How to Build a Semantic Search Pipeline with Voyage AI, NV-Embed, and Open-Source Models in 2026
Specification-first framework for building semantic search in 2026. Choose between Voyage 4, NV-Embed-v2, and BGE-M3 …
How to Build a Similarity Search Pipeline with FAISS, HNSWlib, and ScaNN in 2026
Build a similarity search pipeline with FAISS, HNSWlib, or ScaNN using a specification-first approach. Covers index …
How to Build and Fine-Tune Transformer Models with Hugging Face and PyTorch in 2026
Build and fine-tune transformer models the specification-first way. PyTorch 2.10, Hugging Face Transformers v5, and the …
How to Train and Choose a Custom Tokenizer with tiktoken, SentencePiece, and HF Tokenizers in 2026
Learn how to choose, train, and validate a custom tokenizer using tiktoken, SentencePiece, and HF Tokenizers with a …
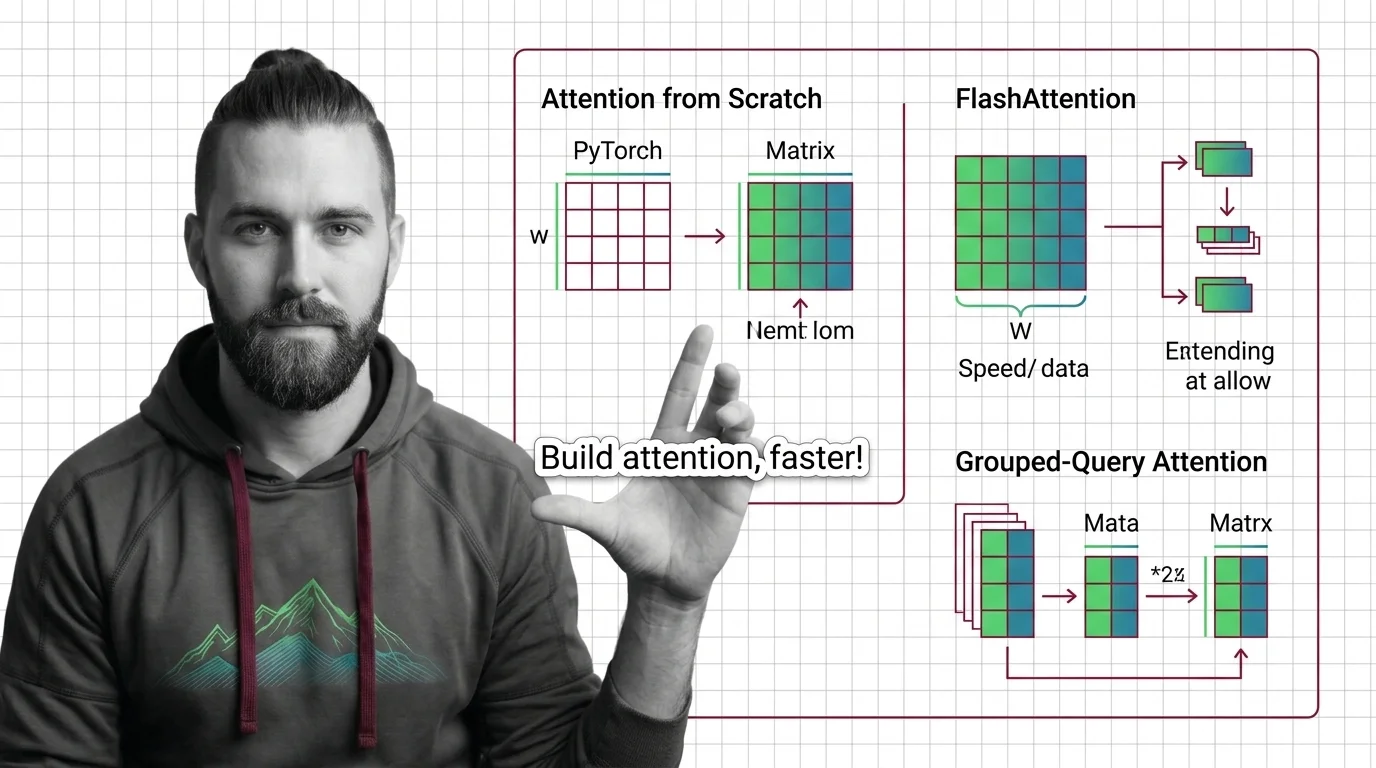
Implementing Attention from Scratch: PyTorch, FlashAttention, and Grouped-Query Optimization
Spec your attention implementation before writing code. Learn to decompose QKV projections, configure FlashAttention …
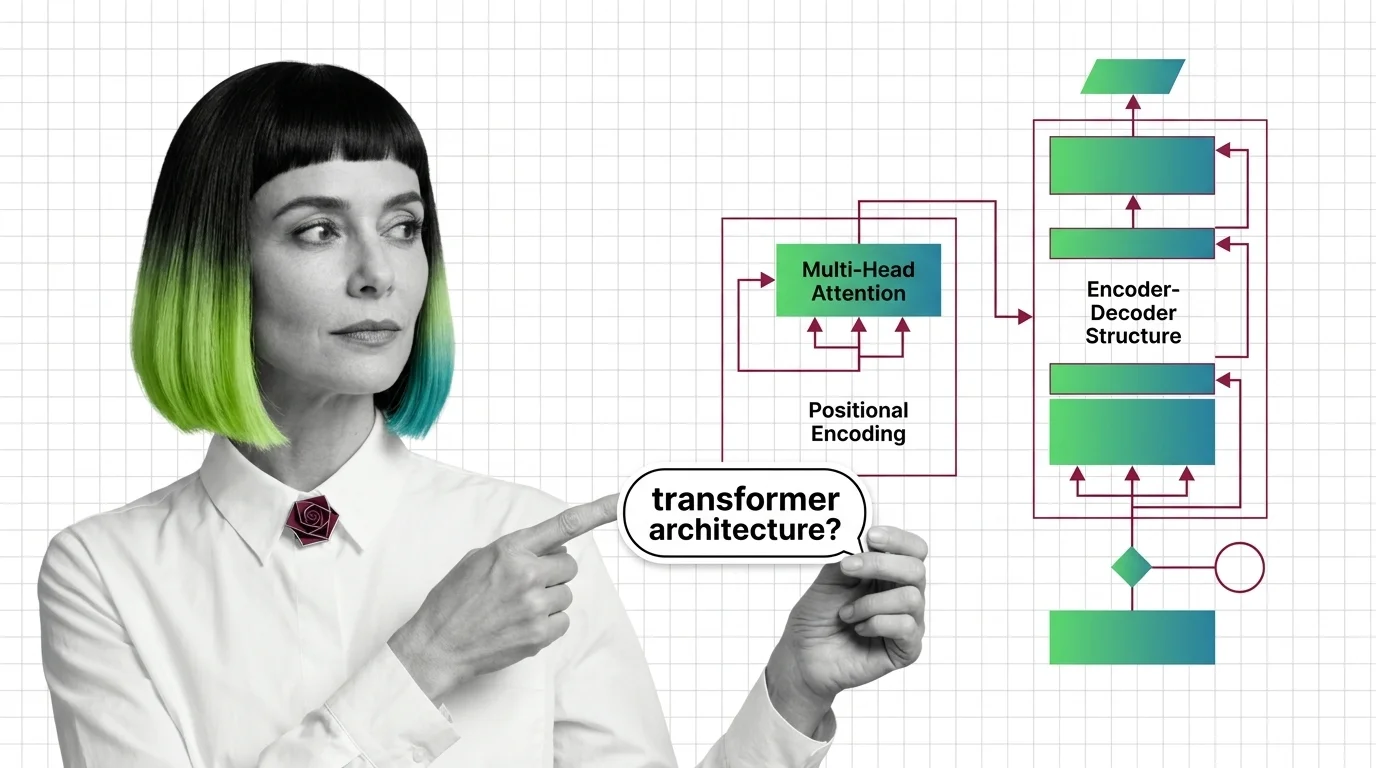
Multi-Head Attention, Positional Encoding, and the Encoder-Decoder Structure Explained
Multi-head attention, positional encoding, and encoder-decoder structure: the three mechanisms inside every transformer, …

NV-Embed v2, Qwen3-Embedding, and the Open-Source Surge Reshaping the Embedding Market in 2026
Open-weight embedding models now match proprietary APIs on benchmarks at a fraction of the cost. What the 2026 market …
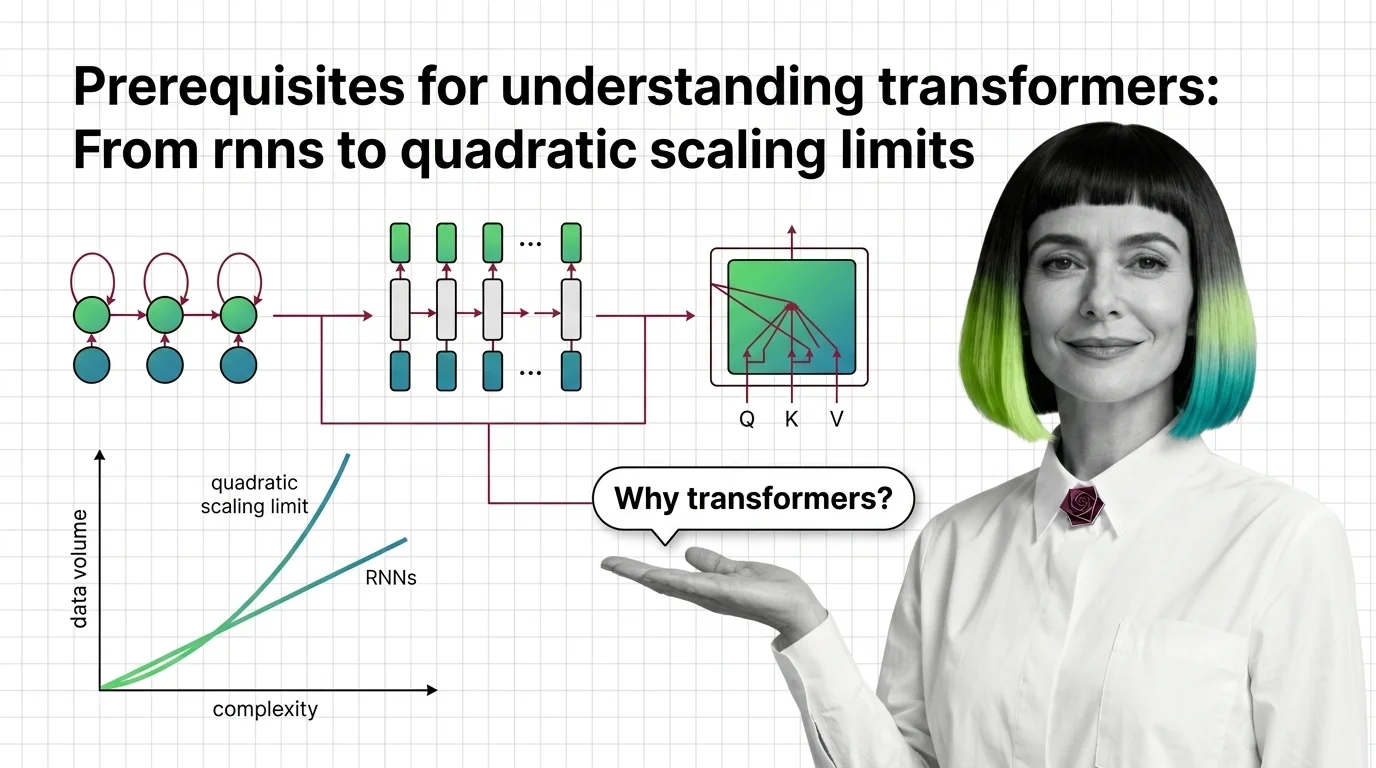
Prerequisites for Understanding Transformers: From RNNs to Quadratic Scaling Limits
Understand why RNNs failed, how transformer self-attention trades parallelism for quadratic cost, and what these …
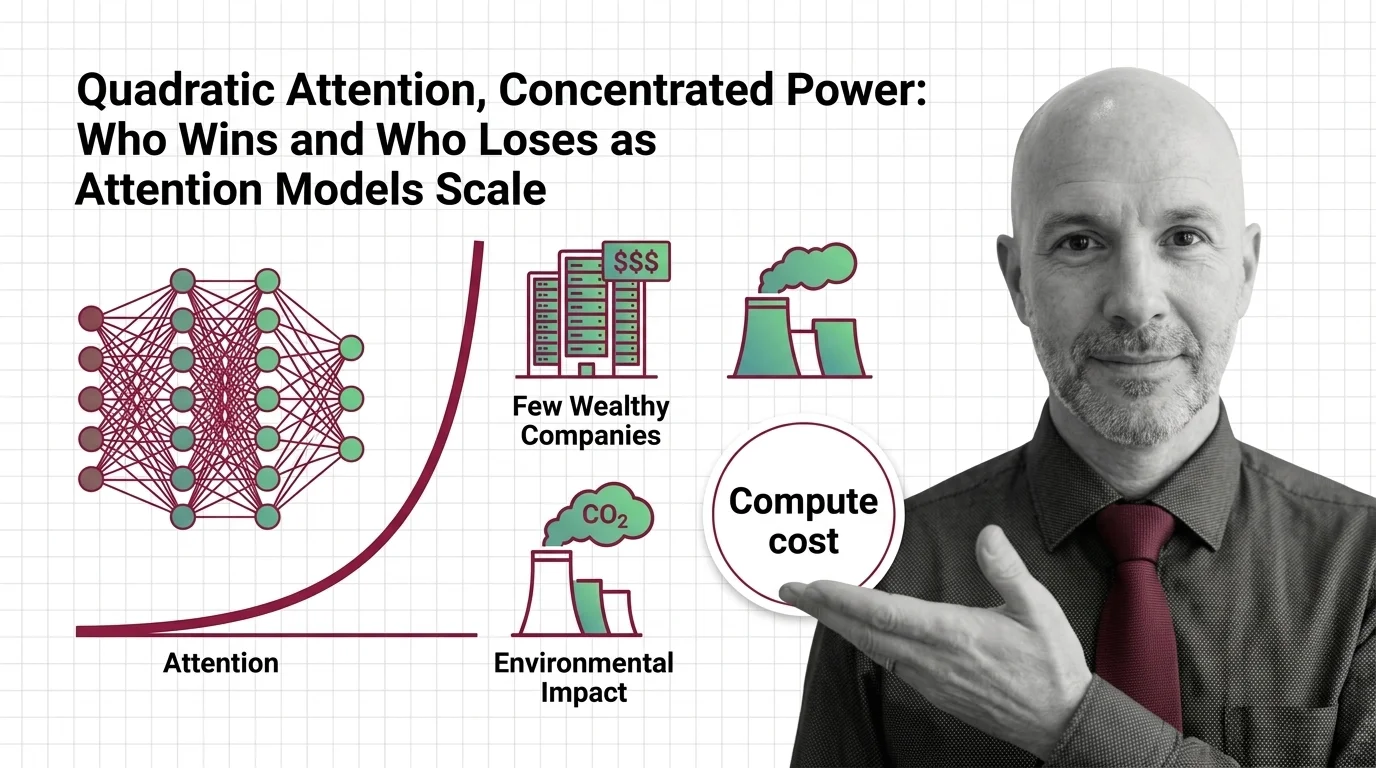
Quadratic Attention, Concentrated Power: Who Wins and Who Loses as Attention Models Scale
Quadratic attention scaling isn't just a compute problem — it shapes who builds frontier AI, who profits, and whose …
Self-Attention vs. Cross-Attention vs. Causal Masking: Attention Variants and Their Limits
Self-attention, cross-attention, and causal masking solve different problems inside transformers. Learn the math, …

SuperBPE, LiteToken, and the 262K Vocabulary Race: Tokenizer Breakthroughs Reshaping LLMs in 2026
BPE tokenization is no longer a solved problem. SuperBPE, LiteToken, and 262K vocabularies expose measurable …
T5Gemma 2 and the Encoder-Decoder Revival: Why Google Doubled Down While Others Went Decoder-Only
Google shipped T5Gemma 2 with 128K context and multimodal input, betting on encoder-decoder while rivals stayed …

The Decoder-Only Monoculture: What the AI Industry Risks by Betting on a Single Architecture
The AI industry converged on decoder-only architecture without rigorous comparison. Explore the ethical and structural …

The Ethical Cost of Transformers: Energy Use, Centralization, and Access Inequality
Transformer architecture demands enormous energy and capital. Explore the ethical costs of quadratic compute, …
The Hidden Bias in Tokenizers: Why Non-English Speakers Pay More Per Token
Tokenizer bias means non-English speakers pay more per API token. Explore why this structural disparity exists and who …
Transformers in 2026: GPT to Gemini, Mamba-3, and the Hybrid Architecture Shift
Mamba-3 and Nvidia Nemotron signal the hybrid architecture era. See which AI models still run pure transformers, who is …
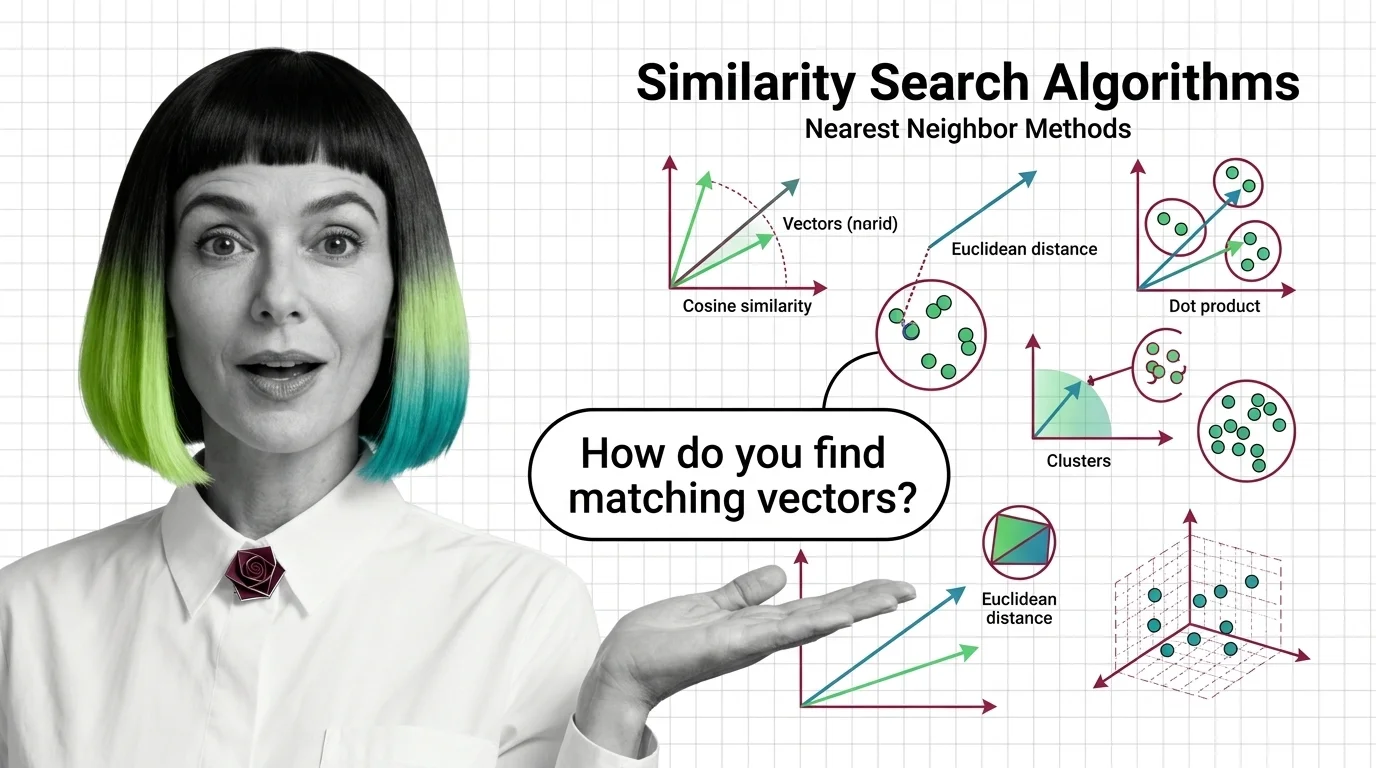
What Are Similarity Search Algorithms and How Nearest Neighbor Methods Find Matching Vectors
Similarity search algorithms find matching vectors by measuring geometric distance, not keywords. Learn how HNSW, PQ, …

What Is an Embedding and How Neural Networks Encode Meaning into Vectors
Embeddings turn words into vector coordinates where distance equals meaning. Learn the geometry, training mechanics, and …

What Is Decoder-Only Architecture and How Autoregressive LLMs Generate Text Token by Token
Decoder-only architecture powers every major LLM today. Learn how causal masking, KV cache, and autoregressive …
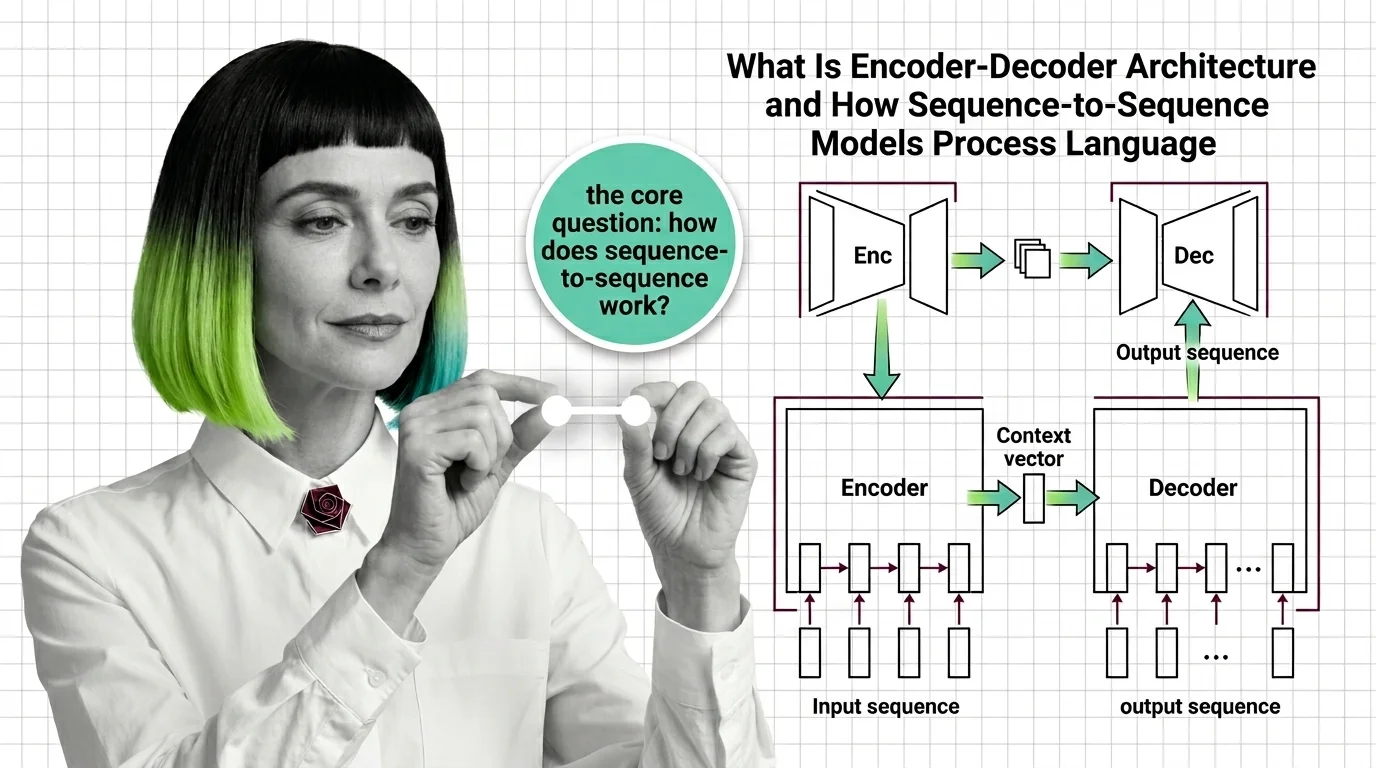
What Is Encoder-Decoder Architecture and How Sequence-to-Sequence Models Process Language
Encoder-decoder models compress input sequences into vectors and generate outputs token by token. Learn how seq2seq …
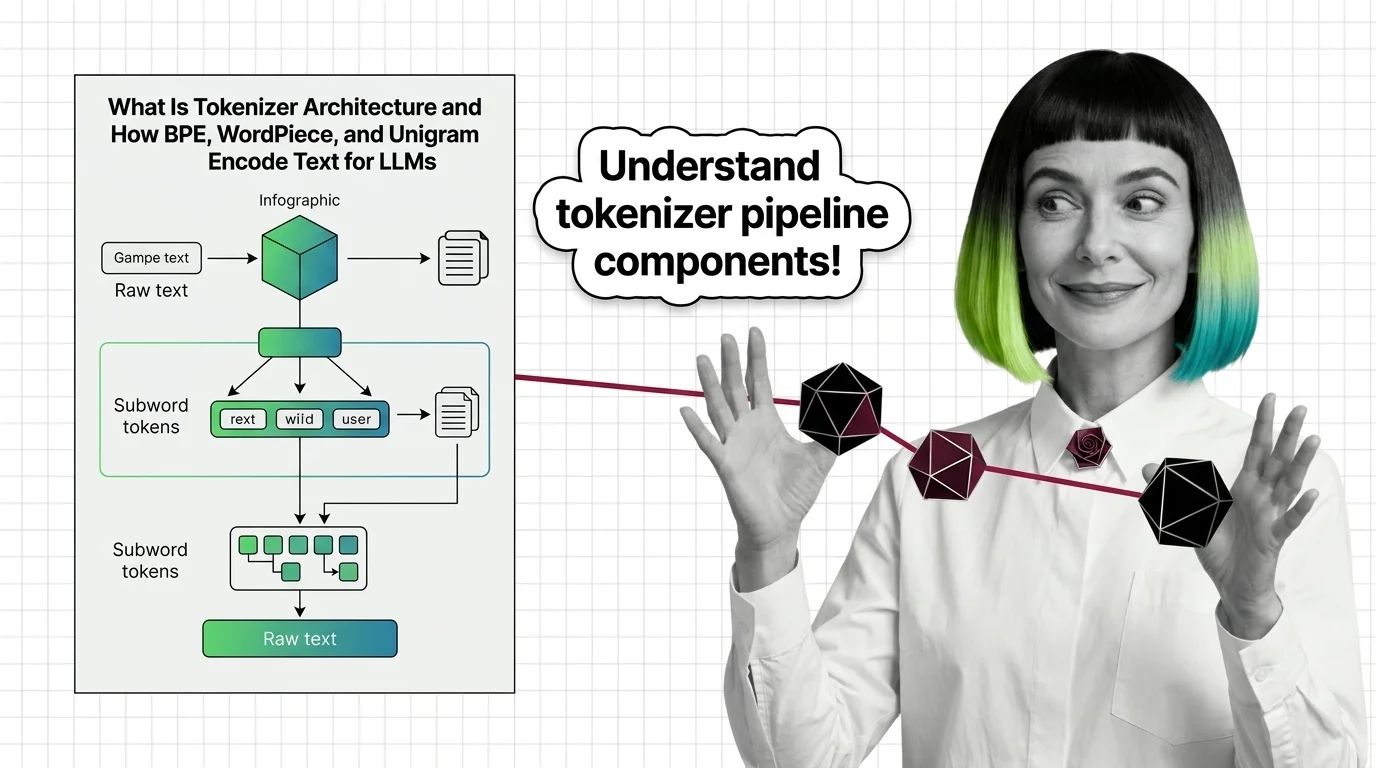
What Is Tokenizer Architecture and How BPE, WordPiece, and Unigram Encode Text for LLMs
Tokenizer architecture determines how LLMs read text. Learn how BPE, WordPiece, and Unigram split text into subword …

What Is Transformer Architecture and How Self-Attention Replaced Recurrence
Transformers replaced sequential recurrence with parallel self-attention. Understand QKV computation, multi-head …

When Nearest Neighbors Are Wrong: Bias Propagation and Accountability Gaps in Similarity Search Systems
Similarity search algorithms sort people at scale. Explore how biased embeddings propagate discrimination in hiring and …
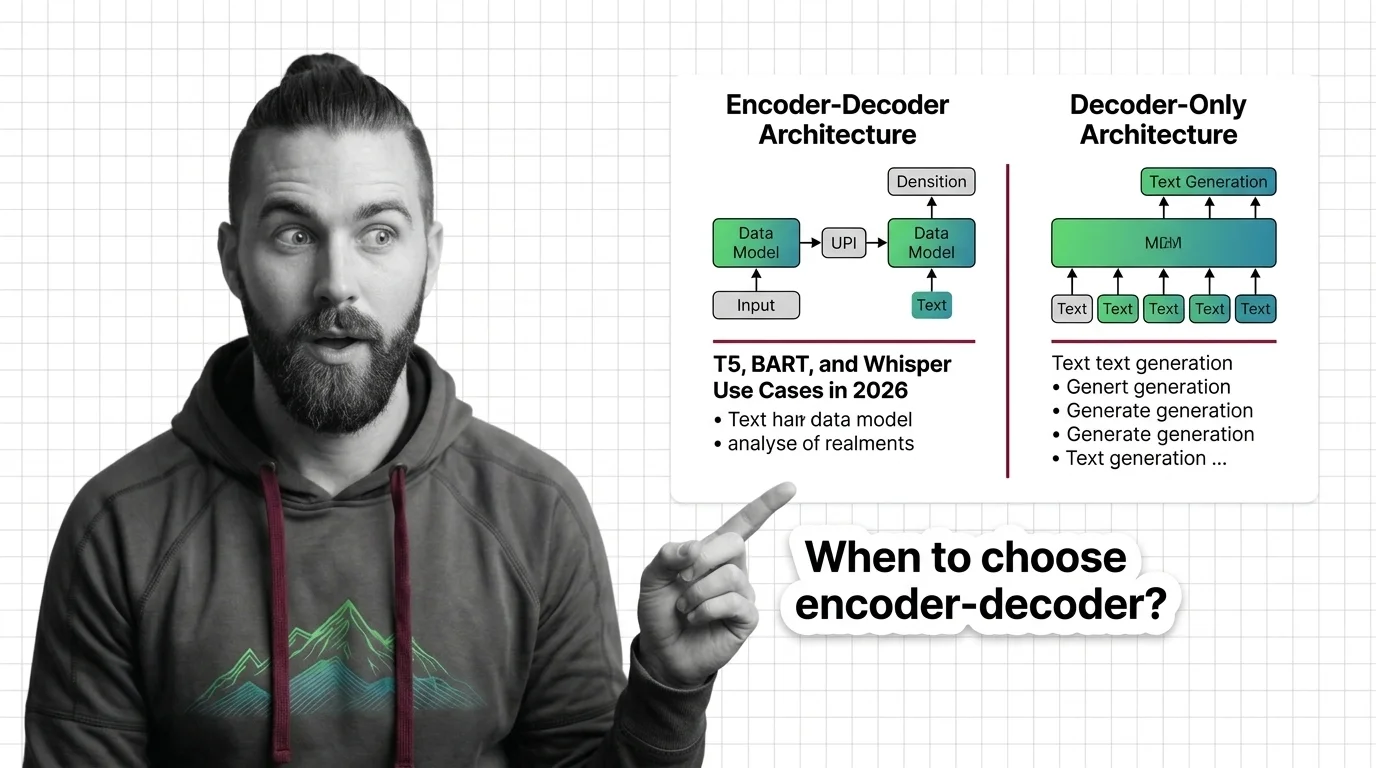
When to Choose Encoder-Decoder Over Decoder-Only: T5, BART, and Whisper Use Cases in 2026
Learn when encoder-decoder models like T5, BART, and Whisper outperform decoder-only alternatives. A spec framework for …
Why Decoder-Only Beat Encoder-Decoder: Scaling Laws, Data Efficiency, and the Simplicity Advantage
Decoder-only models won the scaling race by doing less. Learn how a simpler training objective, scaling laws, and MoE …

Flash Attention, Linear Attention, and the Race to Fix the Bottleneck in 2026
FlashAttention-4 and linear attention models are racing to solve the quadratic bottleneck in transformers. Here's who …
From Embeddings to Attention: The Math You Need Before Studying Transformers
Master the math behind attention mechanisms — dot products, softmax, QKV matrices, and multi-head projections — before …
How to Build a Transformer from Scratch Using PyTorch and Hugging Face
Specify a transformer from scratch in PyTorch and Hugging Face. Decompose attention, embeddings, and training loops into …
How to Implement Multi-Head Attention in PyTorch and Visualize Attention Patterns
Specify multi-head attention for AI-assisted PyTorch builds. Decompose QKV projections, constrain SDPA kernels, and …
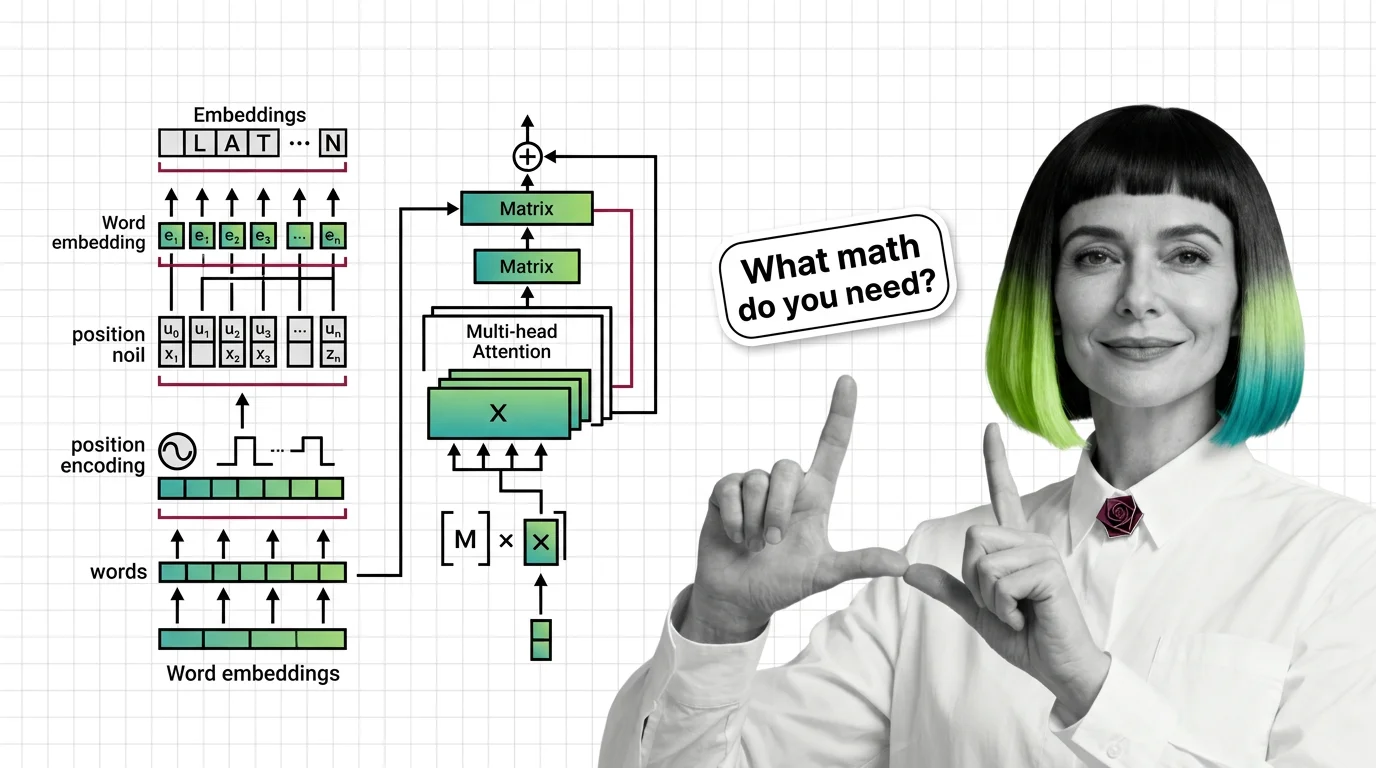
Prerequisites for Understanding Transformers: From Embeddings to Matrix Multiplication
Master the math behind transformers: embeddings, matrix multiplication, positional encoding, and multi-head attention …