Shipping Code You Specified but an Agent Wrote
Table of Contents
A branch shows up in your review queue on Monday. It touches a dozen files across three modules, the tests are green, and the description reads clean. Your first instinct is thirty years old: find the author, ask why they did it this way. You open the commit metadata. The author is an agent. It ran overnight, passed its own checks, and pushed. Nearly every developer says they don’t fully trust code like this — and fewer than half of them actually read it before it merges.
Here is what changed: when an Agentic Coding agent writes the diff, your job moves from authoring code to specifying and bounding it — the spec and the trust boundary become your interface. The instinct that trips you is treating the agent’s pull request like a teammate’s, only faster. It isn’t. No author stands behind it to question, and the spec you wrote is the only record of what the change was meant to do.
This is not a guide to running the agent loop yourself — the topic hub carries the prerequisite map and the common questions. This is about the assumptions your delivery workflow inherits the moment an agent starts opening branches against your repo.
Why There’s No Author Left to Ask
The review ritual you trust rests on a hidden dependency: an author who holds the context. When you flag a strange line, you are not really reading the diff — you are opening a conversation with the person who wrote it. They remember the ticket, the edge case, the reason they rejected the obvious approach. Half of code review is that conversation.
An agent gives you the diff and nothing behind it. Ask it “why did you do this” and you get a fresh, plausible rationalization generated on the spot — not the actual reason, because there was no reasoning you can audit, only a run. The intent that a human author would carry in their head has to live somewhere else now: in the spec you wrote before the agent started. If that spec was thin, the intent is simply gone, and the diff in front of you is the only artifact left. That is the shift MONA’s team documents in detail — the visible product is the scaffold around the model, and the loop, not the model, is where behavior actually comes from.
Mental Model Map: Reviewing Agent-Authored Code From: The agent is a fast teammate whose pull request I review the usual way Shift: There is no author to interrogate — the spec is the only surviving record of intent To: My spec and boundary are the real work; the diff review is the last line, not a lighter one Key insight: You cannot ask an agent “why did you do this” and get accountable context back, so the intent has to live in what you wrote before it ran.
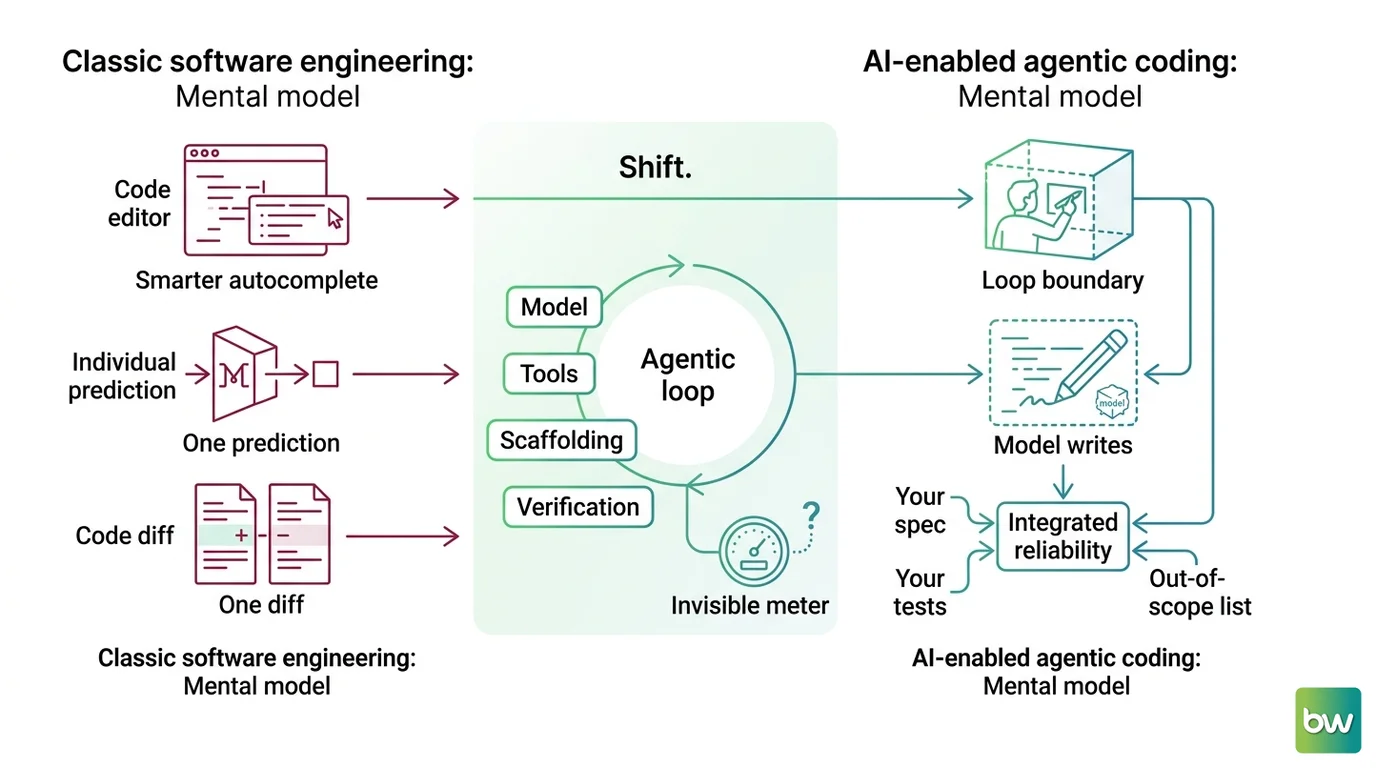
This is why the “agent is just a fast junior developer” analogy quietly betrays you. A junior accumulates your team’s context over months. You can ask them why, and next quarter you can trust them with more and review them less. The agent does neither. It starts every task from the same cold context, so your review can never get lighter the way it does with a person you are training. In practice, the diff review is a permanent tax, not a phase you graduate out of — budget it that way.
Your Ticket Instinct Just Became the Product
Here is the good news, and it is real: the most transferable skill you own is now the highest-leverage one. Writing a tight ticket — clear acceptance criteria, an explicit definition of done, the edge cases called out — was always a discipline that separated senior engineers from the rest. With an agent, that discipline stops being a nicety and becomes the specification the agent executes against.
Three instincts carry over almost unchanged. The acceptance criteria you write for a teammate is the same artifact that tells an agent what “done” looks like. The change-boundary discipline — naming which files a change is allowed to touch — becomes the literal fence you draw around the agent’s blast radius. And your test suite, the thing you already trust as the arbiter of correct behavior, becomes the agent’s verification oracle: the check that closes its loop. MONA’s breakdown of the plan-execute-verify loop makes the mechanism precise — the dominant failure mode in 2026 is the verification gap, where the agent declares completion on a change that does not compile or breaks a test the harness never ran.
| Your delivery instinct | Still works with an agent | Where it stops predicting |
|---|---|---|
| Writing acceptance criteria / definition of done | Directly — it becomes the spec the agent executes | An ambiguity you’d resolve by asking a colleague is a silent guess the agent already committed |
| Naming the change boundary (which files a change may touch) | Directly — it becomes the agent’s allow/deny scope | Nothing physically stops the agent from editing outside it unless you enforce the fence |
| Reading the diff, checking the tests | Directly — this is still your last line of defense | There is no author to question, so the diff must be self-explanatory |
| “I didn’t have time to write that much” as a natural limit | No longer holds | Authoring speed stopped bounding how much can change in one branch |
What does not transfer is the assumption baked into that last row. Your review workflow evolved around a quiet constant: a human could only write so much in a day, so the size of a change was naturally bounded. An agent removes that governor. It can edit across a whole module in one loop, which means “the change is small enough that I can eyeball it” is no longer a safe default — it is an assumption you now have to check on purpose.
The Bottleneck Moved From Typing to Reading
For thirty years the scarce resource in your delivery pipeline was authoring: someone had to type the code. Review was the cheap step at the end. Agents invert that. Generation is now nearly free and nearly instant; the scarce resource is a human who can read, understand, and vouch for what got generated. Your delivery bottleneck moved from the keyboard to the review queue, and most teams have not re-budgeted for it.
The numbers from the deep articles are blunt about what slips through that gate. An analysis of 470 open-source pull requests found AI co-authored merges carried substantially more major issues and more security vulnerabilities than human-only equivalents — the detail is in ALAN’s account of accountability and skill erosion. Veracode’s work, cited in the piece on who owns the code an agent writes, puts a large share of AI-generated code in violation of common security categories. These are not arguments against agents. They are a description of what the review queue now has to catch.
Shift Diagram: Ticket-to-Merge With an Agent Classic: write ticket → write code → teammate reviews PR → merge AI: write spec + boundary → agent generates across files → agent self-tests → you review and merge as engineer of record
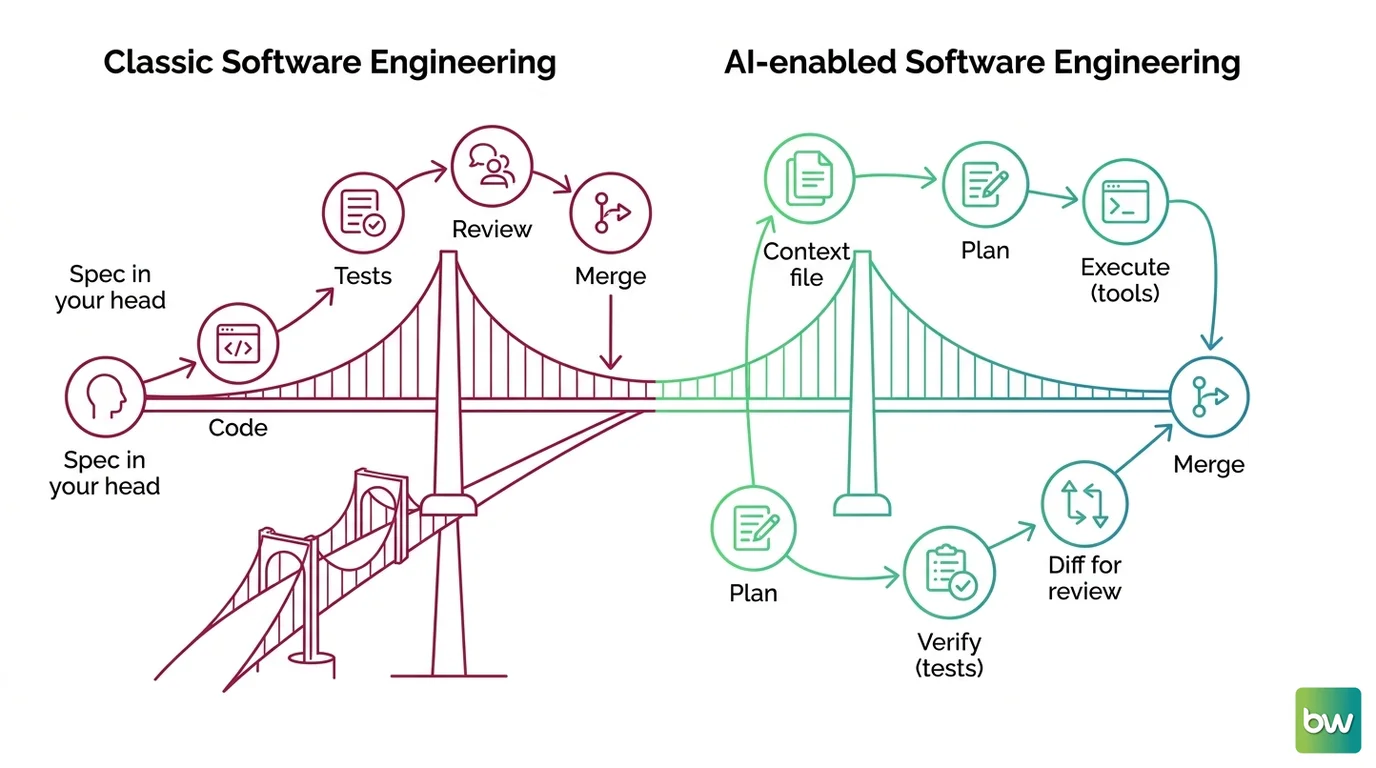
In practice, this means your sprint scoping is now wrong in a specific way. You still estimate by how long the work takes to build, but building is no longer the long pole. The long pole is review throughput, and it does not scale by adding agents. If your definition of done includes “a human who did not write this has read and understood it,” then a story is only as fast as your slowest reviewer — and that is the number to plan against, not the model’s benchmark score.
Your Context File Rots Like Code
Every agent reads a context file before it works — a CLAUDE.md, an AGENTS.md, a .cursorrules. It carries your conventions, your stack versions, your architectural rules, the boundaries you never want crossed. This is
Context Engineering For Code, and treating it as one-time setup is the misconception that produces lottery-quality diffs.
Stale documentation is an old problem with a familiar failure: a human reads it, notices it contradicts the code, and works around it. A stale context file fails differently. The agent obeys it literally and without suspicion. When the file still describes last quarter’s auth pattern, the agent writes last quarter’s auth pattern into a fresh branch — confidently, consistently, and everywhere at once. The rot does not sit quietly in a wiki; it ships. MAX’s guide to engineering context with CLAUDE.md, .cursorrules, and AGENTS.md makes the operational point: the rules that absolutely cannot be violated do not belong in a paragraph the model may skim — they belong in a lint check or a pre-commit hook that fails loud.
There is a boundary on where any of this is safe, and it is worth naming before you scale it up. Strict Vibe Coding — accepting generated code without reading it — is fine for a throwaway prototype and dangerous for anything load-bearing. The agent reaches your tools and data through the Model Context Protocol, which widens what it can touch; the same reach that lets it run your test suite lets it edit files you did not mean to expose. And the legacy-modernization work agents handle well — the AI Code Migration branches your team wants least — is exactly the work where a silent regression hides longest, because the tests that would catch it often do not exist yet.
Before You Merge an Agent’s Branch
Run this over your own stack before you let an agent open branches at scale. These are questions about your setup, not the model’s.
| Runtime question | Why it matters |
|---|---|
| Does a written spec exist before the agent runs, or does intent live only in the prompt? | After the run, the spec is the only surviving record of what the change was supposed to do. |
| Is the change boundary enforced, or just described? | An agent will edit outside a boundary it was merely told about; a fence that isn’t wired is decoration. |
| Have you budgeted review capacity, not just build capacity? | Generation is cheap; the human who vouches for the diff is now the bottleneck. |
| Do your critical conventions live in a failing check, or in a paragraph? | A rule in prose gets skimmed; a rule in a pre-commit hook gets enforced. |
| Who is the engineer of record when the agent’s branch merges? | The commit log will name a person, not a model, when a regression surfaces later. |
| Does your test suite actually cover the behavior the agent is changing? | Tests are the agent’s oracle — where coverage is thin, “green” means nothing. |
If you cannot answer these cleanly, the fix is not a better model. It is a tighter spec, an enforced boundary, and review capacity that matches your generation rate. That is the same architecture MONA, MAX, and DAN keep converging on from different angles: the loop is only as trustworthy as the checks that close it.
What Actually Changed on Your Desk
The agent did not take your job; it moved it. You used to write the change and defend it in review. Now you write the spec, draw the boundary the agent cannot cross, and stand as the reviewer of record for a diff you did not type. Start Monday with one artifact: the boundary list for your next agent branch — the files it may touch, and the ones it may not.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors