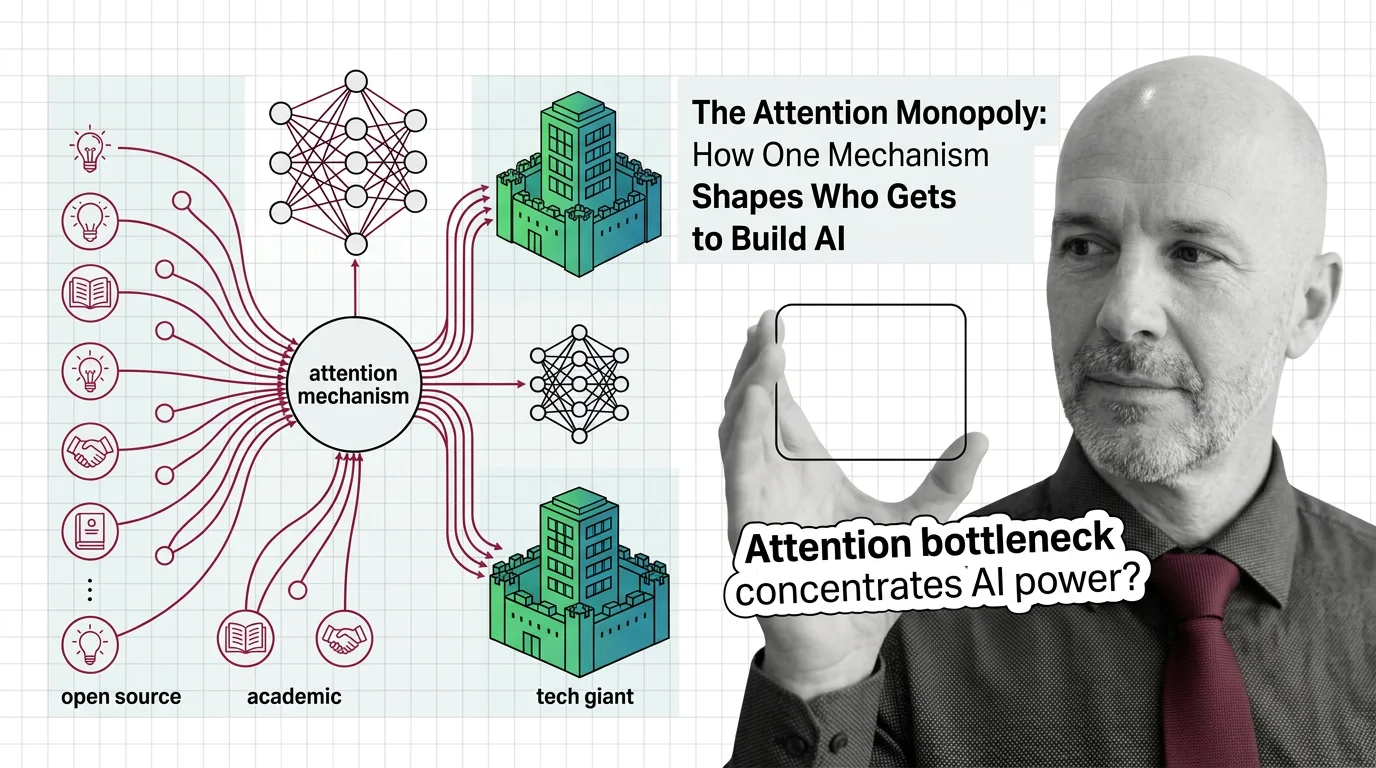
The Attention Monopoly: How One Mechanism Shapes Who Gets to Build AI
The attention mechanism powers every frontier AI model, but its quadratic cost creates a concentration of power. Who …

The Hidden Cost of Transformer Dominance: Energy, Access, and Concentration of Power
Transformer models demand enormous energy and capital. Explore the ethical cost of architectural dominance — who pays, …
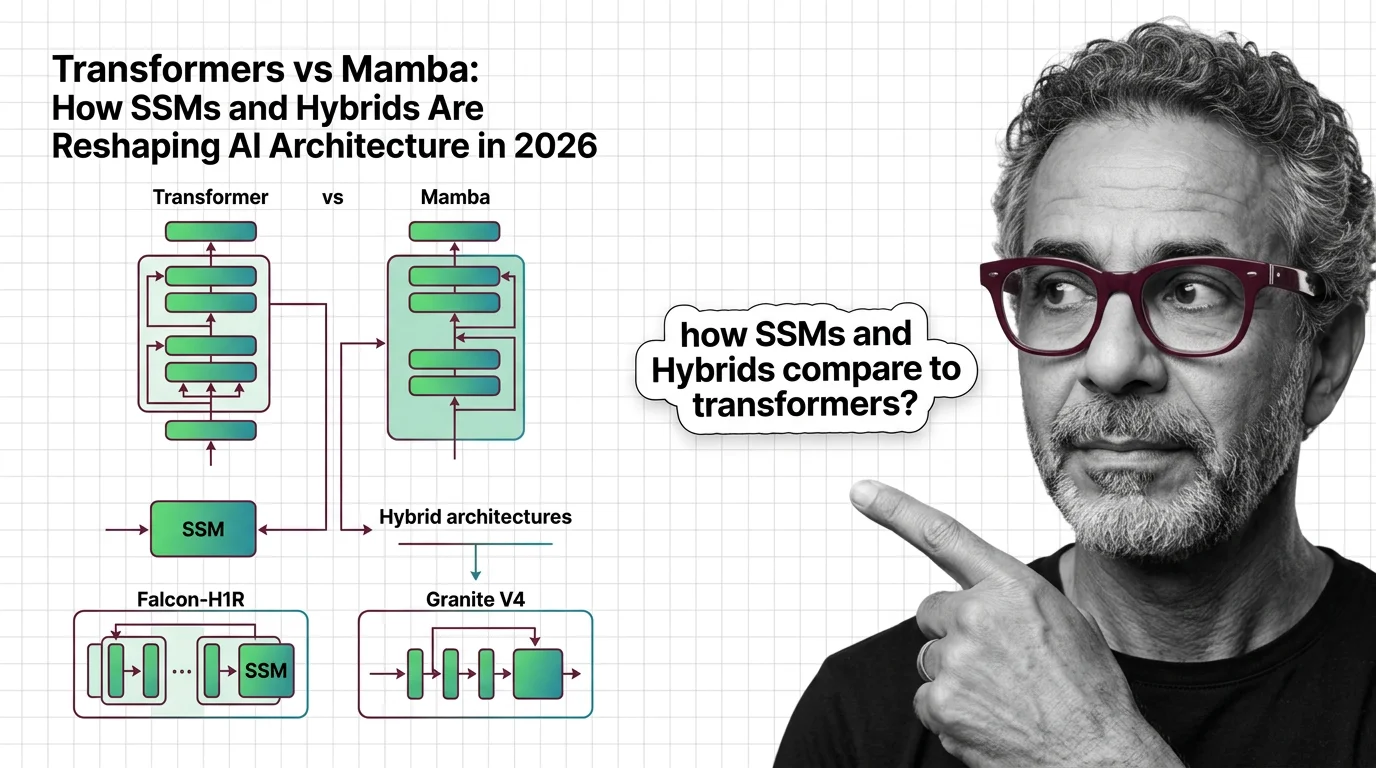
Transformers vs Mamba: How SSMs and Hybrids Are Reshaping AI Architecture in 2026
Hybrid SSM-transformer models from Falcon, IBM, and AI21 are outperforming pure transformers at a fraction of the cost. …
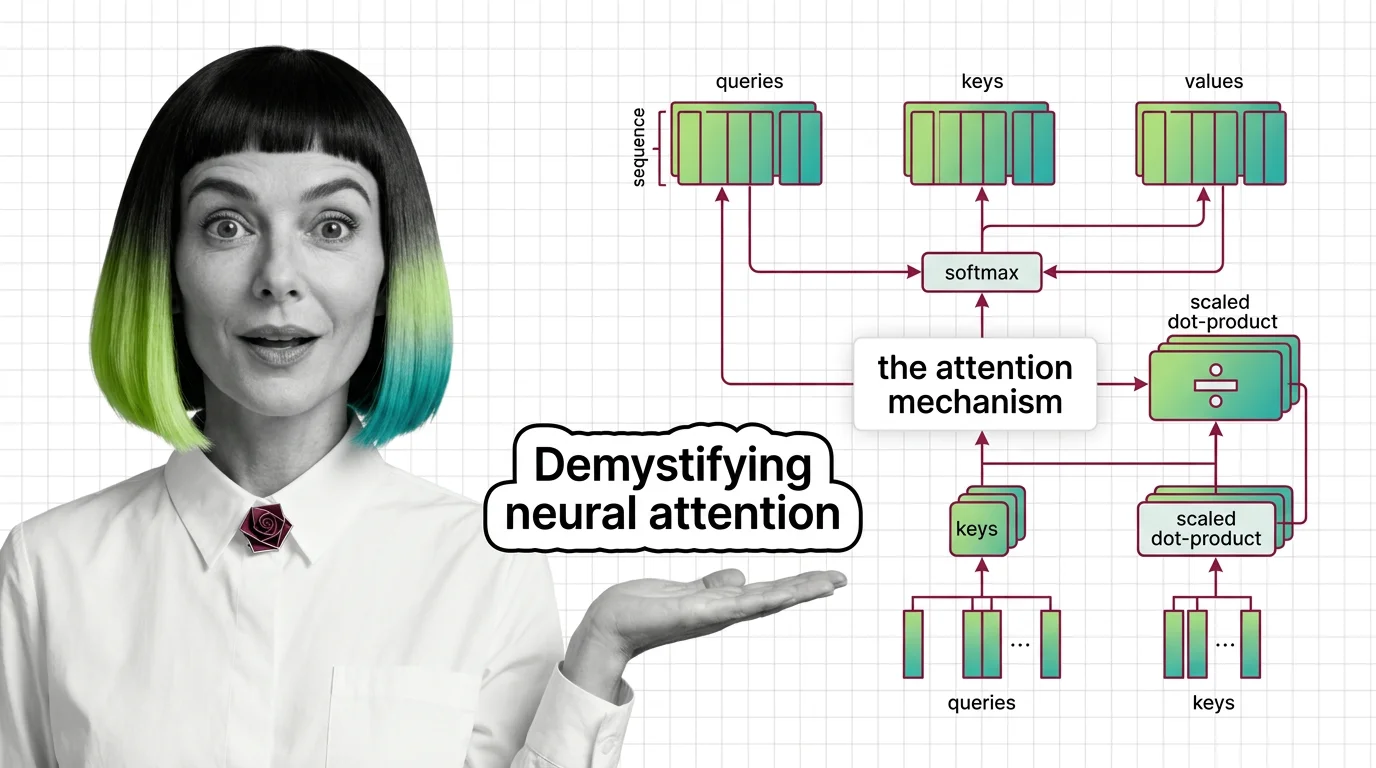
What Is the Attention Mechanism: Scaled Dot-Product, Self-Attention, and Cross-Attention Explained
Understand how the attention mechanism works inside transformers. Covers scaled dot-product attention, self-attention vs …
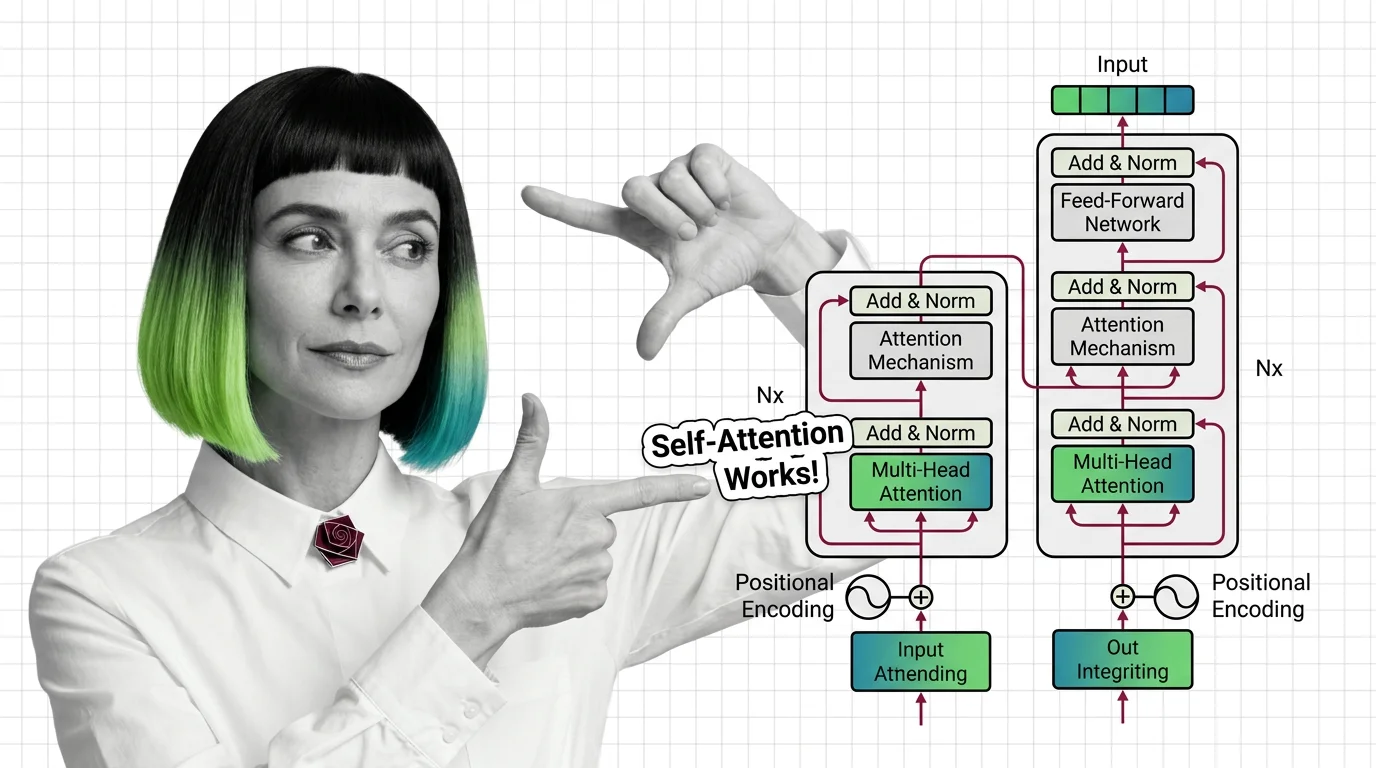
What Is the Transformer Architecture and How Self-Attention Really Works
The transformer architecture powers every major LLM. Learn how self-attention computes token relationships, why …
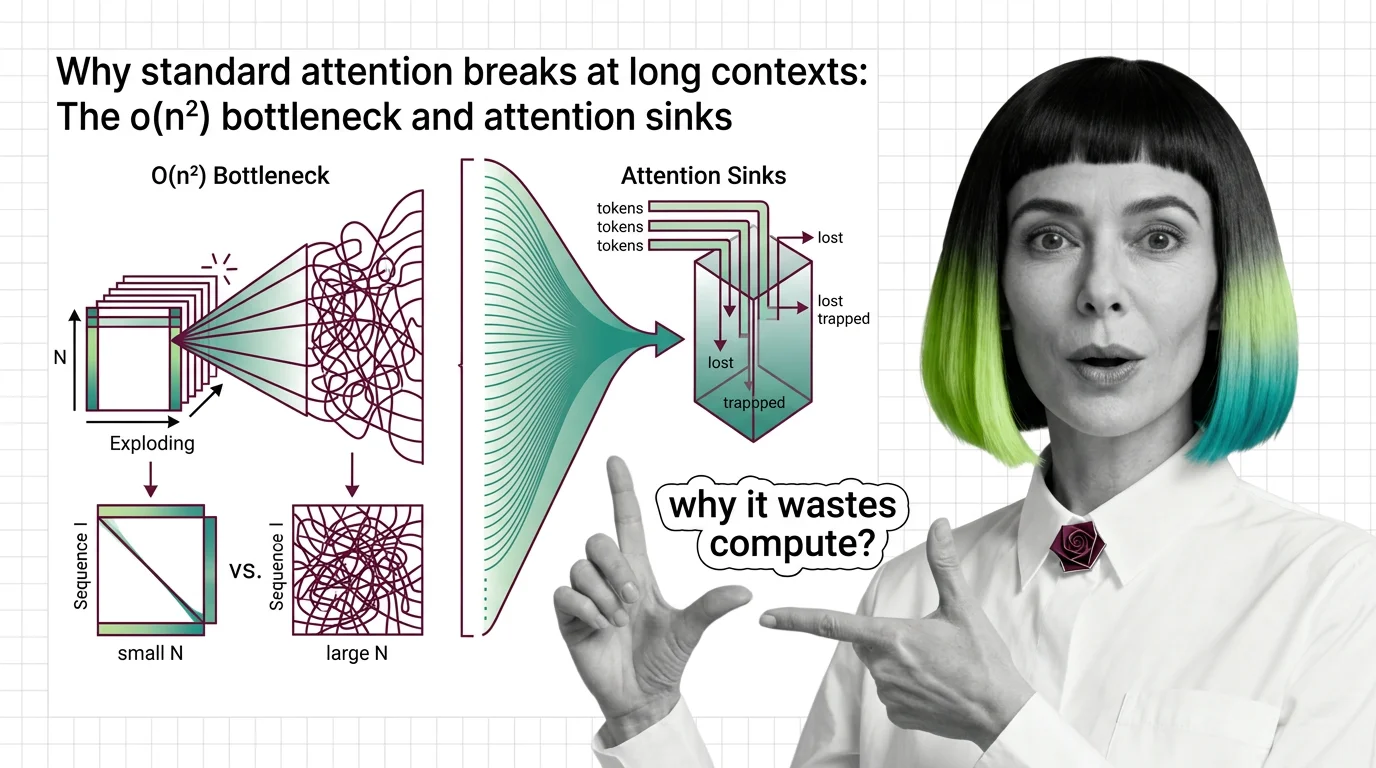
Why Standard Attention Breaks at Long Contexts: The O(n²) Bottleneck and Attention Sinks
Standard attention scales quadratically with sequence length. Learn why O(n²) breaks at long contexts, what attention …
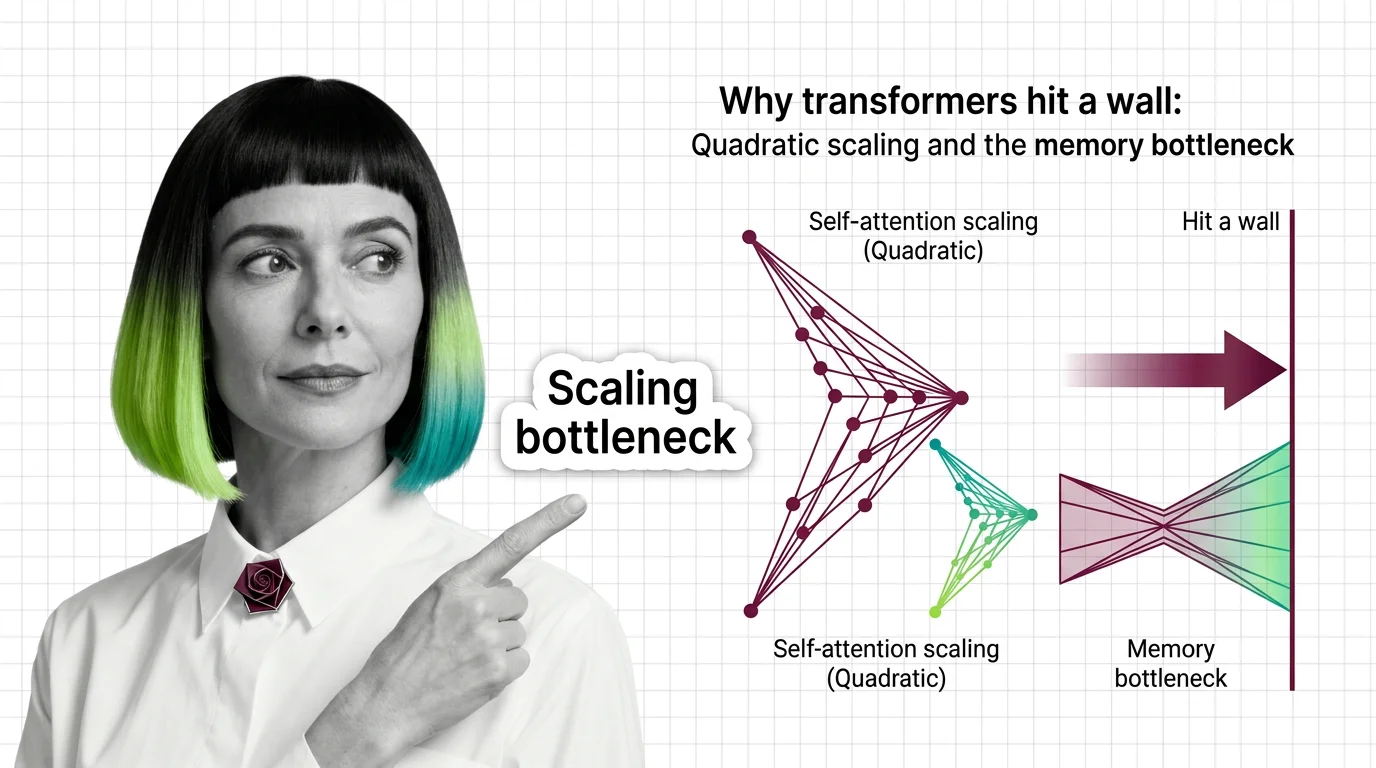
Why Transformers Hit a Wall: Quadratic Scaling and the Memory Bottleneck
Transformer self-attention scales quadratically with sequence length. Understand the O(n²) memory wall, KV cache costs, …