Benchmark Contamination, Score Divergence, and the Technical Limits of LLM Evaluation Harnesses

Table of Contents
ELI5
Evaluation harnesses run standardized tests on language models. The same model scores differently on the same test depending on which harness runs it — because prompt formatting, answer parsing, and contaminated test data all shift the results.
Claude 2.1 lost five percentage points on MMLU Benchmark when Stanford’s HELM ran the test instead of Anthropic’s internal evaluation. GPT-4 dropped four. Same models, same benchmark, same questions — different scores. This was documented in a 2024 analysis by Stanford CRFM, and the gap it revealed is not noise (Stanford CRFM Blog). It is a measurement artifact baked into the instruments themselves.
If you have ever compared two leaderboards and wondered which number to trust, the uncomfortable answer is: possibly neither — and definitely not without understanding what each tool measured and how it measured it.
The Anatomy of a Five-Point Gap
An Evaluation Harness is supposed to function like a standardized testing lab — controlled conditions, reproducible results, no ambiguity about what was measured. In practice, the labs disagree with each other. Sometimes they disagree with the people who built the model being tested. The question is why, and the answer turns out to be less about the models than about the instruments.
Why do lm-evaluation-harness and HELM give different scores for the same model?
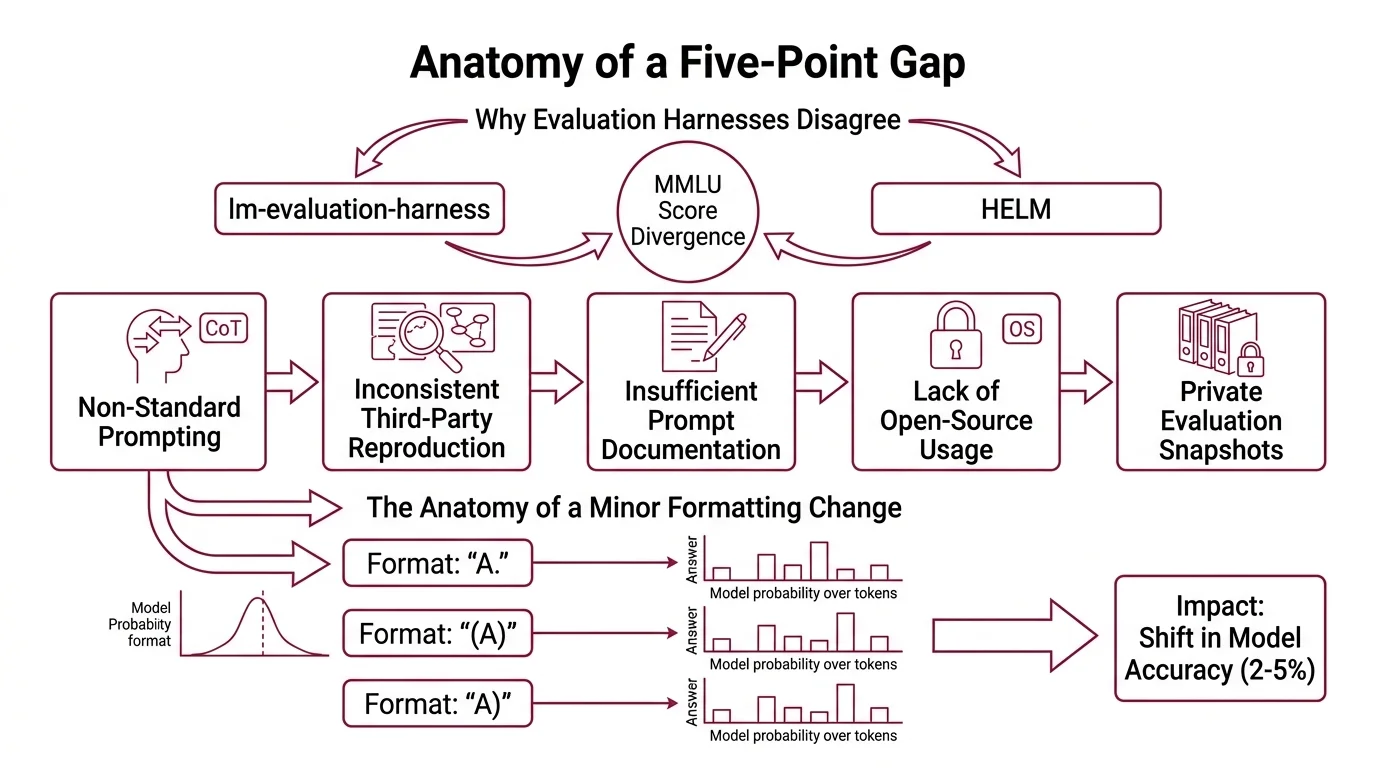
Stanford CRFM’s 2024 investigation into MMLU score divergence identified five root causes (Stanford CRFM Blog). The list reads like a forensic report on measurement failure.
Non-standard prompting: some evaluations use chain-of-thought reasoning with uncertainty routing while others stick to standard few-shot formatting. The model encounters a structurally different task depending on which harness constructed the prompt. Inconsistent third-party reproduction: labs attempt to reproduce published scores without access to the exact prompt templates or inference settings that generated the original numbers. Insufficient prompt documentation: the prompts model creators used are often described at a high level, omitting formatting details that turn out to matter enormously. Lack of open-source framework usage: proprietary evaluation pipelines make independent verification difficult. And private evaluation snapshots that remain unavailable for external review.
The most striking finding from that study: formatting choices alone — the difference between writing “A.” versus “(A)” versus “A)” — shifted accuracy by two to five percentage points. The model’s probability distribution over answer tokens is sensitive to the exact character sequence preceding the options. Change the parenthesis style, and you change which answer the model favors.
This is not a bug. It is the expected behavior of a system that generates outputs based on conditional probability over token sequences. The format is part of the input distribution; the model has learned format-specific biases during training, and those biases interact with every evaluation that touches them.
Helm Benchmark evaluates across multiple dimensions — accuracy, calibration, robustness, fairness, and efficiency — which means it applies a fundamentally different lens than EleutherAI’s lm-evaluation-harness, the framework the Hugging Face Open LLM Leaderboard uses as its backend (Hugging Face). Two instruments measuring the same model but defining “performance” through different axes will produce different numbers. The divergence is structural, not accidental.
The Exam That Was Already in the Textbook
Score divergence between harnesses is a tractable engineering problem — standardize prompts, publish templates, pin configurations, and the gap narrows. But beneath the measurement disagreement lies a deeper fault: the test itself may be compromised before any harness touches it.
How does benchmark contamination affect evaluation harness results?
Benchmark Contamination occurs when models inadvertently incorporate evaluation data from their training corpora — the model has, in effect, already seen the exam (Xu et al.). Its score reflects partial memorization, not generalized capability.
The mechanism is straightforward, but its consequences are corrosive. A contaminated model does not simply score higher than it should. It scores higher on the questions it memorized while performing at its actual level on questions it did not. The resulting score is a weighted average of recall and reasoning, and nothing in the output tells you which is which.
Not generalization. Recollection wearing its mask.
Standard Confusion Matrix analysis assumes the test set is independent of training data. When that assumption breaks, every metric derived from it — Precision, Recall, and F1 Score, accuracy, calibration — carries a bias whose direction and magnitude are unknown without separate contamination testing.
The problem compounds when the benchmark questions themselves contain errors. Stanford’s CRFM study found that 57% of the MMLU “Virology” subset questions contained errors — multiple correct answers, missing context, ambiguous phrasing (Stanford CRFM Blog). A model penalized for choosing the wrong right answer may be more capable than one that selected the designated correct option on a flawed question.
This is Model Evaluation theory’s oldest trap: the instrument is not merely measuring the subject — it is partially measuring itself.
The Structural Ceiling Above Every Leaderboard
The previous sections describe problems with specific benchmarks and specific configurations. The technical limitations of the evaluation ecosystem in 2026 run deeper than any individual tool.
What are the technical limitations of LLM evaluation harnesses in 2026?
As of early 2026, the ecosystem is fragmented across several major frameworks: EleutherAI’s lm-evaluation-harness (v0.4.11, the most recent tagged release as of February 2025, with active development continuing on the main branch), Stanford’s HELM (v0.5.14), OpenCompass (v0.5.2, covering 100+ datasets with strong multilingual support), Inspect AI (v0.3.205, with 100+ pre-built evaluations spanning coding, agentic tasks, and reasoning), and Deepeval (v3.9.5, offering pytest-style LLM testing with 50+ metrics). Each framework makes different architectural choices about prompting, scoring, and task selection — and those choices produce measurably different outcomes on identical models.
The Hugging Face Open LLM Leaderboard v2 moved to harder benchmarks — MMLU-Pro, GPQA, IFEval, BBH, MATH, and MuSR — partly in response to contamination concerns with the original suite. LiveBench attempts contamination-resistant evaluation by deriving questions from recent information sources; even so, as of its early 2025 assessment, top model accuracy remained below 70% across its 18 tasks (LiveBench). The difficulty increase is welcome, but it does not solve the underlying problem: no standardized criteria exist for evaluating the dynamic benchmarks designed to replace static ones (Chen et al.).
The structural limitations cluster around three axes. First, static datasets have a half-life — the longer a benchmark exists, the more likely its questions have appeared in training data, and no post-hoc contamination detection method is completely reliable. Second, evaluation harnesses impose formatting and prompting constraints that interact with model biases in ways that are benchmark-specific and difficult to predict before running the evaluation. Third, composite benchmarks that aggregate scores across diverse tasks compress the variance beneath a single number — a model might excel at mathematical reasoning and fail at instruction following, but the aggregate masks both.
Compatibility notes:
- lm-evaluation-harness v0.4.10+: Core package no longer auto-installs model backends. Explicit installation required (e.g.,
pip install lm_eval[hf]). CLI refactored with subcommands.- lm-evaluation-harness v0.4.9.2+: Python 3.8 support dropped. Minimum Python 3.10 required.
What the Scores Cannot Predict
The practical consequence of everything above is that evaluation scores are ordinal, not cardinal. They tell you roughly which model performs better under specific, stated conditions. They do not tell you how much better, and they do not guarantee that the ordering holds when the conditions change.
If you switch the prompt format, expect the ranking to shift. If you evaluate on a benchmark older than two years, expect some fraction of the score to reflect memorization rather than capability. If you compare results across harnesses without controlling for prompt template and answer parsing logic, the comparison is not informative — it is noise with decimal places.
Rule of thumb: Treat leaderboard scores as approximate rank orderings under stated conditions, not as absolute measures of model capability. When the evaluation conditions are unstated, the score is approximately meaningless.
When it breaks: Evaluation harnesses fail silently when contamination is present. The scores look normal, the rankings look plausible, and nothing in the output flags that the measurement is compromised. The failure mode is not a crash or an error; it is a number that looks right and is not.
The Data Says
The same model, tested on the same benchmark by different evaluation harnesses, can diverge by up to five percentage points — a gap that originates from formatting choices, prompting strategies, and documentation failures rather than model differences. When you add benchmark contamination and ground-truth errors to the measurement chain, the score becomes a composite of capability, memorization, and instrument bias in unknown proportions. The number on the leaderboard is not wrong. It is incomplete, and knowing what it leaves out matters more than the number itself.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors