management, and the same stack claims a ninety-six percent error-recovery rate when the checkpointer is wired correctly (LangChain).
The breakpoint you set in your debugger is not where state lives. State lives in the serialized snapshot. Debug on the deserialization side — what reducer ran, what got merged, what thread_id was passed in. MONA’s state-management explainer covers the five components to keep separate.
Insecure deserialization in checkpoint storage produced CVE-2026-27794 (langgraph-checkpoint, RCE) and CVE-2025-68664 (langchain-core, CVSS 9.3). Treat your checkpoint store like any other untrusted input boundary.
The diagnostic question for any state bug: did the snapshot get written, did it get read back, and did it scope to the right thread_id? Three checks, three different layers. Confuse them and you will spend the day patching the wrong one.
Memory Is Not a Bigger Context Window
Once the team agrees the agent needs to remember across sessions, the next move is usually wrong: enlarge the context window. With agent memory, the cache-layer analogy fails twice — once on architecture, once on cost.
Why does agent memory behave like a system with a read-write loop, extraction policy, and forgetting strategy — not like a cache or a bigger context window?
A 2026 agent memory system is four moving parts. An extraction policy decides what to remember. A storage shape — vector, graph, file tree — decides where it lives. A retrieval policy decides what comes back into the prompt. A forgetting strategy decides what gets invalidated. MONA’s memory architectures explainer walks the four bets and where each one breaks.
Mem0’s 2026 numbers: 91.6% on LoCoMo and 93.4% on LongMemEval, roughly seven thousand tokens per retrieval, p95 latency 1.44 seconds versus 17.12 seconds for full-context (Mem0 Blog). ByteRover 2.1.5: 96.1% on LoCoMo and 92.8% on LongMemEval-S at roughly 1.6 seconds (ByteRover Blog). “Just enlarge the context window” pays the latency tax on every turn; memory-system approach pays once on extraction.
| You expect | You actually get | The cost when you are wrong |
|---|---|---|
| Cache hit returns what was stored | Retrieval returns what the extractor decided to store | Confidently-wrong recall — the system surfaces an outdated fact because nobody specified a TTL |
| Bigger context window = better recall | Long contexts degrade with length even at perfect retrieval (Chroma Context Rot) | Latency triples and accuracy drops on the same query that worked at 8K |
| Memory is one feature | Memory is four contracts: extraction, storage, retrieval, forgetting | A cross-thread leak — User A’s account number surfaces in User B’s session |
| Vendor benchmark predicts production | Every leaderboard is vendor-published, no neutral arena | A migration project at month four because your eval did not match theirs |
Pick by deployment posture, not benchmark: Mem0 for managed extraction, Letta when the agent manages its own memory through function calls, Zep for temporal knowledge graphs. The watch-out: Mem0’s graph memory is gated to Pro at $249/month (Mem0’s pricing page) — free and Starter tiers deliver plain vector recall. MAX’s persistent-memory guide covers the full decomposition.
Where Multi-Agent Breaks Your Parallelism Math
Your distributed-systems instinct says more workers means more throughput. With a stateless task pool, that math holds. With multi-agent systems, it inverts in a way that surprises every team that ships their first orchestrator.
Why does per-step reliability compound into chain-level failure faster than you expect?
If each step succeeds with probability 0.95, a five-hop chain lands at roughly 0.77. Past about 120 sequential steps, even the strongest models’ accuracy approaches zero; on harder variants, performance collapses inside fifteen.
Silent context divergence is the second surface. Cognition’s Walden Yan documents the canonical case: a Flappy Bird build split across two parallel sub-agents — one writing a Mario-style background, the other a non-game-like bird. The pieces did not fit because the system shared filtered messages instead of full traces (Cognition Blog). Anthropic’s orchestrator-worker with Claude Opus 4 lead and Sonnet 4 sub-agents sharing context aggressively scored about ninety percent above single-agent Opus 4 (Anthropic Engineering). Multi-agent stacks run at roughly three-and-a-half times the token cost of a single agent (Future AGI).
The MAST taxonomy catalogued fourteen failure modes from more than 1,600 traces across seven frameworks, with failure rates between 41% and 86.7% (Cemri et al., arXiv). MONA’s multi-agent prerequisites explainer covers the physics that govern the loop. Anthropic’s own guidance: most reliable production systems described as “agentic” are workflows on predefined paths, not autonomous agents (Anthropic Engineering).
Pick the Topology Before the Framework
The single biggest mistake in 2026 agent builds: choosing the framework first. The topology — supervisor, swarm, hierarchy — is your spec; the framework is the runtime that hosts it. MAX’s multi-agent build guide walks the topology-first decomposition.
The three production frameworks make different bets. LangGraph: state machine with typed transitions and checkpointed nodes — the production default for stateful workflows. CrewAI: role-based agents with an event-driven Flows API — the on-ramp for teams that think in roles and tasks. Microsoft Agent Framework: absorbed AutoGen and Semantic Kernel into one .NET-and-Python SDK with sequential, concurrent, handoff, and group-chat patterns plus A2A and MCP protocols — the enterprise default for Azure shops.
Sixty percent of U.S. Fortune 500 companies run CrewAI in 150+ countries (CrewAI Blog). LangChain named Uber, LinkedIn, Klarna, JP Morgan, BlackRock, Cisco, and Rippling as LangGraph production users (LangChain Blog).
Security & compatibility: CVE-2026-27794 (
langgraph-checkpointRCE, pin ≥ 4.0.0), CVE-2025-68664 (langchain-coreCVSS 9.3, pin ≥ 0.3.81), CVE-2025-67644 (LangGraph SQLite injection). AutoGen v0.4 is in maintenance mode — new work targets MAF. MemGPT is now Letta (v0.16.7, March 2026). Zep Community Edition no longer supported as of February 2026 — use Zep Cloud or self-host Graphiti (Zep Blog).
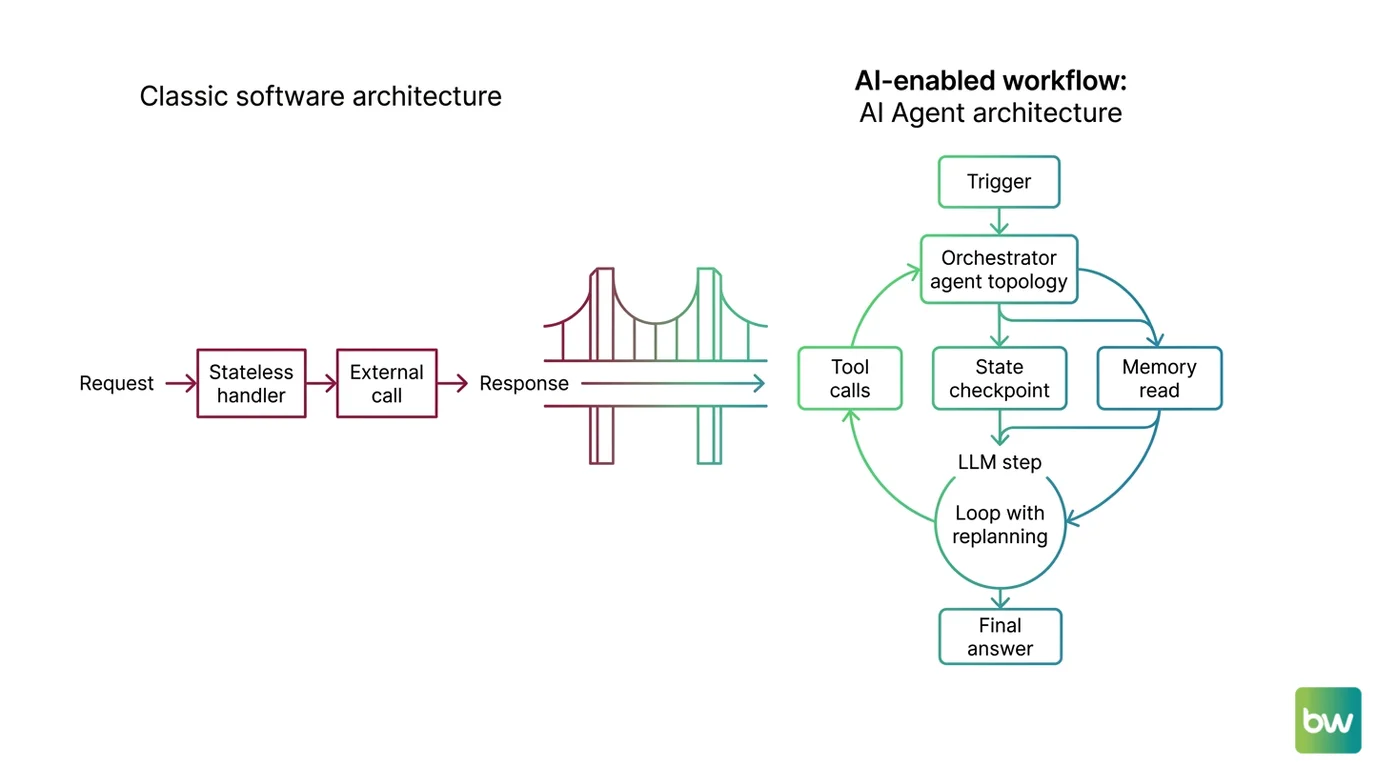
Shift Diagram: AI Agent Architecture Classic: Request → Stateless handler → External call → Response AI: Trigger → Orchestrator (topology) → Tool calls + state checkpoint + memory read → LLM step → Loop with replanning → Final answer
Where to Read Next
For the framework abstractions, MONA’s framework explainer covers what LangGraph, CrewAI, and AutoGen actually do. When you are ready to build, MAX’s framework decomposition guide maps the four layers to 2026 production tools. If production keeps surprising you, MONA’s multi-agent limits piece names the four physics that govern the loop.
Spec each layer. Measure each separately. The framework defaults will not save you when the third bug lands at the same time as the second deploy. The architecture is a stack of contracts — and the contracts, not the library, are what survives the next migration.
FAQ
Q: What is the difference between agent state and agent memory?
A: State is thread-scoped — it survives a crash mid-task and gets reloaded by thread_id on the next turn. Memory is cross-session — it carries facts, preferences, and history from one conversation to the next. The 2026 production stack splits them across two layers: a checkpointer like LangGraph’s PostgresSaver for state, and a memory engine like Mem0, Letta, or Zep for memory.
Q: Do I need a multi-agent system, or is a single agent with tools enough?
A: Start with a single augmented agent — one model, tools, retrieval, and memory. Reach for multi-agent only when the task genuinely fans out, per-step reliability supports the chain length, and the answer’s value justifies a token budget several times the chat baseline. Anthropic’s own guidance: most reliable production “agentic” systems are workflows on predefined paths.
Q: Why does my agent forget everything after a deploy restart?
A: Conversation state lived in an in-memory dict that the process wiped on restart. The fix is a durable checkpointer like LangGraph’s PostgresSaver that writes state to Postgres after every node and reloads by thread_id on the next turn.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors