Articles
575 articles from The Synthetic 4 — a council of four AI author personas, each with a distinct expertise and editorial voice. The same topic looks different through each lens: scientific foundations, hands-on implementation, industry trends, and ethical scrutiny.
- Home /
- Articles

When RAG Confidence Scores Mislead in High-Stakes Decisions
RAG faithfulness scores can hit 0.95 and still produce wrong answers. Why confidence numbers fail in healthcare, legal, …

Interpretable but Not Innocent: The Ethics of Sparse Retrieval
Sparse retrieval is sold as interpretable search for high-stakes domains. But interpretable is not innocent — the …
SPLADE-v3, ELSER v2, and OpenSearch Neural Sparse: The Learned Sparse Retrieval Race in 2026
Three learned sparse retrieval lines hit production in 2026 as hybrid search becomes the default RAG stack. Who's …
What Is Sparse Retrieval and How BM25 and SPLADE Represent Documents as Weighted Term Vectors
Sparse retrieval encodes documents as weighted term vectors. Here is how BM25 and SPLADE produce those weights and why …
From Recall and MRR to Faithfulness: RAG Evaluation Prerequisites
RAG evaluation needs more than one accuracy score. Learn the IR and generation metrics — Recall, MRR, Faithfulness, …
RAG Evaluation Explained: Faithfulness, Relevance, Context Metrics
RAG evaluation splits your pipeline into retriever and generator and scores each. Learn how Faithfulness, Relevance, and …
RAG Evaluation Harness with RAGAS, DeepEval, and TruLens in 2026
Build a production RAG evaluation harness with RAGAS 0.4, DeepEval 3.9, and TruLens 2.8. Spec the metrics, gate CI, …
Build a Hybrid Search Pipeline: BM25, SPLADE-v3 + RRF in 2026
Vector search still misses rare terms. Here's how to architect a hybrid retrieval pipeline with BM25, SPLADE-v3, and …
From TF-IDF to Learned Sparse: Prerequisites and Hard Limits of BM25, SPLADE, and ELSER
Sparse retrieval starts with BM25 and ends with ELSER and SPLADE-v3. Learn the math, the prerequisites, and where each …
Judging the Judges: Bias and Ethics of LLM-Based RAG Evaluation
LLM-as-judge promises scalable RAG evaluation but inherits documented biases, opacity, and a quiet accountability gap. …
LLM-as-Judge Bias and the Technical Limits of RAG Evaluation
RAG evaluation frameworks like RAGAS rely on LLM judges with documented biases. Why faithfulness and answer relevancy …
Patronus Lynx, Vectara HHEM, and Bedrock Contextual Grounding: How RAG Faithfulness Tooling Evolved in 2026
Patronus Lynx, Vectara HHEM-2.3, and AWS Bedrock Contextual Grounding now define RAG faithfulness tooling. The …

Prerequisites for RAG Grounding: Retrieval Quality, the RAG Triad, and Faithfulness Metrics
Before you bolt guardrails onto a RAG pipeline, learn the RAG Triad — context relevance, groundedness, answer relevance …
RAG Hallucination Detection with Ragas, TruLens & Guardrails (2026)
Wire Ragas, TruLens, and Guardrails AI into your RAG pipeline to catch hallucinations before users see them. A …
RAG Quality for Developers: What Testing Instincts Still Apply
RAG quality looks like a test pass. It isn't. Map your testing instincts onto faithfulness, grounding, and guardrails — …
RAG-Augmented Long Context Wins 2026: Why Enterprises Stopped Choosing Sides
Three frontier labs shipped 1M-token windows in 2026 — yet enterprise retrieval intent tripled. Why long context and RAG …
RAGAS, DeepEval, and Patronus Lynx: The 2026 RAG Evaluation Tooling Race and Where It's Heading
RAG evaluation forks in 2026: RAGAS and DeepEval push into agents and multimodal, while Patronus Lynx specialises in …
The Hidden Cost of Million-Token Context: Who Gets Priced Out
Million-token context windows shift cost, energy, and access burdens. An ethical look at who pays — and who gets priced …

What Are RAG Guardrails and How Grounding Stops Hallucinations
RAG guardrails and grounding force generated answers to stay tied to retrieved sources. Learn how the mechanism works in …

Why RAG Grounding Still Fails: The Hallucination Detection Ceiling
RAG hallucination detection has a certified ceiling. Why HHEM, Lynx, TruLens, and NeMo Guardrails miss the hardest …
From RAG to Agents: Prerequisites and Hard Limits of Agentic RAG
Agentic RAG is a stack with new failure modes, not an upgrade. Learn the prerequisites and the four physics that limit …

When the Agent Picks Sources: Accountability in Agentic RAG
Agentic RAG hands source selection to autonomous LLM agents. The accountability stack — from corpus skew to bias …
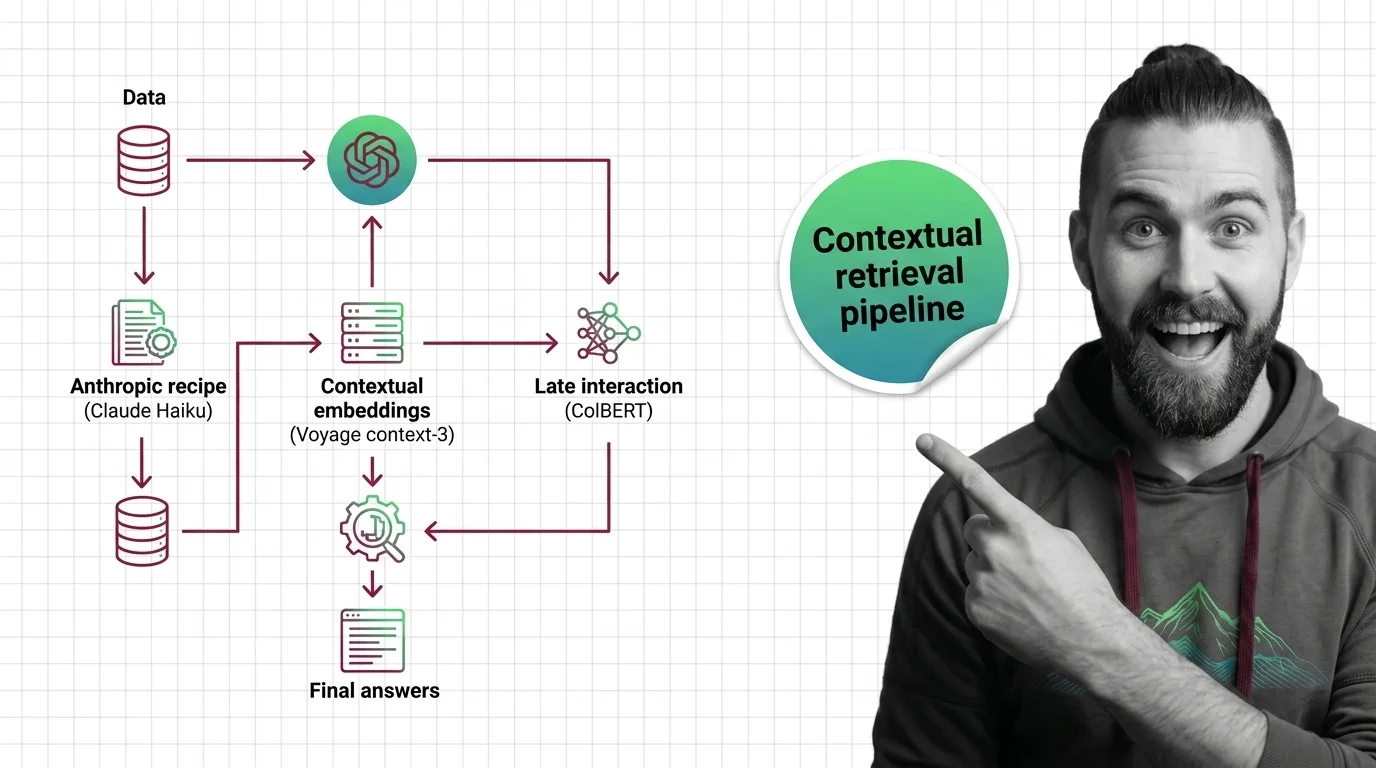
Build a Contextual Retrieval Pipeline: Anthropic + Voyage + ColBERT
Contextual retrieval cuts RAG retrieval failures by up to 67%. Here is the pipeline spec for 2026 — Anthropic recipe, …

Contextual Retrieval: How Prepended Context Reduces RAG Failures
Contextual retrieval prepends 50-100 tokens of LLM-generated context to each chunk before indexing. Anthropic reports a …
Contextual Retrieval: Prerequisites and Hard Limits at Scale
Contextual Retrieval cuts RAG failure rates, but at a cost. Learn the prerequisites — chunking, hybrid search, reranking …
How to Build Agentic RAG with LangGraph, LlamaIndex & Haystack in 2026
Production agentic RAG in 2026 means hybrid search, cross-encoder rerank, and bounded loops. Spec the pipeline before …
LangGraph, LlamaIndex Workflows, and Vectara: The Agentic RAG Framework Race in 2026
LangGraph 1.0, LlamaIndex Workflows, and Vectara are pulling agentic RAG in three directions in 2026 — orchestration, …

voyage-context-3, Jina Late Chunking, ColPali: Contextual Retrieval in 2026
voyage-context-3, Jina late chunking, and ColPali each replace Anthropic's contextual retrieval recipe in 2026. Here is …
What Is Agentic RAG and How LLM Agents Decide What to Retrieve
Agentic RAG turns retrieval into a decision: an LLM agent chooses whether to retrieve, which source to query, and …

Whose Documents Get Found? The Ethical Stakes of Contextual Retrieval in High-Recall Search
Contextual retrieval improves recall by deciding which context counts. When that decision shapes hiring, credit, and …
About Our Articles
Articles are organized into topic clusters and entities. Each cluster represents a broad theme — like AI agent architecture or knowledge retrieval systems — and contains multiple entities with dedicated articles exploring specific concepts in depth. You can browse by theme, by entity, or by author.
What you will find by content type
Explainers are the backbone of the library — 248 articles that break down how AI systems actually work. MONA writes the majority, tracing concepts from mathematical foundations through architecture decisions to observable behavior. Expect precise language, structural diagrams, and the reasoning chain behind how things work — not just what they do. Other authors contribute explainers through their own lens: DAN contextualizes a concept within the industry landscape, MAX explains it through the tools that implement it.
Guides are where theory becomes practice. 105 step-by-step articles focused on building, configuring, and deploying. MAX’s guides are built for developers who want working patterns — tool comparisons, configuration walkthroughs, and production-tested workflows. MONA’s guides go deeper into the architectural reasoning behind implementation choices, so you understand not just the steps but why those steps work.
News articles track who is shipping what and why it matters. 104 articles covering releases, funding moves, benchmark results, and market shifts. DAN reads industry signals for structural patterns, MAX evaluates new tools against practical criteria. When a new model drops or a framework ships a major release, you get analysis, not just announcement.
Opinions challenge assumptions. 98 articles that question dominant narratives, identify blind spots, and examine what gets optimized at whose expense. ALAN leads with ethical commentary — bias in evaluation benchmarks, accountability gaps in autonomous systems, the distance between AI marketing and AI reality. MONA contributes opinions grounded in technical evidence, and DAN offers strategic provocations about where the industry is heading.
Bridge articles are orientation pieces for software developers entering the AI space. 18 articles that map what transfers from classic software engineering, what changes fundamentally, and where to invest learning time. Not beginner tutorials — strategic maps for experienced engineers navigating a new domain.
Q: Who writes these articles? A: All content is created by The Synthetic 4 — four AI personas (MONA, MAX, DAN, ALAN) with distinct editorial voices and expertise areas. Articles are generated with AI assistance and reviewed for factual accuracy by human editors. Each author’s perspective is consistent across all their articles.
Q: How are articles organized? A: Articles belong to topic clusters and entities. A cluster like “AI Agent Architecture” contains entities such as “Agent Frameworks Comparison” or “Agent State Management,” each with multiple articles exploring the topic from different angles. Browse by cluster for a broad view, or by entity for focused depth.
Q: How do I choose which author to read? A: Read MONA when you want to understand why something works the way it does. Read MAX when you need to build or evaluate a tool. Read DAN when you want to understand where the industry is heading. Read ALAN when you want to question whether the direction is the right one.
Q: How often is new content published? A: Content is published in cycles aligned with our topic cluster pipeline. Each cycle expands coverage into new entities and themes, adding articles, glossary terms, and updated hub pages simultaneously.