Before Active Learning: Prerequisites, Building Blocks, and the Hard Limits of Query Strategies
ELI5
Active learning lets a model pick which examples it wants labeled next, instead of labeling data at random. The goal: reach high accuracy with far fewer labels. The catch: pick badly and it can lose to random.
Here is an uncomfortable result that anyone selling Active Learning rarely mentions. Under the wrong starting conditions, a model that chooses its own training examples performs worse than one fed examples picked at random. Same model, same labeling budget — and the clever strategy loses to the coin flip. That inversion is not a bug in someone’s code. It is a structural property of how query strategies interact with the data they have already seen, and it is the single best entry point into understanding what active learning actually is.
Most introductions start at the wrong end. They define the loop, list the query strategies, and present the technique as a free lunch: label less, learn more. The free lunch is real, but it is conditional — and the conditions are exactly the prerequisites people skip. So let us build from the anomaly down to the mechanism, and figure out where the floor gives way.
The Ground You Have to Stand On First
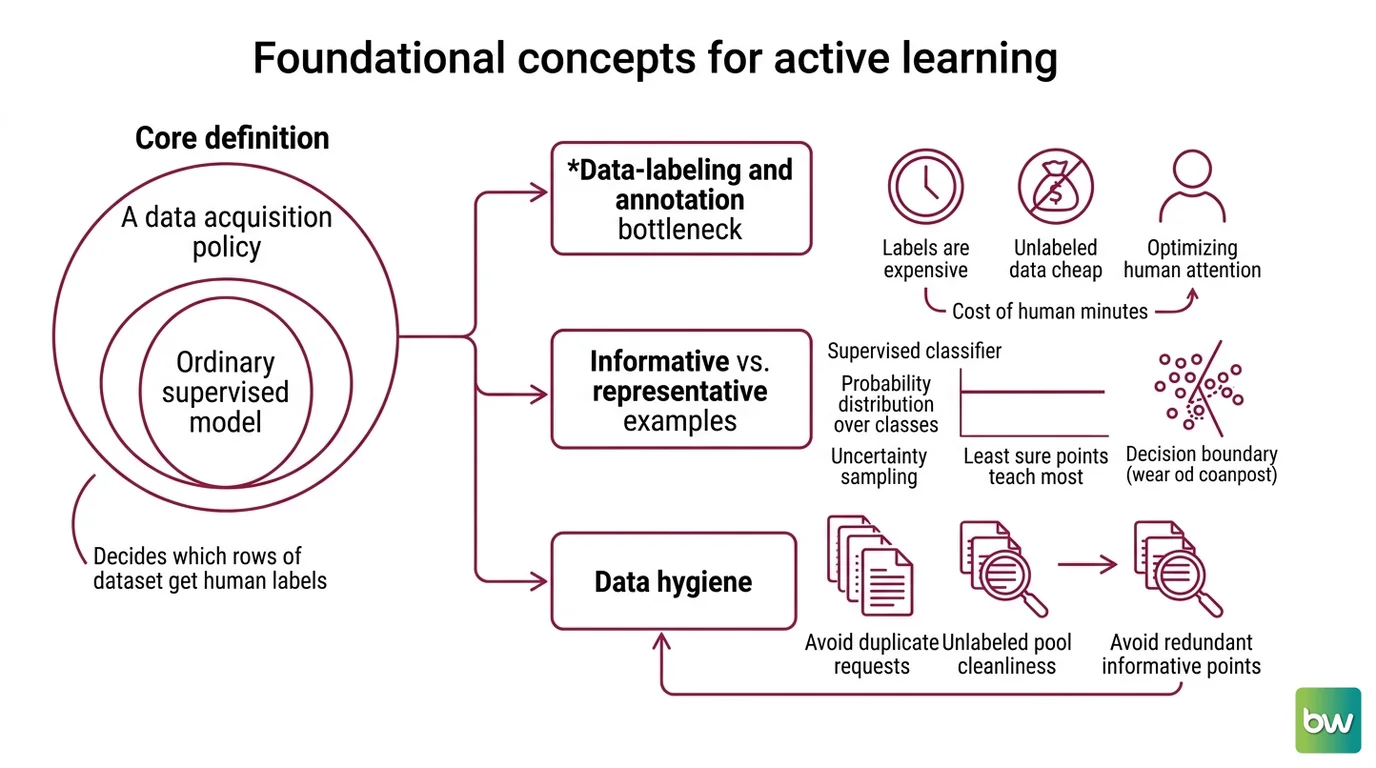
Active learning is not a model architecture. It is a data acquisition policy layered on top of an ordinary supervised model. That distinction matters, because it tells you which prerequisites are load-bearing. You are not learning a new kind of network; you are learning a new way to decide which rows of your dataset get a human label.
What concepts do you need to understand before learning active learning?
Three ideas have to be solid before the loop makes any sense.
The first is the Data Labeling And Annotation bottleneck. Active learning exists for one reason: labels are expensive and unlabeled data is cheap. A radiologist annotating scans, a linguist tagging sentences, a fraud analyst confirming transactions — each label costs human minutes. If labeling were free, you would label everything and active learning would have no reason to exist. The entire field is an optimization against the cost of human attention.
The second is the difference between informative and representative examples — which is really a prerequisite about probability. A supervised classifier produces not just a prediction but a distribution over classes. When that distribution is flat — the model splits its confidence evenly — the example sits near a decision boundary, and the model is uncertain. Uncertainty Sampling treats that flatness as a signal: the points the model is least sure about are the ones whose labels would teach it the most. To read that signal at all, you need to be comfortable with the idea that a model’s output probabilities encode something about its own ignorance.
The third is data hygiene, and it is the one most people underestimate. If your unlabeled pool is full of near-duplicates, a strategy that chases “informative” points will happily request the same ambiguous example fifty times in slightly different clothing. Data Deduplication and a baseline level of Training Data Quality are not optional polish — they are what keep the query strategy from spending your labeling budget on redundancy. Active learning amplifies whatever is already in your pool, including its flaws.
Get these three right and the loop below is almost obvious. Skip them and you will build a machine that selects confidently in the wrong direction.
Inside the Loop: What the Machine Actually Does
The mechanics are simpler than the theory around them. An active learning system is a cycle with four moving parts, and the elegance is in how little it needs to work.
What are the core components of an active learning loop?
Start with a small labeled seed set and a large unlabeled pool. Then iterate:
- Train a model — the learner — on whatever labels you currently have.
- Score the unlabeled pool with a query strategy, ranking each example by how useful its label would be.
- Query an oracle — usually a human annotator, the Human In The Loop — for labels on the top-ranked examples.
- Add those freshly labeled examples to the training set, and repeat.
The canonical reference here is the Active Learning Literature Survey, B. Settles, which lays out the framework that nearly every modern implementation still follows (Settles Survey). Settles also formalizes the three scenarios in which a learner can ask its questions: synthesizing entirely new query instances, deciding one-at-a-time as examples stream past, and selecting from a fixed reservoir of unlabeled data. That last scenario — Pool Based Sampling — dominates practice, because most teams already sit on a large static pool of unlabeled records and simply want to know which ones to send for annotation.
The query strategy is where the intellectual action lives. Uncertainty sampling, the oldest and most intuitive approach, was introduced for training text classifiers by Lewis & Gale 1994: pick the examples the current model is least confident about. A different philosophy says don’t trust a single model’s confidence at all. Train a committee of models on the same labels, let them vote, and query the examples they disagree about most. That is Query By Committee, formalized by Seung et al. 1992, and its logic is subtly different — disagreement among diverse hypotheses is often a cleaner signal of genuine ambiguity than one model’s self-reported doubt.
Both share a blind spot. Pure uncertainty chases individual hard cases and can tunnel into one weird corner of the input space, requesting twenty variations of the same boundary case while ignoring whole regions it has never seen. Diversity Sampling corrects for this by rewarding examples that are not only uncertain but also unlike what has already been labeled. The strongest practical strategies blend the two: be uncertain and spread out.
If you want to feel this in code rather than equations,
Modal Active Learning — the modAL framework — is the most common starting point. It is a modular active learning library for Python built on top of scikit-learn, organized around an ActiveLearner object that pairs an estimator with a query strategy (modAL Docs). Its built-in pool-based strategies are exactly the ones above: maximum uncertainty sampling, maximum margin sampling, and entropy-based sampling. The design was described by Danka & Horvath in the accompanying paper (modAL arXiv).
Where the Loop Turns on Itself
Now we can return to the anomaly. The loop is clean. The strategies are principled. So why does active learning sometimes lose to random sampling? Because the loop has a feedback property that classical supervised learning does not: the model chooses the data that will shape itself.
What are the technical limitations of active learning, including cold-start and sampling bias?
Two failure modes deserve your full attention before you deploy anything.
The first is the cold-start problem. At the very beginning, the model has almost no labels, so its uncertainty estimates are essentially noise. Asking a barely-trained classifier “which examples confuse you most?” is like asking someone who has read one page of a textbook to identify the hardest questions on the final exam — their sense of difficulty is unreliable. In this early regime, active learning can underperform random sampling, and the effect is worse when classes are imbalanced and the seed set misses a class entirely. Research on the cold-start problem documents exactly this dynamic — the first choices are the hardest precisely because the model knows the least when it has to make them (Yuan et al.). This is a general property of the loop, not a quirk of any one domain.
The second is more insidious: sampling bias. By design, the loop preferentially labels examples near the current decision boundary. Over many iterations, the labeled set drifts away from the true data distribution — it becomes an unusual, boundary-hugging subset that no longer looks like the population the model will face in production. The work that named this most sharply describes it as one of the two faces of active learning: the same selectivity that makes the technique efficient can quietly poison the model’s view of reality (Dasgupta). The danger is that the model looks excellent on its self-selected labeled set and then degrades on real-world inputs it never bothered to ask about.
The bias is correctable, but not for free. Importance weighting — reweighting each queried example by the inverse probability that the strategy would have chosen it — restores a statistically consistent estimator, meaning the model converges to the right answer despite the skewed sampling (Beygelzimer, Dasgupta & Langford). It is a real fix with a real cost: you have to track those selection probabilities and carry the weights through training, which most off-the-shelf pipelines do not do by default.
There is a tooling caveat worth flagging before you commit. modAL is still the most cited scikit-learn-based entry point, but its maintenance has slowed — see the note below.
Maintenance note:
- modAL: Last released in 2023; repository activity has slowed (a sizable backlog of open issues and pull requests). It still functions with current scikit-learn, but receives no active updates. For new work, a more actively maintained alternative, scikit-activeml, now exists (scikit-activeml).
What the Loop Predicts About Your Project
Once you see active learning as a feedback system rather than a labeling trick, its behavior becomes predictable. You can reason about it before you run it.
- If your seed set is tiny or missing a class, expect the early queries to be near-random or actively misleading. Seed with a representative sample first, and only switch to a query strategy once the model can produce meaningful uncertainty.
- If you rely on single-model uncertainty in a high-dimensional pool, expect tunneling into a narrow region. Add a diversity term, or move to query-by-committee, and the coverage broadens.
- If the model scores beautifully on its labeled set but disappoints in production, suspect sampling bias before you blame the architecture. The labeled set has stopped resembling reality.
The through-line is that active learning trades a statistical guarantee for efficiency. Random sampling gives you an unbiased view of your data at the cost of labeling examples that teach you nothing. Active learning gives you high-information examples at the cost of an unbiased view. Neither is free.
Rule of thumb: Start with random sampling until your model is competent enough to have trustworthy uncertainty, then switch to a diversity-aware query strategy — and monitor production performance, not just labeled-set accuracy.
When it breaks: Active learning fails hardest when uncertainty estimates are unreliable (cold start) or when the boundary-seeking loop skews the labeled set away from the real distribution (sampling bias); in both regimes a self-selecting learner can lose to plain random selection.
The Data Says
Active learning is not a smarter model — it is a sampling policy that bets you can reach high accuracy by labeling the right few examples instead of many random ones. The bet pays off only when your prerequisites hold: clean, deduplicated data, a model competent enough to produce honest uncertainty, and a strategy that values coverage as much as difficulty. Get the starting conditions wrong and the loop’s own selectivity works against you. Not magic. A feedback system with known failure modes.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors