Benchmark Contamination, Metric Gaming, and the Hard Limits of LLM Evaluation

Table of Contents
ELI5
Benchmark contamination happens when an LLM’s training data includes the test questions it will be scored on — inflating rankings without improving real capability.
Models score 70–80% on a major coding benchmark. The press releases write themselves. Then someone builds a harder version of the same test — same domain, same task type, genuinely unseen problems — and scores collapse to roughly 23%. That gap is not a rounding error. It is the distance between memorization and competence, and it sits at the center of every Model Evaluation leaderboard you have read this year.
The Fingerprints Inside the Training Data
Evaluation depends on a basic assumption: the test is unknown to the test-taker. When that assumption breaks, the score measures recall, not reasoning. And with large language models trained on vast internet corpora, that assumption breaks more often than anyone publishing a leaderboard would prefer to acknowledge.
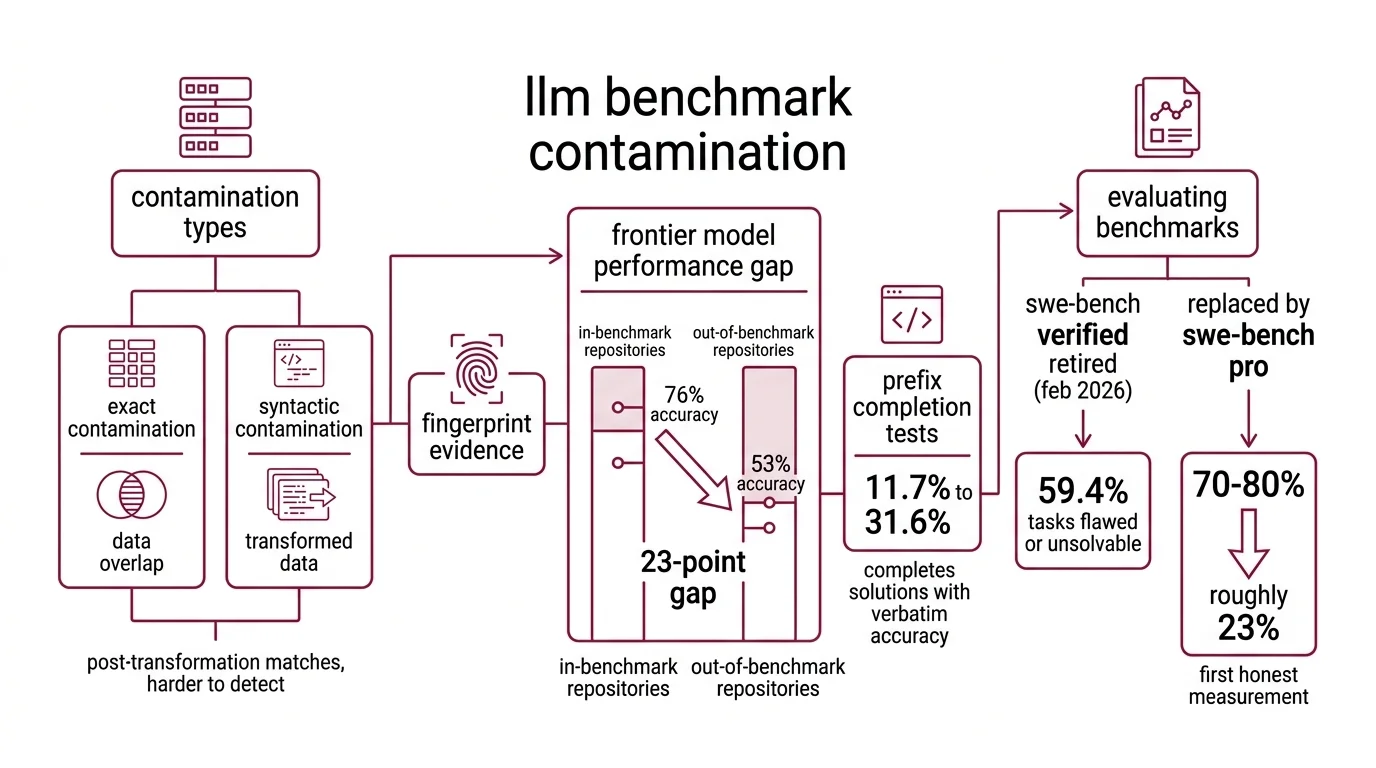
What is benchmark contamination and how does it affect LLM rankings
Benchmark Contamination comes in two documented forms — exact contamination, where identical data appears in both training and test sets, and syntactic contamination, where post-transformation matches survive deduplication filters (Xu et al.). The distinction matters because syntactic contamination is harder to detect and nearly impossible to prevent at scale.
The evidence is no longer circumstantial. A study of SWE Bench found that frontier models predict file paths in benchmark repositories with 76% accuracy — but accuracy drops to 53% on repositories outside the benchmark (Liang et al.). That 23-point gap is a fingerprint. The models are not generalizing their understanding of codebases; they are recognizing specific ones they encountered during training.
The prefix completion tests sharpen the picture further. When given the first few tokens of a benchmark solution, frontier models complete the sequence with verbatim accuracy between 11.7% and 31.6% (Liang et al.). A model that had genuinely never seen those solutions should complete the prefixes at near-chance level.
It does not.
In February 2026, OpenAI retired SWE-bench Verified entirely, disclosing that 59.4% of audited tasks were flawed or unsolvable (OpenAI Blog). The replacement — SWE-bench Pro — immediately cut top scores to roughly 23%, compared to the 70–80% that the same models had achieved on Verified. That collapse was not a regression in capability. It was the first honest measurement.
A separate analysis confirmed 10.6% direct data leakage between SWE-bench Verified and StarCoder’s training corpus, as documented by LessLeak-Bench and surveyed in Xu et al. That figure likely undercounts the true contamination; it captures only exact string matches, not the syntactic variants that evade character-level detection.
The contamination is structural: training pipelines ingest the open internet, and benchmarks live on the open internet. The overlap is not a conspiracy. It is an architectural inevitability — and the effect on rankings is identical regardless of intent.
The Asymptote That Tells You Nothing
Contamination is one failure mode. Saturation is another, and in some ways it is more corrosive — because a saturated benchmark still looks functional. The scores still increment. The leaderboard still updates. The numbers still appear in press releases. They just stop distinguishing anything.
Why do LLM benchmark scores fail to predict real-world performance
HumanEval is a case study in slow death by familiarity. Its coding problems have been public since 2021. Frontier models now score above 93%, clustering within a few percentage points of each other (LXT). The benchmark is not separating capability anymore; it is confirming that every serious lab has optimized against the same problem set. HumanEval+ and BigCodeBench exist as successors, but the original still surfaces in product comparisons as if it carried signal.
MMLU tells a parallel story. Frontier models score between 88% and 93%, with top performers separated by two to four points (LXT). At that compression, the error bars overlap. MMLU-Pro was developed to restore discriminative power, but the original persists in evaluation suites — a number that occupies space without conveying meaning.
The most revealing evidence comes from the gap between these saturated tests and genuinely novel ones. Models scoring above 80% on undergraduate-level benchmarks drop to 30–35% on Humanity’s Last Exam, which sources expert-level questions from domains with minimal internet coverage (Goodeye Labs). That is not a gentle decline. It is a cliff — and it maps the precise boundary between pattern-matched recall and reasoning under novel conditions.
LiveCodeBench provides the temporal proof. Models show score drops between 20% and 30% on coding problems released after their training cutoffs (Goodeye Labs). Before the cutoff: strong scores. After: measurably worse. The variable that changed was not problem difficulty.
It was whether the model had seen the problems before.
Static benchmarks have a shelf life. An industry estimate puts it at six to twelve months before contamination or overfitting renders a benchmark unreliable as a discriminator (Goodeye Labs). That estimate is not a peer-reviewed finding, but the decay pattern it describes is visible across every major evaluation suite that has persisted long enough to be studied.
The Observer Changes the Experiment
If static benchmarks decay, the obvious response is to build dynamic ones. Several teams have. But dynamic evaluation introduces its own epistemological problem — and the most subtle failure mode is that the measurement apparatus itself becomes part of the system being measured.
What are the technical limitations of automated LLM evaluation metrics in 2026
Traditional metrics like BLEU and Perplexity were designed for narrow, well-defined tasks — translation quality scoring, next-token prediction loss. They function within those bounds. They say almost nothing about whether a model follows complex instructions, maintains coherence across long conversations, or resists hallucination under adversarial inputs.
The industry response has been LLM-as-a-judge — using one model to evaluate another’s outputs. The approach scales well and costs a fraction of human evaluation. It also inherits every bias embedded in the judge model, creating a circularity that is difficult to escape: you are measuring capability with an instrument whose own capability you cannot independently verify. A survey of LLM-as-a-judge methods documents systematic biases toward verbose outputs, toward the judge’s own stylistic preferences, and toward answers that resemble the judge model’s training distribution (Gu et al.). When the ruler is made of the same material as the thing being measured, the measurement bends.
Arena — formerly Chatbot Arena, rebranded in January 2026 — represents the human-evaluation alternative. With over six million votes, it generates ELO Rating scores using a Bradley-Terry model (Wikipedia). As of March 2026, Claude Opus 4.6 holds the top position at 1504 Elo, with Gemini 3.1 Pro at 1500 (Arena Leaderboard). The methodology is sound, but it measures aggregate user preference — which correlates with, but is not identical to, technical accuracy. A model can be preferred for conversational fluency while quietly failing at factual precision in domain-specific tasks.
LiveBench takes a different structural approach: monthly new questions drawn from recent sources, with objective ground-truth answers that require no LLM judge (LiveBench). LiveCodeBench applies the same principle to code generation. These contamination-resistant designs represent the current best practice for evaluation integrity — but they demand continuous curation, and their task coverage is necessarily narrower than the static suites they aim to replace.
The Confusion Matrix — the foundational diagnostic for classification tasks — illustrates what evaluation should provide but rarely does: not a single aggregate score, but a map of where the model succeeds and where it fails. A model scoring well overall might perform poorly on the specific task distribution that matters to your deployment. The aggregate hides the failure, and the leaderboard rewards the aggregate.
What Breaks When You Trust the Number
The implications follow a pattern that is worth making explicit.
If you select a model based on a saturated benchmark, you are optimizing for a test that no longer discriminates between candidates. If you rely on a static coding benchmark from before 2025 without checking its contamination status, your evaluation is measuring memory — not engineering competence.
If a benchmark’s test set has been public for more than a year, assume some degree of contamination in any model trained on web-scale data. The question is not whether leakage occurred, but how much it inflates the reported score.
If two models score within a few points of each other on MMLU or HumanEval, that difference is measurement noise. Those benchmarks have compressed the performance range to the point where rank ordering is arbitrary.
If your evaluation relies on LLM-as-a-judge exclusively, you are systematically blind to the judge model’s own biases. Cross-reference with human evaluation or ground-truth benchmarks to catch what the automated judge cannot see.
Rule of thumb: No single benchmark should carry the deciding weight in your model selection. A portfolio of contamination-resistant, task-specific evaluations will outlast any individual leaderboard.
When it breaks: Evaluation frameworks fail when the models being evaluated become sophisticated enough to pattern-match the evaluation process itself. Dynamic benchmarks slow this arms race; they do not end it. The structural tension between open, reproducible science and contamination-resistant measurement has no clean resolution — keeping tests secret improves validity at the cost of verifiability, and publishing them guarantees their eventual corruption.
The Data Says
The era of trusting a single benchmark number to represent model quality is over. Contamination is structural — a consequence of training on the same internet where the tests live. Saturation is accelerating — compressing the score range until leaderboard differences are indistinguishable from noise. And automated metrics carry the biases of their own architecture. The evaluations that resist gaming are the ones that demand continuous renewal, and that renewal has a cost no leaderboard currently accounts for.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors