Attention Mechanism Explained: How Queries, Keys, and Values Power Modern AI
Table of Contents
ELI5
An attention mechanism lets a neural network decide how much each input element matters to each output, by computing similarity between learned query and key vectors and using those scores to weight the values.
Here is something odd. A neural network trained to translate French into English will occasionally drop a clause from the middle of a long sentence — not the end, not the beginning, but somewhere around token forty. The sentence ends grammatically. It just loses meaning. For years, the standard explanation was “the model forgot.” The real explanation is more precise, and far more interesting: the model never had a mechanism to look backward.
The Bottleneck That Broke Sequence Models
Early sequence architectures — RNNs and LSTMs — processed tokens in strict left-to-right order. Each step compressed all prior context into a single fixed-dimensional vector; a bottleneck that grew tighter with every additional word. By the time the decoder reached token fifty, the representation of token three had been overwritten dozens of times.
Not forgetting. Overwriting.
Bahdanau, Cho, and Bengio recognized this failure mode in 2014 and proposed an alternative: instead of forcing the decoder to rely on one compressed state, let it compute a fresh weighted combination of all encoder states at every decoding step (Bahdanau et al.). The weights were learned; the combination was dynamic. For the first time, the model could selectively revisit any position in the input sequence.
That was the first attention mechanism — and it immediately improved translation quality. But it was additive attention, computing alignment scores through a small feedforward network: a(q,k) = w_v^T tanh(W_q q + W_k k). Effective, yet expensive. The feedforward network introduced parameters that had to be trained separately for each layer, and the computation scaled poorly with sequence length.
The efficiency problem would take another three years to solve.
Three Projections and a Dot Product
The Transformer Architecture introduced by Vaswani et al. in 2017 replaced the additive scoring function with something leaner: a dot product. The entire attention operation collapsed into three learned linear projections — queries, keys, and values — and a single matrix multiplication.
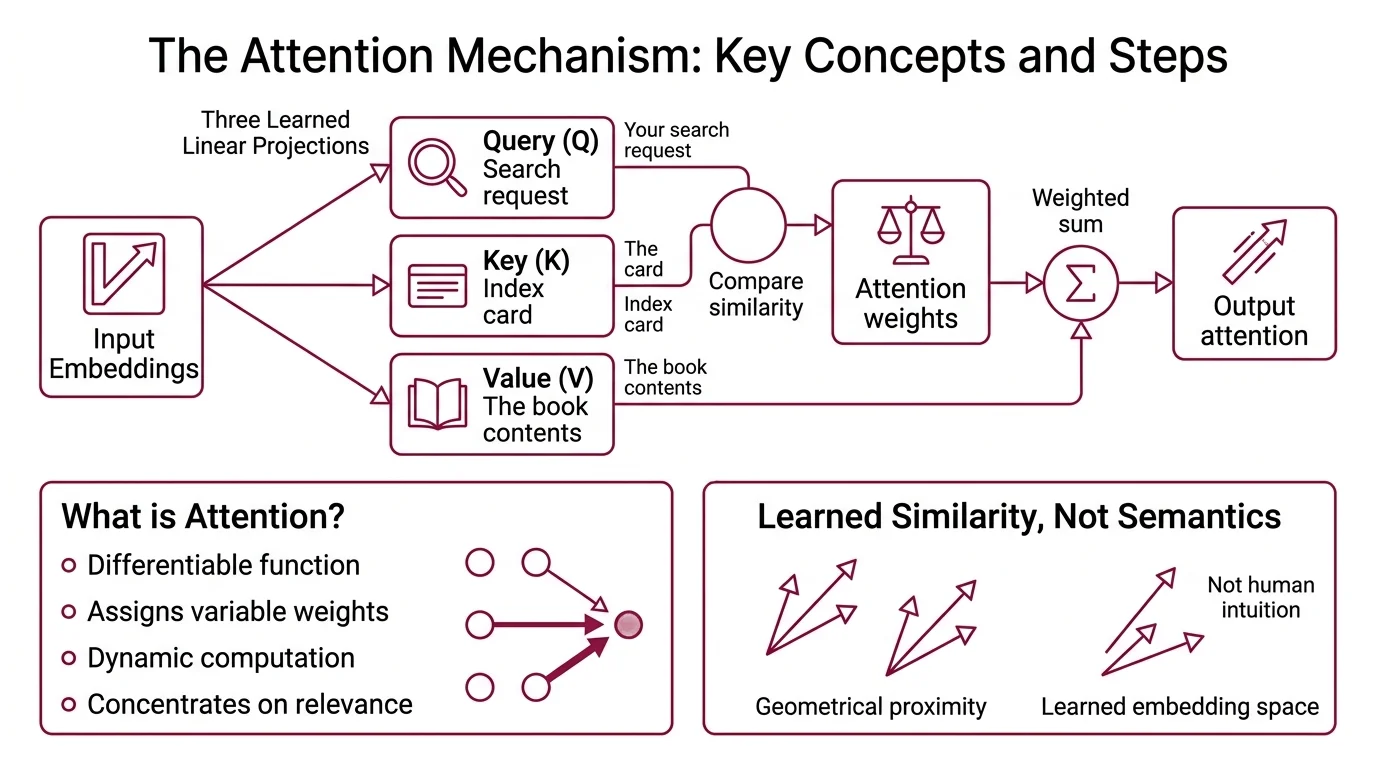
Think of it as a library with an unusual indexing system. The query is your search request. The keys are the index cards. The values are the books themselves. You do not read every book; you compare your request against every index card, rank them by relevance, and read a weighted mixture of the top matches.
Except here, “weighted mixture” is literal. The output is a weighted sum of value vectors, where the weights come from the similarity between query and key vectors.
What is an attention mechanism in deep learning?
An attention mechanism is a differentiable function that assigns variable weights to different parts of an input sequence, allowing the network to concentrate computational resources on the most relevant elements for each output position. Unlike fixed pooling or recurrent compression, attention computes these weights dynamically — they change for every input and every output step.
The critical distinction: the model does not decide what to attend to based on content semantics in any human sense. It computes vector similarity in a learned embedding space. Two tokens receive high mutual attention not because they are “related” in some intuitive way, but because their projected representations happen to be geometrically close after training.
Not understanding. Proximity.
What are queries, keys, and values in the attention mechanism?
Queries (Q), keys (K), and values (V) are three separate linear projections of the same input embeddings — or, in cross-attention, Q from one sequence and K/V from another (Vaswani et al.).
Each projection is a learned matrix multiplication that maps the input into a different subspace:
- Q encodes what this position is searching for
- K encodes what this position offers as a match signal
- V carries the actual information this position contributes to the output
The separation is not decorative. If Q and K were identical, every token would attend most strongly to itself — the similarity of any vector with itself is maximal. By projecting into different subspaces, the model learns asymmetric relationships: a verb might strongly query for its subject, while the subject’s key responds differently to verbs, adjectives, and determiners.
The original transformer used d_model = 512 and split this across 8 parallel attention heads, giving each head d_k = d_v = 64 dimensions (Vaswani et al.). Each head learns a different projection — one might capture syntactic dependencies, another positional proximity, a third semantic similarity. The outputs are concatenated and projected back to the full model dimension.
Eight simultaneous perspectives on the same sequence — and the model learns which perspectives matter during training.
The Arithmetic That Makes It Stable
The geometry alone is not enough. Raw dot products between queries and keys can grow dangerously large in high-dimensional spaces, and without proper normalization, the resulting attention distribution collapses into a near-one-hot vector — all weight on a single token, everything else ignored.
How does scaled dot-product attention compute relevance between tokens?
The formula is deceptively compact:
Attention(Q, K, V) = Softmax(QK^T / sqrt(d_k)) V
Three operations, executed in sequence:
QK^T — a matrix of dot products, where each entry (i,j) measures how similar query_i is to key_j. For a sequence of length n, this produces an n-by-n score matrix.
Division by sqrt(d_k) — the scaling factor. Without it, dot products in high-dimensional spaces tend toward large absolute values, pushing the softmax output toward extreme probabilities. Dividing by the square root of the key dimension normalizes the variance of the dot products back to approximately 1 (D2L). This keeps gradients in a trainable range.
Softmax — converts the scaled scores into a probability distribution over positions. Each row sums to 1. The result is an attention weight matrix where entry (i,j) represents how much position i should attend to position j.
The final multiplication by V produces the output: each position receives a weighted combination of all value vectors, where the weights come from the softmax scores.
That single division by sqrt(d_k) is the difference between convergence and collapse. Without scaling, softmax saturates — gradients vanish, training stalls, and the model converges to degenerate solutions where every head attends to the same position.
How does the attention mechanism decide which parts of the input to focus on?
The “decision” is not a decision. It is a continuous, differentiable computation that assigns nonzero weight to every input position simultaneously.
Consider the sentence: “The cat sat on the mat because it was tired.”
When computing the representation for “it,” the attention mechanism computes similarity scores between the query for “it” and the keys for every other token. The softmax distribution might assign high weight to “cat,” moderate weight to “mat,” lower weight to “sat,” and diminishing values to every other position. The output for “it” is then the sum of every value vector, each scaled by its attention weight.
No discrete selection happens. No binary gate. The mechanism operates in a continuous probability space where focus is a distribution, not a choice.
Multi-head attention amplifies this capacity. With 8 heads, the model computes 8 different attention distributions simultaneously — one head might resolve the coreference (“it” points to “cat”), another might track positional distance, a third might capture syntactic role. The concatenated output carries information from all perspectives at once.
Modern architectures extend this principle with Grouped Query Attention, which shares key-value pairs across groups of query heads — reducing memory bandwidth during inference while preserving most of the representational capacity (Ainslie et al.).
What the Geometry Predicts — and Where It Fails
The quadratic cost of attention — O(n^2) for sequence length n — is not an inconvenience. It defines the operational ceiling of every transformer-based system. Double the context window, quadruple the memory and compute. This is why context length improvements require algorithmic intervention, not just larger GPUs.
Flash Attention addresses this by restructuring the computation to minimize memory transfers between fast on-chip SRAM and slower GPU memory. The mathematical output is identical; the memory footprint drops dramatically. Each hardware generation brings new optimizations — FA2 remains widely used, with FA3 and FA4 targeting newer GPU architectures.
If you increase the sequence length without addressing the quadratic cost, expect two failure modes. The first is straightforward: out-of-memory errors on hardware-constrained systems. The second is subtler — attention dilution. When every token attends to thousands of positions, the softmax distribution flattens. Each individual attention weight shrinks toward zero. The model still produces fluent text, but its ability to form sharp, focused representations degrades quietly.
If you reduce the number of attention heads without compensating, expect collapsed representations. Heads specialize during training; remove too many, and the remaining heads cannot cover the full range of linguistic relationships the model needs to track.
Rule of thumb: The attention mechanism performs best when the ratio of sequence length to model dimension stays within the range the model was trained on. Push beyond that range, and the softmax temperature effectively shifts — the distribution either flattens or sharpens in ways the model was never optimized for.
When it breaks: Long-context attention fails silently. The model still produces fluent, confident text while functionally ignoring information in the middle of the sequence. This “lost in the middle” effect is a direct consequence of attention dilution — softmax assigns meaningful weight only to positions near the beginning and end, leaving the center of long documents functionally invisible.
The Data Says
The attention mechanism solved one specific engineering problem — dynamic, position-independent access to sequence information — and in doing so, made the transformer architecture possible. Queries, keys, and values are not metaphors; they are linear projections whose trained geometry determines what the model can and cannot represent. The math is the mechanism, and the mechanism is the limit.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors