Agent Reliability for Engineers: What SRE Habits Map and Break
Table of Contents
On Tuesday at 2:47am the agent processed eleven thousand customer messages without throwing a single exception. By Wednesday afternoon a refund team noticed that a portion of those replies cited a policy that did not exist. No 5xx. No retries fired. No alerts. The trace dashboard showed green spans top to bottom. The on-call engineer — twelve years of SRE work, half of it on payment infrastructure — opened the runbook, found nothing that matched, and closed the laptop unsure which question to ask next.
That is the moment the SRE map breaks. Not because the engineer is wrong. Because the unit of failure changed and the dashboard did not say so.
Classical Habits Mostly Still Apply, Until They Don’t
If you have ever paged through a postmortem and read the words “retries with exponential backoff,” you already own most of the vocabulary. Idempotency keys. Circuit breakers. Structured tracing. Budget alerts. Code-review gates on destructive actions. Those instincts still frame the right questions for agent reliability — the unit of failure is just no longer an RPC.
The bridge article you wanted is not “AI changed everything.” It is shorter and meaner: here are the four or five places where a senior engineer’s reflexes silently route them toward the wrong fix.
| Classical SRE habit | Still works for | Where it stops predicting |
|---|---|---|
| Retry with exponential backoff | Transient network and 5xx | A model that “retries” with different wrong reasoning |
| Idempotency keys on writes | Tool side effects | Effects that already executed before the retry |
| Distributed tracing | Latency and propagation | What the model decided, with what context |
| CI test gate | Deterministic regressions | Non-deterministic trajectories scored by an LLM |
| Budget alerts | Monthly anomalies | A prompt that quietly evicts its own cache mid-run |
| Approval workflows | Low-volume, high-stakes | Volume your reviewer cannot read |
Each row is one section. Read the row you do not believe yet first.
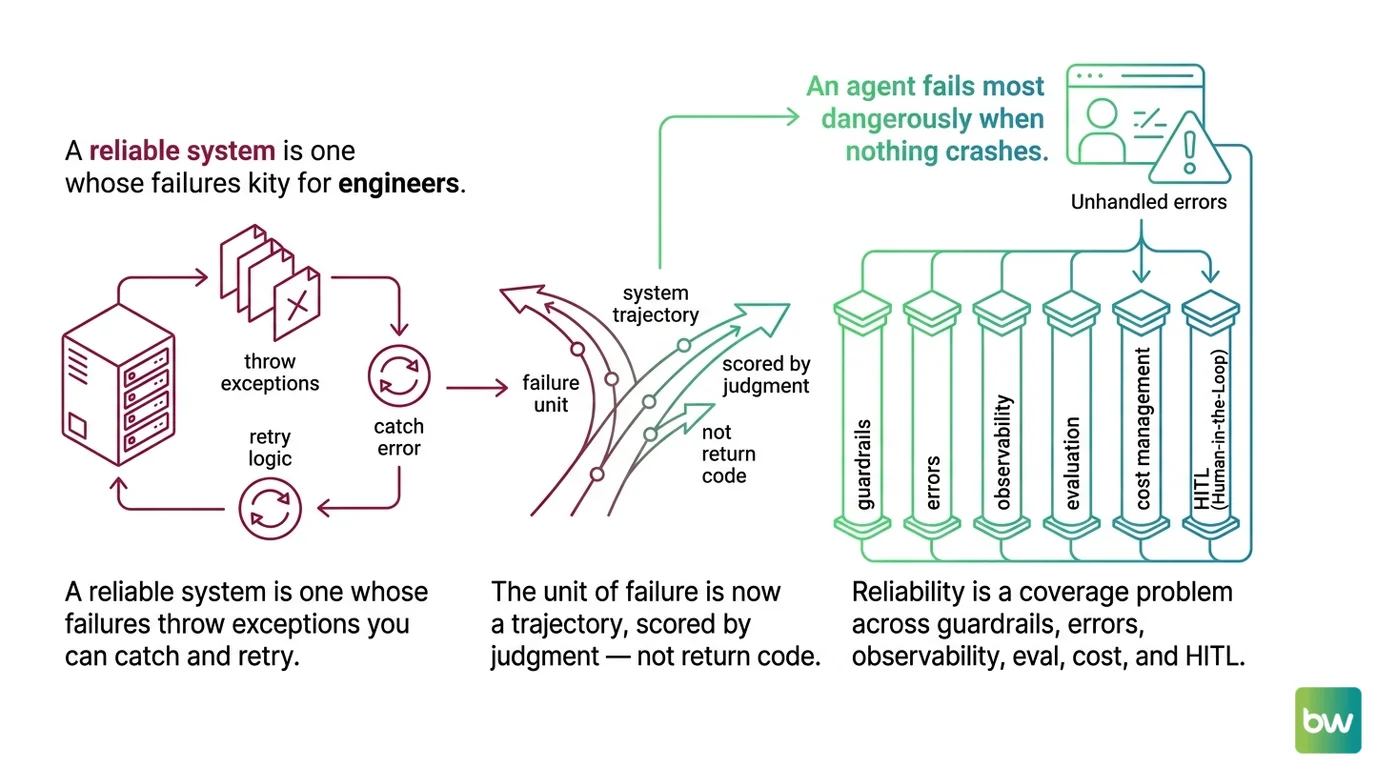
Mental Model Map: Agent Reliability for Engineers From: A reliable system is one whose failures throw exceptions you can catch and retry. Shift: The unit of failure is now a trajectory, scored by judgment — not a return code. To: Reliability is a coverage problem across guardrails, errors, observability, eval, cost, and HITL. Key insight: An agent fails most dangerously when nothing crashes.
The Stack Trace That Never Came
Your first agent incident will not look like a service incident. The model emits confidently formatted JSON. The tool layer runs. Spans close cleanly. Somewhere inside the trajectory the agent committed to a wrong premise and every step after that confirmed it — politely, fluently, downstream.
This is the part most teams underestimate on the first day. Classical systems are mostly fault-driven — something throws, something catches, something retries, the postmortem points at a stack frame. Agent systems are mostly cascade-driven. A single root-cause failure propagates into a chain of downstream mistakes, and the surface that sees the chain is not your code.
The implication for an SRE is uncomfortable: the layer you would normally instrument — exceptions, return codes, status fields — is the layer that says nothing went wrong. Agent Error Handling And Recovery has to live one level up, in a runtime that compares what the agent did against what it should have done, and treats the gap itself as the error signal.
The four-layer model from the deep guides is worth memorising before you write a retry policy: retry handles transient failure, validate handles malformed or semantically wrong outputs, persist handles crash recovery between steps, escalate hands the case to a human. Most of the production incidents you will see in the first year are people calling layer two a layer-one problem and adding more retries. MAX’s retry, fallback, and self-correction guide walks the four layers in detail.
The diagnostic you can use on Monday: if your incident review concludes “the agent did X confidently and was wrong,” do not write a smarter prompt. Identify which of the four layers should have caught it — and which one you have not built yet.
Retries That Make It Worse
This is where the SRE map sends people off the cliff fastest. Retries are the right reflex for transient network errors and rate limits. They are the wrong reflex for the failure mode that actually dominates agent incidents.
Why does “just add retries” fix the wrong layer?
When a deterministic service fails, the same input on retry produces the same output, except for the transient condition that caused the failure. That is what makes the retry safe. An LLM call has no such property. On attempt one the model decided to issue a refund. On attempt two it decides to send an apology email. Both actions go through, because the deduplication layer is keyed by request ID — not by intent. The bug is not that retries failed. The bug is that retries succeeded twice for two different decisions.
The Stripe pattern still helps you here, and that is exactly the kind of transfer worth keeping: the client generates a high-entropy idempotency key, the server retains it for at least twenty-four hours, and the server errors when a retry arrives with the same key but different parameters. That discipline is older than agents — it was already the only way to make HTTP retries safe — and it carries over almost verbatim. What changes is who generates the key. If the LLM picks it, the dedup layer cannot save you. The key must come from deterministic code wrapping the tool call.
The second cliff in this section is durable execution. A retry on a flaky DNS resolution is fine in memory. A retry across a five-minute tool chain after a pod restart is not. Three independent ecosystems — Temporal’s workflow model, LangGraph’s checkpointer graphs, and AWS Step Functions’ redrive feature — converged on the same architectural claim: agents that cannot persist their own state are not production-ready. If you are storing trajectory state only in process memory, your first crash will erase a budget you have already spent. MONA’s prerequisites for resilient agents maps the failure-mode taxonomy that decides which checkpoint store you need.
The Monday-morning action: walk the tools the agent can actually call and label each one idempotent, side-effecting, or destructive. Anything not labeled idempotent needs a key generated outside the model.
Your Trace Is a Projection
Distributed tracing is the SRE skill that transfers most cleanly into agent work, and it is also the one most likely to lull you into thinking the problem is solved when it is not. W3C Trace Context still propagates. OTLP still ships spans to a backend. Datadog, Jaeger, Langfuse, LangSmith, Arize Phoenix — they all speak the same wire format. The plumbing carries over.
What does not carry over is the assumption that a trace is enough.
What changes about observability when traces are non-replayable?
A microservice span answers “how long did this RPC take.” An Agent Observability span has to answer something stranger: what did the model decide, with what context, under what weighting, and which tool did it choose as a result. The same input does not reproduce the same output, so unlike a classical incident, you cannot replay the failing call. The trace itself is the evidence — and if the prompt contents and tool I/O are not captured at the moment of execution, the evidence is gone.
Three things actively bite engineers here. First, the OpenTelemetry GenAI semantic conventions are still in Development status — attribute names, span structures, and metric definitions can change between releases. Pin instrumentation versions, do not pin dashboards to attributes the spec marks Recommended. Second, prompt content lives in span events, not attributes, because attributes have size and cardinality limits the prompt will blow past. Third, span-kind is ambiguous between client and internal depending on whether your agent runs in-process or against a hosted API like the OpenAI Assistants API. The same code, same prompt, can produce a different trace shape from one provider to another. MONA’s OpenTelemetry GenAI explainer maps the four hard limits that come on the moment you turn it on.
If you take only one thing from this section: agent observability is not LLM observability. LLM observability records a call — prompt in, tokens out, latency, cost. Agent observability has to capture the full trajectory, including the reasoning transitions between calls. The vendor market is splitting along that line — DAN’s observability split piece is the procurement-side read.
The diagnostic that works on Monday: pick last week’s worst incident. Can you, from spans alone — no replay, no logs from elsewhere — say which tool returned what at which step? If not, your span schema is incomplete.
The Eval That Lies When the Judge Shares DNA
Classical CI runs a deterministic test suite, gets a green tick or a red one, and gates the merge. Agent evaluation does not work that way, and the first place this matters is the moment a senior engineer treats their LangSmith dashboard like a green pipeline and ships.
Why does evaluation stop being a deterministic CI gate?
Two reasons. The first is that the unit being graded is a trajectory, not an output — and trajectories are scored by a stack of three different signals (outcome, trajectory, cost), each of which can be gamed in isolation. The second is that the grader is often itself an LLM, and LLM-as-judge has documented biases: position bias, verbosity bias, and self-preference bias. When the judge model shares a family with the system under test, scores inflate in ways that have nothing to do with quality.
This is why mature pipelines run Agent Evaluation And Testing as three surfaces, not one: a pre-merge regression layer (cheap, runs in CI, blocks the build), an offline experiment layer (slower, runs against curated datasets, drives prompt or model changes), and a production trace-scoring layer (runs on live traffic and surfaces drift). Each surface catches a different class of failure. Collapse them into one and you find out the hard way which class you stopped catching. MAX’s evaluation pipeline guide specifies the three-surface contract; MONA’s evaluation prerequisites explainer walks the bias surface inside the judge itself.
The misconception worth burning into your spec right now: a green eval dashboard is not the same as a green build. If your eval suite uses one LLM judge and that judge is in the same model family as the agent, your scores carry a bias you have not measured. The cheapest mitigation is a second-family judge on a sample of cases — and a written acknowledgement, in your reliability spec, that the eval surface is itself part of the surface under test.
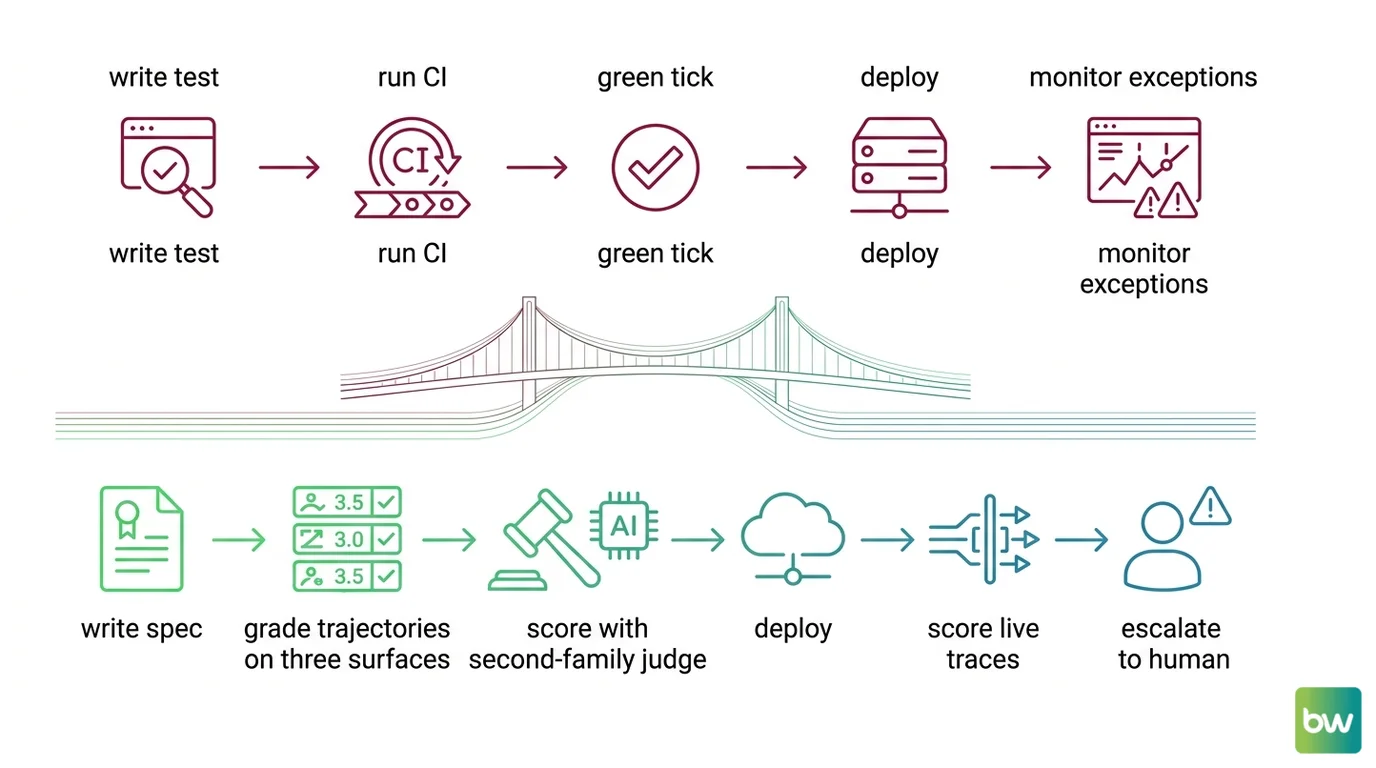
Shift Diagram: Reliability workflow, classical vs agent Classic: write test → run CI → green tick → deploy → monitor exceptions AI: write spec → grade trajectories on three surfaces → score with second-family judge → deploy → score live traces → escalate to human
Your Approval Queue Will Outrun the Reviewer
Procurement instinct says high-risk actions go through a human approval gate. That instinct is right. It is also half the problem.
The pause primitive itself is solved. Every major agent framework — LangGraph’s interrupt, AutoGen’s UserProxyAgent, CrewAI’s human_input, OpenAI Agents SDK’s human_approval, Temporal’s signals — ships a working version of “stop here and ask a human.”
Human In The Loop For Agents is a state-machine pause that hands control to a person and resumes on signal. The mechanics work.
What does not work is the assumption that the human has the time, context, and authority to actually refuse. A reviewer facing a queue that grows faster than she can read it is not oversight — she is a rubber stamp wearing the audit trail. The cognitive-science literature on automation bias and vigilance has been telling us this for forty years: a human cannot maintain effective attention on a low-event-rate signal for more than about half an hour. Agent approval queues are exactly that signal.
The transfer that holds: design the approval gate at the right boundary. Wrap the tool that has the side effect, not the task that ends after the side effect already ran. The transfer that breaks: treating a green approval rate as evidence the gate is working. A 99% approval rate where the reviewer has six seconds per item is not oversight, it is theatre. ALAN’s piece on rubber-stamp approvals and MONA’s HITL prerequisites together map the vigilance ceiling that no framework primitive can lift for you.
The Monday-morning question: how many approvals per hour does your reviewer face, and at what point does throughput exceed the cognitive budget you implicitly purchased from them? If you cannot answer that, your HITL gate is not yet a gate.
The Bill That Spikes While Logs Look Clean
The last cliff is the one most often inherited rather than designed. A vendor migration lands an LLM-inference service in your dependency graph, a per-call cost is buried inside a tool function, and the invoice doubles three weeks before anyone notices the dashboards never showed a per-step cost line.
Classical budget alerts catch monthly anomalies. They catch the shape of cost. They do not catch the cause, because the cause is structural — output tokens cost several times more than input tokens, decode is far slower per token than prefill, and prompt caches return value only when their preconditions hold exactly. A timestamp injected at the front of a prompt invalidates a cache the prompt was designed to hit. The agent still works. The cost just quietly tripled.
This is where Agent Cost Optimization stops being a finance concern and becomes an architecture concern. The deep guide spec is a four-layer model: route (cheap, default, escalation tiers), cache (preconditions, per-provider minimums), budget Agent Guardrails (per-key and per-team spend caps with alerts before the limit lands, not after), and observe (per-call traces with model, tokens, cache hit, route taken, dollar cost). MAX’s cost-cutting guide specifies the four layers and the order to build them in.
Budget guardrails belong to the same architectural family as input and tool guardrails — they are deterministic enforcement, sitting outside the model, refusing to negotiate with it. If a developer can change the model the agent calls by editing a string in agent code, you do not yet have a router. If a developer can blow past the per-key budget by adding one more tool call, you do not yet have a guardrail. Both are common diagnoses on the first cost incident.
The diagnostic that works on Monday: pick the call path that scared finance last quarter. Can you, from observability alone, say which step in the trajectory caused the spike — and which of the four cost layers should have caught it? If not, you are missing a layer, not a discount.
The Updated Model
Reliability for agents is a coverage problem across six surfaces — guardrails, errors, observability, eval, cost, and HITL — and the SRE habit that helps most is the one that asks “which layer should have caught this.” The next action is the small one: take last week’s worst incident, identify which of the six surfaces failed silently, and write the missing contract before you write the next prompt.
FAQ
Q: Why do classical retry strategies fail for AI agent errors?
A: Classical retries assume the same input produces the same output minus a transient fault. LLM calls have no such guarantee. A retried agent may decide on a different action entirely, executing two different side effects under the same request ID. Add idempotency outside the model.
Q: What does observability mean for an AI agent in production?
A: It means capturing the full trajectory — every LLM call, tool invocation, retrieval, and reasoning transition — as structured spans, because the run is non-replayable. The OpenTelemetry GenAI semantic conventions define this schema but are still in Development; pin your instrumentation versions and design dashboards on required attributes only.
Q: Why isn’t a green eval dashboard the same as a green CI build?
A: Agent evaluation grades trajectories, not deterministic outputs, and the grader is often itself an LLM with documented biases — position bias, verbosity bias, self-preference. Run three eval surfaces (pre-merge, offline experiment, production traces), and use a second-family judge on a sample so the eval surface itself stays measurable.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors