Agent Capabilities for Developers: What Maps and What Breaks
Table of Contents
Your team wired a coding agent into the CI runner four months ago. The demo PR merged in ninety seconds. The third week of October, the sandbox bill doubled. The fourth week the agent committed a passing test that nobody could reproduce locally, and an on-call engineer spent two days finding out the test had retrieved a stale doc the agent decided was authoritative. The PR ratio still looked great. The dashboard was green.
That is what an agent capability looks like once it’s in your stack — not the slide-deck version. Code execution, browser control, retrieval-augmented reasoning, workflow orchestration — four families are arriving in production codebases the same way RAG arrived two years ago. Through a vendor SDK, a product roadmap, a CTO directive, or a hackathon prototype somebody could not shut down. You inherited them. You did not pick the architecture. And the classical engineering instincts you used to debug microservices are about half-right — which is the dangerous part.
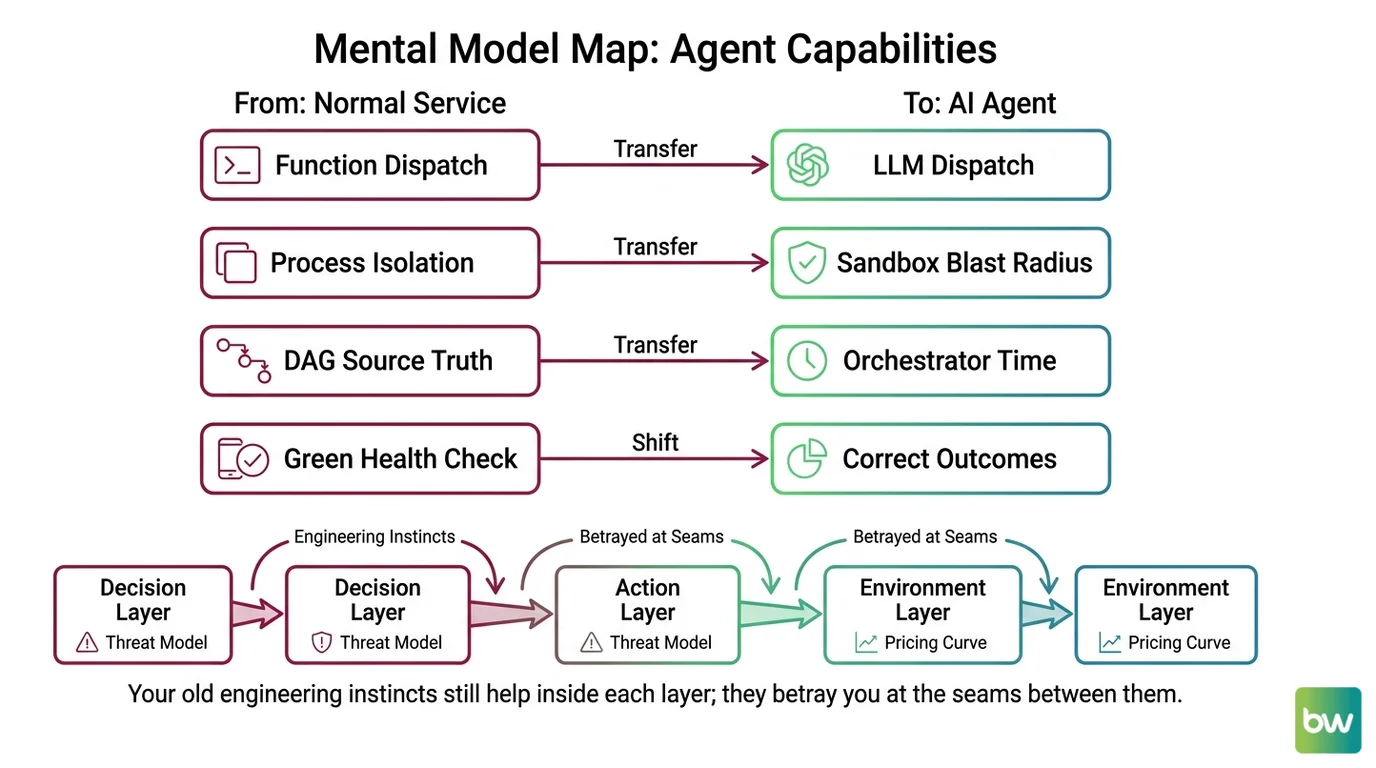
Mental Model Map: agent capabilities for developers From: agents are microservices with an LLM glued on top Shift: the LLM owns dispatch, so cost, retries, and failures change shape To: agents are LLM-driven controllers wrapped in deterministic infrastructure you still own Key insight: the boundary between “what the model decides” and “what your platform persists” is the only abstraction that survives a vendor swap
The Agent Loop Is Not a Job Queue
A coding agent or a retrieval-augmented agent shows up on a system diagram looking like a normal worker. Inputs go in. Outputs come out. There’s a queue, retries, a timeout. If you have built async microservices, your first instinct is to model the agent the same way.
Keep that instinct. Most of it still pays.
Contracts still matter. Idempotency keys still matter. Blast-radius thinking — assume any single call can be retried, replayed, or partially completed — still matters. The pattern that an agent is a service with side effects, accessed behind your API, is the right starting frame.
Why does an agent’s ReAct loop accumulate cost and context bloat in ways a normal job queue never does, and what does that mean for your timeout, budget, and circuit-breaker design?
A traditional job runs once. An agent’s ReAct loop — Thought, Action, Observation, repeat — runs as many times as the model wants to. Every iteration is at least one LLM call plus one tool call. The context grows monotonically: previous thoughts, previous observations, every tool return. The model that read 8K tokens on iteration one is reading 40K on iteration five. The bill scales not with request count but with loop depth multiplied by context length.
Anthropic’s engineering writeups call out the same shape: compaction of stale tool calls, structured note-taking, multi-agent setups that isolate sub-tasks into separate contexts. None of these are nice-to-haves. They are what keeps the loop from becoming a tarpit.
Three classical patterns transfer almost directly, but each needs a delta:
| Classical pattern | Carries over | Where it stops predicting |
|---|---|---|
| Retry policy with exponential backoff | Yes — Temporal-style activity retries work on agent tool calls | Retry on the agent loop itself costs N LLM calls per attempt, not one |
| Per-request timeout | Yes — you still need one | A 30-second timeout becomes a 30-second-times-N-iterations problem; cap iterations, not just wall time |
| Circuit breaker for downstream failures | Yes — bound calls to the model and the tool gateway | Add a budget breaker: max tokens per request, max iterations per task, max dollars per session |
For the full constraint analysis on what makes the loop expensive — sandbox cold-start versus isolation, benchmark fragility, effective context collapse — see Cold Starts, Flaky Tests, and Context Blowup.
Budget the loop, not the request. The unit of accounting is iterations, not invocations.
Your CI Runner Is Not a Sandbox
The most common production mistake with
Code Execution Agents is treating the existing CI worker as the place where model-generated code runs. The CI worker has your network. Your credentials. Your filesystem. The agent that just wrote rm -rf node_modules doesn’t know which directory it owns.
The classical instinct here — “containers isolate processes” — is the bad assumption.
A container shares a kernel with the host. A model that writes code can also write a syscall that exploits that kernel. The 2026 baseline isolation for AI-generated code is not a Docker container. It is a Firecracker microVM (used by E2B), a gVisor user-space kernel, or a fresh-per-task sandbox provider. The numbers reflect physics: microVMs boot in around 150ms, gVisor adds a user-space syscall filter at modest overhead, and the cheaper, faster tiers across the market are precisely the ones with thinner isolation.
What transfers from your existing operational thinking:
- Least-privilege credentials. The sandbox should never get the same API keys your production services use. Scope them per session.
- Egress allowlists. Same instinct as locking down a VPC; the agent’s outbound network is a configuration you write, not a default you inherit.
- Ephemeral state. Each agent task gets a fresh sandbox; if you need persistence between turns, it’s a deliberate choice with its own threat model.
What changes: cold-start latency now sits inside your user-facing path. A 90ms Daytona boot is fine for an interactive agent. A 2-second Firecracker boot is not. The decision between “container speed” and “kernel-level isolation” is now a UX decision, not just an infra decision.
The full landscape — E2B versus Daytona versus the Claude Agent SDK’s built-in tool — is mapped out in the code-execution agent build guide.
Browser Agents Fail Where Selenium Never Did
When
Browser and Computer Use Agents arrive in your stack — through Anthropic Computer Use, OpenAI’s Operator surface, or the open-source browser-use library — the temptation is to file them next to Selenium and Playwright. Same idea, just smarter, right?
No.
Selenium fails on selectors that drift. A browser agent fails on perception. The model is looking at either a DOM tree (accessibility-tree grounding) or a screenshot (pixel-coordinate grounding), and the failure modes those two channels produce are not interchangeable.
Why do browser and computer-use agents fail in ways that don’t resemble Selenium flakiness — and what makes the DOM-versus-screenshot grounding choice a runtime decision instead of a deployment detail?
DOM-grounded agents (Playwright MCP, Browser Use) read semantic structure — role, name, state — and emit actions like click(element_index=14). They are faster, cheaper, and more reliable when the target app exposes a clean DOM with proper ARIA roles. They break on canvas-rendered editors, shadow DOM components, Citrix sessions, and anything where the DOM does not tell the truth about what’s on screen.
Pixel-grounded agents (Claude’s computer use tool) look at a screenshot and emit click(x=412, y=308). They work on remote desktops, Electron apps, and legacy software that will never get an API. They are sensitive to OS theme, scaling, anti-aliasing, and dense layouts.
This is not a deployment detail you can decide later. It determines which class of bugs your team spends the next quarter debugging.
Concrete differences from Selenium thinking:
- Step efficiency is now a metric. Computer-use agents still take 1.4–2.7× the steps a human needs on the same task, per the OSWorld-Human results. A test that “passes” can still burn through your token budget on the way.
- Prompt injection is a new attack class. A page can contain text that overrides the agent’s instructions. Selenium scripts can’t be social-engineered; browser agents can.
- Authenticated, high-stakes flows are explicitly off-limits. Anthropic warns against using Computer Use for banking, medical, or other irreversible workflows. The agent’s confidence is uncorrelated with its accuracy.
The grounding strategy is a runtime decision because the same DOM might be addressable in one tab and a Flash-era canvas in the next. For a production team, this means the perception channel goes into the spec, not into the README. The mechanism analysis lives in DOM Trees vs Screenshots.
Agentic RAG Is a Controller, Not a Pipeline
If you have shipped a RAG system, you already know the shape. Embed the query, fetch the top-k chunks, stuff them in the prompt, decode an answer. Retrieval Augmented Agents look like the same thing with extra steps.
That framing is where teams lose two weeks.
The defining move of agentic RAG is not adding components. It is removing the assumption that retrieval should happen on every query. The agent decides whether to retrieve, what to re-query, and when to stop. The retriever is no longer a pipeline stage. It is a callable surface — bound to the model as a tool — and the LLM has become the scheduler.
The arithmetic of stacked LLM calls arrives right on schedule. If retrieve, rerank, and generate each succeed 95% of the time, the chain succeeds about 81% of the time. Each extra step lowers the ceiling. Each extra step also adds a context-window cost the prototype never paid.
Over-retrieval is the new memory leak. A “smarter” agent calls the retriever more times, packs more context, and ships a slower, more expensive answer than the deterministic search it replaced. Treating agentic RAG as “RAG with more steps” is exactly how you get there.
The transfer point that still works: think in contracts. The router, the retriever-and-grader, and the responder-and-verifier are independent contracts. If you can’t name which layer failed when the agent lies, you don’t have an agent — you have a prompt with extra steps. The full decomposition lives in the retrieval-augmented agent build guide.
Green Workflows That Lie
Of the four agent families landing in your stack, Workflow Orchestration For AI is the one with the most familiar shape. You already run Airflow, or Temporal, or Prefect, or something internal that does roughly what Step Functions does. You wire the LLM steps into the same DAG. The dashboard goes green.
This is where the inherited instincts fail hardest.
A traditional Airflow DAG fails loud. A failed task throws an exception. The graph stops. The pager fires. An LLM step inside that same DAG returns HTTP 200 with confidently wrong output. The DAG keeps walking. The downstream task processes the wrong answer. The customer is harmed. The runbook says nothing happened.
This is not a monitoring oversight. It is structural. APM tools evolved to catch failures that look like failures — stack traces, 5xx codes, timeouts. Looping or hallucinating agents return well-formed responses within normal latency. The dashboard cannot help you here without explicit semantic checks on the output itself.
The 2026 production pattern is hybrid: a durable execution engine on the outside (Temporal, AWS Step Functions, or LangGraph 1.0 with checkpointing), a reasoning framework on the inside. The split is clean — deterministic durable workflows for the outer skeleton, non-deterministic LLM calls inside named, idempotent activities.
What still transfers from your orchestration playbook:
- Idempotency keys. Still required. Now more so, because the engine will replay activities by design.
- Structured traces. Still required. Now extended to per-step outputs and per-decision metadata, not just per-task status.
- Checkpointing. Still required. The new question is: at what granularity? LangGraph saves state between nodes, not inside a node. If your long-running step doesn’t checkpoint, a host crash replays it from scratch — at full token cost.
What stops working: assuming a green workflow means a correct one. Add an output-quality check at every boundary where an LLM result leaves a node. The orchestrator can prove the steps ran. It cannot prove they were right. See DAGs vs. State Machines for the decision tree.
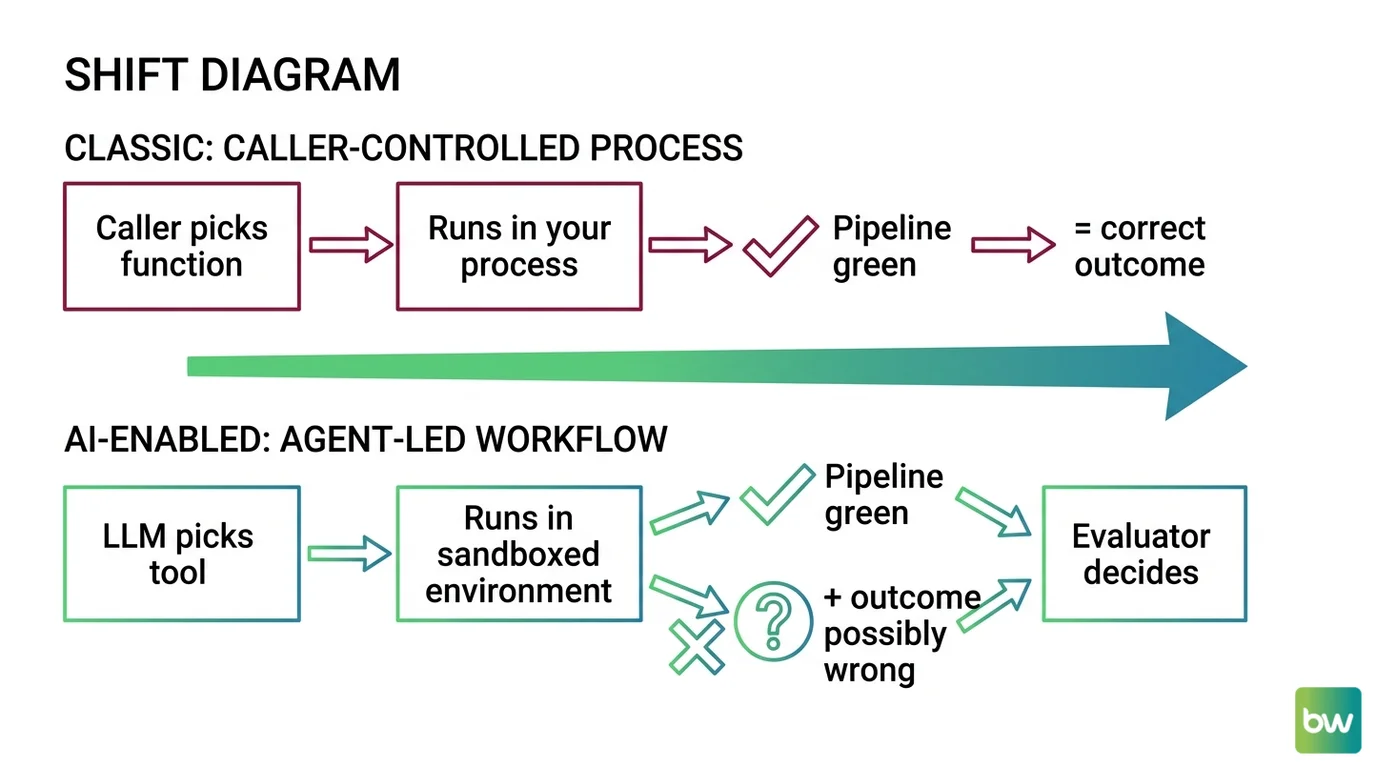
Shift Diagram: agent capabilities versus classical service patterns Classic: Request → Service → Response → Done AI: Goal → Plan → Tool call → Observation → Loop decision → Stop or repeat
Where To Read Next
You now have an updated map. Pick the deeper article by the failure mode you fear most: code-execution sandboxing, browser-grounded perception, retrieval control, or orchestration semantics. The mechanism details live there — this article only marks the boundary between what your old map still gets right and where it sends you off a cliff.
FAQ
Q: Why does my agent cost more than my microservice even when traffic is identical?
A: A microservice runs once per request. An agent runs an LLM loop with several iterations per request, and each iteration includes the growing context as input. Cost scales with loop depth multiplied by context length, not request count. Cap iterations explicitly.
Q: Can I run model-generated code in my existing CI container?
A: Not safely. Containers share a kernel with the host, and model-generated code can write syscalls that exploit it. Use a microVM-based sandbox (Firecracker via E2B), a user-space kernel (gVisor), or a managed code-execution tool. Scope credentials per session.
Q: Why does my orchestration dashboard show all-green while users report wrong answers?
A: LLM steps return HTTP 200 with well-formed output even when the content is wrong. Traditional APM detects timeouts and exceptions, not semantic failure. Add explicit output-quality checks at every node boundary where an LLM result leaves the step.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors