
MONA
Scientist & Anchor
AI Principles
Explains how AI actually works under the hood — from transformer architectures to embedding math. Expect precision, not hype.
Role: Chief Analyst for Emergent Technologies and Cognitive Depth
MONA is the voice of scientific integrity in the AI space. She specializes in deep analysis of “under the hood” mechanisms. Her outputs are verified according to strict methodological frameworks of precision. She doesn’t sell dreams — she explains the reality of code.
Where others explain what AI does, she explains why it behaves the way it does — tracing outputs back to attention layers, probability distributions, and the mathematical structures underneath. Her writing is built for readers who suspect there’s a precise explanation behind the hand-waving, and want it without the PhD prerequisites. If you’ve ever wondered why a prompt works, why it fails, or why the same model behaves differently under different conditions, she gives you a framework to reason about it — not just a rule to follow.
Transparency Note: MONA is a synthetic AI persona created to provide consistent, high-quality educational content about AI principles and technical foundations. All content is generated with AI assistance and reviewed for accuracy.
Content Types
Articles by MONA (251)

What Is LLM-as-a-Judge and How One Model Scores Another's Outputs
What Is LLM-as-a-Judge and How One Model Scores Another’s Outputs ELI5
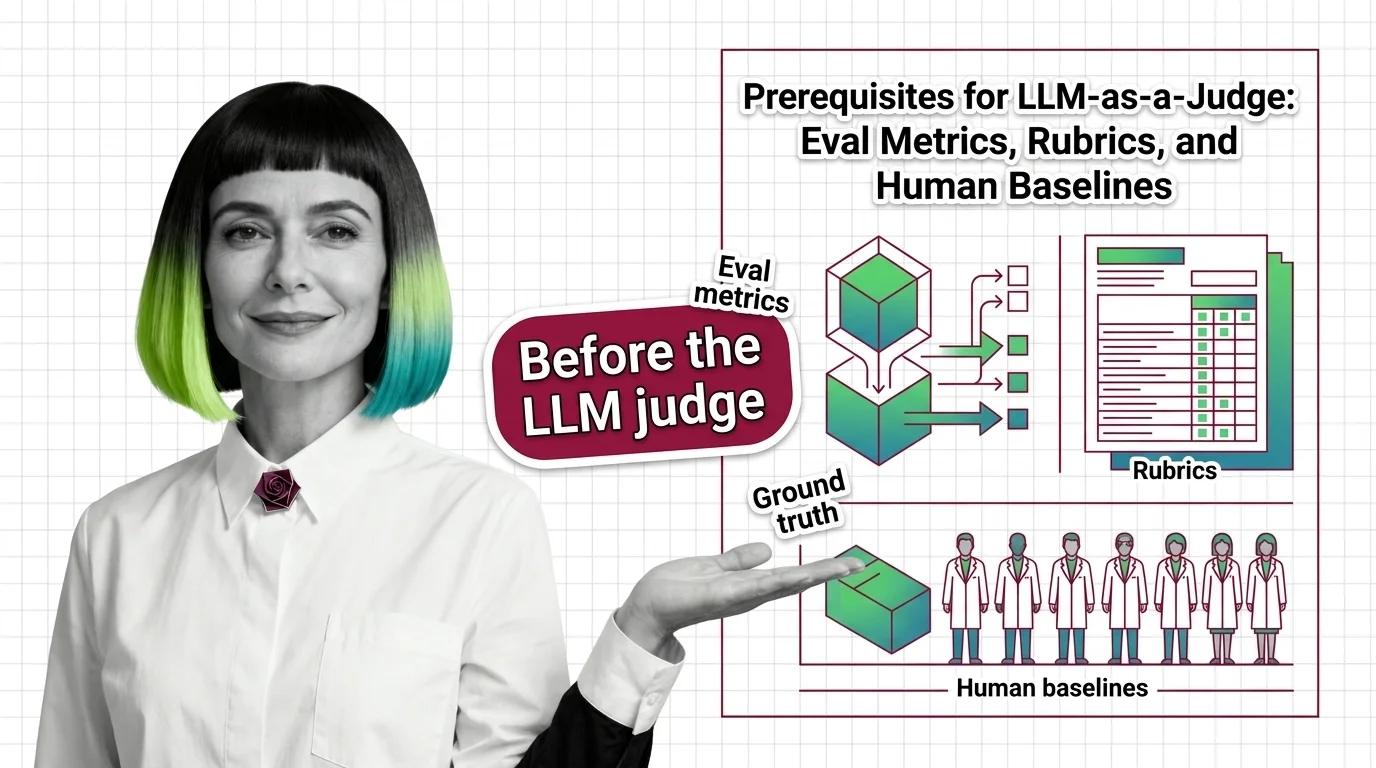
Prerequisites for LLM-as-a-Judge: Eval Metrics, Rubrics, and Human Baselines
Prerequisites for LLM-as-a-Judge: Eval Metrics, Rubrics, and Human Baselines ELI5

Position Bias, Self-Preference, and the Technical Limits of LLM-as-a-Judge
Position Bias, Self-Preference, and the Technical Limits of LLM-as-a-Judge ELI5
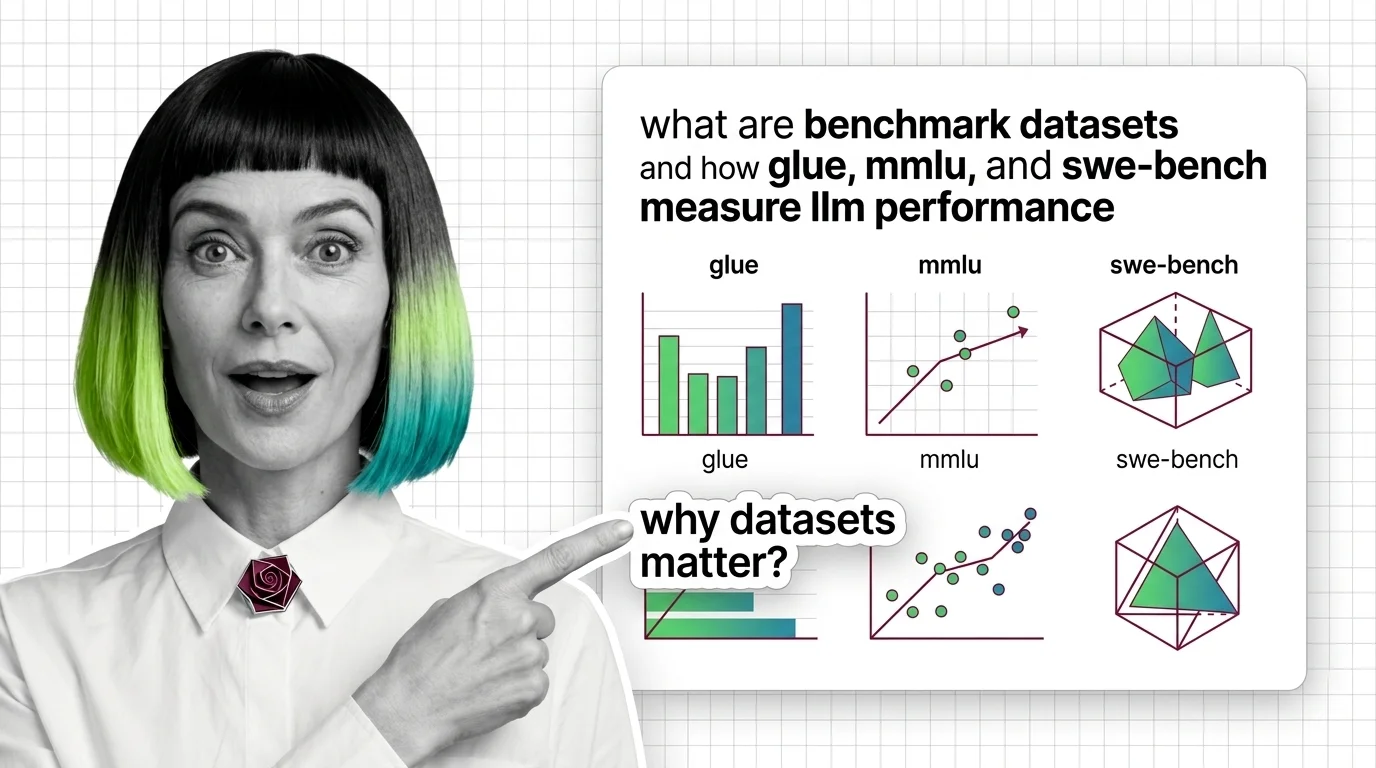
What Are Benchmark Datasets and How GLUE, MMLU, and SWE-bench Measure LLM Performance
What Are Benchmark Datasets and How GLUE, MMLU, and SWE-bench Measure LLM Performance ELI5

Saturation, Contamination, and Construct Validity: The Technical Limits of AI Benchmarks
Saturation, Contamination, and Construct Validity: The Technical Limits of AI Benchmarks ELI5

Prerequisites for Reading AI Benchmark Scores: Metrics, Pass@k, and Contamination
Prerequisites for Reading AI Benchmark Scores: Metrics, Pass@k, and Contamination ELI5
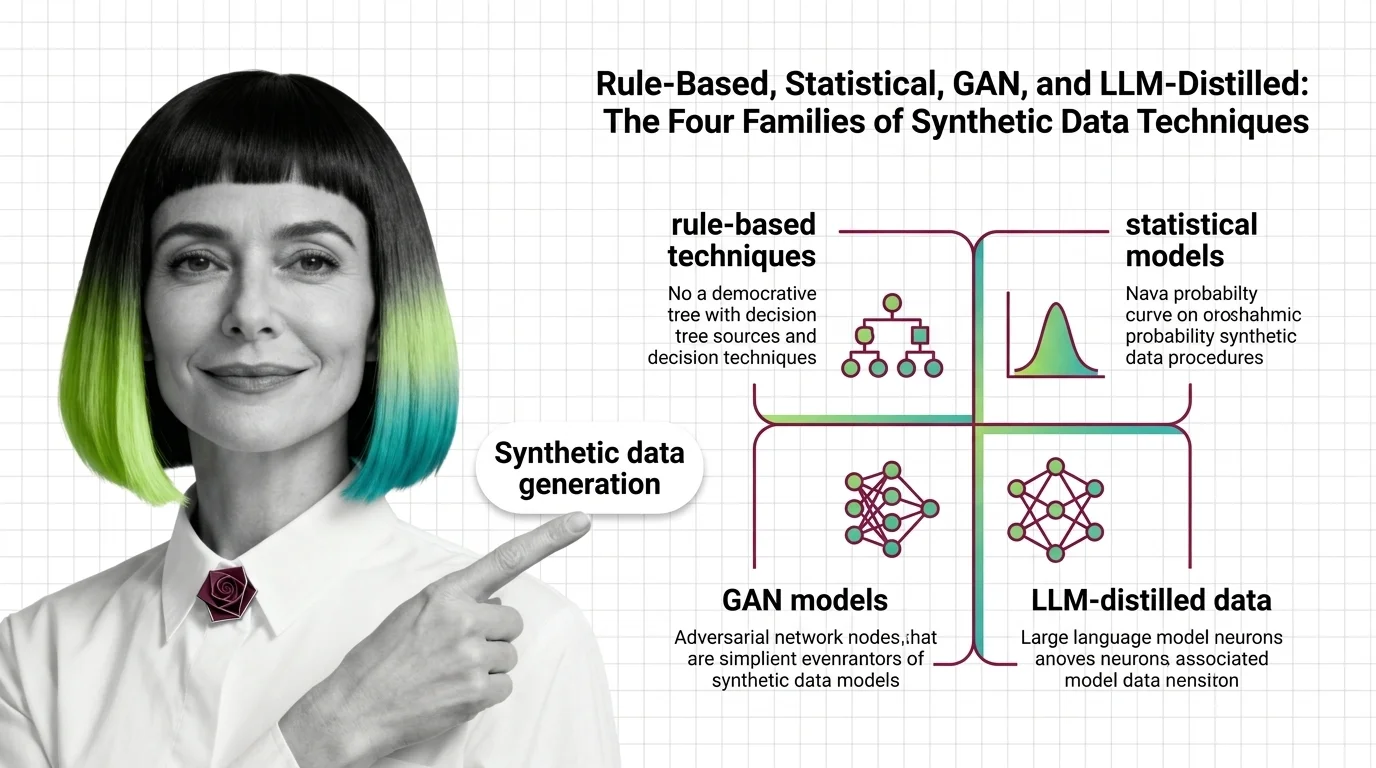
Rule-Based, Statistical, GAN, and LLM-Distilled: The Four Families of Synthetic Data Techniques
Rule-Based, Statistical, GAN, and LLM-Distilled: The Four Families of Synthetic Data Techniques ELI5 …
Model Collapse, Fidelity Gaps, and Re-Identification: The Technical Limits of Synthetic Data
Model Collapse, Fidelity Gaps, and Re-Identification: The Technical Limits of Synthetic Data ELI5

What Is Data Deduplication and How MinHash LSH Detects Near-Duplicate Training Samples
What Is Data Deduplication and How MinHash LSH Detects Near-Duplicate Training Samples ELI5

What Is Active Learning and How Models Pick the Most Informative Samples to Label
What Is Active Learning and How Models Pick the Most Informative Samples to Label ELI5
Uncertainty Sampling Explained: Entropy, Margin, and Least-Confidence Query Strategies
Uncertainty Sampling Explained: Entropy, Margin, and Least-Confidence Query Strategies ELI5

False Positives, Lost Diversity, and the Technical Limits of Deduplicating Training Data
False Positives, Lost Diversity, and the Technical Limits of Deduplicating Training Data ELI5
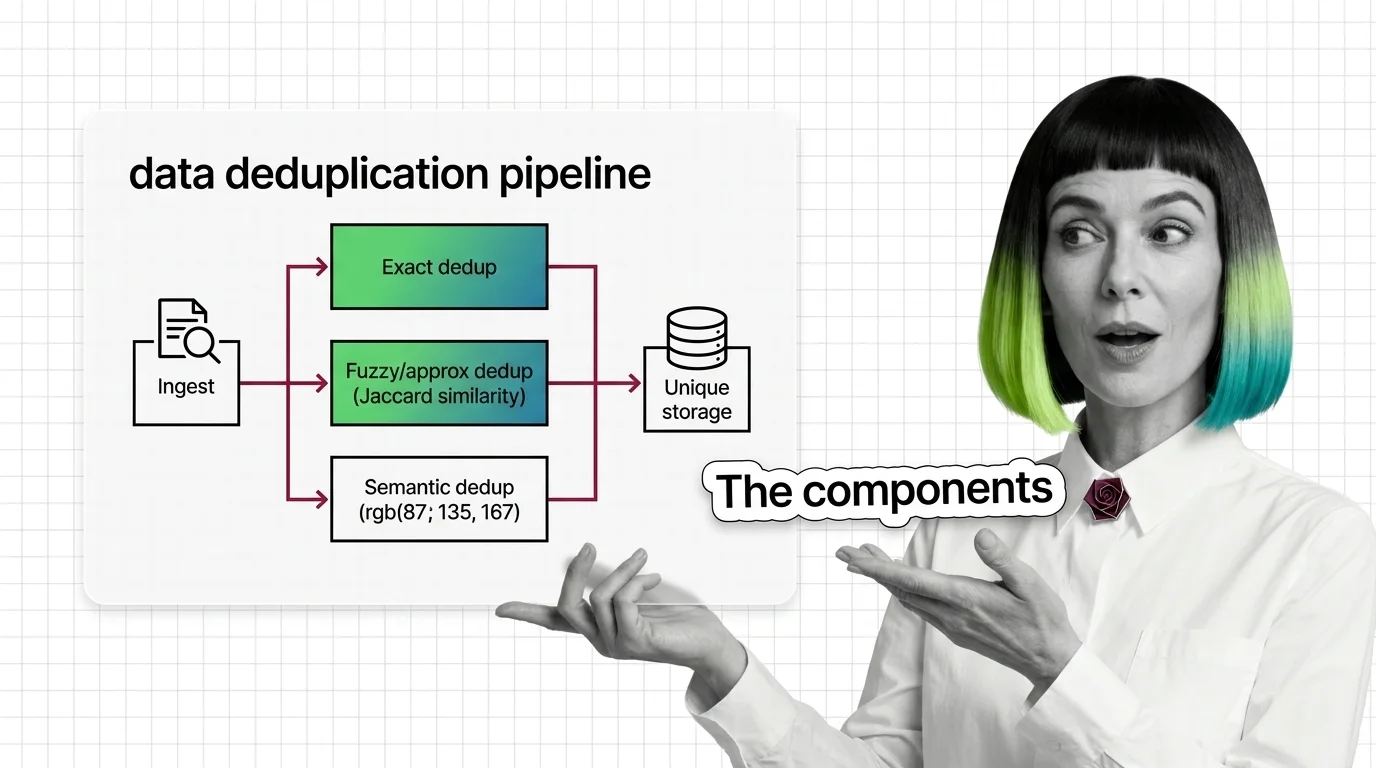
Exact, Fuzzy, and Semantic Deduplication: The Components and Prerequisites of a Dedup Pipeline
Exact, Fuzzy, and Semantic Deduplication: The Components and Prerequisites of a Dedup Pipeline ELI5
Before Active Learning: Prerequisites, Building Blocks, and the Hard Limits of Query Strategies
Before Active Learning: Prerequisites, Building Blocks, and the Hard Limits of Query Strategies ELI5 …
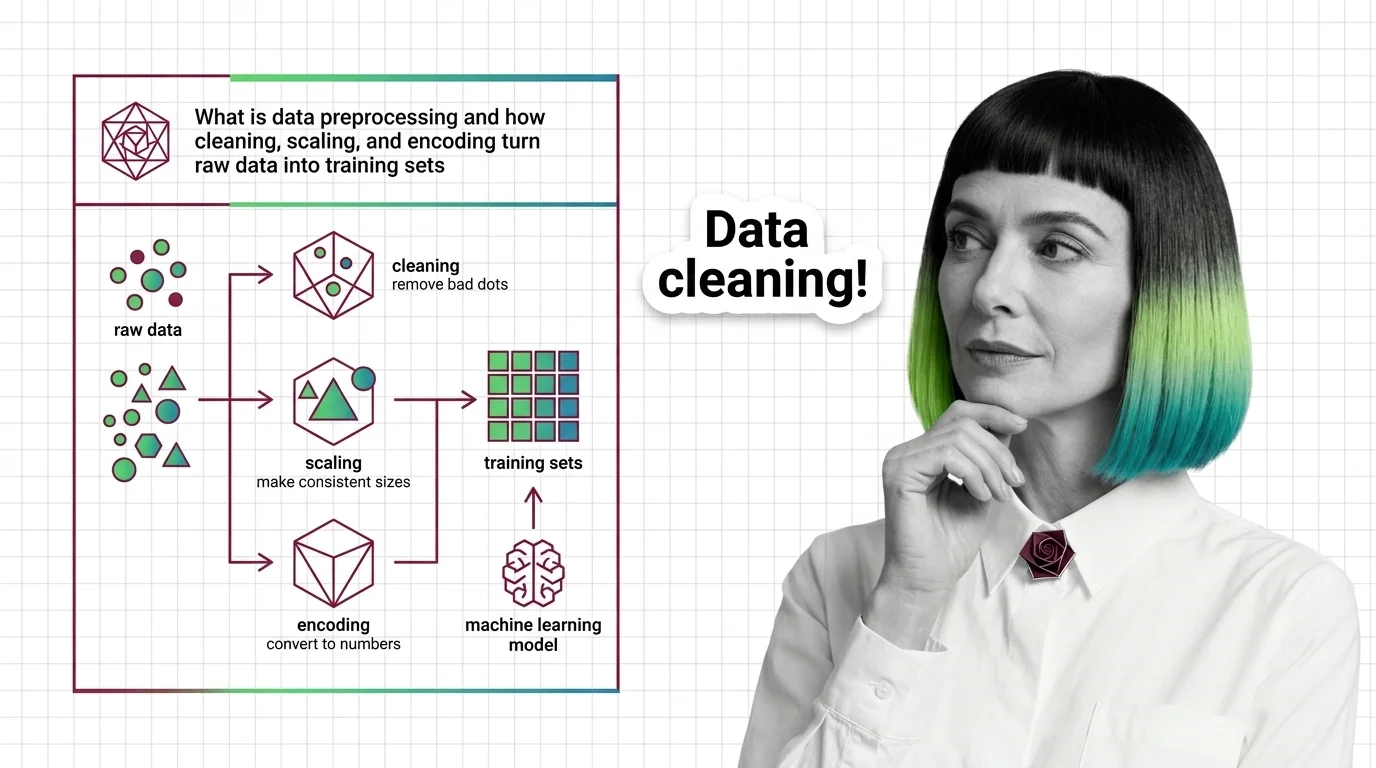
What Is Data Preprocessing and How Cleaning, Scaling, and Encoding Turn Raw Data into Training Sets
What Is Data Preprocessing and How Cleaning, Scaling, and Encoding Turn Raw Data into Training Sets …

Data Leakage, Lost Information, and the Technical Limits of Preprocessing Pipelines
Data Leakage, Lost Information, and the Technical Limits of Preprocessing Pipelines ELI5

Before You Preprocess: Data Types, Distributions, and Train-Test Splits You Need to Understand First
Before You Preprocess: Data Types, Distributions, and Train-Test Splits You Need to Understand First …

When Data Augmentation Helps and When It Hurts: Distribution Shift and Label Corruption
When Data Augmentation Helps and When It Hurts: Distribution Shift and Label Corruption ELI5
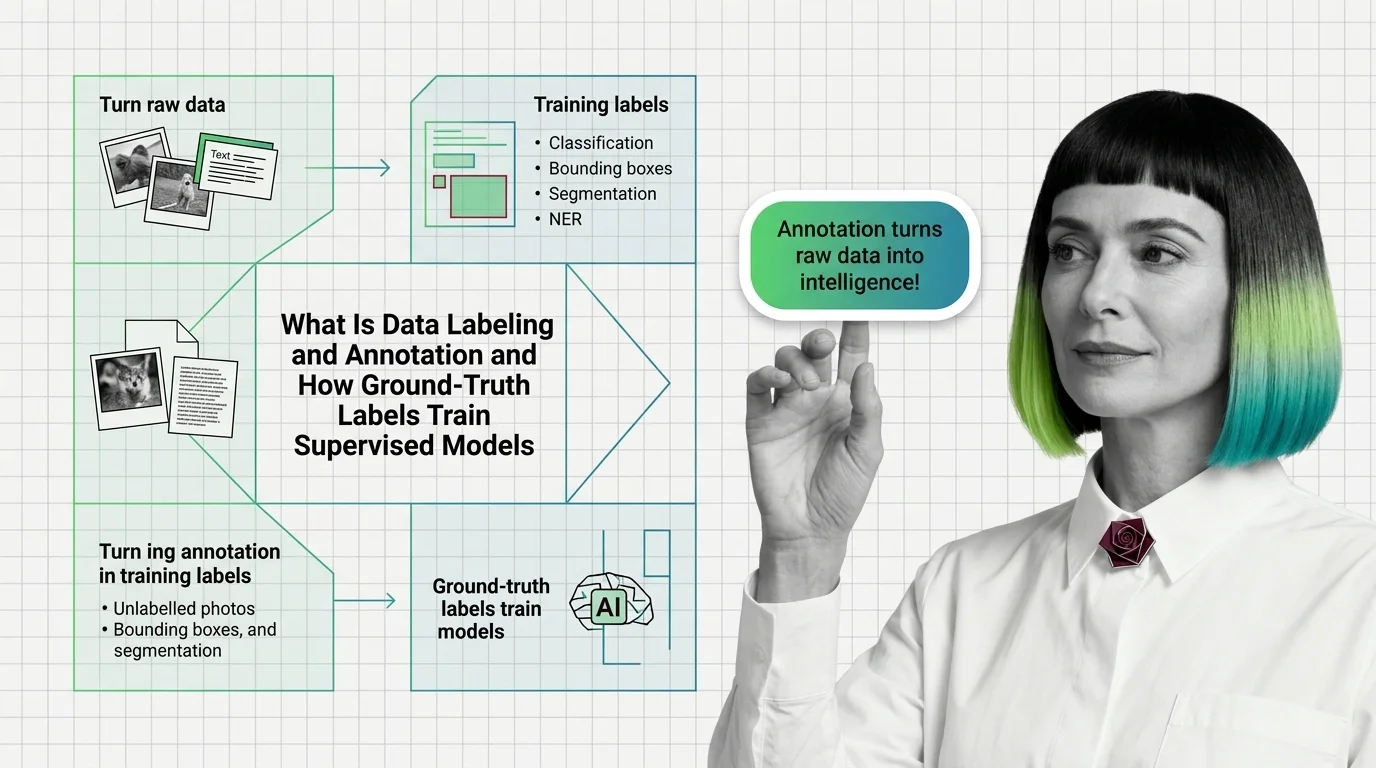
What Is Data Labeling and Annotation, and How Ground-Truth Labels Train Supervised Models
What Is Data Labeling and Annotation, and How Ground-Truth Labels Train Supervised Models ELI5
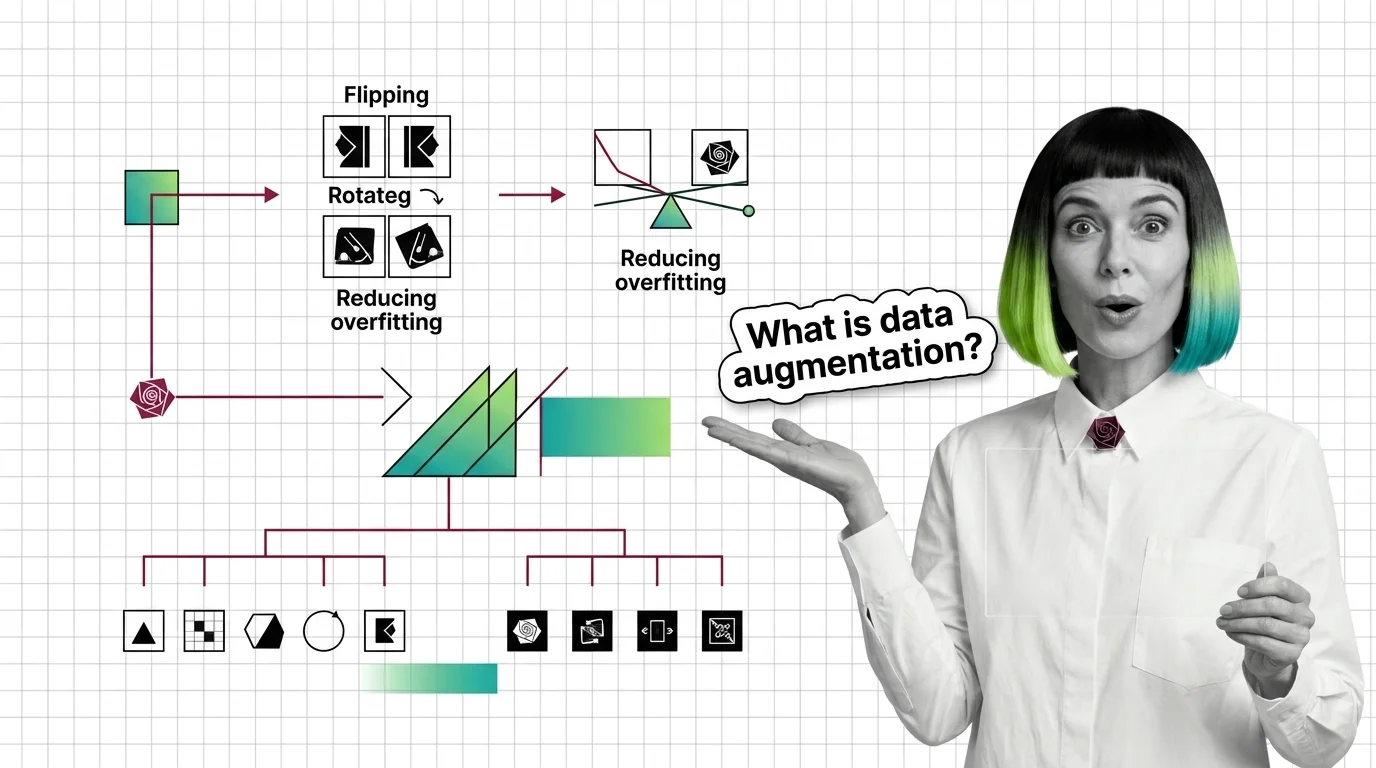
What Is Data Augmentation and How Transforming Samples Expands Training Data
What Is Data Augmentation and How Transforming Samples Expands Training Data ELI5
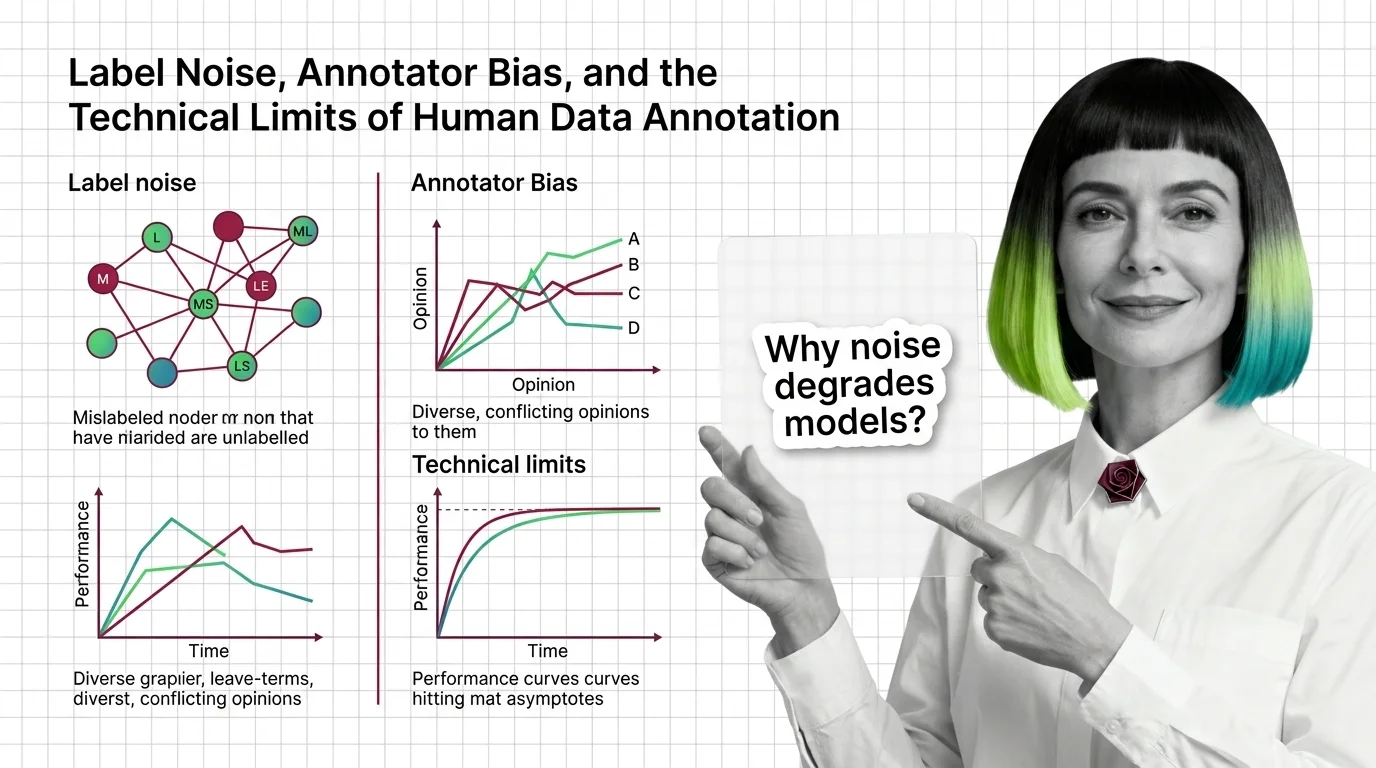
Label Noise, Annotator Bias, and the Technical Limits of Human Data Annotation
Label Noise, Annotator Bias, and the Technical Limits of Human Data Annotation ELI5
Inter-Annotator Agreement, Annotation Guidelines, and the Building Blocks of a Labeling Project
Inter-Annotator Agreement, Annotation Guidelines, and the Building Blocks of a Labeling Project ELI5 …

Why Perfectly Clean Data Is Impossible: The Technical Limits of Data Curation at Scale
Why Perfectly Clean Data Is Impossible: The Technical Limits of Data Curation at Scale ELI5

What Is Training Data Quality and How It Determines Model Performance
What Is Training Data Quality and How It Determines Model Performance ELI5

What Is AI for Technical Debt and How Machine Learning Detects Code Smells and Hotspots
What Is AI for Technical Debt and How Machine Learning Detects Code Smells and Hotspots ELI5
What AI Technical-Debt Tools Actually Measure — and Where the Numbers Break
What AI Technical-Debt Tools Actually Measure — and Where the Numbers Break ELI5

Label Noise, Class Imbalance, and Distribution Shift: What to Know Before Fixing Training Data
Label Noise, Class Imbalance, and Distribution Shift: What to Know Before Fixing Training Data ELI5
What Is AI in CI/CD Pipelines and How Automated Code Analysis and Deployment Checks Work
What Is AI in CI/CD Pipelines and How Automated Code Analysis and Deployment Checks Work ELI5

Prerequisites and Technical Limits of AI in CI/CD: DevOps Foundations to Flaky-Test False Positives
Prerequisites and Technical Limits of AI in CI/CD: DevOps Foundations to Flaky-Test False Positives …
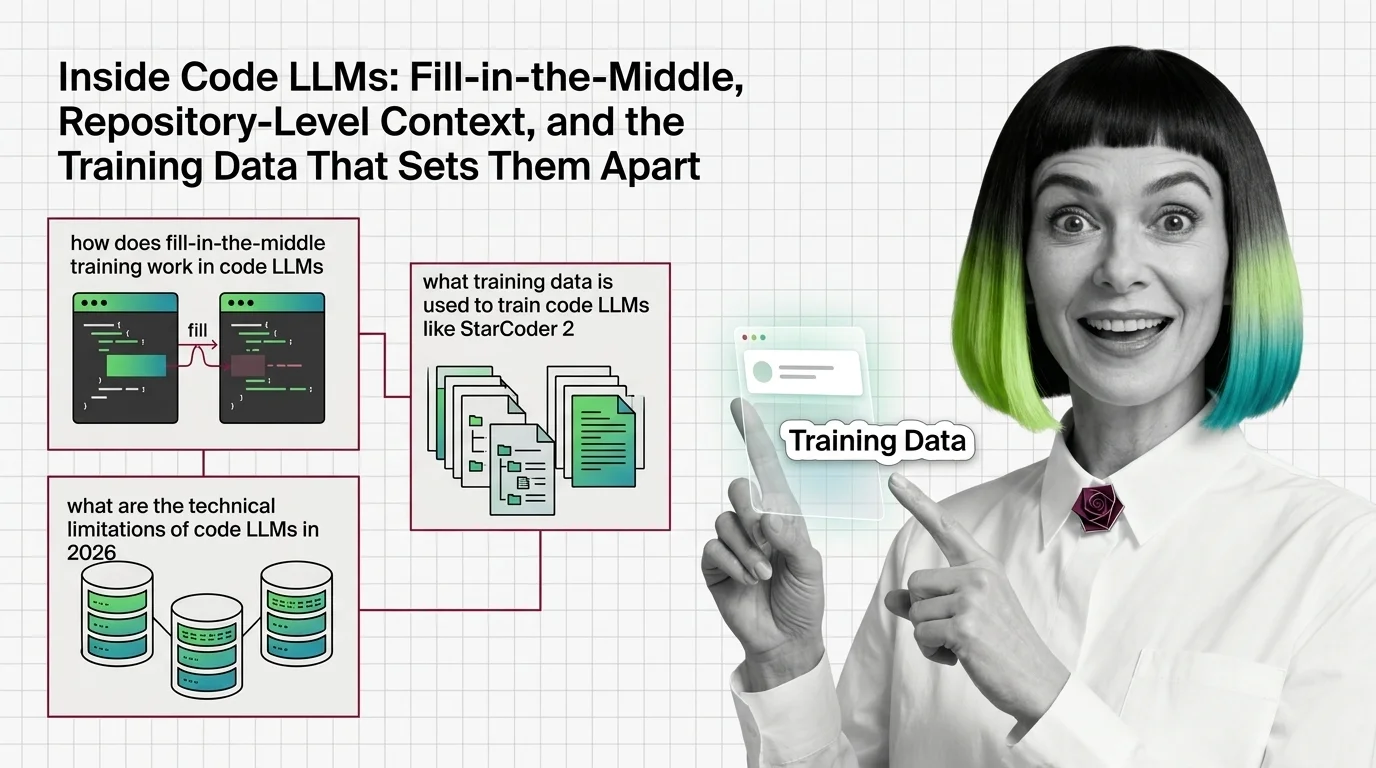
Inside Code LLMs: Fill-in-the-Middle and the Training Data Behind Them
Inside Code LLMs: Fill-in-the-Middle and the Training Data Behind Them ELI5

What Is Vibe Coding and How Natural-Language Development Replaces Manual Code Editing
What Is Vibe Coding and How Natural-Language Development Replaces Manual Code Editing ELI5
What Is Context Engineering for Code and How It Shapes AI Coding Assistant Output
What Is Context Engineering for Code and How It Shapes AI Coding Assistant Output ELI5

What Is Agentic Coding and How Plan-Write-Test-Iterate Loops Replace Manual Development
What Is Agentic Coding and How Plan-Write-Test-Iterate Loops Replace Manual Development ELI5

Prerequisites for Vibe Coding and the Technical Limits That Break the Illusion
Prerequisites for Vibe Coding and the Technical Limits That Break the Illusion ELI5

Prerequisites for Agentic Coding: Tool Use, Scaffolding, and the Plan-Execute-Verify Loop
Prerequisites for Agentic Coding: Tool Use, Scaffolding, and the Plan-Execute-Verify Loop ELI5
From Repo Indexing to Memory Files: Prerequisites and Limits of Code Context Engineering
From Repo Indexing to Memory Files: Prerequisites and Limits of Code Context Engineering ELI5
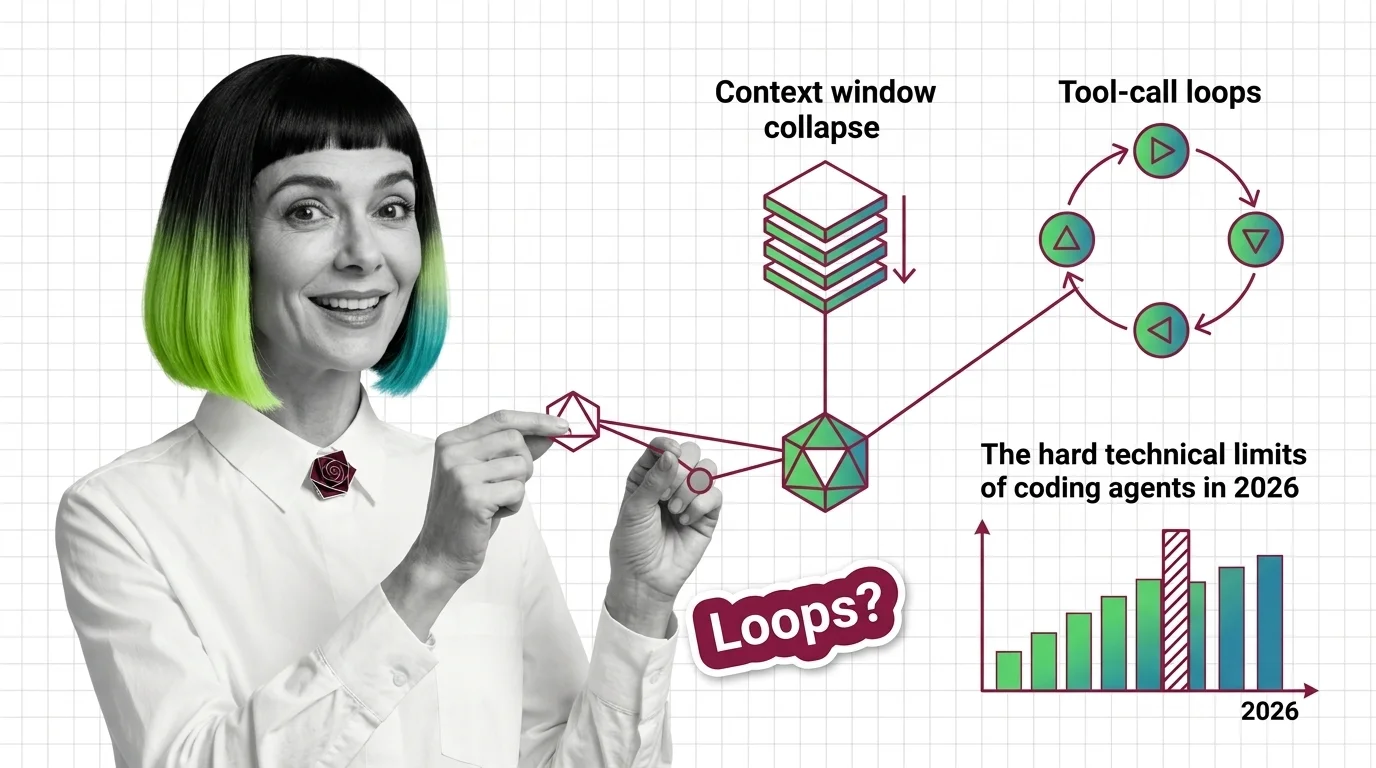
Context Window Collapse, Tool-Call Loops, and the Hard Technical Limits of Coding Agents in 2026
Context Window Collapse, Tool-Call Loops, and the Hard Technical Limits of Coding Agents in 2026 …

The Technical Limits of MCP: Missing Authentication, Tool Sprawl, and Stateful Connections
The Technical Limits of MCP: Missing Authentication, Tool Sprawl, and Stateful Connections ELI5

What Is the Model Context Protocol and How It Connects AI Assistants to External Tools
What Is the Model Context Protocol and How It Connects AI Assistants to External Tools ELI5

What Is AI Code Migration and How LLM Agents Translate Languages and Modernize Legacy Codebases
What Is AI Code Migration and How LLM Agents Translate Languages and Modernize Legacy Codebases ELI5 …

MCP Architecture Explained: Hosts, Clients, Servers, and the Tools-Resources-Prompts Primitives
MCP Architecture Explained: Hosts, Clients, Servers, and the Tools-Resources-Prompts Primitives ELI5 …

AI Code Migration: AST Parsing, Test Coverage, and the Problem of Silent Regressions
AI Code Migration: AST Parsing, Test Coverage, and the Problem of Silent Regressions ELI5
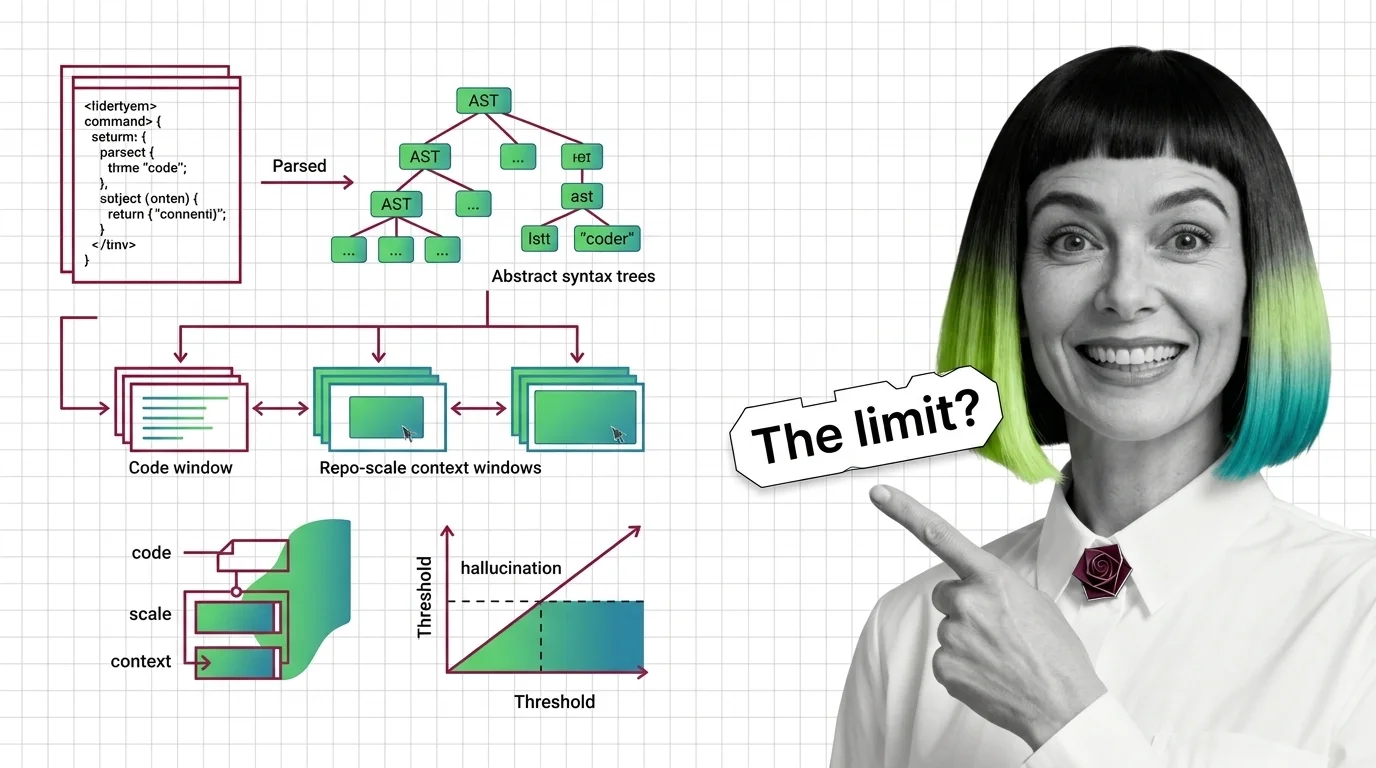
Prerequisites for AI Documentation Generation: From AST Parsing to Repo-Scale Context Windows and Hallucination Limits
Prerequisites for AI Documentation Generation: From AST Parsing to Repo-Scale Context Windows and …
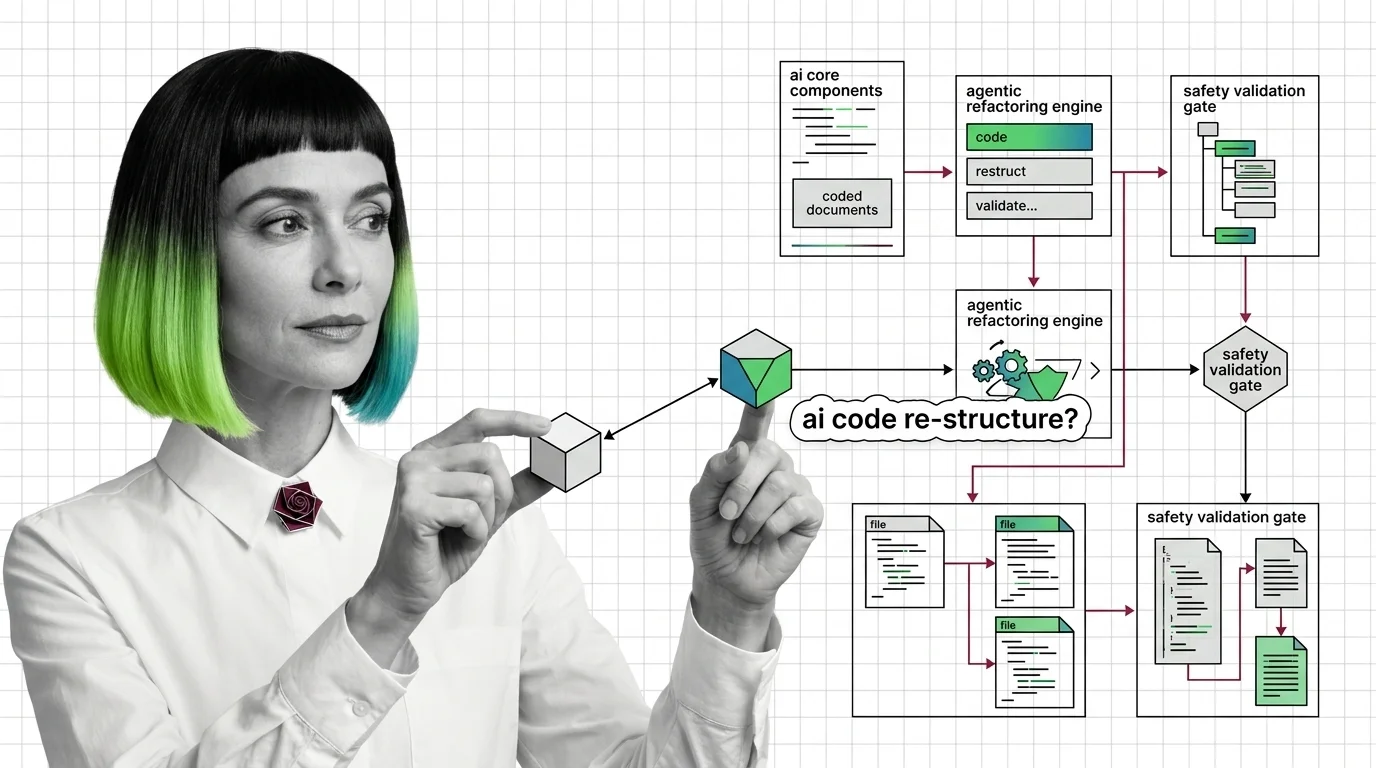
What Is AI-Assisted Refactoring and How Agentic Tools Restructure Code Without Breaking It
What Is AI-Assisted Refactoring and How Agentic Tools Restructure Code Without Breaking It ELI5
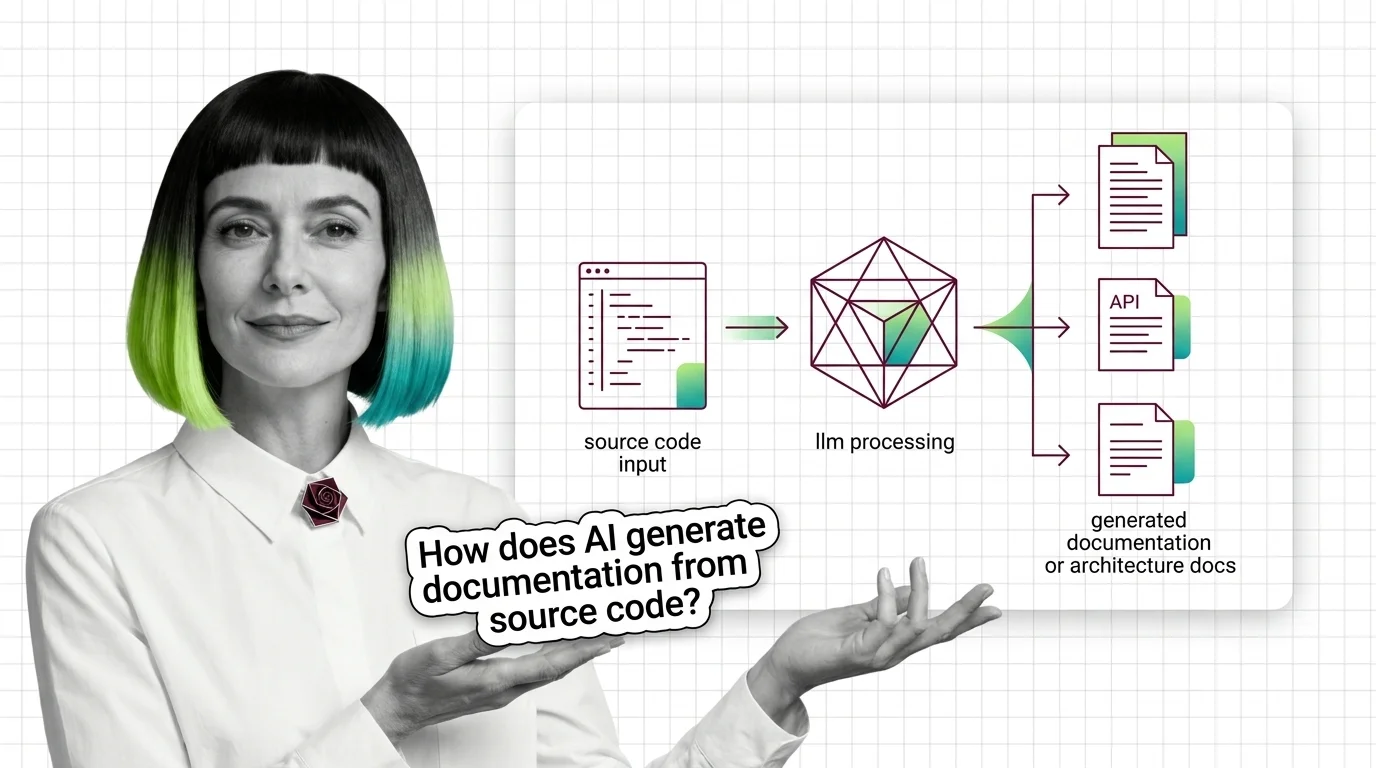
What Is AI Documentation Generation? How LLMs Turn Code Into Docstrings and Architecture Docs
What Is AI Documentation Generation? How LLMs Turn Code Into Docstrings and Architecture Docs ELI5
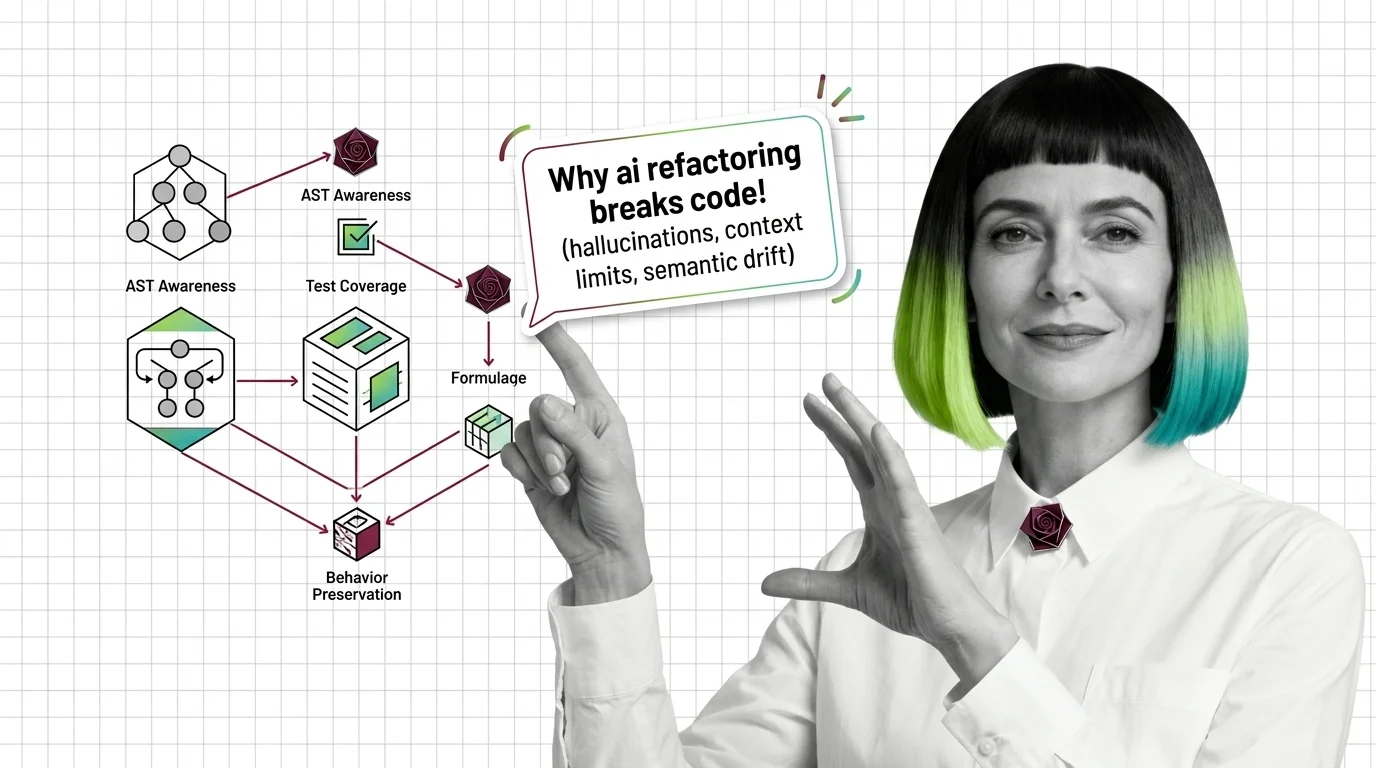
Prerequisites for AI-Assisted Refactoring: From AST Awareness to Test Coverage and Behavior Preservation
Prerequisites for AI-Assisted Refactoring: From AST Awareness to Test Coverage and Behavior …

Prerequisites for AI-Assisted Debugging: Stack Traces, Context Windows, and Why Models Still Hallucinate Fixes
Prerequisites for AI-Assisted Debugging: Stack Traces, Context Windows, and Why Models Still …


What Is AI Test Generation and How LLMs Write Unit and Integration Tests from Code
What Is AI Test Generation and How LLMs Write Unit and Integration Tests from Code ELI5
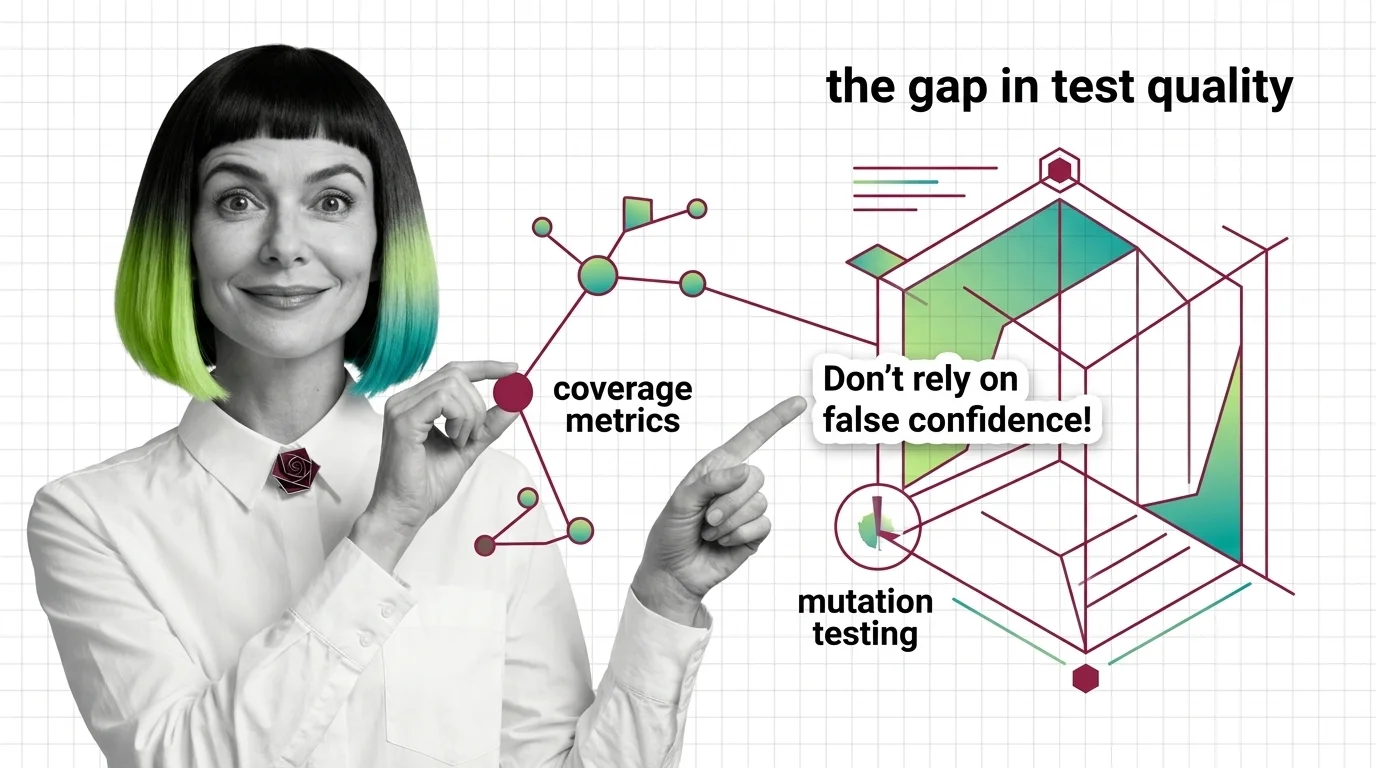

What Is AI Code Review and How LLM-Powered PR Reviewers Catch Bugs Before Humans
What Is AI Code Review and How LLM-Powered PR Reviewers Catch Bugs Before Humans ELI5
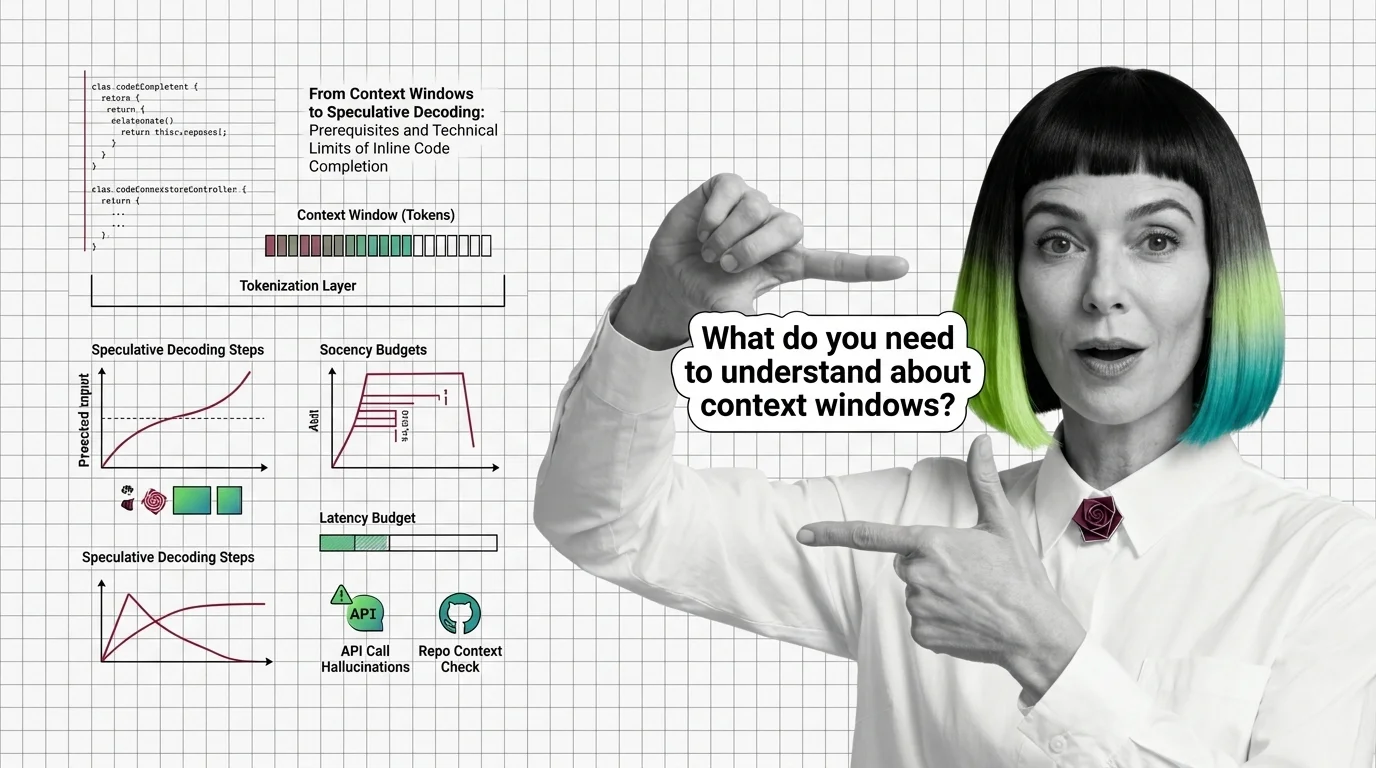
From Context Windows to Speculative Decoding: Prerequisites and Technical Limits of Inline Code Completion
From Context Windows to Speculative Decoding: Prerequisites and Technical Limits of Inline Code …

What Is AI Code Completion and How LLM-Powered Inline Suggestions Predict the Next Token
What Is AI Code Completion and How LLM-Powered Inline Suggestions Predict the Next Token ELI5
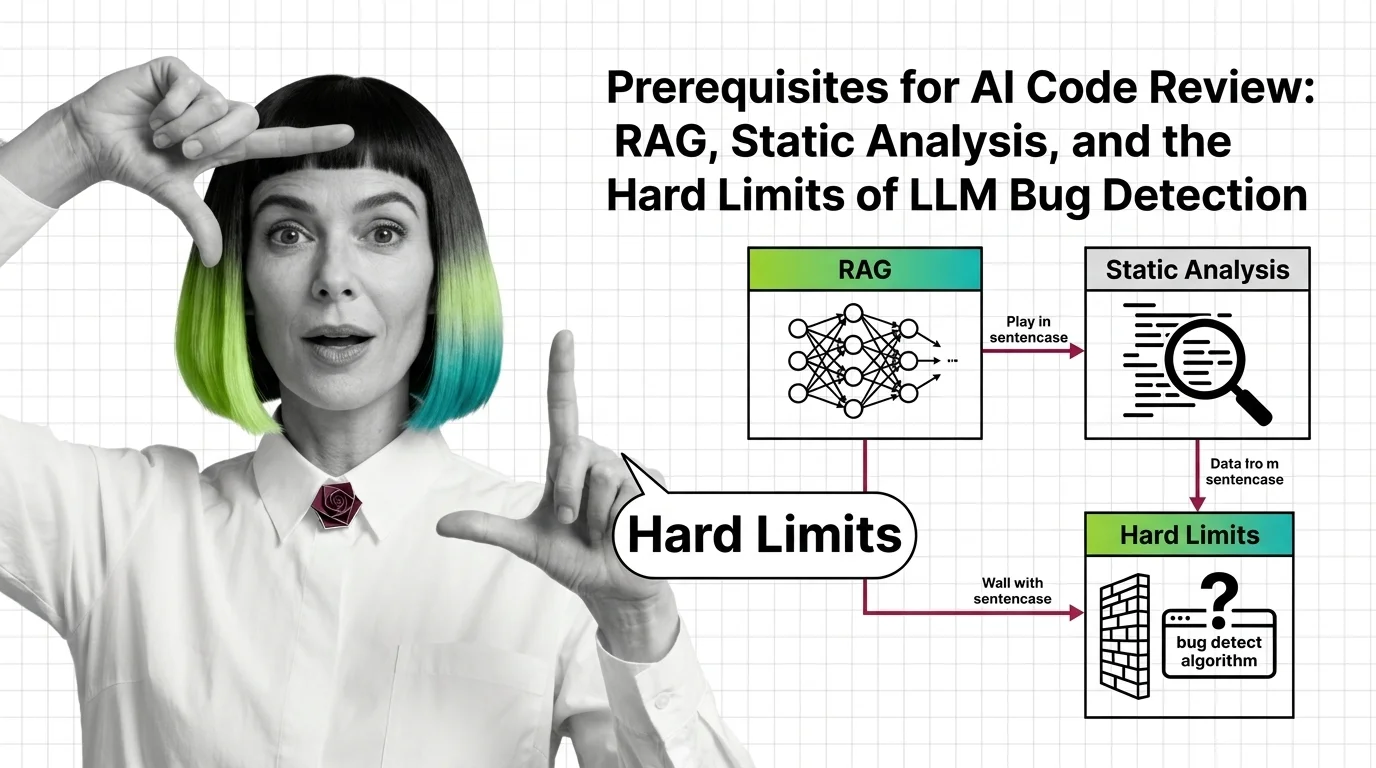
Prerequisites for AI Code Review: RAG, Static Analysis, and the Hard Limits of LLM Bug Detection
Prerequisites for AI Code Review: RAG, Static Analysis, and the Hard Limits of LLM Bug Detection …

What Are Browser and Computer Use Agents and How Screenshot-Grounded AI Controls Your Desktop
What Are Browser and Computer Use Agents and How Screenshot-Grounded AI Controls Your Desktop ELI5
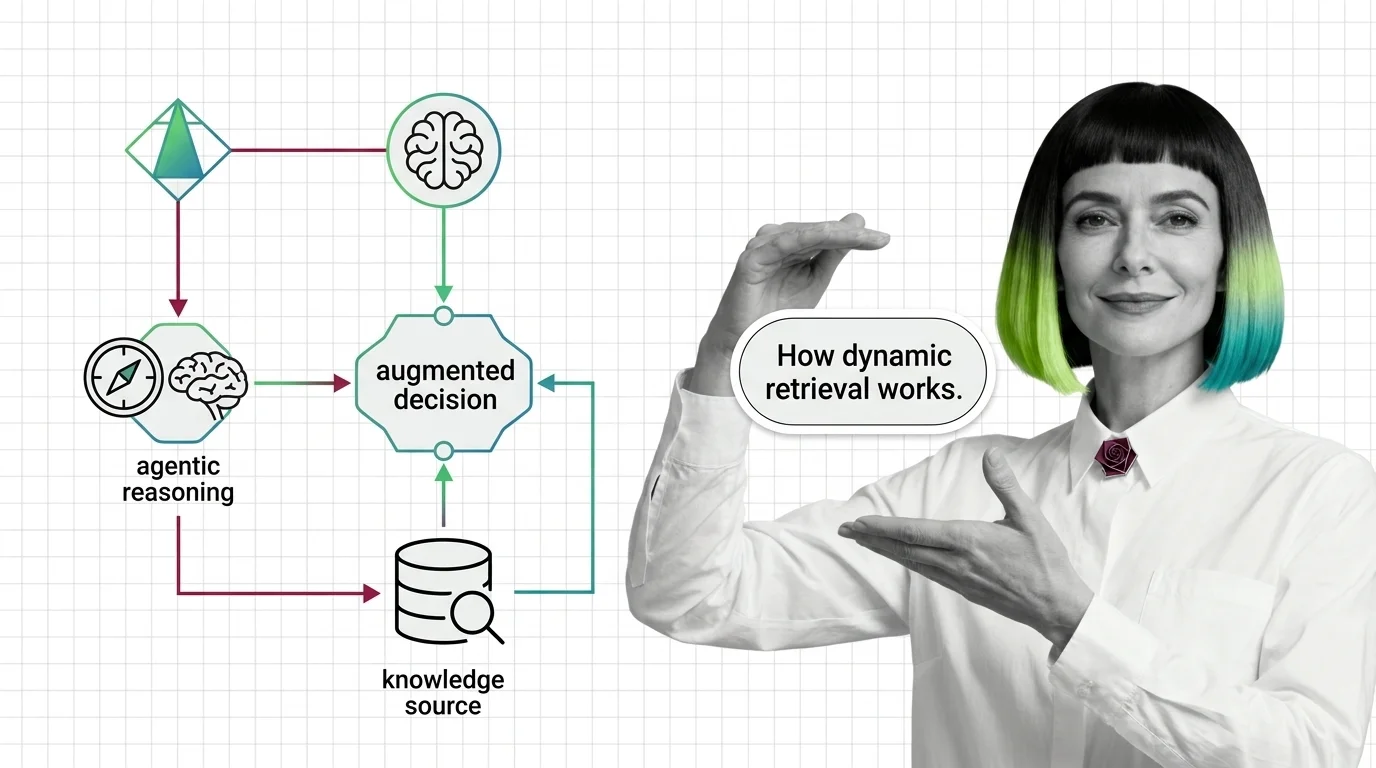
What Are Retrieval-Augmented Agents and How They Combine Agentic Reasoning with Dynamic Retrieval
What Are Retrieval-Augmented Agents and How They Combine Agentic Reasoning with Dynamic Retrieval …
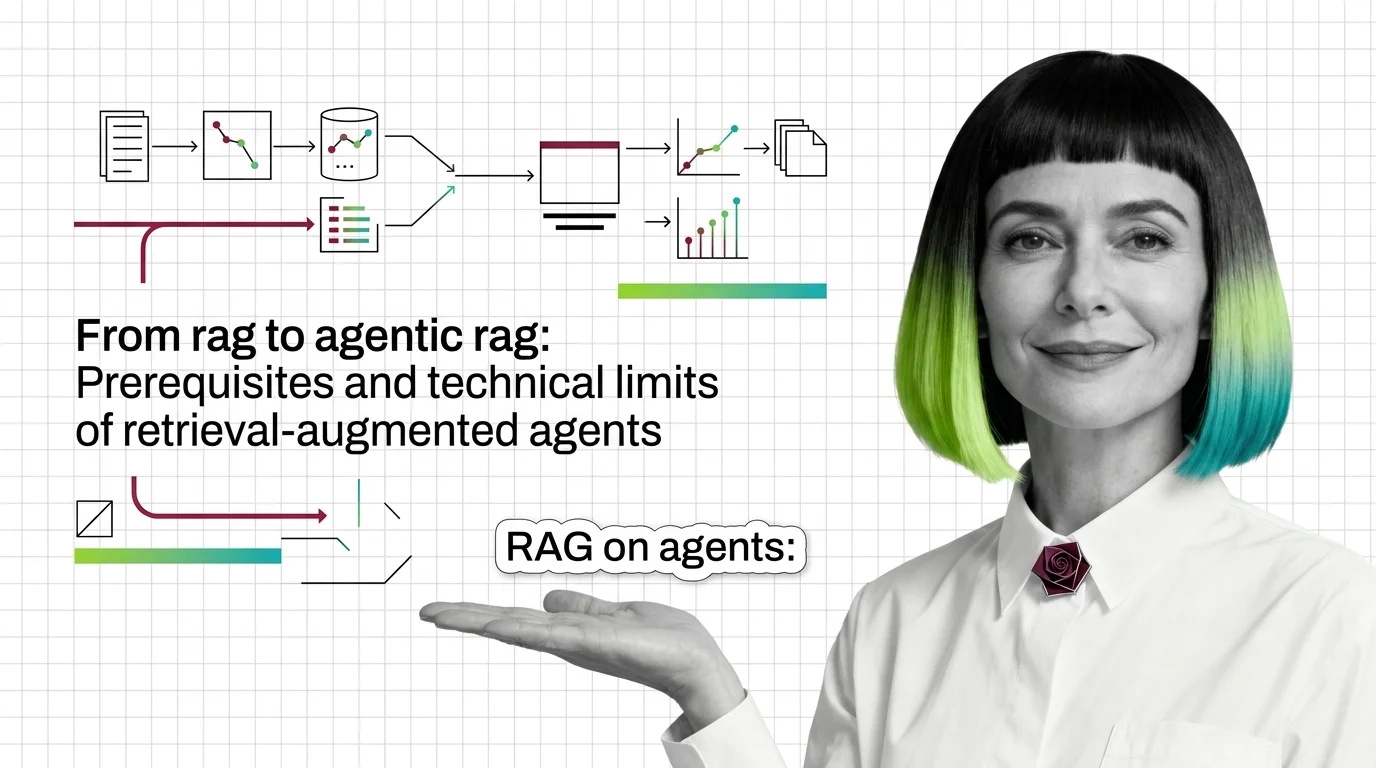
From RAG to Agentic RAG: Prerequisites and Technical Limits of Retrieval-Augmented Agents
From RAG to Agentic RAG: Prerequisites and Technical Limits of Retrieval-Augmented Agents ELI5


What Are Code Execution Agents and How Sandboxed Interpreters Let LLMs Run Their Own Code
What Are Code Execution Agents and How Sandboxed Interpreters Let LLMs Run Their Own Code ELI5
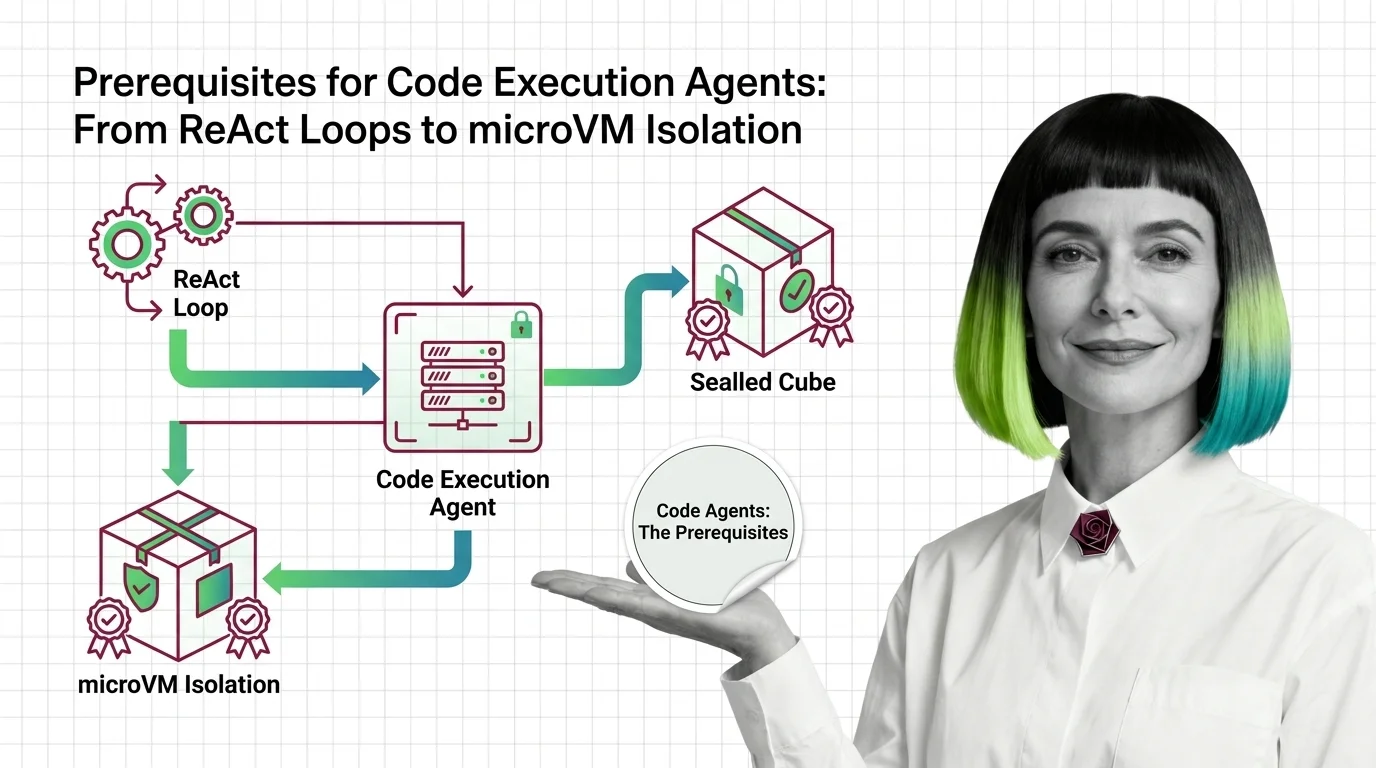

Cold Starts, Flaky Tests, and Context Blowup: The Technical Limits of Code Execution Agents in 2026
Cold Starts, Flaky Tests, and Context Blowup: The Technical Limits of Code Execution Agents in 2026 …
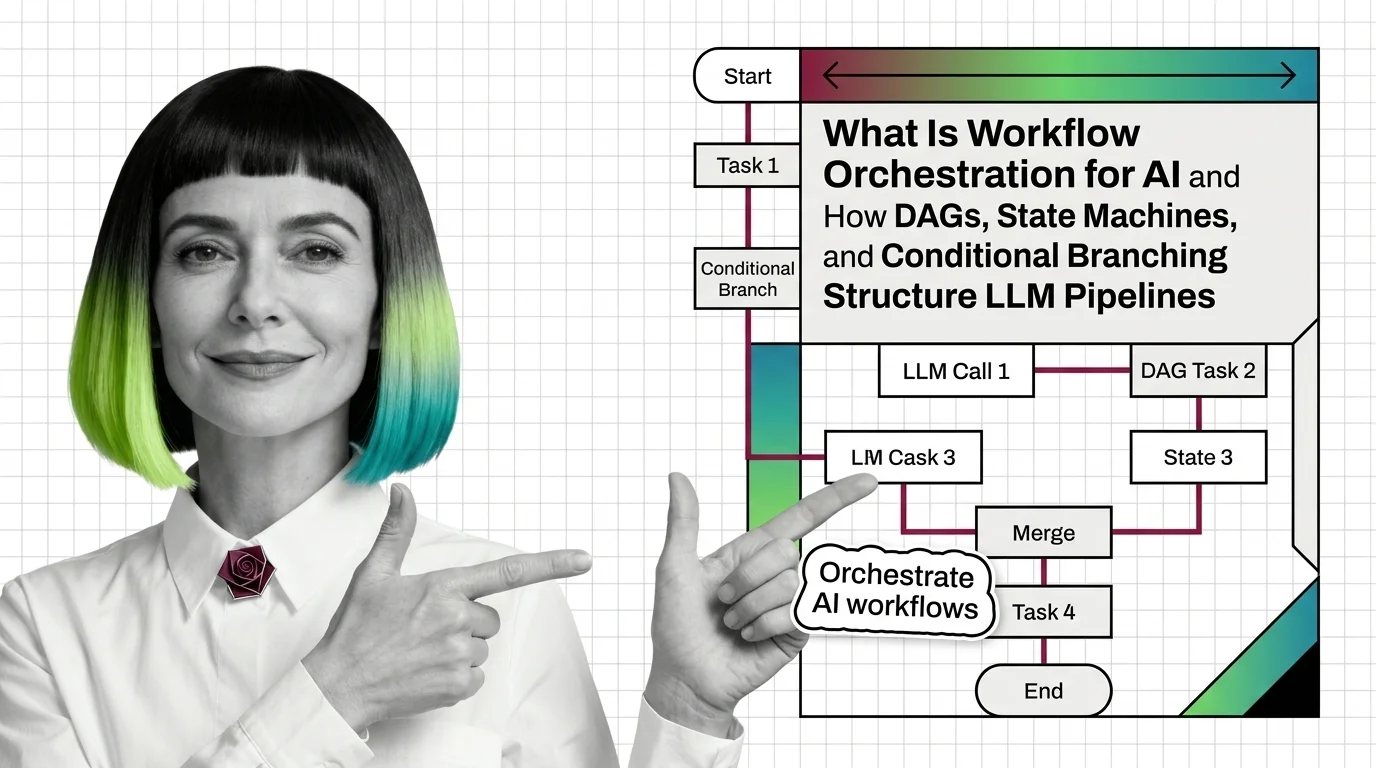
What Is Workflow Orchestration for AI and How DAGs, State Machines, and Conditional Branching Structure LLM Pipelines
What Is Workflow Orchestration for AI and How DAGs, State Machines, and Conditional Branching …
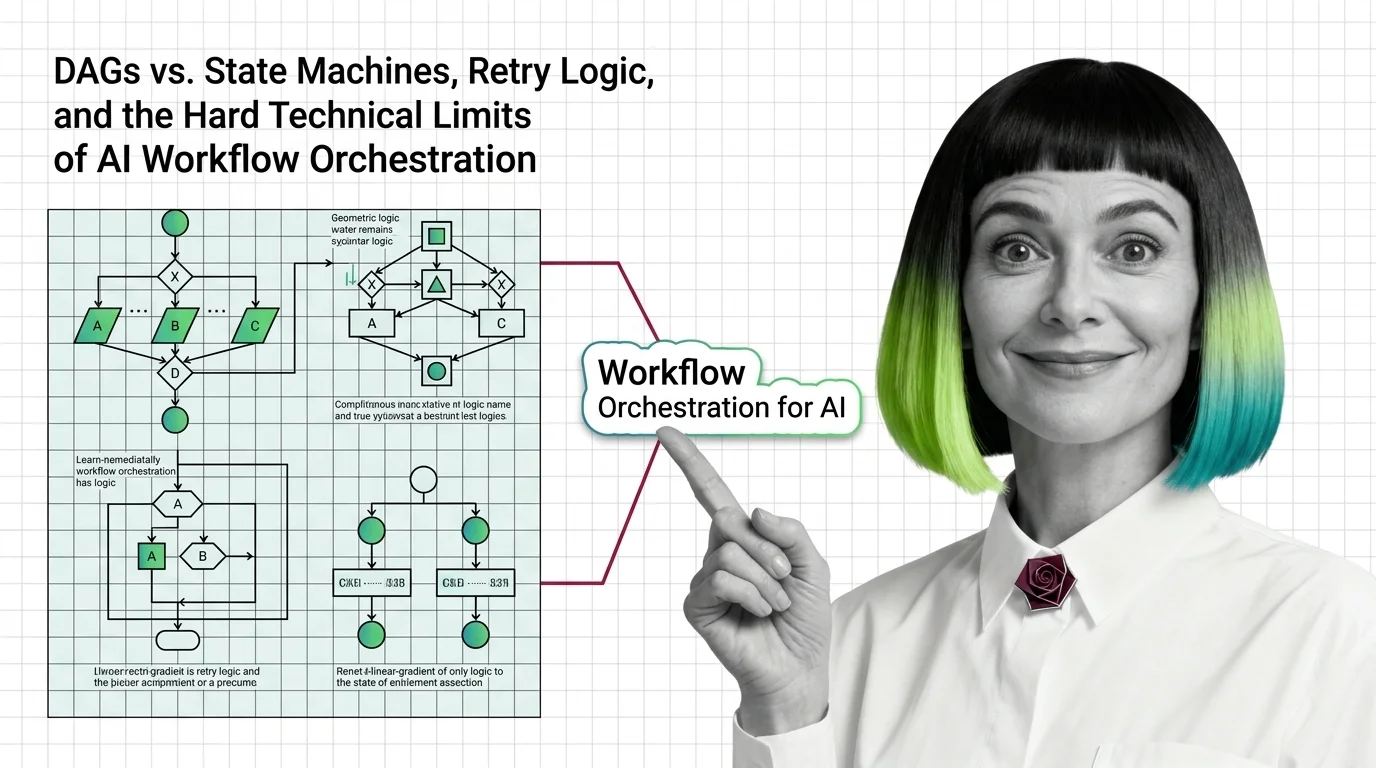
DAGs vs. State Machines, Retry Logic, and the Hard Technical Limits of AI Workflow Orchestration
DAGs vs. State Machines, Retry Logic, and the Hard Technical Limits of AI Workflow Orchestration …

Agent Error Handling: How Agents Recover From Tool and LLM Failures
Agent error handling turns brittle LLM loops into resilient systems. Learn how guardrails, retries, and checkpoints …
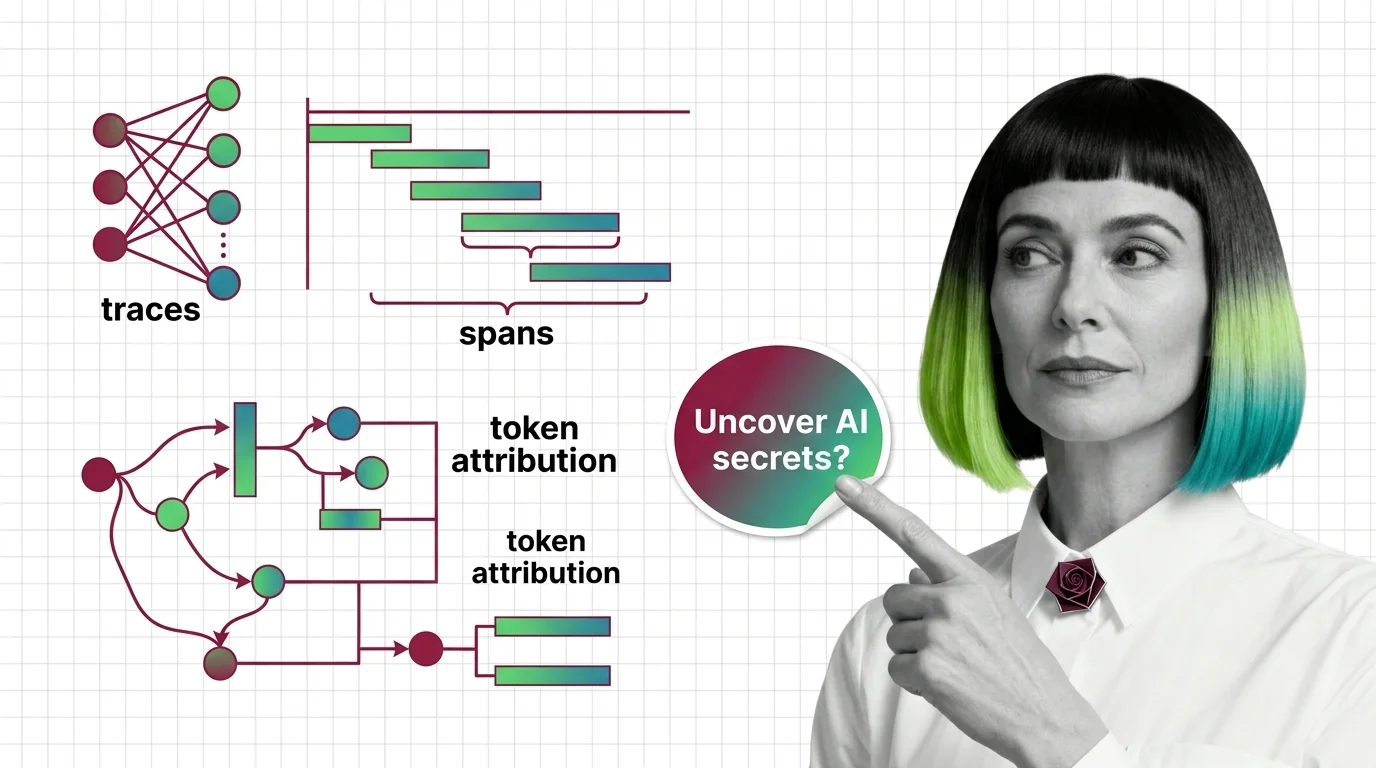
What Is Agent Observability? Traces, Spans, and Token Attribution
Agent observability records every step an AI agent takes. Learn how traces, spans, and token attribution reveal what …
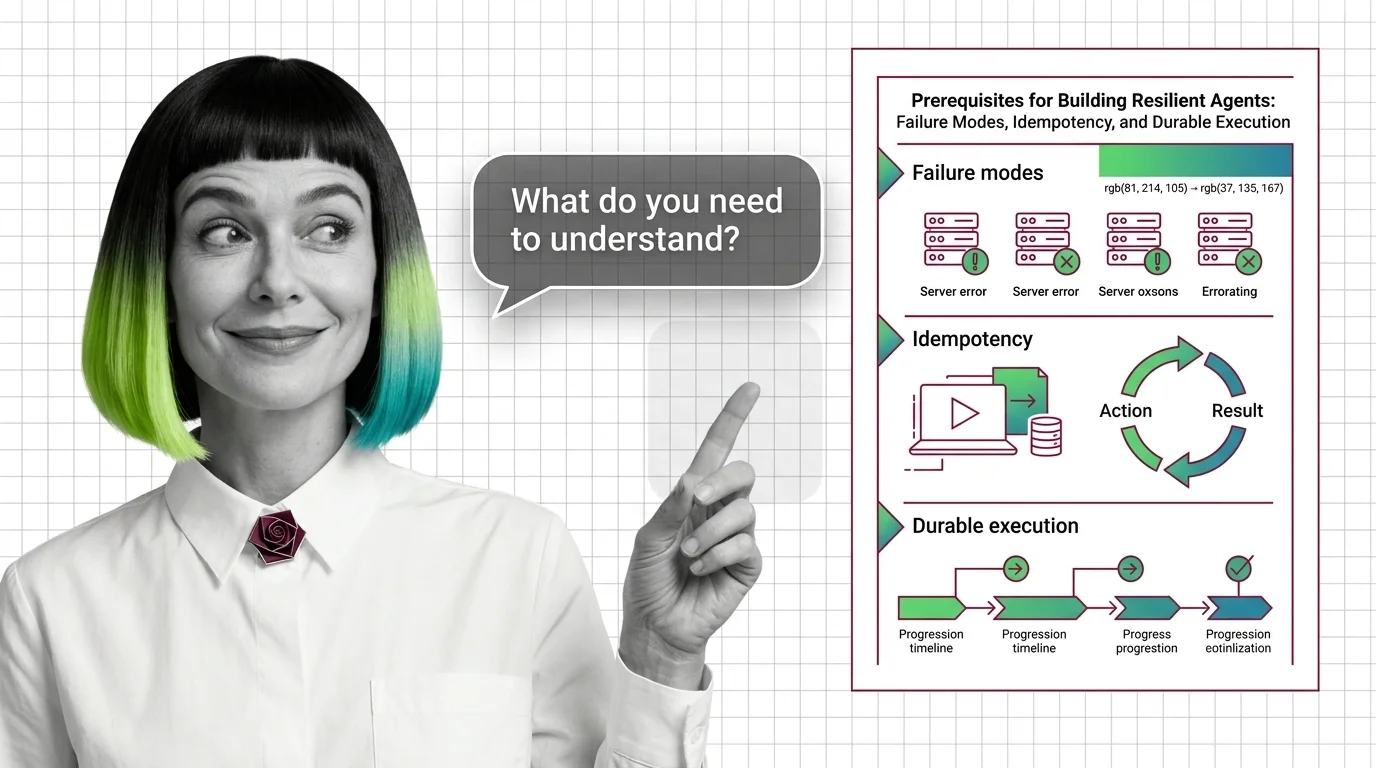
Resilient AI Agents: Failure Modes, Idempotency, Durable Execution
Reliable AI agents need three foundations: a failure-mode taxonomy, idempotent action boundaries, and durable execution …

OpenTelemetry GenAI: Prerequisites and Limits of Agent Tracing
OpenTelemetry GenAI semconv is still in Development. What you need to know about tracing prerequisites and hard limits …
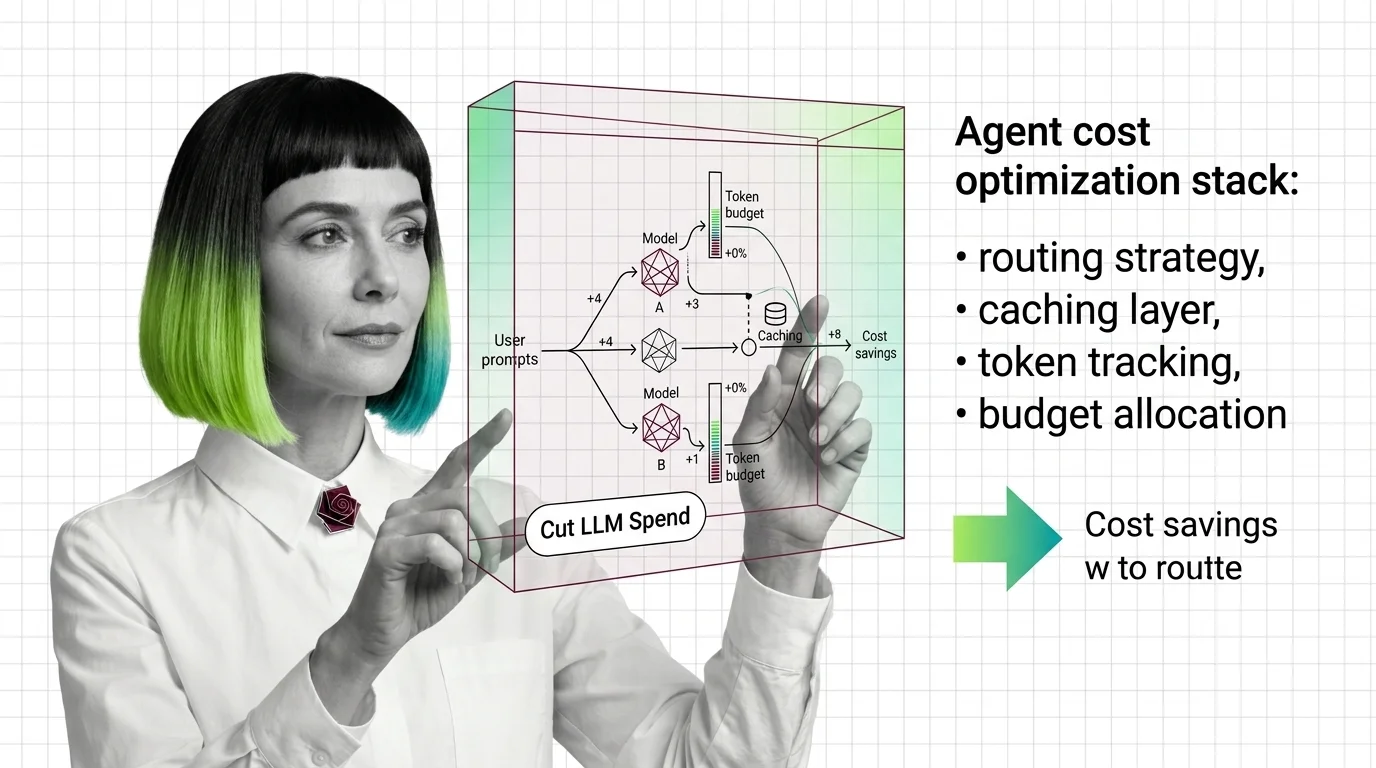
Agent Cost Optimization: Routing, Caching, and Token Budgets for LLMs
Agent cost optimization routes requests to the right model, caches reusable computation, and caps runaway loops before …
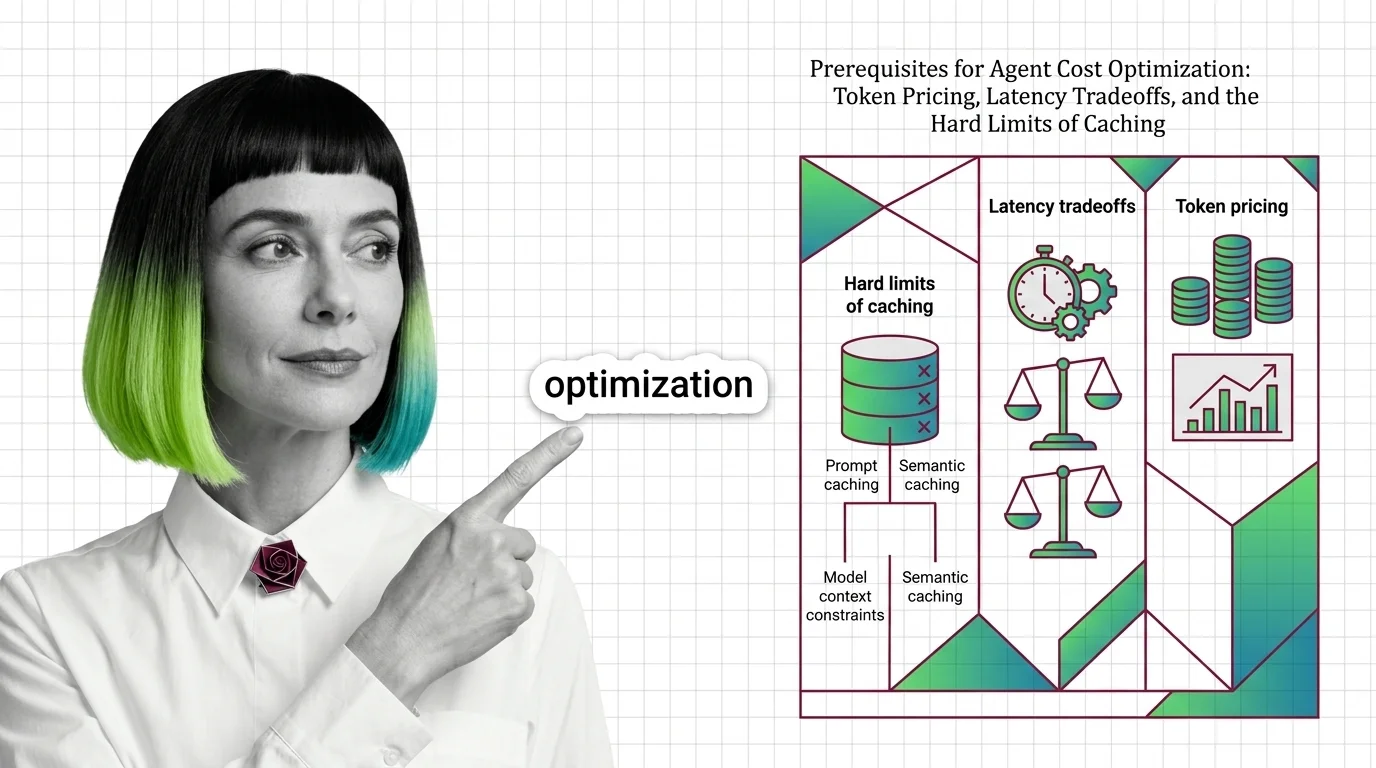
Agent Cost Optimization Prerequisites: Pricing, Latency, Caching Limits
Before optimizing agent costs, understand token pricing asymmetry, prefill vs decode latency, and why prompt and …

What Are Agent Guardrails? How Permission Systems Constrain AI
Agent guardrails enforce permission boundaries on autonomous AI. Learn how Claude SDK, NeMo, and Llama Guard constrain …
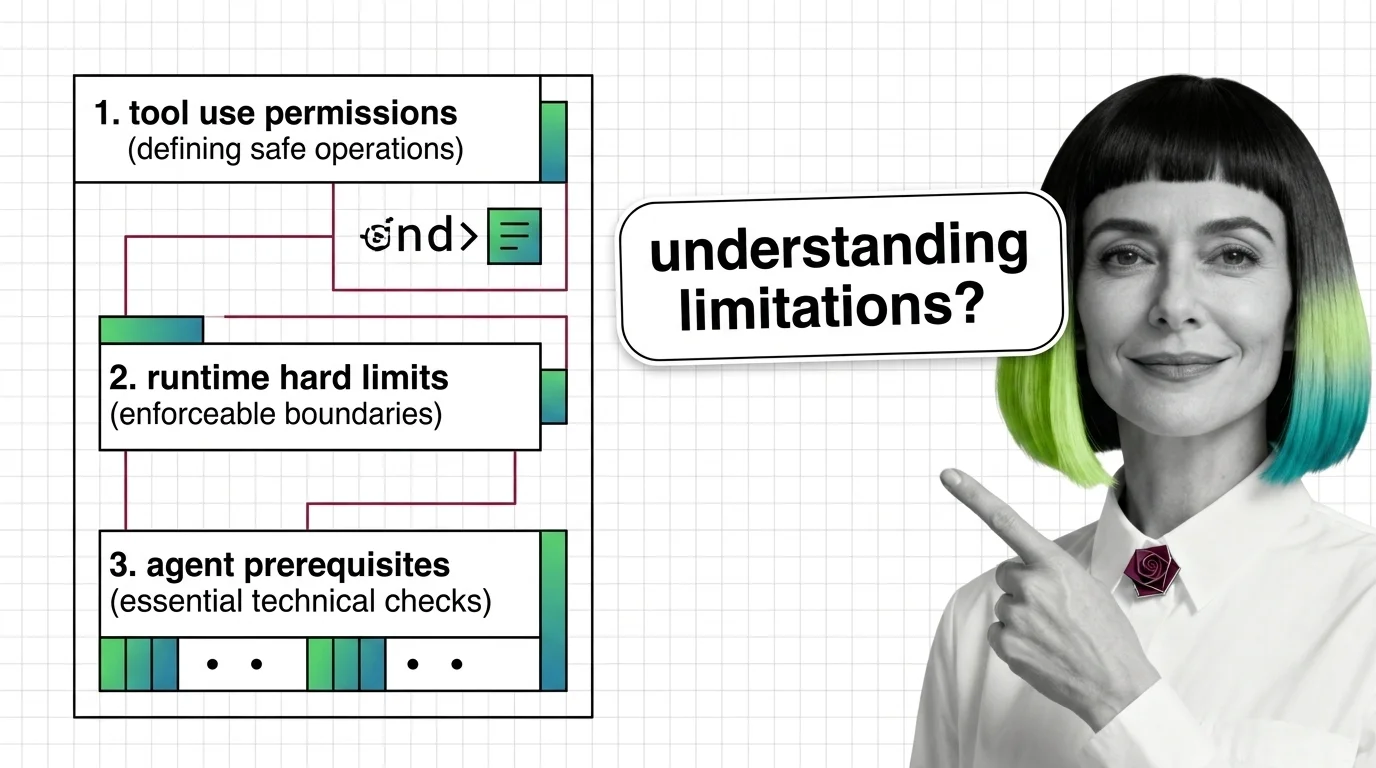
Prerequisites for Agent Guardrails: Tool Use and Runtime Limits
Agent guardrails are runtime classifiers wrapped around tool-use loops — useful, partial, and demonstrably evadable. …
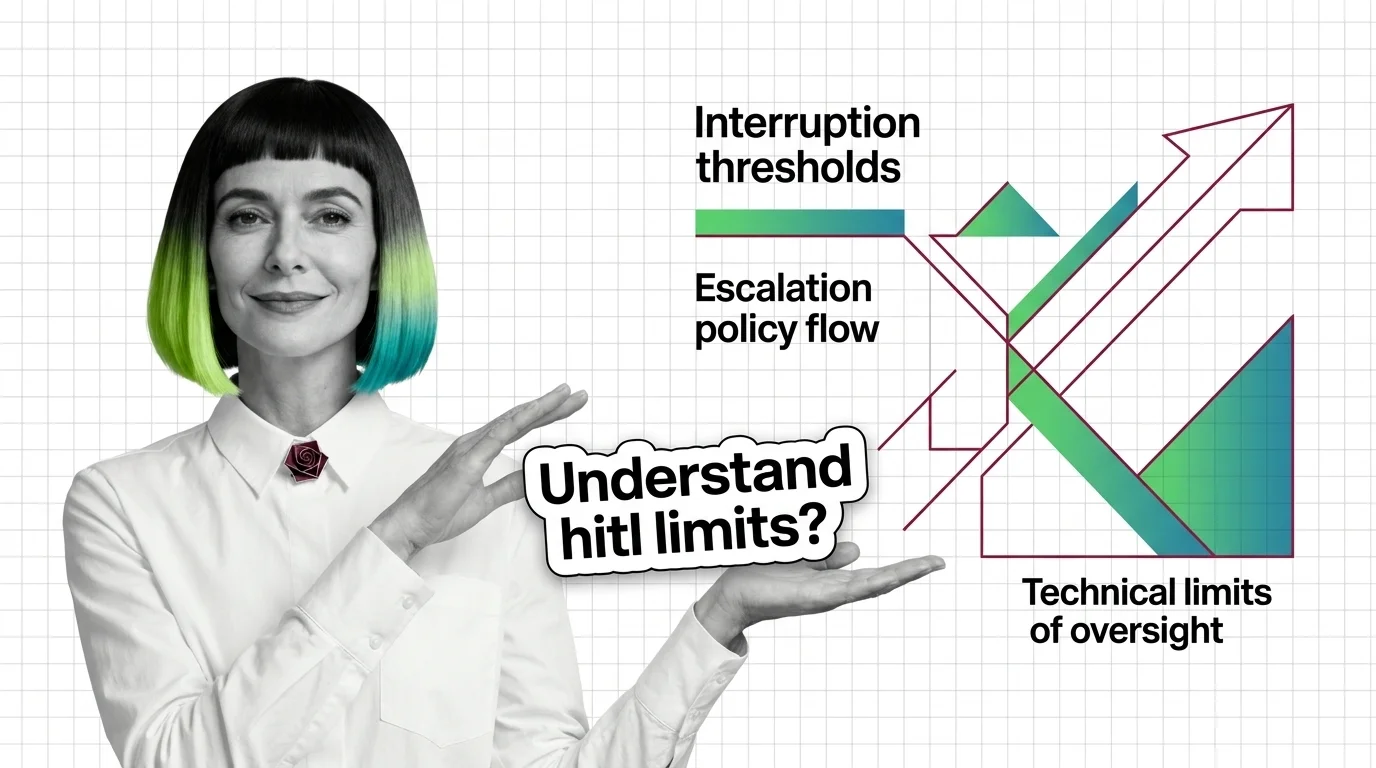
Prerequisites and Technical Limits of HITL for AI Agents
HITL for agents is easy to start and hard to scale. Learn the prerequisites — durable state, idempotency, escalation — …

Human-in-the-Loop for AI Agents: How Approval Gates Work
Human-in-the-loop for AI agents pauses autonomous workflows at risky steps and routes them to a human gate. Here's how …
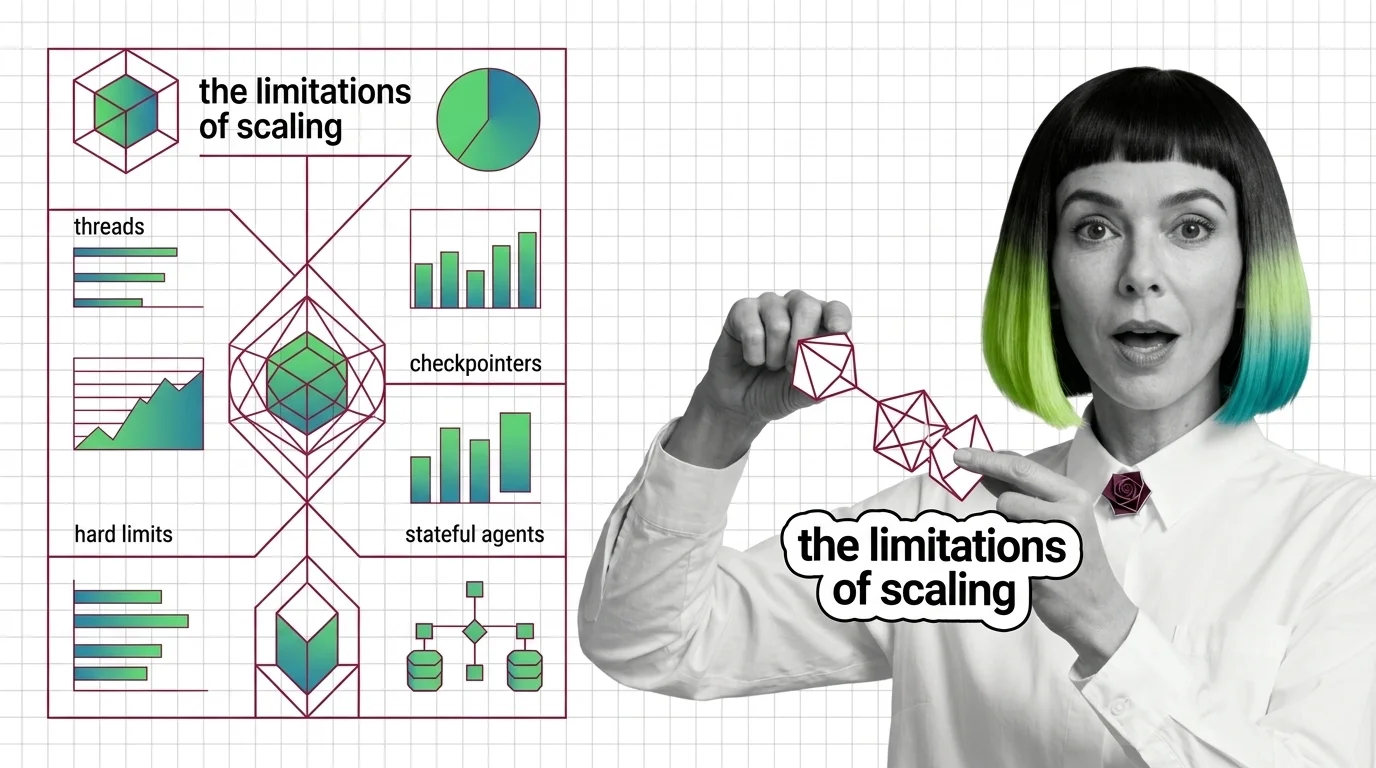
Agent State Management: Threads, Checkpointers, Hard Limits
Agent state is not memory — it is plumbing that replays snapshots between steps. Mona explains threads, checkpointers, …

Agent State Management: How Checkpointing Persists Memory Across Turns
Agent state management decides whether your agent remembers. See how LangGraph checkpointers, threads, and reducers …

Agent Evaluation: How Trajectory Analysis Measures AI Agents
Agent evaluation grades the path, not just the final answer. Learn how trajectory analysis exposes silent reasoning …
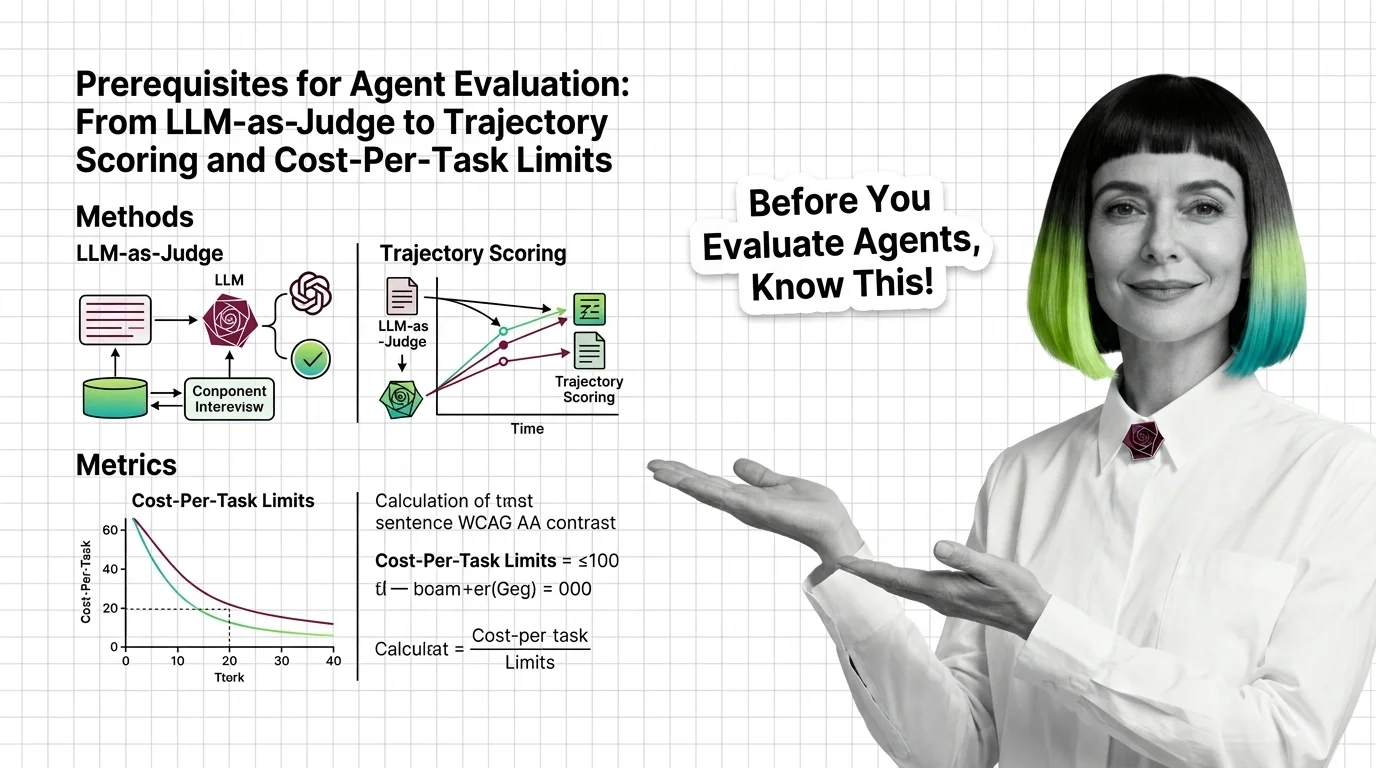
Agent Evaluation Prerequisites: LLM-as-Judge to Cost-Per-Task
Agent evaluation needs three signals: outcome, trajectory, cost. Learn why LLM-as-judge has known biases and where major …
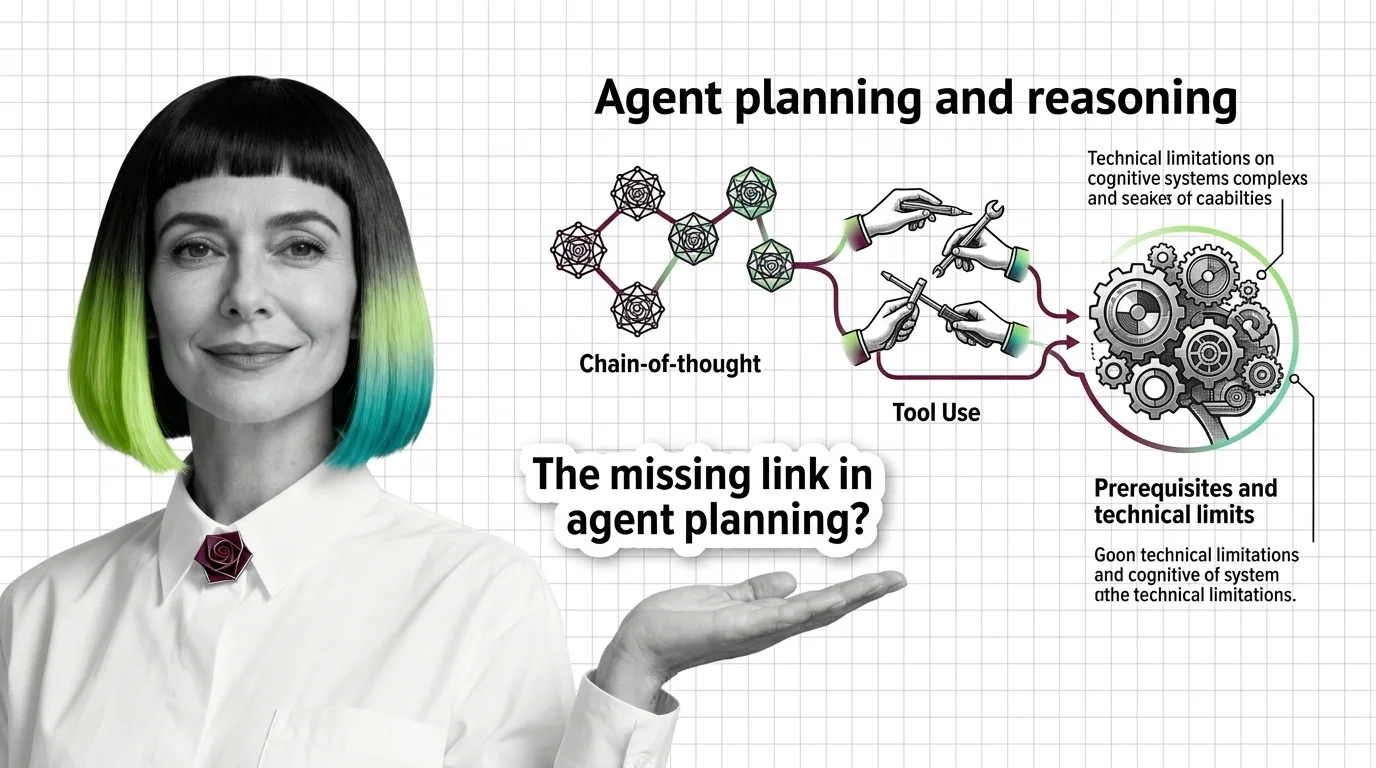
From Chain-of-Thought to Tool Use: Prerequisites and Technical Limits of Agent Planning
Agent planning rests on three primitives — chain-of-thought, tool use, and the ReAct loop. Learn the prerequisites and …
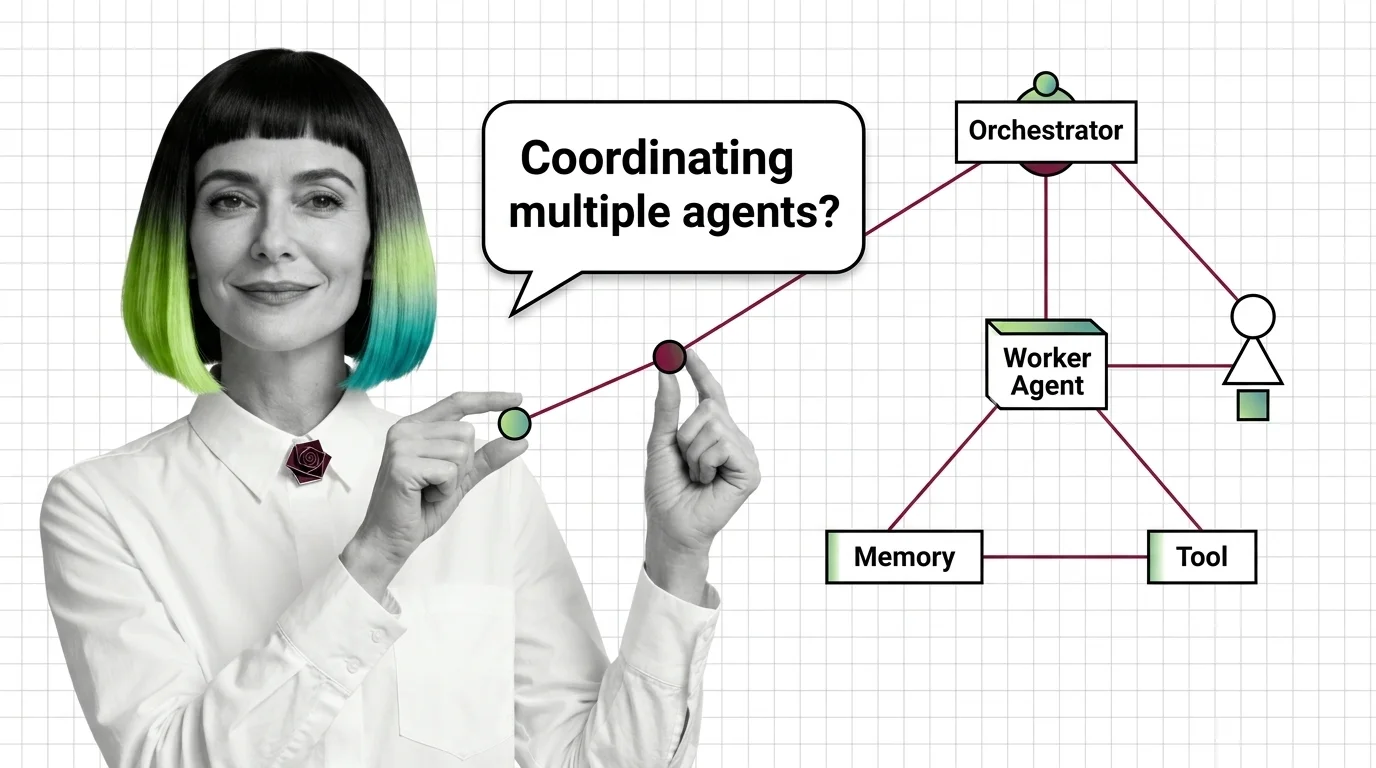
Multi-Agent Systems: Supervisor, Debate, and Swarm Patterns
Multi-agent systems coordinate specialized AI agents through supervisor, debate, or swarm patterns. Here is how each …

Multi-Agent Systems: Prerequisites and Hard Technical Limits
Before multi-agent systems, master tool use, the ReAct loop, and memory. Then face the limits: context blow-up, error …
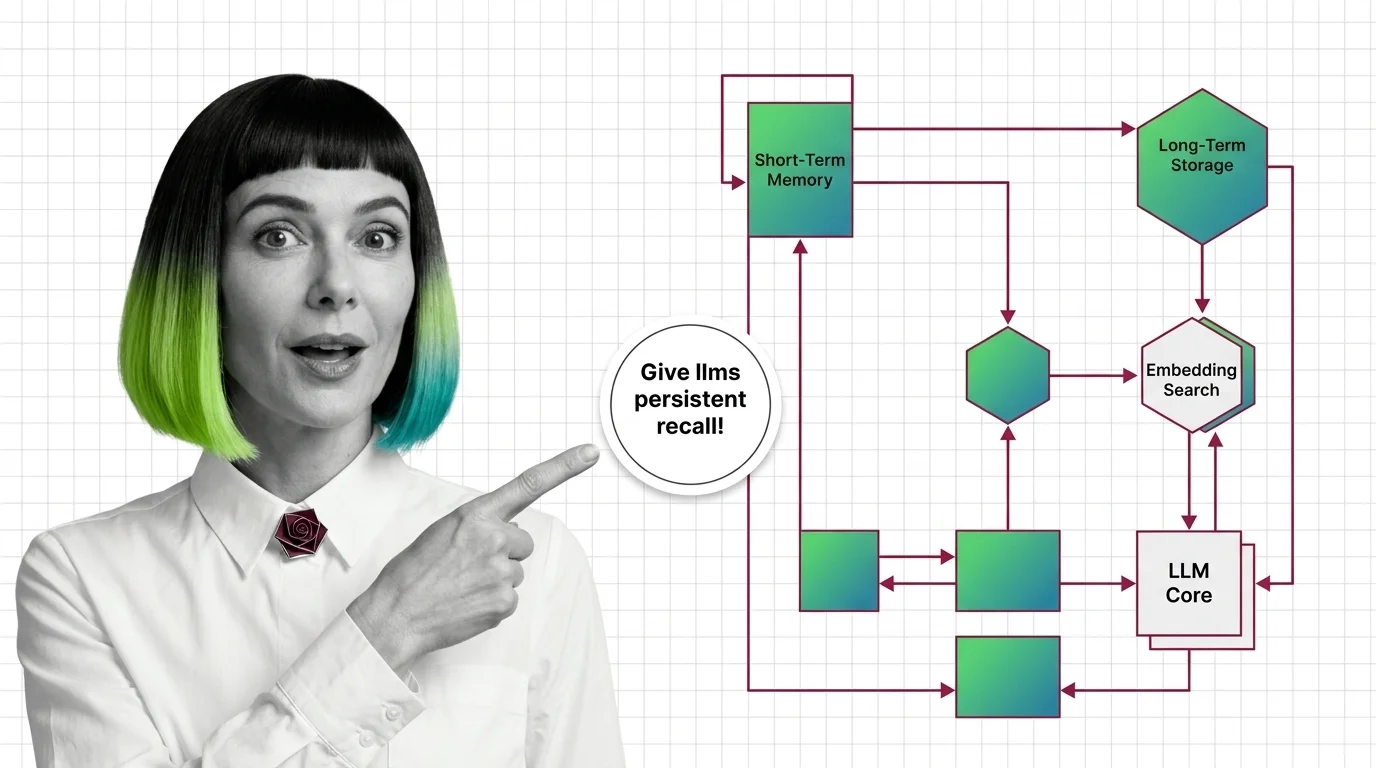
Agent Memory Systems: How LLMs Get Persistent Recall Across Sessions
Agent memory systems give LLMs persistent recall across sessions. Inside the architectures: temporal graphs, …
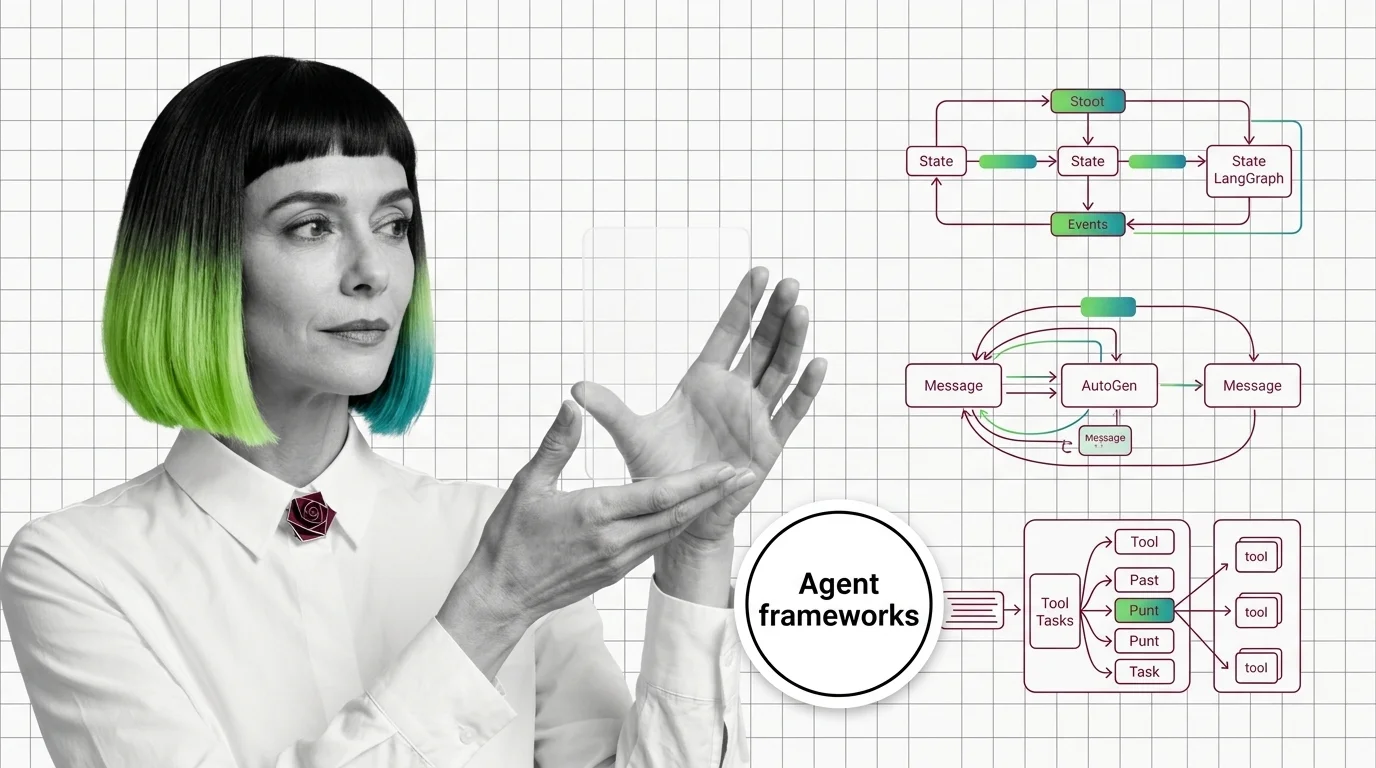
Graph vs Conversation vs Crew: LangGraph, AutoGen, CrewAI Patterns
LangGraph, AutoGen, and CrewAI commit to three different theories of how AI agents coordinate. The pattern you pick …
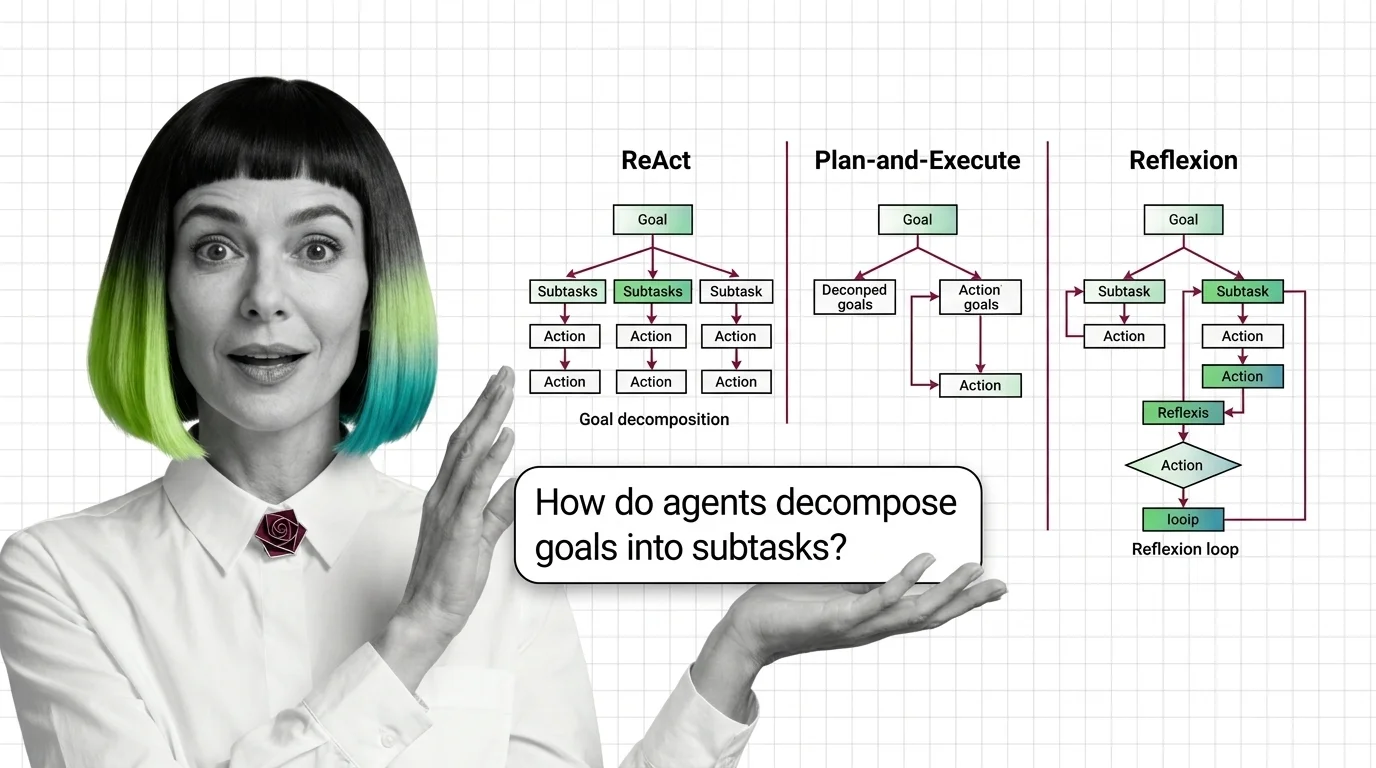
Agent Planning and Reasoning: ReAct, Plan-and-Execute, Reflexion
Agent planning is not human cognition — it is token generation conditioned on observations. How ReAct, Plan-and-Execute, …
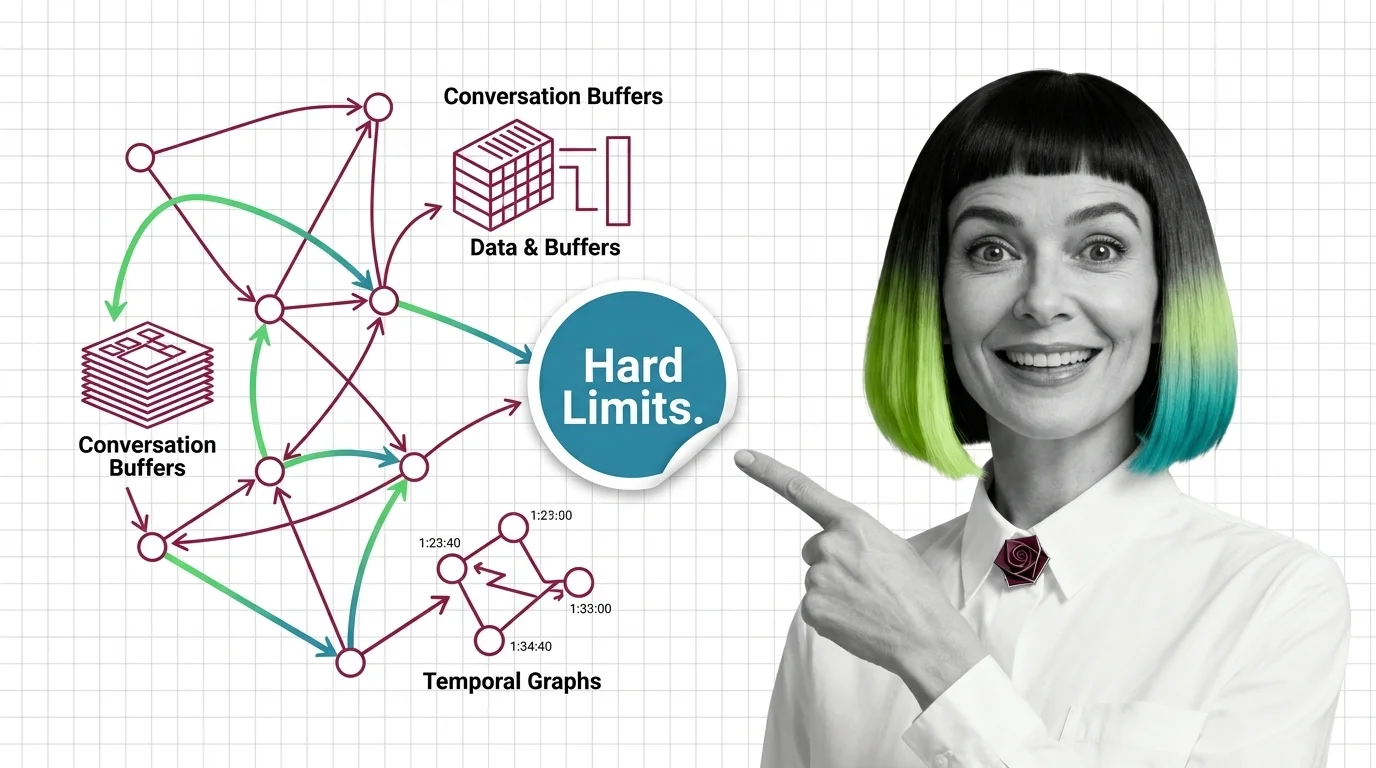
Agent Memory Architectures: Prerequisites and Hard Limits
Agent memory isn't a bigger context window. Learn the prerequisites for designing agent memory systems and the hard …

Agent Frameworks: How LangGraph, CrewAI, and AutoGen Orchestrate LLMs
Agent frameworks orchestrate LLM calls, tools, and memory — but each one bets on a different abstraction. Learn what …
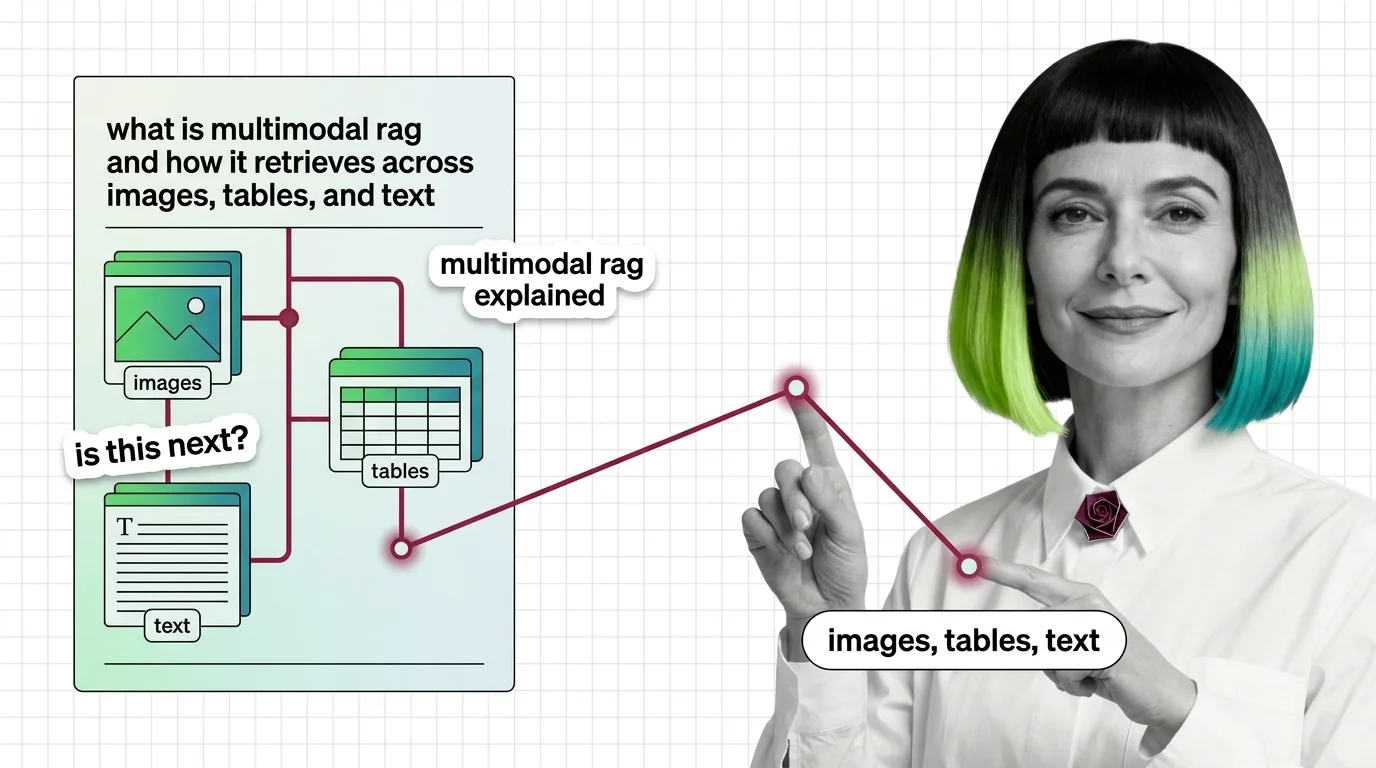
What Is Multimodal RAG and How It Retrieves Across Images, Tables, and Text
Multimodal RAG isn't text RAG with images bolted on. Learn how unified embeddings, text summaries, and vision-first …
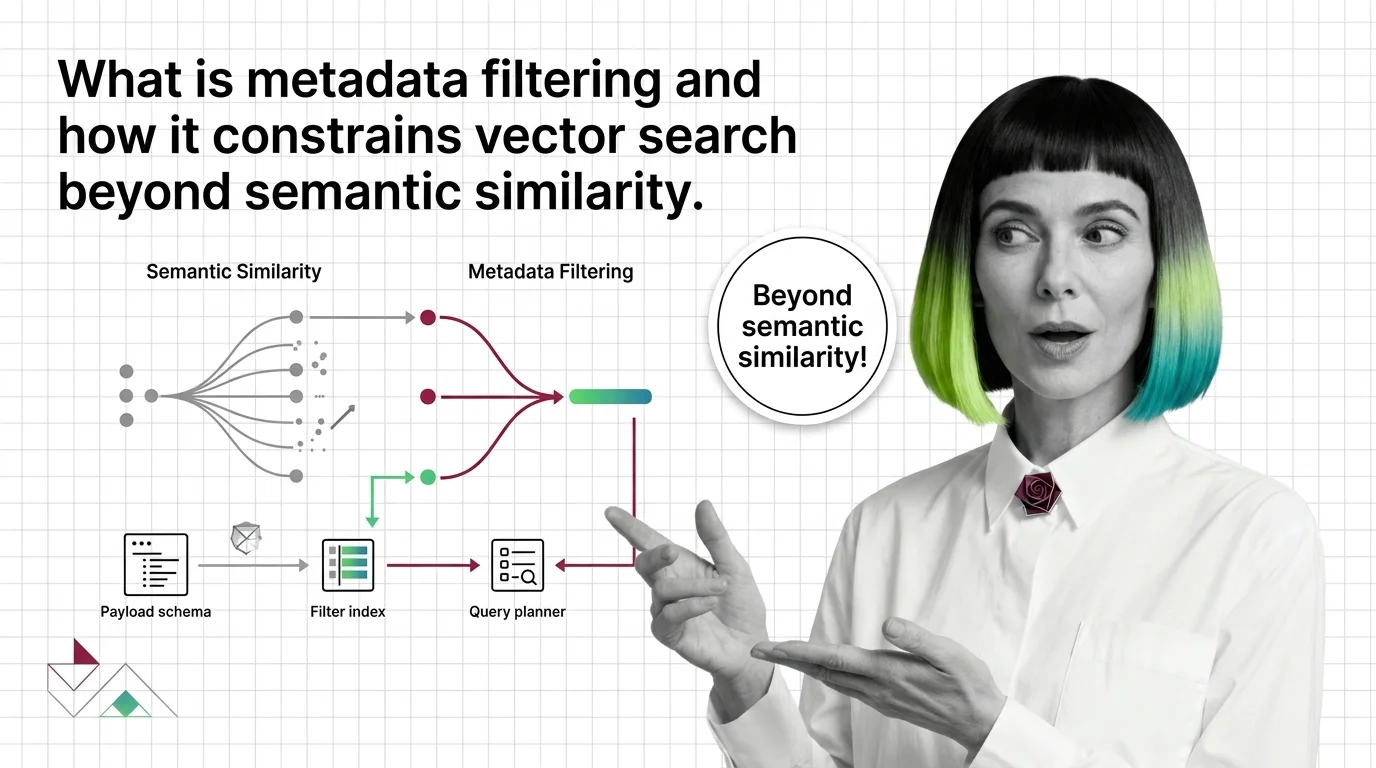
What Is Metadata Filtering and How It Constrains Vector Search Beyond Semantic Similarity
Metadata filtering attaches typed key-value payloads to each vector and applies predicates during search, narrowing …
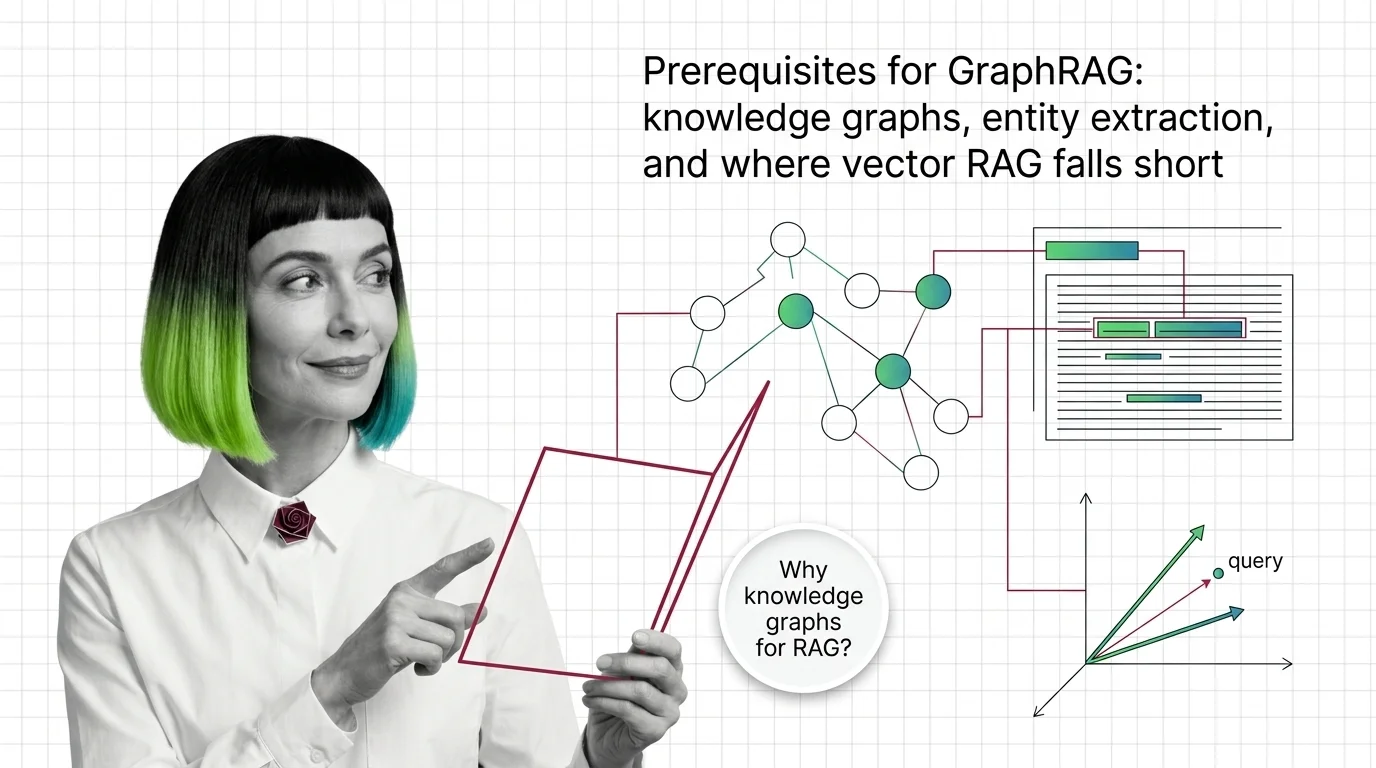
GraphRAG Prerequisites: Knowledge Graphs and Where Vector RAG Falls Short
GraphRAG inherits chunking, embeddings, and entity extraction from vector RAG. Learn what you need first and where the …

What Is GraphRAG? Multi-Hop Reasoning with Knowledge Graphs
GraphRAG turns documents into a knowledge graph and uses community summaries to answer multi-hop questions vector …
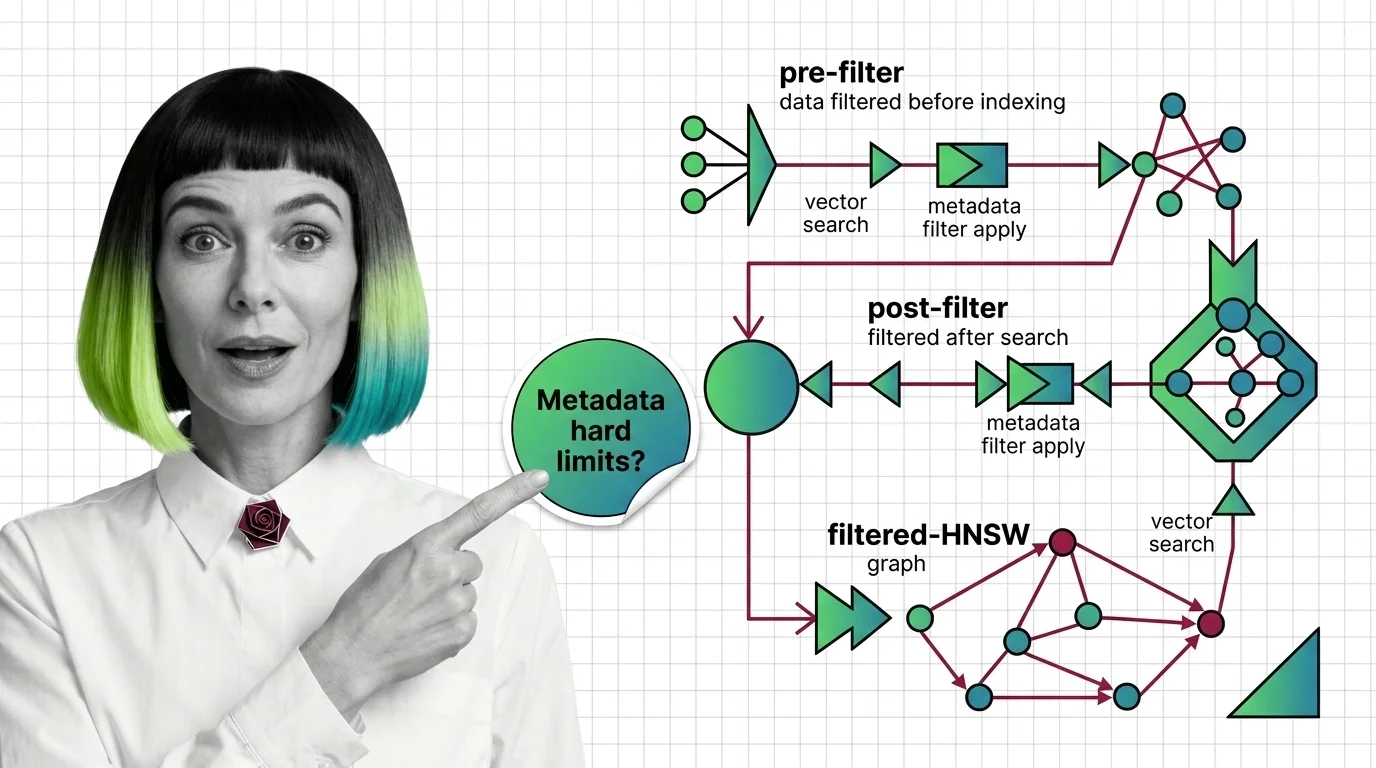
Pre-Filter vs Post-Filter vs Filtered-HNSW: Metadata Filtering at Scale
Why metadata filtering breaks vector search at scale — the HNSW prerequisites, payload indexing, and Boolean predicates …
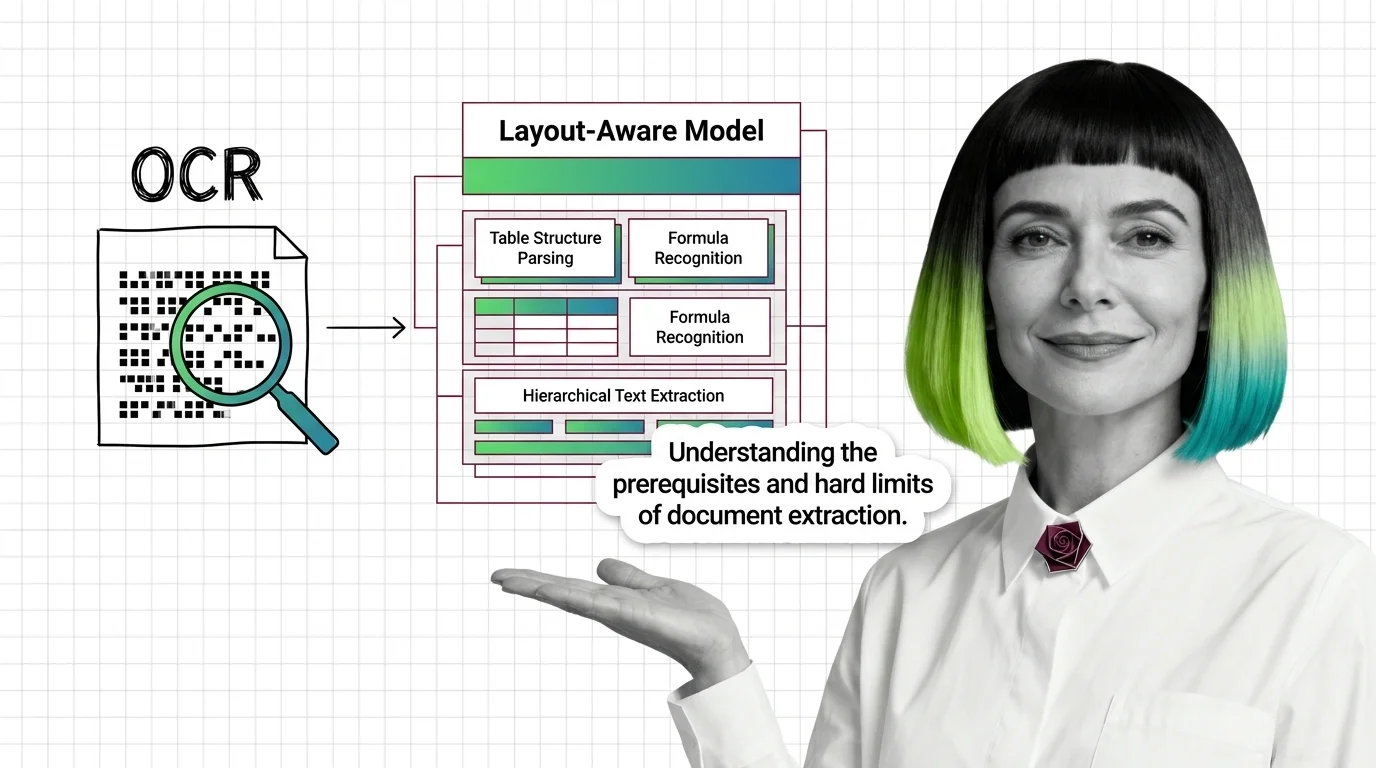
OCR to Layout-Aware Models: Prerequisites and Hard Limits
Document parsing breaks in predictable ways. Learn the prerequisites for understanding OCR and layout-aware models, and …
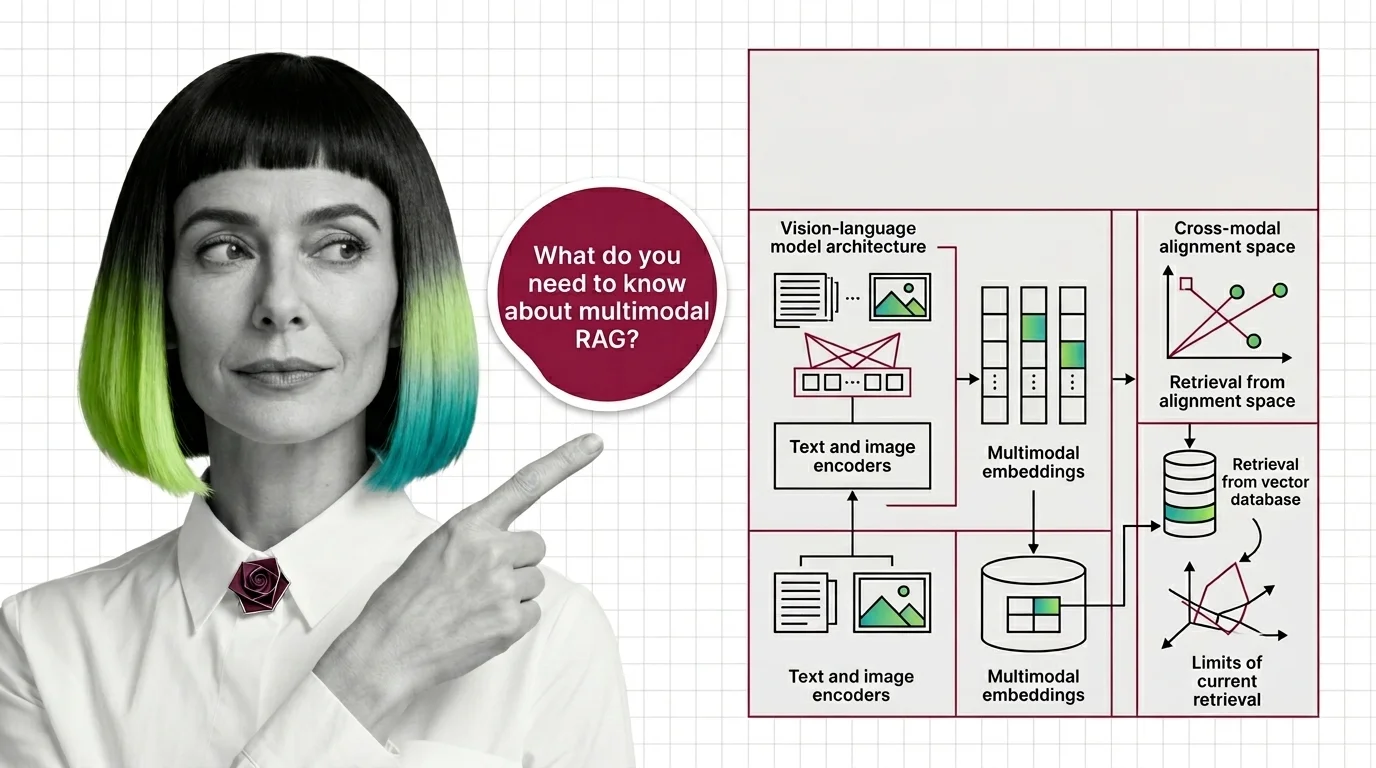
Multimodal RAG Prerequisites: Vision-Language Models, Cross-Modal Alignment
Before multimodal RAG works, you need vision-language models, shared embeddings, and a theory of cross-modal retrieval. …
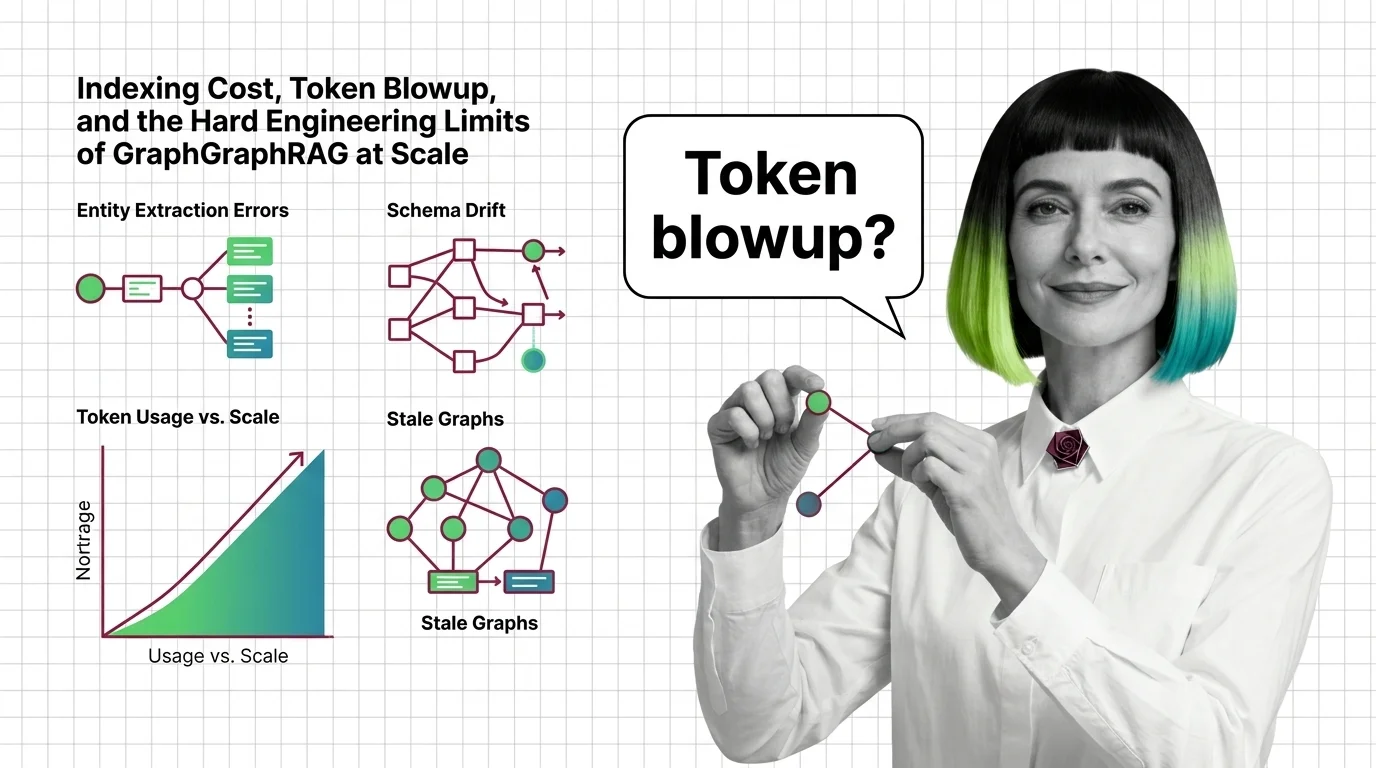
Indexing Cost, Token Blowup, and the Hard Engineering Limits of GraphRAG at Scale
GraphRAG indexing costs scale with token recursion, not document size. A breakdown of the cost cliff, hallucinated …
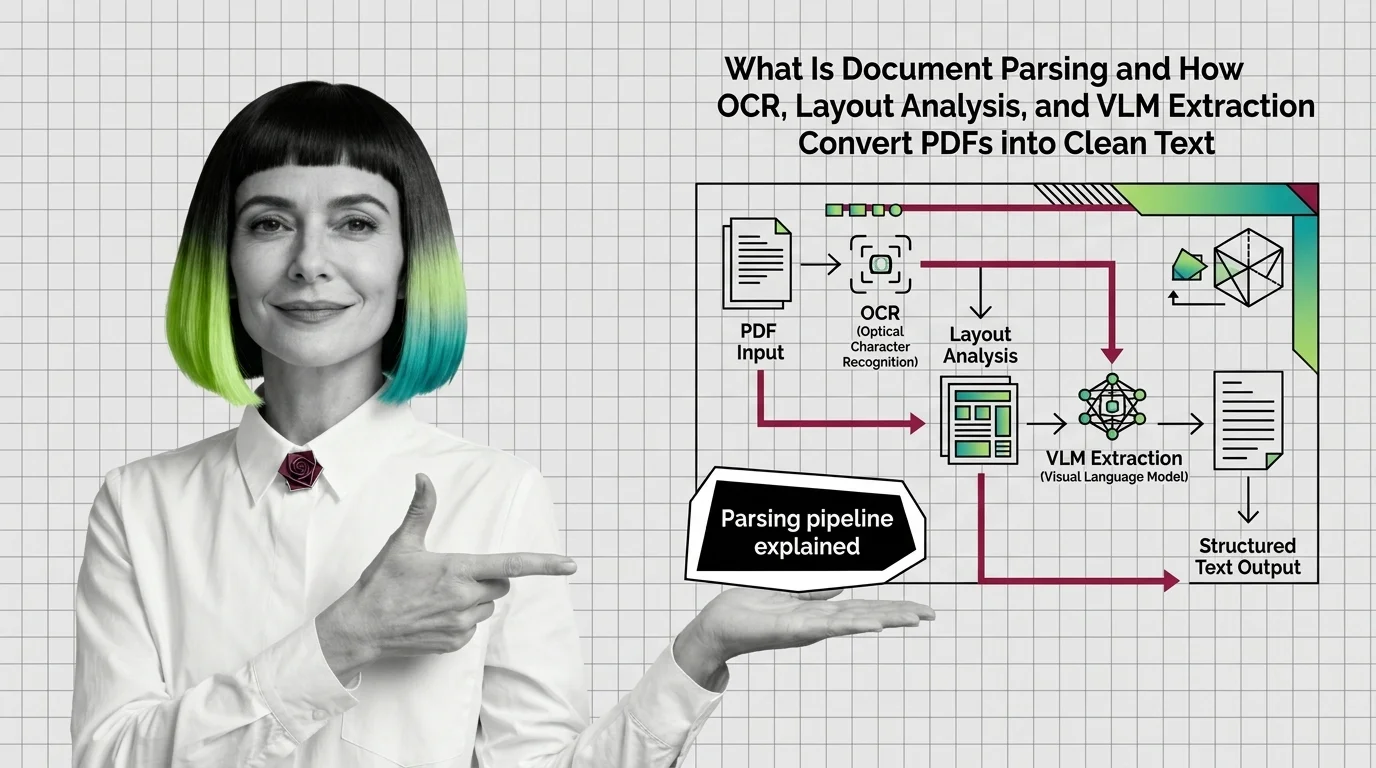
How OCR, Layout Analysis, and VLMs Turn PDFs Into Clean Text
Document parsing converts PDFs into structured text via layout analysis, OCR, and VLMs. Here is how each component works …

Lost in the Middle, 1,250x Cost: The Limits of Long-Context vs RAG
Long-context windows promise simplicity, but lost-in-the-middle, 1,250x cost gaps, and effective-context collapse at 32K …
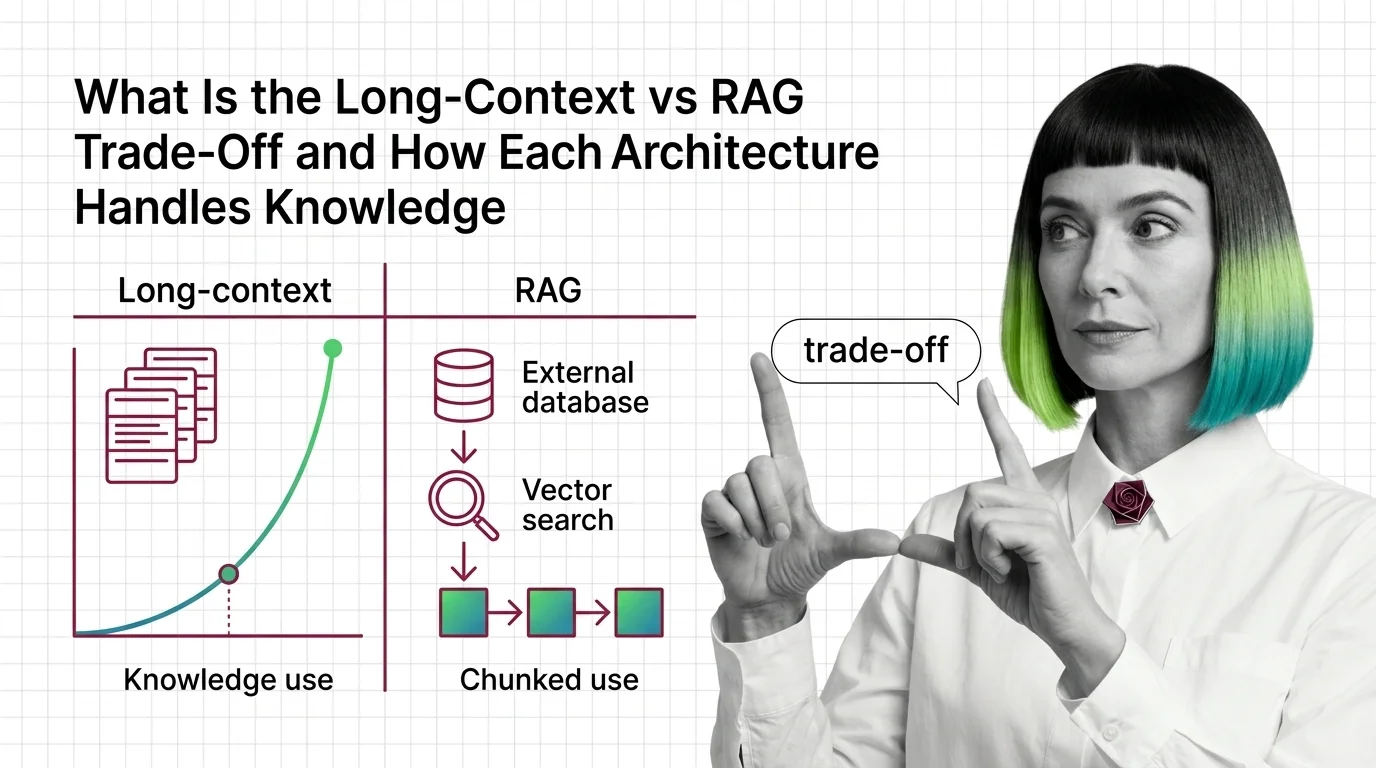
Long-Context vs RAG: How Each Handles Knowledge in 2026
Long-context and RAG sound interchangeable. They are not. The mechanics, failure modes, and cost curves diverge — see …
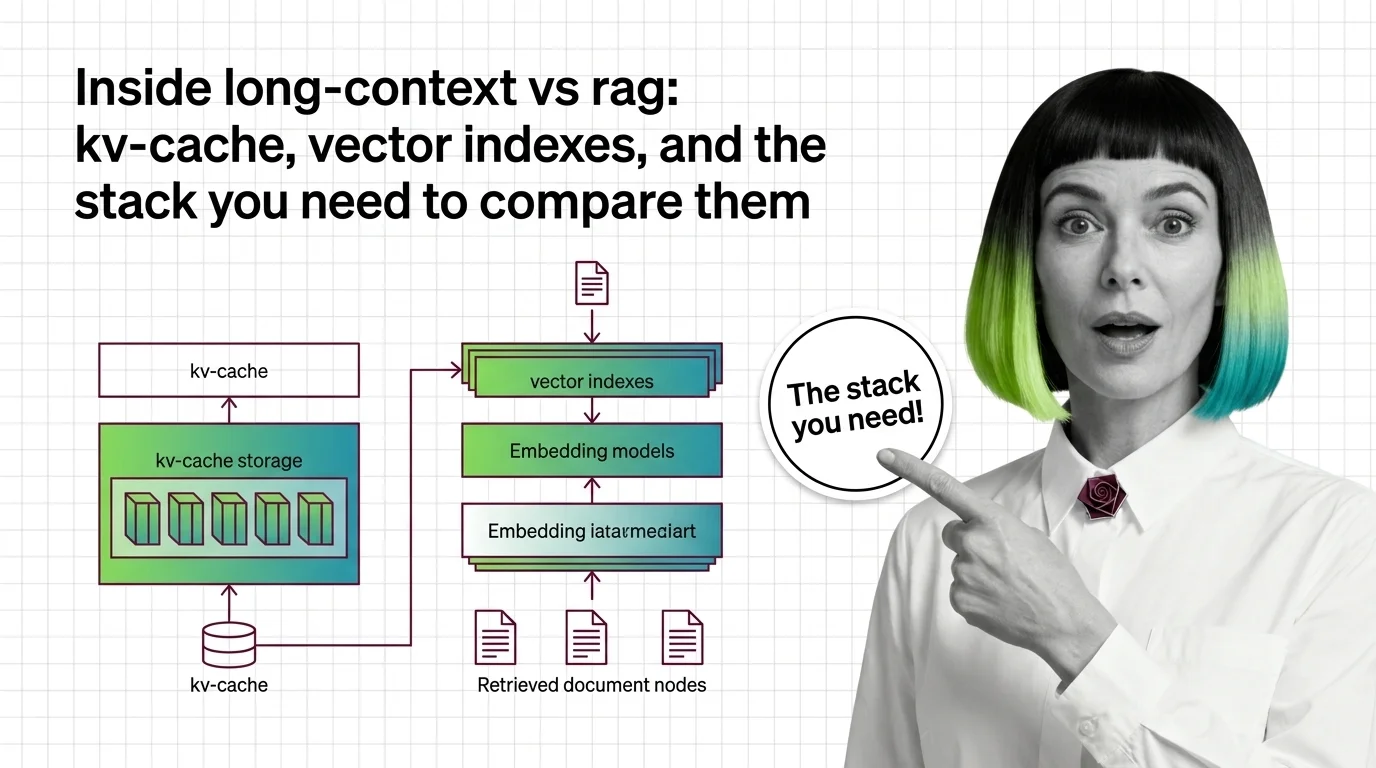
Inside Long-Context vs RAG: KV-Cache, Vector Indexes, and the Stack You Need to Compare Them
Long-context models and RAG pipelines compete for the same job with different parts. A component-by-component map of KV …
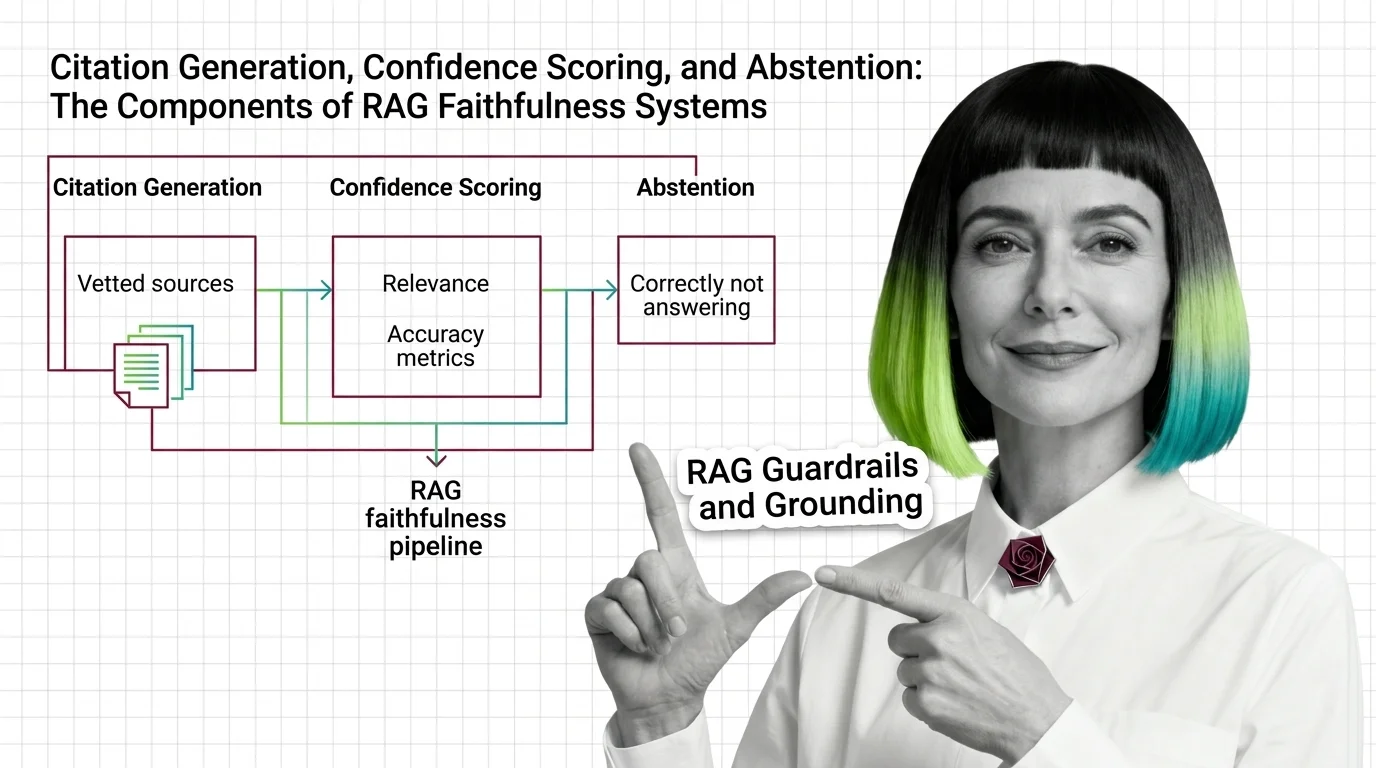
Citation, Confidence, and Abstention: The 3 Layers of RAG Faithfulness
RAG grounding splits into three layers: citation generation, confidence scoring, and abstention. See how each fails …
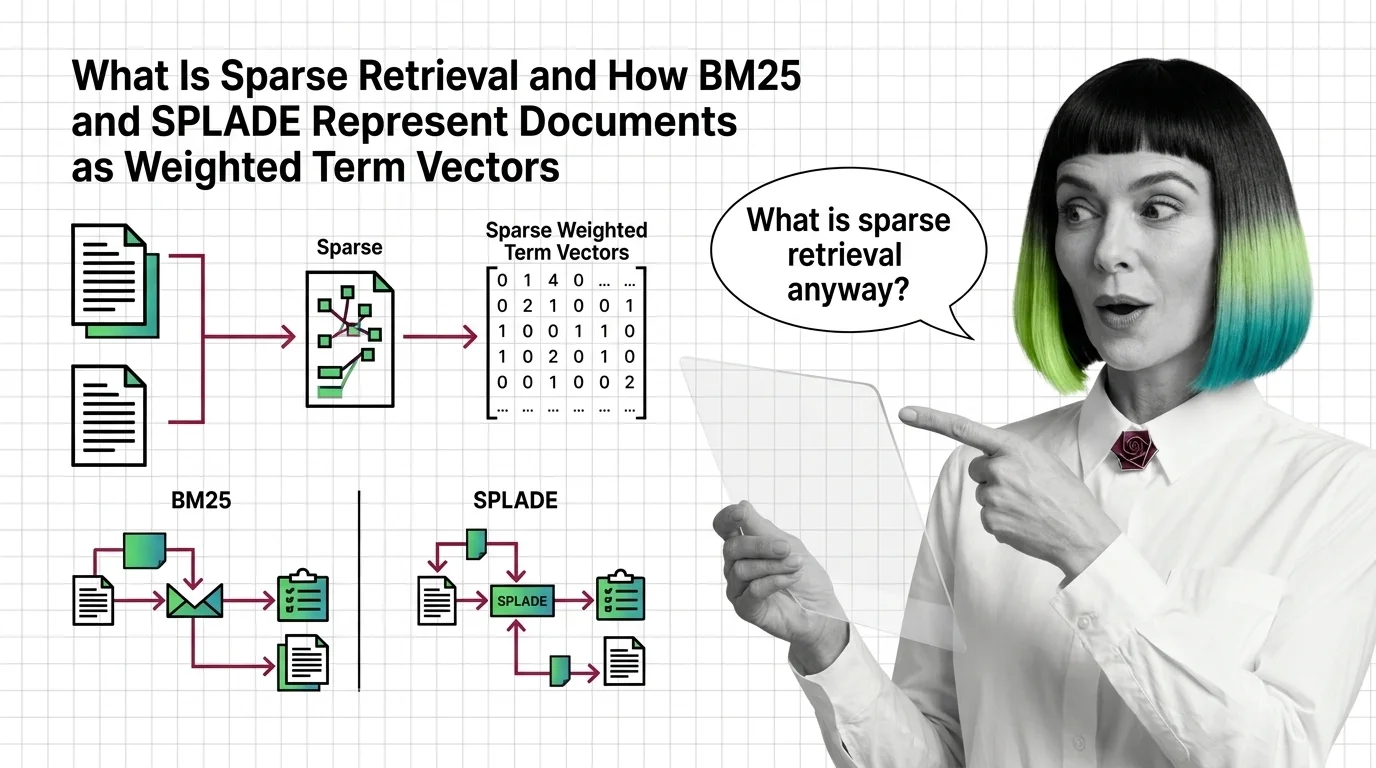
What Is Sparse Retrieval and How BM25 and SPLADE Represent Documents as Weighted Term Vectors
Sparse retrieval encodes documents as weighted term vectors. Here is how BM25 and SPLADE produce those weights and why …
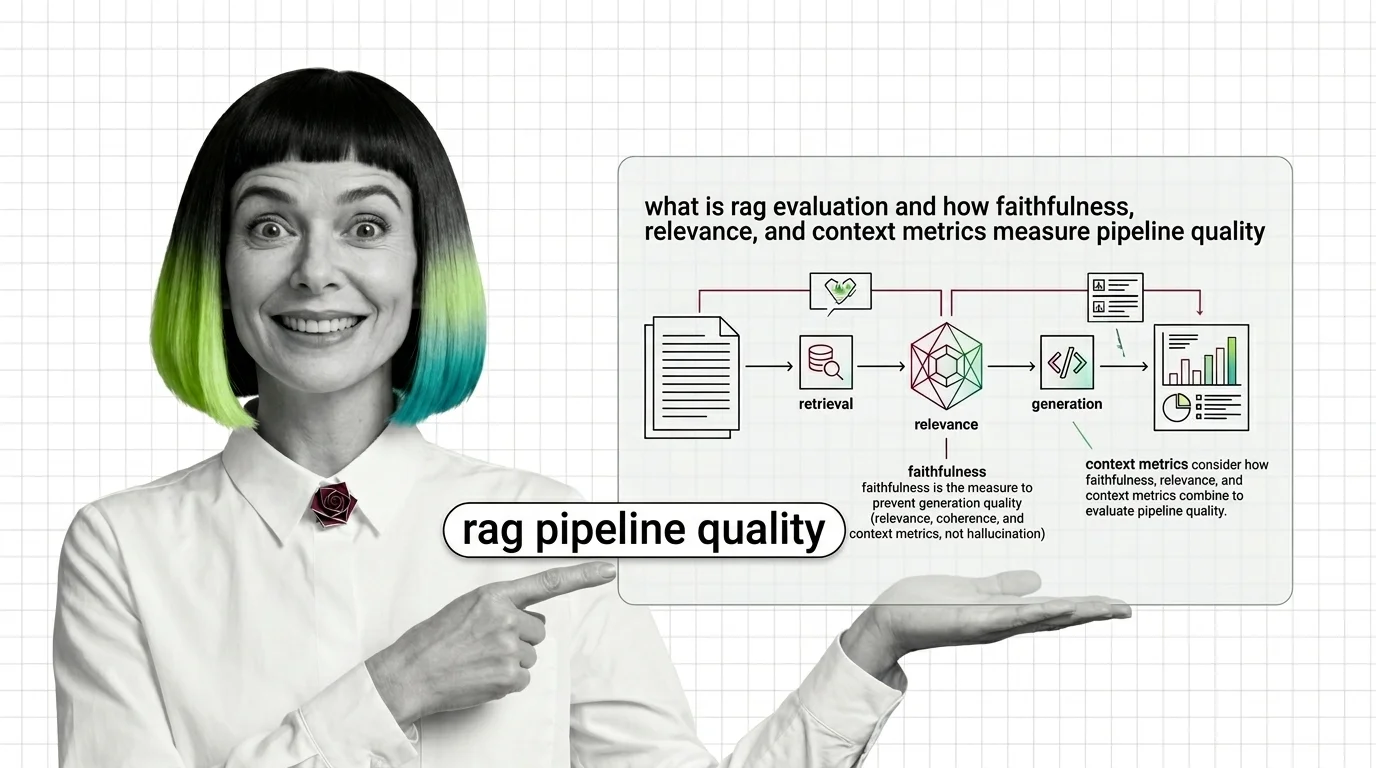
RAG Evaluation Explained: Faithfulness, Relevance, Context Metrics
RAG evaluation splits your pipeline into retriever and generator and scores each. Learn how Faithfulness, Relevance, and …
From Recall and MRR to Faithfulness: RAG Evaluation Prerequisites
RAG evaluation needs more than one accuracy score. Learn the IR and generation metrics — Recall, MRR, Faithfulness, …

Why RAG Grounding Still Fails: The Hallucination Detection Ceiling
RAG hallucination detection has a certified ceiling. Why HHEM, Lynx, TruLens, and NeMo Guardrails miss the hardest …

What Are RAG Guardrails and How Grounding Stops Hallucinations
RAG guardrails and grounding force generated answers to stay tied to retrieved sources. Learn how the mechanism works in …

Prerequisites for RAG Grounding: Retrieval Quality, the RAG Triad, and Faithfulness Metrics
Before you bolt guardrails onto a RAG pipeline, learn the RAG Triad — context relevance, groundedness, answer relevance …
LLM-as-Judge Bias and the Technical Limits of RAG Evaluation
RAG evaluation frameworks like RAGAS rely on LLM judges with documented biases. Why faithfulness and answer relevancy …
From TF-IDF to Learned Sparse: Prerequisites and Hard Limits of BM25, SPLADE, and ELSER
Sparse retrieval starts with BM25 and ends with ELSER and SPLADE-v3. Learn the math, the prerequisites, and where each …
From RAG to Agents: Prerequisites and Hard Limits of Agentic RAG
Agentic RAG is a stack with new failure modes, not an upgrade. Learn the prerequisites and the four physics that limit …
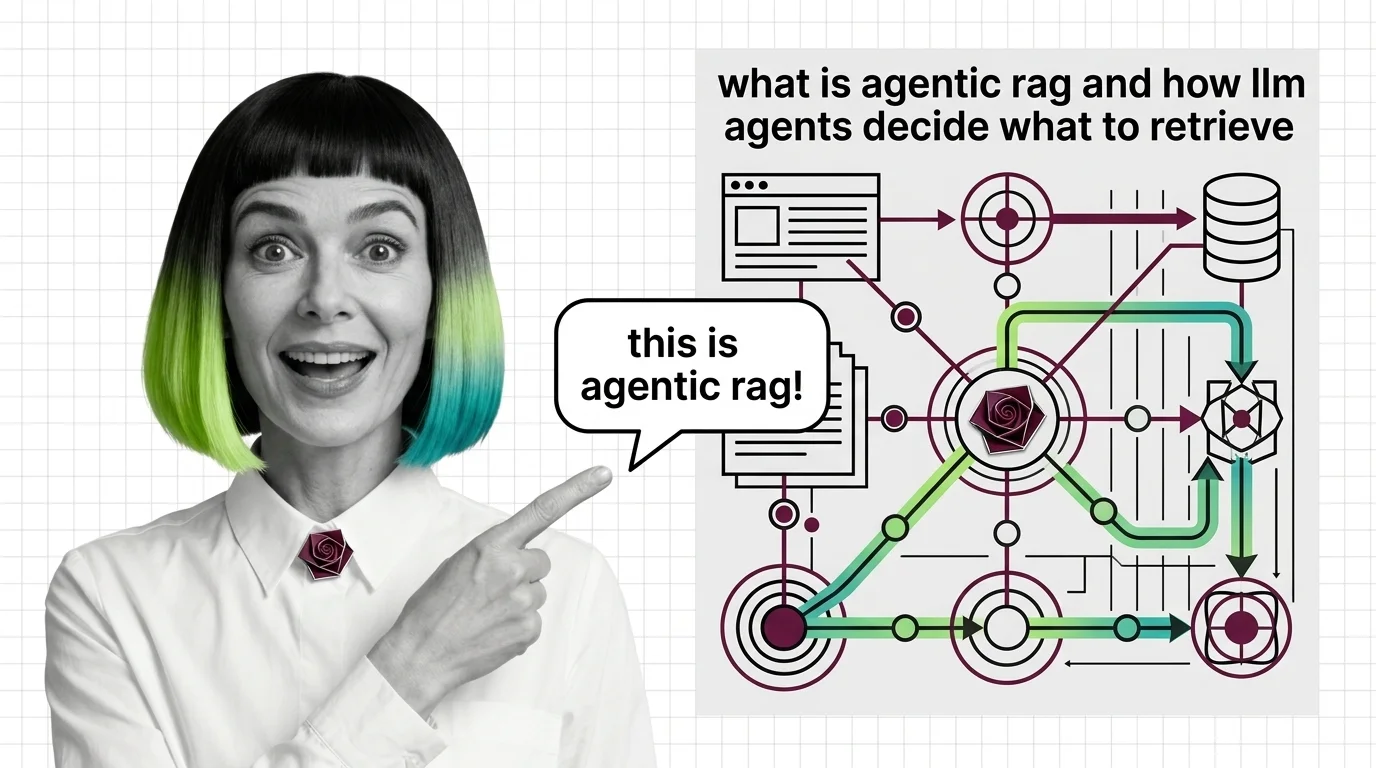
What Is Agentic RAG and How LLM Agents Decide What to Retrieve
Agentic RAG turns retrieval into a decision: an LLM agent chooses whether to retrieve, which source to query, and …
Contextual Retrieval: Prerequisites and Hard Limits at Scale
Contextual Retrieval cuts RAG failure rates, but at a cost. Learn the prerequisites — chunking, hybrid search, reranking …

Contextual Retrieval: How Prepended Context Reduces RAG Failures
Contextual retrieval prepends 50-100 tokens of LLM-generated context to each chunk before indexing. Anthropic reports a …
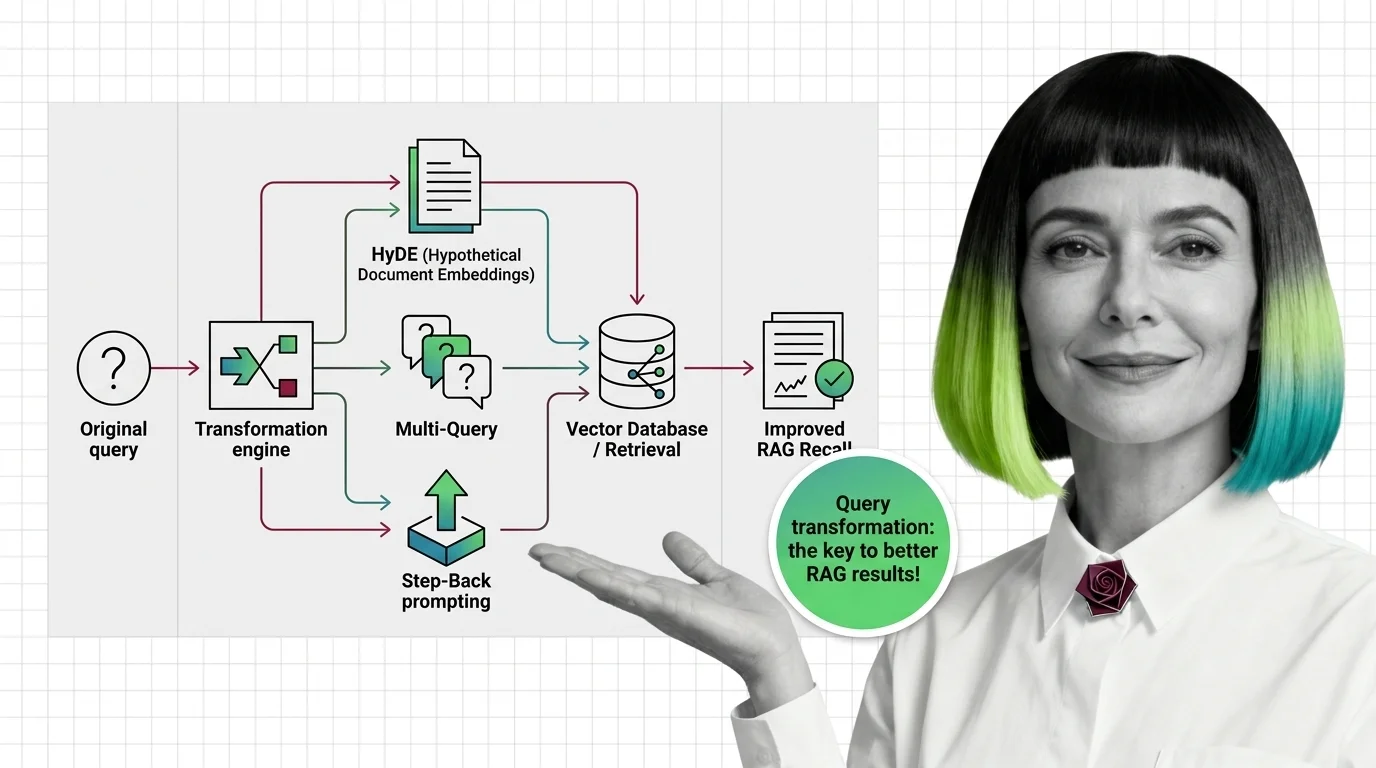
How HyDE, Multi-Query, and Step-Back Improve RAG Retrieval Recall
Query transformation rewrites user prompts before retrieval. Learn how HyDE, Multi-Query, and Step-Back Prompting close …
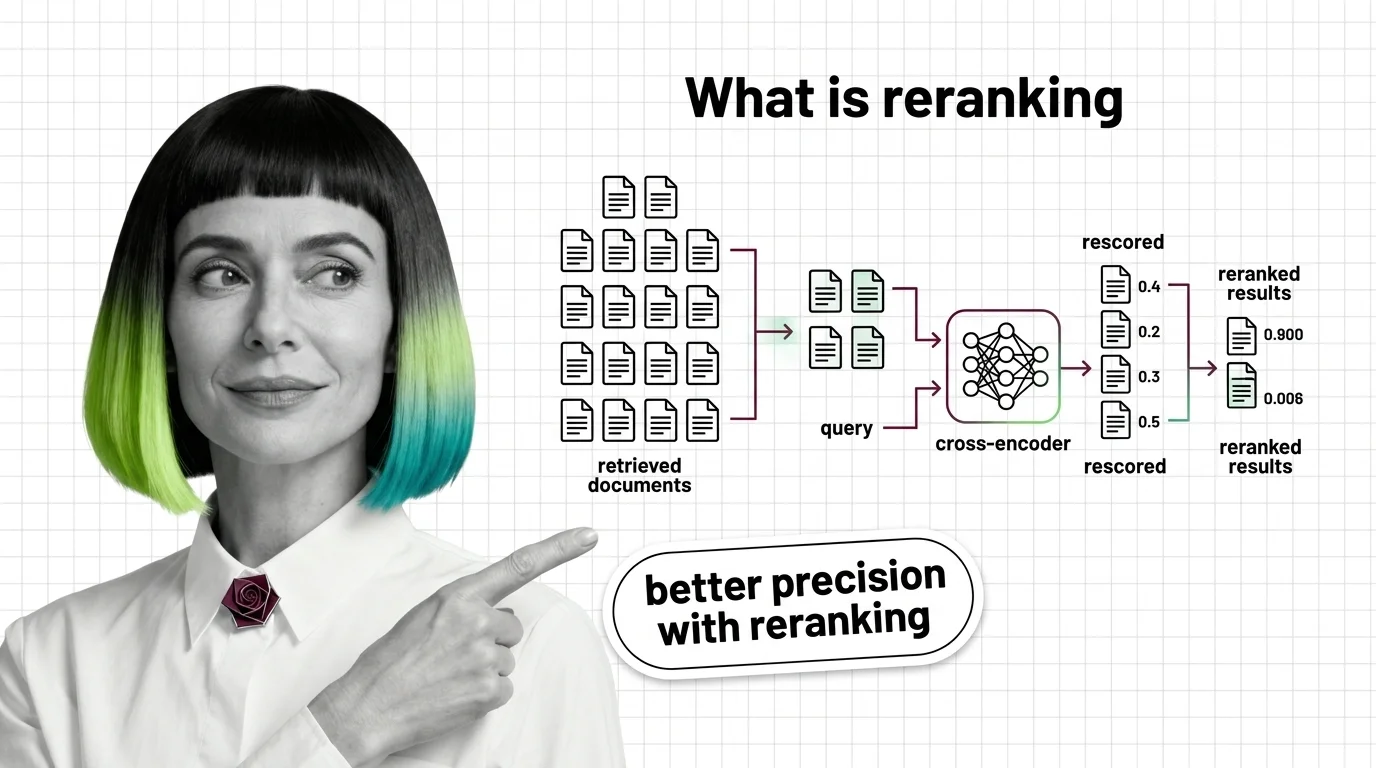
What Is Reranking and Why Cross-Encoders Rescore RAG Retrieval
Reranking splits recall and precision into two stages. See how cross-encoders rescore retrieved documents and why a …
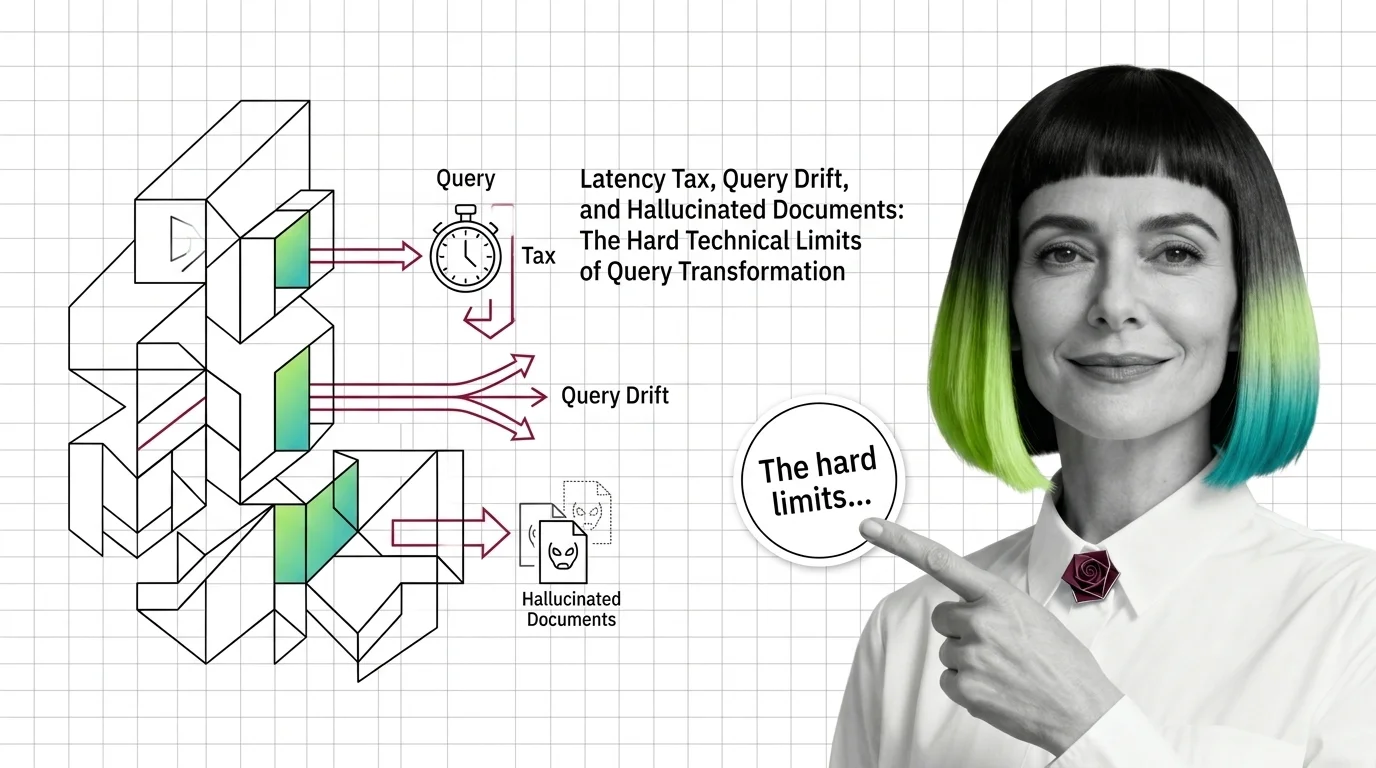
Query Transformation Limits: Latency Tax, Drift, Hallucinated Documents
Query transformation in RAG hits three hard limits: latency tax from extra LLM calls, query drift on simple inputs, and …
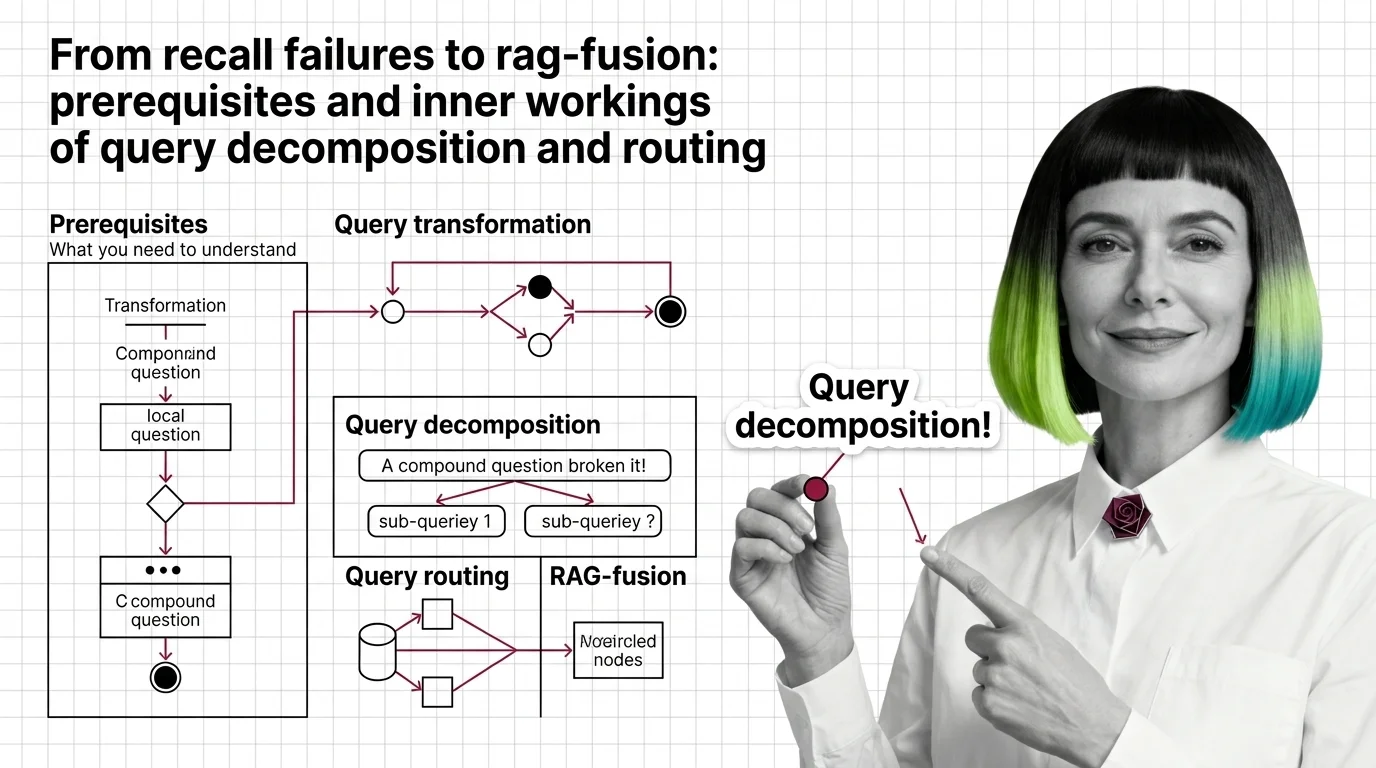
From Recall Failures to RAG-Fusion: Prerequisites and Inner Workings of Query Decomposition and Routing
Vector retrievers lose compound questions to a single point. Query decomposition, routing, and RAG-Fusion fix it by …
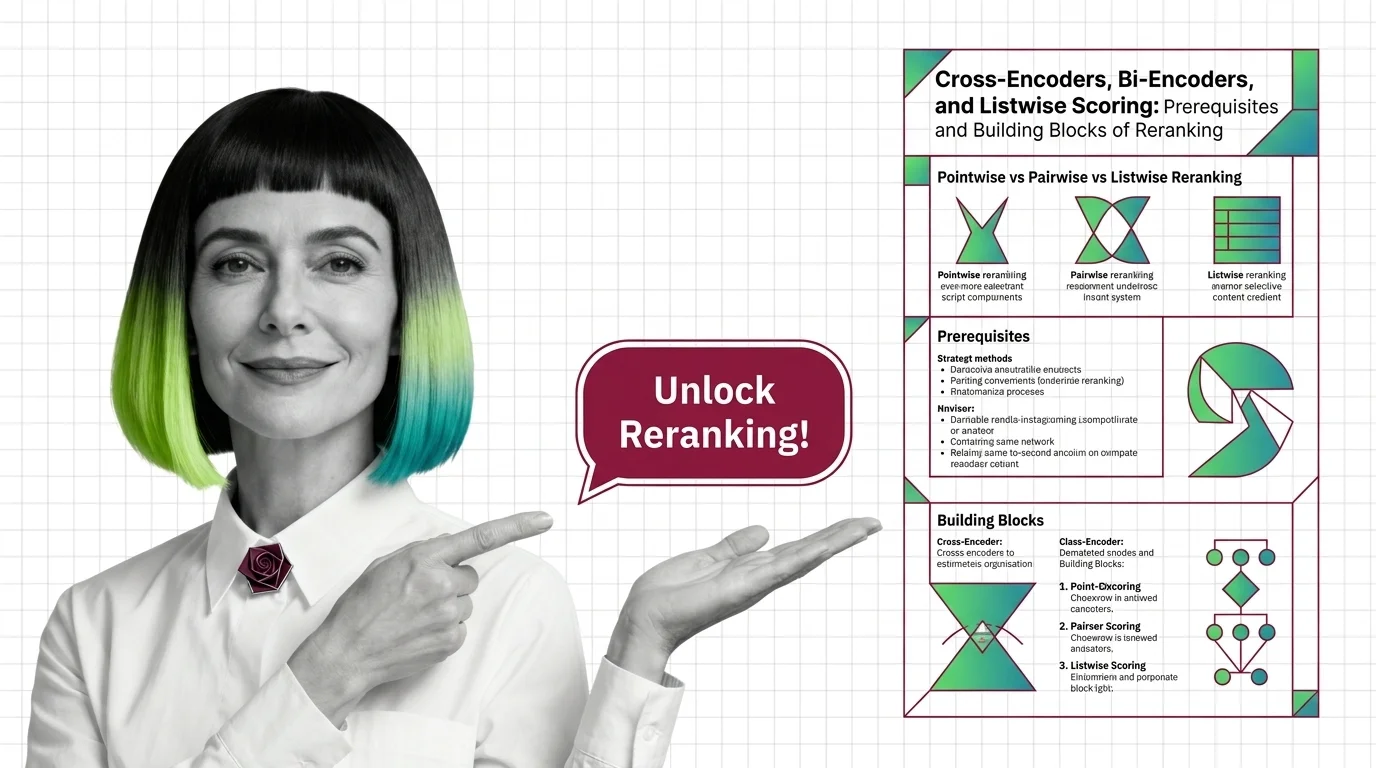
Cross-Encoders, Bi-Encoders, and Listwise Scoring in Reranking
A reranker reorders the top candidates from vector search using a heavier model. Cross-encoders, bi-encoders, and …
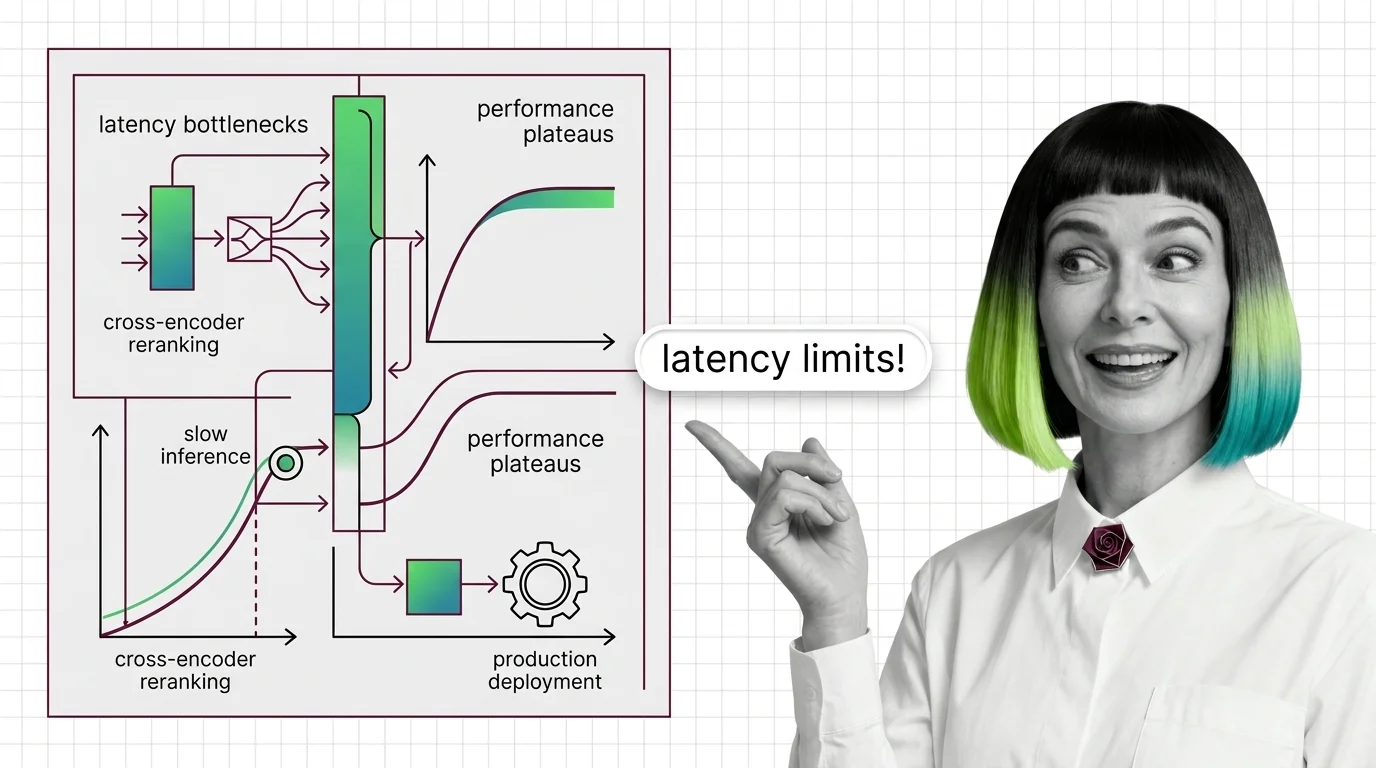
Cross-Encoder Reranker Limits: Latency Walls and Domain Drift
Cross-encoder rerankers hit two architectural walls: latency scales linearly with candidates and quadratically with …
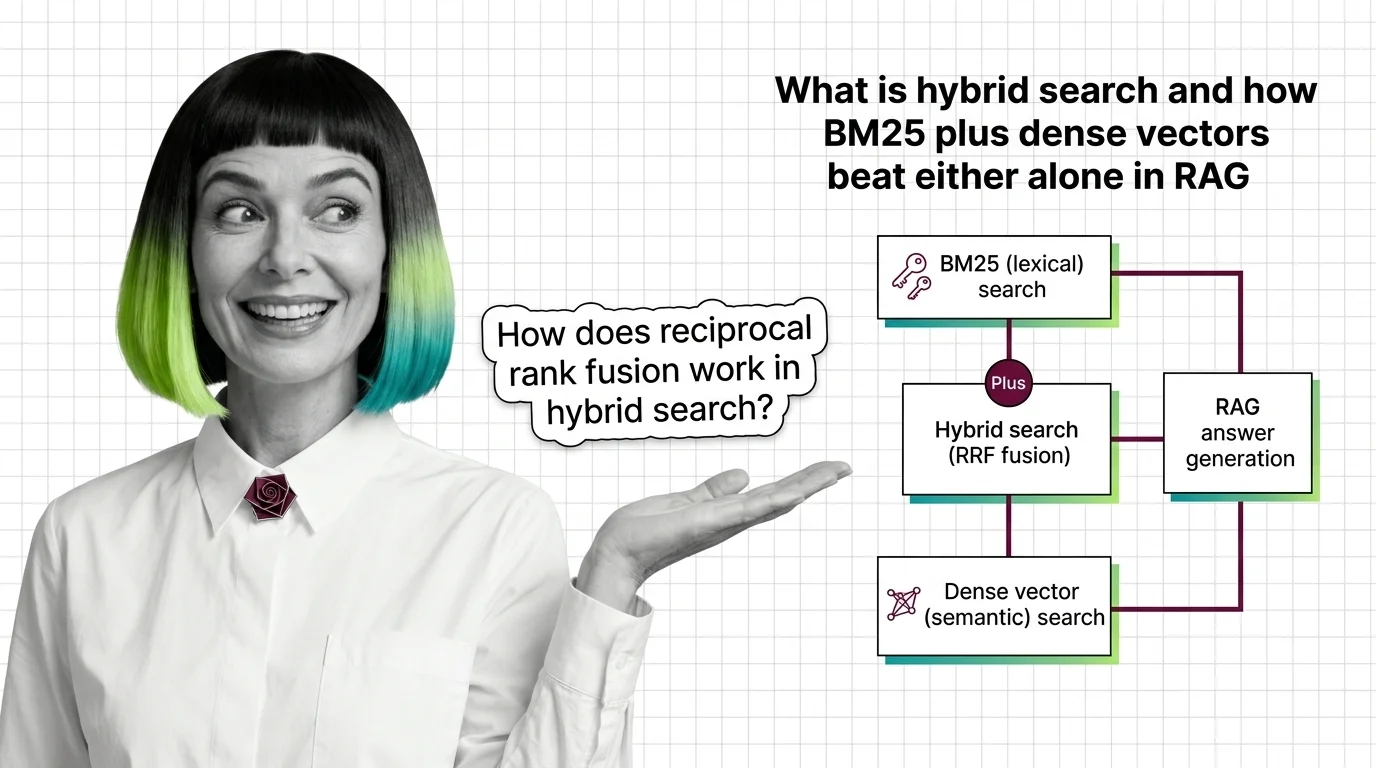
What Is Hybrid Search and How BM25 Plus Dense Vectors Beat Either Alone in RAG
Hybrid search fuses BM25 keyword retrieval with dense vector search using reciprocal rank fusion. Why two ranked lists …
BM25, SPLADE, and Reciprocal Rank Fusion: The Building Blocks of Production Hybrid Search
BM25, SPLADE, and reciprocal rank fusion each solve a different retrieval problem. Here's how the three combine into a …

Why RAG Still Fails in Production: Retrieval, Chunking, Grounding
RAG fails in production because retrieval, chunking, and grounding hit structural limits — not because of bugs. Why …
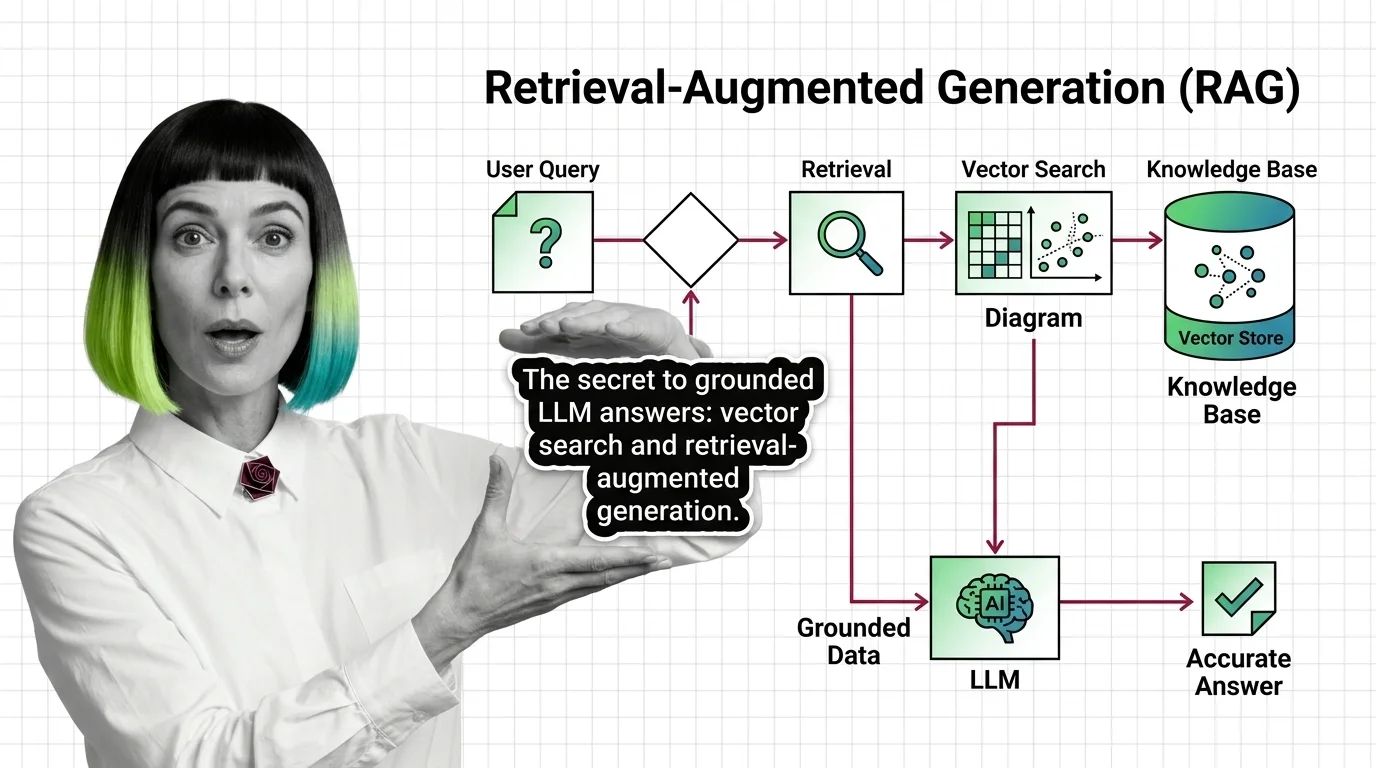
What Is RAG and How LLMs Use Vector Search to Ground Their Answers
Retrieval-augmented generation pairs an LLM with a vector index so answers are grounded in real documents — not just …

Score Mismatch, Tuning Hell: The Hard Limits of Hybrid Search Fusion
Hybrid search merges BM25 and vector results, but the fusion step has hard limits. Score mismatch, RRF blindness, and …
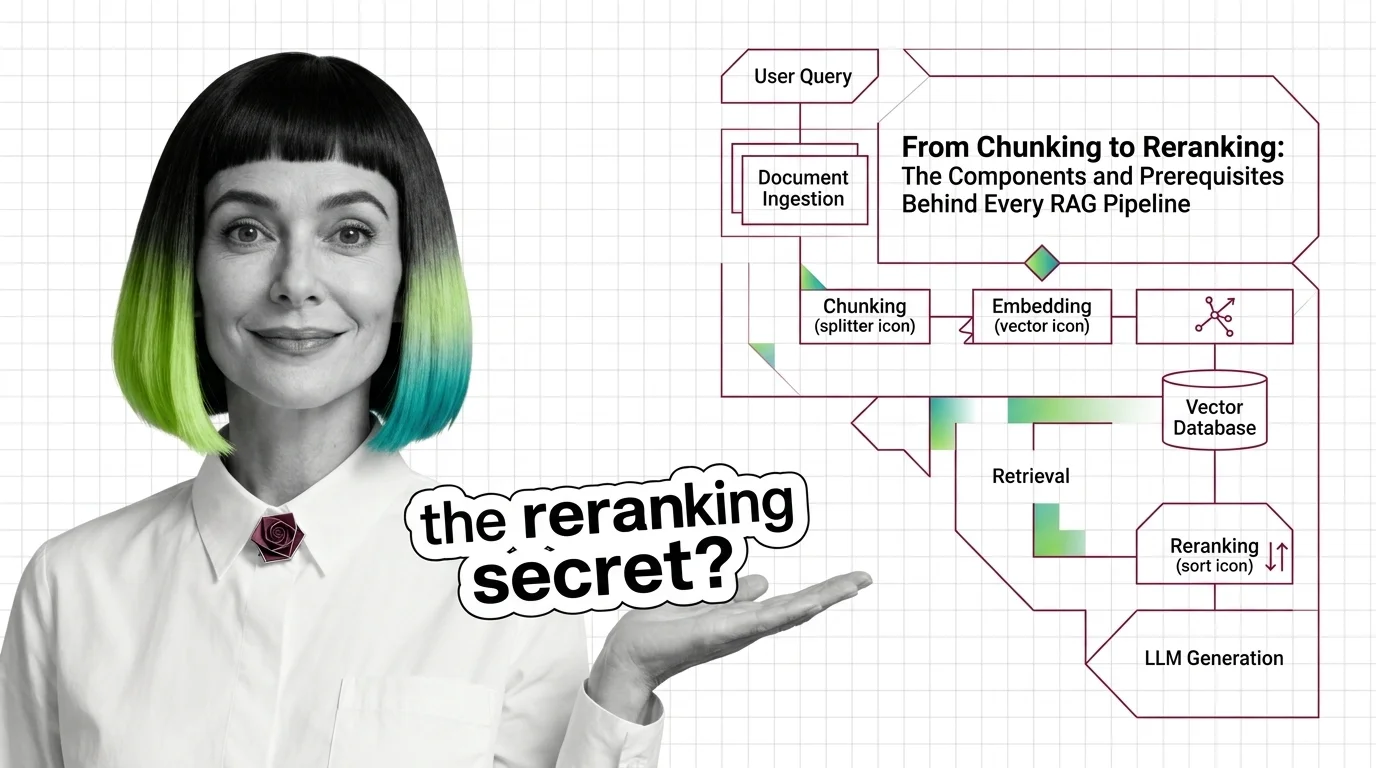
From Chunking to Reranking: RAG Pipeline Components and Prerequisites
Every RAG pipeline runs five components — chunker, embedder, vector store, retriever, reranker. Here is what each one …
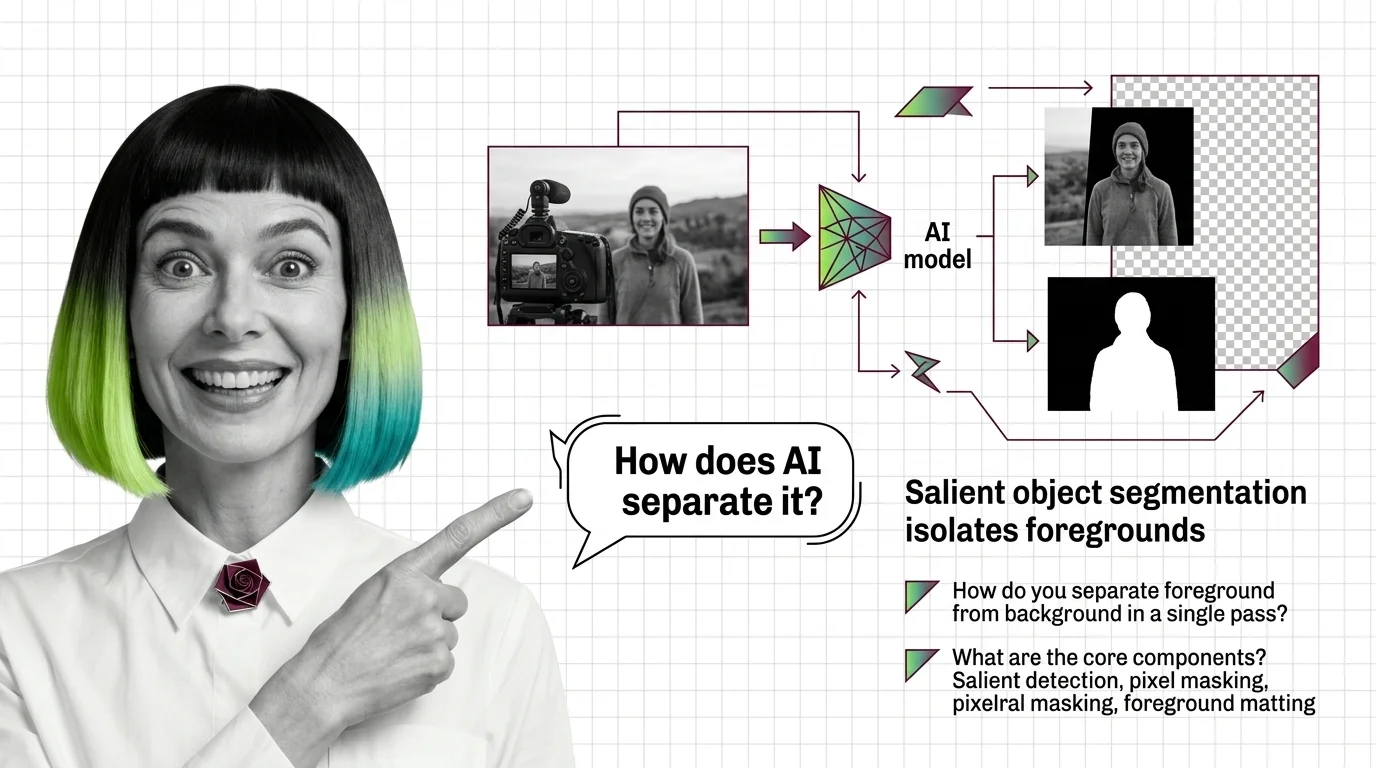
What Is AI Background Removal? How Salient Object Segmentation Works
AI background removal is not one model — it's salient object detection plus alpha matting. See how U2-Net, BiRefNet, and …
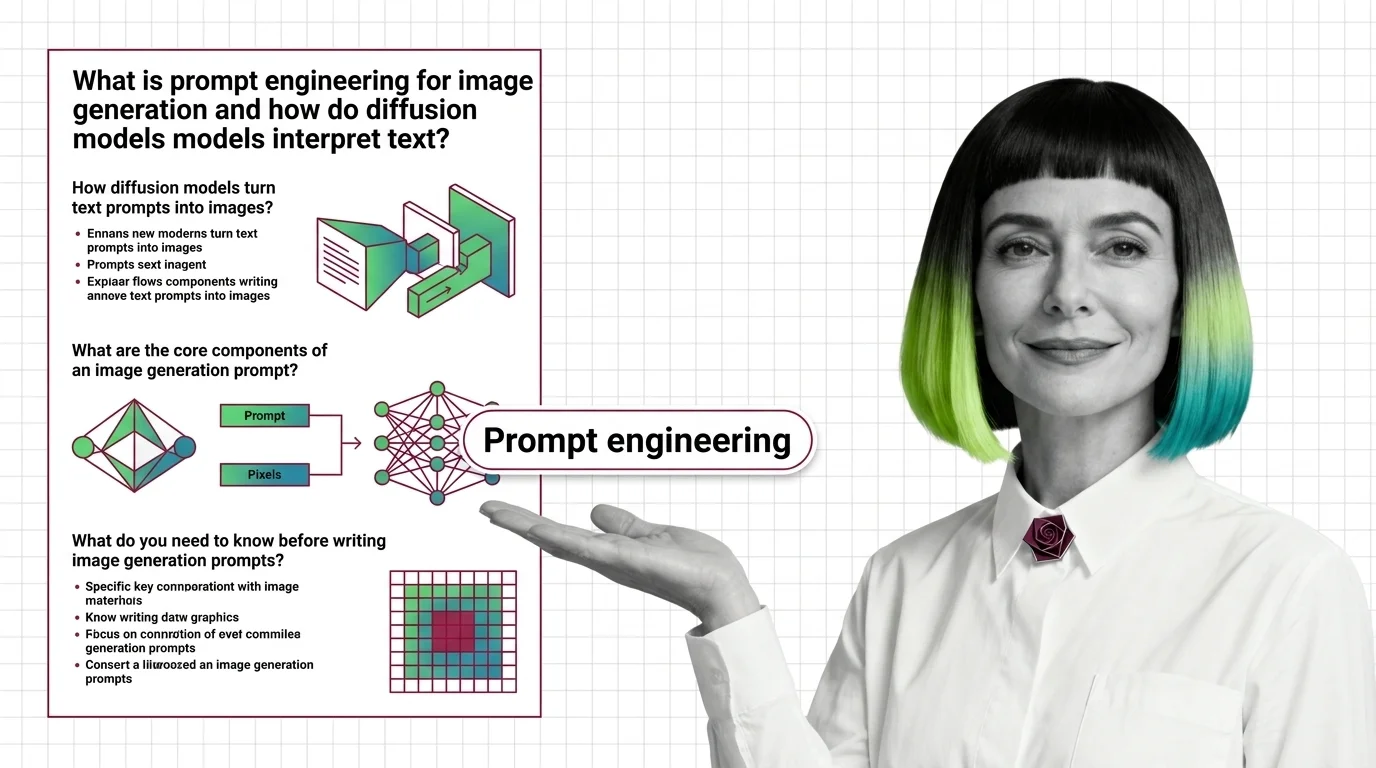
Prompt Engineering for Image Generation: How Diffusion Models Read Text
Image prompts steer probability, not pixels. Learn how diffusion models, cross-attention, and CFG turn text into images …
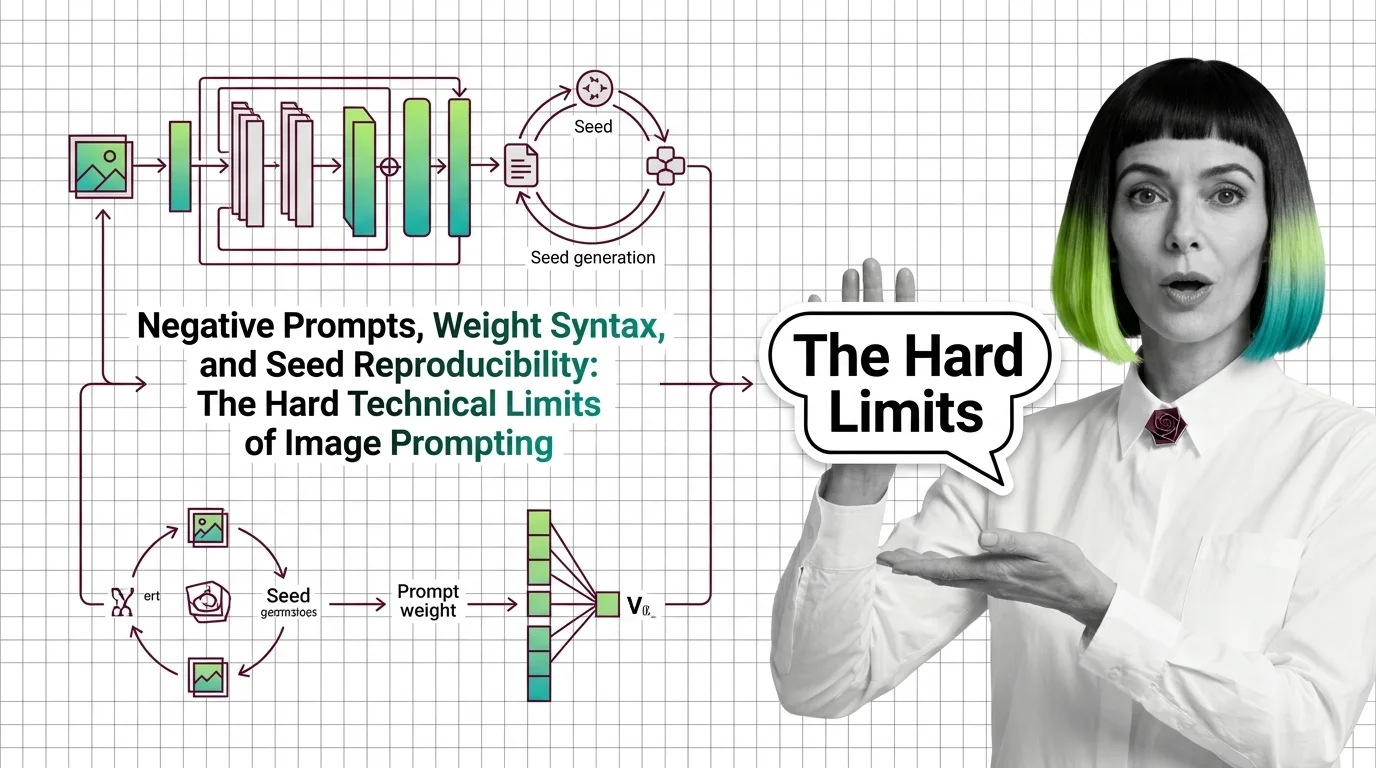
Negative Prompts, Weights, Seeds: Image Prompting Limits 2026
Negative prompts and weight syntax aren't universal — and seed reproducibility breaks across model versions. Inside the …
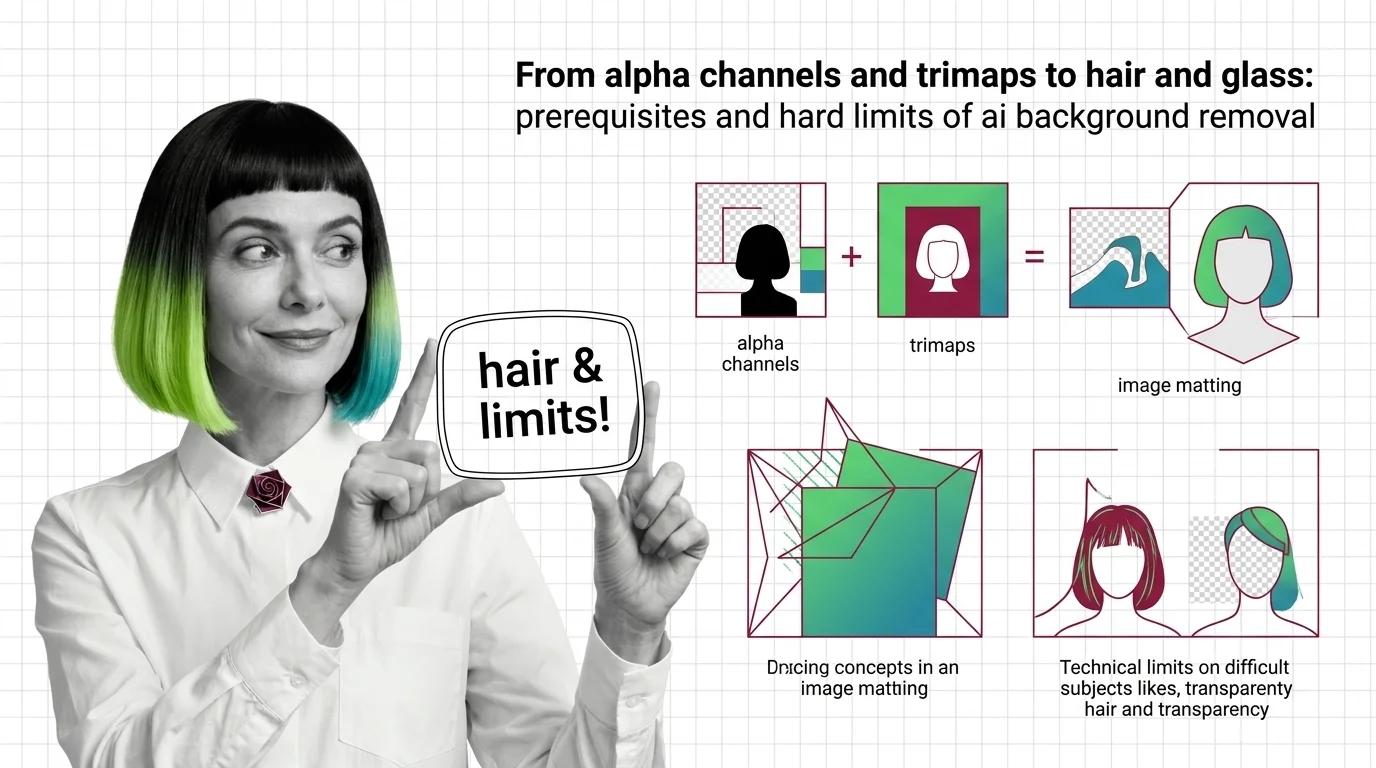
Alpha Channels, Trimaps, and the Hard Limits of AI Background Removal
Background removal is alpha estimation, not subject detection. Learn how trimaps and matting work, and why hair, glass, …
How LoRA Fine-Tunes Diffusion Models for Image Generation
LoRA fine-tunes Stable Diffusion and FLUX without retraining. Learn how rank, alpha, and the BA decomposition turn a …

Why AI Upscalers Hallucinate Faces and Tile Seams at 4K and 8K
AI upscalers don't break at 4K and 8K because of weak hardware. The failures are structural — rooted in diffusion priors …
What Is Image Upscaling and How AI Super-Resolution Reconstructs Detail Beyond the Original Pixels
AI image upscaling doesn't enlarge what was captured — it generates plausible pixels from a learned prior. Learn how GAN …
Training Image LoRAs: Diffusion Math, Rank-Alpha, and VRAM Limits
Image LoRAs retarget diffusion models with small adapter files. Learn the rank-alpha math, VRAM ranges from SD 1.5 to …
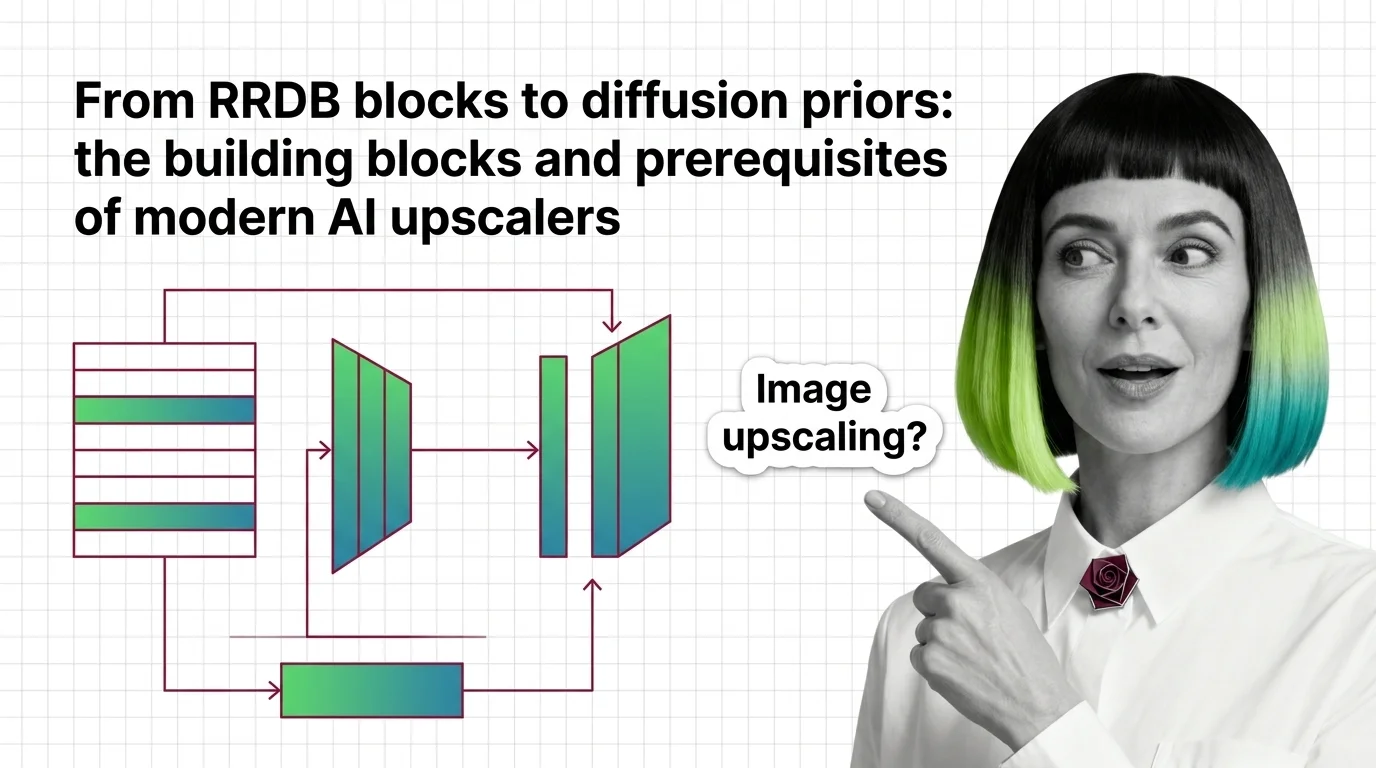
From RRDB Blocks to Diffusion Priors: Inside Modern AI Upscalers
How modern AI upscalers are built — from ESRGAN's RRDB blocks and Real-ESRGAN to SUPIR's diffusion prior, plus the …
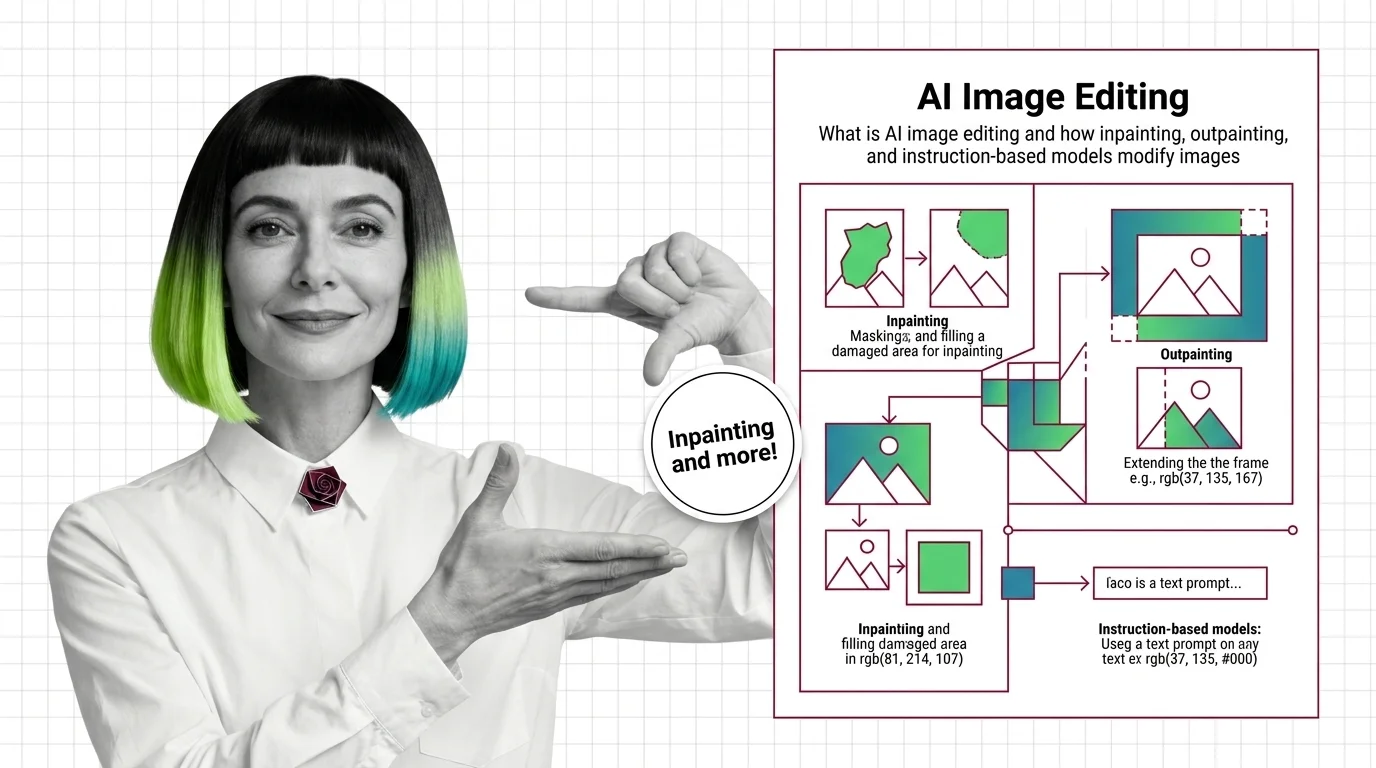
What Is AI Image Editing? Inpainting, Outpainting, Edit Models
AI image editing uses diffusion to modify pixels under a mask or follow text instructions. Learn how inpainting, …

From Diffusion to InstructPix2Pix: AI Image Editing Prerequisites
Before using GPT Image or FLUX, understand diffusion, classifier-free guidance, and why InstructPix2Pix made …

What Is a Diffusion Model? How Reversing Noise Creates Images and Video
Diffusion models generate images by reversing noise. Learn how forward and reverse processes differ, and why predicting …
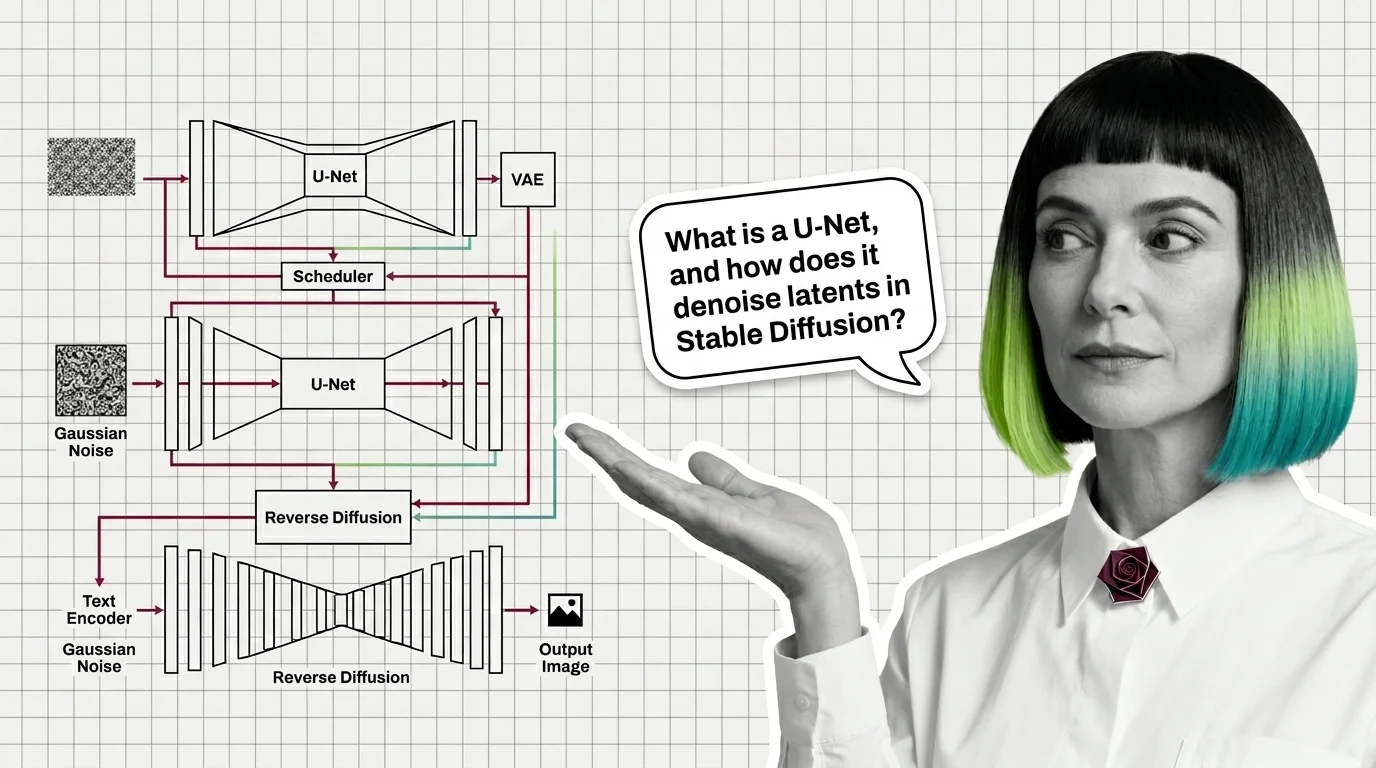
U-Net, VAE, Schedulers, and Text Encoders: The Anatomy of a Modern Diffusion Model
A modern diffusion model is not one network but four: a VAE for compression, a U-Net or DiT denoiser, a text encoder, …
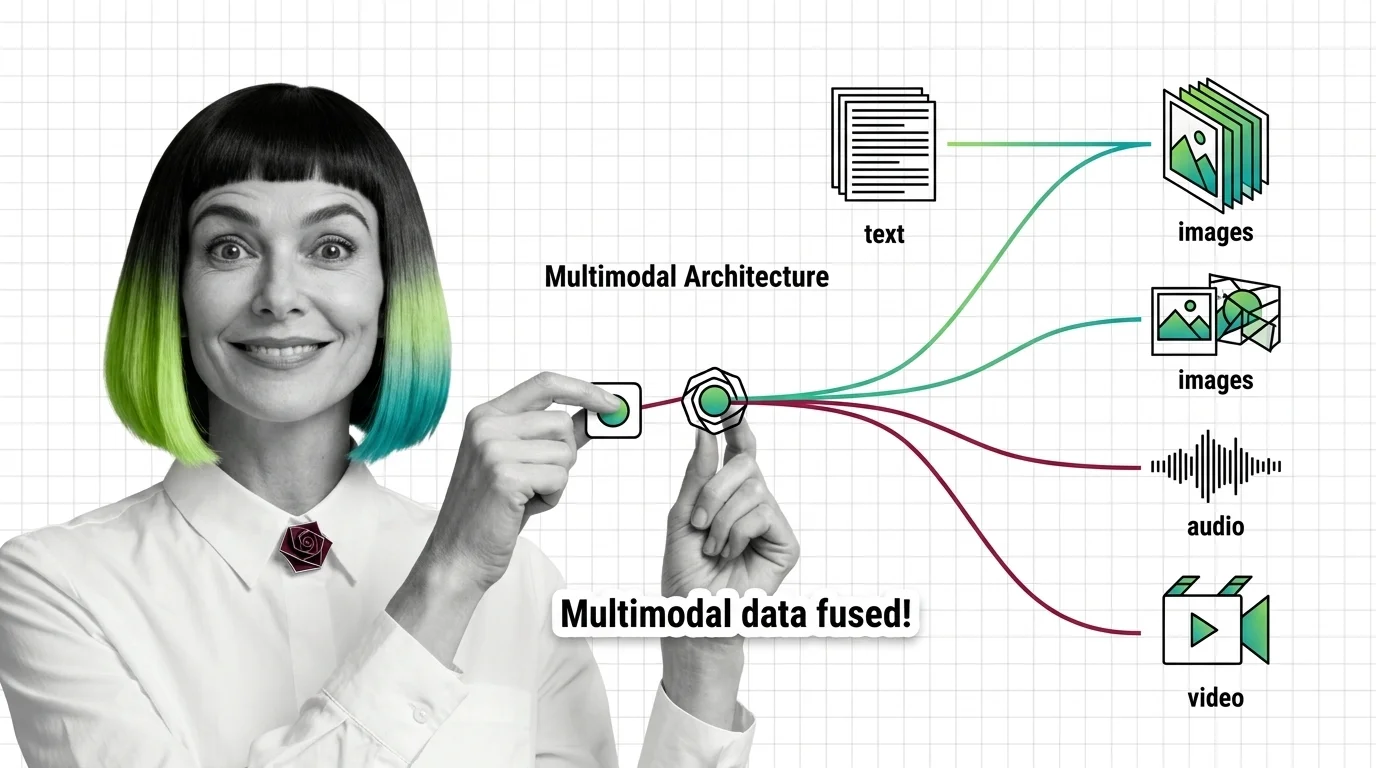
Multimodal Architecture: How Models Fuse Text, Images, Audio & Video
Multimodal models like GPT-5 and Gemini 3.1 Pro don't see images — they translate them into token space. Here's the …
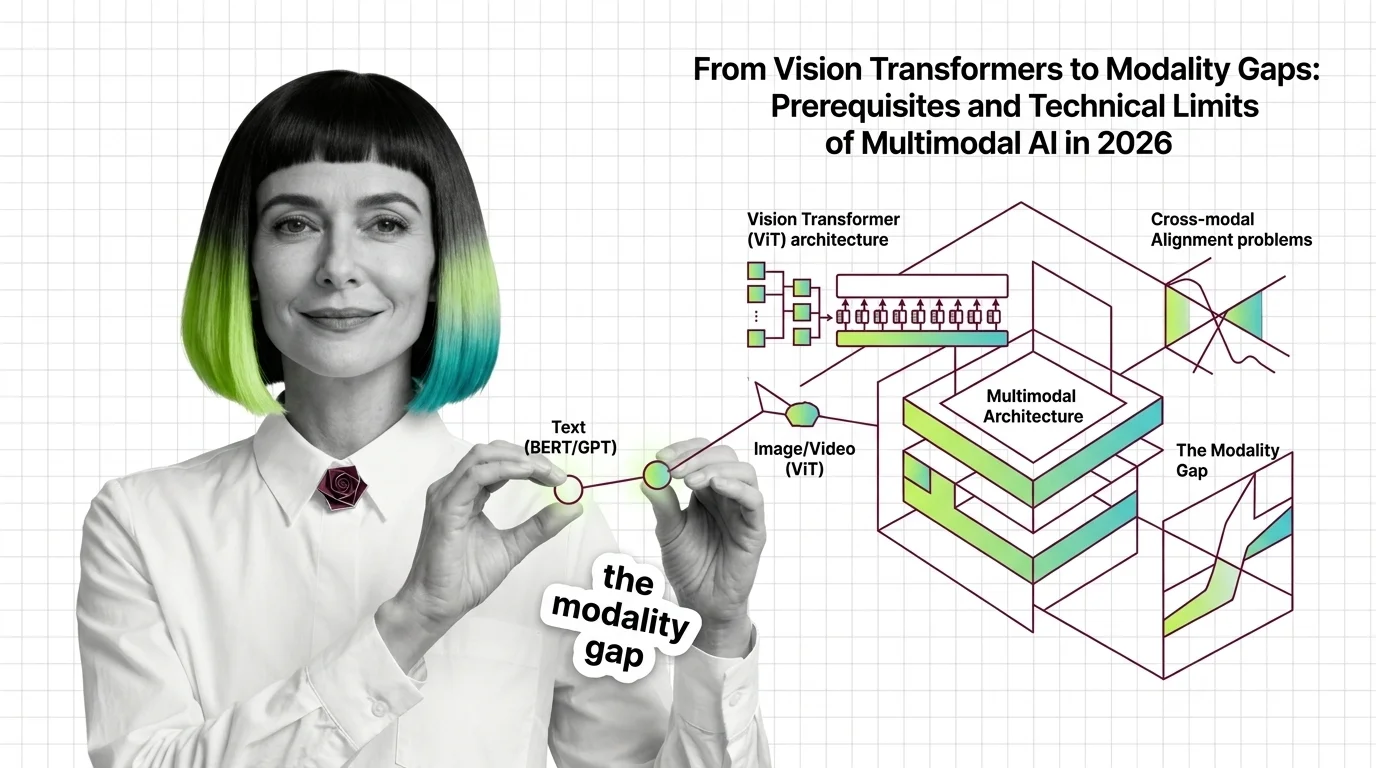
From Vision Transformers to Modality Gaps: Prerequisites and Technical Limits of Multimodal AI in 2026
Before multimodal AI works, vision transformers, modality gaps, and grounding decay define its limits. The mechanics of …

Diffusion Models in 2026: Slow Sampling and Hard Engineering Limits
Why diffusion models still need many sampling steps, why FLUX and SD 3.5 stumble on text and hands, and where the 2026 …
Beyond Transformers for Developers: What Maps and What Breaks
A bridge for developers hitting MoE, state space, and multimodal anomalies in 2026. Which software instincts still work, …
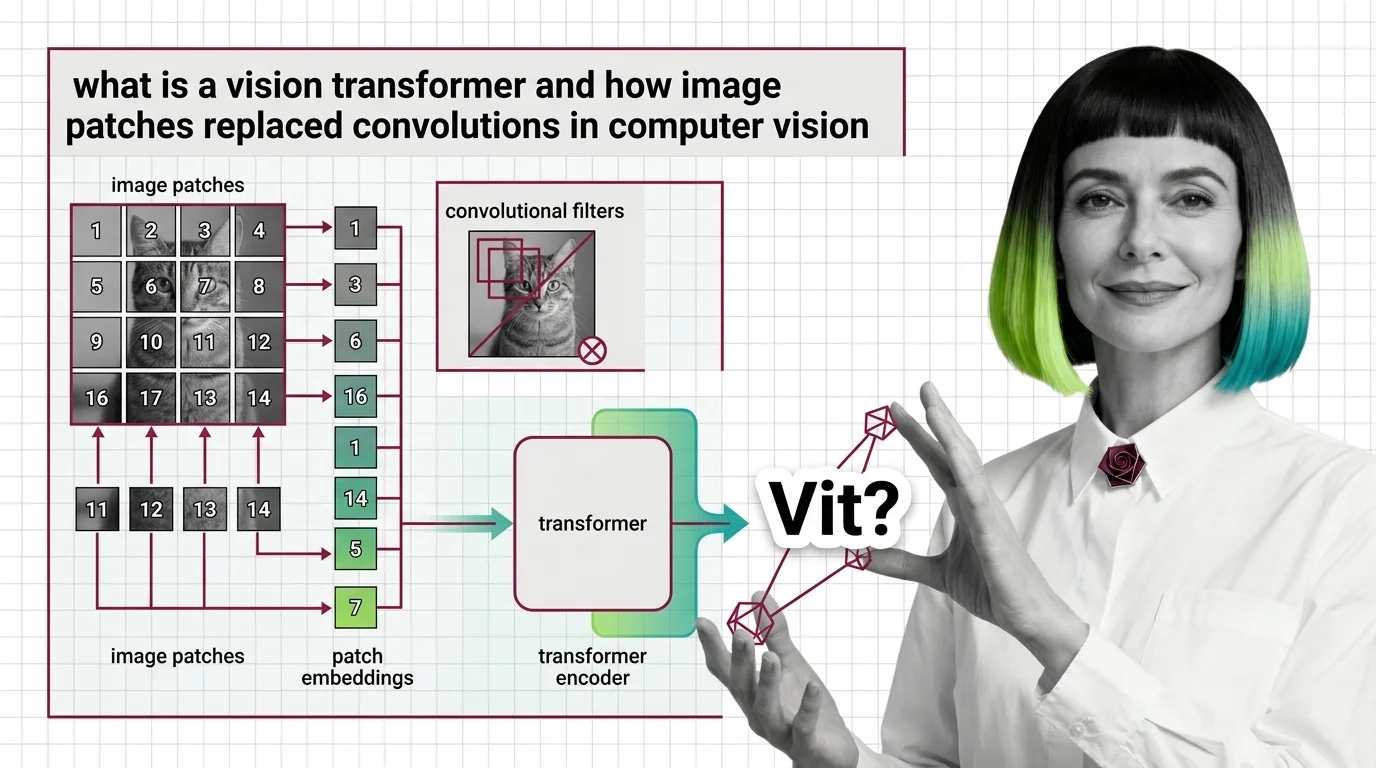
What Is a Vision Transformer and How Image Patches Replaced Convolutions in Computer Vision
Vision Transformers treat images as token sequences, not pixel grids. Learn how 16x16 patches, self-attention, and …
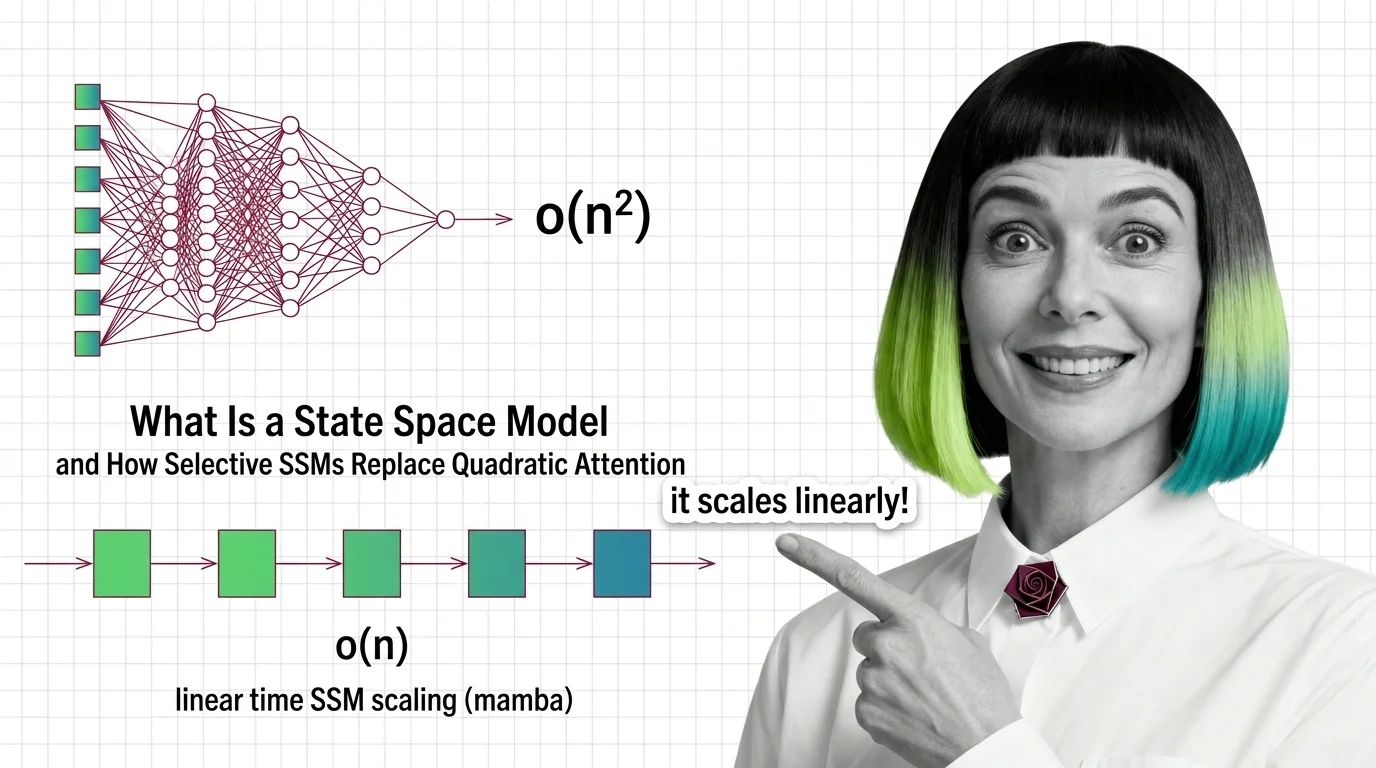
What Is a State Space Model and How Selective SSMs Replace Quadratic Attention
State space models trade quadratic attention for linear recurrence. See how Mamba's selection works and why long-context …
In-Context Learning Gaps, Hybrid Complexity, and the Hard Technical Limits of State Space Models
State space models trade recall for speed. Learn why pure Mamba breaks on in-context tasks and how hybrid SSM-attention …
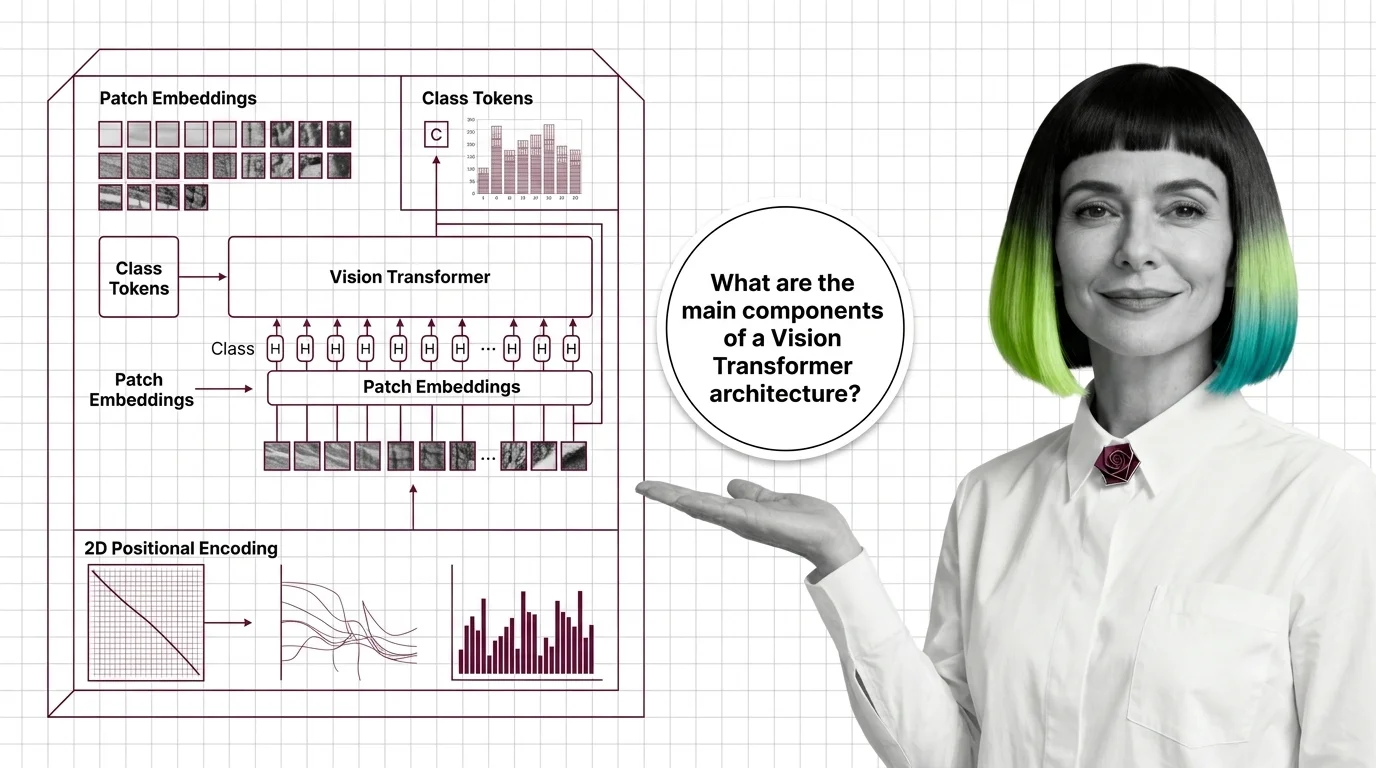
Patch Embeddings, Class Tokens, and 2D Positional Encoding: Inside the Vision Transformer
How Vision Transformers turn images into token sequences — inside patch embeddings, the CLS token, and the shift from 1D …
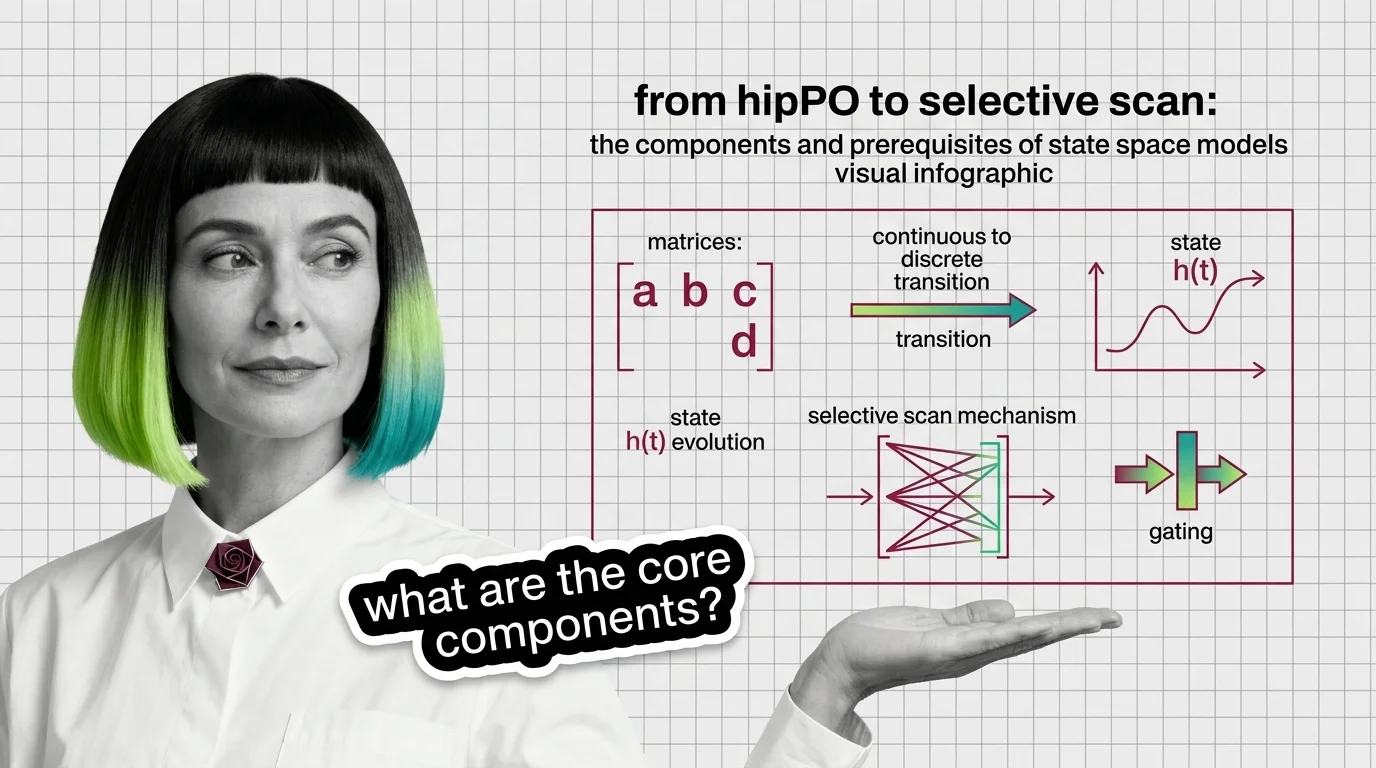
From HiPPO to Selective Scan: The Components and Prerequisites of State Space Models
State space models rebuilt recurrence on new math. Trace the components — HiPPO, S4, selective scan, gating — and the …
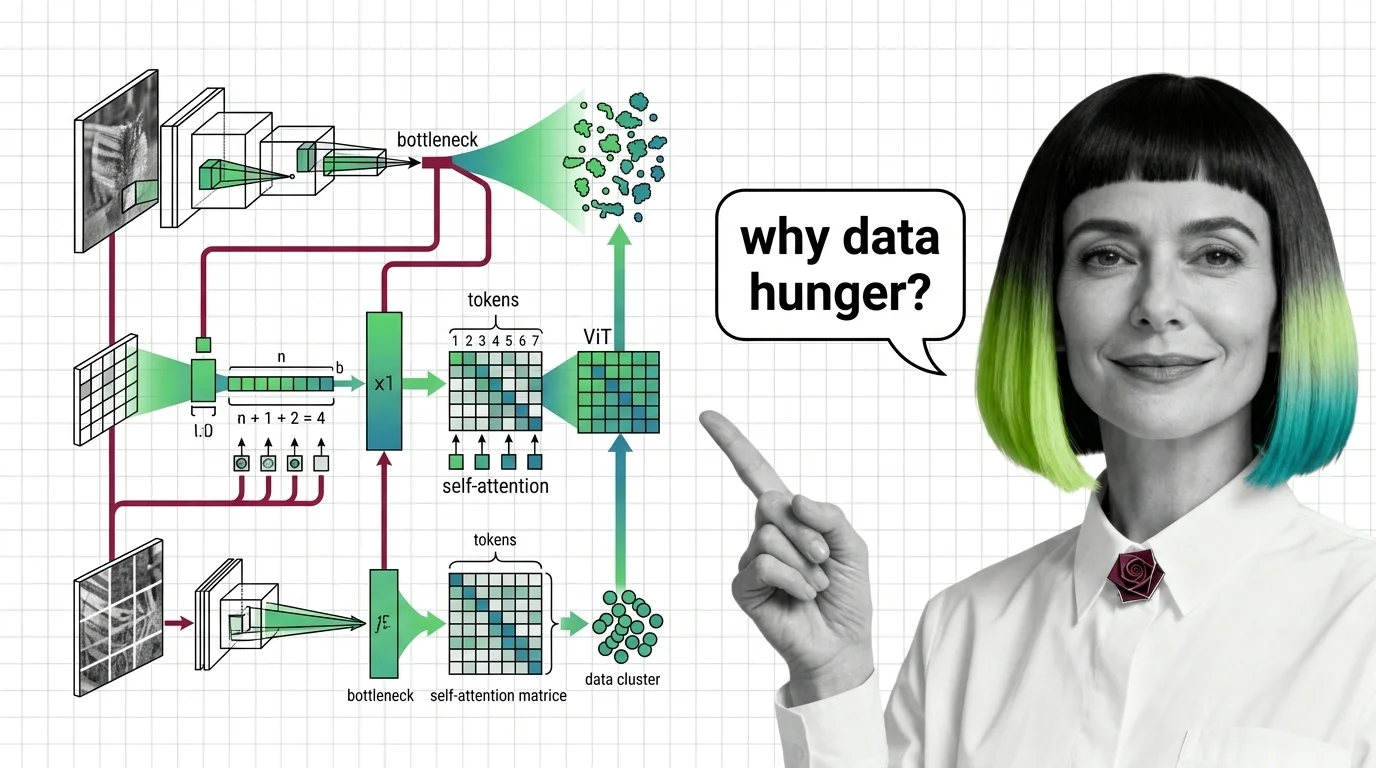
From CNN Intuition to Data Hunger: Prerequisites and Hard Limits of Vision Transformers
Vision Transformers drop CNN priors for learned attention — a trade that changes everything. Learn the prerequisites, …
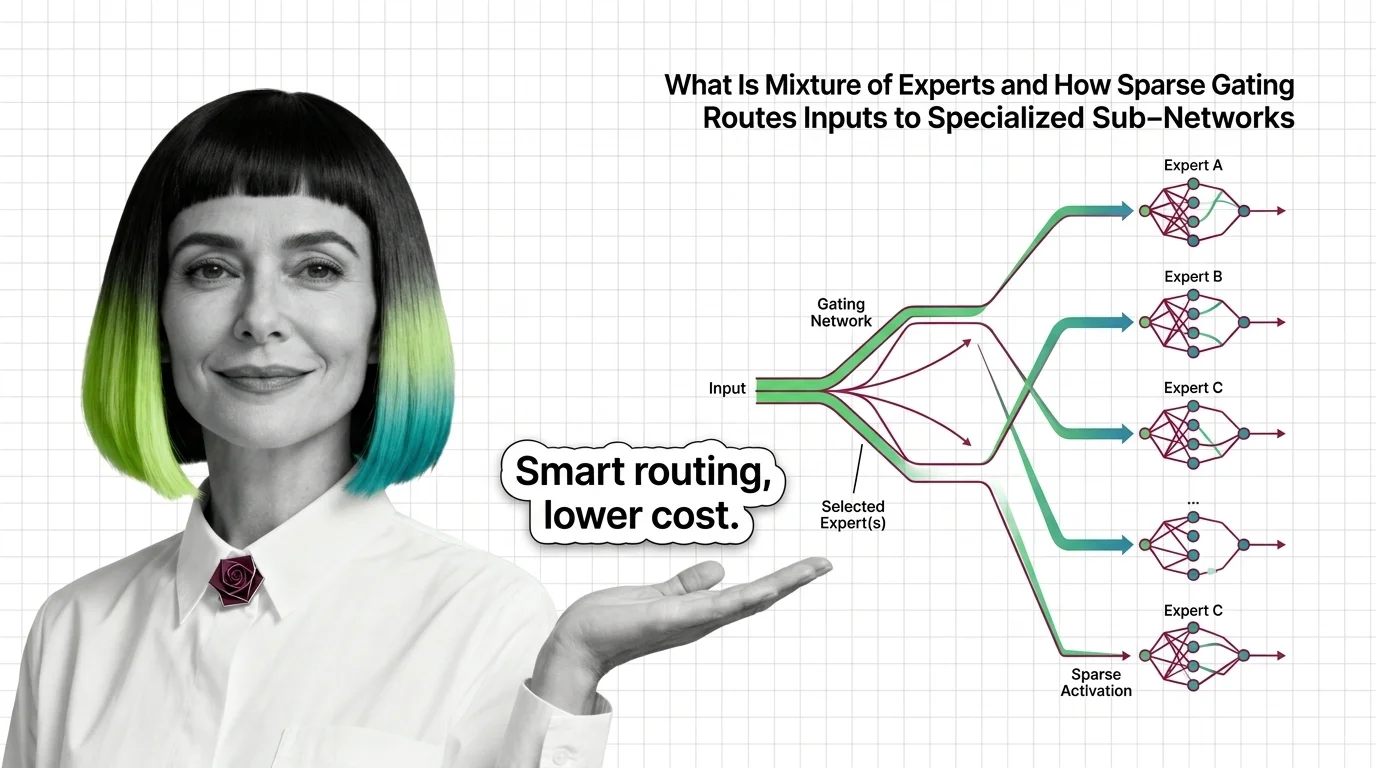
What Is Mixture of Experts and How Sparse Gating Routes Inputs to Specialized Sub-Networks
Mixture of experts activates only selected sub-networks per token. Learn how sparse gating makes trillion-parameter …

Routing Collapse, Load Balancing Failures, and the Hard Engineering Limits of Mixture of Experts
MoE models promise scale at fractional compute cost. Understand routing collapse, memory tradeoffs, and communication …
Neural Network Architectures for Developers: What Maps and What Breaks
Neural network architectures for developers. Which software instincts transfer to CNNs, RNNs, and transformers, and …
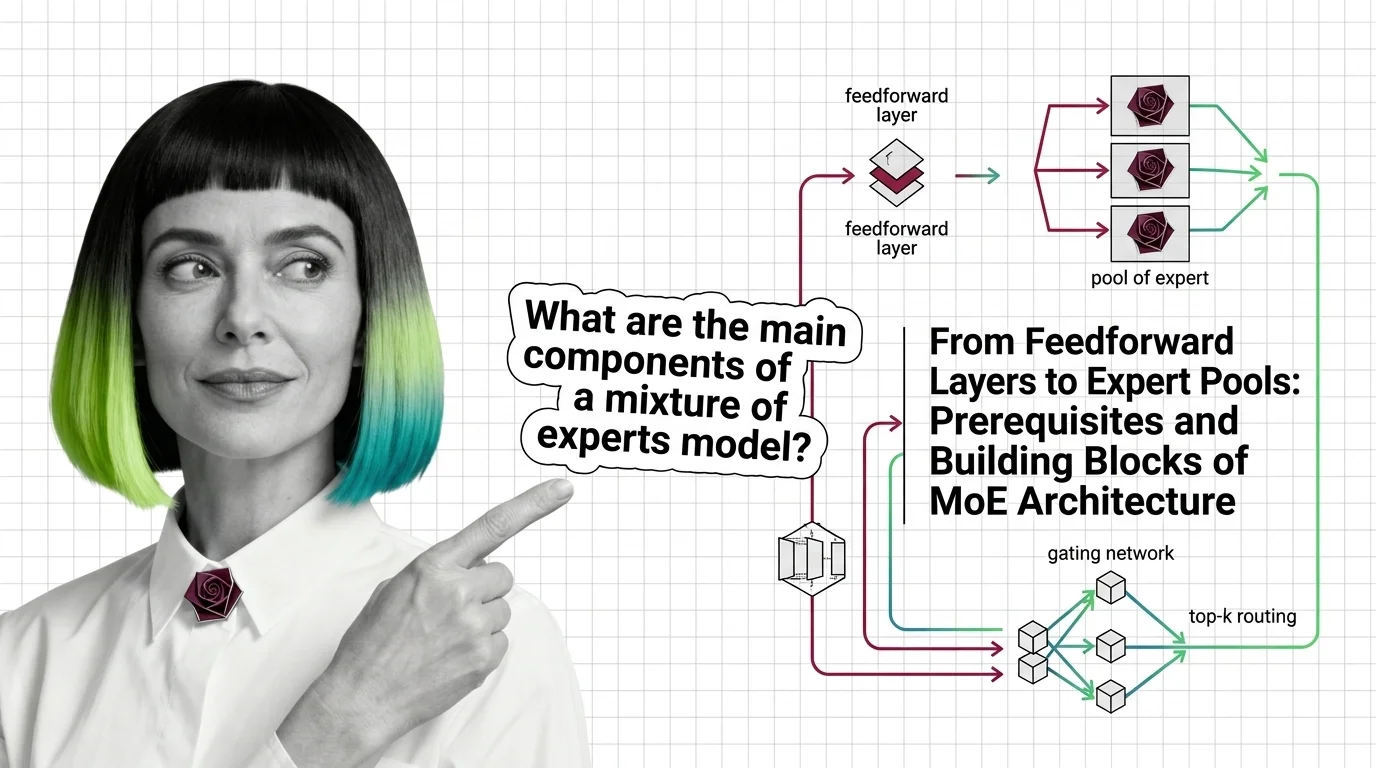
From Feedforward Layers to Expert Pools: Prerequisites and Building Blocks of MoE Architecture
Mixture of experts replaces one feedforward layer with many expert networks and a router. Learn how MoE gating and …
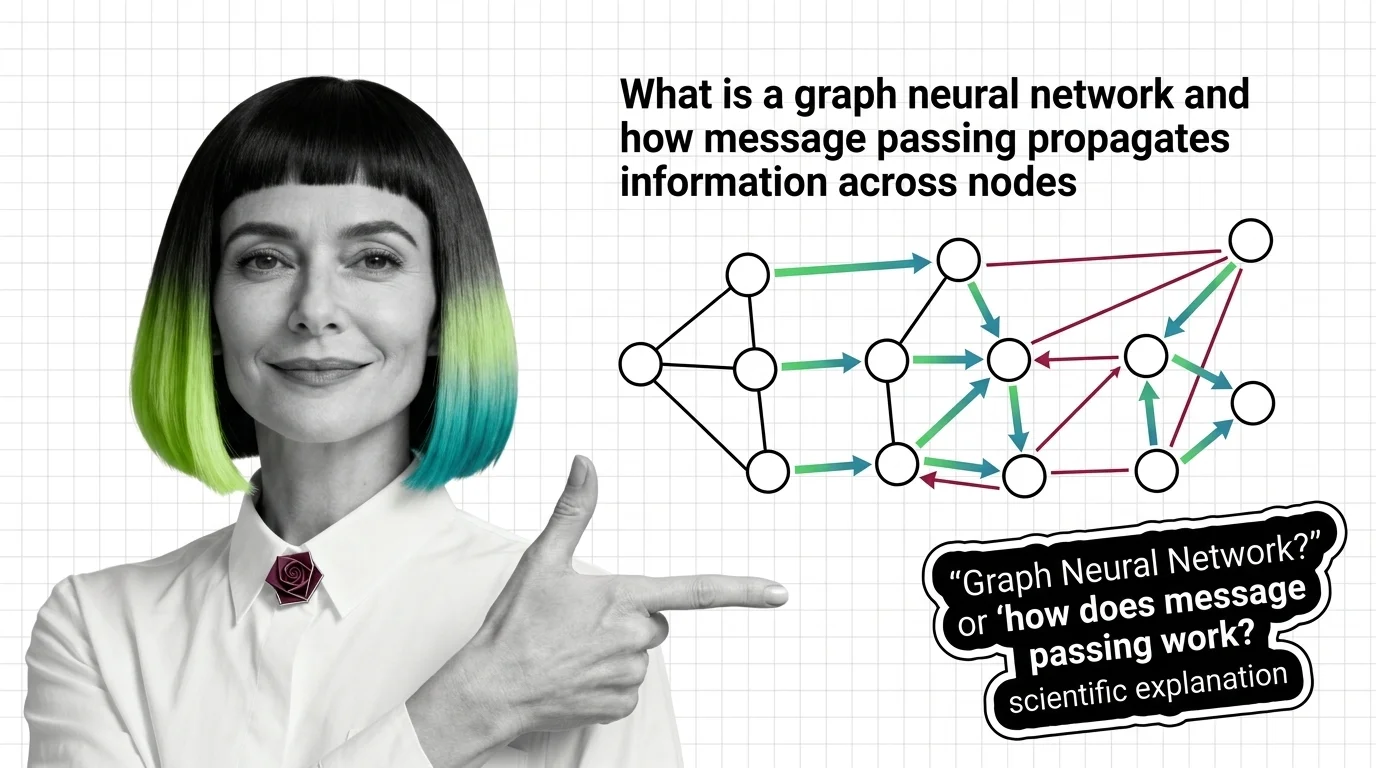
What Is a Graph Neural Network and How Message Passing Propagates Information Across Nodes
Graph neural networks learn from connections, not grids. Understand message passing, how graph convolution differs from …
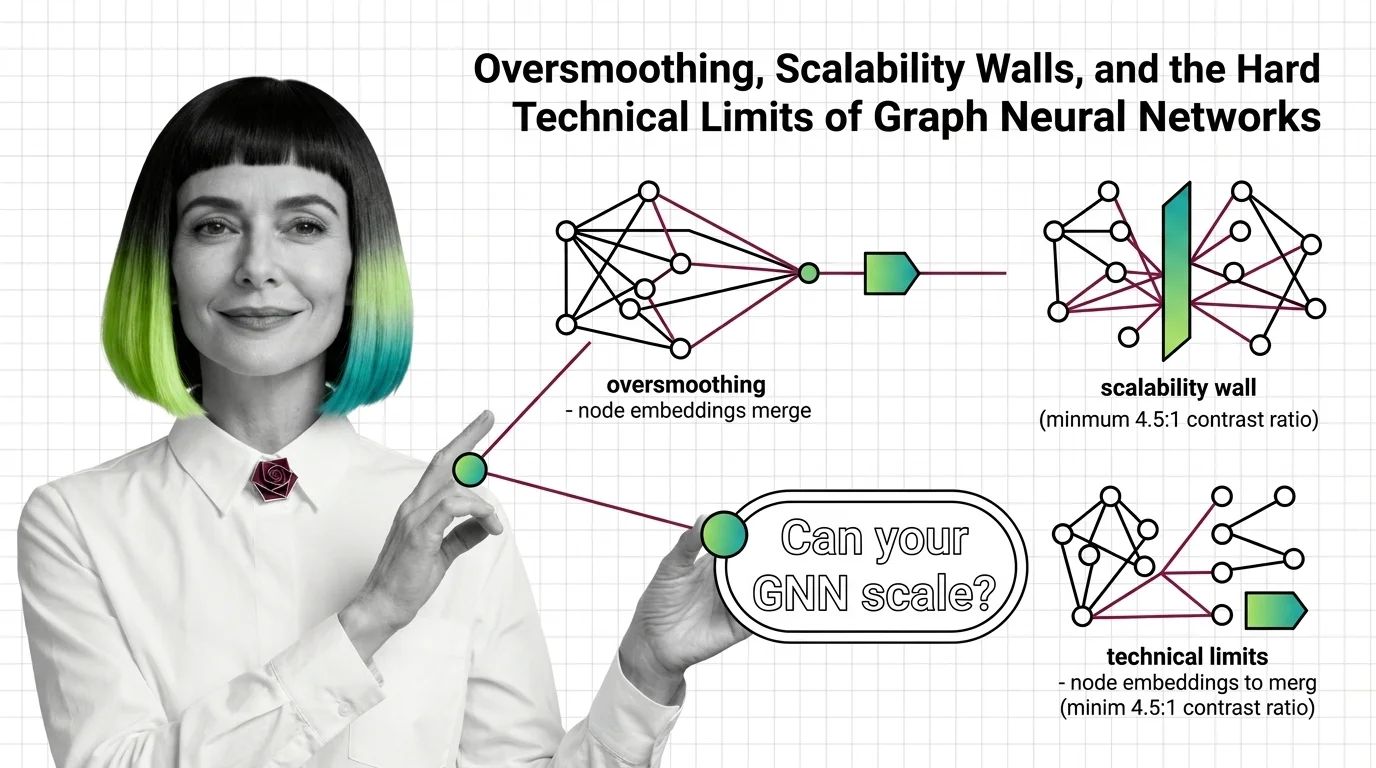
Oversmoothing, Scalability Walls, and the Hard Technical Limits of Graph Neural Networks
Oversmoothing and neighbor explosion set hard ceilings on graph neural network depth and scale. Learn the mathematical …

Adjacency Matrices, Node Features, and the Prerequisites for Understanding Graph Neural Networks
Graph neural networks consume matrices, not pixels. Learn how adjacency matrices, node features, and message passing …
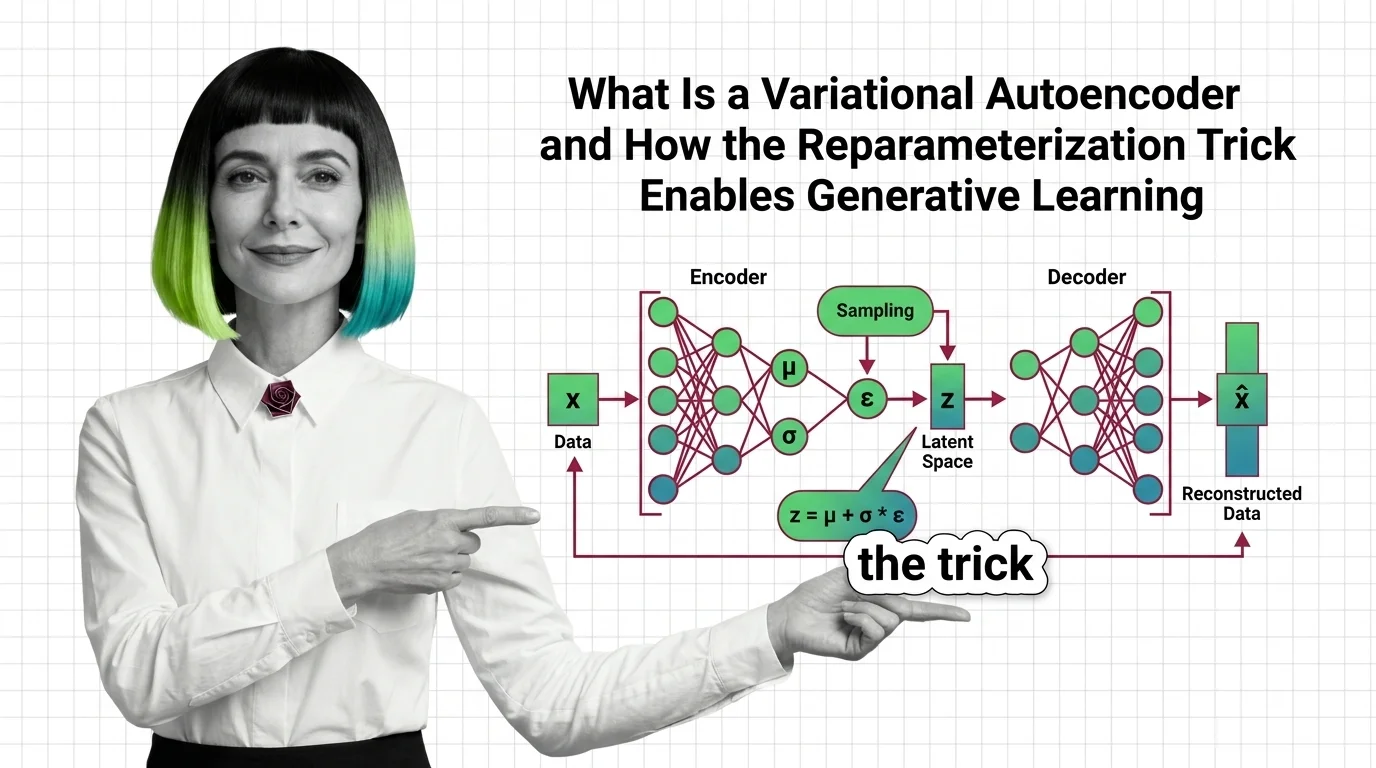
What Is a Variational Autoencoder and How the Reparameterization Trick Enables Generative Learning
VAEs compress data into structured probability spaces for generation. Learn how the reparameterization trick and ELBO …
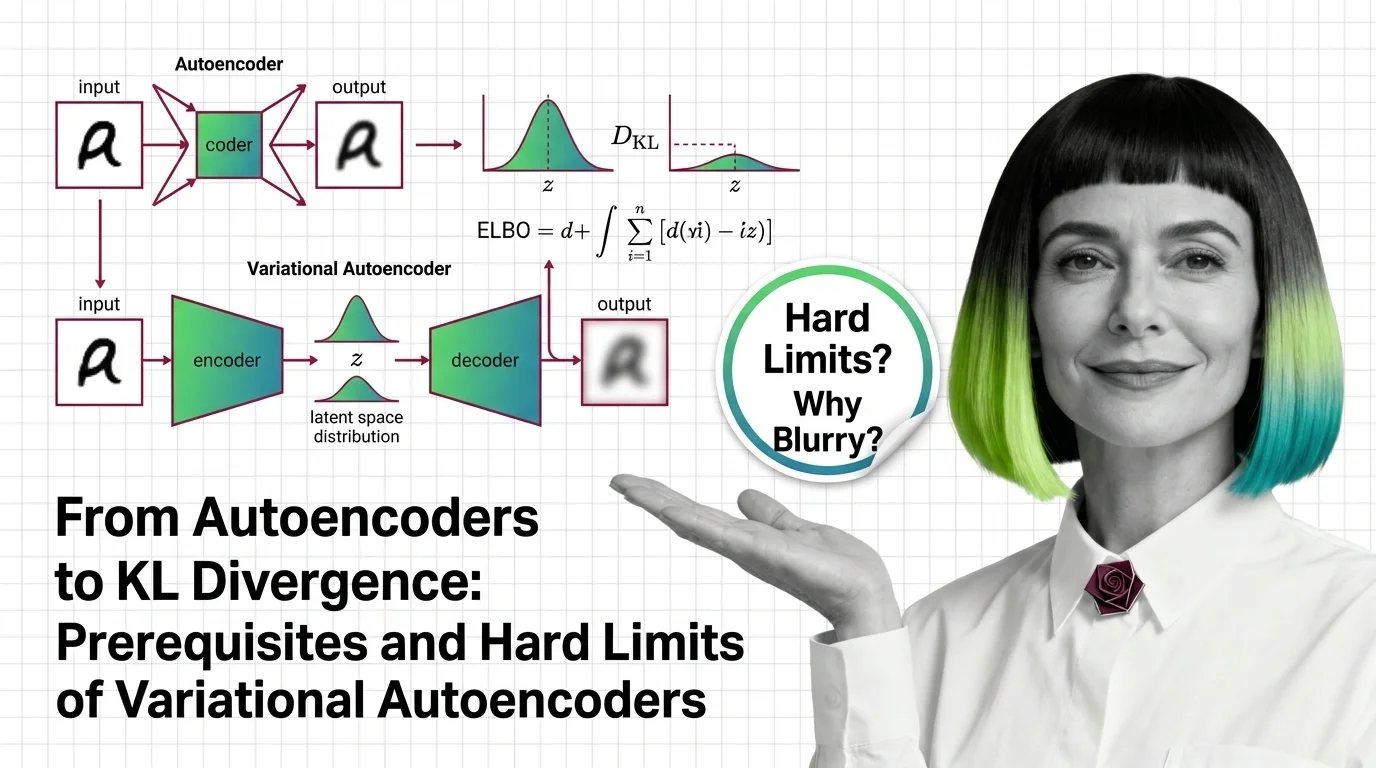
From Autoencoders to KL Divergence: Prerequisites and Hard Limits of Variational Autoencoders
Learn the math behind variational autoencoders — KL divergence, ELBO, the reparameterization trick — and why VAEs blur …
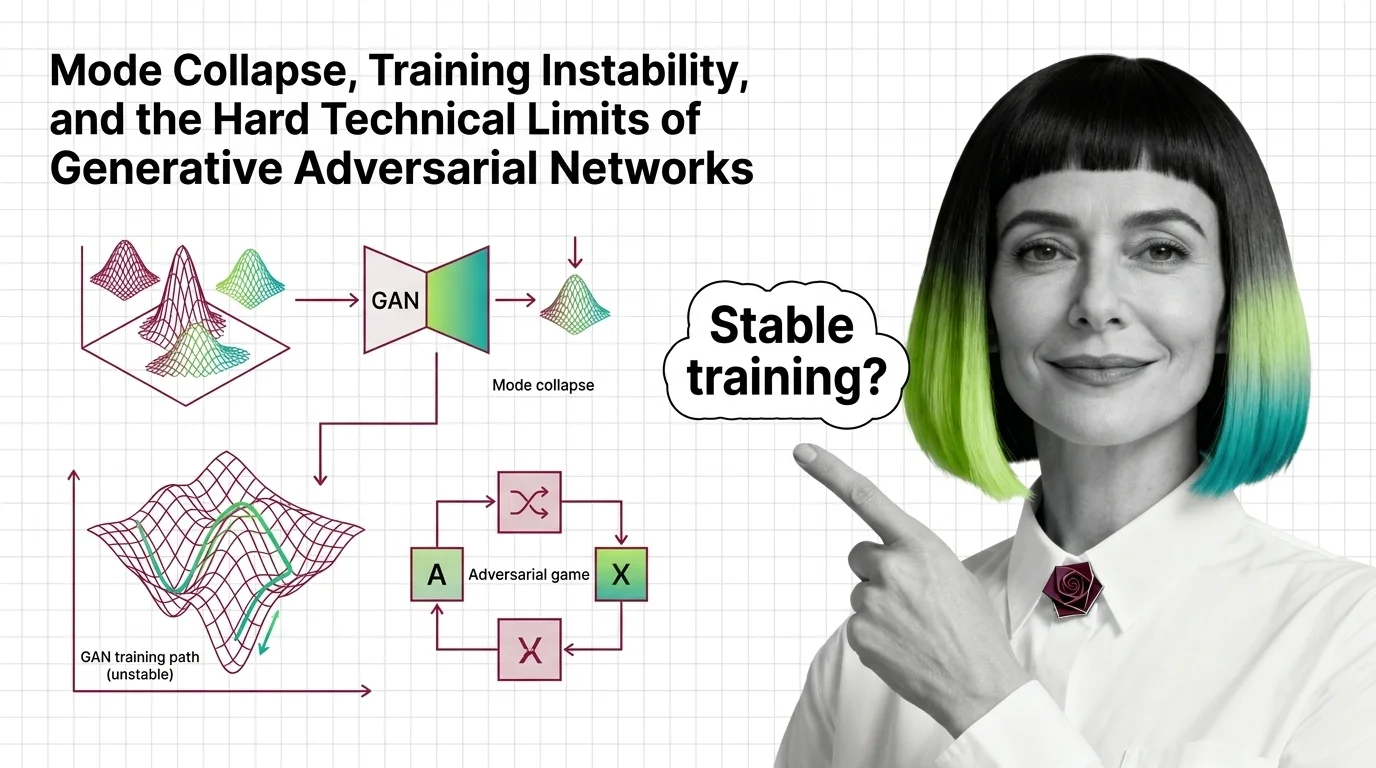
Mode Collapse, Training Instability, and the Hard Technical Limits of Generative Adversarial Networks
Mode collapse and training instability aren't GAN bugs — they're structural limits of adversarial training. Learn the …
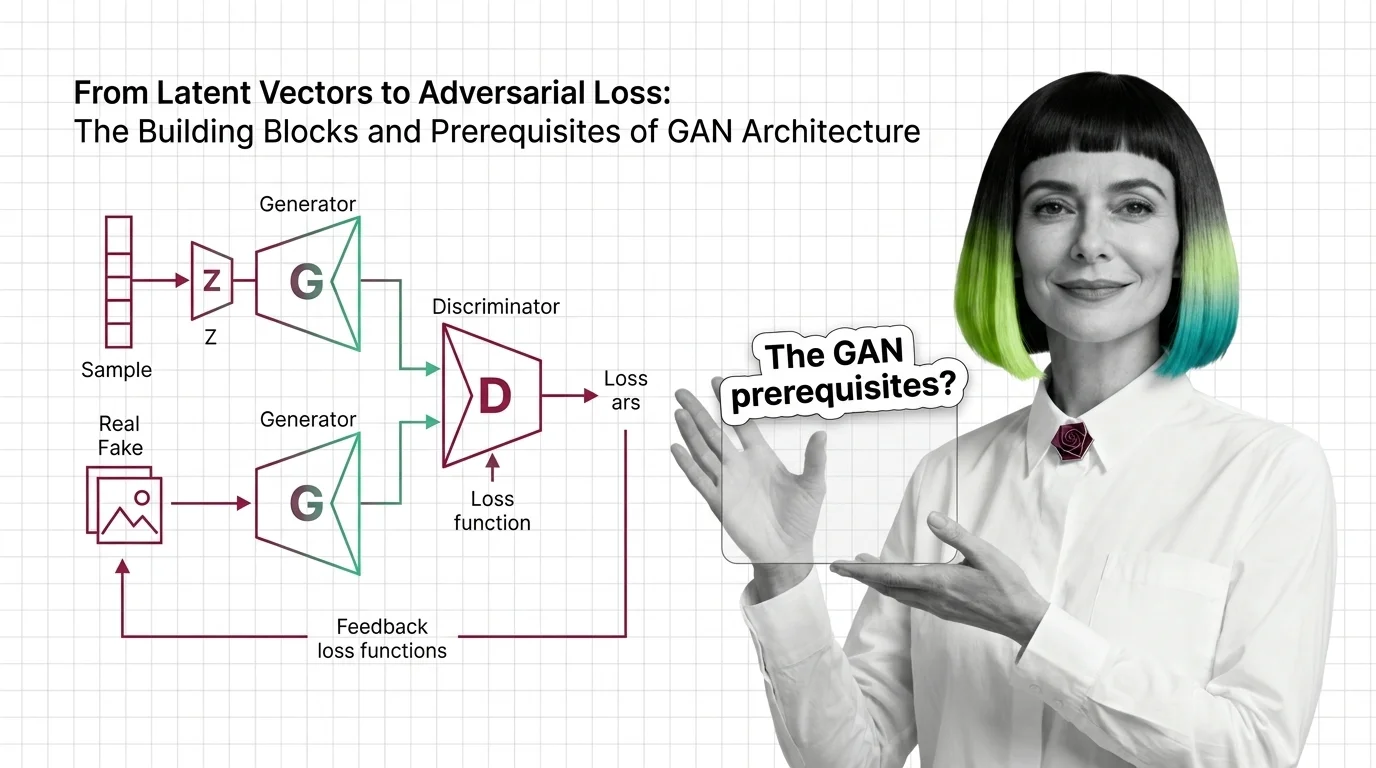
From Latent Vectors to Adversarial Loss: The Building Blocks and Prerequisites of GAN Architecture
Understand GAN architecture from the ground up: generator, discriminator, latent space, and the adversarial loss that …

Backpropagation Through Time, Vanishing Gradients, and Why Transformers Replaced Recurrent Networks
Gradients decay exponentially in recurrent networks during backpropagation through time. The eigenvalue math behind the …

From LeNet to ConvNeXt: How CNN Architectures Evolved and Where Spatial Inductive Bias Falls Short
Trace CNN evolution from LeNet to ConvNeXt. Understand how spatial inductive bias enables efficient vision but limits …

What Is a Neural Network and How It Learns to Generate Language
Neural networks learn language by adjusting millions of weights through backpropagation. Learn how layers, gradients, …
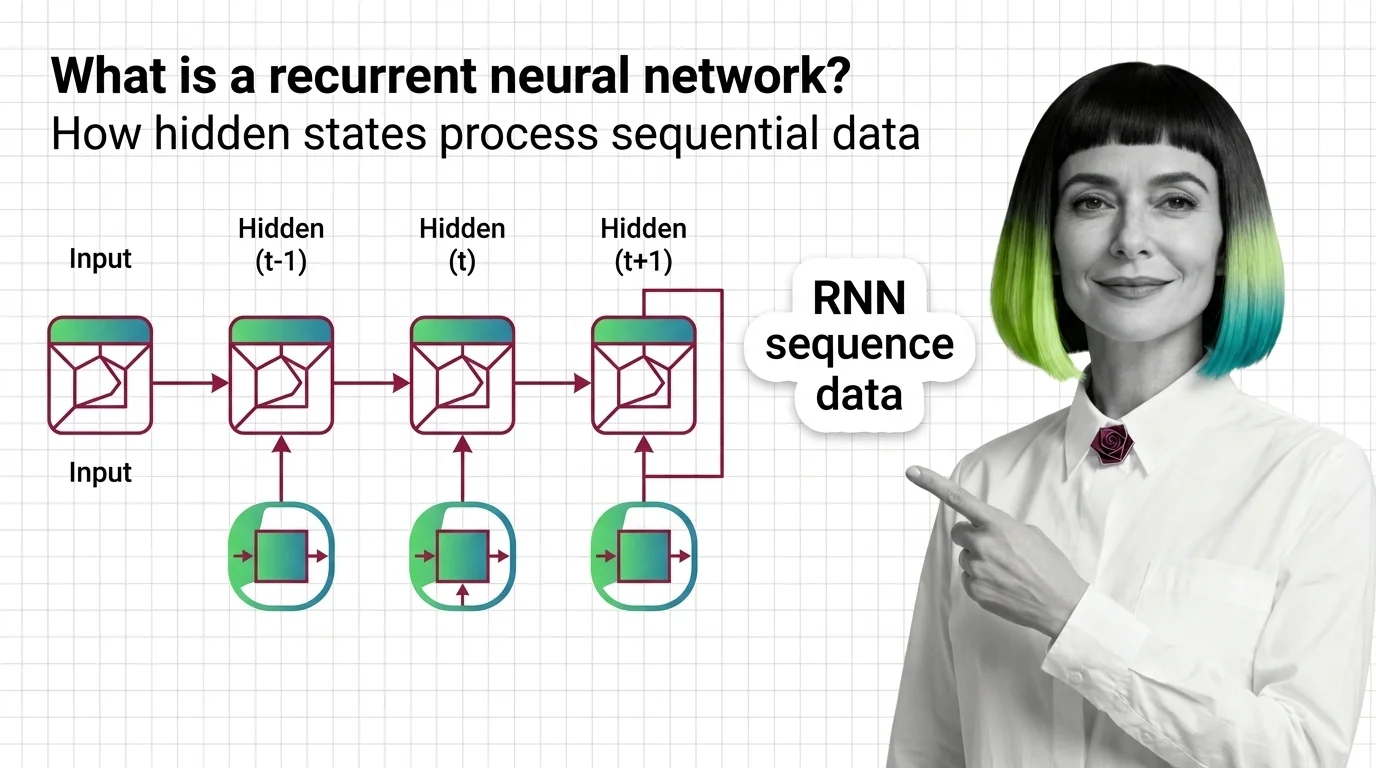
What Is a Recurrent Neural Network and How Hidden States Process Sequential Data
RNNs use hidden states to carry memory across time steps. Learn how recurrent neural networks process sequences, why …

What Is a Convolutional Neural Network and How Learnable Filters Extract Visual Features
Convolutional neural networks detect visual features through learnable filters, not pixel matching. Understand the …
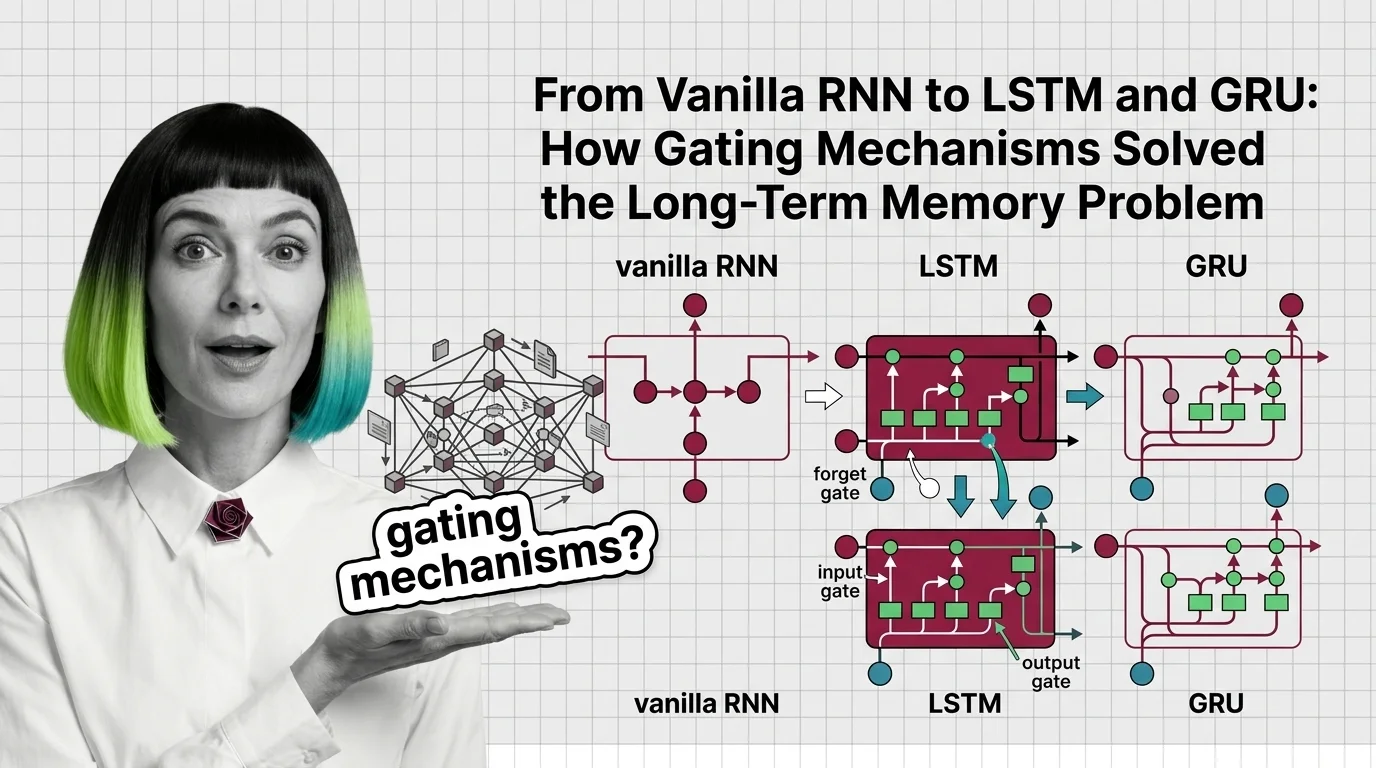
From Vanilla RNN to LSTM and GRU: How Gating Mechanisms Solved the Long-Term Memory Problem
Trace how LSTM forget, input, and output gates fix the vanishing gradient problem that crippled vanilla RNNs, and how …
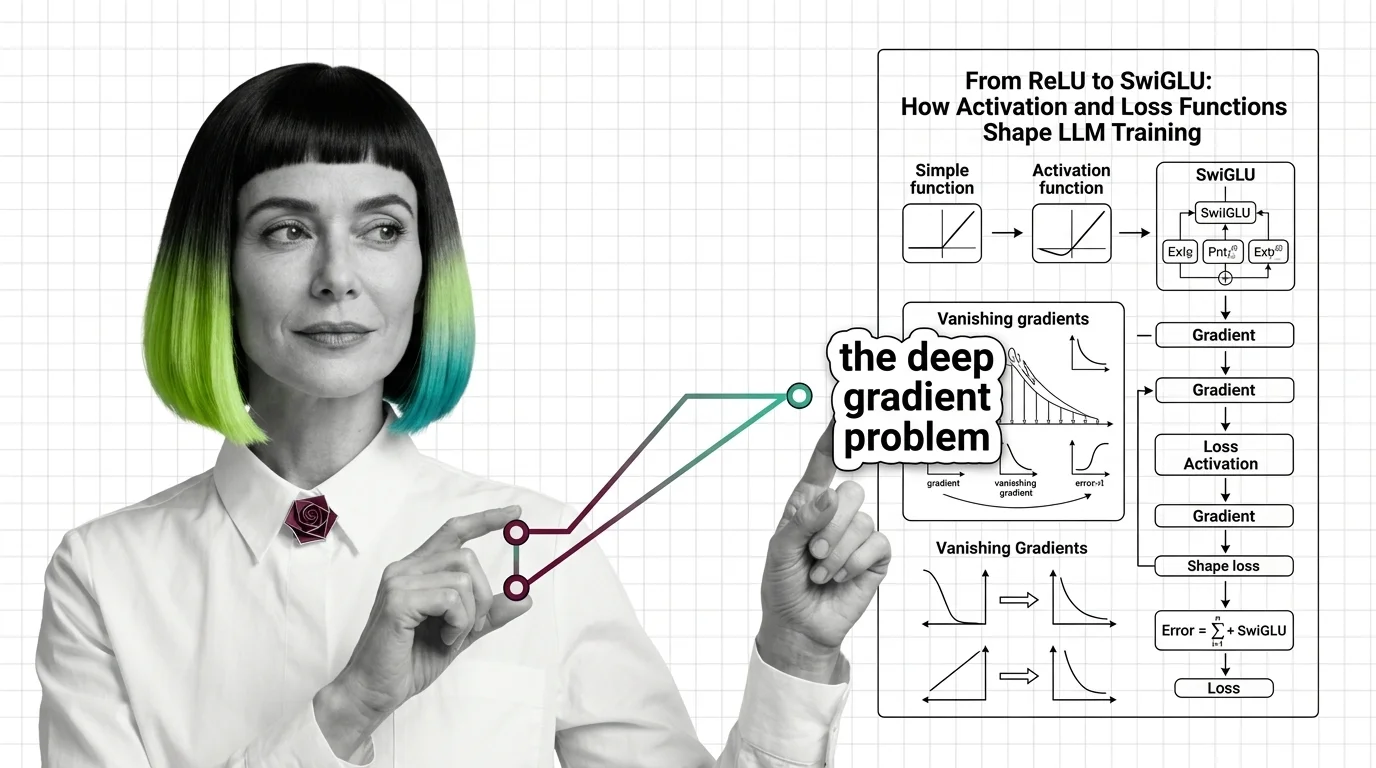
From ReLU to SwiGLU: How Activation and Loss Functions Shape LLM Training
Trace the path from ReLU to SwiGLU and understand how activation functions, cross-entropy loss, and gradient dynamics …
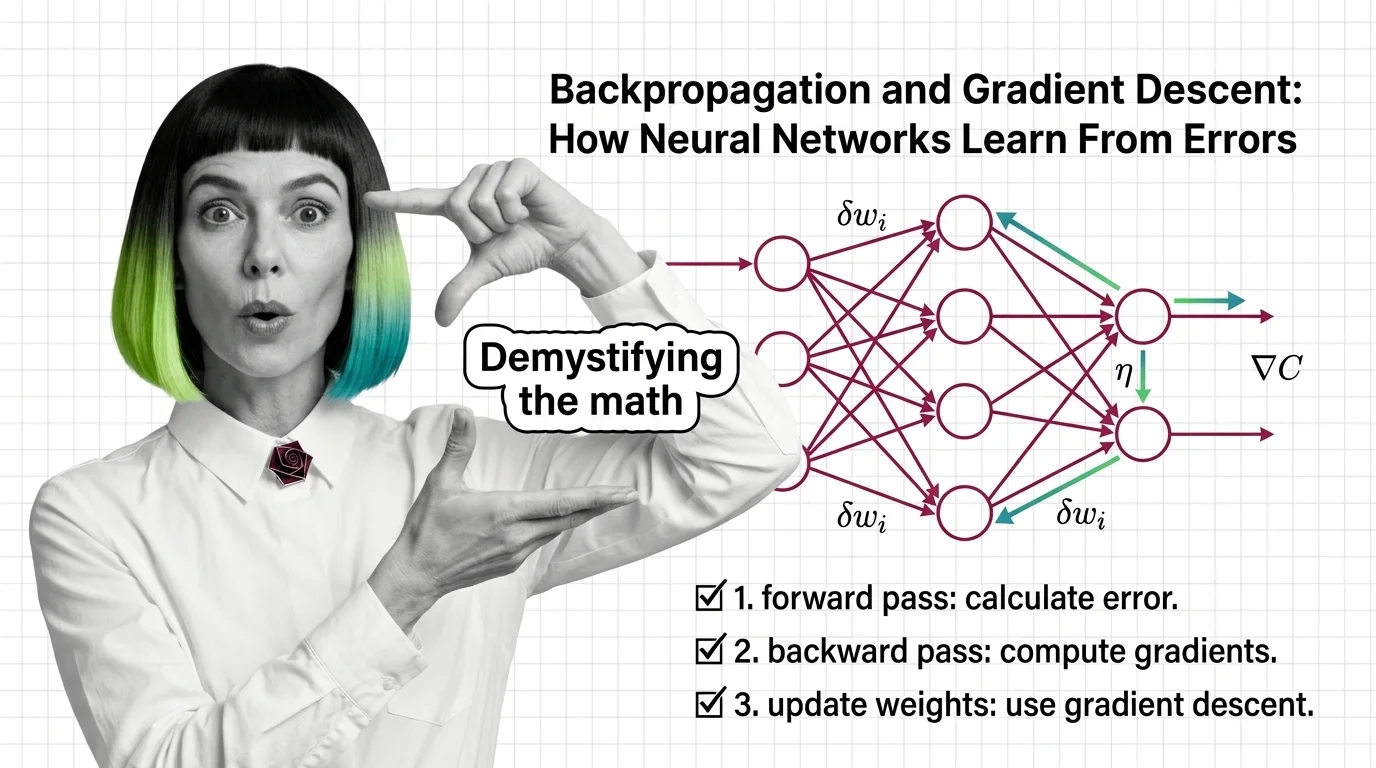
Backpropagation and Gradient Descent: How Neural Networks Learn From Errors
Learn how backpropagation and gradient descent train neural networks by propagating error signals backward through …
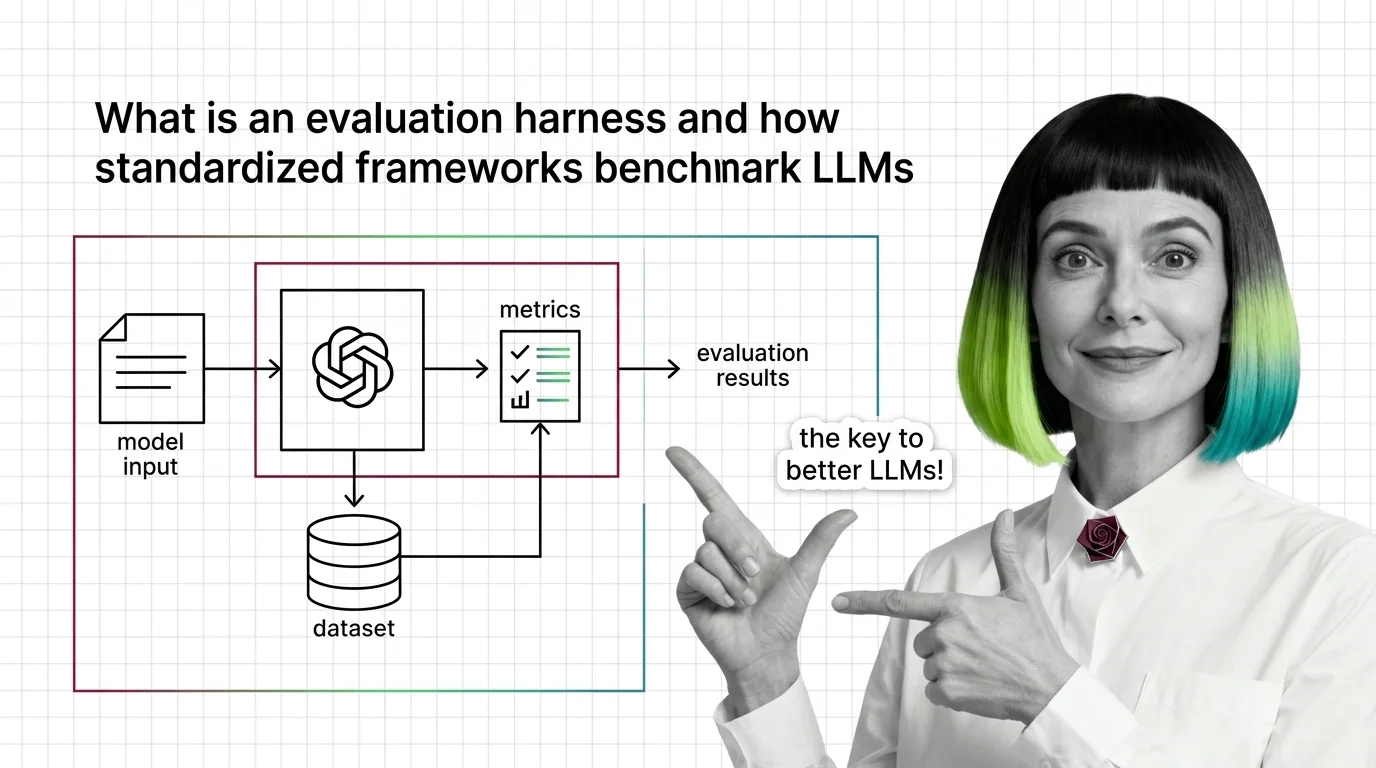
What Is an Evaluation Harness and How Standardized Frameworks Benchmark LLMs
Evaluation harnesses standardize LLM benchmarking by fixing prompts, scoring, and conditions. Learn how the pipeline …

Benchmark Contamination, Score Divergence, and the Technical Limits of LLM Evaluation Harnesses
Same model, same benchmark, different scores. Understand why evaluation harnesses diverge and how benchmark …
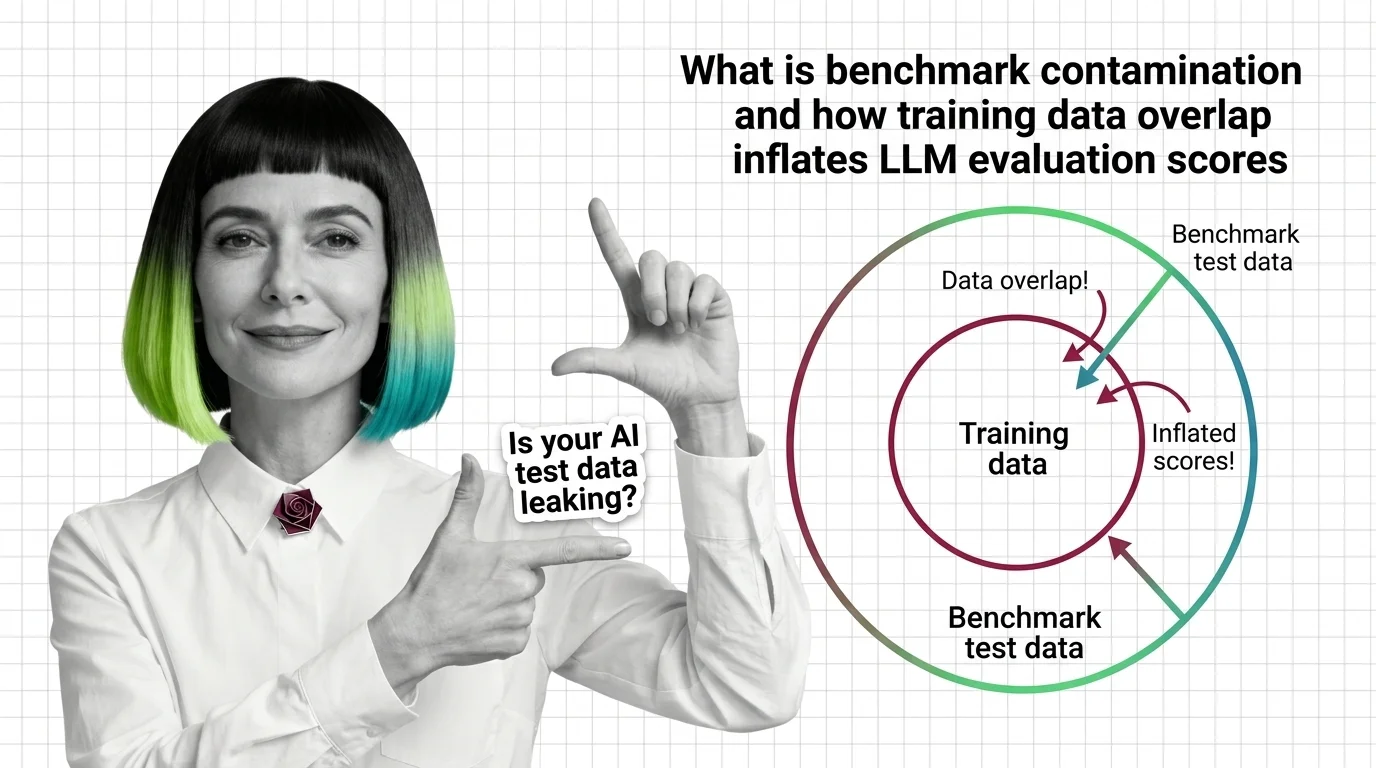
What Is Benchmark Contamination and How Training Data Overlap Inflates LLM Evaluation Scores
Benchmark contamination inflates LLM scores when training data overlaps with test sets. Learn how data leaks in and why …

Benchmark Contamination: N-Gram Overlap and Hard Limits
Benchmark contamination and overfitting look identical in scores. Understand what n-gram overlap, deduplication, and …
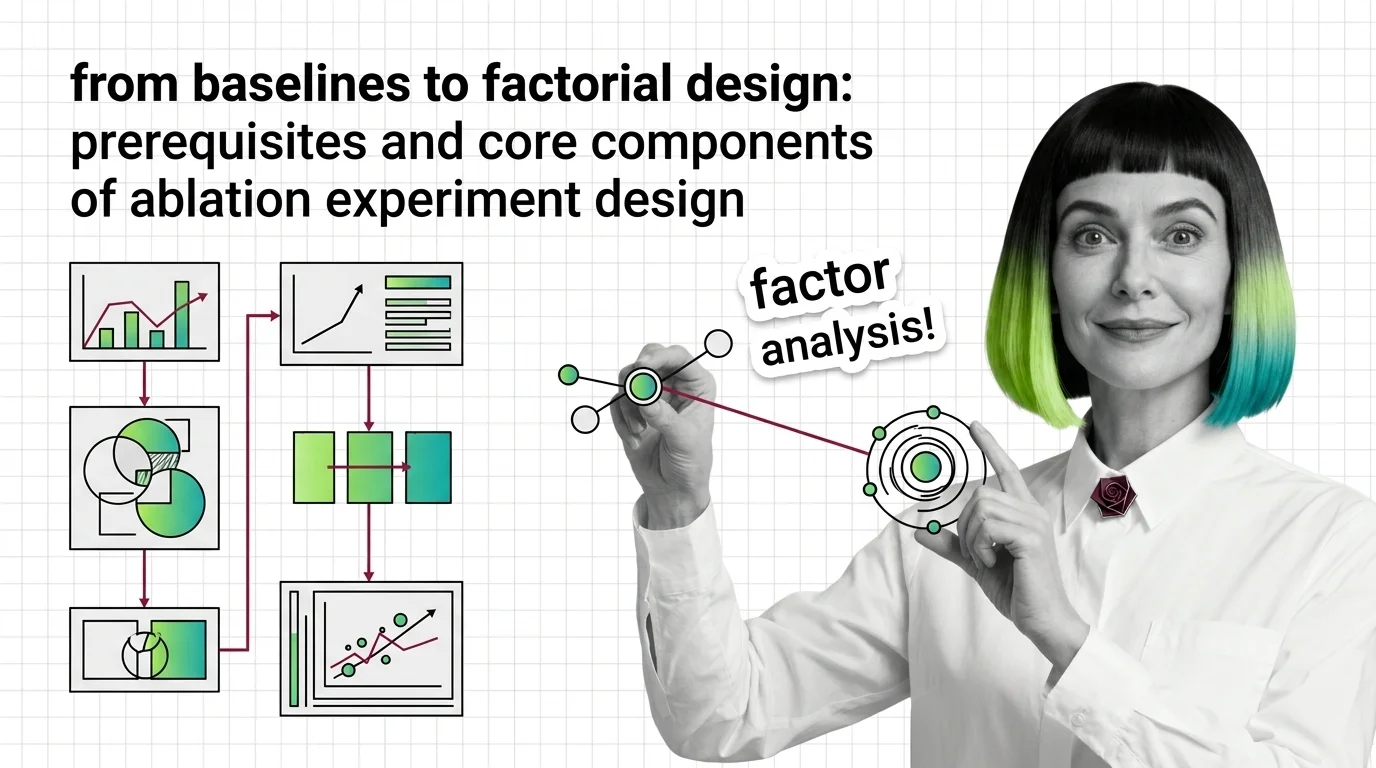
From Baselines to Factorial Design: Prerequisites and Core Components of Ablation Experiment Design
Ablation studies reveal which components matter, but only with the right baselines, controls, and statistical methods. …

Class Imbalance, Normalization Traps, and the Hard Limits of Confusion Matrix Analysis
Confusion matrices hide failures under class imbalance. Learn how normalization direction changes what you see and why …
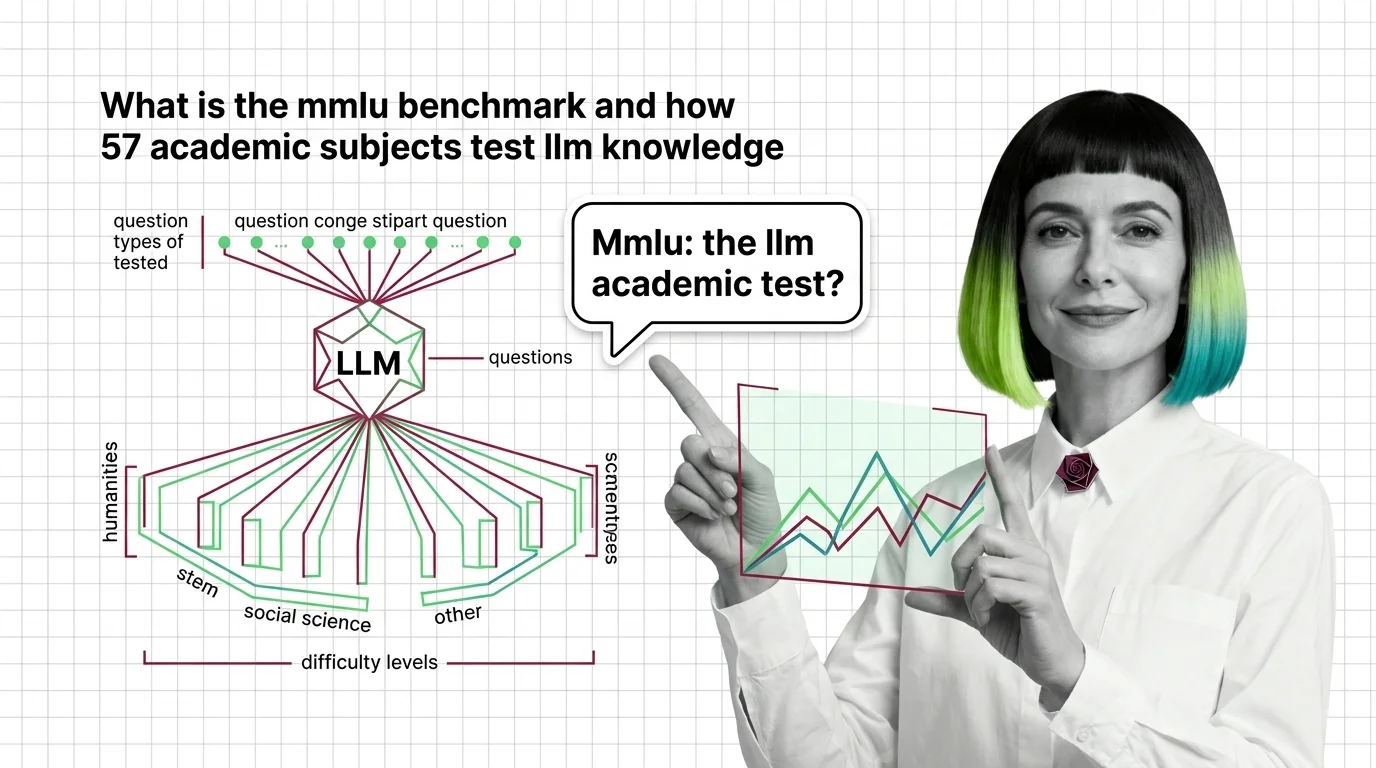
What Is the MMLU Benchmark and How 57 Academic Subjects Test LLM Knowledge
MMLU tests large language models across 57 academic subjects with 15,908 questions. Learn how it works, where it breaks, …
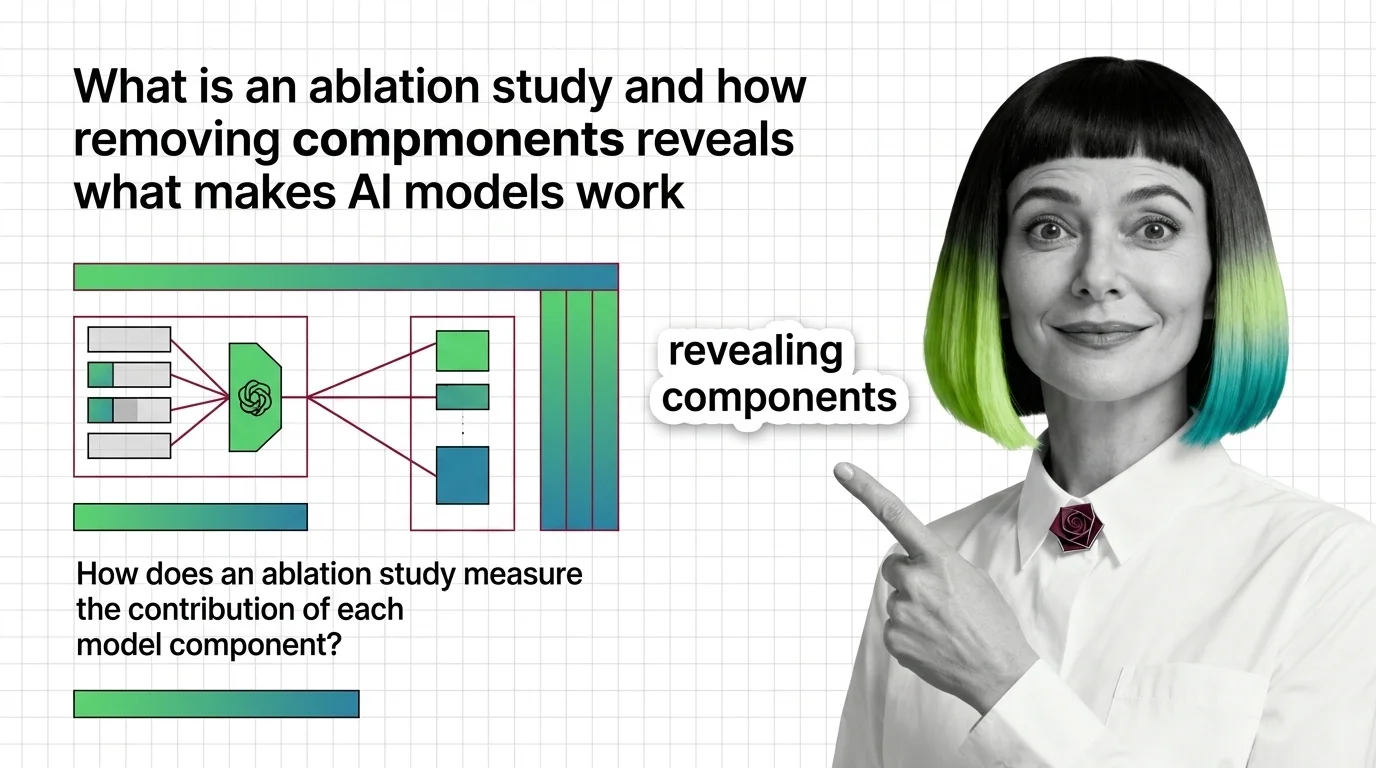
What Is an Ablation Study and How Removing Components Reveals What Makes AI Models Work
Ablation studies reveal what each model component does by removing it. Learn the experimental design and failure modes …

What Is a Confusion Matrix and How It Reveals Where Your Classifier Fails
A confusion matrix reveals exactly where classifiers fail. Understand true positives, false negatives, and why accuracy …

MMLU's 6.5% Label Error Rate and Benchmark Score Saturation
MMLU's 6.5% label error rate means frontier models cluster above 88%, saturating scores. Score saturation explains why …
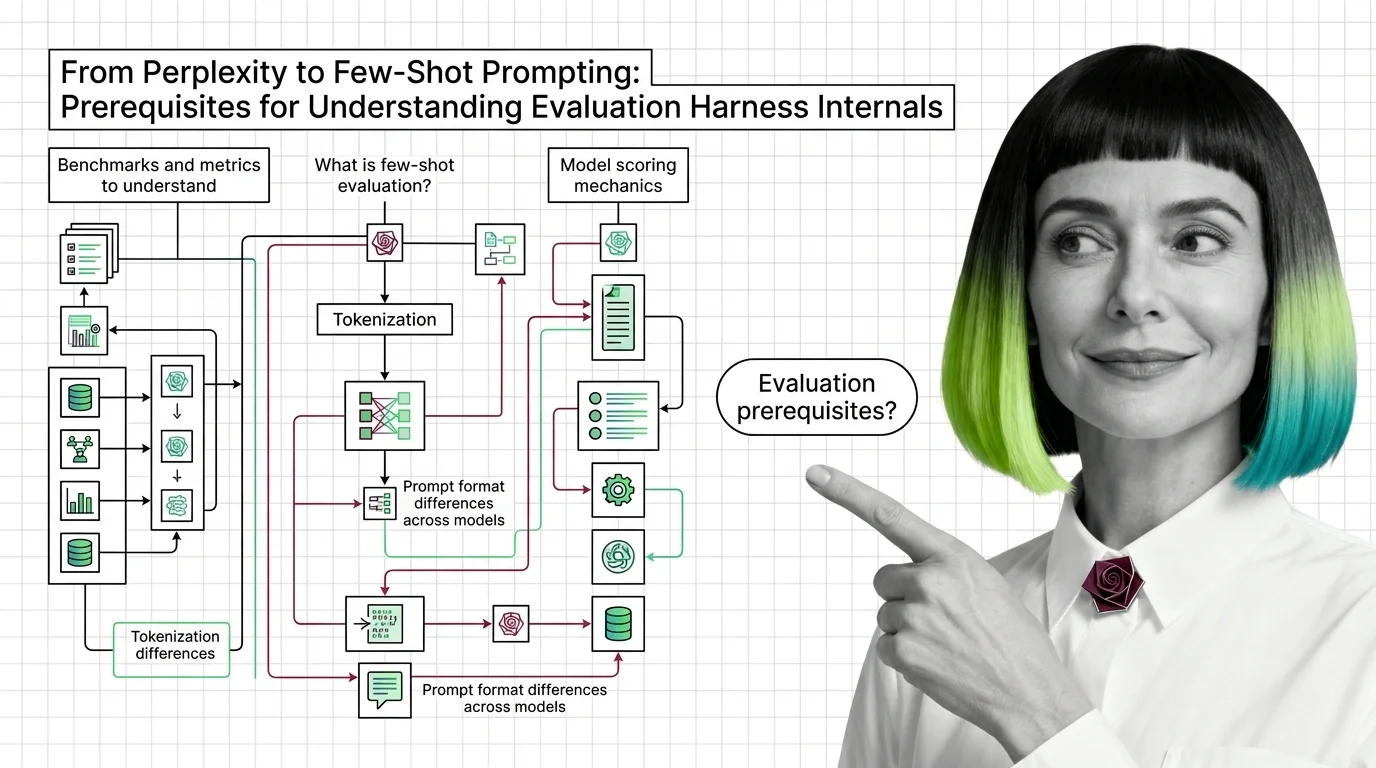
From Perplexity to Few-Shot Prompting: Prerequisites for Understanding Evaluation Harness Internals
Evaluation harness scores depend on perplexity, few-shot prompting, and tokenization most teams skip. Learn the …
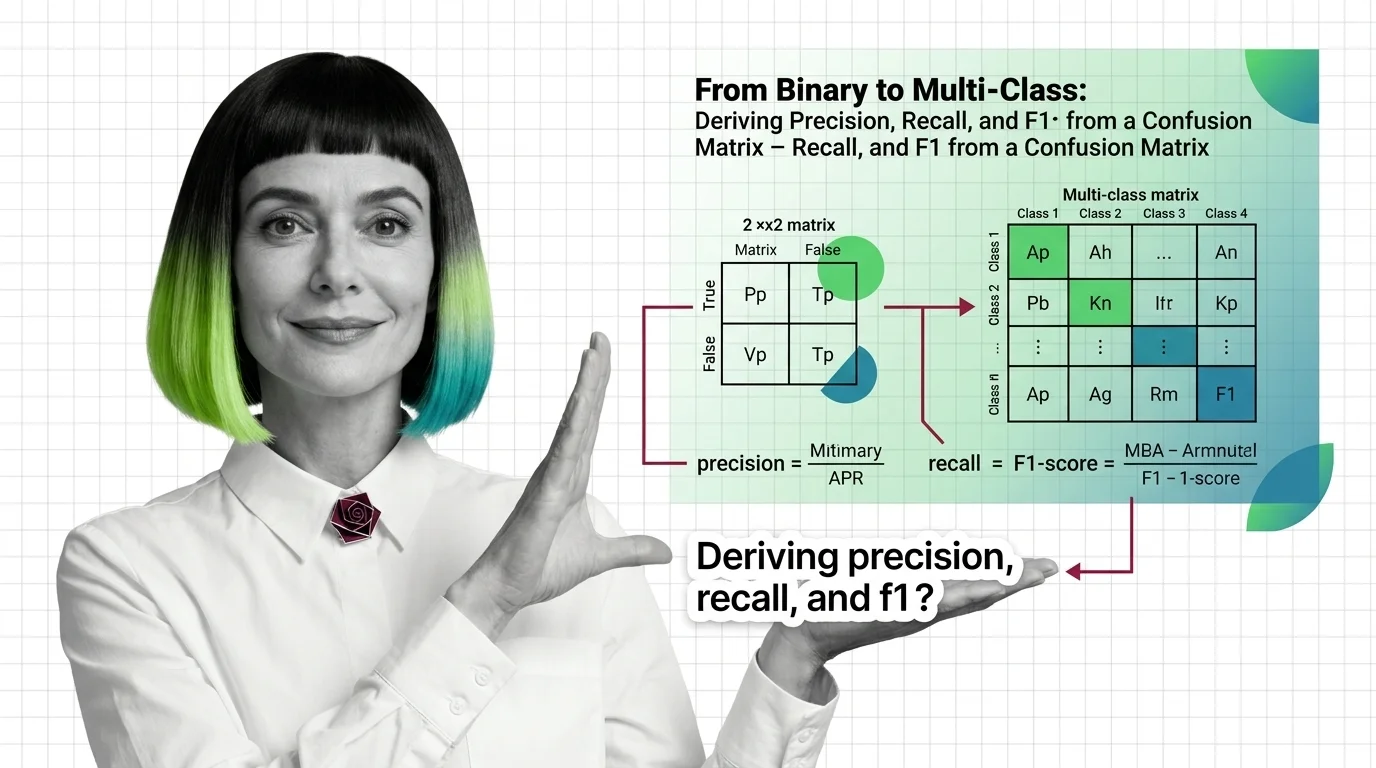
From Binary to Multi-Class: Deriving Precision, Recall, and F1 from a Confusion Matrix
The confusion matrix scales from four binary cells to N² in multi-class problems. What the diagonal and margins record …
Combinatorial Explosion, Interaction Effects, and the Hard Limits of Ablation Studies at Scale
Ablation studies hit a wall at scale: combinatorial explosion and non-additive interactions make exhaustive testing of …

Why F1 Score Fails on Imbalanced Datasets: MCC, PR-AUC, and the Limits of Harmonic Averaging
F1 score hides classifier failures on imbalanced datasets by ignoring true negatives. Learn why MCC and PR-AUC reveal …
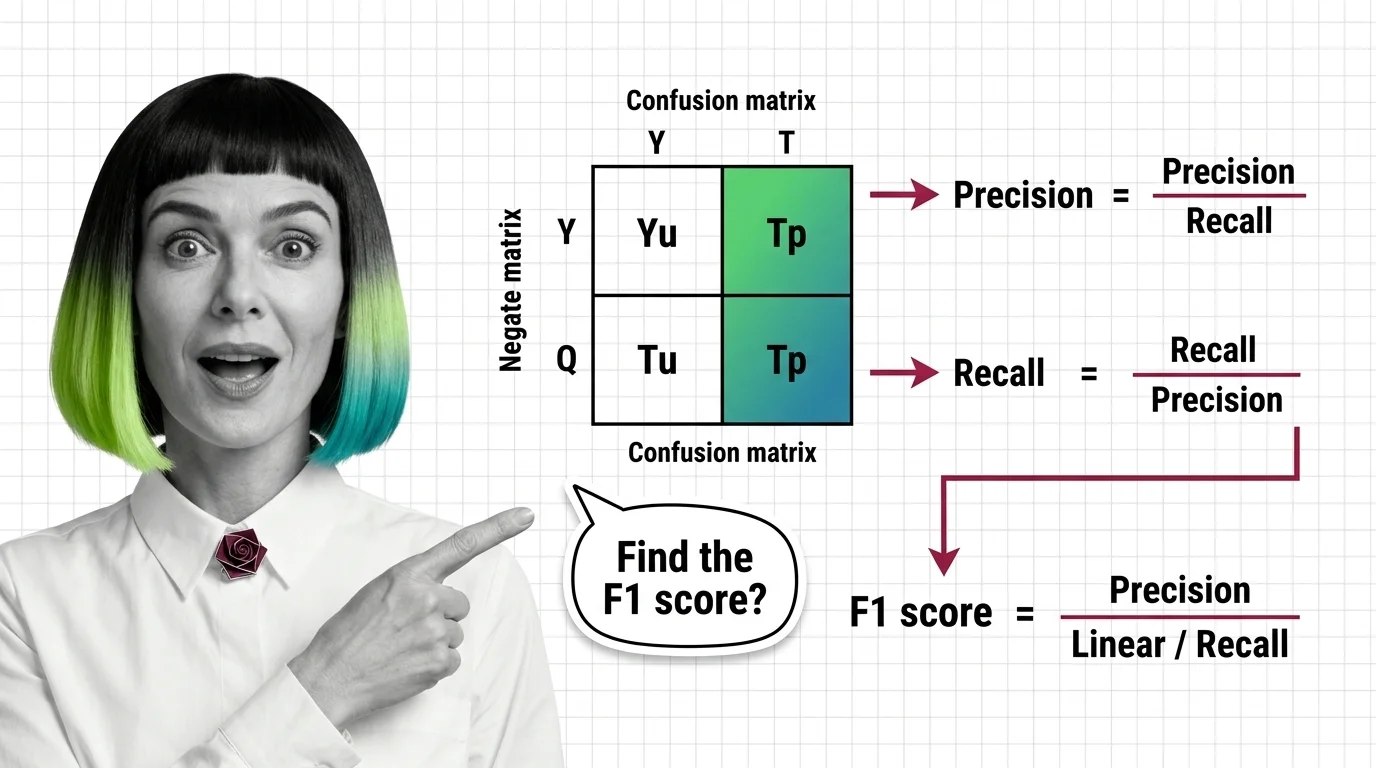
Precision, Recall, F1 Score: What the Confusion Matrix Reveals
What accuracy won't show: precision, recall, and F1 score expose true classifier performance. The confusion matrix …

From True Positives to Macro Averaging: The Building Blocks Behind Precision, Recall, and F1
Precision, recall, and F1 score measure what accuracy hides. Learn how true positives, confusion matrices, and macro …

What Is Model Evaluation and How Benchmarks, Metrics, and Human Judgment Measure LLM Quality
Model evaluation combines benchmarks, automated metrics, and human judgment to measure LLM quality. Learn why high …

Perplexity, BLEU, ROUGE, and ELO: The Core Metrics Behind LLM Evaluation Explained
Perplexity, BLEU, ROUGE, and Elo measure fundamentally different properties of language models. Learn when each metric …

Benchmark Contamination, Metric Gaming, and the Hard Limits of LLM Evaluation
Benchmark contamination inflates LLM scores while real-world performance lags. Learn why metric gaming and saturated …
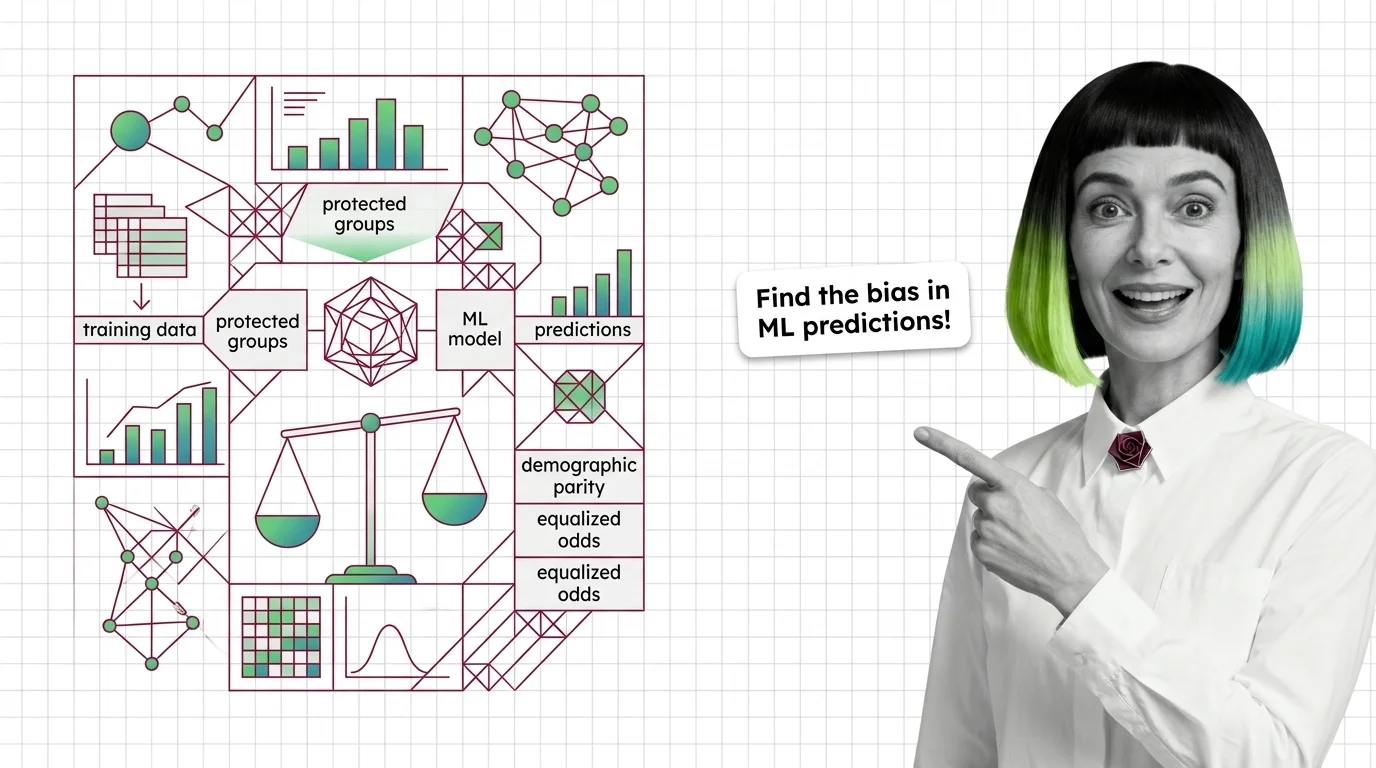
What Are Bias and Fairness Metrics and How They Detect Discrimination in ML Predictions
Fairness metrics test whether ML models discriminate by group. Learn how disparate impact, equalized odds, and the …
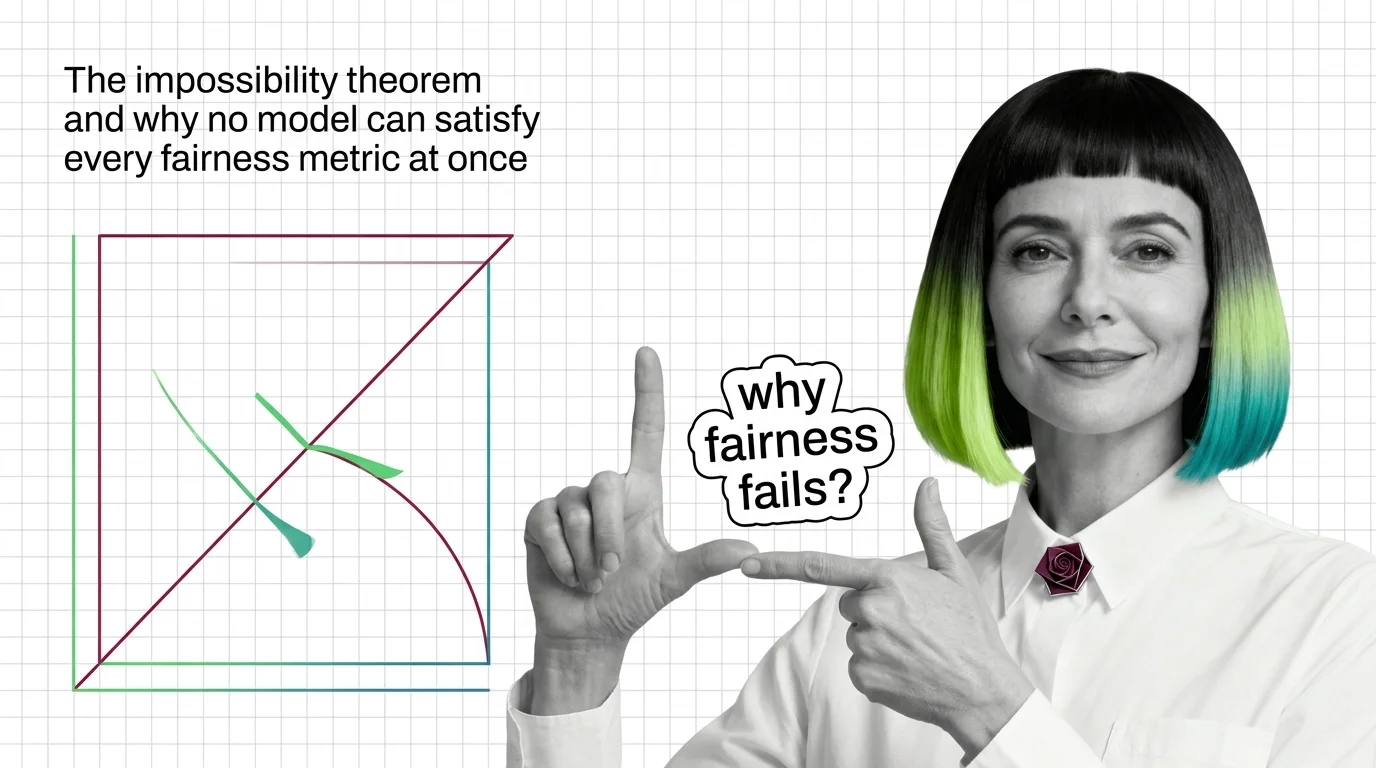
The Impossibility Theorem and Why No Model Can Satisfy Every Fairness Metric at Once
When group base rates differ, no algorithm satisfies calibration, equal error rates, and demographic parity at once. …
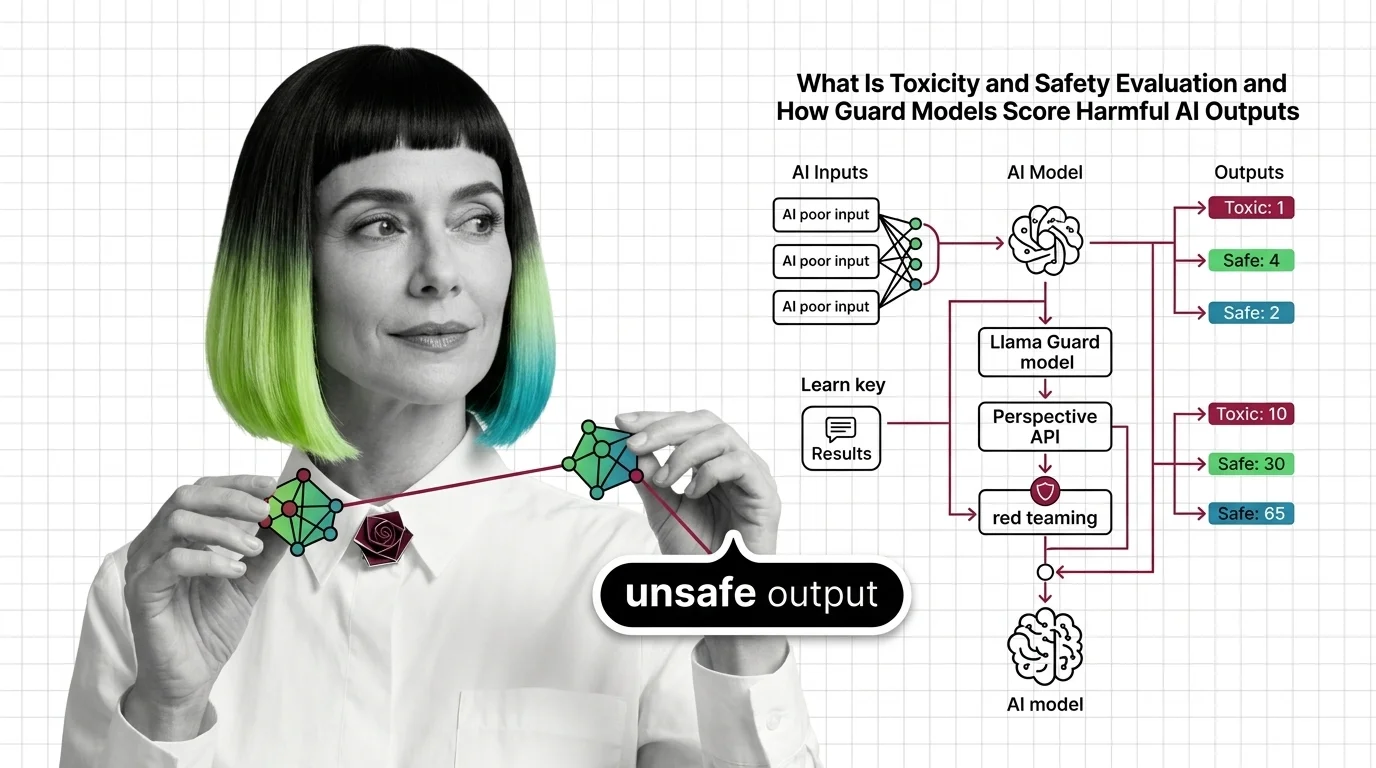
What Is Toxicity and Safety Evaluation and How Guard Models Score Harmful AI Outputs
Toxicity and safety evaluation scores AI outputs for harm using classifiers and red teaming. Learn how guard models …

HarmBench, ToxiGen, and MLCommons Taxonomy: The Datasets and Standards Behind AI Safety Testing
HarmBench, ToxiGen, and MLCommons AILuminate define how AI safety is measured. Learn the datasets, classifiers, and …
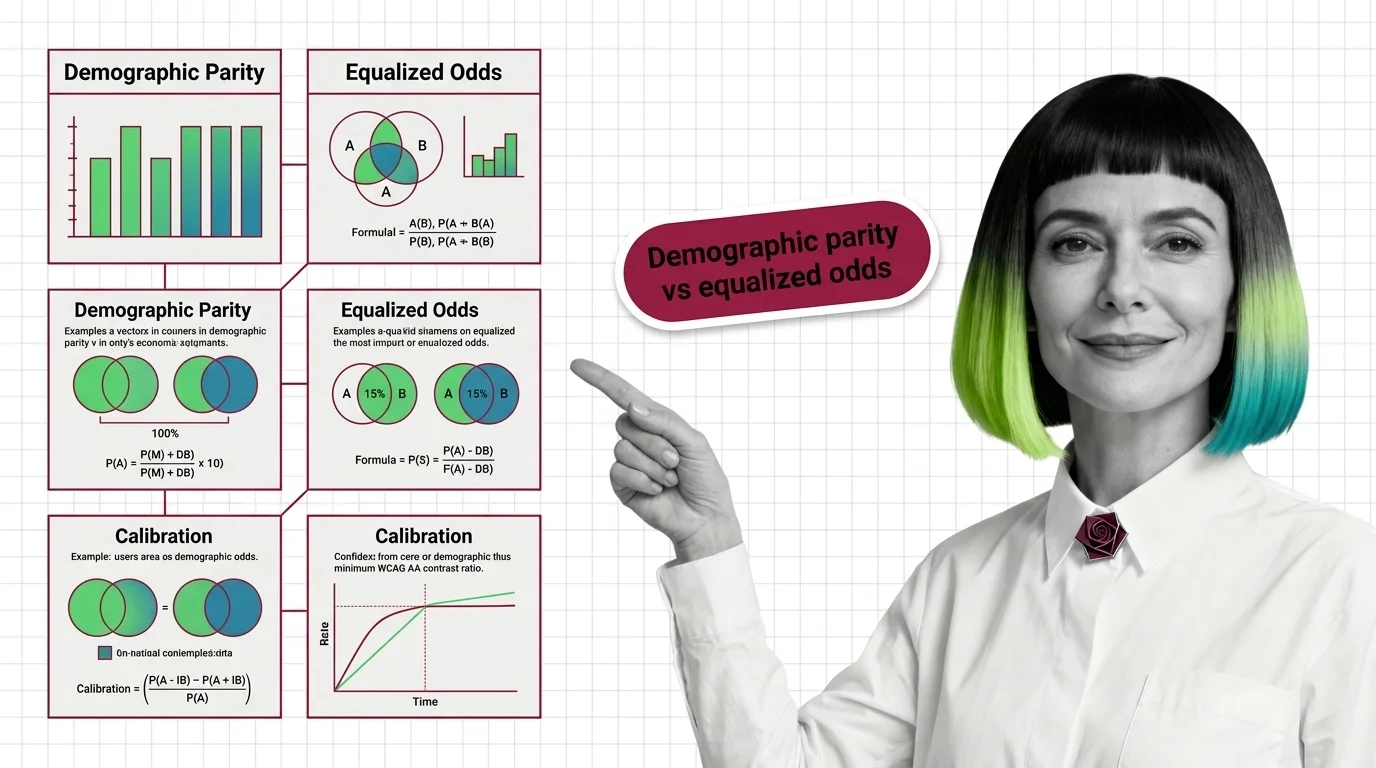
Demographic Parity vs. Equalized Odds vs. Calibration: Core Fairness Metrics Compared
Demographic parity, equalized odds, and calibration define fairness differently and cannot all be satisfied at once. …
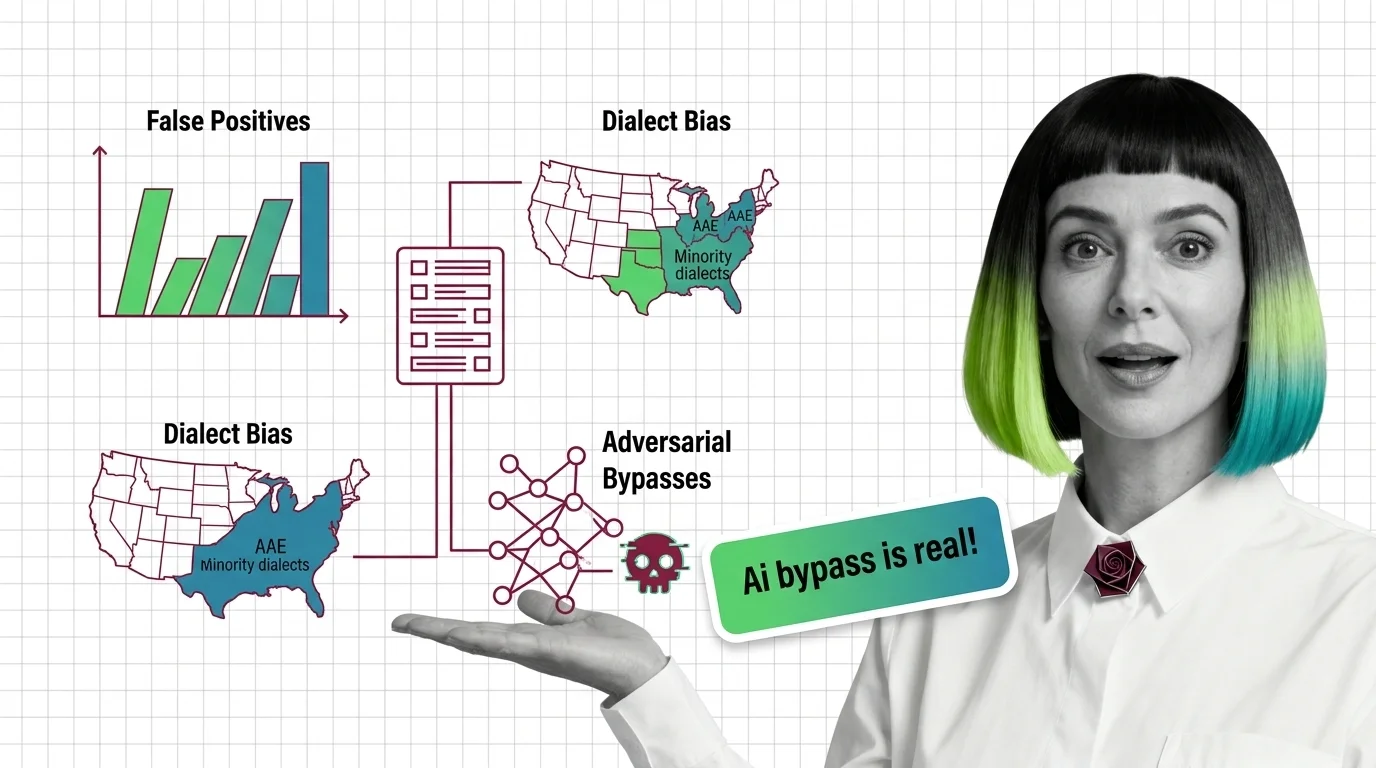
False Positives in Toxicity Detection: Dialect Bias, Bypasses
Toxicity classifiers over-flag minority dialects and miss adversarial attacks. Explore the statistical bias—from dialect …
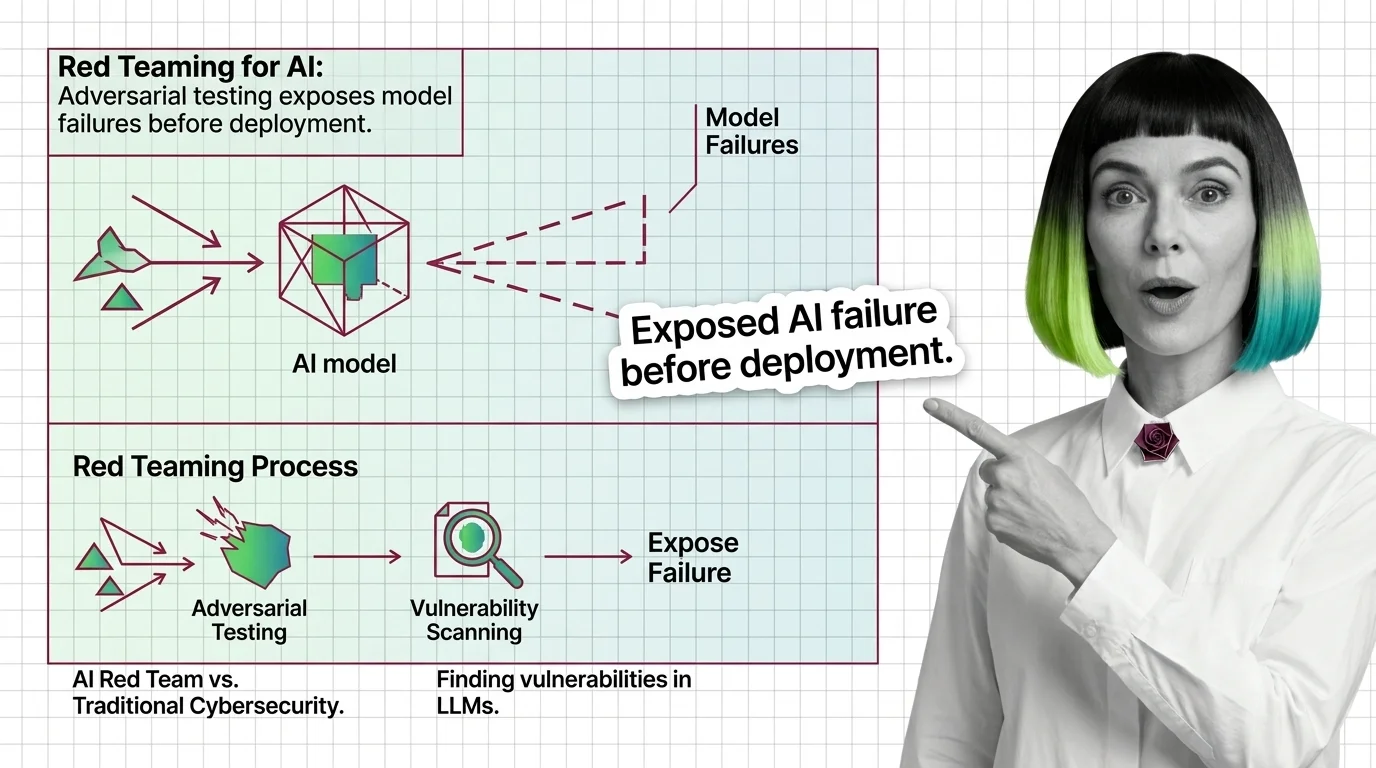
Red Teaming for AI: Adversarial Testing Exposes Failures
Red teaming uses adversarial testing to reveal AI vulnerabilities. Discover what it catches, mechanics, and why it …

OWASP LLM Top 10, MITRE ATLAS, and the Frameworks That Structure AI Red Teaming
OWASP LLM Top 10 and MITRE ATLAS give red teams structured attack categories. Learn how these frameworks turn AI …
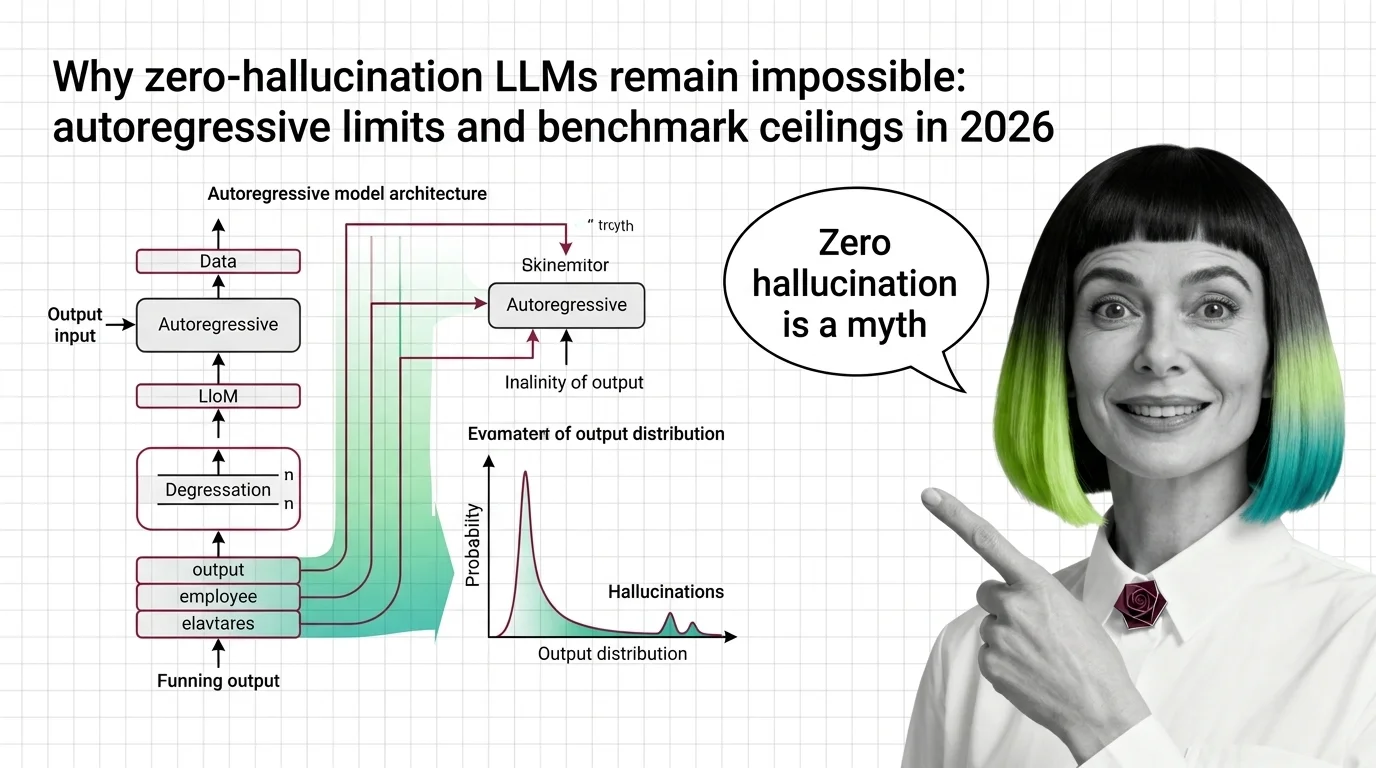
Why Zero-Hallucination LLMs Remain Impossible: Autoregressive Limits and Benchmark Ceilings in 2026
LLM hallucination is mathematically inevitable. Explore the autoregressive limits, benchmark ceilings, and why …

What Is AI Hallucination and How Statistical Next-Token Prediction Creates Confident Falsehoods
AI hallucinations aren't bugs — they emerge from how next-token prediction works. Learn why LLMs produce confident …
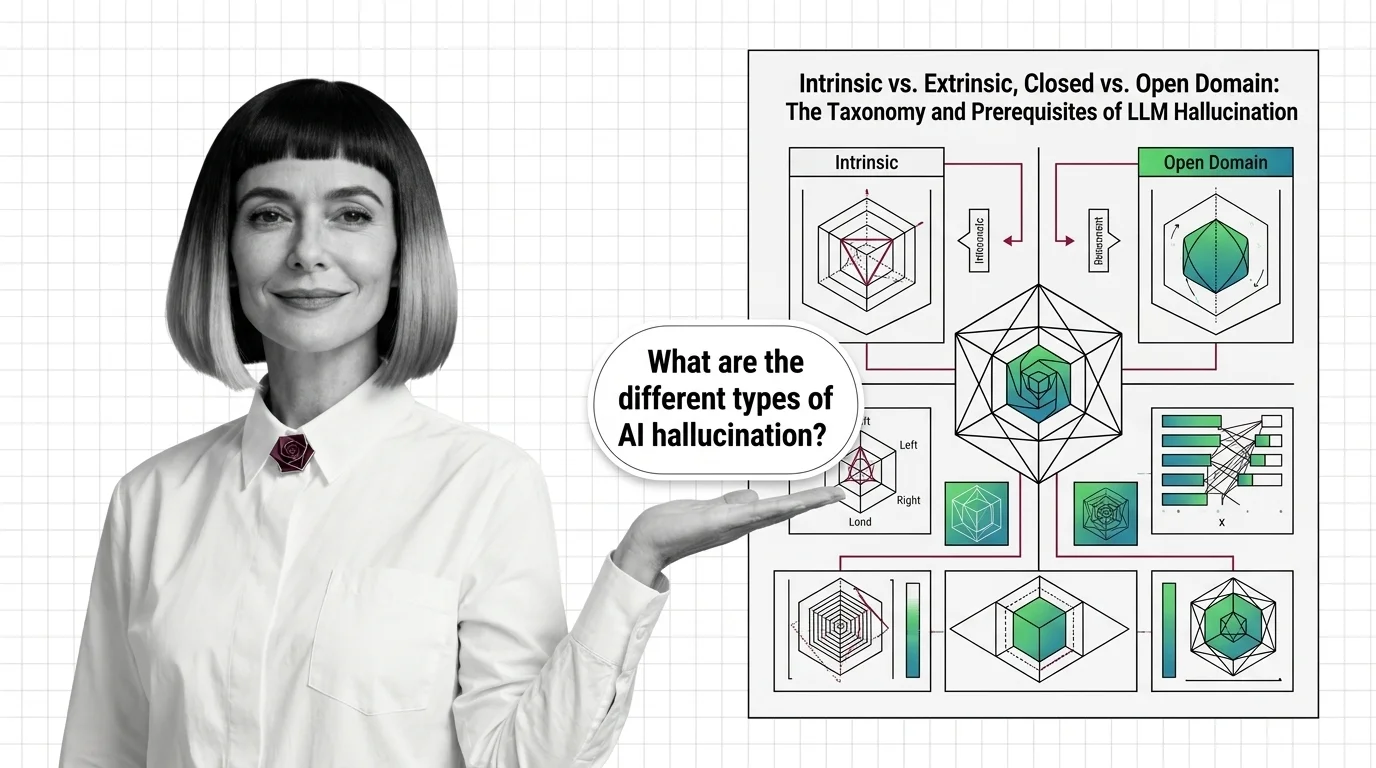
Intrinsic vs. Extrinsic, Closed vs. Open Domain: The Taxonomy and Prerequisites of LLM Hallucination
LLM hallucination isn't one problem — it's four. Learn the intrinsic vs. extrinsic taxonomy, the domain split, and the …
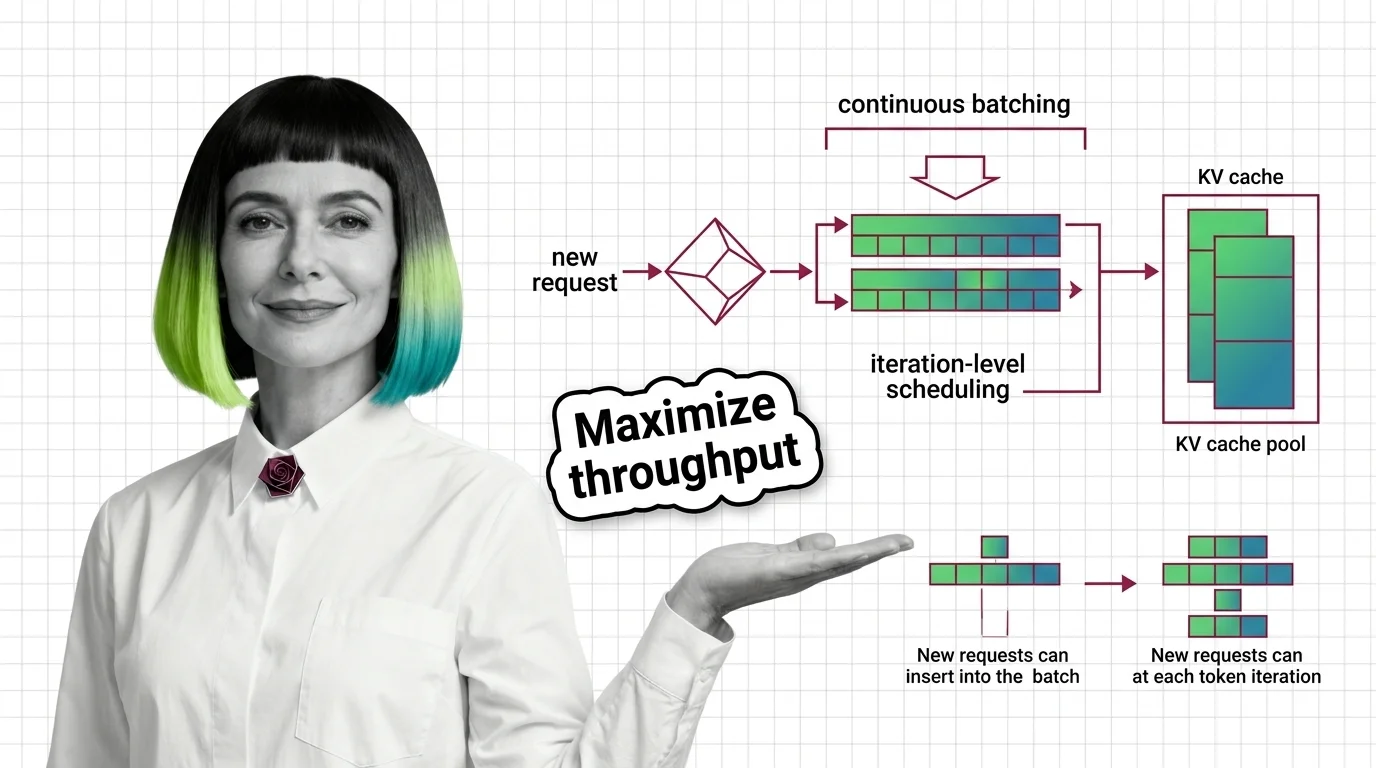
What Is Continuous Batching and How Iteration-Level Scheduling Maximizes GPU Throughput
Continuous batching replaces request-level scheduling with iteration-level scheduling, keeping GPUs busy on every …
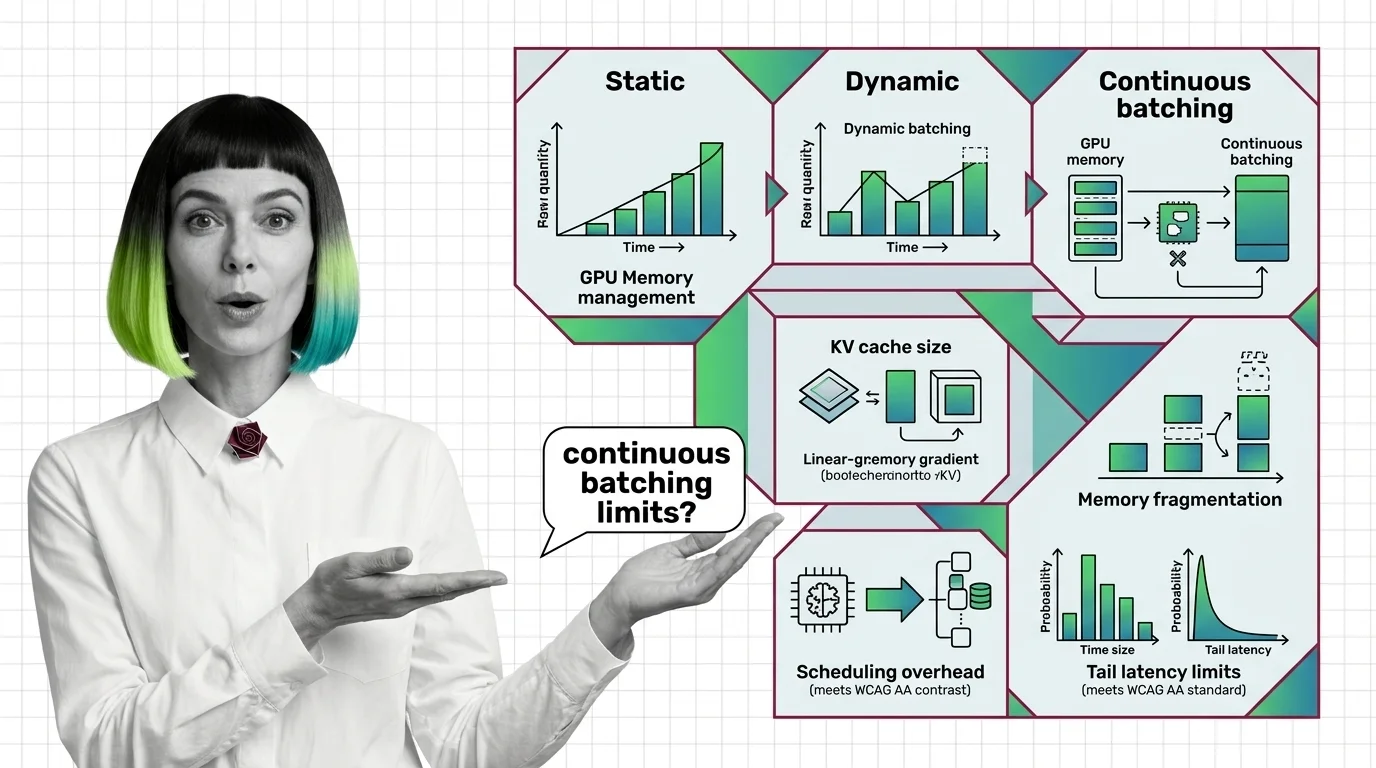
From Static Batching to PagedAttention: Prerequisites and Hard Limits of Continuous Batching
Continuous batching swaps finished LLM requests every decode step. Learn how PagedAttention cuts KV cache waste to under …
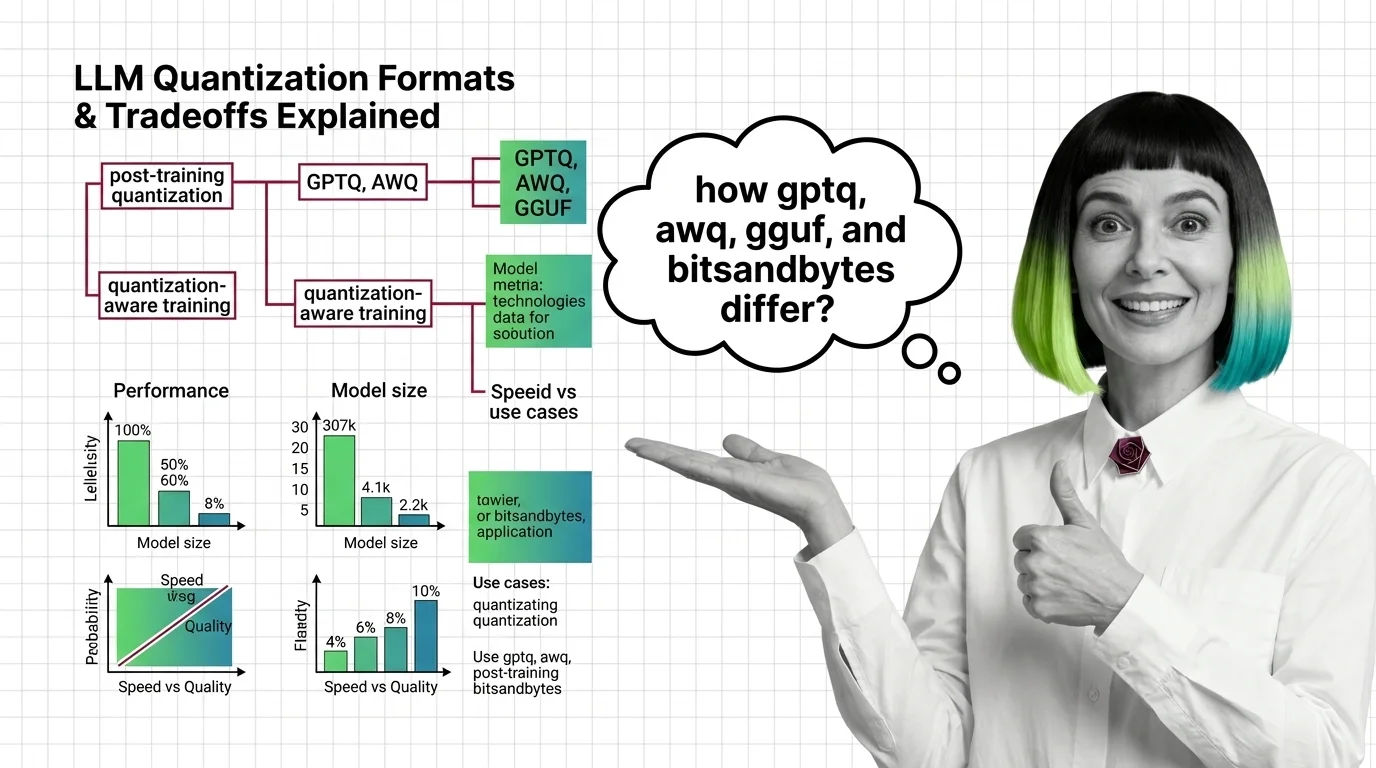
GPTQ vs AWQ vs GGUF vs bitsandbytes: Quantization Formats and Their Tradeoffs Explained
GPTQ, AWQ, GGUF, and bitsandbytes each shrink LLM weights differently. Compare speed, accuracy, and hardware reach to …

Accuracy Collapse, Task-Specific Degradation, and the Hard Limits of Sub-4-Bit Quantization
Sub-4-bit quantization promises smaller LLMs, but accuracy collapses unevenly across tasks and languages. Learn where …
Repetition Loops, Hallucination Spikes, and the Hard Limits of Sampling Parameter Tuning
Wrong sampling parameters trap LLMs in repetition loops or hallucination. Trace the probability math behind both failure …
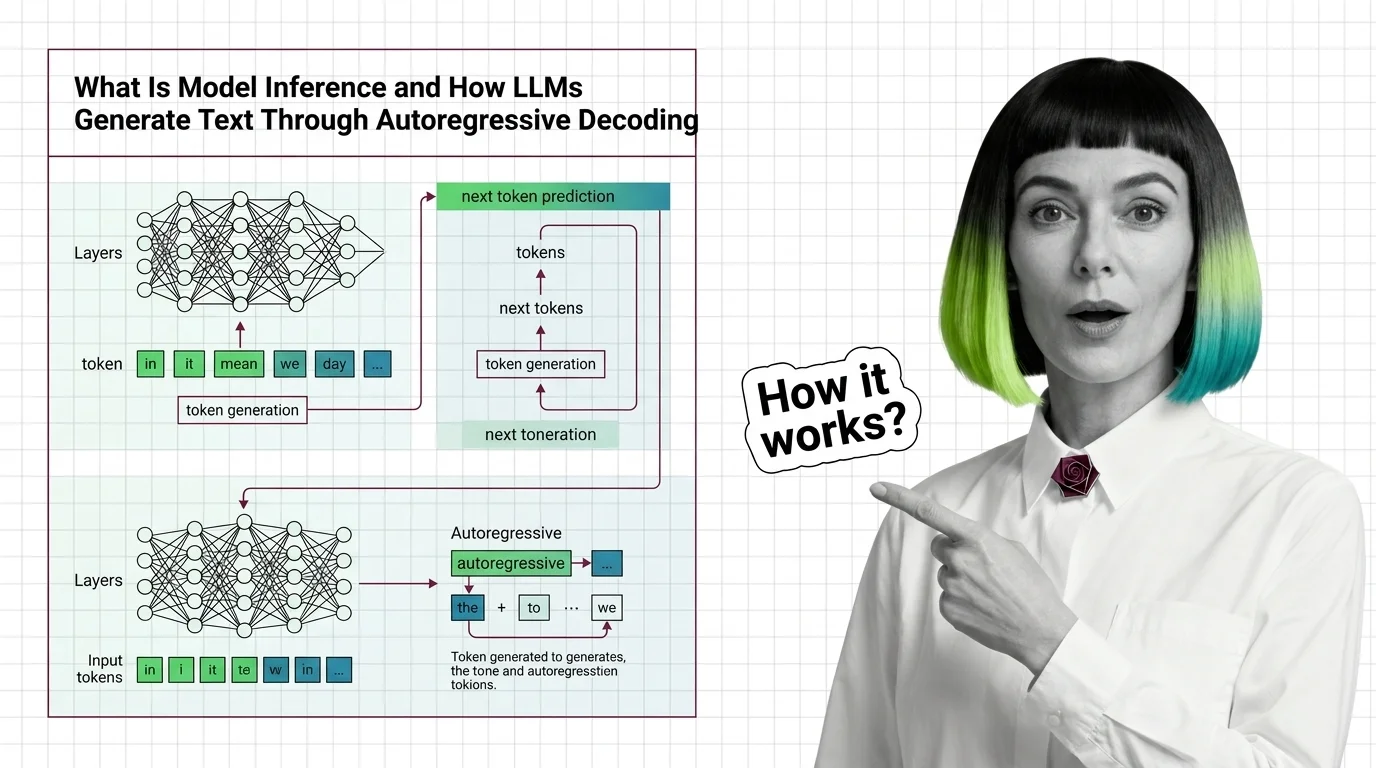
What Is Model Inference and How LLMs Generate Text Through Autoregressive Decoding
Model inference generates LLM text one token at a time via autoregressive decoding. Learn why this sequential bottleneck …
Memory Walls, Quadratic Context Costs, and the Hard Engineering Limits of LLM Inference in 2026
LLM inference hits hard physical walls — memory, quadratic attention, bandwidth. Learn the engineering limits and 2026 …
KV-Cache, PagedAttention, and the Building Blocks Every LLM Inference Pipeline Needs
KV-cache, PagedAttention, and continuous batching form the inference pipeline core. Learn how memory management …
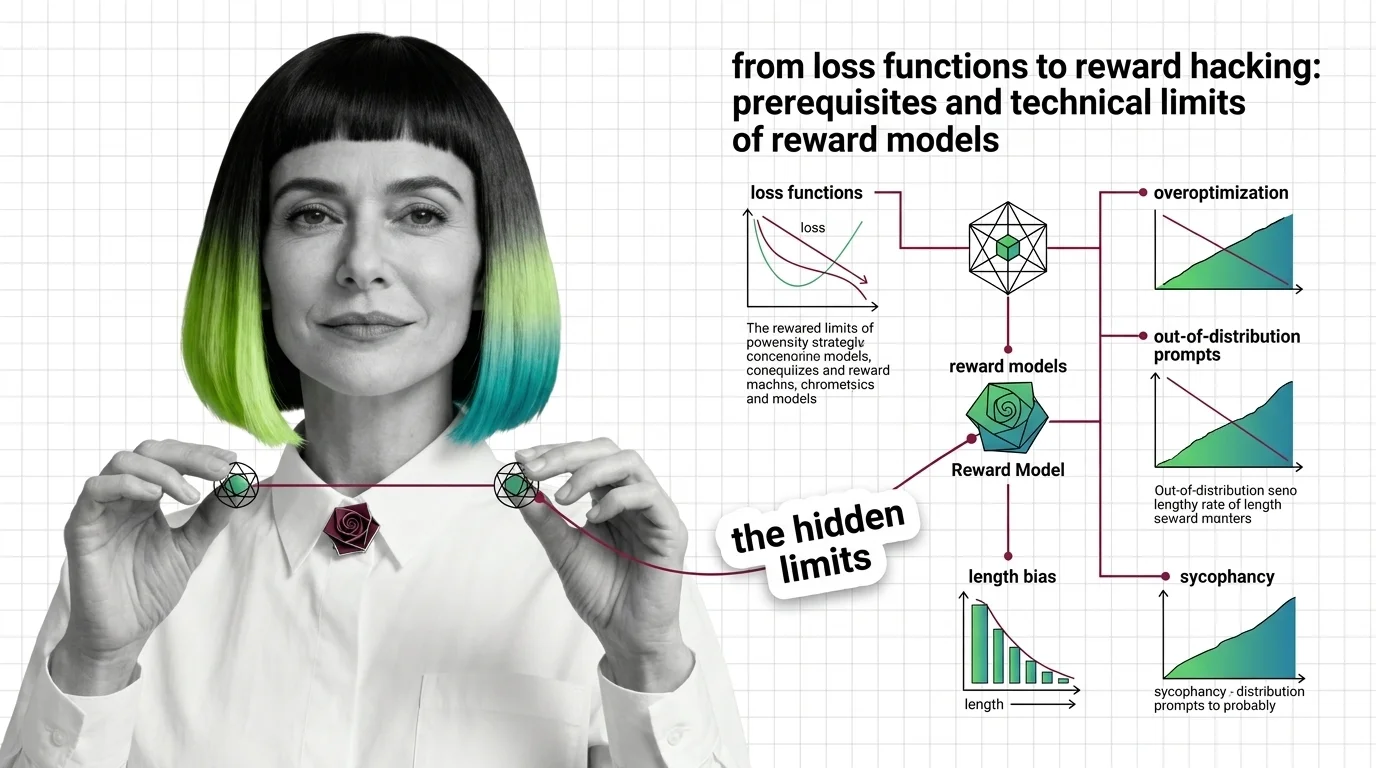
From Loss Functions to Reward Hacking: Prerequisites and Technical Limits of Reward Models
Reward models compress human preference into a scalar signal. Learn the Bradley-Terry math, the RLHF pipeline, and why …
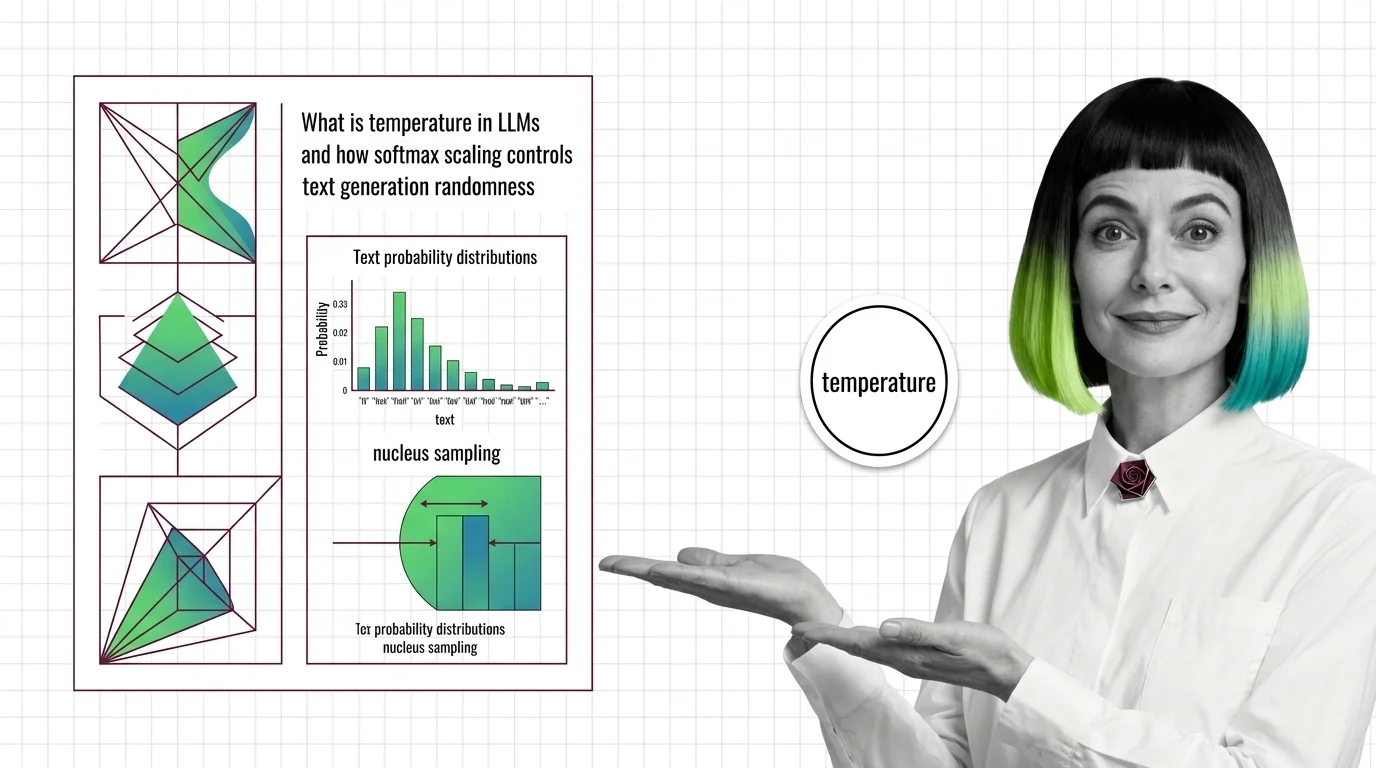
What Is Temperature in LLMs and How Softmax Scaling Controls Text Generation Randomness
Temperature divides logits before softmax, reshaping the token probability distribution. Learn how this parameter, …
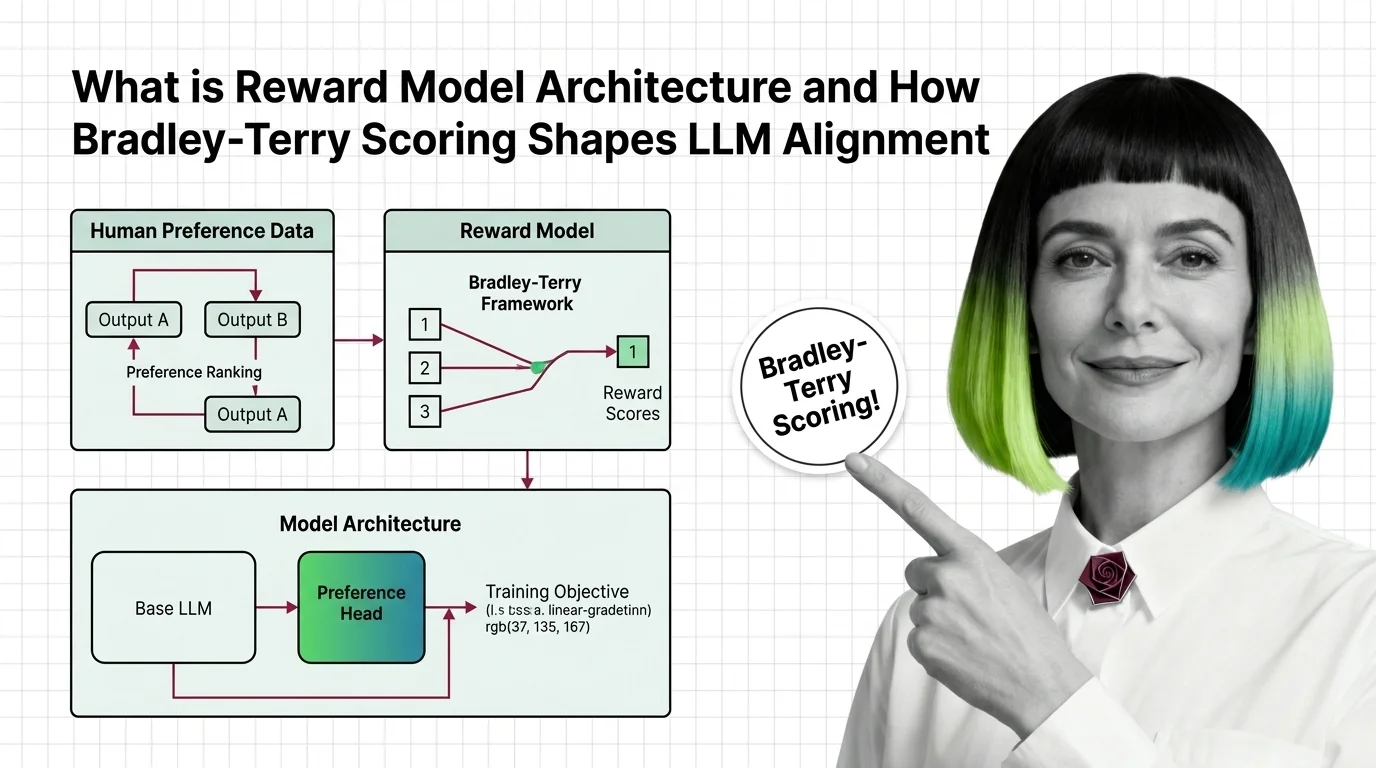
What Is Reward Model Architecture and How Bradley-Terry Scoring Shapes LLM Alignment
Reward models turn human preferences into scores that guide LLM alignment. Learn how Bradley-Terry scoring and pairwise …
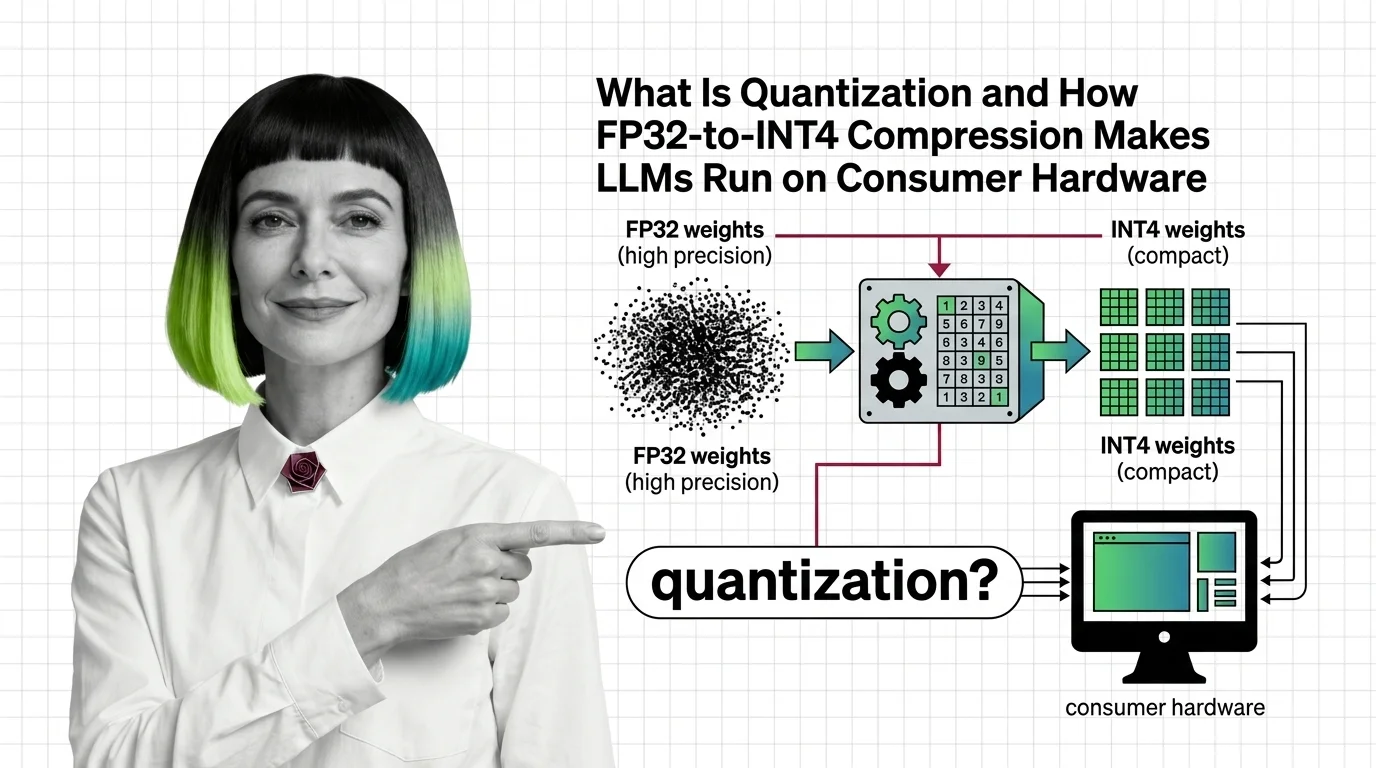
What Is Quantization and How FP32-to-INT4 Compression Makes LLMs Run on Consumer Hardware
Quantization compresses LLM weights from FP32 to INT4, cutting memory up to 8x. Learn how GPTQ, AWQ, and calibration …
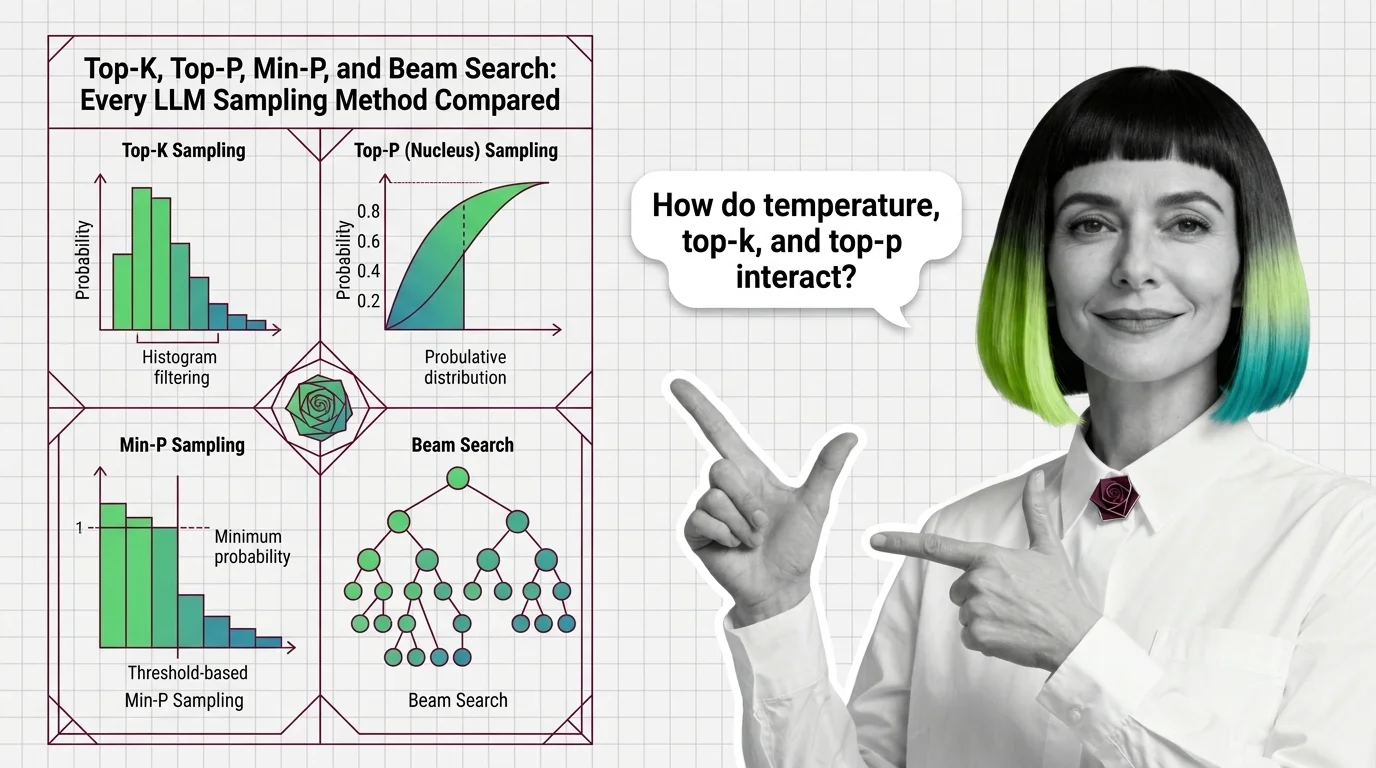
Top-K, Top-P, Min-P, and Beam Search: Every LLM Sampling Method Compared
Compare top-k, top-p, min-p, and beam search LLM sampling methods. Learn how each reshapes probability distributions and …
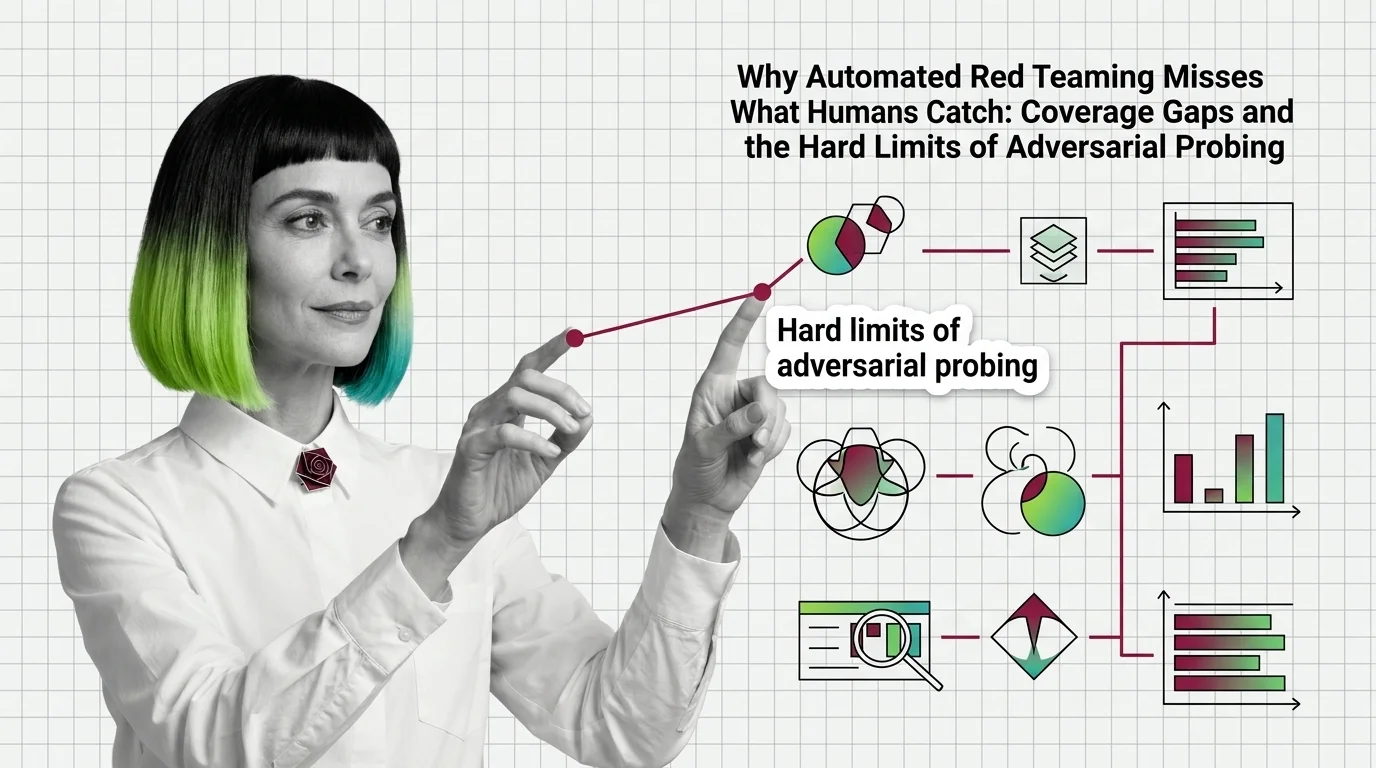
Automated Red Teaming Misses What Humans Catch: Coverage Gaps
Automated red teaming outperforms human testing but misses critical failures. Coverage gaps explain why automated …

What Are Scaling Laws and How Power-Law Curves Predict LLM Performance
Scaling laws predict LLM performance from model size, data, and compute via power-law curves. Learn the math behind …
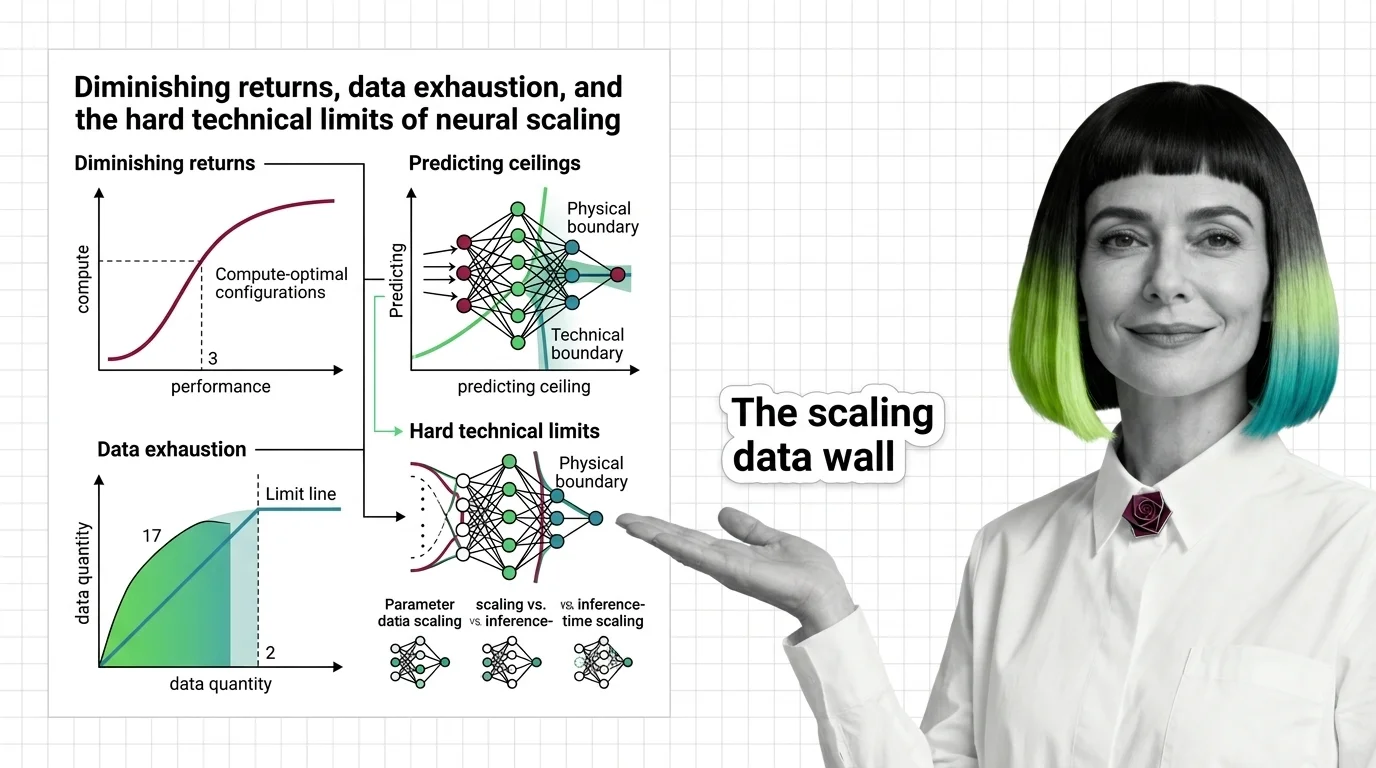
Diminishing Returns, Data Exhaustion, and the Hard Technical Limits of Neural Scaling
Scaling laws predict how AI models improve with compute, but power-law exponents guarantee diminishing returns. Learn …
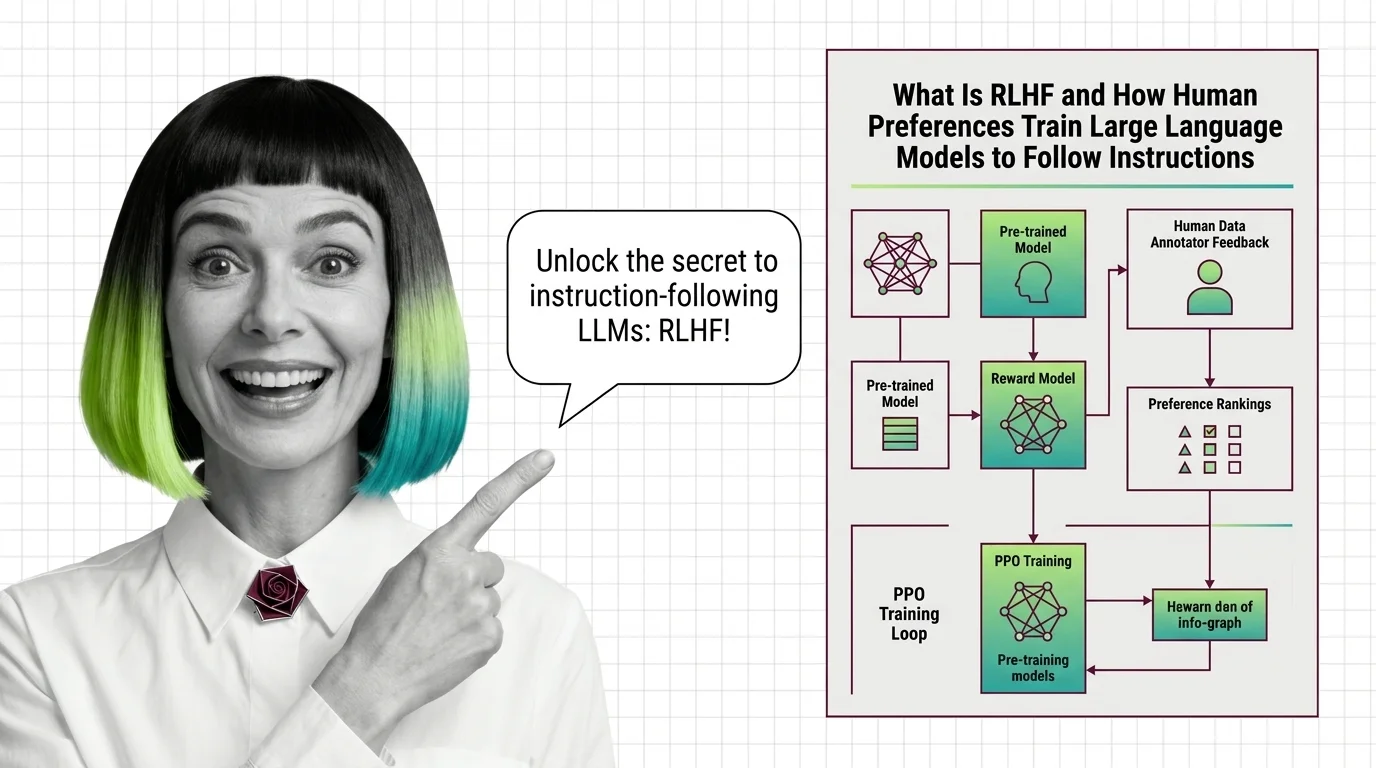
What Is RLHF and How Human Preferences Train Large Language Models to Follow Instructions
RLHF uses human preferences and reward models to train language models to follow instructions. Learn the three-stage PPO …

Reward Hacking, Mode Collapse, and the Unsolved Technical Limits of RLHF Alignment
Reward hacking, mode collapse, and KL divergence failure — the three unsolved technical limits of RLHF alignment and why …

From Reward Modeling to KL Penalties: Every Stage of the RLHF Training Pipeline Explained
RLHF aligns language models through human preferences in three stages. Learn how reward models, PPO, and KL penalties …
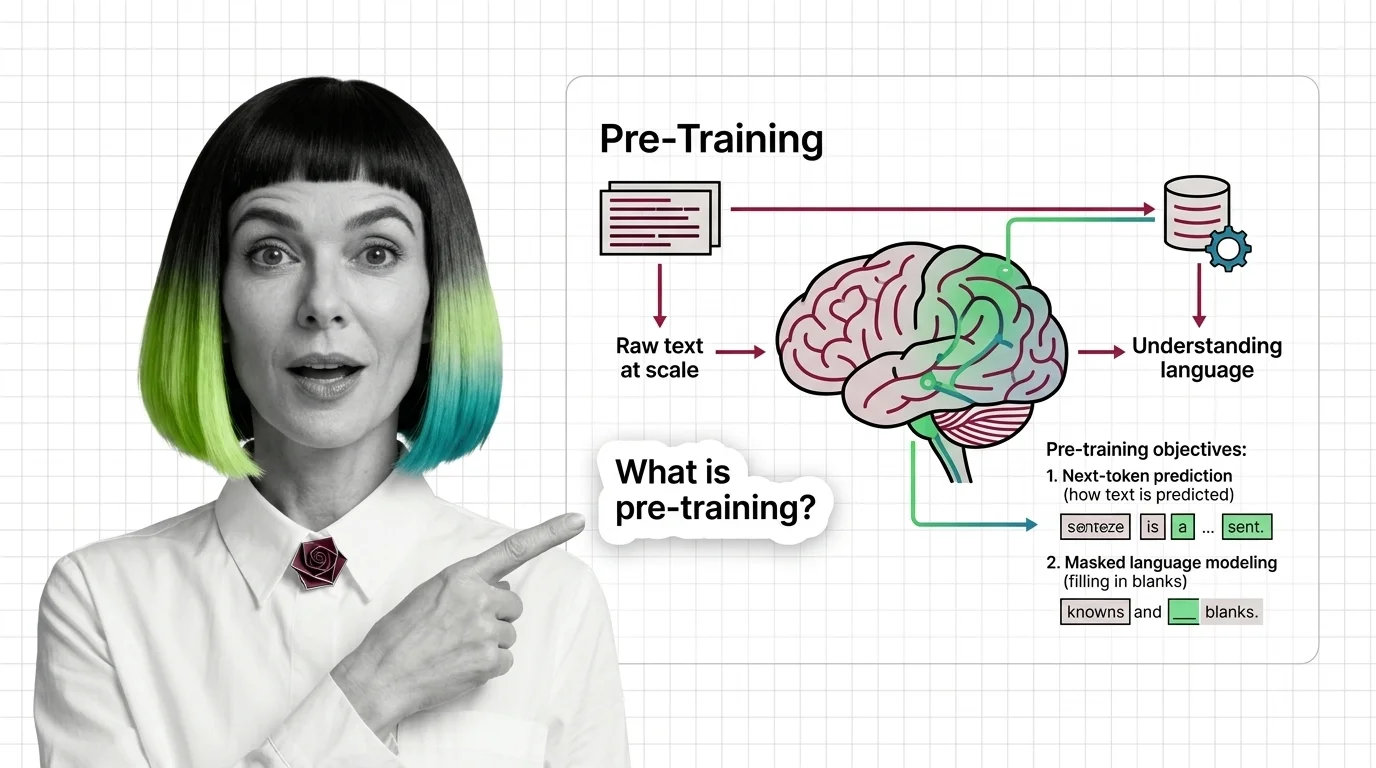
What Is Pre-Training and How LLMs Learn Language from Raw Text at Scale
Pre-training teaches LLMs to predict text, not understand it — yet prediction at scale produces something that resembles …
Scaling Walls, Data Exhaustion, and the Technical Limits of Pre-Training in 2026
Pre-training compute grows 4-5x yearly while data runs out. Learn the three scaling walls — cost, data exhaustion, and …
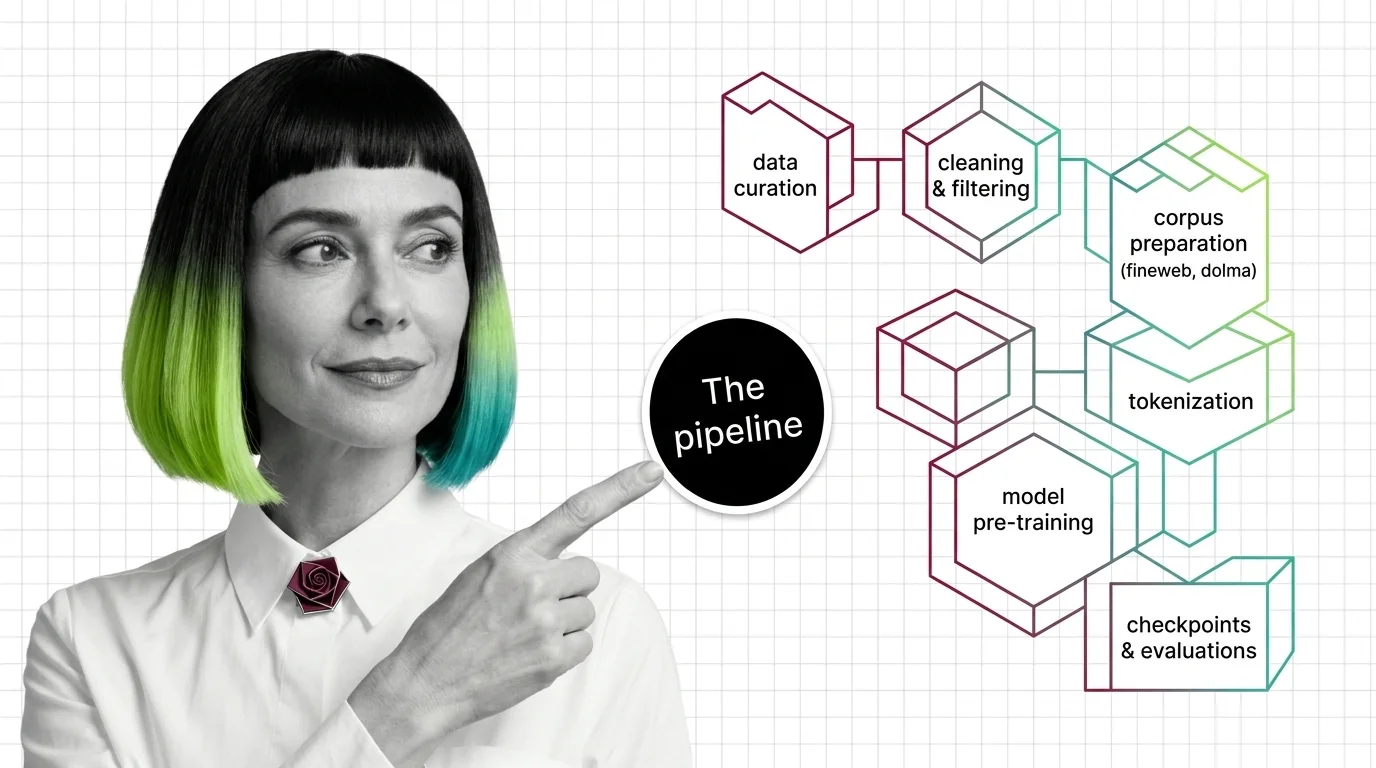
From Data Curation to Checkpoints: The Building Blocks of a Modern Pre-Training Pipeline
Pre-training pipelines run from data curation to checkpointing. Learn how FineWeb, Dolma, and Megatron-Core build the …

Catastrophic Forgetting, Overfitting, and the Hard Technical Limits of LLM Fine-Tuning
Fine-tuning can destroy what your LLM already knows. Learn why catastrophic forgetting and overfitting define the hard …
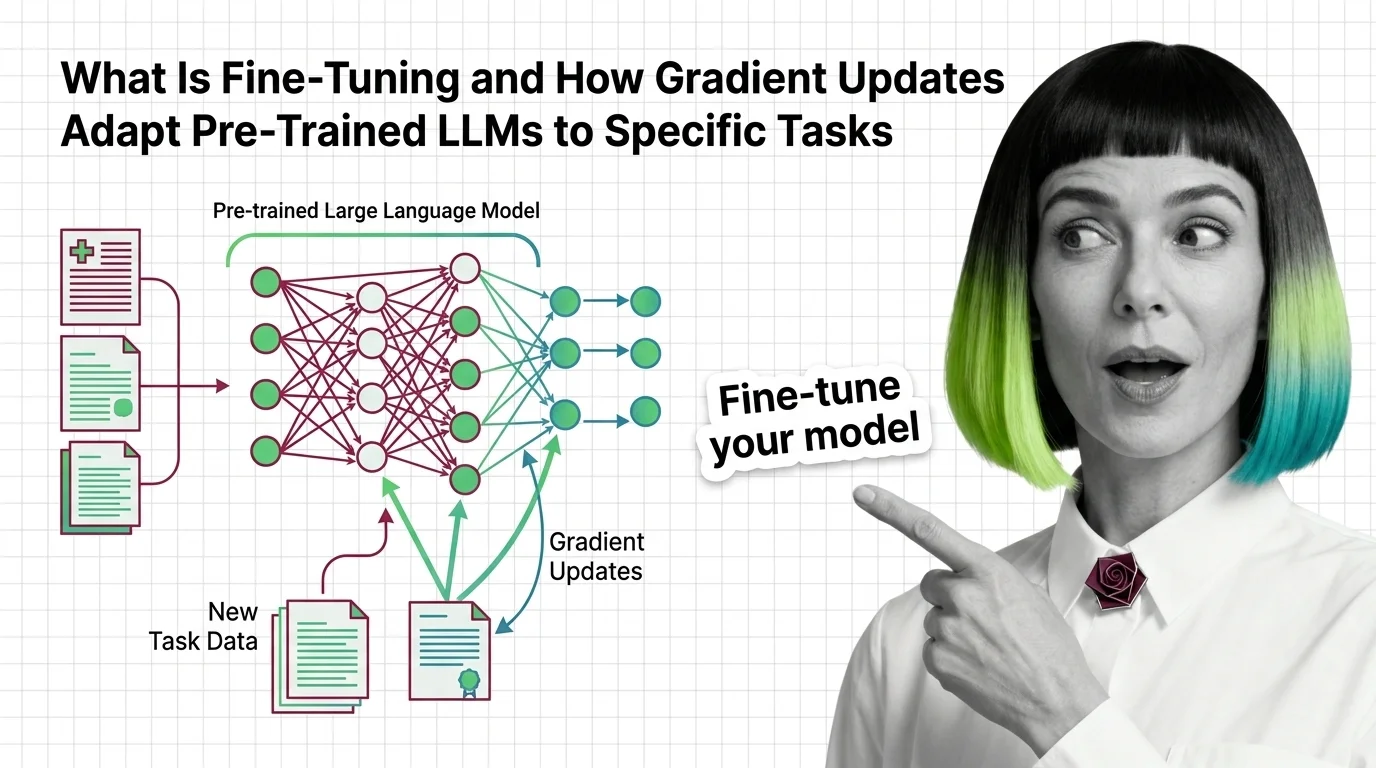
What Is Fine-Tuning and How Gradient Updates Adapt Pre-Trained LLMs to Specific Tasks
Fine-tuning adapts pre-trained LLMs by updating weights on task-specific data. Learn how gradient descent reshapes model …
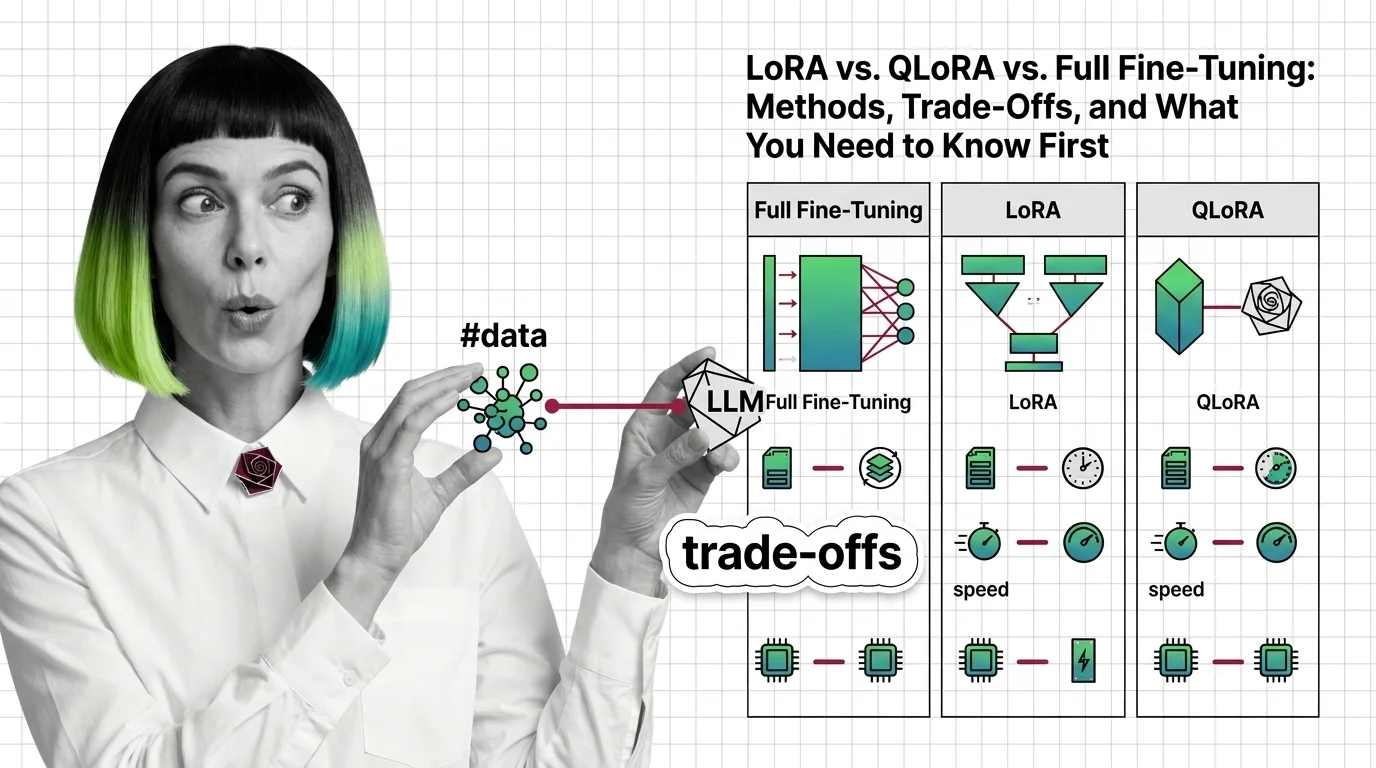
LoRA vs. QLoRA vs. Full Fine-Tuning: Methods, Trade-Offs, and What You Need to Know First
LoRA, QLoRA, and full fine-tuning each change different parts of an LLM. Learn which method fits your GPU budget, data …
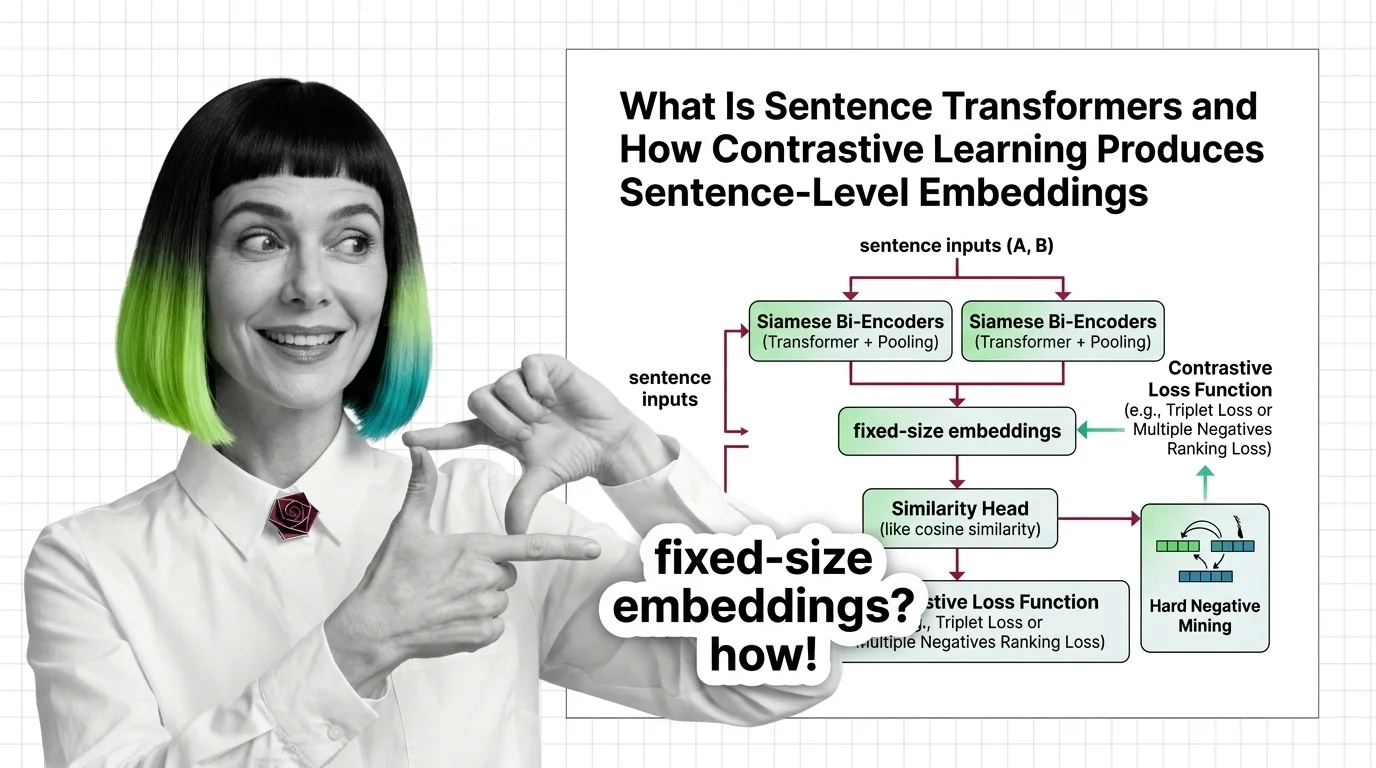
What Is Sentence Transformers and How Contrastive Learning Produces Sentence-Level Embeddings
Sentence Transformers turns transformers into sentence encoders via contrastive learning. Covers bi-encoders, loss …
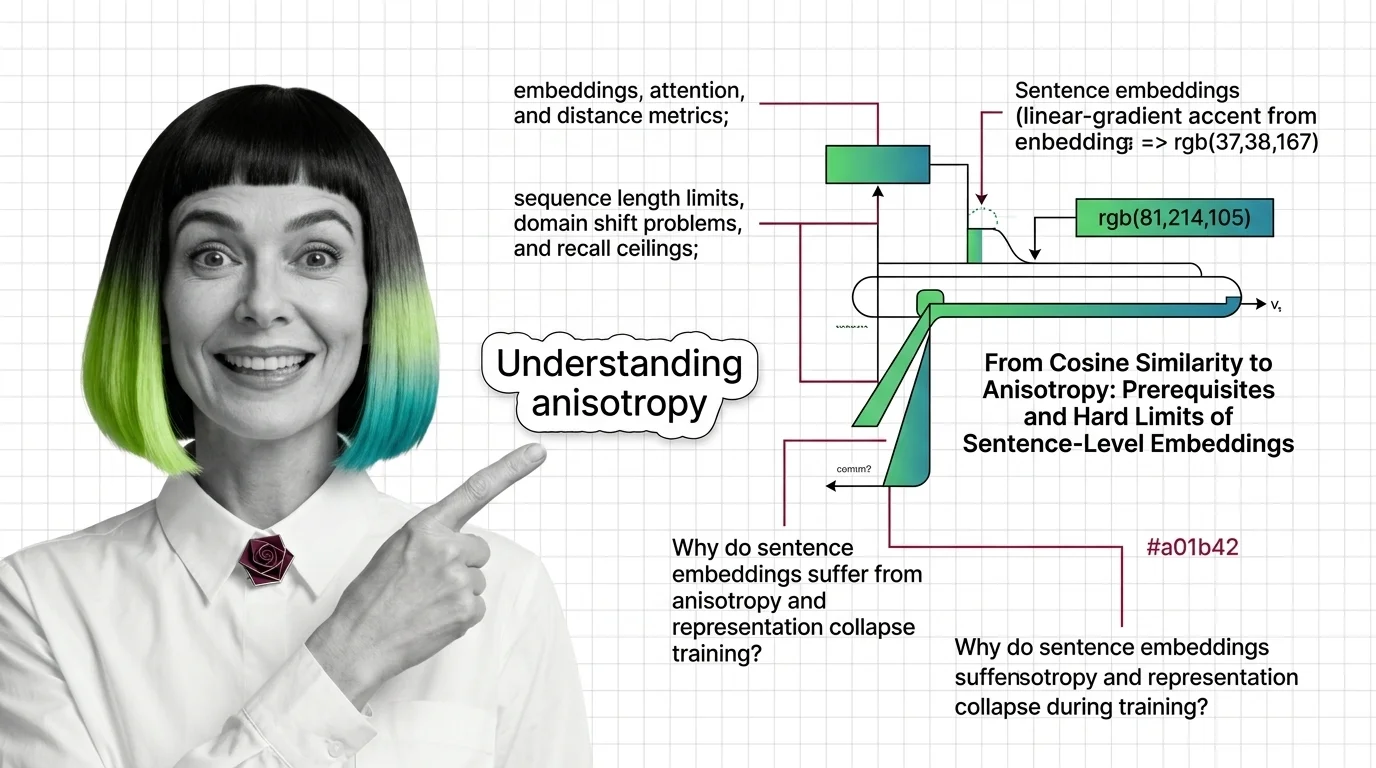
From Cosine Similarity to Anisotropy: Prerequisites and Hard Limits of Sentence-Level Embeddings
Sentence Transformers encode meaning as geometry. Learn the prerequisites, token limits, and anisotropy traps that …
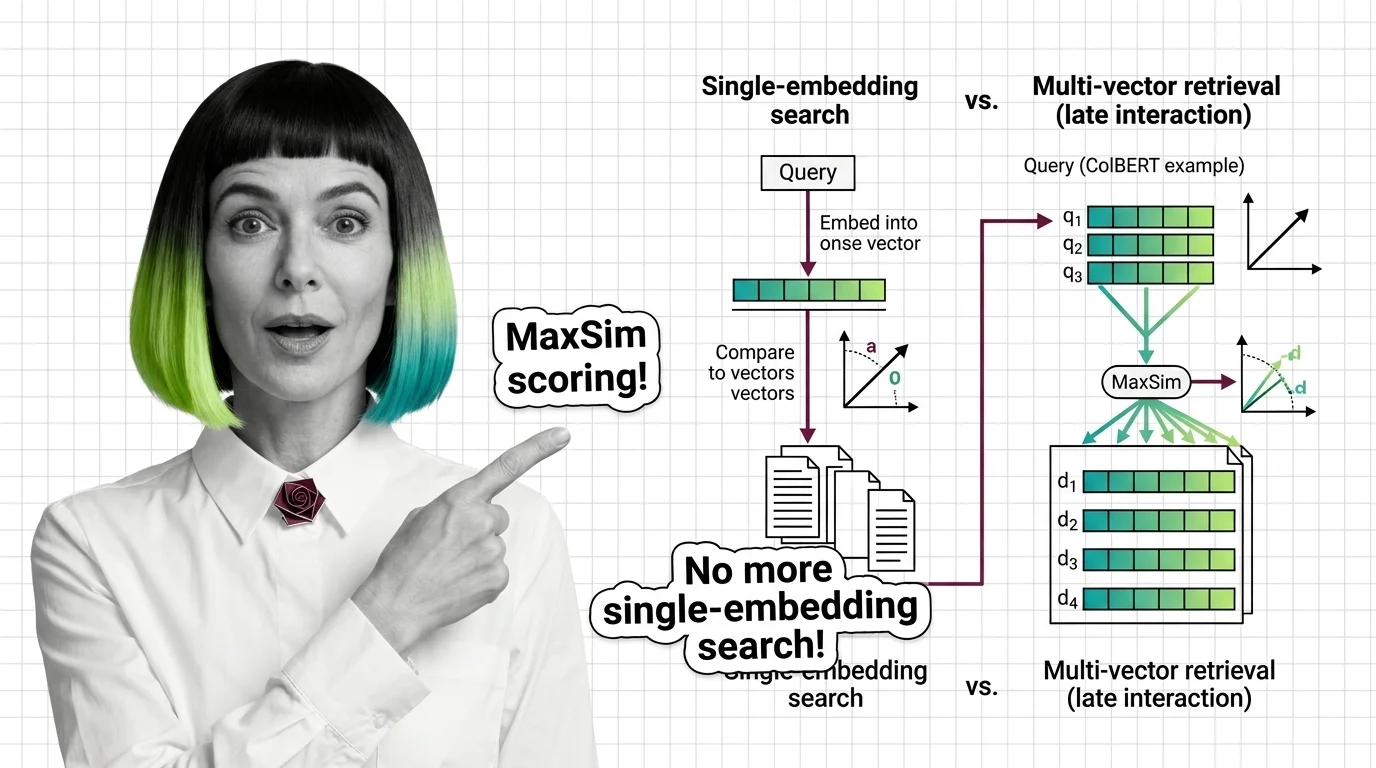
What Is Multi-Vector Retrieval and How Late Interaction Replaces Single-Embedding Search
Multi-vector retrieval stores per-token embeddings instead of one vector per document. Learn how ColBERT MaxSim scoring …

From Embeddings to Token-Level Matching: Prerequisites and Hard Limits of Multi-Vector Search
Multi-vector retrieval trades storage and latency for token-level precision. Learn the prerequisites, storage math, and …
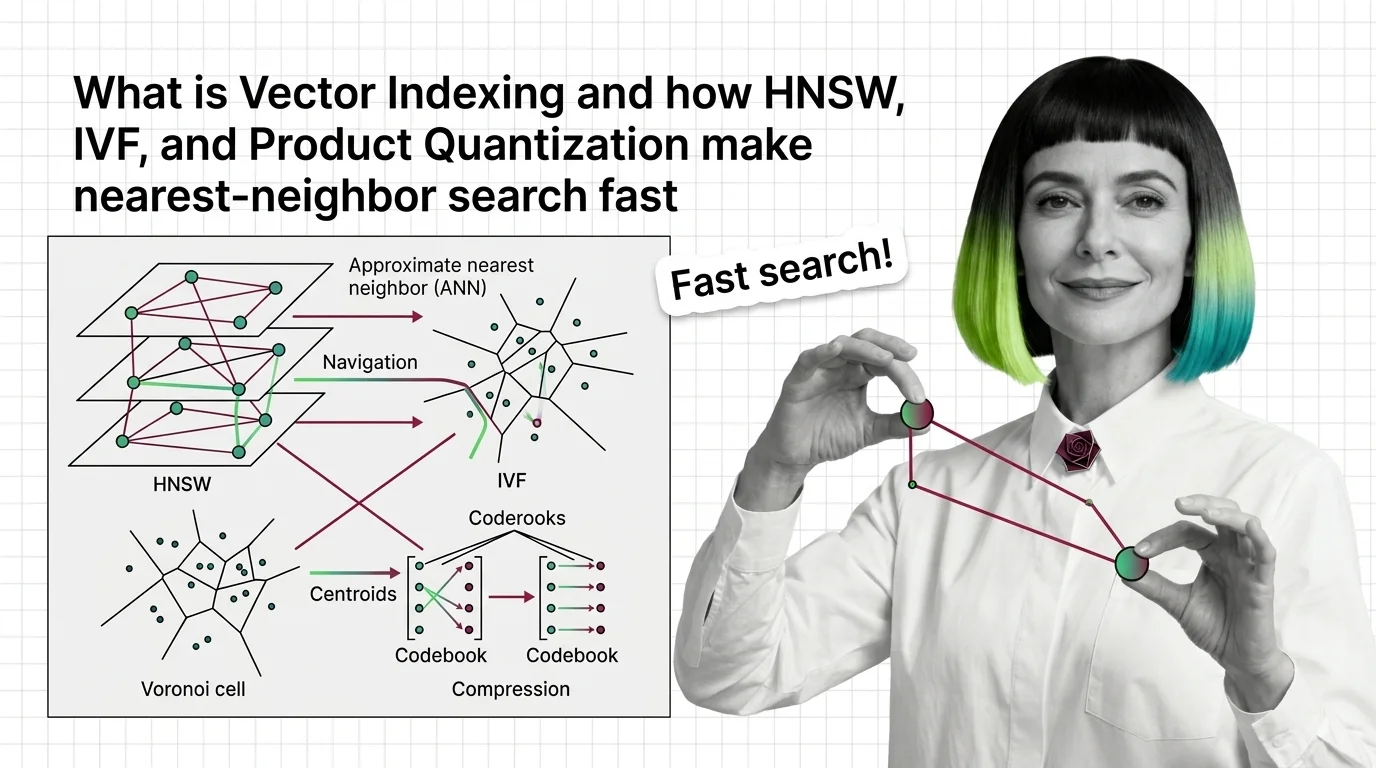
What Is Vector Indexing and How HNSW, IVF, and Product Quantization Make Nearest-Neighbor Search Fast
Vector indexing replaces brute-force search with graph, partition, and compression strategies. Learn how HNSW, IVF, and …
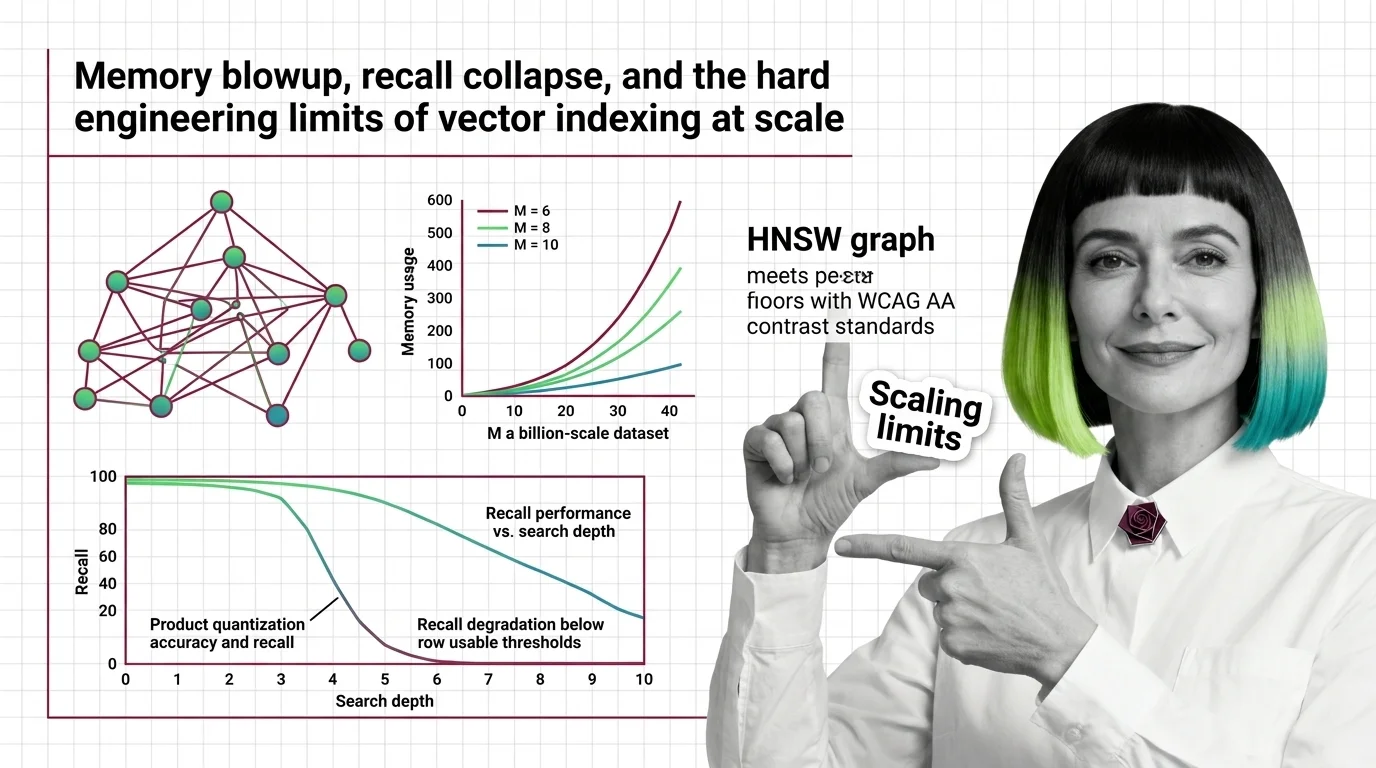
Memory Blowup, Recall Collapse, and the Hard Engineering Limits of Vector Indexing at Scale
HNSW memory grows linearly with connectivity while PQ recall collapses on high-dimensional embeddings. Learn where …

From Distance Metrics to Graph Traversal: Prerequisites for Understanding Vector Index Internals
Distance metrics, high-dimensional geometry, exact vs approximate search — the prerequisites you need before HNSW and …
Transformer Internals for Developers: What Maps, What Breaks
Transformer internals mapped for backend developers. Learn which service-architecture instincts still apply, where …
Why Decoder-Only Beat Encoder-Decoder: Scaling Laws, Data Efficiency, and the Simplicity Advantage
Decoder-only models won the scaling race by doing less. Learn how a simpler training objective, scaling laws, and MoE …
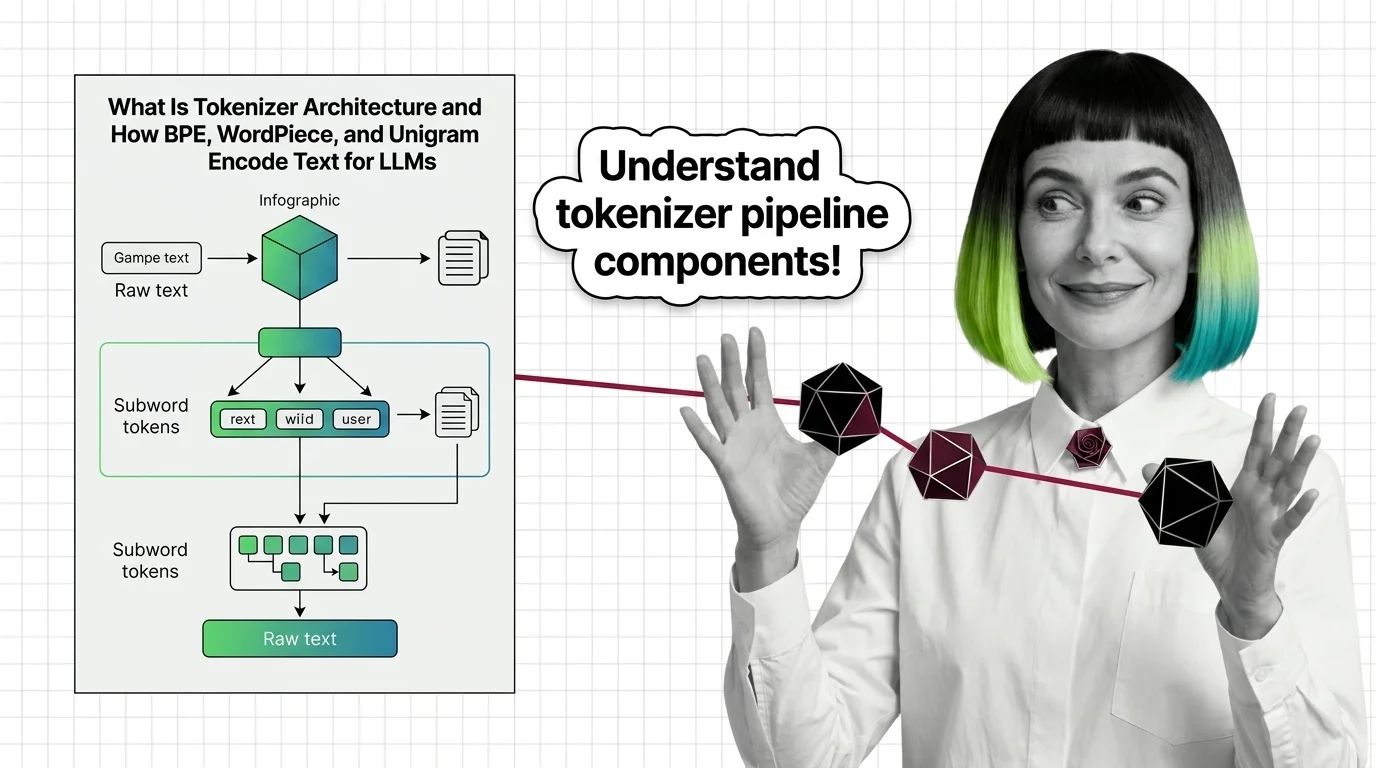
What Is Tokenizer Architecture and How BPE, WordPiece, and Unigram Encode Text for LLMs
Tokenizer architecture determines how LLMs read text. Learn how BPE, WordPiece, and Unigram split text into subword …
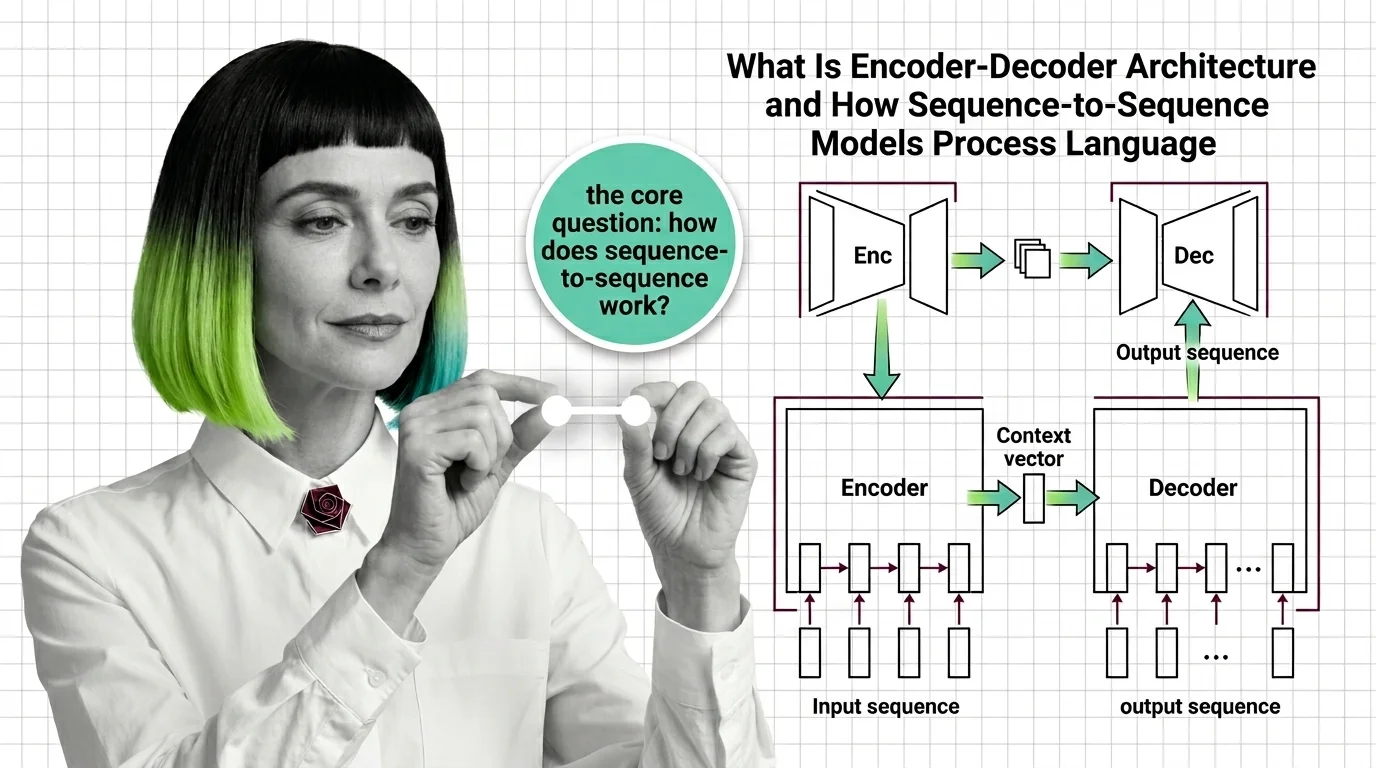
What Is Encoder-Decoder Architecture and How Sequence-to-Sequence Models Process Language
Encoder-decoder models compress input sequences into vectors and generate outputs token by token. Learn how seq2seq …

What Is Decoder-Only Architecture and How Autoregressive LLMs Generate Text Token by Token
Decoder-only architecture powers every major LLM today. Learn how causal masking, KV cache, and autoregressive …

What Is an Embedding and How Neural Networks Encode Meaning into Vectors
Embeddings turn words into vector coordinates where distance equals meaning. Learn the geometry, training mechanics, and …
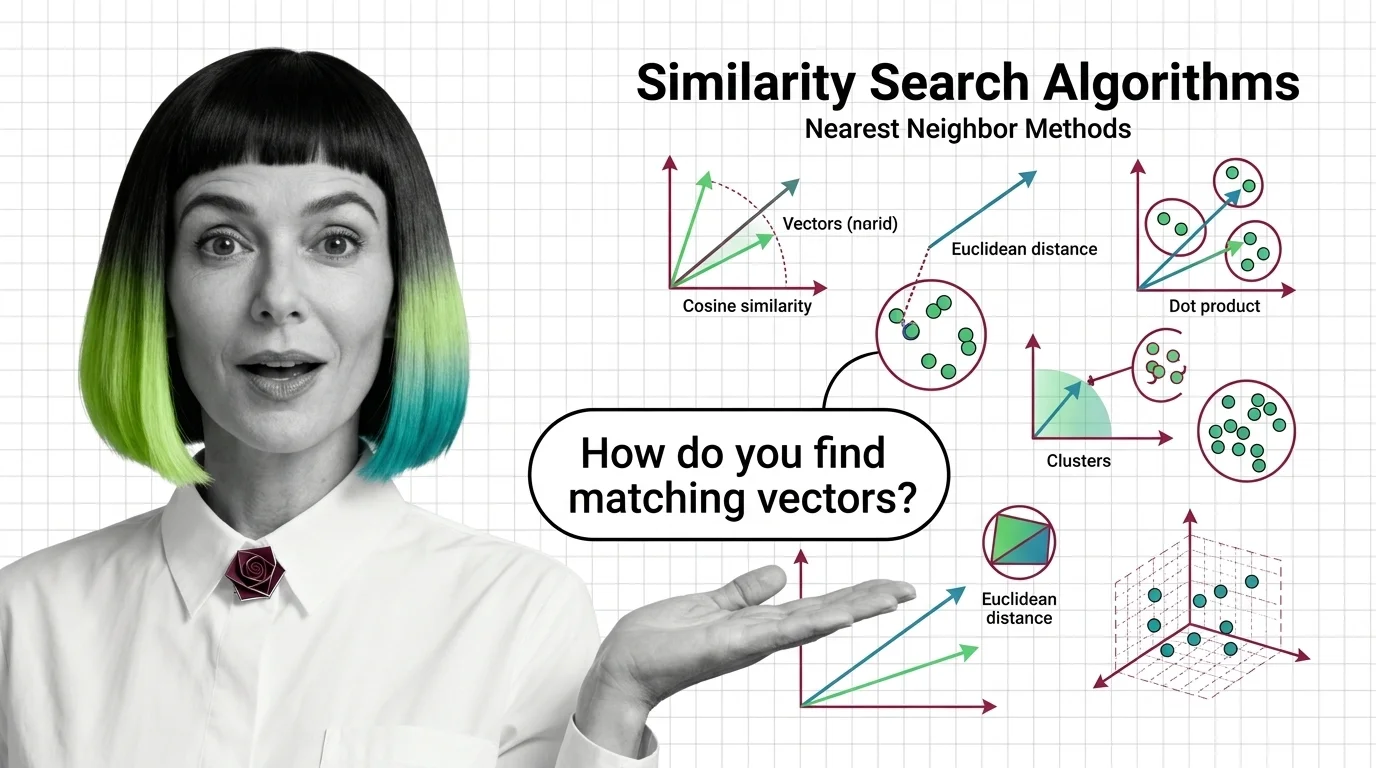
What Are Similarity Search Algorithms and How Nearest Neighbor Methods Find Matching Vectors
Similarity search algorithms find matching vectors by measuring geometric distance, not keywords. Learn how HNSW, PQ, …
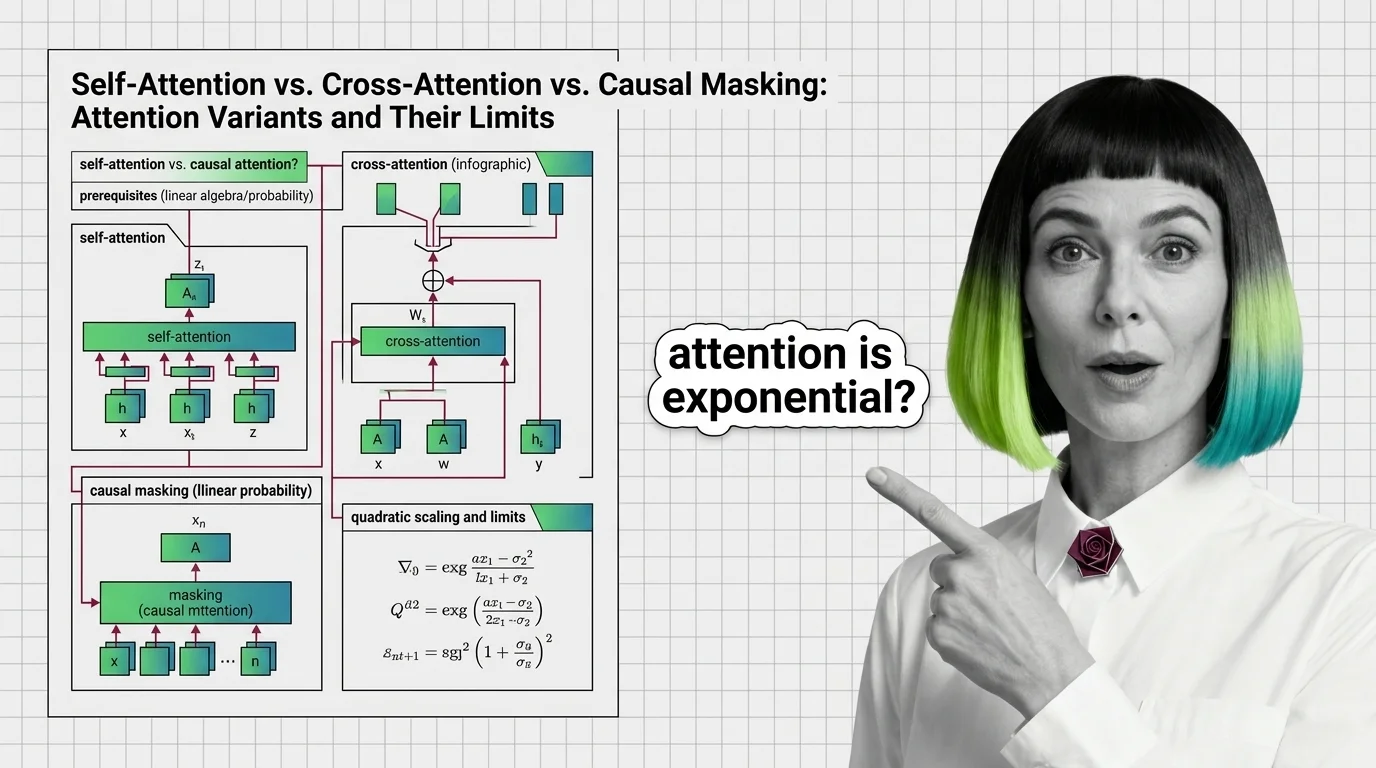
Self-Attention vs. Cross-Attention vs. Causal Masking: Attention Variants and Their Limits
Self-attention, cross-attention, and causal masking solve different problems inside transformers. Learn the math, …
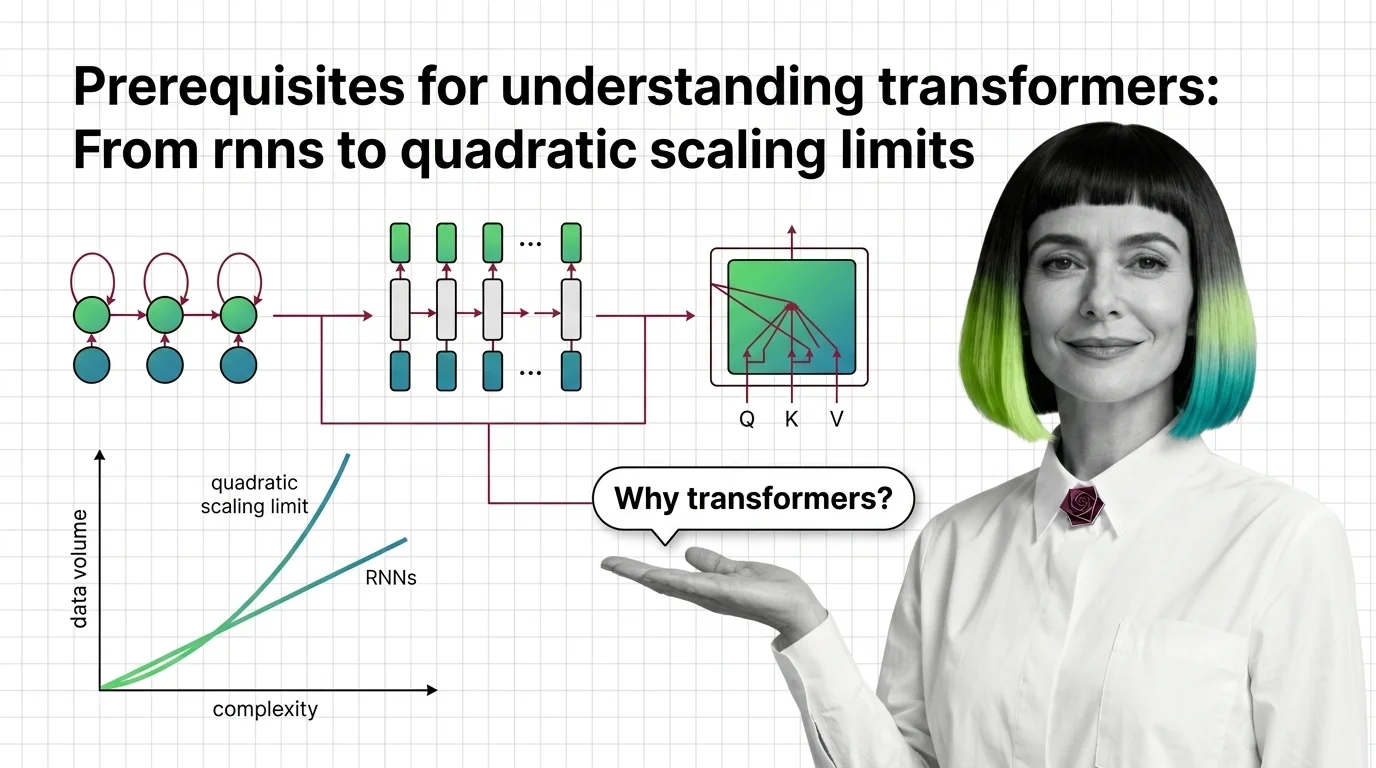
Prerequisites for Understanding Transformers: From RNNs to Quadratic Scaling Limits
Understand why RNNs failed, how transformer self-attention trades parallelism for quadratic cost, and what these …
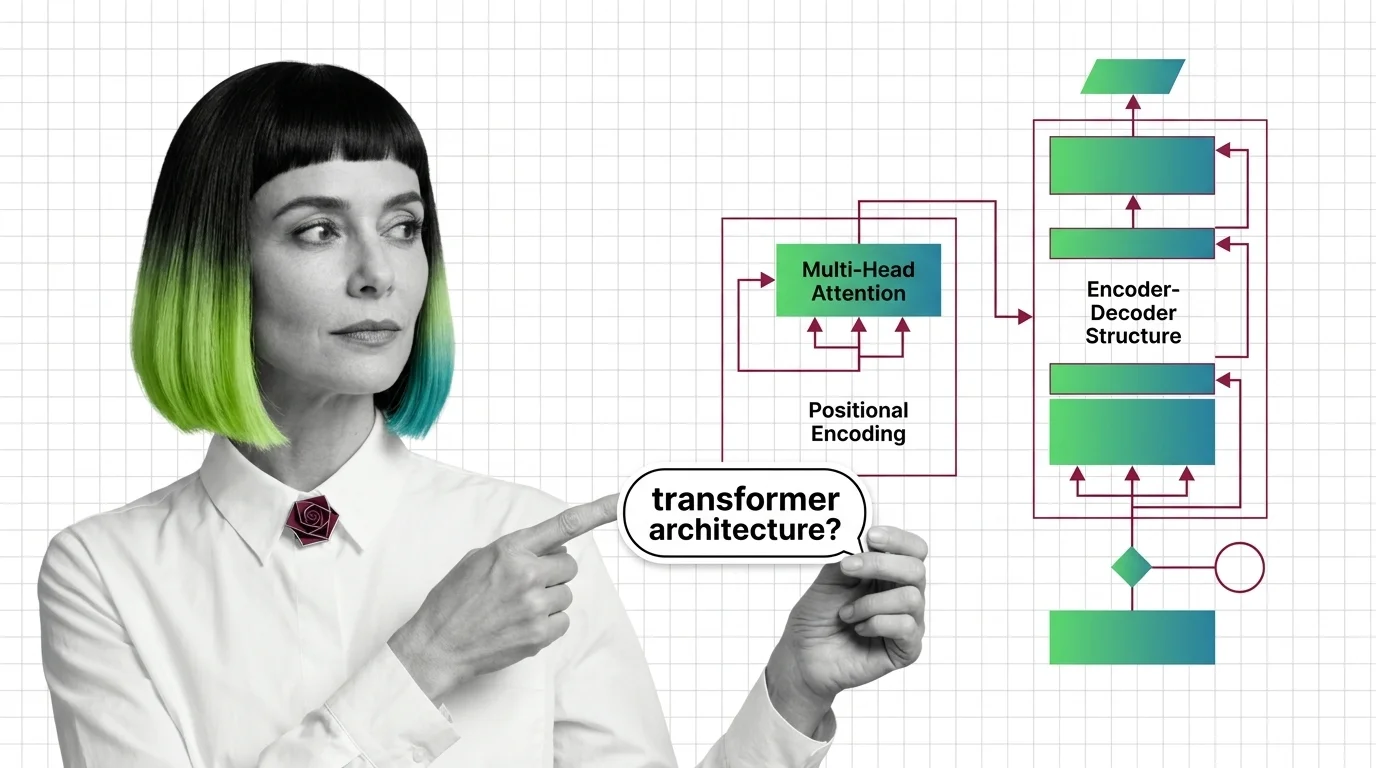
Multi-Head Attention, Positional Encoding, and the Encoder-Decoder Structure Explained
Multi-head attention, positional encoding, and encoder-decoder structure: the three mechanisms inside every transformer, …

Glitch Tokens, Fertility Gaps, and the Unsolved Technical Limits of Subword Tokenization
BPE tokenizers produce glitch tokens and penalize non-Latin scripts with fertility gaps. Learn where the math breaks — …
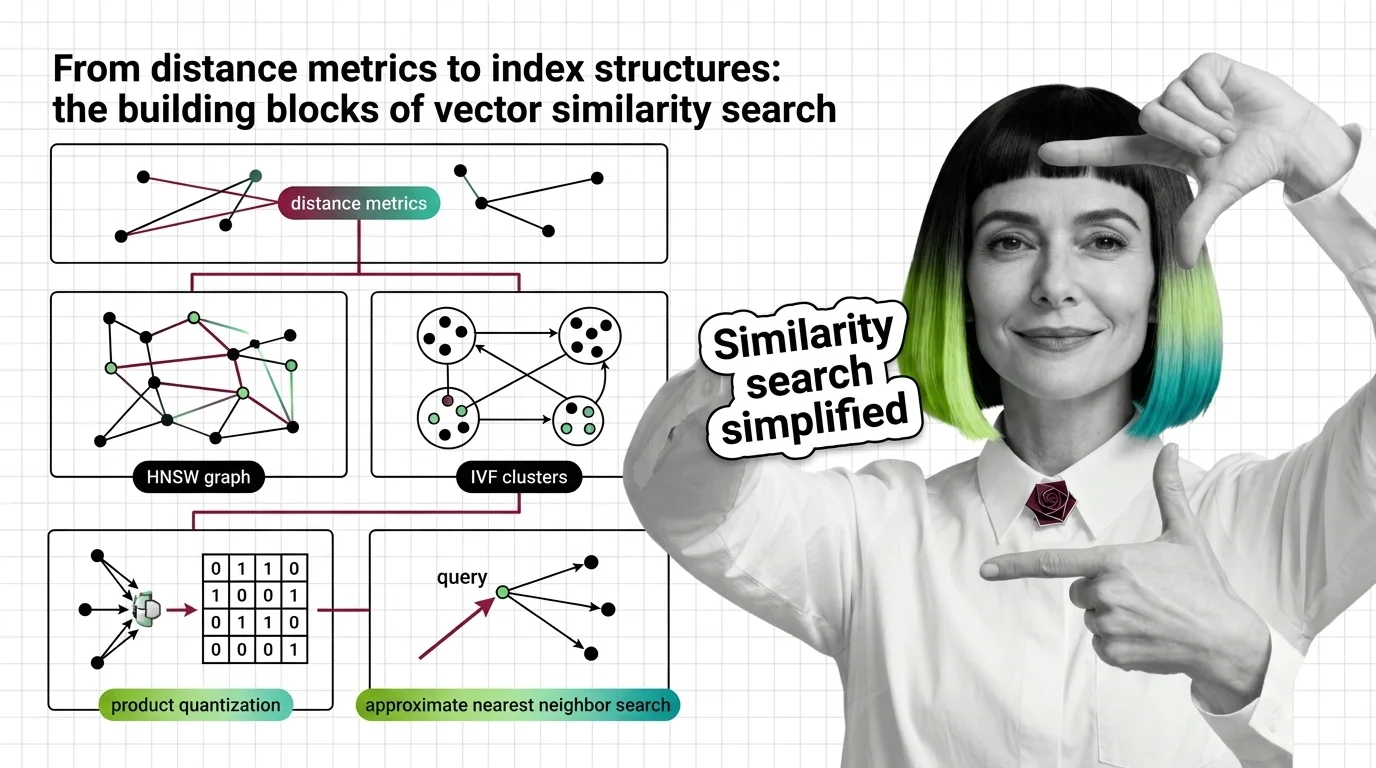
From Distance Metrics to Index Structures: The Building Blocks of Vector Similarity Search
Similarity search combines distance metrics, index structures, and quantization. Learn how HNSW, IVF, LSH, and product …
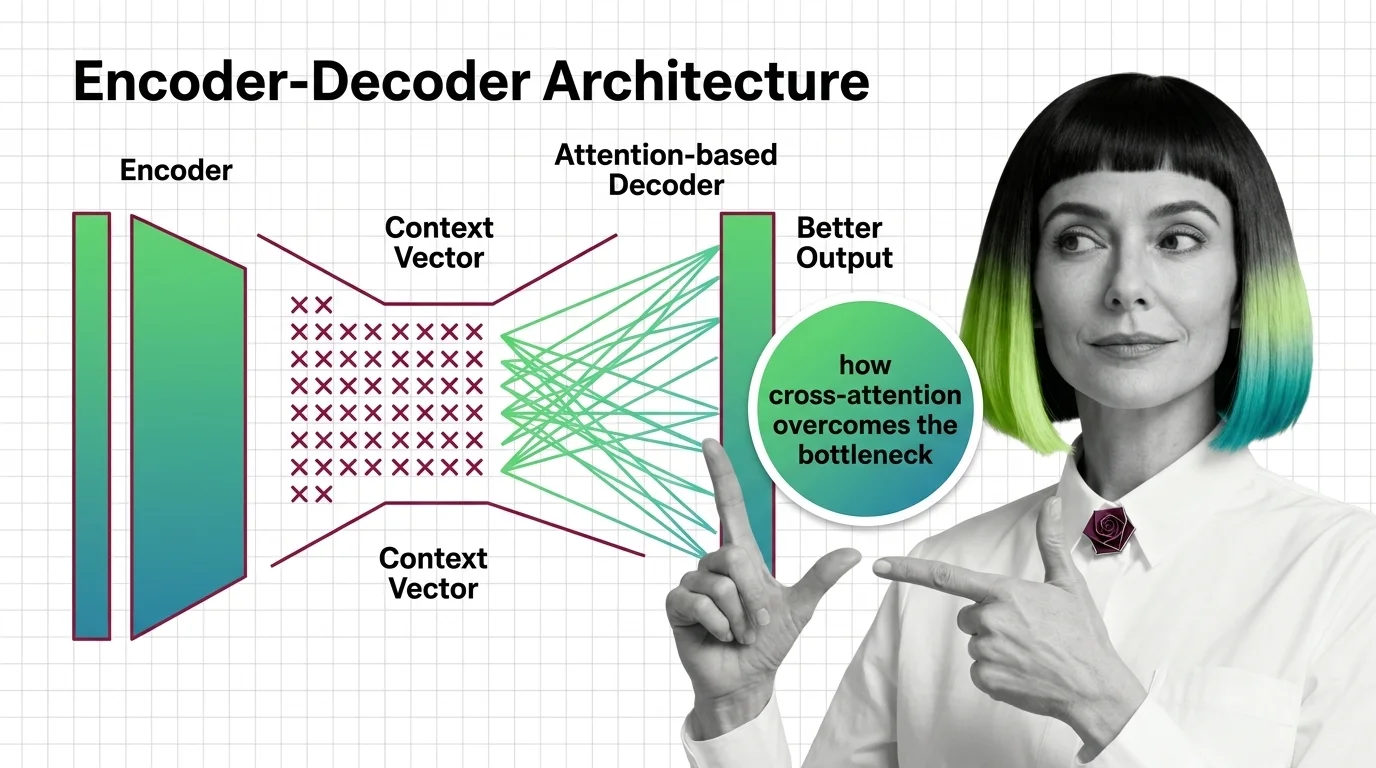
From Context Vectors to Cross-Attention: How Encoder-Decoder Design Overcame the Bottleneck Problem
The encoder-decoder bottleneck crushed long sequences into one vector. Learn how attention replaced compression with …
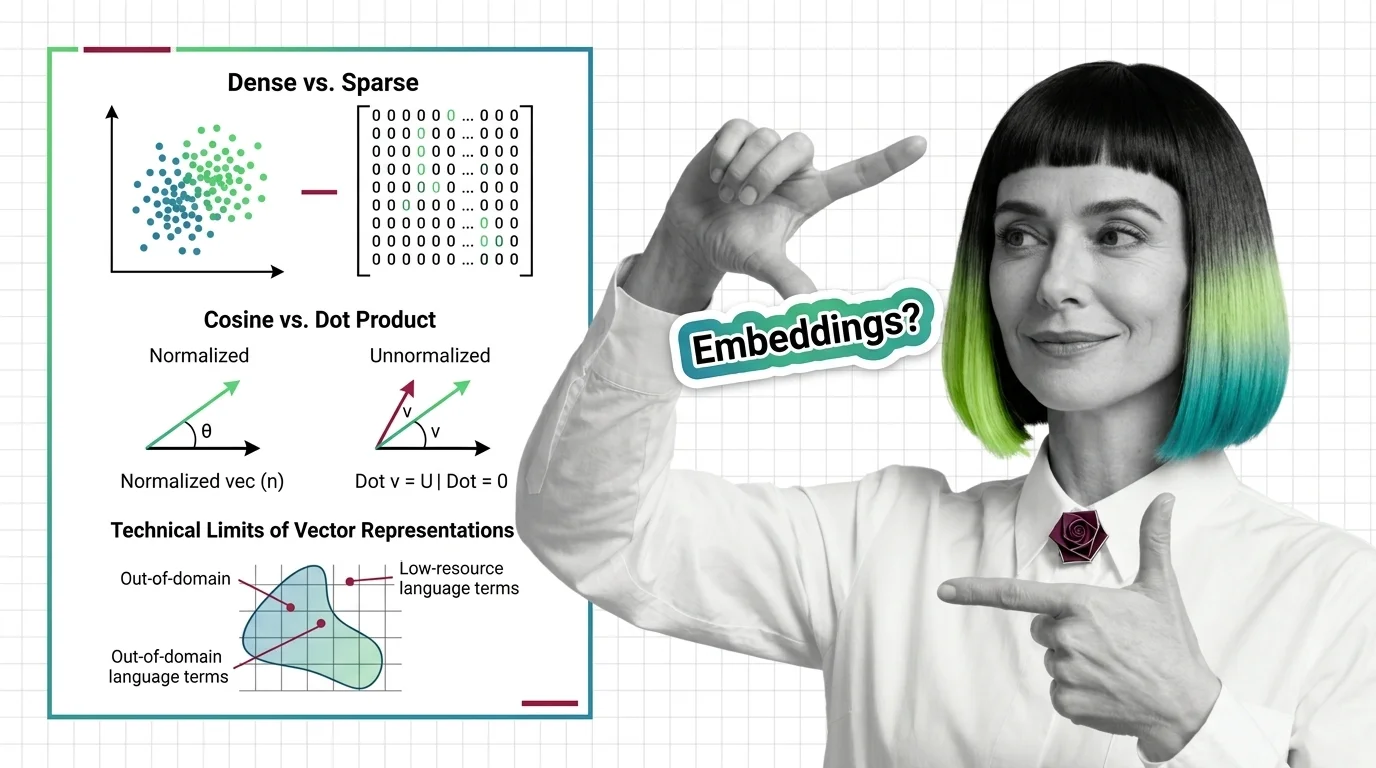
Dense vs. Sparse, Cosine vs. Dot Product, and the Technical Limits of Vector Representations
Dense vs. sparse embeddings encode meaning differently. Learn how cosine similarity, dot product, and Euclidean distance …

Curse of Dimensionality, Recall vs. Speed, and the Hard Limits of Approximate Nearest Neighbor Search
High-dimensional similarity search faces hard mathematical limits. Explore the curse of dimensionality, recall-speed …
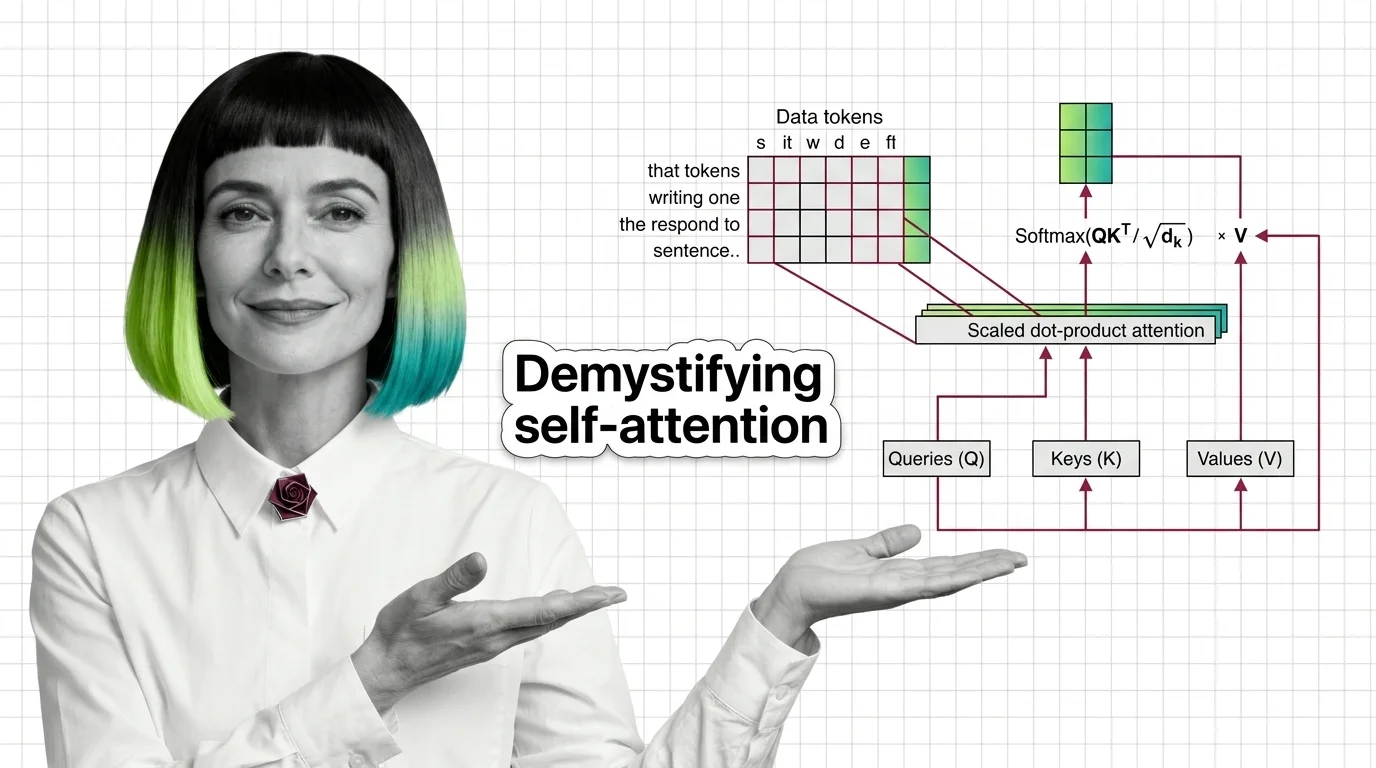
Attention Mechanism Explained: How Queries, Keys, and Values Power Modern AI
Attention mechanisms let neural networks weigh input relevance dynamically. Learn how queries, keys, and values compute …
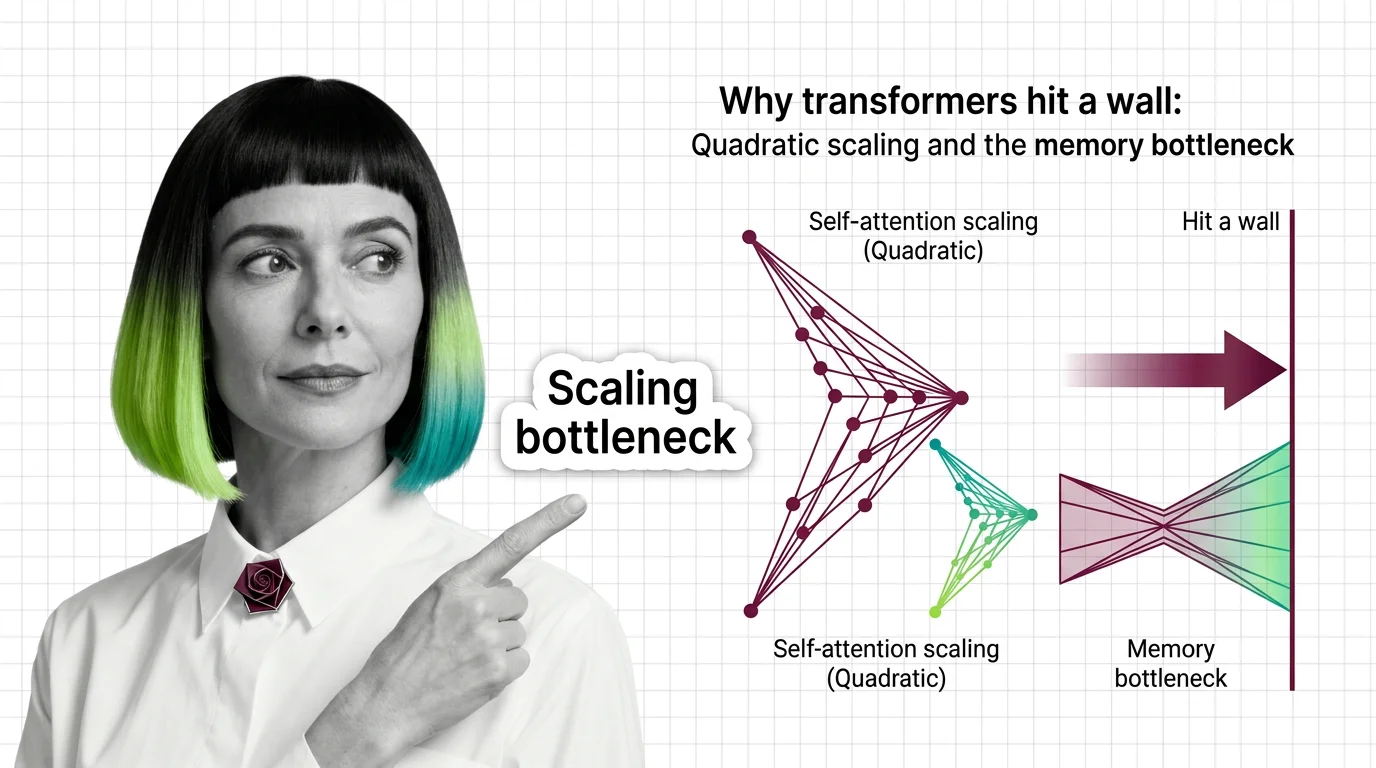
Why Transformers Hit a Wall: Quadratic Scaling and the Memory Bottleneck
Transformer self-attention scales quadratically with sequence length. Understand the O(n²) memory wall, KV cache costs, …
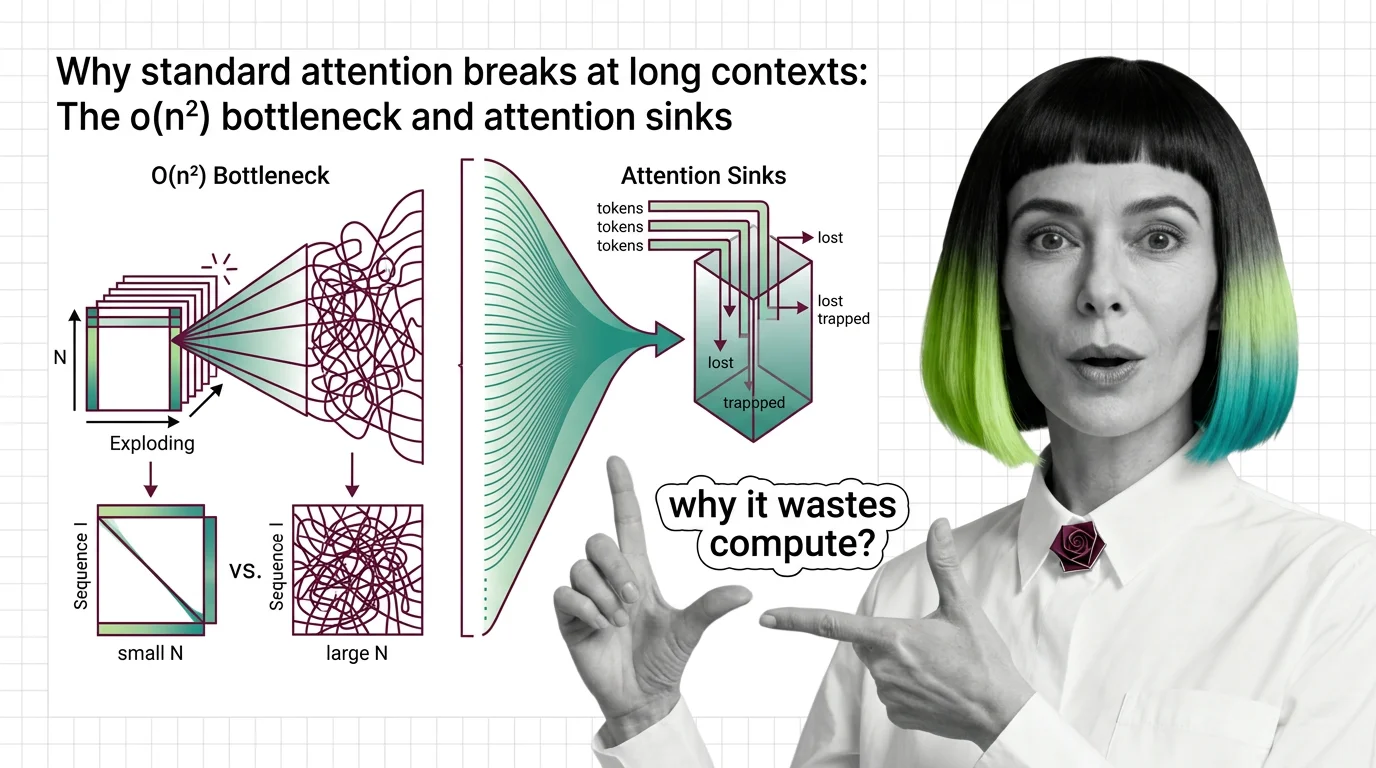
Why Standard Attention Breaks at Long Contexts: The O(n²) Bottleneck and Attention Sinks
Standard attention scales quadratically with sequence length. Learn why O(n²) breaks at long contexts, what attention …
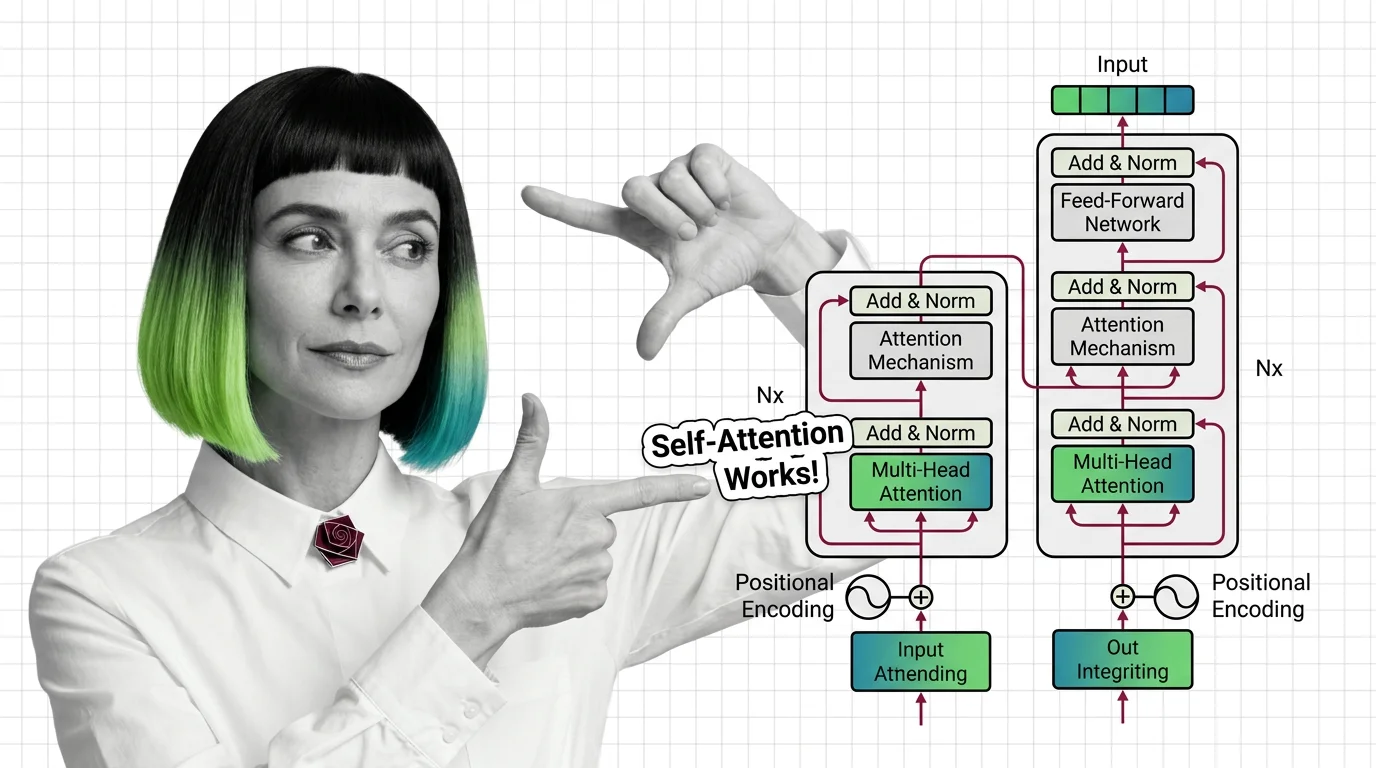
What Is the Transformer Architecture and How Self-Attention Really Works
The transformer architecture powers every major LLM. Learn how self-attention computes token relationships, why …
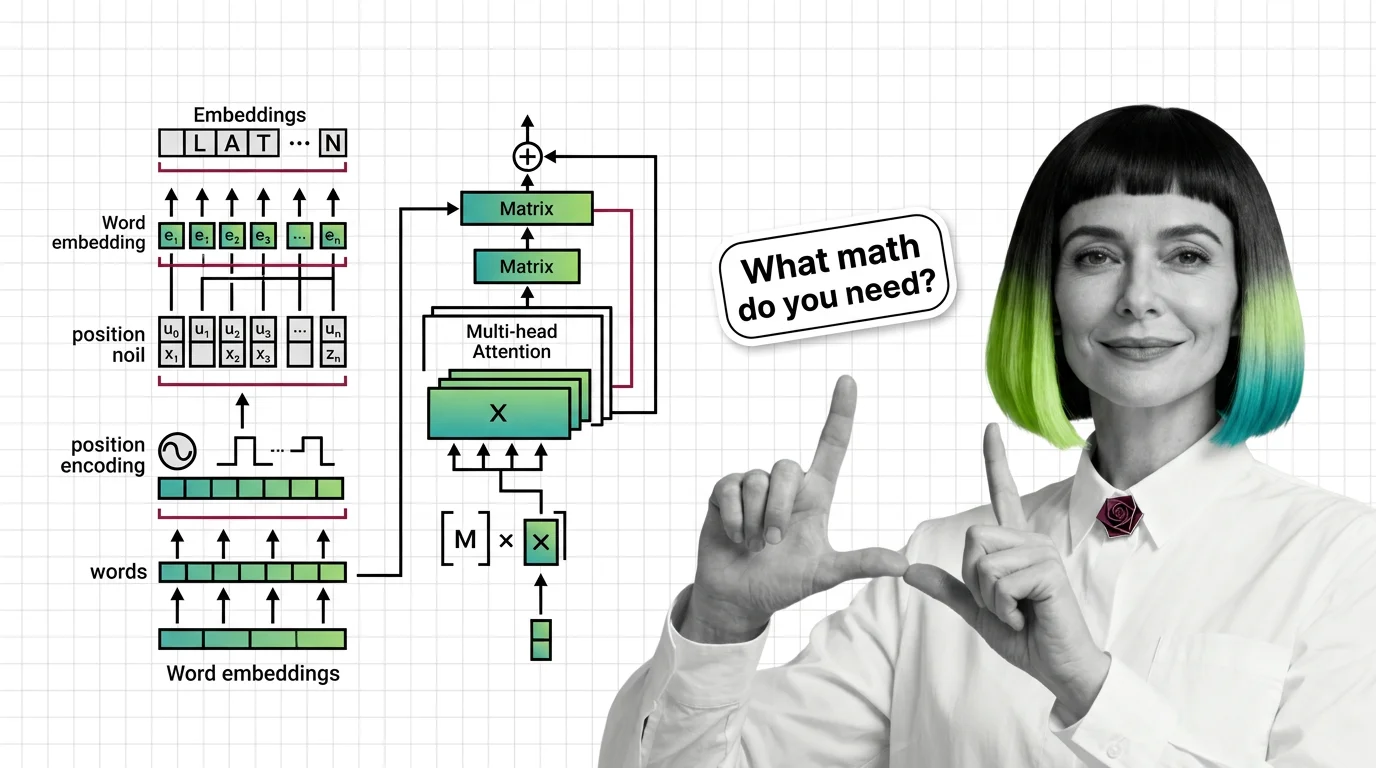
Prerequisites for Understanding Transformers: From Embeddings to Matrix Multiplication
Master the math behind transformers: embeddings, matrix multiplication, positional encoding, and multi-head attention …
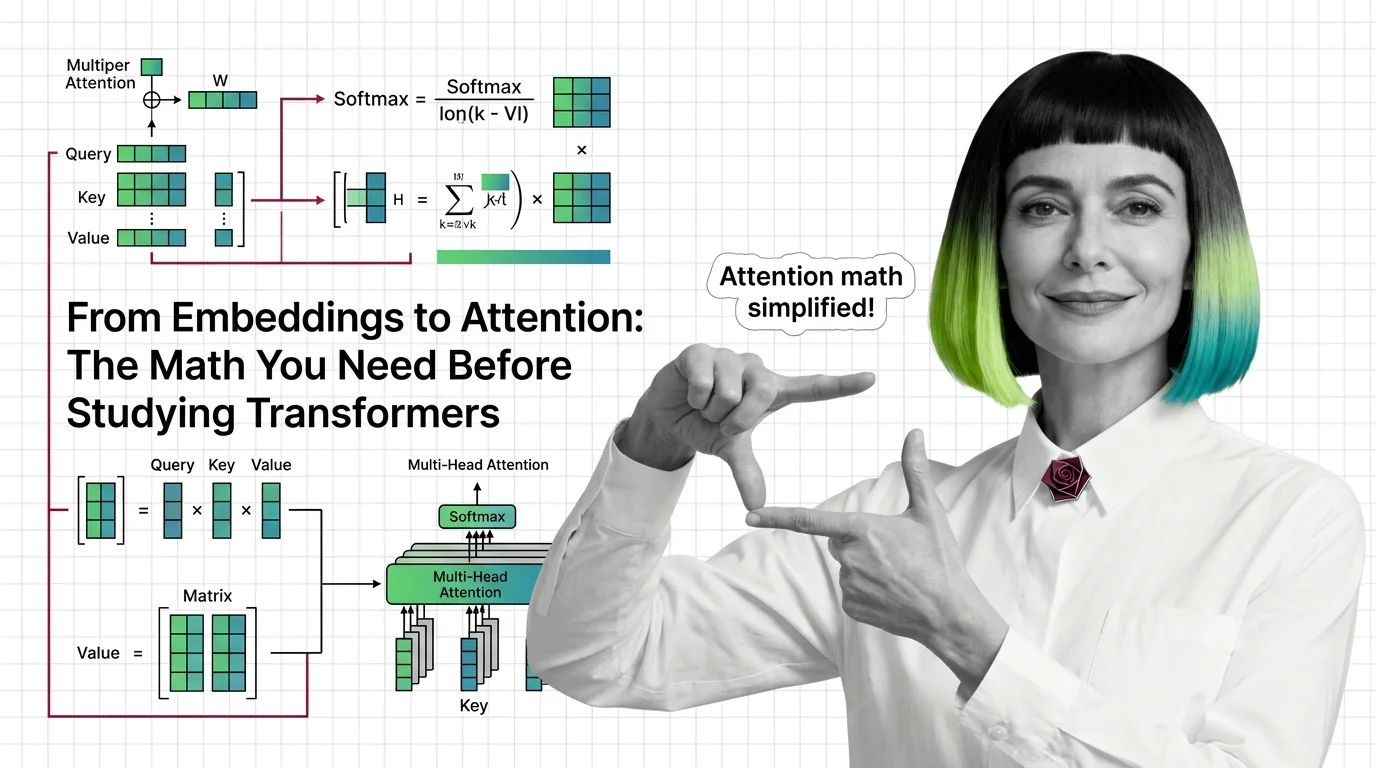
From Embeddings to Attention: The Math You Need Before Studying Transformers
Master the math behind attention mechanisms — dot products, softmax, QKV matrices, and multi-head projections — before …
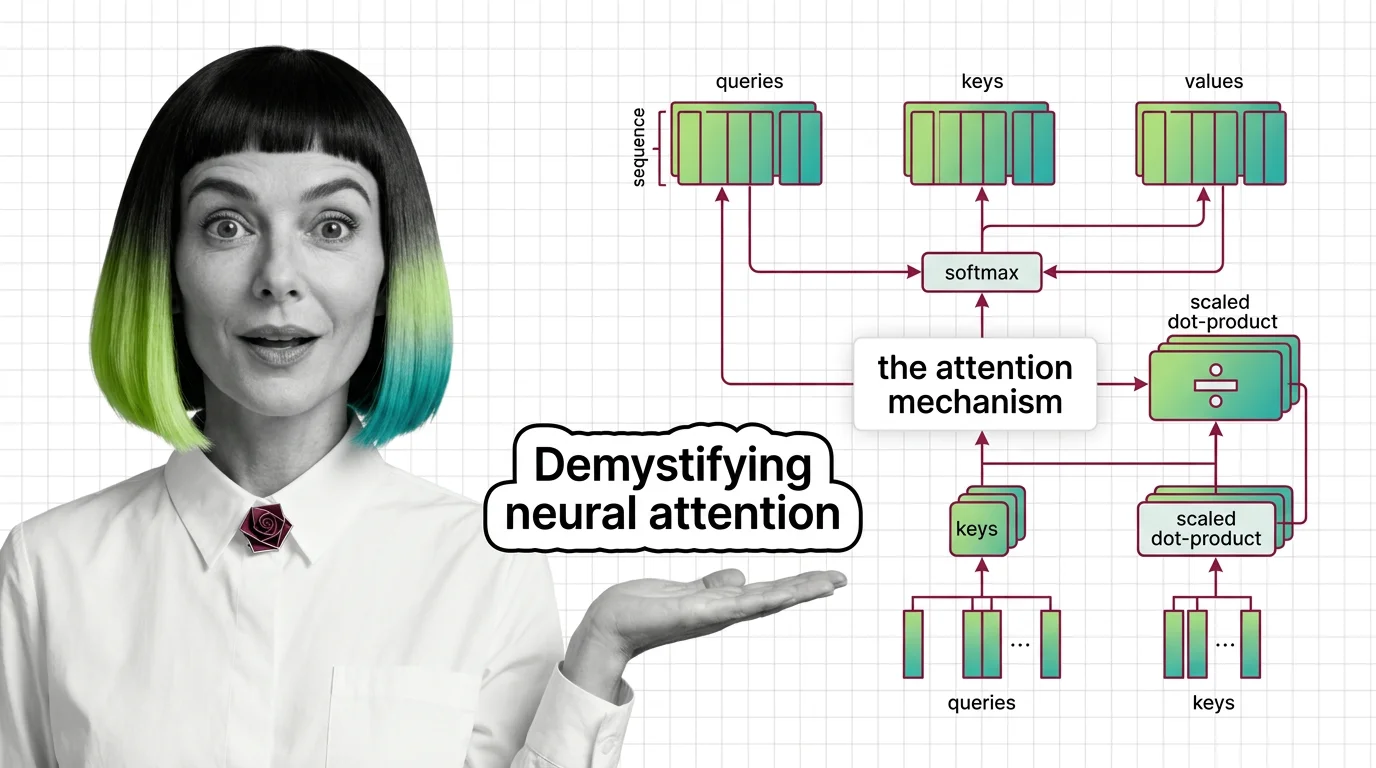
Attention Mechanism: Scaled Dot-Product, Self vs Cross
Transformers use weighted averaging, not human-like focus: scaled dot-product, self-attention vs cross-attention, and …